
融合词性与外部知识的方面级情感分析
2023-10-29 04:21:06谷雨影高美凤
计算机与生活 2023年10期
谷雨影,高美凤+
1.江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122
2.江南大学 物联网工程学院,江苏 无锡 214122
情感分析,也称意见挖掘,是指对一段文本的感情进行分类。观察微博、淘宝以及美团等一些平台上的评论,大部分文本都体现出了用户的情绪倾向,提取并分析其中的情绪数据,对其进行情感分类,可以更好地理解用户行为。方面级情感分析是一种重要的细粒度情感分类,它的主要目的是识别句子中不同方面词的情绪极性(积极、中性和消极)。例如,在“The battery is durable but the screen is small.”中,句子体现了评论者对商品两方面的态度倾向,对“battery”的积极和“screen”的消极。细粒度的情感分析可以捕捉到与不同方面词相关的意见词,因此,方面级情感分析的研究具有深远的应用价值。
早期的方面级情感分析研究方法基于情感词典和传统机器学习进行,Malouf等人[1]应用情感字典和支持向量机(support vector machine,SVM)进行情感分类。但是这些方法需要人工制定分类规则,并且需要投入高额的人工成本,得到的模型不仅效果和泛化能力不理想,而且随着网络时代的发展,已经不能满足情感分类任务高标准的要求。因此近年来,方面级情感分析的研究方法转向了深度学习模型,Kim[2]使用卷积神经网络(convolutional neural network,CNN)模型捕捉文本的局部相关性;基于循环神经网络(recurrent neural network,RNN)的模型可以捕获序列之间的关系;Mnih等人[3]将注意力机制用在图像分类任务中,使结合了注意力机制的神经网络模型成为研究的热点。随后,Bahdanau等人[4]将注意力机制和RNN 结合,在自然语言处理领域内掀起了注意力机制和神经网络结合应用的热潮。Zhou 等人[5]结合句子层次的注意力来突破现有模型对局部特征和远距离依赖特征提取能力的局限性。Lin等人[6]将语义信息引入深度记忆网络,并将方面词与上下文之间的距离信息融入注意力机制进行情感分类。Fan等 人[7]利 用BiLSTM(bidirectional long short-term memory)对语义信息进行建模,设计了一种多粒度注意力机制,以细粒度的方式学习方面词和上下文之间的关系。Wu等人[8]使用残余注意力机制解决了一般注意力机制容易丢失原始信息的问题,来更好地捕获上下文面向方面术语的语义信息。对于一个句子,RNN模型对方面词上下文的关注度不高,注意力机制可以使神经网络模型更加关注上下文中的情感信息,忽略与方面词无关的噪声词,从而提高模型分类的性能。然而,在需要捕捉复杂语句中的情感信息时,这些模型的表现还具有改进潜力。
外部知识[9-10]通常被用作在情感分析任务中增强情感特征表示的来源,Ren等人[11]利用情感词典来捕获句子中的情绪信息来计算注意力权重。Valle-Cruz等人[12]验证与其他情感词典对比,SenticNet能够更好地捕捉词语之间的相关性。SenticNet[13]是用于意见挖掘和情感分析的公开资源,它为每个概念提供了情感值。Ma等人[14]将常识知识融入LSTM(long shortterm memory)模型,通过利用通用知识提取目标级和句子级的情感特征,在两个公开的数据集上表现出优秀的性能。然而,在包含多个方面词的句子中,由于它们不能充分捕捉上下文词与句子中各个方面词之间的句法依赖关系,这些模型的应用仍然有限。
句法依赖分析可将长距离的方面词与意见词通过句法函数相关联,从而加强词语之间的联系,而为了利用依赖关系图信息,图卷积神经网络(graph convolutional network,GCN)[15]被应用来从依赖树中学习句子的句法特征表示。Zhang 等人[16]在句子依赖树的基础上提出了图卷积网络模型,充分利用了上下文的句法信息和单词间的依赖关系。Wang等人[17]通过依赖句法分析文本的自然语言语义特征,以此来融合方面词和整体句子。Yu等人[18]提出多权重图卷积网络模型来避免注意力机制引起的不准确权重,上下文词语与最终权重的结合突出显示了方面词,并有效保留了整体语义的有用信息。Xu 等人[19]使用异构图定义句子和方面节点,并提出窗口机制和位置机制来分别学习句子和方面表达。Zhao等人[20]使用两个聚合器捕获远距离依赖的特征,有效地提取上下文和方面序列的信息。然而,大部分研究人员更关注于深度神经网络的改进[21-22],没有专注于依赖关系图的构建,从而忽略了其他细粒度信息(例如词性信息和位置信息)和常识性知识信息,并且使基于深度学习的方面级情感分析模型越发复杂,参数过多的情况下模型训练更易引发过拟合。
针对上述问题,本文提出了一种多融合简化图卷积神经网络模型(multi-fusion simplifying graph convolutional network,MFSGC)。模型利用词性进行信息筛选,对句法依赖树进行剪枝处理,使模型更关注方面词与意见词,同时运用情感词典来增强情感特征表示,它能够充分利用句法依存信息,从而提高分类效果。并使用简化图卷积网络(simplifying graph convolutional network,SGC)[23],提高基于图卷积的方面级情感分析模型性能。本文贡献如下:
(1)提出多融合邻接矩阵算法,使用情感词典增强情感词的作用,并利用词性对句法依赖树进行剪枝处理,旨在提高对句法依赖树信息的利用率。
(2)将简化图卷积网络用于方面级情感分析任务中,通过消除GCN层间的非线性来使网络更高效。
(3)对五个公开数据集进行了实验,结果证明了本文模型的性能。
1 MFSGC模型
模型如图1所示,由词嵌入层、语义提取层、多融合邻接矩阵算法层、图卷积网络层、掩码机制层、注意力机制层和最终的情感分类层组成。在本文模型中,使用s={w1,w2,…,wτ,…,wτ+m,…,wn-1,wn}表示长度为n的输入句子,即每个句子由一系列单词wi组成,其中{w1,w2,…,wτ}和{wτ+m+1,…,wn-1,wn}分别为句子中的上下文词,a={wτ+1,wτ+2,…,wτ+m}为给定句子中长度为m的方面词。
1.1 词嵌入层
对于给定的包含n个单词的句子s,首先将每个单词映射到一个低维向量空间,本文采用Glove预训练词典获得词嵌入矩阵。对于每一个输入单词wi,均由一个d维向量vi表示,词向量在预训练词典中查找方式为:
通过式(1)得到每个单词对应的词向量vi,嵌入完成后的句子表示为V={v1,v2,…,vτ,…,vτ+m,…,vn-1,vn}。
1.2 语义提取层
循环神经网络已经成功应用于自然语言处理领域内,然而,标准的RNN经常面临梯度消失和梯度爆炸的问题。LSTM 是一种特殊的RNN,在每个时间步长上通过三种门控机制调整细胞状态,更好地解决了长距离依赖性的问题。对于文本情感分类问题,序列后值和序列前值一样会影响分类结果,本模型采用BiLSTM 构成语义提取层。BiLSTM 可以建立正向和反向的上下文依赖关系,与单向LSTM 相比,它可以同时通过前向传播算法和后向传播算法来学习更多的上下文信息。
1.3 多融合邻接矩阵
大部分基于图卷积网络的方面级情感分析对句法依赖树上的信息利用较为低效,为充分利用句法依赖树中包含的情感信息,受文献[24]的启发,本文提出多融合邻接矩阵算法,使用情感词典增强句子中的情感词,参照Xiao 等人[25]的方法通过手动和模型选择构建无效词性组合来对原始依赖树进行剪枝处理,去除与方面词无关的文本带来的噪声,并加强方面词与情感词间的依赖性,使模型更关注于与方面词相关的意见词。多融合邻接矩阵的构建过程如图2 所示:首先,对于每一个输入句子,对其分词、提取词性和方面词;然后,使用SenticNet词典赋予单词情感分数以增强文本情感特征;最后,剪掉词性在无效词性列表中文本的依赖关系。

图2 多融合邻接矩阵流程图Fig.2 Flowchart of multi-fusion adjacency matrix
1.3.1 情感词典
由于SenticNet 能很好地捕捉词语之间的相关性,本文选择它来增强文本情感特征。SenticNet 可以对句子中的每个词语进行分析,计算它们的情感分数,其中sn.polarity_value(wi)∈[-1,1],对于积极的文本数据,其情感分数为正,而消极的文本数据,其情感分数为负值,表1列举了几个文本词及其情感分数。
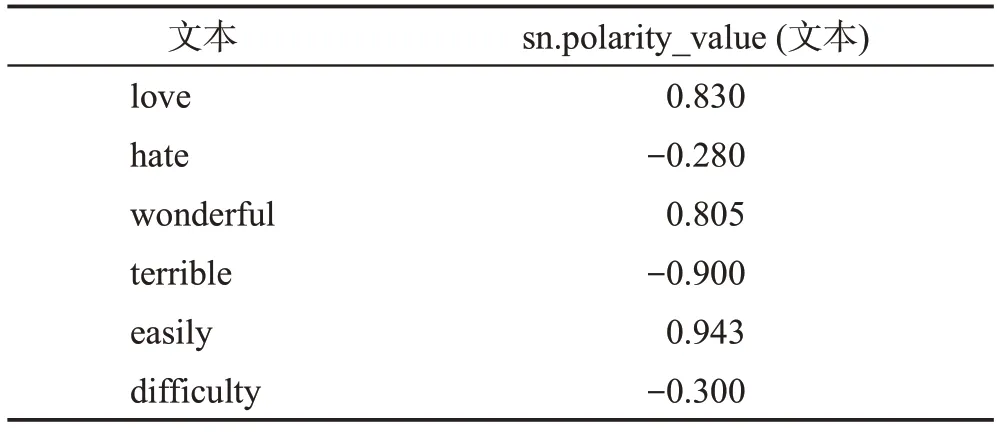
表1 文本情感分数示例Table 1 Example of text emotional score
参照文献[24]的方法,将具有依赖关系的词的情感分数相加,增强文本之间的情感特征表示,使模型更关注情感词,可以充分利用上下文单词间的潜在情感依赖性。运用SenticNet得到两个单词间的情感依赖强度Sij,为:
其中,wi、wj表示输入句子中的单词文本,sn.polarity_value(wi)和sn.polarity_value(wj)为SenticNet 计算得到的单词情感分数。
1.3.2 剪枝句法依赖树
句子经过解析得到的句法依赖关系图中通常包含一些不必要的依赖关系,例如句子“But the staff was so horrible to us”的关系图为图3(a),图中存在文本“the”和“us”的依赖关系,但其不包含情感信息,对这些冗余的依赖关系进行剪枝处理可使模型更关注意见词。参照文献[25]的方法,提取得到输入文本的词性序列,结合语言学知识分析数据集文本,发现带有情感色彩的文本词性集中在名词、形容词、副词和动词上,先将其他种类的词性视为无效词性,在生成邻接矩阵过程中删除其中某一词性单词后,若情感分类准确率得到了提高,就将此词性添加到列表B中,并在后续处理中剪掉此词性文本的所有句法关系,即Pij=0。在上述句子中剪掉冗余的依赖关系后,得到句法依赖关系图3(b),在剪枝后的关系图中存在更少的依赖关系,一定程度上可以消除无效词性文本带来的噪音,对比邻接矩阵表2 和表3 可知,剪枝后的邻接矩阵更为稀疏,可以使模型更关注与方面词相关的意见词,从而提高模型的分类性能。图3中,CC(coordinating conjunction)表示连接词;DT(determiner)表示限定词;NN(noun,singular or mass)表示常用名词单数形式;VBD(verb,past tense)表示动词过去式;RB(adverb)表示副词;JJ(adjective)表示形容词或序数词;IN(preposition or subordinating conjunction)表示介词或从属连词;PRP(personal pronoun)表示人称代词;nsubj(nominal subject)表示名词性主语;advmod(adverbial modifier)表示状语修饰语;acomp(adjectival complement)表示动词的形容词补语;prep(prepositional modifier)表示介词修饰;pobj(object of a preposition)表示介词的宾语。
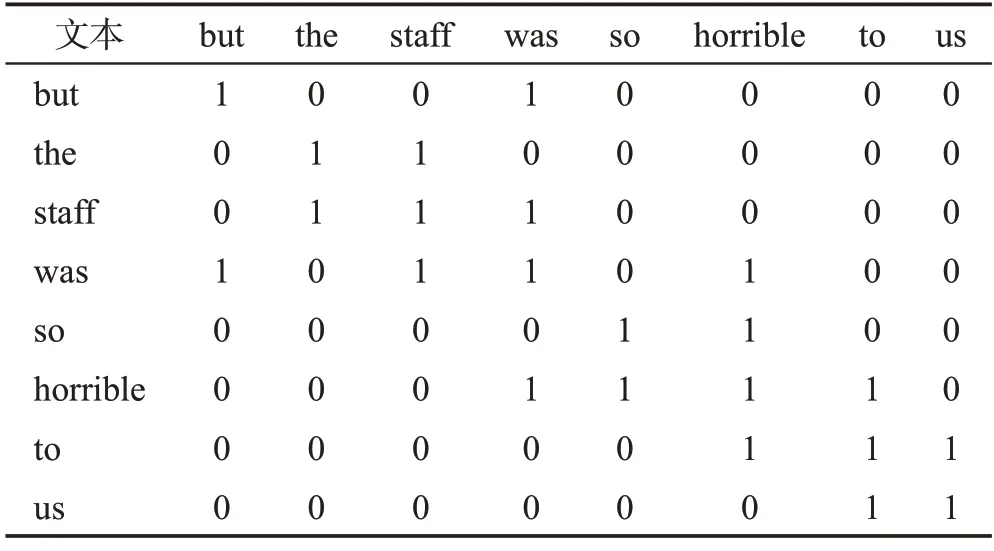
表2 原始邻接矩阵Table 2 Primitive adjacency matrix
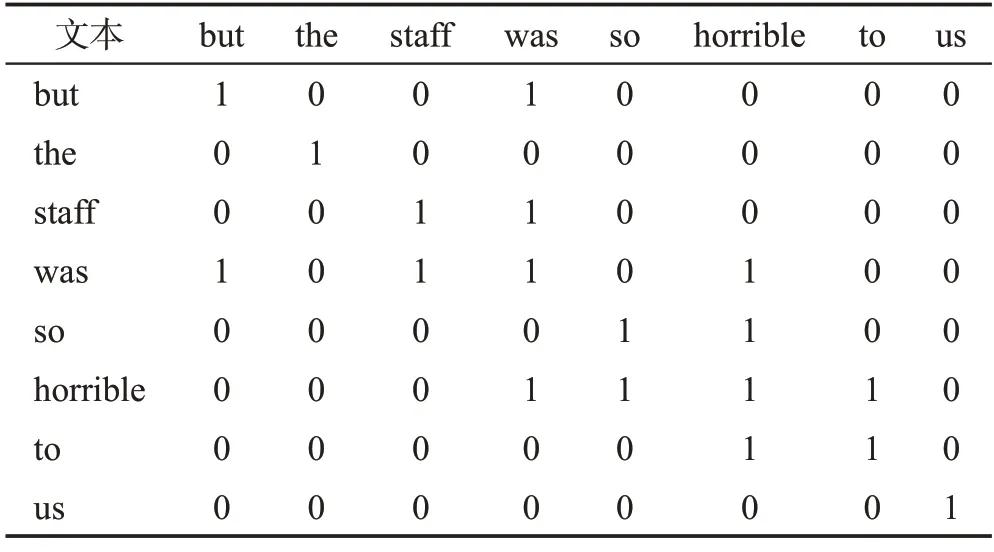
表3 剪枝后邻接矩阵Table 3 Adjacency matrix after pruning
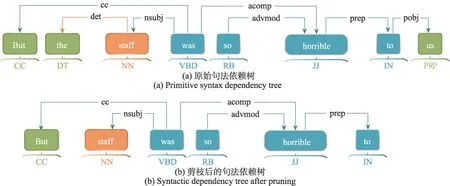
图3 句法依赖树示例Fig.3 Syntax dependency tree example
1.3.3 多融合邻接矩阵
对输入句子解析得到原始句法依赖树,若单词间存在依赖关系,则Rij=1,否则Rij=0。为了增强上下文词和方面词间的情感依赖关系,若依赖关系中双方分别为情感词和方面词,则令Cij=1,否则为0。最终句子的邻接矩阵中元素Aij的计算方式为:
其中,Rij为基于原始句法图的邻接矩阵元素,Sij为经过情感词典加强后的情感分数。Pij为剪枝后的句法依赖树得到的邻接矩阵元素。最后,向模型加入自循环约束[16],另每个节点都有指向自身的连接,即邻接矩阵主对角线上的元素为非0值。
1.4 基于多融合邻接矩阵算法的SGC
GCN 的灵感主要来自深度学习方法,因此可能会继承不必要的复杂度和冗余计算,本文运用Felix等人[23]的SGC对基于图卷积的方面级情感分类进行改进。SGC通过反复消除GCN层之间的非线性并将得到的函数折叠成一个线性变换来减少GCN的额外复杂度,减少计算量的同时更高效。为增强与方面词相近的上下文词的重要性,在输入SGC层前,对文本进行位置编码。
句子“sometimes I get good food and ok service”中,方面词为“food”,另外可以观察得到“good”包含的信息对预测方面词“food”的情感极性更重要,因此使用位置权重层,第i个词的位置权重qi的计算方式为:
其中,τ+1 和τ+m分别为方面词的开始位置和结束位置,对语义提取层得到的隐藏状态向量进行权重分配,为:
其中,ht为语义提取层得到的单词隐藏状态向量。
依赖关系树转换为邻接矩阵图,其节点表示给定句子中的单词,将图输入到SGC层中,以学习单词之间的依赖关系,得到第i个节点的第l层SGC的输出为:
1.5 掩码机制层
为突出方面词的特征,对图卷积网络层的输出进行遮掩,屏蔽非方面词,并保持方面词的向量不变[16]。掩码权重mi计算方式为:
掩码机制层的最终输出HL-MASK为:
1.6 注意力机制层
运用基于检索的注意力机制,从给定句子的隐藏状态向量中检索与方面词情感极性相关的单词[16],而从改进句法依赖树构建的图可以得出句子中单词的情感依赖信息,按照每个上下文单词的重要程度分配权重。注意力权重计算方式为:
其中,αt为得到的注意力权重,ht为上文中经过BiLSTM处理后得到的词向量,最终的带权特征向量r为:
1.7 情感分类层
将得到的表示输入到一个全连接层,通过softmax分类器将向量映射到极性决策空间上进行分类,如下:
其中,Wp和bp是可训练的权重矩阵和偏置项。
2 实验
2.1 实验数据
为了验证模型有效性,本文使用Li等人[26]整理的Twitter短文本评论数据集,以及由SemEval官方发布的ASC 基准数据集,包 括SemEval-2014 Task 4[27]、SemEval-2015 Task 12[28]和SemEval-2016 Task 5[29]中的数据集。其中,使用SemEval-2014 中的Restaurant14 和Laptop14 数据集,SemEval-2015 中的Restaurant15数据集,SemEval-2016中的Restaurant16数据集。每个数据集中都包含一个训练集和测试集,每个数据都是一个句子,包含评论文本、方面词、与方面词对应的情感标签以及方面词的起始位置。标签包含积极、中性和消极的情感,训练集和测试集以及标签分布见表4。

表4 数据集Table 4 Dataset
2.2 实验环境和参数配置
本文实验使用Windows 10 64 位操作系统以及Intel Core i5-9400@2.90 GHz CPU。在实验中,使用两种词嵌入方法,嵌入维度为300 的预训练Glove 词向量和嵌入维度768的Bert预训练模型,参数设置如下,学习率设置为0.001,使用adam 优化器用于优化训练参数,采用L2 正则化,正则化项系数设置为0.000 01,防止网络过拟合以及加快网络收敛,批训练样本设置为32。此外,本文模型除MFSGC-Bert外,均使用Glove词向量进行文本表示。
2.3 损失函数
本文使用交叉熵损失函数对模型的参数进行优化和更新,如式(14)所示:
其中,λ是L2正则化的系数;C为情感极性标签的数量,为3;D代表训练样本的数量;y为模型预测的极性类别;代表方面词真实的极性类别。
2.4 对比模型
SVM[30]:以经典的支持向量机为基础建立模型,将人工构造的特征和外部情感词典融合进行分类。
LSTM[31]:以长短时记忆网络为基础建立模型用于方面级情感分类。
MemNet[32]:引入深度记忆网络,在词嵌入上使用多个注意力层来构建更高层次的语义信息。
IAN(interactive attention networks)[33]:使用两个LSTM分别对方面词和上下文建模,交互注意机制学习上下文词与方面词间的联系。
AEN(attentional encoder network)[34]:采用基于注意的编码建立目标和上下文词之间的模型,在损失函数中加入标签平滑正则化项来解决标签不可靠性问题。
TranCaps[35]:使用转移胶囊网络将外部文档级情感信息融入到方面级情感分类中。
AOA(attention-over-attention)[36]:学习方面词与上下文的隐藏信息,并通过注意力机制关注句子中的重要部分。
ASGCN(aspect-specific graph convolutional networks)[16]:在句子依赖树上运用图卷积网络,充分利用了句子的语法信息和单词依存关系。
CDT(convolution over a dependency tree)[37]:将句子的依赖关系树与图神经网络结合,学习方面特征表示。
TD-GAT(target-dependent graph attention network)[38]:使用多层图注意网络将情感特征从重要的邻近词传递到方面目标词。
AEGCN(attention-enhanced graph convolutional network)[21]:引入多头自我关注捕捉上下文语义信息,使用多头交互注意力更好地结合语义和句法信息。
MHAGCN(multi-head attention mechanism and a graph convolutional network)[22]:设计分层多头注意力机制,结合语义信息实现方面词与上下文之间的交互。
2.5 实验结果与分析
如表5所示,本文提出的基于多融合邻接矩阵的图卷积神经网络模型MFSGC在5个数据集上均取得了优秀的情感分类效果,与直接运用依赖树中信息的ASGCN和CDT模型相比,所提出的模型在数据集中都取得了更高的准确率。在Twitter 数据集上,本文模型提升并不明显,仔细对比这5 个数据集,可以发现Twitter上的评论更加口语化,句法信息较弱,而MFSGC 增强了情感词信息,并修剪冗余的句法依赖树,这也使模型一定程度上更关注句法信息,因此,相较于其他数据集,本文模型在Twitter 上的改善不是很突出。此外,本文实验还采用了Bert预训练模型进行文本表示,MFSGC-Bert 在5 个数据集上达到了最佳效果,主要是因为Bert模型解决了Glove模型的一词多义问题。虽然使用Bert 预训练模型取得了更明显的提升效果,但其训练耗时长,且网络参数占用大量内存,预测较慢。
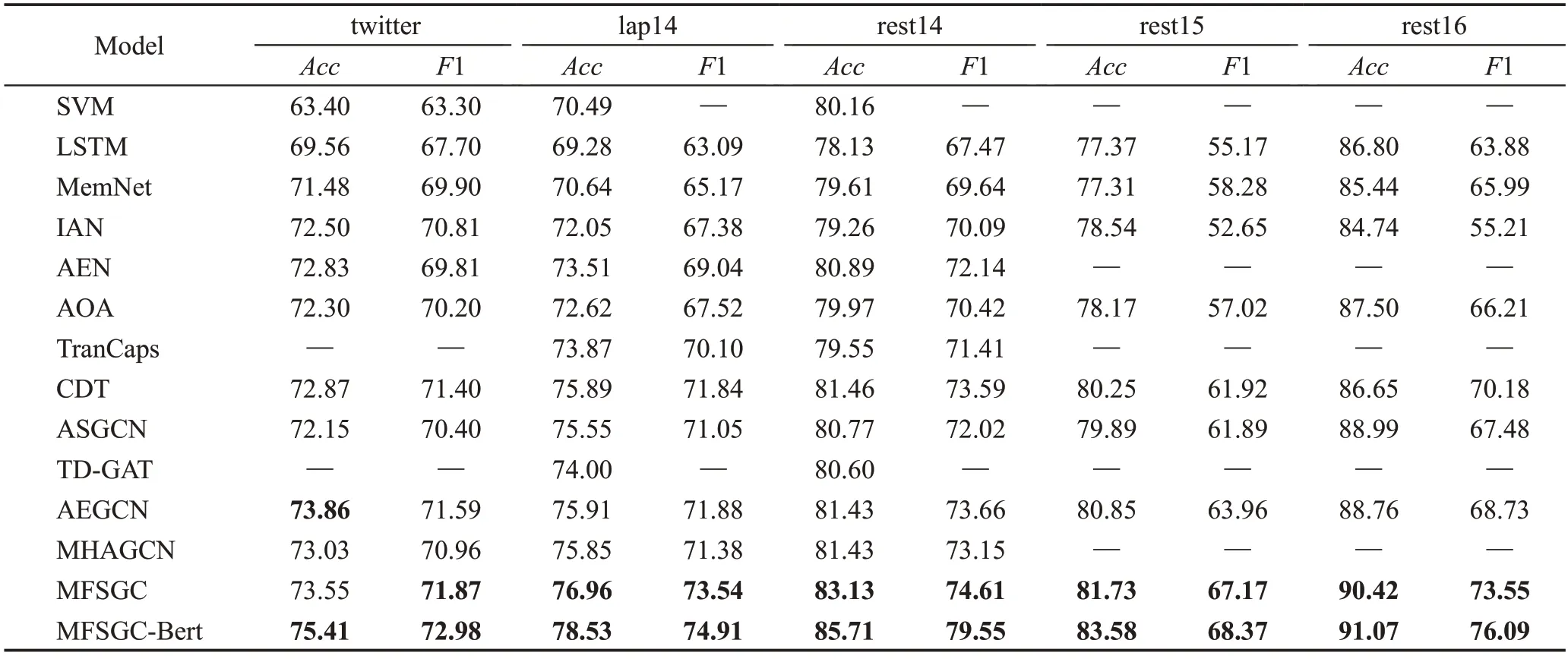
表5 实验对比结果Table 5 Experimental comparison results 单位:%
2.6 消融实验
2.6.1 多融合邻接矩阵消融实验
本文设计移除了多融合邻接矩阵算法的模型(spacy-model)与应用了多融合邻接矩阵算法的模型(MF-model)对比,来验证多融合邻接矩阵算法对分类的影响。在对比实验中增加只修剪了句法依赖树的模型(pos-model)和应用情感词典与spacy 句法融合的模型(sn-model),来分别验证这两部分对分类的影响。结果如图4、图5 所示,可以明显看出,修剪后的句法依赖树和增强情感特征都有益于模型进行情感分析,多融合邻接矩阵算法在5个数据集上的分类准确率也都有明显的提高,并且rest15数据集上的F1有大幅提高,证明经过多融合邻接矩阵算法得到的邻接矩阵可以改善模型性能。

图4 多融合对Acc 的影响Fig.4 Effect of multi-fusion on Acc
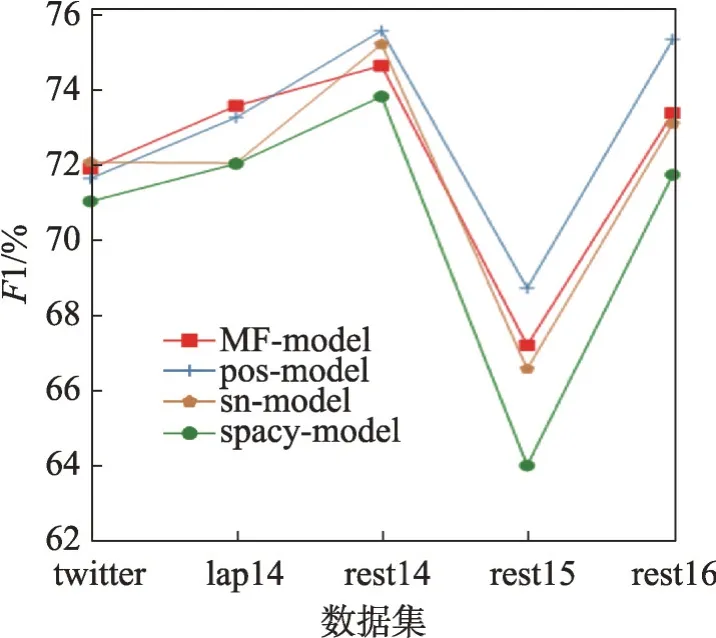
图5 多融合对F1 的影响Fig.5 Effect of multi-fusion on F1
2.6.2 不同无效词性组合分析
本文中,5个数据集的无效词性组合如表6所示,人们评价的角度随事物的不同而改变,在不同的背景中,一些本身并没有感情色彩的词放在特定的语境中可能会表现出情感倾向。在Twitter 平台,WRB词性大多数为how,包含情感信息,例如“Interesting!How to present like steve jobs”。但在餐厅和笔记本领域内,WRB 词性大多数为when,例如“when we sat,we got great and fast service.”,很明显,“when”对判断方面词“service”的情感极性不起作用。

表6 各个数据集的无效词性组合Table 6 Invalid pos combination of each dataset
为更好地突出词性的作用,使用上文中的posmodel 来对比不同的无效词性在5 个数据集上的效果,在5 个数据集上的Acc如图6 所示。从图中可以明显看出,模型只有利用数据集对应的无效词性组合时才能达到最优性能,由于去掉了词性对应文本的句法依赖关系,而其中存在与预测方面词极性相关的情感信息,不匹配的组合对模型性能产生了反效果。
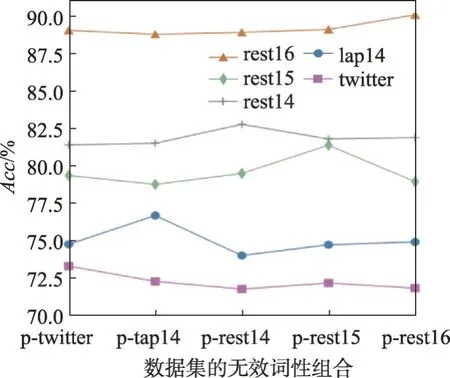
图6 不同无效词性组合的对比Fig.6 Comparison of different invalid pos combinations
2.6.3 SGC-model与GCN-model对比
为验证简化图卷积网络相对于传统GCN对于模型性能的改善,设计对比实验,应用简化图卷积的模型(SGC-model)和应用传统GCN 的模型(GCNmodel),其他层和参数与表5实验一致。从图7、图8中可以看出,相较于传统GCN,SGC取得了更高的准确率,并且在rest15和rest16数据集上F1有大幅提高。从表7 中可以看出,在twitter 数据集上,SGC 的训练时间为GCN 的1/2,参数的减少降低了过拟合的情况,并减少了内存的使用,而这可能是性能提升的原因。
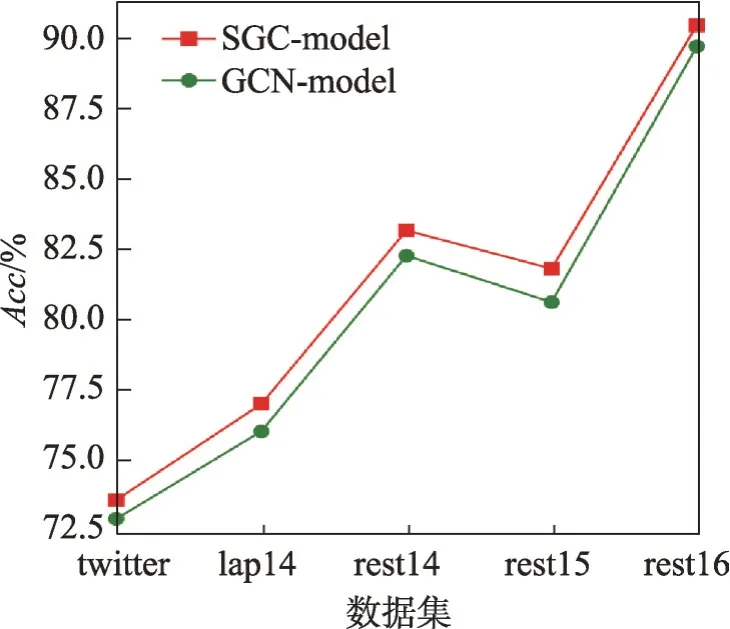
图7 SGC-model与GCN-model的Acc 对比Fig.7 Acc comparison of SGC-model and GCN-model
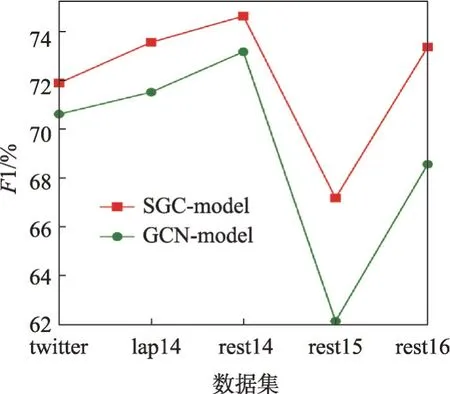
图8 SGC-model与GCN-model的F1 对比Fig.8 F1 comparison of SGC-model and GCN-model
2.6.4 SGC层数分析
为验证SGC 层数对模型性能的影响,其他参数保持不变,将SGC层的数量从1增加到10。5个数据集上的Acc如图9所示。从图中可以明显看出,SGC层数为2 时,模型达到最佳性能,之后随着网络深度的增加,性能逐渐降低。由于层数增加,模型的训练变得困难并且更容易发生过拟合。
2.7 实例分析
为更直观地表述本文模型的分类效果,取测试集中的实例来进行注意力可视化分析,如图10所示,其中,颜色的深度表示一个单词在句子中的重要性,颜色越深越重要。实例1“great food but the service was dreadful!”中有两个方面词,分别为“food”和“service”,对于“food”而言,模型指向“great”判断其极性为积极,而对于“service”,模型则指向“dreadful”判断其极性为消极,与真实极性一致。实例2“the food really isn’t very good and the service is terrible.”中方面词为“food”和“service”,模型判断其极性分别为消极和消极,与真实极性一致。从图中可以看出,当文本中有多个方面词时,模型可以正确指向对应的意见词并给其相应的注意力权重,从而识别方面词的情感极性。
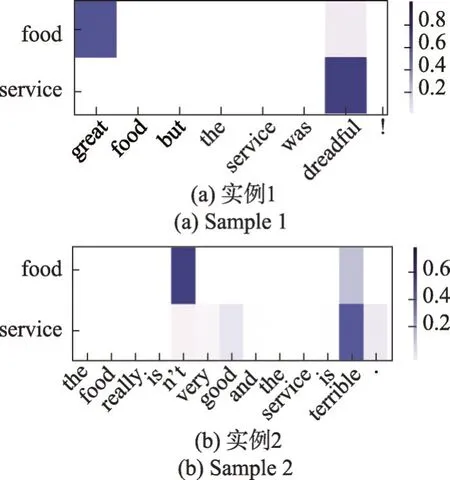
图10 实例分析Fig.10 Sample analysis
3 结束语
为充分利用句法信息和减少图卷积网络的复杂度,本文将外部知识和词性与原始句法依赖树融合,并使用简化图卷积网络,提出了一种基于多融合邻接矩阵的方面级情感分析模型。去除无效词性文本,减少了句法依赖树的冗余信息,使模型更关注于方面词与意见词,在句法分析时加入外部知识,增强了情感词的单词依赖性,并加强了方面词与情感词间的联系。实验验证了本文提出的基于多融合邻接矩阵算法的模型可以充分利用上下文和方面词间的句法信息,简化图卷积网络也明显提高了分类的性能。
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13 11:41:32
中华诗词(2021年3期)2021-12-31 08:07:22
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
大连民族大学学报(2021年2期)2021-07-16 05:41:42
电子制作(2019年11期)2019-07-04 00:34:38
中华诗词(2018年3期)2018-08-01 06:40:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中华诗词(2018年11期)2018-03-26 06:41:32
网络空间安全(2016年3期)2016-06-15 20:27:07
读写算·教研版(2015年13期)2015-07-28 07:13:11
