
基于改进YOLOX的小麦不完善粒检测技术研究
2023-10-24 08:45周永强
河南工业大学学报(自然科学版) 2023年5期
吴 兰,周永强
1.河南工业大学 机电工程学院,河南 郑州 450001
2.河南工业大学 电气工程学院,河南 郑州 450001
开展小麦不完善粒检测技术的研究,对于小麦评级和粮食储藏品质检测具有重要现实意义。小麦不完善粒是指受到损伤但仍有食用价值的籽粒,包括破损粒、虫蚀粒、病斑粒(黑胚粒以及赤霉病粒)、生芽粒、霉变粒等[1]。传统小麦不完善粒检测方法主要有人工检测和传统机器学习。其中人工检测方法由质检员进行人工识别判断,主观性强、费时费力、时效性较差[2-3]。传统机器学习则是一种快速而无损的检测方法[4]。左卫刚等[5]设计了具有多层感知器的FFBP-ANN模型用于识别籽粒,分类准确率达99%。蒋雪松等[6]对麦粒光谱图像预处理后,建立LDA识别模型,对霉变粒识别率达90.6%。Olgun等[7]根据提取籽粒的密集尺度不变特征,使用支持向量机算法进行分类,准确率为88.33%。但这些传统方法需要人工提取籽粒特征并设计分类器模型,操作过程复杂。
随着计算机技术和卷积神经网络(CNN)的迅速发展,许多研究者将深度学习技术应用到小麦不完善粒识别领域中。一些学者基于数据增强和融合的方法对图像进行处理,输入到分类网络进行识别。郝传铭等[8]将小麦高光谱图像与彩色图像匹配融合后输入到VGG网络进行识别,准确率较仅使用彩色图像和高光谱图像分别提高3.34%和6.08%。贺杰安等[9]使用交替最小化算法对籽粒特征进行细节增强,输送到CNN中进行识别,准确率较经典网络提高7百分点。于重重等[10]采集多波段的小麦高光谱图像,并进行边缘降噪处理,实现对4类不完善粒的无损检测。张博[11]对单籽粒图像进行样本扩充,使用引入残差结构的CNN模型实现对不完善粒的平均识别率达90.6%。但上述方法均需要对图像进行复杂的预处理,耗时较长,识别率有待提升,且高光谱设备成本高。
部分学者对经典分类网络进行改进,用以提升不完善粒的识别率。如余乐等[12]通过增加卷积核的数量提高LeNet-5网络的性能,但数据样本较小,模型对3种小麦不完善粒的平均识别准确率达93%。曹婷翠等[13]利用空间金字塔池化(SPP)对普通CNN网络进行改进,并采用双面识别方案,对完善粒、破损粒和病斑粒的平均识别准确率达到90%。祝诗平等[14]使用加入Droupout层的AlexNet网络建立小麦检测模型对2类不完善粒进行识别,并与LeNet-5、VGG-16、ResNet-34和AlexNet经典网络对比,该改进模型识别效果最佳,准确率高达98%。张庆辉等[15]将多粒小麦图像分割为单籽粒,输入到VGG16、VGG19和ResNet50的融合模型中进行特征提取,使用深度信念网络(DBN)代替隐藏层和softmax识别不完善粒,准确率达91.86%。以上这些方法样本的获取需要进行烦琐的单籽粒分割操作,增加了识别时间。同时,改进后的网络无法实现对多籽粒的同时识别并进行计数,识别效率较低。
深度学习目标检测算法能够实现多类别目标快速识别检测和解决多目标粘连的问题,但目前目标检测算法多应用于麦穗检测方向[16-18],在小麦籽粒检测方向的研究较少。虽然,WU等[19]通过优化Faster R-CNN模型对小麦有效分蘖中的籽粒进行检测和计数。宋怀波等[20]在YOLOv5网络基础上,引入压缩激励模块提高检测精度,对正常粒的平均检测精度达到90%。但是以上模型仅检测完善粒,籽粒类型单一,泛化能力较弱,难以用于多类别的不完善粒粮食质量检测。
为此,以多类别的小麦不完善粒为研究对象,提出一种改进YOLOX的小麦不完善粒检测方法。针对YOLOX应用在不完善粒检测中,存在模型计算量大,对不同大小的不完善粒识别效果差的问题,在原网络主干部分添加坐标注意力机制(coordinate attention,CA)增强不完善特征;使用加权双向特征金字塔(BiFPN)结构,使不同大小籽粒的多尺度特征有效融合;使用深度可分离卷积对网络进行轻量化处理,减少参数量,实现对多籽粒的快速准确识别。该检测模型提供了一种批量、连续的不完善粒检测方法,为多类别小麦不完善粒的实时检测和计数提供技术参考。
1 材料与仪器
1.1 试验材料
豫农908、郑麦618和郑麦136:许昌市粮食质量检测中心。试验前从小麦中挑选出完善粒、破损粒、生芽粒、虫蚀粒、病斑粒(本研究选黑胚粒)。
1.2 仪器与设备
MV-CS050-10GC工业相机、MVL-HF0628M-6MPE镜头:杭州海康威视数字技术股份有限公司;PFM-HX3475CO10W-A-1A2环形光源:浙江华睿科技股份有限公司。
2 图像采集与数据集制作
2.1 图像采集
由于公开数据集COCO、ImageNet和PASCALVOC均不包含本研究的对象,因此,手动采集制作小麦图像数据集。图像采集装置由5部分构成,包括工业相机、亮度可调节的环形光源、升降杆、载物板和计算机。同时,每次选取1~20粒,21~40粒,41~60粒的小麦样品随机撒在载物板上,在90°角度和不同高度下(10、15、20 cm)拍摄不同密集程度的小麦籽粒原始图像,共获得3 572幅图像。实际场景下,光线和噪声等条件无法保证绝对均匀,为了使模型适应性更强,通过变暗、引入椒盐噪声、旋转和颜色空间转换等方法对小麦籽粒进行数据增强,增加样本多样性。每张图片随机使用1~2种方法进行增强,原图由原来的3 572幅筛选后扩充至6 000张。图1为部分经过数据增强的小麦图像。

图1 图像增强后的小麦籽粒图像Fig.1 Images of wheat kernels enhanced by different methods
2.2 数据集构建
采用LabelImg工具对小麦图像进行标注,生成与其对应的XML标签文件。将图像按照7∶2∶1随机划分为训练集4 200张、验证集1 200张、测试集600张,各类小麦籽粒的简称和数量如表1所示。

表1 小麦籽粒类型简称和数量Table 1 Abbreviation and number of different wheat grain types
3 小麦不完善粒检测方法
3.1 改进的YOLOX模型
YOLOX模型由主干特征提取网络(Backbone)、特征融合网络(PANet)和预测端的解耦检测头(Yolo Head)组成,并引入无先验框和正负样本匹配策略(Sim OTA)使网络检测性能得到有效提升。该模型在公开数据集上具有较好的检测性能,但对于小麦图像中多类别不完善粒的检测和计数,仍有计算量大、对不同大小的不完善粒识别效果差的问题。
为此,基于YOLOX算法将主干网络中的普通卷积替换为深度可分离卷积,通过逐层和逐点的不同卷积方式减少模型计算参数量。同时,为提高模型精度,在YOLOX的主干特征网络中CSP模块与卷积块之间添加坐标注意力机制(coordinate attention,CA),使模型更加关注籽粒细节特征,提高不完善粒的特征表达能力。此外,在特征融合部分使用加权双向特征金字塔结构进行双向跨尺度连接,提高模型的特征学习能力,增强特征的鲁棒性。提出的算法检测框架如图2所示。算法检测流程:采集多个品种的小麦籽粒图像进行图像增强和数据标注,构建小麦数据集,并划分为训练集、验证集和测试集;将训练集图片输入到引入CA和使用加权双向特征金字塔结构及深度可分离卷积(Depthwise separable convolution,DwConv)进行改进的YOLOX网络中进行训练,从而获得检测模型的最优训练权重;利用训练得到的模型权重对测试集图片进行检测,得到各类别不完善粒的数量和置信度。

图2 算法的检测框架Fig.2 Detection framework of the proposed algorithm
3.1.1 坐标注意力模块
由于小麦籽粒较小,在图像中所占像素较少,原YOLOX网络采样时容易丢失小目标的特征信息,故引入坐标注意力,增强麦粒的特征显著度,进而提高不完善粒的识别精度。以往的注意力机制如CBAM[21]、SENet[22]等使用全局池化编码空间信息会造成位置信息丢失。如图3所示,坐标注意力机制[23]包含坐标信息嵌入和注意力生成两部分。在信息嵌入阶段,将位置信息加入到通道注意力中,将通道注意力全局池化分解为水平和垂直方向的一维特征编码,得到尺寸C×H×1和C×1×W的特征图,在两个空间方向进行聚合,返回方向注意力图。注意力模块保存一个空间方向的精准位置信息,同时获取另一个空间方向的长程依赖,有助于网络更准确地定位目标。注意力生成阶段,首先,将两个特征图拼接得到C×1×(H+W)的特征图,使用1×1卷积将其进行压缩,得到中间特征图f,将其沿空间维度分解为C/r×1×W的水平注意张量和C/r×H×1的垂直注意张量。然后,用两组1×1的卷积将通道维度从C/r变换到C维。最后,将获取的两个注意图C×H×1和C×1×W与输入特征图F相乘,完成坐标注意力的施加。原始YOLOX网络在特征提取过程中对特征信息采用相同的权重进行提取,无法获取不同目标的特有信息。在CSP模块后引入CA模块,使网络在特征提取中更加关注目标重要信息。

图3 CA 模块Fig.3 CA module
3.1.2 深度可分离卷积模块
为了使网络具有较高检测精度,同时减少引入注意力机制后对网络检测速度的影响,使用深度可分离卷积(DwConv)[24]替换原YOLOX主干网络的普通卷积,DwConv将卷积过程分解为逐层卷积和逐点卷积,相较于普通卷积能够大幅减少参数计算量,提高模型计算速度。DwConv结构如图4所示。

注:H1、W1、C1分别表示输入特征图的高、宽和通道数,H2、W2、C2分别表示输出特征图的高、宽和通道数,n×n表示卷积核的大小。图4 深度可分离卷积结构Fig.4 Deep separable convolution structure
使用普通卷积对特征图进行卷积运算,其参数计算量P1如式(1)所示:
P1=n2×C1×C2×H2×W2。
(1)
DwConv使用n×n的逐层卷积和1×1的逐点卷积,其参数计算量P2如式(2)所示:
P2=n2×C1×H2×W2+C1×C2×H2×W2。
(2)
由以上可得,两种卷积的参数计算量比值如式(3)所示:
主干网络输入通道数为3,输出通道数为512,使用DwConv后的参数计算量约为使用普通卷积运算的1/9,极大地减少了网络的参数计算量。
3.1.3 加权双向特征金字塔网络
原始YOLOX网络中采用FPN+PAN结构进行多尺度特征融合,但是二者进行特征融合时,需要将特征图变换成相同的尺寸进行相加,无法进行不同尺度特征图之间的融合,导致网络的检测精度受限。
为了提高网络对籽粒的检测精度,实现对不同尺寸不完善粒特征图的高效融合,引入加权双向特征金字塔网络(BiFPN)。首先,删除只有一条输入边的特征图,只有一条输入边且未与其他输入边的特征图融合,其对融合不同特征的网络贡献很小,将其删除对网络影响小,同时简化了双向网络。然后,将删除的单输入边的特征图输入到下一层的特征图中,实现跨尺度融合,达到更强的特征融合。最后,在同一层网络中,在原输入节点到输出节点之间新加一条输入边,在不增加计算量的前提下融合更多特征。通过上述策略构建BiFPN,结果如图5所示。改进的模型将主干网络中提取的3种不同尺度特征图F1、F2、F3作为BiFPN的输入,利用不同尺度的特征进行跨尺度特征融合,提高网络对于小目标的检测精度。

图5 双向特征金字塔网络Fig.5 Pyramid network with bidirectional features
4 试验与结果分析
4.1 试验设置
为了验证本文模型的有效性,从引入CA、应用DwConv、使用BiFPN结构3个方面进行消融试验,并用训练模型对小麦籽粒进行检测。所有试验均使用相同数据集在同一台计算机上进行,计算机操作系统为Ubuntu18.04LTS,CPU为E5-2673V4,GPU为NVIDIAGeForceRTX2080Ti,显存 12G。CUDA版本为 11.1.0,CUDNN版本为 8.1.0。深度学习框架为Pytorch1.7。
4.2 评价指标
为了能够全面评价模型的性能,使用精确率(Precision)、召回率(Recall)、平均精度均值(meanaverageprecision,mAP)和损失值(Loss)作为指标评价模型,各指标的计算公式如下:
式中:TP(truepositives)表示被正确分类的正样本;TN(truenegatives) 表示被正确分类的负样本;FP(falsepositives)表示被错误分类的正样本;FN(falsenegatives)表示被错误分类的负样本。平均精度(averageprecision,AP)是以Recall为横轴,Precision为纵轴组合的曲线下积分的面积,m为检测目标的类别数量。
精确率反映的是检测结果中检测正确的目标数量占全部识别目标数量的比率。召回率表示在所有小麦籽粒中不完善粒被识别出来的比率,这两个指标值越大,表明所训练的模型检测性能越好。损失值用来描述预测值与真实值之间的误差,数值越小,表示模型预测越准确。
4.3 结果分析
将原YOLOX主干网络中的普通卷积替换为深度可分离卷积,并在每一个CSP模块后引入CA注意力模块,同时使用加权双向特征金字塔结构进行双向跨尺度连接,得到改进的YOLOX网络模型。模型训练中,动量因子设为0.937,每次训练批次大小为32,学习率设置为0.000 1,权重衰减设置为0.000 5,使用Adam优化器。将模型迭代训练100轮,训练过程中平均精度均值mAP(交并比为0.5)和损失值的变化如图6所示。由图6可知,该模型具有较高的检测精度,同时损失值较小,具有很好的收敛效果。
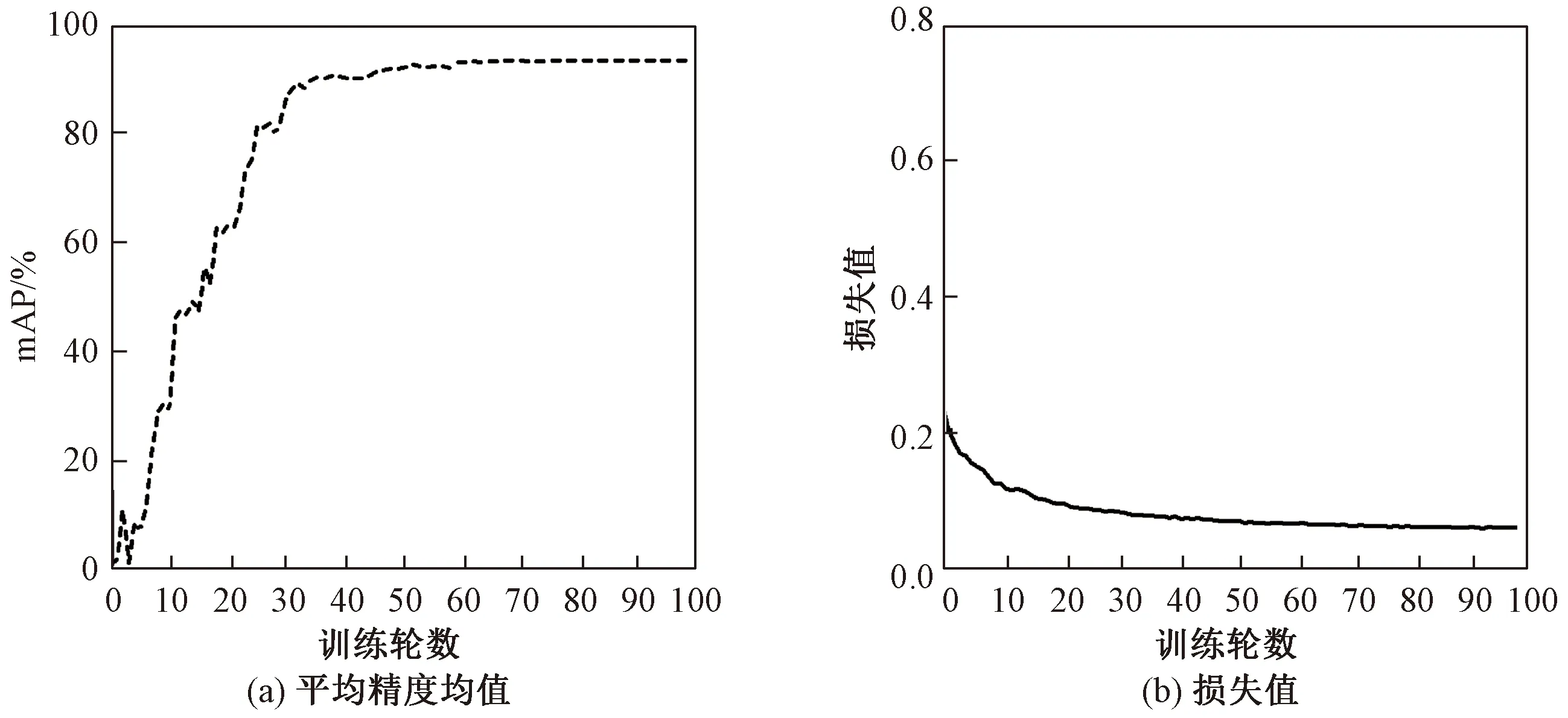
图6 训练结果Fig.6 Training results
4.3.1 消融试验
为了验证本文改进方法的有效性,采用消融试验验证不同改进策略对整个模型的影响。进行4组试验,第1组为原始YOLOX网络模型;第2组在主干网络CPS模块后引入CA注意力机制模块;第3组在第2组的基础上使用BiFPN结构;第4组在第3组的基础上将主干网络中的普通卷积替换为DwConv卷积,即本文提出改进模型。
消融试验结果如表2所示,由第2组试验可知,引入CA注意力模块后,参数量增加了0.03M,但模型检测时间影响很小,而模型的mAP提升了2.09百分点,说明加入CA注意力模块后网络更加关注麦粒局部的不完善特征,提高不完善粒的特征表达能力,使用Grad-CAM绘制模型引入CA前后不完善粒的对比结果如图7所示(以虫蚀粒为例)。
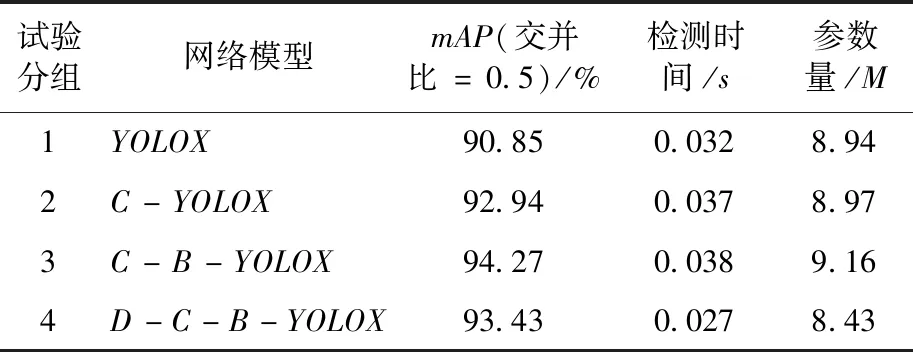
表2 消融试验结果Table 2 Ablation experiment results
图7中红色区域为各不完善粒特征明显区域,且颜色越深表示显著度越高。引入坐标注意力机制,使模型更关注不完善特征,降低模型漏检率。由表2可知,第3组试验相对于第2组,mAP提高了1.33百分点,参数量仅增加了0.19M,检测速度(检测时间的倒数)基本不变。采用加权跨尺度特征融合算法,充分利用不同尺度籽粒特征的语义信息,提高不完善粒的检测精度。第4组试验相对于第3组,模型mAP下降了0.84百分点,但参数量减少了7.97%,检测速度提高了10.72fps,表明深度可分离卷积能够有效降低模型的参数量,提高检测速度,但同时会损失一些精度。本文算法综合各模块的优点,检测精度达到93.43%,并且具有更好的检测实时性。
4.3.2 不同籽粒数量的检测试验
为了检验模型的准确性,使用不同数量籽粒的图片进行测试,结果如表3所示。当图像中的籽粒数小于30时,没有漏检情况,识别准确率达到100%。当籽粒数小于40时,大多数样本的漏检率不超过3%。当籽粒数量达到60时,漏检率有所增加,最高不超过5%。其中,模型不受小麦品种类型和密集程度的影响,鲁棒性较强。使用改进模型对不同籽粒数量的样本图片进行识别,部分检测结果如图8所示。

表3 不同籽粒数下模型检测结果Table 3 Model detecting results for different grain numbers

图8 不同籽粒数量检测结果Fig.8 Test results of different grain numbers
实际应用时,对于模型单幅图像的检测速度有一定的时间要求,最好能够实现对目标的实时检测。检测时间小于1s可考虑将模型应用于移动端[25],检测模型对图像尺寸为640×640像素的不同数量籽粒的检测时间如图9所示。由图9可知,检测时间随着籽粒数量的增加而增加,模型对于单幅图像的平均检测时间为0.027s,检测速度达到37fps,最大检测时间为0.04s。

图9 不同籽粒数量的检测时间Fig.9 Detection time of different grain numbers
4.3.3 混合籽粒的检测试验
从试验材料中另外采集5个类别的小麦籽粒图像,每类200粒。每幅图像包含20粒混合籽粒,共50幅小麦图像,使用改进后的网络进行检测,结果如表4所示。由表4可知,完善粒、破损粒、虫蚀粒、生芽粒和黑胚粒正确识别个数分别为188、179、185、189、186,识别准确率分别为94%、89.5%、92.5%、94.5%、93%,平均识别正确率为92.7%。结果表明,模型对于不同的小麦籽粒类型均能有效识别与检测。将此检测技术应用到实际粮食质量检测中,通过统计批量小麦中完善粒的数量,其余均为不完善粒,计算完善粒的占比即可对该批小麦的质量进行评级。
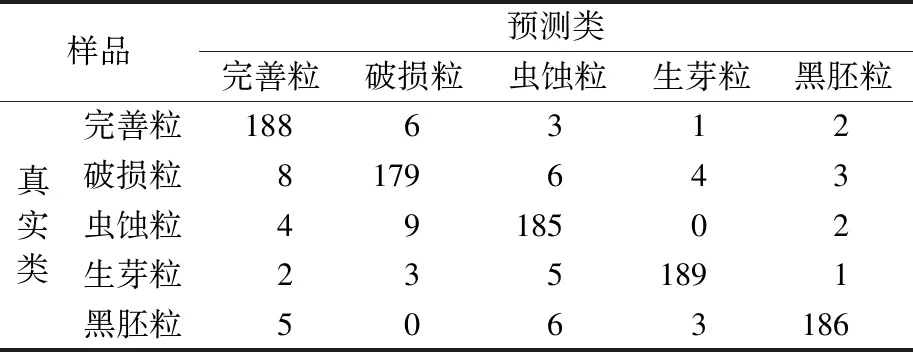
表4 改进YOLOX模型对混合籽粒的检测结果Table 4 Detection results of mixed grains by improved YOLOX model
为验证本文所作改进对YOLOX模型的提升效果,将其与原YOLOX模型进行对比;同时为说明YOLOX相较于YOLOv5模型的轻量性及检测优势,也将YOLOv5模型作为对比对象之一;选取小麦籽粒检测方面的FasterRCNN[19]和YOLOv5-MDC[20]以及在农作物检测广泛使用的单阶段检测网络SSD[26]进行了对比,结果如表5所示。

表5 不同检测算法结果的对比Table 5 Comparison of results by different detection algorithms
由表5可知,本文算法相较于一阶段的SSD和YOLOv5-MDC以及两阶段的Faster-RCNN网络模型轻量化了许多;YOLOv5-MDC的检测精度比本文算法稍微优越一点,比本文高0.78百分点,但其网络模型参数量比本文多12.97M,检测速度低于本文算法。本文算法的检测精度高于其他3种主流检测算法,相较于原YOLOX算法平均检测精度提升了2.58百分点,检测速度提高了5.78fps,检测速度更快,能够更好地满足实时检测的要求。
5 结论
本文提出一种基于改进YOLOX的小麦不完善粒检测算法。针对籽粒过小难以检测的问题,通过引入CA注意力机制有效增强小麦籽粒局部的不完善特征显著度,并将网络特征融合部分改为加权双向特征金字塔(BiFPN)结构,实现多尺度籽粒特征更有效地融合和表达,进而提高目标的检测精度;针对不完善粒检测实时性问题,通过应用DwConv卷积,降低网络的计算复杂度,提高模型的检测速度。利用自制的小麦数据集,通过对多个品种不同密集程度的多籽粒进行检测,本文算法对于随机分布的多类别不完善粒的平均检测精度达到93.43%,单幅图像平均检测时间为0.027s,且模型占用内存小,便于移植至嵌入式设备。该模型可用于多品种、不同数量的密集小麦籽粒识别检测中,为小麦不完善粒检测提供一种新的技术参考。
本文未对实际检测场景下批量的小麦不完善粒进行连续检测,下一步研究的重点是在保证模型检测速度和精度的前提下,对模型进一步完善后在嵌入式平台上进行部署,并在实际应用场景下进行检测测试。
猜你喜欢
今日农业(2022年16期)2022-11-09
现代畜牧科技(2021年4期)2021-12-05
现代畜牧科技(2021年10期)2021-11-19
金桥(2021年10期)2021-11-05
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2021年13期)2021-08-14
作文小学中年级(2020年4期)2020-06-11
电子制作(2019年11期)2019-07-04
河北农业科学(2018年2期)2018-07-26
北京航空航天大学学报(2018年1期)2018-04-20
