
基于CEEMD和改进SSA-LSSVM风功率预测模型*
2023-10-25 01:12:22常雨芳朱自铭黄文聪
传感器与微系统 2023年10期
常雨芳,朱自铭,唐 杨,黄文聪
(湖北工业大学 电气与电子工程学院,湖北 武汉 430068)
0 引 言
风能作为洁净高效的绿色新能源,有极大的随机性与波动性。所以对短期风电功率预测成为风电行业热点问题[1~4]。风电功率预测方法分为基于物理学、统计学和机器学习三类方法[5~10]。物理方法需要现实数据,计算复杂。统计学方法通过分类法对不同时间序列分类,对其所属类型匹配预测模型预测。在基于统计学预测模型中,常见分类方法包括模糊聚类法[11]和基于空间相关性的分类方法[12],预测方法有移动平均法、自回归法和自回归差分移动平均法[13]。为了提高预测精度,引入机器学习模型,包括支持向量机(support vector machines,SVM)[14]、极限学习机[15]和神经网络[16]等。采取智能优化算法对机器学习模型参数寻优[17,18]是一大研究热点。最小二乘支持向量机(least square support vector machine,LSSVM)因其拥有优秀的回归预测性、易实现从而广泛应用,但该法的核函数参数σ和惩戒参数γ主要依靠人为经验选取,精度不能满足实际需求[19]。
本文提出一种基于完备总体经验模态分解(complementary ensemble empirical mode decomposition,CEEMD)改进麻雀搜索算法(sparrow search algorithm,SSA)优化LSSVM(SSA-LSSVM)算法的预测方法,并通过某实测风电场数据进行仿真验证,证明上述改进算法在某种情况下具有更加准确可靠的预测性能。
1 实验原理与方法
1.1 CEEMD
CEEMD向待分解数据信号中加入大小相等符号相反的辅助噪声信号[20]。CEEMD 有较好的自适应性和完备性,既减轻了经验模态分解(empirical mode decomposition,EMD)算法的模态混叠现象,又不会对原始信号产生较大影响;因LSSVM 预测模型时间序列存在自相关性,上述CEEMD方法可以降低自相关性影响,最终表现在减少预测曲线滞后性。其主要步骤如下:
1)在原始时间序列Z(t)中,添加符号相反的辅助噪声信号εi(t)
式中 cij为第i次添加辅助白噪声,再分解的第j个模态分量,正负号分别为添加正负辅助噪声信号,重复步骤n 次,得n组本征模态分量,最后一组命名为趋势项(Res)。计算集合平均值,得最终模态分量组ci(t)
1.2 LSSVM
LSSVM 将SVM 中非等式约束条件转化为等式约束[21]。对于样本集{(xi,yi)},其中,xi∈Rn为训练样本的输入向量,yi∈R为对应预测输出,N为样本个数,n为向量维数,利用非线性函数φ(x),将样本映射到高维特征空间,得出其回归预测模型
式中 wT为特征空间内权重向量,b为偏差,b∈R。
当LSSVM用于回归任务时,依据最小化结构风险原则,优化模型可表示如下
式中 γ为惩戒参数,ξi为松弛变量,ϕ(xi)为原始数据映射之后的值,s.t.为约束条件,其他变量参考式(4),然后利用拉格朗日乘子法与KKT条件求解,可以获得回归函数如下所示
式中 αi为拉格朗日乘子,K(x,xi)为核函数。用RBF 为核函数,得表达式为
式中 σ为核宽度值,为自由参数,其中x与xi为原始序列值,对LSSVM预测精度与收敛速度影响较大的核函数参数σ和惩戒参数γ,本文用SSA对σ和γ寻优。
1.3 SSA及其改进
1.3.1 SSA
SSA是依据麻雀觅食与逃避捕食者提出的群智能优化算法。麻雀分为发现者与追随者,发现者提供觅食区域与方向,追随者追随发现者[22]。发现者会较快找到食物,职责是引导追随者寻食方向,所以发现者搜索范围比追随者大。
每一次迭代过程中,更新发现者位置为
式中 t为当前迭代次数,itermax为最大迭代次数。为第i个麻雀于第j维里的位置信息,为发现者更新之后位置。其中,α∈(0,1]为一个随机数。R2∈(0,1]与ST∈[0.5,1]分别为预警值与安全值。Q 为服从正态分布随机数。L为1 ×d矩阵,每个元素为1。
追随者位置更新为
式中 Xp为目前发现者所占据的最优位置;Xworst则为当前全局最差的位置;t 和t +1 则分别为原始时刻和更新之后时刻;A为一个1 ×d矩阵,其中每个元素都被随机赋值为1或-1,并且A+=AT(AAT)-1,其中,A+是伪逆矩阵。
当意识到危险时,种群做出反捕食行为,其数学表达式如下
式中 Xbest为全局最优位置;β为服从方差为1 正态分布随机数的步长控制参数;K∈[-1,1]为一个随机数,表示麻雀移动的方向,同时它也是步长控制参数;fi为目前该麻雀个体适应度值;当前全局最佳与最差的适应度值为fg和fw;ε为最小的常数,以避免分母出现零的现象。当fi>fg时为麻雀容易受到攻击;当fi=fg时为麻雀向其他个体靠近。
1.3.2 改进SSA
针对传统SSA在迭代后期种群多样性减少,容易陷入局部最优等难题,提出加入混沌序列与交换学习策略的改进SSA。通过引入混沌序列,提高了初始解质量,使初始麻雀位置分布更加均匀,增加了种群多样性,通过交换学习策略增强了全局搜索能力。
混沌映射表达式如下
式中 NT为混沌序列中的粒子个数,rand(0,1)为[0,1]之间的随机数,zi和zi+1分别为原始的种群和更新之后的种群,mod指取模运算。据混沌映射特性,于域中产生混沌序列步骤如下:1)随机产生(0,1)内的初值z0,记i =0。2)利用上述式子进行迭代,产生Z序列,同时i自增1。3)如果迭代的次数满足最大次数,则程序停止运行,同时保存产生的Z序列,并将之作为麻雀算法的初始种群。
交换学习策略操作具体是在不同种群的相同维度中进行相互交叉运算,提高数据交互性[23]。针对SSA全局搜索能力不强问题,采用交换学习策略对警戒者位置更新。第一步将父代个体进行随机的配对,于第d 维进行交换学习操作,公式如下

2 超短期风功率联合预测模型原理与流程
本文采用数值天气预报(numerical weather prediction,NWP)数据输入为4维,有风速、风向、温度、湿度;输出为风机功率。
本文采用CEEMD对风功率时间序列进行分解,可降低预测模型中自相关性,避免预测值滞后于实际值,再采取预测性能强的LSSVM作为模型主体进行风功率预测。同时,采用改进SSA对LSSVM的核函数参数和惩戒参数优化,可改善LSSVM预测精准性。基于CEEMD和改进SSA-LSSVM的超短期风功率预测模型基本流程,如图1所示。

图1 风功率联合预测模型
基本流程如下:1)CEEMD 分解,得IMF 分量;2)利用SSA-LSSVM预测模型对多个IMF分量分别进行预测,对结果进行求和,得到CEEMD-SSA-LSSVM预测结果;3)结果分为测试集训练结果与训练集预测结果,将训练集的预测结果输入到改进SSA参数寻优中,可以获得最优核函数参数和惩戒参数,最后将最优值输入模型得到最优SSA-LSSVM预测模型,再将测试集代入得到预测结果。
3 实验原理与方法
3.1 实例数据说明
本文采取中国西北部某风电场实际数据进行预测,其中风机负荷时序如图2(a)。10 min一次采样,取2173组数据,其中1 522 组为模型训练集,余下为测试集。风功率NWP数据是输入,输出为风功率,同时将预处理之后数据进行分解之后的负荷时序如图2(b)所示。

图2 风电场功率时序与风速数据CEEMD
3.2 评价指标
平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)为评价指标[24]。为增加可靠性,将仿真程序运行时间和自相关函数(autocorrelation function,ACF)新增为评价指标,ACF 是用来计算时间序列自相关性。ACF描述的是一组时间序列和其前面间隔n个时刻的一组时间序列相关性[25]
式中 et为t时预测绝对误差值;Rt为t 时真实值;m 为预测时间点数。式(17)中,ρ(t1,t2)是同一时间序列不同时间的相关性,βt1和βt2分别为t1和t2时间序列的方差,α(t1,t2)为上述两时间序列协方差。
3.3 预测结果对比与分析
3.3.1 预测模型滞后性分析
为了验证本文中所提到的CEEMD方法可以改善预测算法自相关性,减少预测曲线滞后性,本文将单一预测模型LSSVM,单一预测模型SVM,SSA-LSSVM,CEEMD-LSSVM,CEEMD-SVM,CEEMD-SSA-LSSVM联合预测模型645 组预测结果进行对比分析,并且将部分数据局部放大,突出不同预测模型预测效果。在MATLAB 2020b 实验平台进行仿真,预测结果与局部放大如图3、图4所示。

图3 预测模型结果
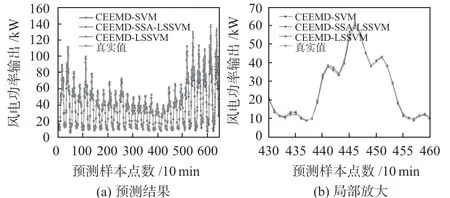
图4 CEEMD分解预测模型结果
图3(b)和图4(b)均为选取的430 ~460 数据段,仿真结果表明:该段数据的分离性好,可以充分论证结论。综合实验数据和图像可得:
1)从图3(b)和表1 中可知,SSA-LSSVM 预测模型的MAPE值是10.0894%,优于单一LSSVM和SVM预测模型的11.5454%与11.6632%,分别提升了10.6732%和13.4937%,同时其平均预测准确度提高了5.7496%与6.9583%,说明联合预测模型预测精度比单一高,也减少运行时间。

表1 不同模型的误差指标对比
2)由图3(b)和图4(b)对比可知,图中的LSSVM 与CEEMD-LSSVM模型的预测曲线与实际值滞后性降低,证明CEEMD分解可以极大改善预测数据的自相关性,表现在可以将部分预测曲线的滞后性大大降低,使预测值更加贴近实际值,提高了预测模型的应用价值,实验结果表明上述方法可以将LSSVM单一预测模型的自相关性减少13.6%。通过进一步观察图3(b),证明了CEEMD 分解对SSA-LSSVM联合预测模型比单一预测模型改善效果更好。
3.3.2 基于改进SSA的联合预测模型
本文将改进SSA-SVM,原始SSA-SVM 预测模型,改进SSA-LSSVM 预测模型,原始SSA-LSSVM 和鲸鱼优化算法(whale optimization algorithm,WOA)优化的LSSVM 模型5种模型的预测结果进行对比分析,并且将它们的局部放大显示,以便更加方便直观地观察出实际区别。仿真实验均在MATLAB 2020b实验平台进行,其预测结果与局部放大如图5所示。误差指标对比如表2。

表2 不同模型的误差指标对比
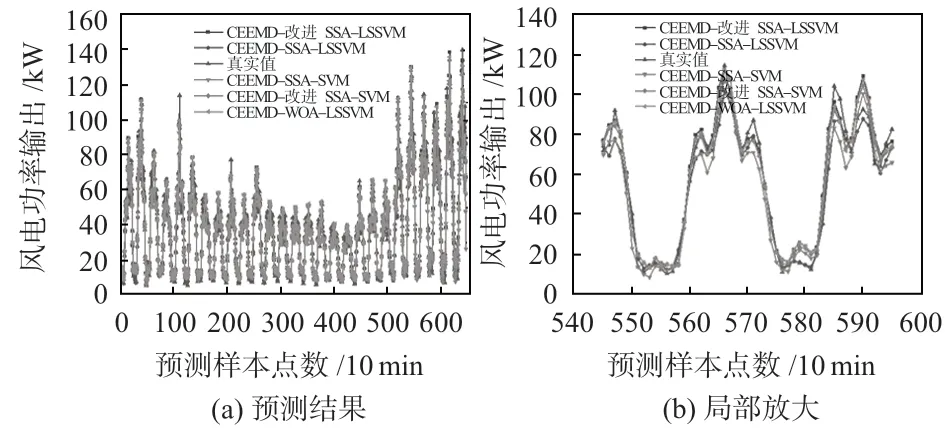
图5 不同模型预测结果
图5(b)为选取545~595 数据段,通过仿真可得:该段数据分离性好,可以充分论证结论。综合实验数据和图像可得:图5中改进SSA提升了LSSVM预测模型精度。本文提出的引入混沌序列和交换学习策略的改进SSA具有优越性,通过引入混沌序列,提升初始解质量,让初始麻雀位置分布更均匀,增加了种群多样性;引入交换学习策略增强算法全局搜索能力。结果显示,上述方法较SSA-LSSVM 预测精度提高26.73%,即改进后SSA对LSSVM 预测模型核函数和惩戒参数有较高寻优精度,提高了预测模型应用价值。
从表2中可知,CEEMD—改进SSA-LSSVM 预测模型的MAPE值是9.073 4 %,优于原始SSA-LSSVM 预测模型的11.123 6%,提升了18.4310%;优于原始CEEMD-SSA-SVM模型的11.545 4%,提升了10.759 5%;优于CEEMD-WOALSSVM的10.369 4%,提升了12.498 3%。实验结果证明:提出的联合预测模型相较于上述预测模型有更好预测精度,其运行时间较其他模型略微增加。
4 结 论
通过实例仿真得到以下结论:
1)CEEMD对数据分解,得到稳定分量,强化模型对时间序列的学习捕捉能力,极大解决了非线性原始数据不平稳导致误差较大的问题,同时改善了数据自相关性,最终表现在降低了预测曲线滞后性上,提高预测模型使用范围。
2)本文通过组建联合预测模型,运用仿真平台对比可以得到改进后的SSA 对LSSVM 预测模型的核函数和惩戒参数优化有较大提升,通过引入混沌序列,提升初始解质量,让初始麻雀位置分布更均匀,增加了种群多样性;引入交换学习策略增强算法全局搜索能力。测试结果表明,改进后的SSA优化了传统SSA 在迭代后期种群多样性减少,容易陷入局部最优等难题,具有较好应用价值。
猜你喜欢
作文小学中年级(2019年10期)2019-11-04 00:39:52
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
法律方法(2018年2期)2018-07-13 03:21:42
趣味(语文)(2018年2期)2018-05-26 09:17:55
魅力中国(2017年6期)2017-05-13 12:56:17
数理化解题研究(2017年4期)2017-05-04 04:07:59
中学生数理化·八年级物理人教版(2017年11期)2017-02-15 02:12:21
山东青年(2016年1期)2016-02-28 14:25:22
江西理工大学学报(2015年3期)2015-12-22 05:26:25
湖北科技学院学报(2014年6期)2014-07-12 15:29:44
