
基于深度学习的多文档机器阅读理解综述
2023-10-25 02:20倪建成周子力李艳艳
中文信息学报 2023年8期
高 峰,倪建成,高 鹏,周子力,李艳艳
(1. 曲阜师范大学 网络空间安全学院,山东 曲阜 273165;2. 华东师范大学 计算机科学与技术学院,上海 200062;3. 曲阜师范大学 网络信息中心,山东 曲阜 273165)
1 多文档机器阅读理解的发展与任务定义
机器阅读理解(Machine Reading Comprehension,MRC)一直以来是人工智能领域中一项具有挑战性的研究任务,是检验机器是否具有人工智慧的一项重要参考[1]。作为具有较长研究历史的任务,按研究方法区分,机器阅读理解经历了三个较为清晰的阶段: 早期系统时代(1970—2012)、传统机器学习时代(2013—2015)、深度学习时代(2015— )[2]。得益于深度学习理论和框架的成熟,机器阅读理解任务目前正处于繁荣发展的阶段,从传统的单文档阅读理解任务逐渐转向对阅读理解能力、推理能力和概括能力要求更高的多文档机器阅读理解任务,形成了以数据驱动方法创新的局面。
1.1 单文档机器阅读理解
单文档机器阅读理解(Single-Document Machine Reading Comprehension)是阅读理解的最初任务形式,在深度学习时代其可被形式化为一个有监督的学习问题: 对于给定的问题q、文本段落d,要求模型f输出预测答案a,如式(1)所示。
f:q,d→a
(1)
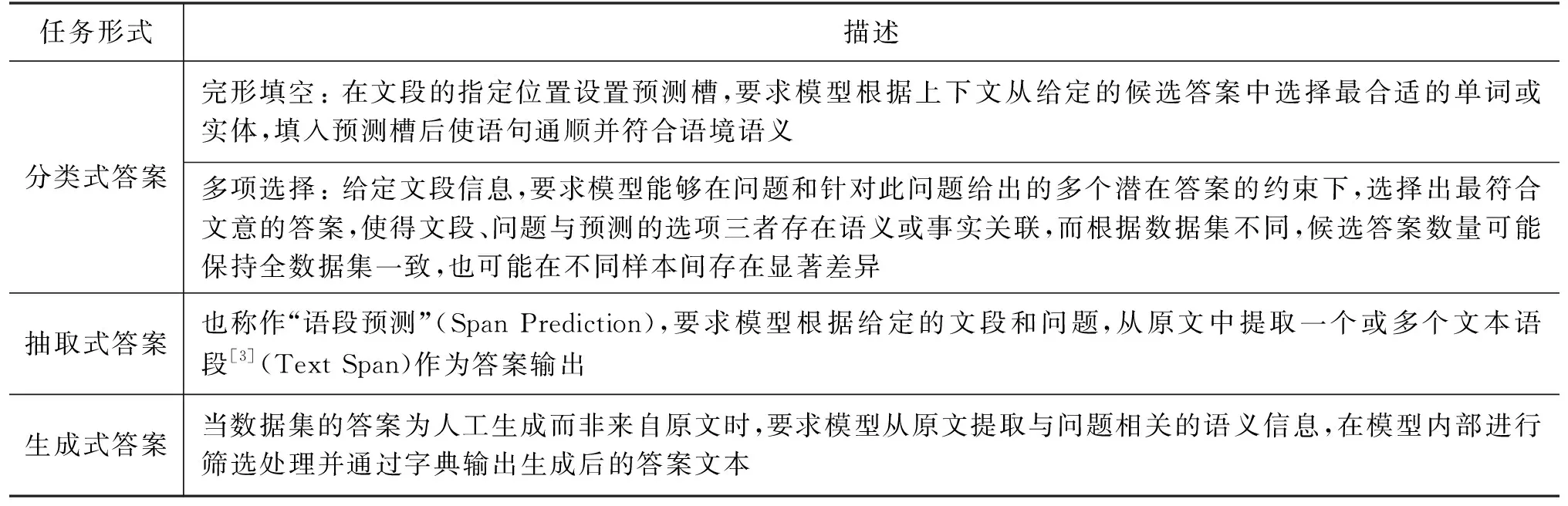
表1 单文档机器阅读理解任务形式描述
1.2 多文档机器阅读理解
多文档机器阅读理解(Multi-Document Machine Reading Comprehension)是在单文档的基础上,将给定的文档数量从单个扩增为多个,并进一步关注问题与多个文档间的内部逻辑关系。因此,多文档机器阅读理解任务对模型的理解、推理和概括能力要求更高,引领了利用机器理解人类复杂语言逻辑关系的研究浪潮。在式(1)的基础上,多文档机器阅读理解任务的形式化如下: 对于给定问题q、多个文档集合D,要求预测器f能够输出预测答案a,如式(2)所示。
f:q,D→a
(2)
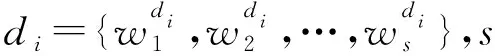
1.3 多文档与单文档机器阅读理解的联系与区别
随着大规模预训练语言模型的出现,在多个单文档机器阅读理解数据集任务上,人类的作答结果已逐渐被机器模型超越[4]。如何以贴近人类思维的方式完成更复杂的机器阅读理解任务,成为了阅读领域的研究热点,其中推理能力成为了研究主流方向之一,如SQuAD 2.0[5]数据集在SQuAD 1.1[6]的基础上,要求模型不仅能正确地作答问题,还要求模型在无法根据给定文档作出问题的正确答案时,主动停止预测,以判断模型是否对问题和文档有足够的理解能力,而不是强行作答。
多文档机器阅读理解可以视作单文档阅读理解的升级任务,其内部存在紧密的联系。首先,两者作为自然语言处理领域中的文本理解类任务,前序处理流程相似,如利用文本嵌入将自然语言映射至向量空间中,或通过编码层将线性文本信息转化为序列编码等;其次,两者可共享阅读理解任务的形式与评价指标,即使多文档阅读更注重文档间的关系理解和逻辑推理,然而在具体的任务形式上,虽然两者仍可保持一致,如中文单文档阅读数据集C3[7]与英文多文档阅读数据集WikiHop[8],两者给定的阅读文档数量不同,但问题和答案的形式均是多项选择问答。
多文档阅读理解与单文档阅读理解的区别主要表现在以下三个方面:
信息源多元化与单文档阅读理解仅有单个文档不同,多文档阅读理解需要协调处理来自多个文档的信息。由于不同数据集的创建方式和任务定义不同,同一样本下的多个文档可能存在不同的语义关系,如文档间存在观点矛盾[9-10],或需在多个文档中进行线性推理[8],甚至文档集合内存在噪声文档干扰正常的阅读推理[11]等,这些现象都增加了模型阅读理解的难度,需要进行适应化处理。
对推理能力与可解释性要求的提升由于多文档的阅读过程更贴近人类阅读时复杂的信息选择过程,研究者们大多通过多种启发式方法为模型赋予推理能力,以提升任务表现与鲁棒性。如在阅读过程中引入事理、知识图谱等外部知识,将信息转换为模型内部的判断机理,可以进一步提升推理过程的感知和分析能力[12]。而阅读过程的可解释性,则需要分析模型的预测过程是否符合人类思维认知的模式,进而探讨在不同数据集或应用场景下模型的泛化可能。
对时空伸缩性的要求无文档数量上限的多文档阅读理解任务,有时会导致答案搜索空间的爆炸,这就要求算法模型在作答时具有协调时空消耗的能力: 即使文档规模增大,但在回答问题时仍需要保持相对稳定的响应时间,同时也要有策略地选择文档集合并将其调入模型,以控制阅读时机器的算力和存储开销,保证问答系统运行的稳定。
总之,多文档机器阅读理解脱胎于单文档机器阅读理解,但提出了更复杂的逻辑推理要求,其形式也更接近人类阅读的真实过程[13],这决定了其在具有较高研究难度的同时,拥有广阔的商业应用前景。
2 多文档机器阅读理解数据集与评价指标
2.1 多文档机器阅读理解数据集
在深度学习领域,高质量的海量数据集将直接助益模型达到更好的效果[13],进一步推动研究的发展。我们选取了8个有代表意义的多文档阅读理解数据集,从数据集创建的驱动原因、语料来源、生成方式、任务特点和应用意义等角度对它们进行了总结,并在表2中详细展示各项指标参数,以期从数据集的角度呈现多文档机器阅读理解的发展趋势。

表2 多文档阅读理解数据库(2016—2020年)横向比较
2.1.1 MS MARCO
2016年,Nguyen等人[10]认识到当时的阅读理解数据集严重依赖于文档中显式的信息,缺少对内容的深入理解,因此基于微软必应搜索引擎的用户搜索记录和网页文档,构建了能反映真实世界中人类问题需求的多文档机器阅读理解数据集——MS MARCO。每样本包含6个字段: ①用户在搜索时预期可通过搜索引擎直接获得答案的问题; ②10个来自必应搜索引擎并经过人工确认与问题相关的独立文档; ③由人工从文档中直接抽取的答案; ④由人工根据文档重新编写的答案,并要求此答案比③更符合自然语言的语法与逻辑,且保证与原文档的内容具有一定区分度; ⑤文档的原文链接、原文标题、原主体文本等未经加工的源信息; ⑥对问题的分类标签,如“数字型”“实体型”“地点型”、“人物型”或“描述型”等。MS MARCO数据集是一项里程碑式的工作,它较早地认识到利用搜索引擎日志,从用户的主观意图和海量网络文档入手,产出可反馈人类社会真实需求的多文档阅读理解数据集。
2.1.2 TriviaQA
2017年,Joshi等人[14]提出,如果直接将智力问答竞赛中涉及多个知识领域的赛题作为阅读理解任务的问题,不仅可以避免需要人工针对文档重新编造问题的繁琐过程,还能减少因问题文本语言风格或问题与文档信息相关性过强而导致的数据偏置问题。他们基于约9.5万个智力问答“问题-答案”对,将维基百科与网络文档作为语料库,创建了面向智力问答的多文档阅读理解数据集——TriviaQA。平均每个样本有6个相关文档用于答案的预测。
与其他数据集相比,TriviaQA有3个特点: (1)不仅涵盖了多个领域的智力挑战问题,而且真实地迁移了人类社会在“问答”方面的兴趣爱好到机器世界中;(2) 通过对随机采样样本进行定性分析,发现分别在维基百科抽取到和从网络文档筛选的两种文档集合中,能够涵盖正确回答问题的比例分别为79.7%和75.4%,同时,与SQuAD相比,超过三倍以上的问题需要通过对多个句子的推理才能得出答案,证明了其有效性和全面性;(3) TriviaQA不仅可用于信息检索式阅读理解,而且为构建基于结构化知识的问答系统提供了可用素材,为文本结合外部知识的阅读问答方法研究奠定了语料基础。
2.1.3 DuReader
2018年,为了增添阅读理解数据集语言的多样性,He等人[9]利用百度搜索引擎日志和大型互助问答社区“百度知道”,建立了中文的多文档阅读理解问答数据集——DuReader,创新性地引入了针对答案是否为“主观观点/客观事实”和“实体性/描述性/是否命题”的两种分类标准,利用人工汇总多个网络文档和百度知道社区回答,生成针对问题的人工准确答案。DuReader数据集包含了约20万个问题,42万个答案和100万个文档,是发布时最大的中文阅读理解数据集。
2.1.4 WikiHop
2018年,Welbl等人[8]认为当时的多文档阅读理解数据集中缺少对文档间逻辑推理的要求,因此他们基于Wikidata(1)https://www.wikidata.org的关系三元组和维基百科,利用有向二部图,构建了文档间存在线性逻辑关系的开放域多文档阅读理解数据集QAngaroo WikiHop。首先将先验知识三元组(Subject Entity,Relation,Object Entity),转化为问答的形式: Question=(Subject Entity,Relation,?),Answer=(Object Entity);然后构建如图1所示的有向二部图,左侧为实体节点,右侧为文档节点,当文档中包含某个实体时则从文档连接至实体;最后利用广度优先搜索(Breadth-First Search)算法构建从Subject Entity到Object Entity的搜索路径,收集路径中命中的文档与相关的实体并保存为一个样本,其中与答案实体类型一致的其他实体将被保存为问题的干扰候选项。特别地,若在收集的单个样本中,存在多个同时成立的先验知识,即在答案实体和干扰项中同时满足先验知识(s,r,o)与先验知识(s,r,o′),则舍弃候选项o′,以保证在同一问题下存在唯一的答案o。图1中有底色的项目表示在搜索时命中的文档和实体,对号表示为正确答案,叉号表示为候选项中的干扰答案。为了验证数据集的有效性,Welbl等人对开发集与测试集中的每条数据邀请了3名志愿者,进行问题与文档间逻辑关系的验证,结果显示有约74%的数据遵循或可能遵循“回答问题需要在多个文档间进行逻辑推理”的假设。
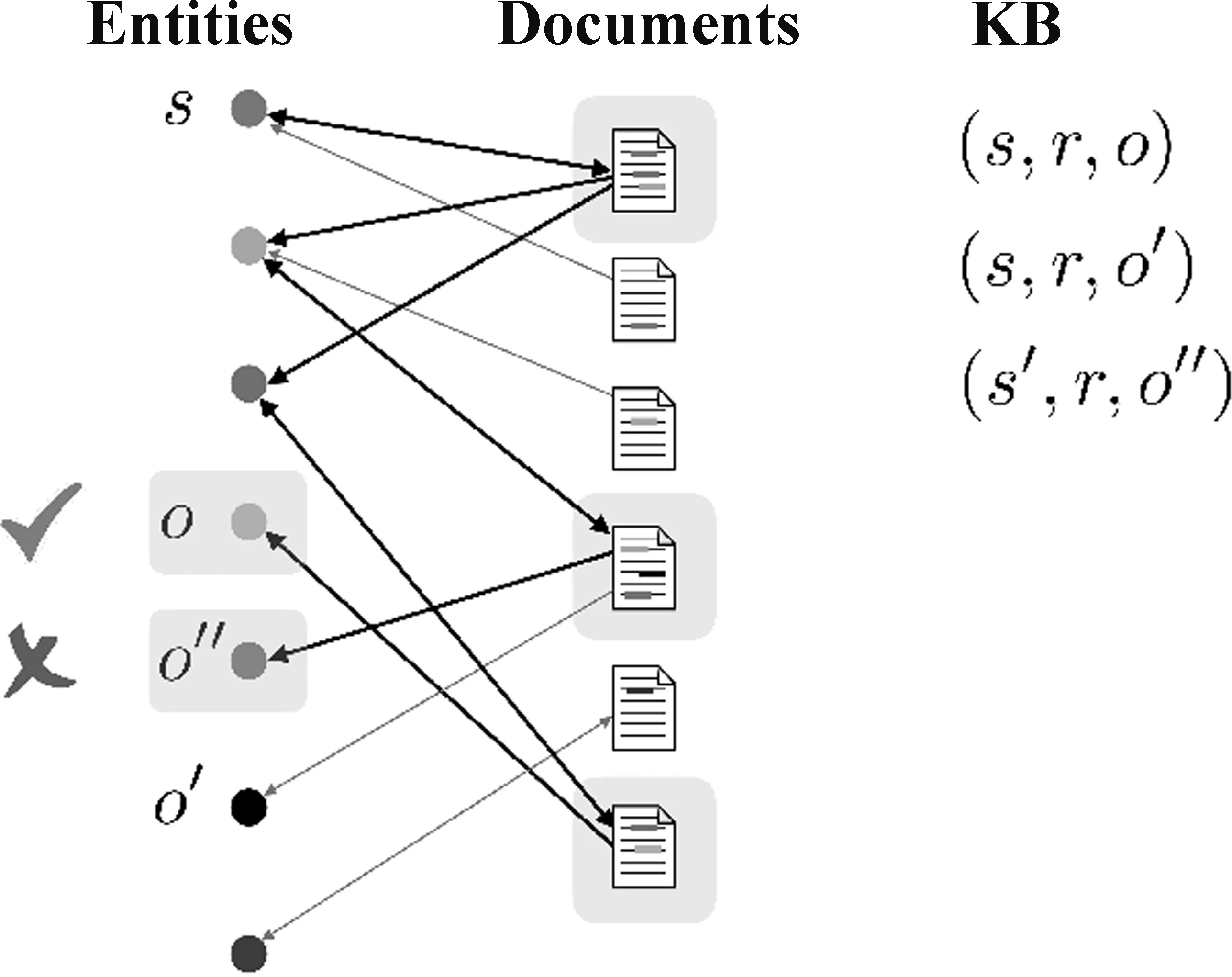
图1 WikiHop数据集创建示意图引用自原论文
2.1.5 MedHop
近年来,分子生物学(Molecular Biology)的出版物数量呈指数级增长[15],而且其相关的数据分析经历了严格生物化学实验验证,具有较强的科学性和客观性。在此背景下Welbl等人[8]以DrugBank[16-17]为结构化知识、Medline药物文献摘要为语料库,复用WikiHop的创建方式,提出了面向封闭域的QAngaroo MedHop[8]数据集,目的在于利用记录了药物生化性质的文献摘要,通过机器阅读理解的形式进行药物间反应(Drug-Drug Interactions,DDIs)预测。
药物反应预测涉及药物-蛋白质反应、蛋白质-蛋白质反应等多种生物化学过程,因此MedHop数据集具有一定的挑战性,其将多文档机器阅读任务的研究领域扩展到了分子生物学,使用完全基于自然语言理解的方式对DDIs进行预测。利用科学、严谨和定量分析的生物化学研究成果能促进自然语言领域的相关研究,而自然语言领域预测的结果又可以有针对性地指导生物化学的相关实验过程,提高实验效率,减少实验损耗,实现两研究领域的共同发展。
2.1.6 HotpotQA
2018年,Yang等人[4]指出多文档阅读理解任务中存在的一个关键缺陷,即当时的数据集不能在阅读理解过程中明确地提供文档间前进或后退的逻辑关系证据,进而导致在学习过程只关注如何预测答案,却忽视了分析预测过程的逻辑性。为此,Yang等人通过人工标记出在人类思维阅读、推理时使用的相关句子,以Wikipedia为语料库创建了带有摘选标记的多文档数据集——HotpotQA。HotpotQA有4个主要特征: (1) 问题需要在提供的多个文档中进行选择和推理才能回答;(2) 问题形式多样,且问题的生成未依赖于任何先验知识;(3) 提供了语句级别的支持性逻辑链条,帮助模型学习人类的阅读推理过程,并提出了对模型的回答过程进行合理性验证的要求;(4) 新增了两实体间属性比较的问题种类,用于测评模型提取信息和比较信息的能力。
HotpotQA数据集具有112 779个样本,其中训练集、开发集和测试集包含的样本数量分别为90 564个、7 405个和7 405个。由于此数据集的设计理念先进,更贴合人类阅读理解习惯,在发布后迅速得到了大量研究者的关注和评测提交。
2.1.7 AmazonQA
2019年,Gupta等人[18]观察到每天有几千名的顾客在亚马逊购物网站的商品详情页面进行提问,而这些问题能在广泛地浏览来自其他用户的评论后得出答案。因此,Gupta等人从亚马逊网站15.6万件商品中的1 400万位用户的评论文档中收集了92.3万个问题和360万个答案,开发了基于用户社区商品问答的多文档机器阅读理解数据集——AmazonQA。与其他数据集相比,该数据集着眼于电子商务领域的数据信息,完整地反映真实用户的问题需求,是发布时最大的描述性问答数据集。为了训练与检测模型对数据的理解能力,与SQuAD 2.0类似,AmazonQA提供了是否可以通过文档回答问题的指示标记。
2.1.8 R4C
在实际应用中,类似于HotpotQA提供的支持性事实(Supporting Facts)是以句子形式出现的,而语句中仅有少部分内容是有效的驱动信息,大部分为冗余信息。为了使推理过程更准确、清晰,Inoue等人[19]于2020年提出了半结构化、具有更细粒度的派生事实(Derivation)驱动的多文档推理数据集——R4C。从文档中抽取的派生事实d的形式化如式(3)所示。
d≡
(3)
其中,dh与dt是名词性短语实体,dr是动词性短语,用于表示dh和dt的逻辑关系。式(3)半结构化逻辑表示结构,可以为模型提供更清晰明确的逻辑跳转事实,细化、充实了推理链路的完整性、可靠性和合理性。
由于派生事实粒度较细且提取困难,R4C数据集的规模小于HotpotQA,其包含约4 600个样本,每个样本均包含3条人工提取的优质派生事实。尽管数据集规模较小,但这种小粒度的推理链条,模拟了人类阅读中细粒度可解释理解的过程,是多文档阅读理解任务中研究的新趋势,有助于模型在细节推理方向的创新。
2.2 多文档机器阅读理解评价指标
2.2.1 准确率
对于分类式阅读理解任务,一般采用准确率(Accuracy)评价模型的预测结果[6,20-22],准确率是预测结果正确的样本数占样本总数的比值。
2.2.2 联合F1和EM
对于逻辑链路预测要求的多文档阅读理解任务,一般需要采用联合F1(JointF1)指标以评价模型在预测过程中生成链路的质量[11,19]。计算时,以词语为粒度分别计算正确答案、正确推理链路与预测答案、预测推理链路之间的答案查准率Pans、推理链路查准率Psup、答案查全率Rans、推理链路查全率Rsup,并分别将答案与推理链路的查准率和查全率作积得到联合查准率与联合查全率。联合查准率Pjoint、联合查全率Rjoint和联合F1的定义如式(4)~式(6)所示。
EM精确匹配(Exact Match) 是一项较为严格的评价指标,对于模型给出的候选答案词组、句子,只有在候选答案与参考答案完全相同时才可视为匹配成功。若数据集中共有N个问题,模型给出M个匹配成功的候选答案,其EM得分计算如式(7)所示。
(7)
2.2.3 BLEU
对于生成式阅读理解任务,可使用BLEU(Bilingual Evaluation Understudy)[23]进行答案质量评价。该指标最初被应用在机器翻译任务中,评价生成译文相对于标准译文的质量,如式(8)~式(10)所示。
(8)

(9)
(10)
其中,N-gram表示采用N元精度(N-gram precision),一般选用四元精度(4-gram Precision)进行句子级别的评价;BP(Brevity Penalty)为简洁惩罚因子,以惩罚候选语句在低召回率下语句过短的情况。
2.2.4 ROUGE
对于生成式阅读理解任务,还可使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[24]进行答案质量评价。该指标起初主要用于评价自动摘要生成任务的生成语句[25],与BLEU不同的是其可从查全率的角度对候选语句与参考语句进行评价。在生成式机器阅读理解任务的实际应用中,最常用的指标是ROUGE-L,假定对于某模型有长度为m的参考序列文本答案X和长度为n的候选序列文本答案Y,ROUGE-L得分Flcs计算过程如式(11)~式(13)所示。
其中,LCS(X,Y)为X与Y的最长公共子序列长度;Rlcs为查全率;Plcs为查准率;β为平衡因子,在机器阅读理解任务中一般可取值为1.2;而当β足够大时,得分Flcs=Rlcs,即指标关注查全率。
3 多文档机器阅读理解模型
基于深度学习的多文档机器阅读理解模型,可按照模型的线性处理顺序,抽象为如图2所示的自底向上的模型层次图,包含映射自然语言至向量空间的嵌入层、捕捉线性文本序列特征的编码层、理解文本与实体间语义关系的阅读理解层和适应任务特性的答案输出层。通过研究模型在各层,尤其是阅读理解层的技术方法,实现研究者的设计思路以适应数据集任务的特点,是提升模型在多文档阅读理解任务中表现的重要手段。
3.1 嵌入层
嵌入层(Embedding Layer)负责将问题、文档和答案等文字信息投射到高维稠密的向量空间中,实现文本信息的数字化与向量化表示。依据嵌入过程中的粒度级别、语境依赖和词性等特征,嵌入方法可以分为字级嵌入、词级嵌入、语境嵌入和特征嵌入等方法。在应用中可组合多种嵌入方法以提高模型效果。
3.1.1 字级嵌入方法
如图3所示,字级嵌入(Character Embedding)通常是以字母为单位并结合诸如卷积神经网络(Convolutional Neural Networks)[26]等深度学习框架的文本嵌入方法。此方法可用来解决噪声字符(Noisy Character)、未登录词(Out-of-Vocabulary)和生僻词(Rare Word)等问题[27-33],在Tu等人[34]提出的多文档阅读模型HDE中,将N-gram字级嵌入[29]作为文本特征的一部分,以缓解因粗粒度嵌入方法导致的信息表示不足的问题。
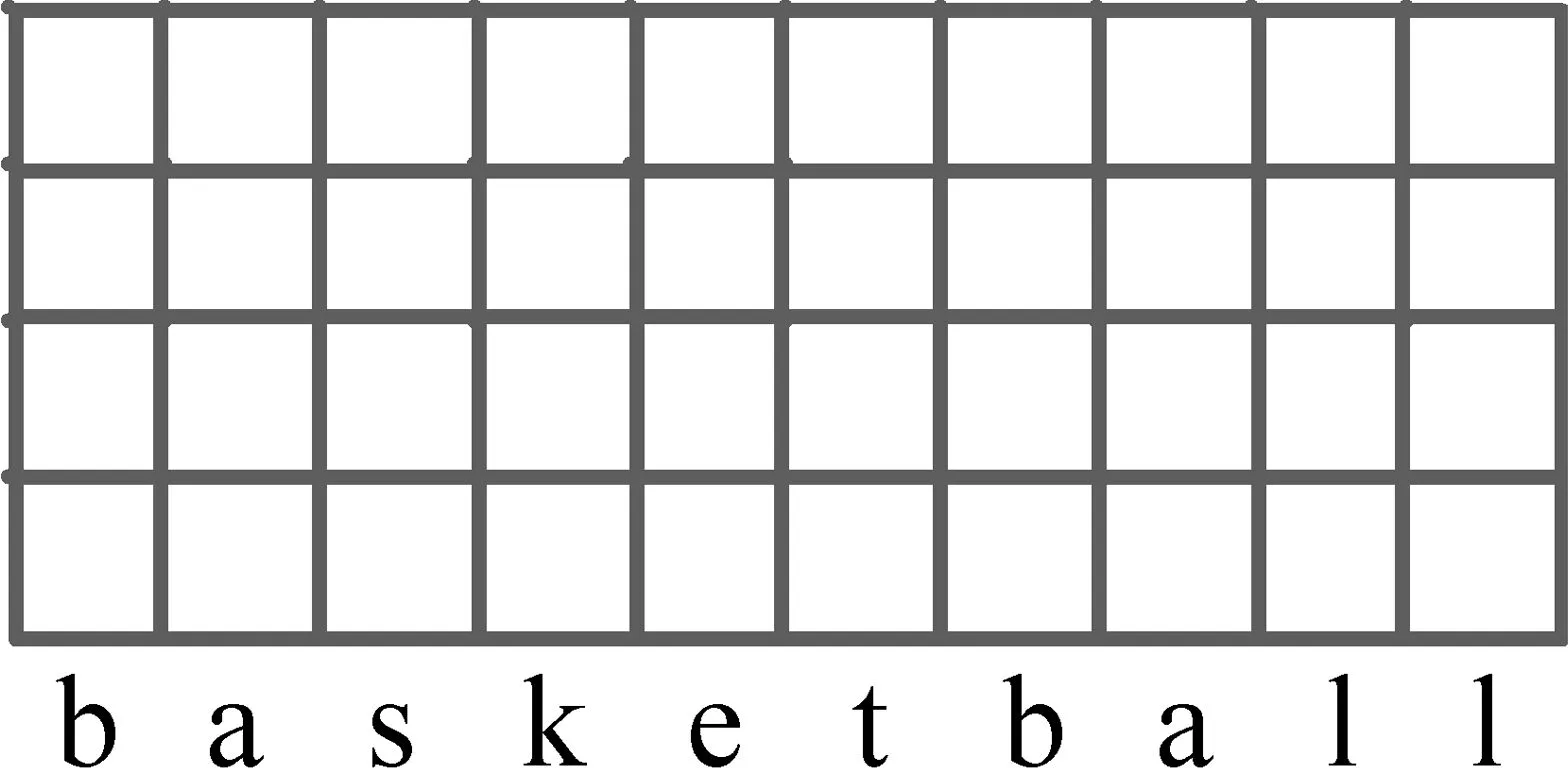
图3 字级嵌入示意图
3.1.2 词级嵌入方法
如图4所示,词级嵌入(Word Embedding)是将文本以单词为单位,基于单词分布式假设进行的实值向量化表示。2013年,Mikolov等人[35-36]提出了基于连续词袋模型和连续跳跃元语法模型,用于单词相似性检验的词向量嵌入模型Word2Vec,实现了对词语关系的建模。2014年,为了更好地利用大规模语料库的语言共现(Co-occurrence)统计特性, Pennington等人[37]基于全局对数双线性回归方法提出了GloVe模型,结合了局部上下文窗口和全局矩阵分解两种方法的优点,并在多个多文档阅读理解模型的应用中提高了答案预测的准确率[34,38-39]。
图4 词级嵌入示意图
3.1.3 语境嵌入方法
虽然在词级嵌入方法中固定的实值嵌入方法取得了很大的成功,但是研究者发现如图5所示结合了上下文的语境嵌入方法展现出更强大的语言表示能力。此类方法一方面可以区分一词多义,另一方面还可以通过利用预训练深度网络模型中的高低阶层来表示语境中蕴含的单词含义和句法结构信息[40]。2018年,Peters等人[40]基于双向LSTM提出了一种利用长短时记忆网络(Long Short-term Memory,LSTM)基于特征(Feature-Based)的语言模型ELMo。该模型利用单词的上下文对文字进行特定语境的双向嵌入表示,有效提升了其应用到自然语言处理的其他下游任务的表现。2019年,Devlin等人[4]在双向Transformer的基础上提出了利用预训练+精调(Fine-Tuned)策略的双向特征表示语言理解模型BERT,在单文档阅读理解任务SquAD 1.1上超越了人类的作答结果。2020年,针对“预训练+精调”的两段式语言嵌入框架需要大量领域标注数据,有悖于人类在少量样本上就可学习语言规律的问题,Brown等人[41]提出了基于小样本(Few-Shot)的自回归语言模型(Autoregressive Language Model) GPT-3。得益于该模型先进的设计理念,在多文档阅读理解数据集TriviaQA[14]上,超越了当时效果最好的“预训练+精调”式模型RAG[42]的预测结果。

图5 语境嵌入示意图
3.1.4 特征嵌入方法
如图6所示,特征嵌入(Feature Embedding)可以将诸如命名实体识别(Named-Entity Recognition,NER)、词性标注(Part-of-Speech,POS)、位置特征(Position)等文本低维度特征与其他特征嵌入进行拼接,进而提升模型的阅读理解能力。Cao等人[39]在BAG模型中,将文本的NER、POS特征和语义嵌入拼接形成联合嵌入后,提升了多文档阅读理解任务的答案预测准确率。
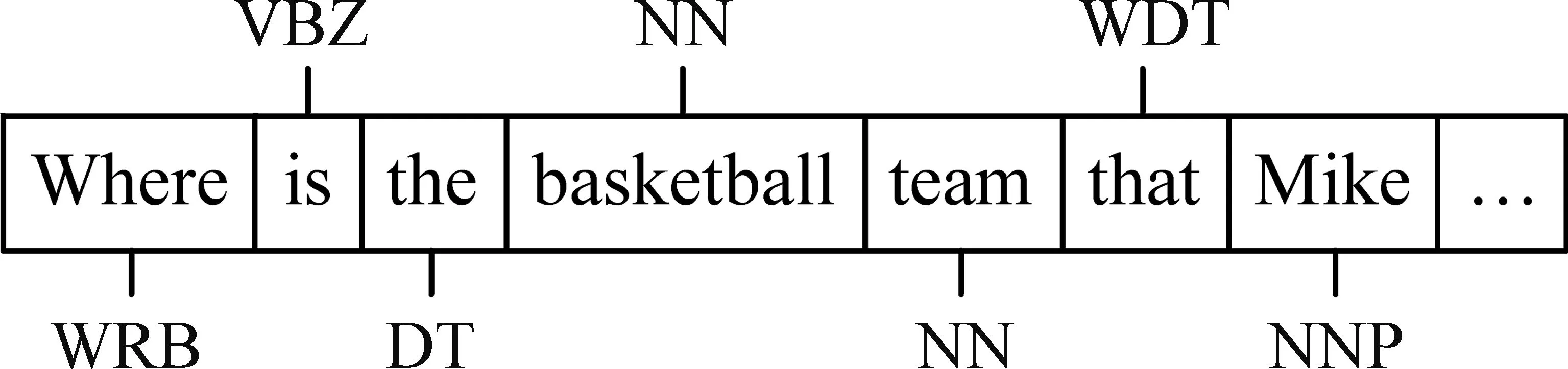
图6 特征嵌入示意图
3.2 编码层
在多文档阅读理解模型中,编码层(Encoder Layer)主要对线性文本序列的上下文语境进行编码,是模型中通用的基础部分。多文档机器阅读理解模型中常用的编码层结构有循环神经网络(Recurrent Neural Networks,RNN)及其变种和Transformer及其变种。
3.2.1 循环神经网络
如图7所示,RNN[43]及其变种LSTM[44]、GRU[45]可以通过时间步的前进方向顺序地处理文本。由于此类网络模型包含学习单元和参数共享机制,使其在应用中具有记忆功能。在实际应用中,除了有从前向后的时间步顺序,还可以结合从后向前的反向时间步顺序,拼接生成双向的(Bidirectional)特征表示[31,46-50],从而更好地学习文本特征。
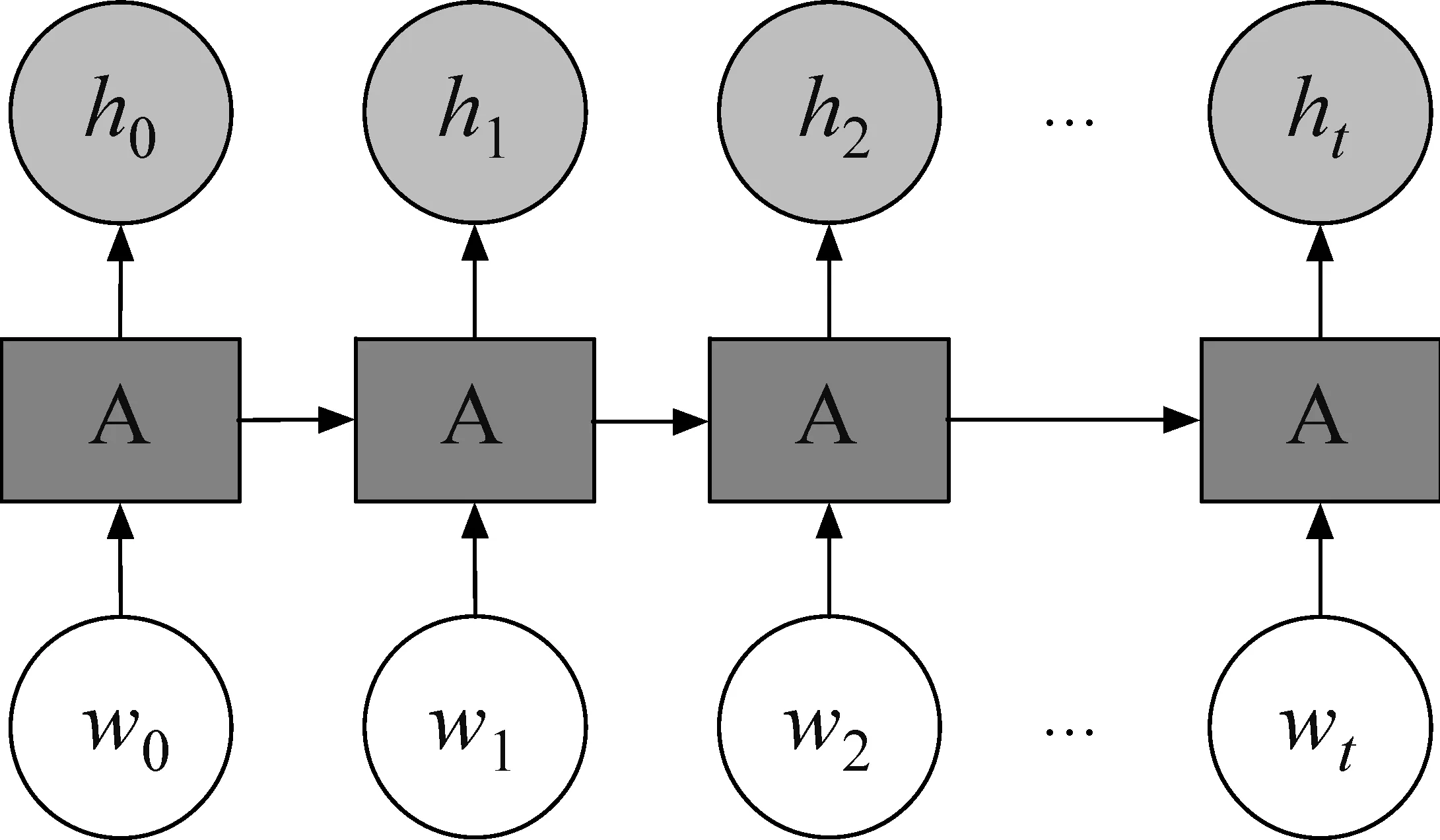
图7 循环神经网络时间序列展开图
3.2.2 Transformer
虽然RNN模型展现出了强大的时序信息编码能力,但是其所依赖的时序学习模式不仅计算效率较低,还会导致长序列文本的前文信息出现丢失。2017年,Vaswani等人[51]提出了不依赖时间步的完全基于自注意力机制的Transformer模型。如图8所示,该模型可通过并行计算模式提高计算效率,有效地解决了RNN模型中信息丢失的问题。
图8 基于自注意力机制的Transformer编码示意图
Transformer模型在编码和解码过程中,把分别由源输入序列和目标输出序列充当的线性文本序列划分为3个角色: 查询Q(Query)、键K(Key)、值V(Value),并通过计算序列间的缩放点积注意力(Scaled Dot-product Attention)进行特征学习,如式(14)所示。
(14)
3.3 阅读理解层
阅读理解层是整个模型中最灵活的自定义处理层之一,也是研究者们集思广益后提出的针对不同多文档阅读理解任务特点而进行特定处理的模块。根据模型的侧重点,阅读理解层包含4种主流研究方法: “多文档-问题”选择式、Transformer精调式、图卷积神经网络式和外部知识融合式。
3.3.1 “多文档-问题”选择式阅读方法
鉴于多文档阅读理解任务需要对多个文档进行阅读和答案预测,研究者们提出了根据多个文档与问题的关联性和重要性,有侧重地进行文档选择的方法。2018年,Clark等人[32]认为在多个文档中预测答案,会被不相干的文档干扰,造成正确率下降,因此提出了利用TF-IDF算法先选择与问题相关的文档子集,后将子集内各文档预测的答案语段进行全局共享的归一化操作,避免了不同文档间各答案的特征差异而导致的输出偏置,迫使模型可以产出在不同文档间具有可比性的候选答案集合。
2018年,Wang等人[46]提出的跨文档验证式阅读理解模型将多个文档拼接为一个超长序列,根据负采样对数概率在各文档的子序列部分各抽取一个候选答案语段An(n为文档及答案的序号),并在每个序列分词上设置是否与候选答案重叠的标记(与答案重合的分词标记为1,其他位置标记为0),以保证抽取到的答案语段相对于该文档的预测质量。最后利用Softmax函数对来自n个文档的候选答案语段联合表示rAn进行答案与多个段落的相关性验证,并输出最终预测的答案。
然而,将多个文档进行简单的拼接会因文档数量的增加而导致阅读效率下降。为解决这个问题,Yan等人[47]提出了面向多文档阅读的深度级联模型,通过“文档-段落-答案”不断细化的阅读过程,平衡了答案预测的正确率和阅读效率。多个文档在阅读过程中经历了文档排序、段落排序、文档提取、段落提取和答案提取5个处理过程,用于过滤与问题不相关的文档与段落,逐渐缩小答案搜索空间,保证了推理过程的合理性,在不断细化的级联过程中实现对答案语段的预测。
不同于上述两种模型从文档与答案的角度进行预测,在Mao等人[55]从丰富问题语义度的角度提出的GAR模型,扩充了阅读理解中“问题”的语义信息,以提高答案检索时相关文档的数量与质量。Mao提出了三种扩展问题语句的方式: (1) 将原始问题语句直接送入预训练语言模型中(如GPT-3[41]或BART-large[58])以生成“伪答案”语句,这些生成语句可能直接包含正确答案;(2) 给定文档中包含“伪答案”的原文语句;(3)从维基百科中提取的,与原始问题语句相关且包含“伪答案”的语句。通过从文档中直接抽取答案和由模型接生成答案的两项实验,证明了以上三种扩增语句对提升答案预测准确率的有效性。
综上,“多文档-问题”选择式阅读方法是在单文档阅读理解任务的研究基础上,为满足多文档阅读理解任务要求而进行的必要扩展,为后续开展在多文档信息逻辑推理奠定了坚实基础。
3.3.2 Transformer精调式阅读方法
尽管Transformer模型具有较强的信息捕捉能力,然而考虑到模型复杂度,在应用中需要限制文本序列的长度。例如朴素Transformer模型支持的文本序列长度上限为512,极大制约了Transformer模型在多文档或长序列文本上的应用。为了降低Transformer模型的复杂度,Beltagy等人[57]提出了稀疏自注意力模型Longformer。该模型利用滑动窗口注意力、扩张滑动窗口注意力和全局滑动窗口注意力三种机制,将Transofrmer模型的复杂度从指数级降为线性级。同时,全局滑动窗口注意力机制的引入,能够获取问题文本的相对于整个文本序列的全局特征注意力,确保问题特征能被后续文本捕捉到。通过将多文档信息拼接为单个超长文本序列,Longformer模型在发表时取得了WikiHop和TriviaQA数据集上的最佳表现。
受图的稀疏化启发,Zaheer等人[54]提出了Big Bird模型,引入了随机注意力、窗口注意力和全局注意力三种机制,复杂度仅为线性级。在HotpotQA、TriviaQA和WikiHop数据集上的实验结果表明该模型具有较强的长文本特征捕捉能力。
总之,基于Transformer的精调式阅读方法是将多个文档拼接成单个文档,利用或改进单文档阅读理解的方法完成答案预测,性能主要受文本序列长度的影响,而基于图神经网络的多文档阅读理解方法则从特征提取的拓扑结构上实现创新。
3.3.3 图卷积神经网络式阅读方法
图卷积神经网络(Graph Convolutional Networks,GCNs)是一种有效表示真实世界中复杂关系的网络拓扑结构[59],可对应在多文档阅读理解中的实体逻辑关系。
2019年,Cao等人[60]认为当时的机器阅读理解方法主要应用于单个文档的信息检索,为了整合和推理来自多个文档的消息,提出了基于GCN的跨文档阅读理解模型——Entity-GCN。在阅读过程中将从文档中提取出的候选答案实体固化为图中的提及节点(Mention Nodes),利用“同段”(连接来自同一文档段落的节点)、“同指”(连接同一候选答案的不同节点)和“共指”(利用指代消解连接同一实体的不同节点)的加边方式建立为图9的拓扑结构。图中虚线矩形框代表单个文档;节点是文档中与候选答案匹配的文本语段(Text Span);来自同一个文档的所有节点用实线连接,而不同文档的相同文字节点用虚线连接。使用多关系型GCN[61]更新节点特征,如式(15)所示。

图9 基于图卷积神经网络的多文档阅读方法建模图
(15)
其中,u为节点特征,l为GCN的迭代层数,Ni为节点i的邻居节点集合,R为图中存在的关系集合,fs和fr分别为学习自身节点特征和在某特定关系下邻居节点特征的线性学习矩阵。
2019年,为了更好地融合问题与节点特征,Cao等人[39]将单文档阅读理解方法中的双向注意力机制[28]引入到Entity-GCN的节点特征中,提出了BAG模型,实现了将双向注意力机制由序列文本到图结构的应用。问题与节点特征的相似度矩阵S的计算过程如式(16)所示。
S=avg-1fa(Concat(hn,fq,hn∘fq))
(16)
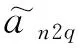
(17)
2020年,Tang等人[38]从补全多跳阅读理解实体推理链条的角度提出了Path-based GCN模型,其主要思想是除提取与候选答案一致的文本语段作为节点之外,还抽取了与节点有关的命名实体和名词性短语作为推理节点补充到阅读图。图9中方角矩形的推理实体连接了两答案节点,构建潜在的推理链路。此外,Tang等人还提出了问题感知的门控机制(Question-aware Gate),不同于BAG模型中问题节点特征的引入方式,问题感知门控作用于GCN的推理过程,可控制节点的特征更新。
与节点均为实体的同质图不同,Tu等人[34]为了表示多语义角度,将涉及的多个文档提取为与其他节点异质的文档节点挂载到图网络,最终提出了包含不同信息粒度的异质图神经网络HDE[34]。如图9的圆角矩形所示,将文档节点连接到其自身包含的实体节点,得到异质图网络。
受认知科学启发,Ding等人[62]提出的CogQA模型将多文档阅读分为两个过程: 隐式信息提取和显式逻辑推理,分别用BERT语言模型和图卷积神经网络GCN实现。在阅读时,迭代地使用BERT从文档中提取实体作为潜在的跳跃实体和答案实体,再利用GCN进行推理,直到节点穷尽或GCN达到一定规模。CogQA的实体提取过程如式(18)~(21)所示。
(18)
(19)
(20)
(21)
其中,Sans、Eans、Shop和Ehop为指针向量,分别用于计算文档中第i个分词成为答案节点和跳跃节点的概率,T表示分词的向量特征,Tj表示与第i个分词位于同一语句的其他分词的特征。提取到的节点在基于GCN的逻辑推理模块中依照拓扑结构进行特征更新。
3.3.4 融合外部知识的阅读方法
2019年,为了提升阅读过程的推理能力,Ye等人[63]提出了基于知识增强的图阅读模型KGNN。该模型从多个文档中提取节点,利用知识图谱(Knowledge Graph)中现存的实体关系连接已知的且有知识关系的节点,进而建立关系矩阵Er。同时,KGNN模型将共指的节点进行连接,利用如式(22)所示特定关系的信息传播方式完成推理过程。
(22)
其中,Nr(vi)表示在r关系下节点vi的邻居节点,αr是将问题和关系r匹配的注意力权重矩阵,利用φr(vj)=FFN(vj+Er)的方式将邻居节点和特定连接关系进行融合,这里FFN(·)为全联接的前向传播层。KGNN模型从建模实体间关系的角度出发,利用了知识图谱的先验知识指导节点的连接,对提升模型推理链合理性和表现起到助力作用。
除利用知识外部知识指导关系建模外,Yang等人[64]提出了一种从知识图谱提取知识嵌入到阅读图的模型KT-NET。对于文档和问题分词的全集W,该模型从知识库C中匹配相关的知识概念c∈C(w),并通过相似度矩阵α匹配w与c的语义关系,将与w相关的知识向量嵌入融合到BERT模型给出的语义向量中进行后续预测。KT-NET模型的优点在于不仅可以整合知识图谱与文档语义的知识信息,还可以从多个知识图谱全局的角度考虑补充文档中未显示给出的知识嵌入信息,协调了语言模型和先验知识的应用关系。
为了在图神经网络中利用知识三元组信息,Sun等人[65]提出了包含文档、实体和知识三元组的异质图网络模型PullNet。该模型通过迭代地从知识图谱中“拉取”三元组的方式,在文档和知识图谱中找到与问题相关的实体并补充到阅读图中,最终使图包含来自知识图谱中的实体节点集合Ve、表示单句话的文档节点集合Vd和包含知识三元组信息的事实节点集合Vf。令E表示图网络的边集合,图中存在两种边关系: (1)若Ve中的节点vs,vo包含于知识图谱三元组中,则分别连接vs,vo和对应的vf;(2)若实体节点ve在文本序列vd中被提及,则连接vd与ve。在建立阅读图后,基于节点分类的方式完成答案预测。PullNet是整合多文档文本信息和知识图谱知识的模型,其创新在于通过建立包含先验知识信息的异质推理图,进行融合先验知识的阅读理解过程。
为了充分理解问题语义,结合问题类型实现有针对性的答案预测,谭红叶等人[66]提出了一种基于外部知识和层级篇章表示的多文档阅读理解方法。该方法从利用外部知识加强对问题的理解程度出发,先定义了识别问题语句中重要词的多种规则,再引入了重要词在《现代汉语词典》(第六版)的字典释义和HowNet义原,使用特征嵌入拼接的方式,得到融合字典释义的问题特征表示。实验表明,《现代汉语词典》对重要词的覆盖率为88.1%,HowNet对重要词的覆盖率为92.7%,因此能较好地适应问题中复杂的语义关系,实现丰富问题语义知识表示的目的,进一步提高了模型通过问题特征捕捉原文信息进行阅读理解的能力。
3.4 输出层
输出层的主要目的是适应阅读理解层的输出与数据集的任务形式,生成模型的最终答案预测。根据阅读理解层的特点与多文档阅读理解的任务特性,常用的输出层有三种类型: 图节点分类式、长文本分类提取式和文本生成式。
3.4.1 图节点分类式
利用GCN对实体和文档进行关系建模的方法[34,38-39,60]在阅读理解层后连接多层感知机(Multilayer Perceptron,MLP)作为输出层,在正确答案与候选答案间使用交叉熵函数计算损失,进而优化模型参数。如图10所示,HDE模型[34]从GCN提取提及节点(Mention Nodes)和候选节点(Candidate Nodes)的特征,并将它们输入到两个独立的MLP计算每个类别的分布得分a,如式(23)所示。
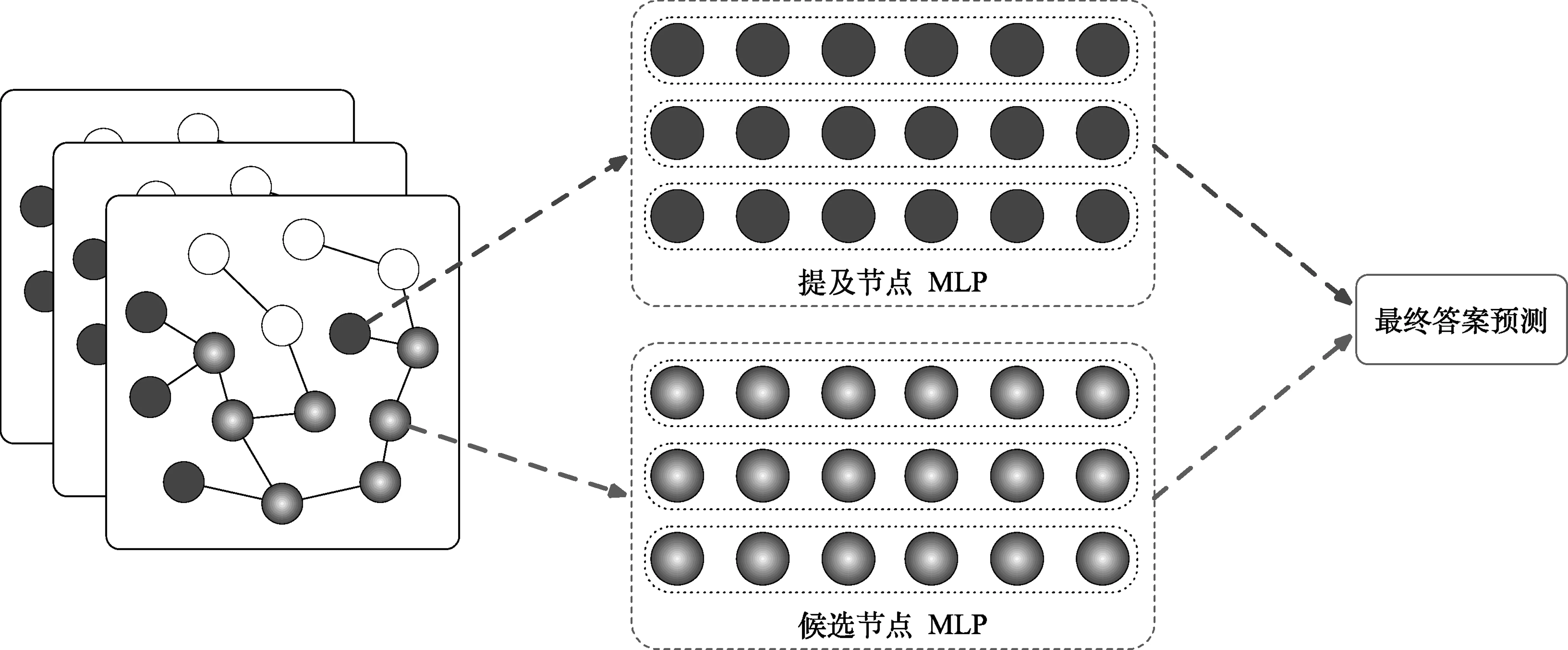
图10 图节点分类式输出层示意图
a=fC(HC)+ACCmax(fE(HE))
(23)
其中,HC、HE分别表示阅读图中候选节点和对应的实体提及节点特征,在两个独立的双层感知机fC、fE的作用下,得到每个节点的预测得分,ACCmax(·)表示从一组数据中提取的最大值。将两者按照类别相加,得到各类的分布得分。
3.4.2 长文本分类提取式
在序列式文本中,模型会预测每个分词作为答案文本语段的起始概率pstart和结束概率pend,并将两者的最大概率对应的文本语段作为输出,形式与CogQA模型提取跳跃实体文本语段或候选答案语段的方法类似,不再赘述。
对于给定多个候选答案的分类式阅读理解任务,一些长文本阅读模型采取拼接多个候选项和增加特殊标记的方式,计算分类预测结果的得分。如Longformer模型[57]将针对问题给出的多个候选答案(candidates)、问题(question)与多个文档(context)拼接为单个长序列文本: [q] question [/q] [ent] candidate1 [/ent] … [ent] candidateN [/ent] context1 … contextM ,这里[q]、[/q]、[ent]、[/ent]和均为用于微调模型的标记。在微调的过程中,标记被赋予特殊含义,预测时将每个实体前的[ent]标签输入到输出层,得到该实体作为答案预测的概率。
3.4.3 文本生成式
由于在多文档机器阅读理解任务中作答时需整合多篇文档的语义信息,直接从文档中抽取文本语段作为答案可能会导致答案片面狭隘,无法统筹所有文档的语义信息。为解决该问题,部分模型使用基于序列到序列(Sequence-to-Sequence)的生成式输出层对文档与答案进行编解码,获取符合多个文档语义信息的答案。Masque模型[52]遵循Transformer的编解码模式,在输出答案最终分布概率前,考虑了两种不同来源的答案分布概率,即扩展词汇分布(Extended Vocabulary Distribution)和拷贝分布(Copy Distributions),前者负责计算从词典Vext中输出词汇yt的概率Pv(yt),后者负责协调从多个文档和问题原文中拷贝词汇yt作为答案的概率Pp(yt)、Pq(yt)。将词汇yt的三个概率加权求和,得到如式(24)所示的yt输出概率分布,如式(24)所示。
P(yt)=λvPv(yt)+λqPq(yt)+λpPp(yt)
(24)
其中,λv、λq、λp为学习得到用于控制三者分布的平衡参数,词典Vext中每个词汇yt的输出概率由标准答案、问题文本和多文档文本综合调控,充分地利用了多文档机器阅读理解具有多个源文档的任务特性,优势较为显著。
表3展示了本文涉及模型按照数据集分组后,输出层预测结果的横向比较。其中,加粗的字体表示同组模型中更优的表现,人工作答表现用斜体标记。此外,为公平比较模型的预测结果,在表3中均选取单个模型的预测结果进行比较。在HotpotQA数据集评价排名中,“D”“F”分别表示Distractor Setting和Fullwiki Setting两种不同的评价环境。

表3 数据集中代表模型的横向比较结果
4 总结与展望
本文从机器阅读理解发展的角度,梳理了多文档阅读理解作为机器阅读新兴研究方向的发展历程;辨析了多文档阅读理解与单文档阅读理解的区别与联系,确立该任务的研究意义;介绍了8个大型多文档阅读理解数据集和5个通用的评价标准;调研了当前多文档阅读理解的主流研究方法,按照处理顺序把模型划分为4个层次;在层次一致的前提下,介绍并比较了各方法的独到之处。
总体上,多文档阅读理解是在单文档阅读理解的研究基础上发展而来的新任务,它加深了机器从文本中显式地提取答案,到隐式地学习推理多文本间潜在语义逻辑关系的研究深度,是推广机器阅读理解技术在人类世界应用的必经研究阶段。然而,多文档机器阅读理解任务还存在以下三方面值得进一步研究。
多文档阅读过程的推理能力要求目前多文档阅读理解数据集对问题的回答提出了两个要求: ①多源信息的筛选拟合; ②多文档的语义逻辑推理。尽管诸如将多文档拼接为单文档的阅读理解方法能够对信息进行一定的筛选,但是此类改进的单文档阅读理解方法在多文档间进行逻辑推理和可解释的能力较弱。同时,针对长文本序列的阅读方法虽然在一定程度上缓解了因文本规模增大而导致的信息丢失和存储开销增加等问题,但是面对日益增长的信息量,长文本序列的建模方法显得捉襟见肘,伸缩能力的缺乏仍有可能导致其预测效率降低。因此,从提升模型推理能力的角度展开研究,不仅可以解释阅读的推理决策过程,还可以避免从全文盲目寻找答案的过程。基于级联推理和GCN的方法,借助文本序列的空间拓扑结构,为模型赋予伸缩能力与逻辑推理能力。
多文档推理过程的细粒度化与人类阅读过程相似,多文档阅读理解模型需要在推理过程中筛选有意义的信息,逐渐缩小答案搜索空间,进而输出准确的预测。HotpotQA数据集提供了语句级的支持性语句,帮助模型学习语句的选择过程,而人类阅读时不总是在整段文本上进行推理,常常以更细粒度的形式选择有用信息,比如利用命名实体在多个相关文档间进行无监督的逻辑推理跳转[7],构建推理链路。借助R4C数据集给出的比语句更细化、表述更清晰的三元组推理依据,模型可进行有监督的实体逻辑推理学习过程。此外,借助模型在细粒度数据上的学习结果,可以尝试分析其在其他数据集上的泛化能力,进一步解释模型在预测过程中的选择决策依据,提升模型的综合鲁棒性。
与外部知识结合的阅读理解与阅读理解任务相比,基于知识库的知识问答任务也具有相当长的研究历史,且取得了一批有价值的研究成果。由于文档受篇幅或叙述角度的局限,模型阅读时可用语料信息不足或将导致推理过程不合理或失效。当前已有模型借助外部知识库建模文本的实体关系,或将知识三元组直接引入到阅读过程中,取得了一定的成功。因此,利用结构化的外部知识提升无结构文本阅读理解性能的方法值得进一步研究。
猜你喜欢
黄河之声(2022年10期)2022-09-27
环球时报(2022-07-13)2022-07-13
客联(2022年3期)2022-05-31
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
环球时报(2022-03-14)2022-03-14
中国新闻周刊(2021年26期)2021-07-27
电影(2018年8期)2018-09-21
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
信息安全研究(2016年4期)2016-12-01
