
高阶条件随机场引导的多分支极化SAR图像分类
2023-10-24 13:58:30张帆闫敏超倪军项德良
中国图象图形学报 2023年10期
张帆,闫敏超,倪军,项德良
1.北京化工大学信息科学与技术学院,北京 100029;2.北京化工大学人工智能交叉研究中心,北京 100029
0 引言
合成孔径雷达(synthetic aperture radar,SAR)作为一种主动式的微波成像传感器,具有全天候成像的能力,并具有一定的穿透性,可以获取地面物体的反向散射信息及无人区的关键信息,广泛应用在土地利用、土地覆盖分类等领域(张红 等,2014)。深度学习方法因具有强大的数据分析和特征自动提取能力,在遥感图像地物分类任务中展现出卓越性能,成为SAR 数据分析领域的研究热点。在网络结构的不断演变中,卷积神经网络(convolutional neural network,CNN)、堆叠自动编码器(stacked autoencoder,SAE)、深度信念网络(deep belief network,DBN)、递归神经网络(recursive neural network,RNN)和生成对抗网络(generative adversarial network,GAN)等成为深度学习中有效和重要的基础结构类型(王俊 等,2018)。其中,CNN 具有提取更具判别性和不变性特征的优势,有助于去除SAR 图像中存在的斑点噪声(李亚飞和董红斌,2018)。随着深度网络模型的不断发展,CNN 在SAR 图像分类方面取得了极大的成功。
在特征学习的过程中,除了每个像素点具有的特征信息外,图像中包含的空间信息对类别的正确识别也有显著影响(汤玲英 等,2018)。对此,已经提出了一种集成像素坐标信息的双路神经网络(conditional random field network,CRF-NET),在遥感图像土地覆盖分类中取得了一定的分类效果(Zhang 等,2021)。然而,除了位置信息外,还可以利用更多的上下文和语义线索来实现多层次空间特征关联。Han等人(2020)利用神经网络提取语义特征,并将其作为条件随机场(conditional random field,CRF)模型的高阶势函数集成到新型能量函数中,在CRF 框架内增加类别感知度,以从不同的角度提供互补信息;Wang等人(2019)将条件随机场框架嵌入到网络模型中,充分利用亚像素、像素和超像素的互补特性,对应构造了CRF 能量函数中的一元势、二元势和高阶势函数,有效地将位置、上下文和语义信息集成为强大表征特征以提高分类性能。基于以上启发,本文对已提出的CRF-NET 进一步改进,引入高阶语义特征的概念,增加具有方位修正性的邻域信息提取支路,构建多分支神经网络以融合不同类型的空间特征。
此外,在传统的图像分类过程中不难发现,相近地理区域内的土地覆盖类型往往是相同的(赵斐等,2019),将相同地物目标的类别进行统一可以有效避免散斑噪声的影响。为此,本文引入了超像素约束模块。超像素可以自适应地描述不同大小和形状的局部结构信息,且很好地保持对象边界。对于多分支网络输出的预分类结果,依据超像素分割情况取匀质区域内的像素点进行类别约束,可以有效平滑相邻像素之间的特异性和相似性,提高分类结果的可靠性。
1 高阶CRF深度神经网络
针对目前极化合成孔径雷达(polarimetric synthetic aperture radar,PolSAR)地物分类方法普遍存在数据特征表征能力弱的问题,本文提出一种由高阶条件随机场模型引导的图像分类网络,总体流程示意图如图1 所示,主要包含数据预处理、多分支特征提取和超像素约束3个模块。

图1 高阶CRF多分支网络流程图Fig.1 The flowchart of multi-branch network based on high-order CRF model
1.1 PolSAR数据预处理
与光学彩色图像和高光谱图像不同,PolSAR 数据并非真正意义上的图像,而是探测区域对发射电磁波的反应,主要体现后向散射系数。PolSAR 数据中包含丰富的地物信息,但原始的散射特征并不能从散射机制上解译不同目标之间的可区分性,例如,一个分辨单元内可以包含许多地物类型的散射回波,且往往有不同的相位值。因此直接利用极化散射特征获得的分类结果往往并不理想。极化目标分解是一种有效描述地物极化信息的方法,可以依据真实的地物空间分布,将混合散射机制拆分为几种互不相关的单一模型分量,在降低数据复杂性的同时提取更具纯净度和抗干扰性的特征。多种独立的散射分量从不同的方面解释了目标的几何分布特征和物理散射机制,能够提供更加丰富的地表覆盖信息。在众多经典方法中,Yamaguchi 四分量分解模型(Yamaguchi 等,2005)充分考虑了复杂地形的反射不对称性,利用非相干分解方式将数据分解为奇次散射、偶次散射、体散射和螺旋散射,广泛应用于分析非对称自然区域和人造建筑。因此,在进行特征提取之前,首先将原始SAR 数据进行Yamaguchi四分量分解处理,分解模型表示为
1.2 高阶CRF模型
在遥感图像分类领域,传统的分类方式使用统计学习算法独立地分析每个像素的特征信息,为像元分配不同的预定义标签实现分类(滑文强 等,2019)。然而,PolSAR 数据中包含大量的空间上下文信息,单纯提取像素级特征往往会忽略这部分关键信息而导致分类结果不准确。
CRF(Lafferty等,2001)是一种后验概率图模型,通常用于将原始空间信息整合到图像分类问题中。CRF 模型的本质是在不同的基团上定义势函数,根据基团包含变量个数的不同,可分为一阶势函数、二阶势函数以及高阶势函数。具有高阶势函数的CRF模型能够更好地集成位置—上下文—语义线索,增加像素点之间的空间依赖性,有效克服特征识别度低的问题。因此,针对分类结果中存在的场景错分、地物边界模糊的问题,在已完成模型CRF-NET 的基础上,设计了多分支特征提取网络,进一步融合全局及局部空间特征。网络结构模型及参数设计分别如图2和表1所示。

表1 多分支网络参数Table 1 Multi-branch network parameters
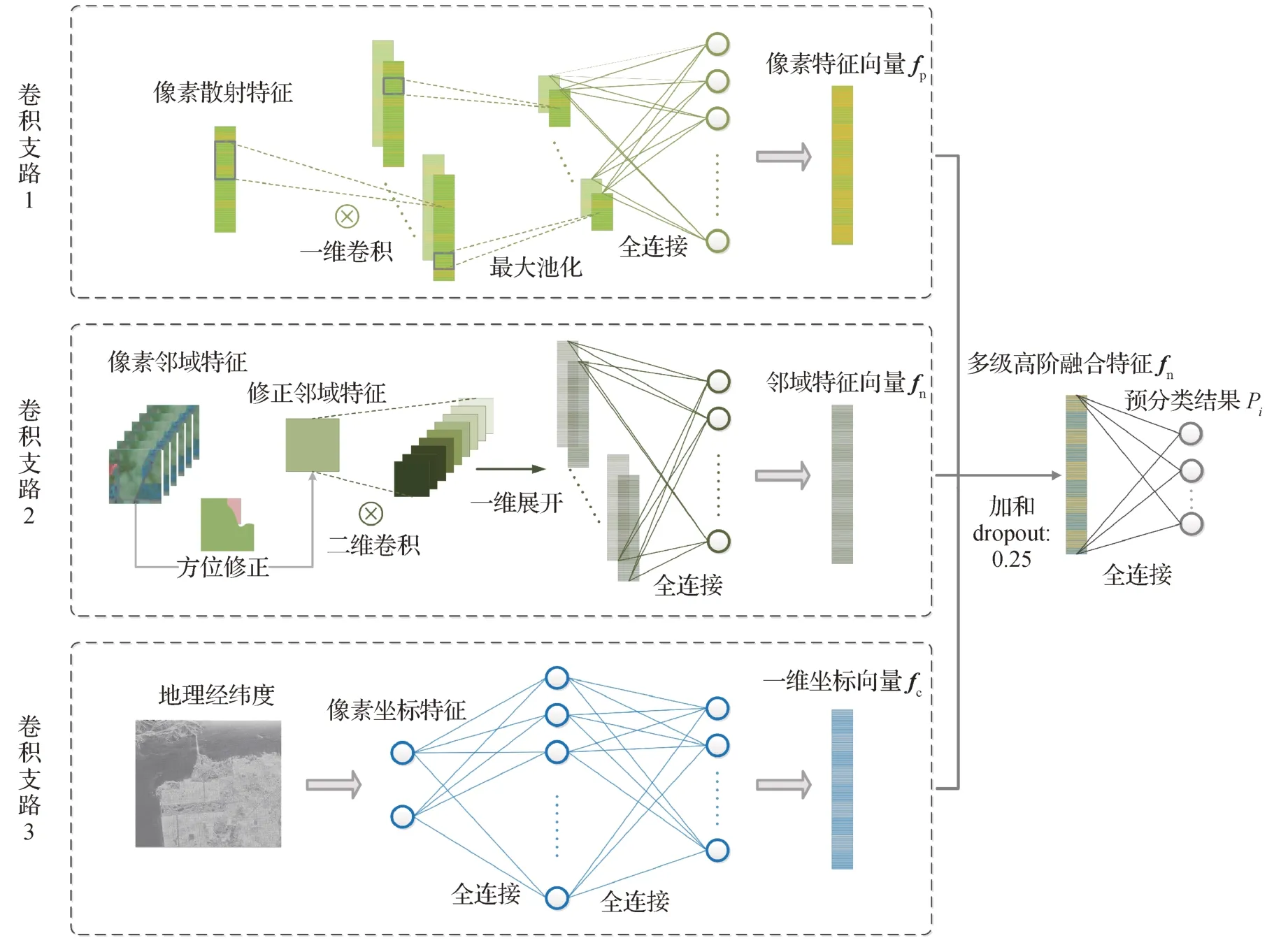
图2 高阶CRF多分支网络流程图Fig.2 Multi-branch feature extraction network
对应于CRF能量函数项,表达式示意为
式中,c 表示像素点k所在的基团,即方位修正像素块,xk和xm分别表示像素点k的特征向量和其所在像素块的平均特征向量,ωm和θm分别为权重系数和迭代参数。具体而言,像素的有效邻域信息即为所在基团,如图3 所示,红框表示中心像素,黑框内为其3 × 3的邻域区间,不同的颜色及对应序号表示不同的分割区域。
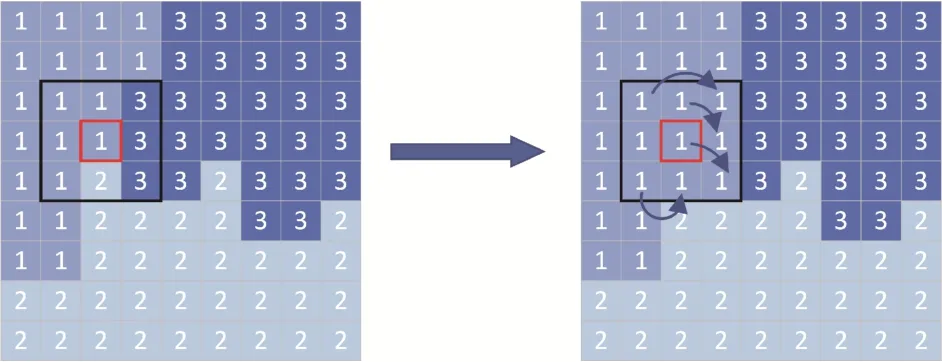
图3 方位修正像素块示意图Fig.3 Schematic diagram of azimuth correction pixel block
卷积模型通常以像素块作为输入,并利用该区域内的全部信息确定中心像素的最终类别。然而在大部分像素与中心像素属于不同类别的情况下,分类结果可能与真实类别存在误差。如图3 所示,中心点为“1”类,处于边界位置,其邻域不可避免地包含其他地物信息,无法准确表达原始类别特征。因此,本文引入了方位修正的概念。
对于分解后的散射特征,取每个分辨单元的3 × 3 邻域作为初始值,依据超像素分割结果,将与中心点不属于同一地物类型的像素特征值归零,并随机取中心像素所在的均质区域内像素点进行数据填充,如图3 右图所示。区别于传统的二维卷积输入,具有方位修正性的像素块可以将边界信息进行修正,避免不同地物目标之间边缘模糊的问题。
高阶势函数也建模为CNN 层,设计二维卷积神经网络用于提取修正后的邻域特征信息,如图2 中“卷积支路2”所示。利用像素块代替独立像素点进行信息交互,实现类似效果。在网络末端将3 种特征值进行加和融合,表达式为
式中,FC(⋅)表示全连接操作,Conv1d(⋅)表示一维卷积操作,Conv2d(⋅)表示二维卷积操作,fp,fc,fn,fh分别表示像素特征、坐标特征、邻域特征和多级高阶融合特征。最后,将多级高阶融合特征fh输入到softmax分类器中得到预分类结果。
1.3 超像素约束
尽管上述多分支提取模型可以学习到不同层次的空间特征,提供互补信息,但仍然不能进一步还原地物目标的局部结构。这是因为在CNN 的基础架构下,输入数据多为一维向量或规则矩阵,无法结合地物目标的不规则形态信息。而超像素能够灵活地适应目标边界,呈现更加详细的局部空间信息。为此,本文设计了超像素约束模块,对预分类结果进行对象级改进,以建立像素级数据和对象级数据间的尺度关联。具体步骤为:依据超像素的分割结果,计算每个最小超像素单元内所有像素点的后验概率均值,取分配概率最大的类别对预分类结果进行修正,鼓励连通区域的类别一致性。表达式为
式中,argmax{⋅}表示获取最大元素索引值的函数,mean[⋅]表示求取平均值操作,δ(⋅)表示类别判别模块,Si和Li分别表示第i个超像素集合及其类别标签,Pj(y|X)表示该超像素中第j个像素点的预分类概率值,L 为类别标签向量。由于PolSAR 数据与光学遥感图像之间存在显著的数据类型差别,为了更好地保留边缘信息,平衡过分割和欠分割,本文采用自适应—极化线性迭代聚类方法来生成超像素(Xiang等,2017)。
2 实验设计及结果分析
本节针对不同数据集设计了两组实验来评估不同采样策略下模型的分类性能,采用总精度、平均精度和Kappa 系数作为评估标准。考虑到网络不稳定性对分类结果的影响,将每个实验重复10 次,取平均值作为最终展示结果。
本文所有实验均在同一环境配置下进行。操作系统为Windows 10,Intel Core i7-10700K @3.80 GHz CPU,NVIDIA GeForce GTX 1080Ti GPU,Tensor-Flow2.0.0,Python3.6.9。
2.1 数据集介绍
为了验证本文方法的有效性,对两组极化SAR数据的分类结果进行了分析。
1)Flevoland 数据集,由美国航空航天局喷气推进实验室AIRSAR(AIRborne Synthetic Aperture Radar)系统于1989 年8 月在荷兰中部采集获得,广泛用于地物分类算法的性能评估。图4(a)展示了其伪彩色图,尺寸为750 × 1 024 像素。图4(b)为其对应的真值地物图,包含了11 种不同的土地覆盖类别,标记样本量总数为68 188。

图4 Flevoland数据集中的Pauli图像及标签图信息Fig.4 Pauli image and ground truth information of Flevoland dataset((a)Pauil RGB image;(b)ground truth map;(c)random sampling map;(d)spatial disjoint sampling map)
2)San Francisco 数据集,由NASA/JPL AIRSAR系统于美国获得的L波段数据,空间分辨率为10 m,由900 × 1 024 像素组成。图5(a)展示了其伪彩色图,图5(b)为其对应的真值地物图,共涵盖了5种不同的地物类别,标记样本量总数为830 536。

图5 San Francisco数据集中的Pauli图像及标签图信息Fig.5 Pauli image and ground truth information of San Francisco dataset((a)Pauil RGB image;(b)ground truth map;(c)random sampling map;(d)spatial disjoint sampling map)
2.2 采样策略
一些新的趋势表明(Paoletti 等,2019;Liang 等,2017),随机采样方法可能会使训练集和测试集的样本位置分布十分相似,如图4(c)和图4(b)所示,导致二者空间相邻像素之间出现高度相关性,使网络模型单纯地“记忆”分类方式,从而提高精度。出于模型泛化性考虑,这种情况的分类结果一定程度上并不能体现网络模型的真实分类性能(Hänsch 等,2017)。为此,本实验同时采用离散随机采样和空间不相交采样方法,从标记样本中抽取大约1%的数据作为训练样本,剩余数据为测试集,对两种实验结果进行对比分析。
对于空间不相交采样,取样方法为:在每类区域中随机初始化种子点,并依据采样率增长为1 个或多个离散矩阵,直至像素点总数等于该类别所需训练样本数。矩阵边长分别从[3,5,7,9]中随机选取。两种采样策略的训练集分别如图4(c)和图4(d)以及图5(c)和图5(d)所示。
2.3 实验方法
为了验证所提出算法的有效性,选取以下方法进行对比实验。1)二维卷积神经网络(CNN2D),主要由二维卷积函数和全连接函数组成(Chen 和Tao,2018);2)三维卷积神经网络(CNN3D),主要由三维卷积函数和全连接函数组成(Yang 等,2018);3)支持向量机(support vector machine,SVM),一种传统的机器学习方法(Zhang 等,2017);4)全卷积网络(fully convolutional network,FCN),采用卷积函数实现从图像像素到类别标签的变换(赵泉华 等,2020);5)CRF-NET,融合像素特征和坐标特征的双分支分类神经网络(Zhang 等,2021)。
对于使用线性核函数的SVM 算法,计算效率与支持向量数量n和特征维度d相关,浮点运算数(floating point operations,FLOPs)为N(d×n)。对于CNN2D、CNN3D、FCN、CRF-NET 以及高阶CRF 多分支网络模型这5 种深度学习方法,浮点运算数N主要由卷积层和全连接层的数量和参数决定(He 和Sun,2015),具体为
2.4 实验结果分析
2.4.1 基于Flevoland数据集的实验结果
针对应用最为广泛的Flevoland 数据集进行两种采样策略下的分类实验,并对不同的算法进行对比和分析。
1)随机采样。在随机采样条件下,具体精度结果及分类展示图分别如表3 和图6 所示。从表3 中的数据可知,在11 种类别中,除了“油菜籽”以外,本文方法均可以达到100%的分类准确率。其次,以“草地”为关注重点,对于没有引入坐标信息的CNN2D、CNN3D、SVM 和FCN,均无法将其正确分类,而本文方法在CRF-NET 的基础上又将精度进一步提升。进一步分析发现,尽管CRF-NET 也可以将总精度提升至99%以上,然而,由图6(g)及图6(h)对比可以看出,后者可以更好地将不同地物类别的特征分隔开来,形成明显的边界线并紧密聚类。同时,由表2中的时间复杂度可知,高阶CRF 模型并无明显增加运算成本,证明了此方法已经将分类精度和计算效率做出了较好平衡,可以在标记样本仅为1%的情况下实现高效地地物分类。

表2 算法复杂度对比Table 2 Comparison of algorithm complexity

表3 Flevoland数据集随机采样分类精度Table 3 The classification accuracy of random sampling on Flevoland dataset /%

图6 Flevoland数据集随机采样分类结果图Fig.6 The classification maps of random sampling on Flevoland dataset((a)Pauli RGB image;(b)ground truth map;(c)CNN2D;(d)CNN3D;(e)SVM;(f)FCN;(g)CRF-NET;(h)ours)
除去精度结果以外,训练效果也是评估分类性能的有效方式。图7 展示了不同算法的训练结果可视图,该图像通过t-SNE 降维工具(van der Maaten 和Hinton,2008)将模型提取到的最终高维特征值映射到二维空间而获得。从可视化结果图中能够看出,CRF-NET 和本文算法在不同类别特征之间均具有明显的可区分性,在有限且独立的邻域空间内高度聚集,且无颜色交叉的情况出现。进一步对比图7(e)(f),可以发现后者的特征空间分布则更为紧凑,表明本文算法的特征区分性能更好。而其他算法在特征提取过程中,不同类别之间具有明显的交杂现象出现,表示在这些网络模型的数据分析过程中,无法进行良好的特征区分,从表3 可以看出,这些算法的分类结果与CRF-NET 和本文方法相比,精度较低。

图7 Flevoland数据集随机采样训练结果可视图Fig.7 The viewable training results of random sampling on Flevoland dataset((a)CNN2D;(b)CNN3D;(c)SVM;(d)FCN;(e)CRF-NET;(f)ours)
图8 给出了所有神经网络模型的损失函数在Flevoland数据集中的变化情况。随着网络训练次数的不断增加,相较于只利用像素级特征和简单利用空间特征的CNN2D、CNN3D、SVM和FCN方法,本文算法明显加快了收敛速度。这表明,此方法在针对PolSAR 数据进行分级特征学习后,不同类别的特征表达能力及可区分性显著增强,证实了本文方法可以在标记样本匮乏的情况下有效减小过拟合风险,并提高网络模型的类别辨识度。

图8 Flevoland数据集随机采样损失函数变化图Fig.8 The loss function graph of random sampling on Flevoland dataset
2)空间不相交采样。在空间不相交采样条件下,具体分类结果如表4 所示。与随机采样相比,所有方法的分类精度均有所降低,但本文方法仍然保持97.54%的总精度,明显高于其他方法。与表3展示的均匀随机采样结果进行对比,可以看出在不相交采样情况下,由于样本中不携带如图4(c)所示的样本之间的空间相交信息,不同算法的分类精度均呈现明显下降,特别是在CRF-NET 中,总分类精度下降超过了14%。而本文算法在结合了方位修正信息及超像素空间约束后,分类精度只下降了约2%左右,能够在标记样本分布不均的情况下也保持较好的分类精度。

表4 Flevoland数据集空间不相交采样分类精度Table 4 The classification accuracy of spatially disjoint sampling on Flevoland dataset /%
图9 展示了不同方法对应的分类结果图,可以看出,本文方法的地物边界更加清晰,误分类情况更少,整体分类效果明显优于其他方法,且只有此方法可以将数据含量最少的“草地”完全正确分类。由图9(g)和图9(h)对比可以看出,在加入修正邻域信息和超像素特征约束后,不同地物目标之间的分类混杂现象得到了极大改善。

图9 Flevoland数据集空间不相交采样分类结果图Fig.9 The classification maps of spatially disjoint sampling on Flevoland dataset((a)Pauli RGB image;(b)ground truth map;(c)CNN2D;(d)CNN3D;(e)SVM;(f)FCN;(g)CRF-NET;(h)ours )
图10 展示了损失函数变化图,与图8 进行对比可以看出,尽管CRF-NET 在随机采样条件下能够获得较好的网络收敛效果,但是在不相交采样策略中,由于样本的空间分布不均衡,导致CRF-NET 网络的收敛明显变弱,同时也增加了不稳定因素。而本文算法在多级特征相互学习的情况下,并没有受到样本空间因素的制约,依然保持着稳定的收敛速度。

图10 Flevoland数据集空间不相交采样损失函数变化图Fig.10 The loss function graph of spatially disjoint sampling on Flevoland dataset
2.4.2 基于San Francisco数据集的实验结果
第2个实验分析了San Francisco地区的数据,作为对比实验增加结果可靠性。
1)随机采样。随机采样条件下的具体分类精度及结果展示图分别如表5和图11所示。

表5 San Francisco数据集随机采样分类精度Table 5 The classification accuracy of random sampling on San Francisco dataset /%

图11 San Francisco数据集随机采样分类结果图Fig.11 The classification maps of random sampling on San Francisco dataset((a)Pauli RGB image;(b)ground truth map;(c)CNN2D;(d)CNN3D;(e)SVM;(f)FCN;(g)CRF-NET;(h)ours )
对比2.4.1 节的实验,分析表5 中的数据可知,在样本含量更多的San Francisco 数据集上,每种方法的分类效果均有下降。所有对比算法的总精度均降低9%以上,其中,FCN总精度降低率高达24%,而本文方法的总精度保持在98%以上,展现出良好的模型泛化能力。在3 种“城市”类型中,未融入坐标特征信息的CNN2D、CNN3D、SVM 和FCN 方法均无法很好地将“密集城市”、“发达地区”和“非密集城市”这3 种相似类别区分开,且非密集城市的分类效果最差,精度均不高于10%。
对应图11(c)—(f),可以看出类间错分现象十分严重。而本文方法在CRF-NET 的基础上进一步提升了模型辨别能力,将最难区分的“非密集城市”类别精度提高了10%,增加到了91.34%。同时,由图11(g)(h)对比可得,本文方法的分类结果地物边界线更加准确,形态轮廓更加清晰。
图12 展示了Sanfrancisco 数据集在随机采样下的训练结果可视图,由图12(e)与图12(a)—(d)的对比可以看出,CRF-NET 已经将同类型特征进行了有效聚合。在此基础上,由图12(f)可以观察到,本文方法进一步优化了聚合程度,使得不同类型特征之间几乎没有重叠。

图12 San Francisco数据集随机采样训练结果可视图Fig.12 The viewable training results of random sampling on San Francisco dataset((a)CNN2D;(b)CNN3D;(c)SVM;(d)FCN;(e)CRF-NET;(f)ours)
图13 展示了随机采样条件下不同神经网络模型的损失函数变化图。由图中可以看出,本文算法的损失函数平稳下降,在不同数据集上展示出优秀的泛化能力。同时,观察CNN2D、CNN3D 和FCN 方法的曲线变化趋势可以看出,这3 种算法的损失函数值下降缓慢,在网络迭代次数为200时依旧在0.5以上,出现了因提取信息过于片面、无法充分学习类别特征而导致的网络参数难以调优的问题。与此同时,CRF-NET 与本文方法均可以将损失函数降低至0.2 左右,且后者的网络收敛程度更高、下降速度更快,证明了多级空间特征的融合可以有效增强网络模型对不同类型特征的感知能力,进一步提高数据可分性。
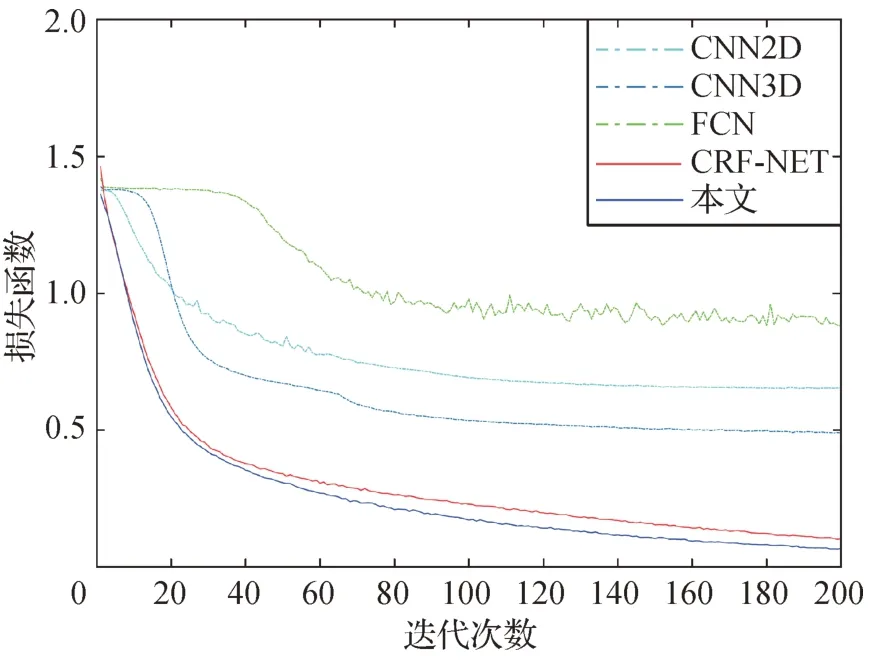
图13 San Francisco数据集随机采样损失函数变化图Fig.13 The loss function graph of random sampling on San Francisco dataset
2)空间不相交采样。在空间不相交采样情况下,分类精度结果如表6 所示。由表5 和表6 比较可得,对于San Francisco 数据集,两种采样策略对于分类结果影响较小,所有方法的总精度变化范围均在5%以下。其中,只有SVM 的精度变化呈略微上升状态,其余方法均存在不同程度的精度下降。结合2.4.1 节的实验结果可知,空间不相交采样方式对于深度神经网络影响较大,而对于以SVM 代表的传统机器学习方式则影响较小。
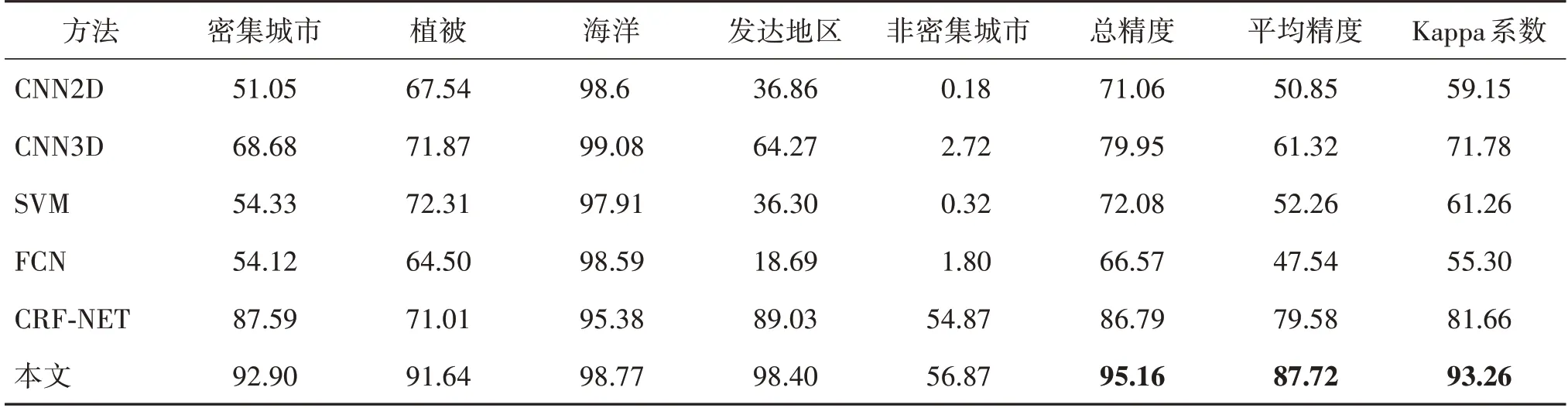
表6 San Francisco数据集空间不相交采样分类精度Table 6 The classification accuracy of spatially disjoint sampling on San Francisco dataset /%
3 结论
本文针对PolSAR 小样本分类中的类块间边界模糊和类块内噪声问题,提出一种多分支PolSAR 分类的深层网络模型。该方法受高阶CRF 一元势、二元势和高阶势联合优化的启发,分别针对像素极化特征、全局空间特征和邻域空间特征设计了卷积分支进行特征学习,通过多特征联合学习以提升模型的小样本分类性能。此外,为了进一步优化分类效果,在后处理阶段引入超像素约束模块用于划分异构区域边界,将同一地物类型的匀质区域进行类别统一,有效建立了像素级和对象级数据间的尺度关联。
为了进一步限制空间先验信息的引入,在实验环节增加了空间不相交采样方式进行训练样本选择,并与包含一定空间先验信息的随机采样方式进行对比分析。实验结果表明,融合极化特征和多种空间特征的高阶CRF 模型可以更好地区分地物散射组成,极大提高了类别感知度。相较于只利用像素级特征或简单利用空间特征的网络模型,能够从不同的角度提供互补特征,进一步克服了地物目标空间形态信息丢失和边缘轮廓变形的问题。但是,本文实验结果仅针对Flevoland 数据集和San Francisco 数据集进行分析,存在一定的片面性,网络模型的迁移性有待考量,后续将考虑结合因果学习方法构建更加稳健的鉴别性特征,开展跨场景分类研究,进一步丰富PolSAR分类技术的应用场景。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
CHIP新电脑(2016年3期)2016-03-10 14:22:03
新校长(2016年8期)2016-01-10 06:43:59
天津师范大学学报(自然科学版)(2015年2期)2015-03-11 18:46:50
商事法论集(2014年1期)2014-06-27 01:20:42
