
引入分组注意力的医学图像分割模型
2023-10-24 13:58:22张学峰张胜张冬晖刘瑞
中国图象图形学报 2023年10期
张学峰,张胜,张冬晖,刘瑞
南昌航空大学信息工程学院,南昌 330063
0 引言
随着卷积神经网络(convolutional neural network,CNN)在计算机视觉领域(Dhruv 和 Naskar,2020)和医学图像处理领域的广泛应用,深度学习已经成为医学图像分割任务中的主流方法,并促进了医学图像分割技术的发展。这种端到端的精确分割结果能够在医疗诊断中为医生提供辅助依据,有效地减少因医生个人水平差异对诊断结果所带来的主观影响,且在日常工作中,医院产生的医学图像数据是巨大的,而自动医学图像分割技术能够有效地减轻医生的工作负担。因此,具有十分重要的研究意义和价值。
医学图像分割方法主要采用具有U型结构的全卷积神经网络(Ronneberger 等,2015;Milletari 等,2016)。最典型的是U-Net(Ronneberger 等,2015),它主要由对称的编码器—解码器以及中间的跳跃连接组成。在编码器部分,通过一系列的卷积和连续下采样层来对输入图像进行深层的特征提取。解码器部分则通过上采样操作,将提取的深层特征图的分辨率提升到与输入图像相同的层次来进行像素级的语义预测,同时将来自编码器不同尺度的特征图通过跳跃连接与解码器的特征进行融合,以此来减少下采样带来的空间信息的丢失。凭借着这种优雅的结构设计,U-Net在各种医学图像分割任务中取得了巨大成功。基于U-Net 架构,研究人员提出了许多算法,如nnU-Net(Isensee 等,2021)、Res_UNet(Xiao 等,2018)、U-Net++(Zhou 等,2018)、U-Net3+(Huang等,2020)、3D U-Net(Çiçek等,2016)等,并表现出了更加出色的性能和分割结果,同时也证明了CNN 具有很强的特征学习能力。尽管如此,基于CNN 的方法依然无法满足医学应用对于分割精度的严格要求。这主要是由于卷积操作本身的局部性,而使其在建立全局和远程语义信息依赖关系中存在局限性(Cao 等,2023)。为解决这个问题,一些研究人员采取了各种措施,如扩张卷积(Gu 等,2019)、金字塔池化(Zhao 等,2017)、自注意力机制(Schlemper 等,2019;Wang 等,2018)等,尽管这些策略能够在一定程度上缓解这种局限性带来的影响,但依然无法解决这一问题。
由于Transformer(Vaswani 等,2017)在自然语言处理(natural language processing,NLP)领域取得了巨大成功,研究人员开始尝试将Transformer 引入计算机视觉领域,Dosovitskiy 等人(2020)提出了VIT(vision Transformer),通过将2D 图像转化为1D 图像序列,使其能够在全局范围建立图像特征间的依赖关系,并在图像识别任务中,获得了与CNN 相当的性能表现,但其计算复杂度较高,且需要进行大规模的预训练。为解决这一问题,Liu等人(2021)提出了一种高效的分层视觉转换器 Swin Transformer,对图像采用分层设计和移动窗口操作,在不需要大规模预训练的同时,降低了计算复杂度,并以此为网络主干,在图像分类、目标检测和语义分割等任务中取得了当时最佳的性能表现。在此基础上,一些研究者开始将VIT或Swin Transformer应用于医学图像分割领域,并提出了各种分割模型,取得了超过CNN 的分割结果,但由于Transformer 这种对图像的序列化操作方式,导致其过多地关注全局特征,而一定程度上忽略了局部像素通道间信息交互的重要性。
为此,本文提出了一种基于分组注意力的医学图像分割方法GAU-Net。网络整体为U-Net架构,使用ResNet 作为编码器主干网络进行特征下采样,并在每个编码层下串联本文提出的分组注意力模块。此分组注意力模块主要由局部注意力子模块、全局注意力子模块和特征融合单元3 部分组成。编码层的输出特征在输入分组注意力模块前,首先在通道方向上对其进行分组,然后并行输入到分组注意力模块中进行局部和全局注意力计算以及特征融合,再将融合后特征输入到下一层编码层,进行进一步特征提取。最后将编码器输出的高层次特征送入解码器,使用连续的上采样操作恢复图像的分辨率。通过上述结构设计后,GAU-Net能够同时实现对局部和全局重要特征信息的获取和交互,使得网络提取的特征信息更加丰富、多样,从而提高模型的分割效果。
本文主要贡献如下:1)提出一种能够同时获取全局和局部重要特征的分组注意力模块,基于Swin Transformer 和CNN 分别构建模块中的全局注意力子模块和局部注意力子模块,对输入特征分别进行全局注意力和局部注意力计算,然后将经过注意力子模块处理后的特征通过一个残差单元进行特征融合,使网络获取的特征信息更全面且更有针对性。2)采取一种有别于以往方法的注意力操作方式。现有方法的注意力操作均在特征的全通道上进行,此方式无法充分获取图像中的重要特征,且易出现计算冗余。为此,采用特征分组方式进行注意力计算,将输入特征在通道维度上进行分组,然后对分组后的特征分别进行不同的注意力操作,进一步丰富了特征中包含的语义信息,使得网络获取的特征信息更具有多样性。
1 相关工作
1.1 基于卷积神经网络的注意力机制
注意力机制在医学图像分割领域的使用愈加广泛,它使得网络能够更加关注与任务相关的重要特征,减少不必要信息对结果的影响。如Hu 等人(2020)提出了压缩激励网络(squeeze and excitation networks,SENet),通过信息的压缩激励对每个通道的权重进行调整,以此增大网络对目标区域的关注度,从而增强网络的特征提取能力,提升最终的分割效果。而瓶颈注意力模型(bottleneck attention module,BAM)(Park 等,2018)和卷积块注意力模块(convolutional block attention module,CBAM)(Woo等,2018)通过融合特征图的空间信息和通道信息,获得了更好的目标识别能力。Li等人(2022)提出了一种边缘信息增强的注意力模块(contour enhanced attention module,CEAM),通过捕获具有位置感知的跨通道信息及更加明确的边缘轮廓信息,提高了分割的准确性。郝晓宇等人(2020)以3D U-Net 为基础结构,将每两个相邻的卷积层替换为残差结构,并在上采样和下采样路径之间添加了并联的位置注意力模块和通道注意力模块,有效提升了肺肿瘤的分割精度。
1.2 基于Transformer的医学图像分割方法
Transformer 在医学图像分割领域的应用主要有两种方式。
1)混合Transformer 模型。Chen 等人(2021)通过将U-Net 网络中编码器的最后一层卷积层替换为VIT,提出了第1 个基于Transformer 的医学图像分割框架TransUNet,并将其用于2D 医学图像分割。Zhang 等人(2021)提出一种并行分支结构Trans-Fuse,通过在网络中构建基于Transformer 和基于CNN 的双编码器来捕获全局依赖性和低级空间特征。Lin等人(2022)提出了一种新型的多尺度架构,在其中构建了跨尺度的全局Transformer和用于边界感知的局部Transformer,将医学图像分割划分成了由粗到细的过程,取得了较好性能表现。Li 等人(2022)提出了一种视觉语言医学图像分割模型(language meets vision Transformer,LviT),模型是由U 形CNN 分支和U 形VIT 分支组成的双U 结构,通过引入医学文本注释来弥补图像数据中的缺陷,并在全监督和半监督条件下都取得了很好的分割结果。
2)纯Transformer 模型。Cao 等人(2023)提出基于Swin Transformer 的分割模型SwinUNet,展示了纯Transformer 在医学图像分割方面的潜力。在此基础上,Huang 等人(2021)提出了一个分层编解码网络MissTransformer,通过对Transformer 块以及跳跃连接方式的重新设计,使网络获得了更佳的分割能力。但上述工作主要集中在使用Transformer层替换卷积层或将两者按顺序堆叠,未能充分发挥CNN 和Transformer在医学图像分割方面的潜力。
2 GAU-Net
2.1 模型简介
GAU-Net(group attention network)整体结构如图1 所示,主要由编码器、解码器和中间的跳跃连接3部分组成。编码器部分包括特征提取层和分组注意力层,即图中ResNet_Stagei(i=1,2,…,5)和GA modulei(i=1,…,4),其中特征提取层用于自上而下对输入图像进行特征提取,分组注意力层则对上层网络提取的特征进行分组注意力操作,加强网络对重要特征的关注。解码器则采用双线性插值对编码器提取的最终特征进行特征分辨率恢复,并在解码过程中,对相同尺度的特征图,通过跳跃连接将编码器提取的特征和解码器获取的特征进行多尺度特征融合,最终输出想要的分割特征图。

图1 GAU-Net整体结构示意图Fig.1 Schematic diagram of the overall structure of GAU-Net
2.2 分组注意力模块(GA module)
分组注意力模块(group attention module,GA module)结构如图2 所示,主要由3 部分组成。1)基于卷积操作的像素通道注意力和空间注意力的混合注意力子模块;2)基于Swin Transformer 的注意力子模块;3)特征融合单元,即图中ResConv。其中,为ResNet_Stagei输出的特征图,按照通道维度将特征图Xi划分成两组,即和
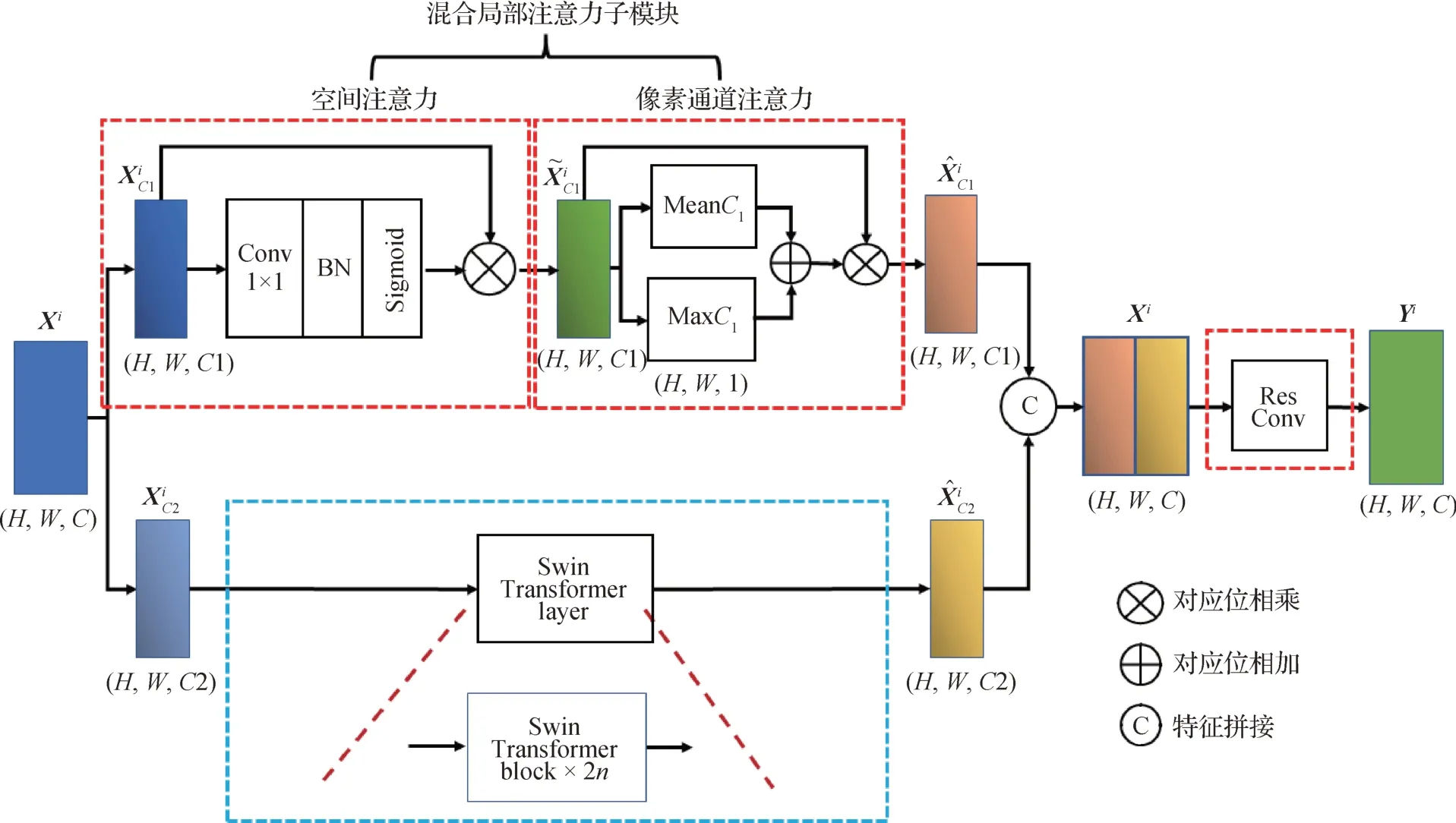
图2 GA module结构示意图Fig.2 Schematic diagram of the structure of the GA module
1)混合注意力子模块。如图2上方方框所示,由空间注意力和像素通道注意力两部分组成,这两部分可以进行串联或并联组合,而相较于并联结构对输入特征分别独立进行空间和像素通道注意力计算,串联结构更能有效加强对重要信息的提取与交互,同时实际测试中也证明了串联结构比并联更加有效。
式中,Conv1×1是1 × 1 准卷积;BN(batch normalization)是批归一化操作;fSigmoid是非线性激活函数,将特征图中数值映射到0~1,作为空间注意力权重。和分别是空间注意力和像素通道注意力的输出特征。
然后,在每个像素通道维度上进行通道注意力计算,得到输出特征,计算过程为
式中,MeanC1、MaxC1分别表示在特征图每个像素通道维度上计算平均值和最大值。
式中,fDim_div和fDim_rec分别表示维度划分和维度恢复,fSwin_attnC2表示经过Swin Transformer 层进行全局注意力计算。
图2中Swin Transformer 层的基本单元为两个连续的Swin Transformer block,结构如图3所示。

图3 Swin Transformer层基本单元结构示意图Fig.3 Schematic diagram of the basic unit structure of Swin Transformer layer
GAU-Net 中基本单元的数目由参数n进行控制。与VIT 的多头注意力不同,Swin Transformer 是基于滑动窗口构建,相较于VIT,其计算复杂度大大降低。每个基本单元由LN(layernorm)层、基于窗口多头注意力模块(window-based multi-head selfattention,W-MSA)、基于滑动窗口的多头注意力模块(shifted window multi-head self-attention,SWMSA)、残差连接和两层多层感知机(multi-layer perceptron,MLP)组成,其计算式为
式中,fsoftmax为归一化函数,Q、K、V∈表示查询矩阵、键矩阵和值矩阵,M和d分别为窗口中的patch的数量以及Q 或K 的维度。B 矩阵中的值则是来自于偏置矩阵∈R(2M-1)×(2M+1)。
3)特征融合单元。如图2 右侧方框所示,经过上述两个注意力子模块处理后将得到的两组特征和,为进行下一阶段特征提取,需要将其在通道维度进行特征拼接,以此保持与输入特征相同的特征维度,并采用一个残差单元作为特征融合单元,对拼接后的特征进行特征融合,最后得到输出特征,计算过程为
式中,cat表示将特征和在通道维度上进行拼接,fResConv则表示用于特征融合的残差单元。
2.3 解码器以及跳跃连接
解码器采用双线性插值进行特征分辨率恢复,与U-Net 类似,在上采样过程中,通过跳跃连接将编码器中得到的不同尺度特征与上采样中同尺度特征进行特征融合,如图1 中skip 1/4、skip 1/8、skip 1/16所示,以此减少下采样过程中带来的空间信息的丢失。
3 实验结果与分析
3.1 实验数据集
1)Synapse 多器官分割数据集。此数据集包括30例共3 779幅轴向腹部临床CT(computed tomography)图像。将18个样本作为训练集,12个样本作为测试集。数据集对8 个腹部器官进行了标注,即主动脉(aorta)、胆囊(gallbladder)、脾脏(spleen)、左肾(kidney(L)、右肾(kidney(R)、肝脏(liver)、胰腺(pancreas)、胃(stomach)。
2)心脏自动诊断挑战数据集(automated cardiac diagnosis challenge,ACDC)。此数据集使用MRI(magnetic resonance imaging)扫描仪从不同患者处收集得到。针对每个患者的图像,对左心室(left ventical,LV)、右心室(right ventrical,RV)和心肌(myocardium,MYO)进行了标注。数据集包括70个训练样本、10个验证样本和20个测试样本。
3.2 实验参数设置
本网络模型基于python3.8 和pytorch1.9 实现。对所有的训练样本使用随机翻转和旋转等方式进行数据增强。输入图像尺寸为224 × 224 像素。在两张分别具有11 GB 内存的Nvidia 1080ti GPU 上训练本文模型。训练参数设置为:epoch为150,batch size为16,初始学习率为0.15,使用SGD(stochastic gradient descent)优化器(动量为0.9,权重衰减10-5)来优化反向传播模型。
3.3 评价指标
采用Dice 相似系数(Dice similarity coefficient,DSC)和Hausdorff 距离(Hausdorff distance,HD)作为评价指标,对当前模型的性能优劣进行评估。DSC对图像分割像素的内部填充有较强的约束性,而HD对分割的边界有更高的敏感度,因此,将两者结合使用,有助于获得更精确的分割结果。
3.4 实验结果分析
3.4.1 Synapse多器官数据集上的实验结果与分析
1)分割结果分析。DSC 与HD GAU-Net 在Synapse多器官CT数据集上的相关对比实验结果如表1所示。可以看出,整体上,GAU-Net相较于其他方法取得了最佳的分割结果,DSC 和HD 分别为82.93%和12.32%。与MISSFormer方法相比,在DSC评估指标上取得了0.97%的提升,而在HD评估指标上减少了5.88%。但在单个器官分割上,本文方法在胆囊、左肾、右肾、肝脏和胃等器官分割精度上实现了最优,在主动脉分割上Att-UNet最优,为89.55%(DSC),高于本文方法0.91%,而在胰腺和脾脏分割上,则MISSFormer 最佳,分别为65.67%(DSC)和91.92%(DSC),高于本文方法0.63%和1.51%,说明本文方法在小器官和边缘复杂的器官分割上略有不足。

表1 不同方法在Synapse多器官CT数据集上的分割精度Table 1 Segmentation accuracy of different methods on the Synapse multi-organ CT dataset /%
2)模型分割实例分析。不同方法在Synapse 多器官CT 数据集上的分割结果实例如图4 所示,从最终分割效果可以看出,与MISSFormer、SwinUNet 和TransUNet等方法的分割结果相比,本文方法的分割结果更接近人工标注结果。其中图4(c)(d)分别为MISSFormer 和SwinUNet 的分割实例,两者均为纯Transformer网络,在特征提取过程中,由于SwinUNet过多的关注特征的全局信息问题,导致其忽略了特征间的局部依赖关系,而MISSFormer 通过其独特的设计,使得模型能够在编解码过程中进行局部上下文信息的补充,但其却忽略了特征通道间以及像素通道间信息交互的重要性。而图4(e)则为TransUNet 的分割实例,TransUNet 是结合VIT 和CNN 的混合网络,其只在编码器的最后阶段使用VIT 对全局特征进行建模,未考虑前期特征提取过程中全局特征信息的重要性。由于以上原因,导致它们存在较明显的欠分割和过分割问题。

图4 不同方法在Synapse多器官CT数据集上的分割结果Fig.4 Segmentation results of different methods on the Synapse multi-organ CT dataset((a)ground truth;(b)GAU-Net;(c)MISSFormer;(d)SwinUNet;(e)TransUNet)
3)模型训练过程Loss的收敛情况分析。模型训练过程中的Loss 曲线如图5 所示。可以看出,在收敛速度上,GAU-Net 和SwinUNet 相当,但优于TransUNet 和MISSFormer。而模型收敛时达到的Loss值,GAU-Net 均低于对比方法,具有较好的收敛状态。
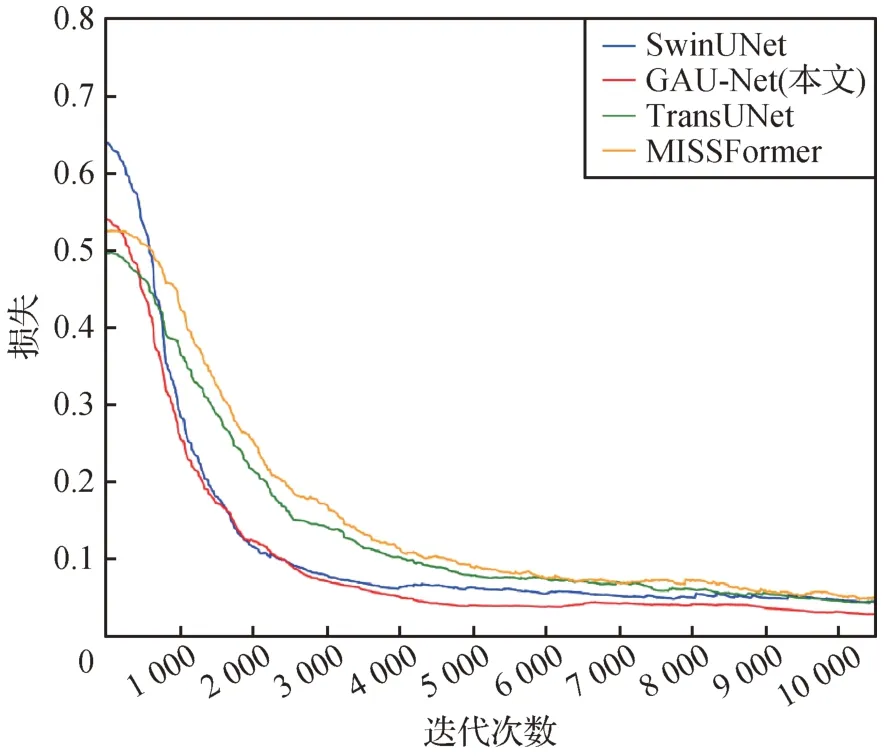
图5 Loss曲线Fig.5 Loss curve
4)模型推理时间和占用内存分析。GAU-Net和对比方法对单幅图像的推理时间(inference time)和内存占用(memory)情况如表2所示。数据均在相同实验条件下,使用相同方法获得。从表2 中可以看出,SwinUNet 表现最佳,其训练过程中单幅图像推理时间为12.44 ms,内存占用为166.86 M。但对于医学图像分割来说,分割精度是评判模型效果的一项关键指标,且每一点的分割精度的提升都具有重大的意义。因此,GAU-Net 在没有较大幅度增加模型推理时间以及内存占用的前提下,以此获取更好的分割精度性能提升是值得的。但同时本文模型也需要进一步改进,使其能够在不损失分割精度的同时,尽可能降低对计算资源的消耗。

表2 不同模型的推理时间和占用内存的比较Table 2 Comparison of inference time and memory usage of different models
3.4.2 ACDC数据集上的实验结果与分析
GAU-Net 在ACDC 数据集上相关对比实验结果如表3 所示。从表3 中可以看出,在单个器官分割上,GAU-Net 在右心室和心肌两个器官上取得了优于其他方法的分割精度,分别为91.07%(DSC)和88.49%(DSC),在左心室分割上,SwinUnet取得了最佳分割精度,为95.83%(DSC),高于本文方法1.46%。但在整体分割精度上,GAU-Net 表现仍取得了最佳结果,为91.34%(DSC),高于目前先进方法MISSFormer 0.48%(DSC)。

表3 不同方法在ACDC数据集上的分割精度Table 3 Segmentation accuracy of different methods on the ACDC dataset /%
此外,将GAU-Net 在ACDC 数据集的实验结果与ACDC 数据集网络排名前3 的方法进行比较(数据来源https://acdc.creatis.insa-lyon.fr),如表4 所示。3 个单器官分割中,本文方法在右心室和右心室分割排名中均位于第1,仅在心肌分割排名中排名第4,且相较于排名第1 的方法相差3.8%。说明本文方法具备一定的先进性和竞争力。
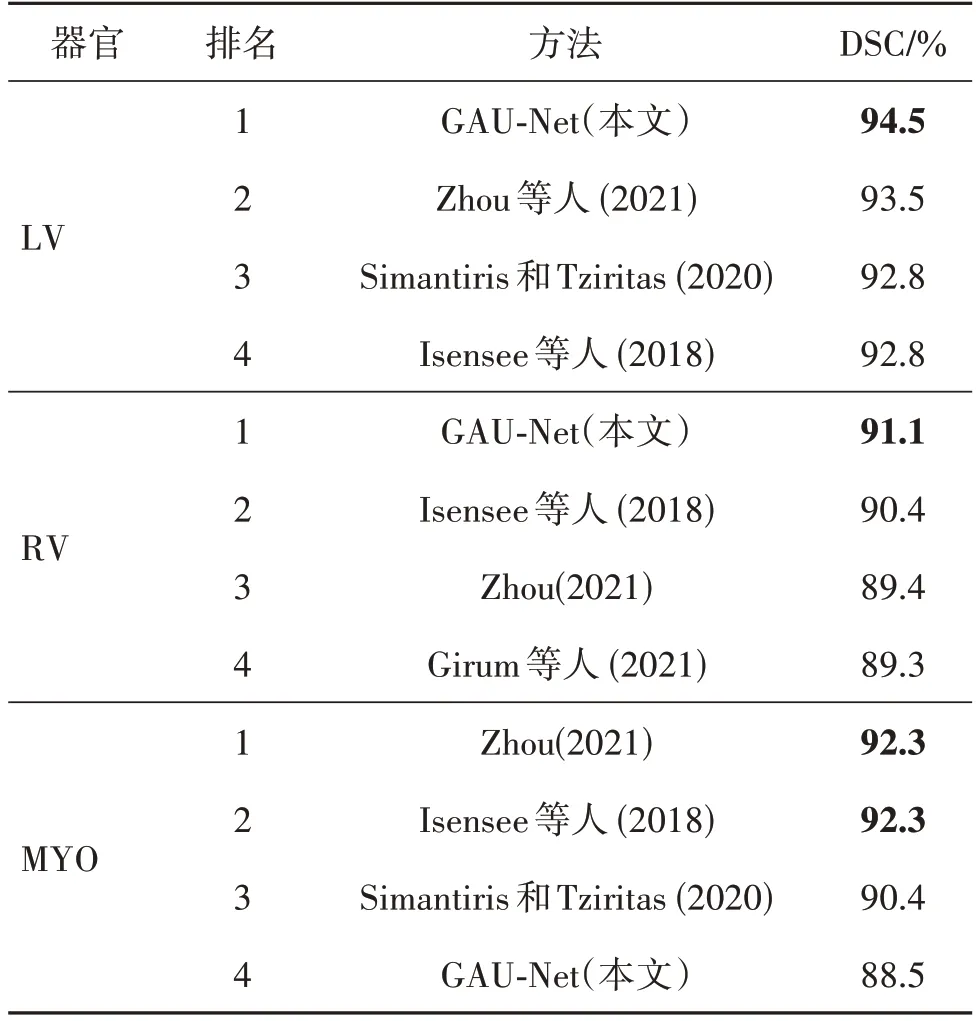
表4 ACDC数据集网络排名比较Table 4 Comparison of network rankings on ACDC dataset
3.5 消融实验
为了探究不同因素对模型性能的影响,通过控制变量的方式,在Synapse数据集上进行了相关的消融实验。实验内容主要包括:1)不同ResNet_Stage数量的影响;2)分组注意力模块中各组件的影响;3)不同特征通道划分数量的影响;4)跳跃连接数量的影响;5)Swin Transformer block数量的影响。
3.5.1 各层ResNet_Stage中残差单元数量的影响
本文模型的特征提取主干网络为ResNet50,其各特征提取层的残差单元数设置为[3,4,6,3],为探究各层不同的残差单元数配置方案对模型性能的影响,对此进行了3 组实验,将图1 中ResNet_Stage 2—5 的残差单元数分别设置为[2,2,4,2]、[4,4,4,4]、[3,6,8,3]。实验结果如表5所示,此3组残差单元数配置方案导致分割精度分别下降了4.81%、2.78%、1.72%。因此,为保证获得最佳的分割性能,选择[3,4,6,3]作为主干网络中ResNet_Stage 2—5的残差单元数配置方案。
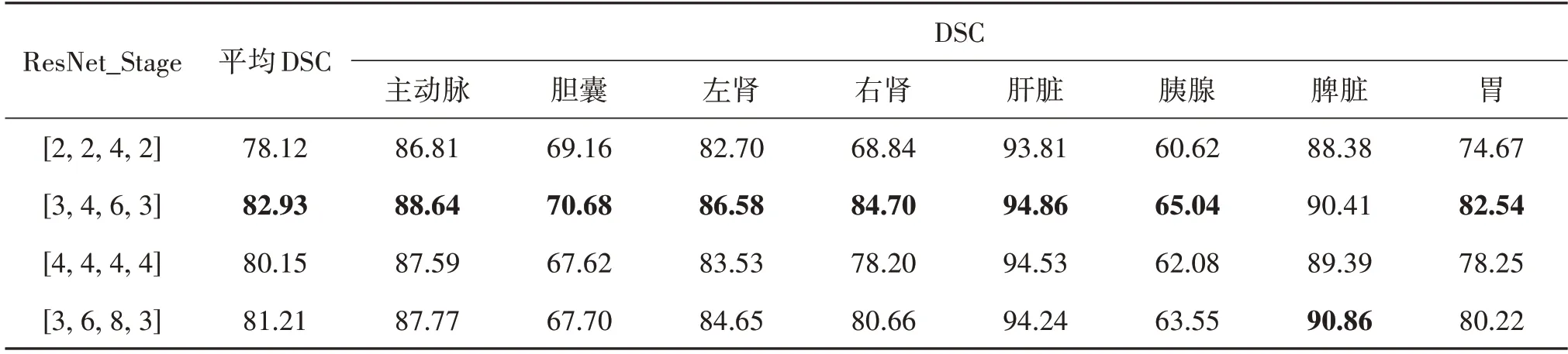
表5 各层ResNet_Stage中残差单元数量的影响Table 5 Influence of the number of residual units in ResNet_Stage at each layer /%
3.5.2 分组注意力模块中各组件的影响
本文在编码中设计了分组注意力模块,此模块由3 部分子模块组成,为探究各子模块对网络性能的影响,本文对此进行了3 组实验。1)混合注意力子模块的影响(No_FuseAttn);2)基于Swin Transformer 的注意力子模块的影响(No_SwinAttn);3)特征融合子模块的影响(No_Fuse)。如表6 所示,去除各子模块后网络性能分别下降了2.41%、0.93%和0.38%。其中混合注意力子模块对网络性能的影响最大。此实验结果验证了本文设计的分组注意力模块的合理性和有效性。
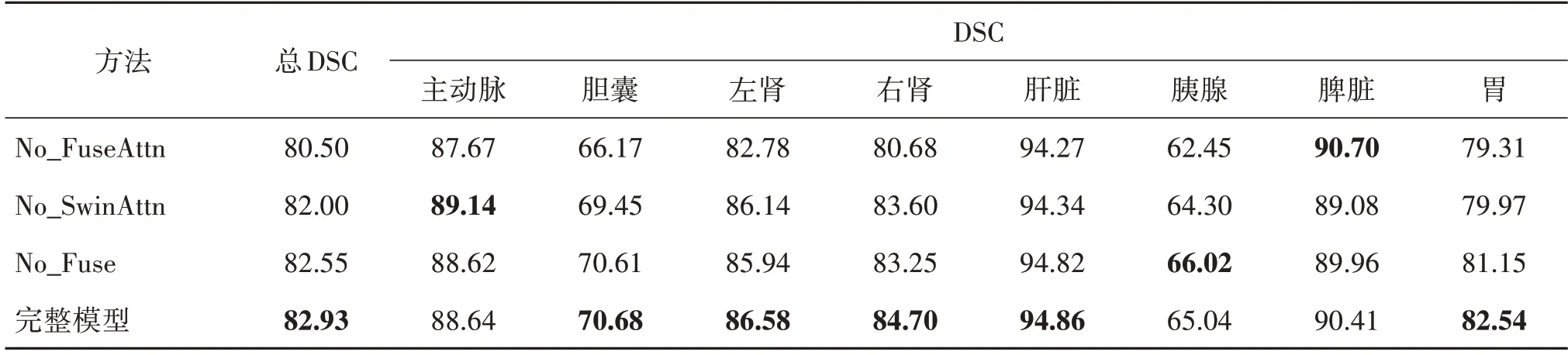
表6 分组注意力模块中各组件对网络性能影响的消融实验Table 6 Ablation experiments on the effect of each component in the grouped attention module on network performance /%
3.5.3 不同特征通道划分数量的影响
上层特征在输入分组注意力模块前,会先按通道划分为不同通道数的两组特征,然后分别送入分组注意力模块的两个并行注意力路径中,为探索特征通道数划分的比例不同对分割精确度的影响,本文对此进行了相关实验,如表7 所示。表7 中,C1、C2对应通道数是以ResNet_Stage2为例,此层特征通道数为256,后面网络层特征通道总数以及对应通道划分数量均为上一网络层对应通道数量的2 倍。从表7 中可以看出,当按1∶1 划分通道数时,模型分割精确度达到最高,因此,本文模型采用1∶1 比例对特征通道进行划分。

表7 特征通道数划分比例对网络性能影响的消融实验Table 7 Ablation experiments on the effect of feature channel number division ratio on network performance /%
3.5.4 跳跃连接数量的影响
GAU-Net在编解码器之间建立的跳跃连接的特征分辨率比例分别为1/4、1/8、1/16,通过将跳跃连接数分别设置为0、1、2和3,探究了不同跳跃连接对模型分割精确度的影响。如表8所示,可以看到,模型的分割精确度与跳跃连接的数量成正比例关系。因此,为提高最终的分割精确度,本文将跳跃连接数设置为3。

表8 跳跃连接数量对网络性能影响的消融实验Table 8 Ablation experiments on the effect of the number of skip connections on network performance /%
3.5.5 Swin Transformer block数量的影响
提出的分组注意力模块中,将两个连续的Swin Transformer block 作为其中一个注意力分支的基本单元,为探究Swin Transformer block 数量,即图2中n的设定对模型性能的影响,将其中Swin Transformer层中Swin Transformer block 的数量按照网络层次分别设置为[2,2,2,2]、[2,4,4,2]、[2,4,4,4]、[4,4,4,4]。实验结果如表9 所示,当将Swin Transformer block 数量设为[2,4,4,2]时,网络分割性能表现最佳。因此,本文考虑将[2,4,4,4,2]作为Swin Transformer block 数量的最终设定,以此获得更好的分割效果。
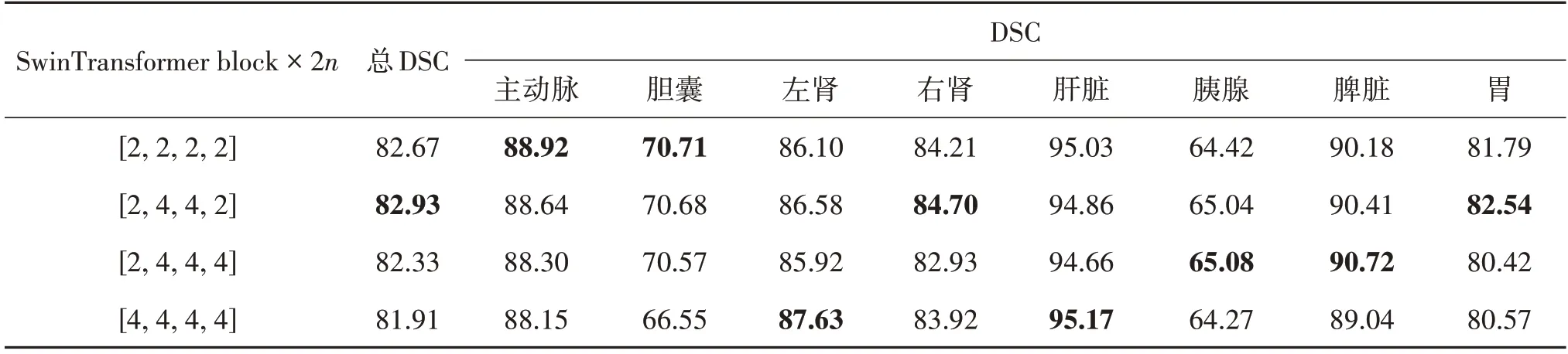
表9 Swin Transformer block 数量对网络性能影响的消融实验Table 9 Ablation experiments on the effect of the number of Swin Transformer blocks on network performance /%
4 结论
本文提出了一种基于分组注意力的医学图像分割模型。通过并行融合Swin Transformer 和CNN 的方式构建了一种分组注意力模块,并将其加入到下采样路径中的各编码层后,有效地增强了模型对局部和全局重要特征的提取能力。此外,在各编码层输出特征进入分组注意力模块前,先对其进行特征分组处理,以此减少计算信息冗余,进一步提升模型的分割性能。在Synapse 数据集和ACDC 数据集上进行了相关实验,GAU-Net 取得的实验结果均优于SwinUNet、MISSFormer等现有方法,能够更有效地完成医学图像分割任务。但本文方法在小目标分割上还略有不足,主要是因为在特征分组处理上尚未制定相关的分组规则,从而导致一定程度上的特征匹配不均衡和信息丢失问题,对此将在后续工作中进行进一步研究和改进,增强模型对精细结构的感知能力。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
传媒评论(2017年3期)2017-06-13 09:18:10
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
电子设计工程(2017年20期)2017-02-10 03:39:29
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
