
双编码特征注意网络的手术器械分割
2023-10-24 13:58:20杨磊谷玉格边桂彬刘艳红
中国图象图形学报 2023年10期
杨磊,谷玉格,边桂彬,2,刘艳红*
1.郑州大学电气与信息工程学院,郑州 450001;2.中国科学院自动化研究所,北京 100190
0 引言
随着医疗技术的发展和生活水平的提高,人们在就医时不仅关注治疗的效果和时效,还十分关注治疗方法对于身体产生的不可逆创伤。因此,相较于传统的手术方式,微创手术以其创口小、伤害小的优点受到大众的欢迎,如显微镜手术或内窥镜手术能够有效提升手术的精度和安全性,是现代外科手术的发展趋势之一。随着机器人技术的发展,机器人辅助的手术逐渐应用到外科手术中,其依赖于手术图像的自动分析,为医生操作和决策提供丰富的信息,如判断手术的阶段、识别手术高风险区域等,其中语义分割可以提供给外科医生手术器械和解剖器官的类别与位置信息,为医生安全手术操作提供直观提示(Bouget 等,2017;Allan 等,2020)。手术器械分割作为机器人辅助手术的关键环节,对于克服复杂的手术环境影响、减小手术风险具有重要意义。手术器械分割是医学图像分割领域中的一项重要课题,吸引了很多研究学者的注意。
目前,已经有大量的学者提出和改进了不同的方法,以实现手术器械的自动分割,但是手术器械的准确分割仍然是一个难点。首先,在手术期间,外科医生能接受到的全部信息仅来源于手术中图像采集设备传回来的图像信息,因此医生接受到的信息十分有限,而且,部分具有挑战性的图像人眼难以有效地分析,容易产生误判,因此,准确、自动的自动图像分析对手术机器人也就显得尤为重要。其次,不同的手术类型使用不同的手术器械,这些手术器械的形状、大小存在较大差异,即使是相同的手术器械,手术过程中的运动和姿态变换也会使得手术器械的形状、大小产生较大变化,给手术器械的分割带来一定挑战。除此之外,复杂的手术环境,例如烟雾、血液、镜面反射和运动伪影等因素也会对手术器械的精确分割造成干扰(Wang等,2019)。因此,准确、自动的手术器械分割仍是一项有意义且存在挑战性的研究工作。针对上述问题和难点,为了进一步提升手术器械分割精度,本文提出了基于卷积神经网络(convolutional neural network,CNN)和Transformer 的双编码器融合的手术器械分割网络。具体来说,基于CNN 和Transformer 各自的优点,设计了一种双编码器结构,引入Transformer网络分支,增强网络的全局上下文语义信息提取能力,弥补CNN 编码分支的不足。提出了多尺度注意融合模块,实现局部特征图的特征增强,丰富网络对于不同大小目标特征的处理能力。同时,针对分割任务存在的类不平衡问题,引入全局注意力机制,增强网络对于有效特征的处理,并引入Soft Dice 损失函数指导网络训练,减少类不平衡问题带来的影响。
本文的主要贡献如下:1)提出了用于手术器械分割的基于CNN 和Transformer 的双编码器融合的手术器械分割网络,其很好地结合CNN 和Transformer 的各自优点,实现端到端的手术器械的分割;2)设计了多尺度注意融合模块,实现局部特征的多尺度特征表征,提高网络在多尺度目标的检测能力;3)针对类不平衡问题,引入全局注意力机制,突出显著的图像区域和抑制无关的图像区域;4)利用公开数据集验证模型的有效性,在两个公开数据集上的实验结果表明,相较于对比方法,本文模型获得了优异的分割精度,改善了手术器械分割中边界模糊和细节特征丢失的问题。
1 相关工作
在深度学习出现之前,手术器械分割通常使用基于模型的半自动方法,这种方法可以概括为传统图像分割方法。传统图像分割方法多是通过颜色、边沿和纹理等基本特征对图像进行分割。该类方法常见的有阈值(Cheriet 等,1998)、边缘(Fabijańska,2011)、聚类(Jing等,2018)和图论(虎晓红 等,2013)等分割方法。Wang 等人(2022)提出了一种基于OTSU多阈值分割算法的改进状态转移算法,引入一种新的跳跃算子增强网络的局部搜索能力以达到寻找最佳阈值的稳定性和快速性。Tang(2010)将分水岭算法与种子区域生长算法相结合,提出了一种基于区域的自动种子区域生长的彩色图像分割方法。这种分割方法能够较为准确地分割出图像中的局部细节,但是容易形成过分割。总之,基于模型的传统图像分割方法在医学图像分割领域有许多应用,能够较准确地分割图像、识别边界,但是其存在计算复杂、分割效率低的问题,限制了传统图像分割方法在手术器械分割领域的应用。除此之外,传统的图像分割方法需要针对不同的目标建立不同的模型,需要丰富的专业知识和人工干预支撑,大大增加了应用的难度。
随着人工智能和大数据的发展,深度学习算法已经在医学图像分割领域广泛应用,众多研究者提出了各种基于深度学习的图像分割方法(罗恺锴等,2021)。基于深度学习的图像处理方法通常可以直接处理原始数据,并自动学习到复杂、抽象的高维特征信息,使网络具备自动分割图像的能力。目前,常见的深度图像分割网络包括全卷积网络(fully convolutional network,FCN)(Long 等,2015)、Deep-Lab(Chen 等,2018a)、SegNet(Badrinar ayanan 等,2017)和U-Net(Ronneberger 等,2015)。为了减少计算成本和能源消耗,Li 等人(2018)将传统分水岭算法和FCN 网络结合,提出了一种轻量级网络,传统分水岭分割方法使得深度学习网络加强对可能影响分割精度的像素的关注。但是由于FCN 网络本身对于局部特征和上下文信息的关注不够强烈,该方法存在局部特征丢失的问题。Chen 等人(2016,2017,2018a,b)提出了一系列的DeepLab网络,通过不同编码器、空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)和深度可分离卷积增强网络对于多尺度信息的提取,但其可视化结果依旧明显存在细节丢失和上下文提取不充分的问题。Yue 等人(2020)提出了一种将条件随机场与SegNet网络相结合的分割方法,在公共数据集上的实验结果表明,该网络在精度和速度两个方面都达到了不错的分割效果。但是,该方法的训练十分复杂,对于上下文信息的提取也不够充分,容易造成小目标的错分以及大目标的局部误分。针对以上分割网络对于局部特征关注不够充分、细节丢失较为严重的问题,通过跳跃连接,U-Net 网络在一定程度上减少了细节丢失,增强了网络对于细节特征的恢复能力,连续的双卷积结构也加强了网络对于局部特征的关注,改善了基础网络的局限性。鉴于U-Net 的这些优点,本文使用U-Net 作为基础网络,提出了基于CNN 和Transformer 的双编码器融合的手术器械分割网络,实现手术器械的准确分割。
U-Net凭借其卓越的分割性能,在医学图像分割领域得到广泛应用,许多以此为基础架构的网络相继提出(周涛 等,2021)。U-Net 的改进思路大致可以分为两种:引入新模块和改进编解码器。引入新模块是指在U-Net 结构的现有基础上额外使用其他可以增强特征提取能力、改善类不平衡问题的模块。例如,Feng 等人(2020)提出了一种用于皮肤病变分割的CPFNet(context pyramid fusion network)模型。该网络在瓶颈层引入了一个尺度感知金字塔融合模块获取高级特征中的多尺度上下文信息,并在重构的跳跃连接上引入了全局金字塔引导模块,为解码器提供不同分辨率的细节信息和上下文信息。Gu等人(2019)提出的CE-Net(context encoder network)同样以U-Net 为基础架构,在瓶颈层应用密集空洞卷积块和残差多核池化模块组成的上下文提取模块,以提升网络对于多尺度上下文的提取能力。改进编解码器的一般方法为将编码器或解码器中的双卷积结构更改为特征提取能力更强的模块或参数占用更少的模块,以追求更高的分割精度或更快的处理速度。除此之外,使用预训练的经典网络结构作为编码器也是改进思路之一,例如ResNet(residual network)(He 等,2016)和VGG(Visual Geometry Group)(Simonyan 和Zisserman,2015)。Xia 等 人(2022)将编码器、解码器中的双卷积结构替换成SPConv(split based convolution),剔除冗余特征的信息流,加强对于有效特征所在通道的关注,在尽量少损失分割精度的条件下追求更少的参数占用。Lu等人(2022)提出了DCA-Cnet(dual context aggregation and attention-guided cross deconvolution network),在编码器端引入边缘信息注意模块,加强网络对于边缘信息的保存,在解码器端使用注意导向的交叉反卷积代替双卷积结构,使得解码器获取到更全面的多尺度信息,并学会有效利用。
尽管目前基于CNN 的方法在不同的分割任务中取得了不错的效果,但这些方法都存在上下文提取能力不足的问题。因为卷积核的大小有限,能够提取较小的目标对象的上下文信息。但是对于较大的目标对象,很难准确识别上下文语义。因此,本文提出了基于CNN 和Transformer 的双编码器融合的手术器械分割网络以解决上述问题。
2 本文方法
为了充分提取全局上下文信息,增强网络内部特征表达,更精确地分割出手术器械,本文提出一种基于CNN 和Transformer 的双编码器融合的手术器械分割网络,具体分割网络框架如图1所示。

图1 基于CNN和Transformer的多尺度融合注意网络的网络结构Fig.1 Network structure of multi-scale fusion attention network based on CNN and Transformer
该网络沿用编码器—解码器的网络结构,使用收缩扩展路径在很大程度上减少了无关信息的干扰。手术器械分割属于区域性分割任务,丰富的上下文特征提取显得尤为重要,而CNN 在这方面略有不足,主要聚焦于局部信息提取。因此,本文在分割网络的编码器单元,提出CNN 和Transformer 结合的双编码器结构,从而实现同时对局部特征和全局上下文语义信息的充分提取。
除此之外,针对手术器械大小、形状的多样性,本文提出了多尺度注意融合模块以嵌入到瓶颈层,丰富多尺度语义信息,增强网络局部特征表达和不同尺度的上下文信息提取,使分割网络对于差异较大的目标具有相同的分割能力。另外,类不均衡作为医学图像分割存在的普遍问题,同样存在于手术器械分割中。为了缓解这一问题,网络在解码器单元引入全局注意力模块,指导编码器输出特征图的特征学习,并与解码器传递的特征图进行融合,增强分割网络对目标像素的关注度,减少对冗余特征的关注。
2.1 骨干网络
本文提出的基于CNN 和Transformer 的双编码器融合的手术器械分割网络沿用了U-Net 的基础架构,使用编码器—解码器的架构来处理输入图像,实现端到端的语义信息提取与图像分割。本文主干网络深度设置为4 层,从浅到深,特征通道数依次设置为64、128、256、512。
编码器采用预训练的ResNet34的前4层代替传统的双卷积结构,实现图像特征的有效提取,并加快网络的反向传播,加速网络收敛,避免梯度消失和梯度爆炸问题。而解码器单元采用双卷积结构,同时,采用转置卷积(Dumoulin 和Visin,2018)实现特征的上采样。与线性插值上采样不同,转置卷积上采样不使用预设的插值方案,自适应地学习最优的上采样方式。除此之外,在解码器的每一层前端,使用一个注意力模块AG(attention gate)(Oktay 等,2018),指导来自解码器底层和镜像层编码器传递过来的特征信息融合,通过两个非线性激活函数,有目的地放大有效信息,加强网络对于显著特征的关注。
同时,为了减少连续的池化运算造成的细节信息丢失的问题,在编码器—解码器结构的基础上,引入跳跃连接,实现低级图像特征和高层图像特征的融合。
2.2 双编码器结构
对于传统的U-Net网络来说,编码器单元由2个3 × 3 卷积和下采样层堆叠而成,但是由于卷积操作对于计算参数的引入量较大。为了保证分割网络的计算效率,卷积操作只能在相对固定的感受野中学习特征。对于大目标对象来说,感受野过小会影响全局上下文特征提取。出于减少计算成本、降低硬件设备要求的目的,卷积核通常比较小,即使随着层数加深,感受野也在逐步上升,但是仍难以达到图像的大小,从而限制了编码过程中全局上下文信息的学习。相反,Transformer 在全局范围内关注输入切片与其他所有切片的相关性,在每一次操作中学习所有输入切片的上下文信息,可以很好地弥补卷积层上下文信息学习能力不足的缺陷。但是,由于Transformer 以切片为对象而不是以像素为对象,只聚焦于切片之间相似性的学习,缺乏对于切片内部局部特征的关注,所以Transformer 容易忽略输入图像的局部细节。CNN编码器刚好弥补了Transformer局部特征学习不充分的问题。因此,本文提出了基于CNN 和Transformer 结合的双编码器结构,增强分割网络的全局上下文信息和局部特征的提取能力。
相比于其他文献直接融合CNN 编码器和多层Transformer 输出特征图的做法,本文融合每个对应层的CNN 和Transformer 特征图,作为后续信息储备通过跳跃连接传递到解码器。这种融合方式可以充分利用每一层的特征信息,使每一次上采样过程的特征融合都可以同时包含全面的局部细节和全局上下文信息,相比直接融合底层输出特征图的做法,可以在增加较少参数的情况下,增强有用信息流的传递。
本文使用的Transformer 分支编码结构(Wu 等,2022)由12 层Transformer 堆叠而成,每个层结构相同,具体结构如图1所示。将输入图像输入到Transformer 层之前,需要通过3 个图像预处理步骤:线性投影、位置嵌入和补丁嵌入。
具体来说,对于RGB 三通道输入图像x∈R3×H×W,它的尺寸为H×W,将它按照固定尺寸裁剪成N个切片,尺寸为H/N×W/N。然后为了与Transformer 的输入契合,使用线性投影将2D 的输入图像切片映射到1D 空间,生成像素序列xL∈RN×P,其中P=H/N×W/N。然后,将像素位置和切片顺序嵌入生成的1D像素序列,生成带有位置先验的输出序列xe∈RN×P,并将此序列作为最浅层Transformer的输入。每个Transformer层都包含多头自注意层和前馈网络层两个部分,两个部分都使用残差连接分支。多头自注意层包含一个层归一化块和一个多头自注意块,通过查询向量Q、键向量K 和值向量V 帮助编码器在对每个切片进行编码时关注其他切片,学习它们之间的相关性。每层Transformer对于输入特征图Fi的操作为
式中,Fsa表示输入特征图经过多头自注意力模块处理后与残差分支相加的特征图,Ft表示对应层Transformer 的输出特征图,H(·)表示多头自注意模块的功能函数,g(·)表示层归一化。M(·)为前馈网络的功能函数,其包含两个线性层和一个ReLU(rectified linear unit)激活函数,线性层用L(·)表示,ReLU 激活函数用σ表示。
另外,Transformer 层处理过的特征图与对应的CNN 输出特征图按通道串联,实现全局语义信息和局部语义信息的特征融合,并作为跳跃连接的输入,输入到attention gate模块。
2.3 多尺度融合注意模块
单一尺度的特征学习限制了分割网络的信息丰富度,影响对于不同尺度目标的分割能力。然而,直接增加其他卷积核大小的卷积分支以获取不同尺度信息的做法会引入大量参数,很大程度降低网络的处理速度,影响网络的推理效率。为了解决上述问题,人们提出了经典的ASPP(atrous spatial pyramid pooling)网络(Yu 和Koltun,2016),多分支并行的空洞卷积既可以提取多尺度特征信息,又可以尽量减少计算参数的大量使用。但是,不同膨胀率的多尺度卷积直接并行处理会产生视觉盲区,忽视膨胀卷积核中值为零的点,这种现象称之为网格效应,如图2所示。
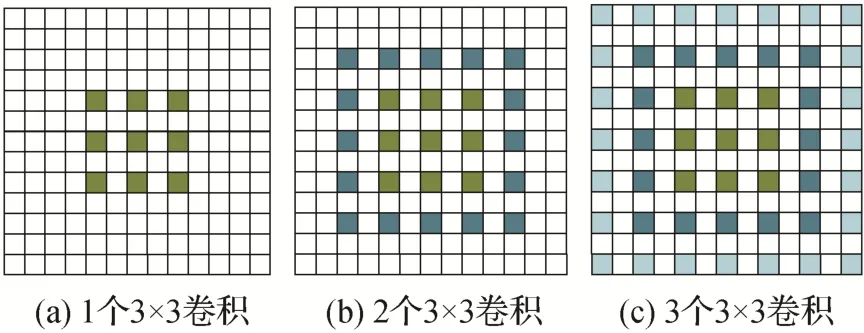
图2 串联空洞卷积的网格效应Fig.2 Grid effect of tandem atrous convolution((a)one 3 × 3 convolution;(b)two concatenated 3 × 3 convolutions;(c)three concatenated 3 × 3 convolutions)
为了缓解这个问题,设计了多尺度注意融合模块,将不同膨胀率的空洞卷积特征图递进融合,加强不同尺度处理分支的信息交流,弥补视觉盲区带来的信息丢失。多尺度融合注意模块的结构如图3 所示。多尺度注意融合模块由两个部分组成,多尺度信息提取部分和残差连接部分。残差连接通道仅使用一个1 × 1 卷积。本文使用了4 个空洞卷积,膨胀率分别为1,2,5,7。4 个空洞卷积的并行分支输入特征图处理后都会产生两个输出分支,一个分支用于后续特征图融合;另一个分支用于后续空洞卷积的信息交互。为了进一步加快网络的分割速度,将使用到的卷积全部替换为深度可分离卷积(Howard等,2017)。通过各尺度分支处理后的特征图按通道串联,生成包含多尺度语义信息的特征图。面对多通道特征图,为了减少对于无效尺度特征的重复利用,本文引入挤压—激励(squeeze-and-excitation,SE)通道注意力模块(Hu等,2018)实现通道标定,其通过挤压—激励机制,自适应地学习每个尺度特征的有效性,并调整高权重至有效尺度,加强网络对于有效尺度特征的关注。
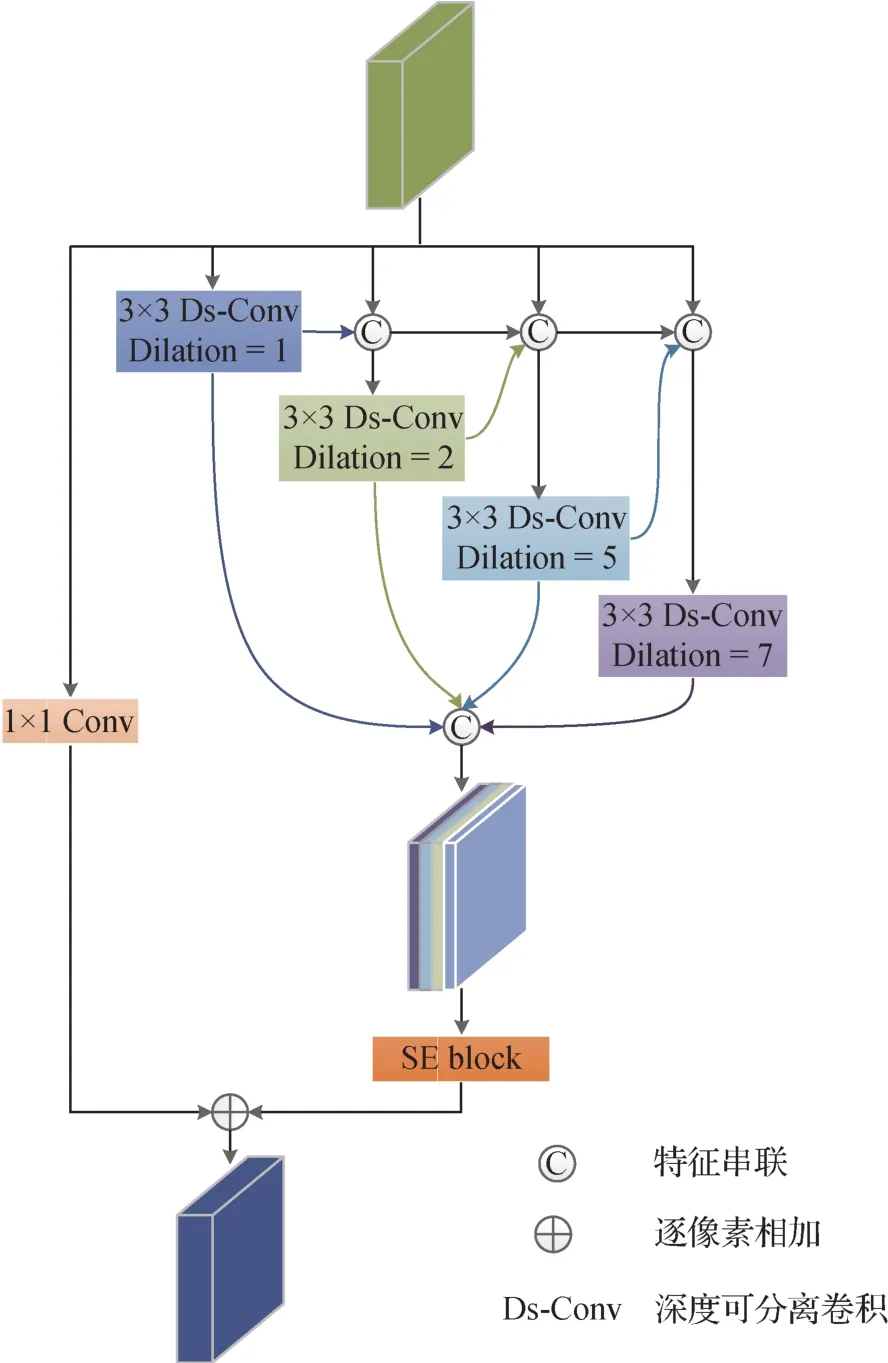
图3 多尺度注意融合模块的网络结构Fig.3 Network structure of the proposed multi-scale attention fusion block
为了更直观地阐述多尺度融合注意模块,将x设为输入特征图,Y 设为输出特征图,y1为梯形连接的空洞卷积分支的输出特征图,y2为残差分支的输出特征图,多尺度注意融合模块可以表述为
Hi表示膨胀率为i的深度可分离空洞卷积,fse表示SE block 的功能函数,C1表示1 × 1 卷积,⊙表示特征图按通道串联。
3 实验设置
为了验证本文分割网络的性能,对两个公共手术器械分割数据集进行了实验分析。本节给出了模型评估和测试时使用的数据集详情,并阐述了实验过程中使用的实验平台、参数设置和评价指标。
3.1 实验数据集
为了测试基于CNN 和Transformer 的双编码器融合的手术器械分割网络的分割性能和泛化性,使用白内障手术器械分割数据集Endovis2017 和胃肠道手术数据集Kvasir-instrument 进行模型的训练和测试。这两个手术器械分割相关数据集的手术器械类型和收集环境都存在很大差异,可以有效验证分割模型的泛化性。
1)Endovis2017 数据集。Endovis2017 来 自MICCAI Endovis Challenge 2017 挑战赛(Allan 等,2019)。该数据集是由 Vinci Xi 机器人在白内障手术中获取的,由10 个白内障手术视频采样得到的图像序列组成,包含7 种类型的手术器械。然而,这些图像序列中,仅前8 个图像序列包含原始图像和标注图像,后2 个图像序列只有原始图像,不包含相应标注图像。在本实验中,仅使用含有标注图像的前8 个图像序列进行模型的训练和测试。这8 个图像序列共有1 800 幅手术图像,分辨率均为1 280 ×1 024像素。
2)Kvasir-instrument 数据集。该数据集是从挪威 Bærum 医院进行的内窥镜检查中通过Vestre Viken Hospital Trust 的Olympus(Olympus Europe)和Pentax(Pentax Medical Europe)的标准内窥镜设备收集的胃肠道手术图像(Jha 等,2021a)。本研究中使用的所有数据均来自遵循 Bærum 医院患者同意协议程序的视频。此数据集包含590 幅分辨率大小从720 × 576 像素到1 280 × 1 024 像素不等的胃肠道手术器械图像和它们对应的标注图像,标注图像由两名专业的研究助理完成并由胃肠道专家进行修正。
在实验之前,为了统一标准,将这两种公开数据集resize 中图像尺寸统一调整至相同尺寸224 × 224像素,这个操作将大部分原始图像的手术器械部分放至图像的中央并裁剪部分与手术器械无关的像素,既有利于手术器械的分割,又减少了对于无效像素的使用,节省了内存占用。在实验过程中,按照相同的比例对每个数据集划分训练集、验证集和测试集。训练集和测试集的比例设置为4∶1,其中验证集来自于训练集,取训练集图像的25%作为验证集。除此之外,为了使分割结果更有信服力,在每个数据集上使用5倍交叉验证,结果取平均值。
3.2 网络训练
本文基于PyTorch 深度学习框架构建了基于CNN 和Transformer 的双编码器融合的手术器械分割网络,同时,为了加速网络的训练和测试,相关分割实验均在具有24 GB内存的NVIDIA Geforce RTX-3090 GPU平台上实现。
优化器使用自适应矩估计优化器(Adam),初始学习率设置为0.000 1,Batch size 的大小设置为 16,迭代次数为300 次。损失函数使用Soft Dice 损失函数来训练网络,并使用所有epoch 中在验证集上性能最好的模型进行测试。
3.3 评价指标
在图像分割中常用的两个评价指标为Dice 分数和平均交并比(mean intersection over union,mIOU),其不容易受到类不均衡问题的影响。因此,本文同样使用这两个流行的评价指标评估本文手术器械分割网络的分割性能。Dice分数是评估预测结果与真实值的相似性评价指标。mIOU 值是计算预测结果与真实值的重叠度量化指标。具体为
式中,P和G分别代表预测结果与真实值。
4 实验结果及分析
为了充分验证本文提出的网络对于手术器械分割精度提升的有效性,实验使用以上介绍的两个公开数据集,并基于上述两个评价指标作为验证标准,分别进行了对比实验和消融实验,从定量分析和定性分析两个角度分析本文网络在手术器械分割任务上的性能以及每个子模块对于整体分割精度提升的贡献。
4.1 Endovis2017数据集上的实验结果
4.1.1 对比实验
首先,将本文网络在此数据集的8 组视频图像上的分割结果与挑战赛上的其他方法进行对比,表1给出了对比模型和本文方法在各个子数据集上的mIOU 值。可以看出,与MICCAI 分割挑战赛中提出的其他分割方法相比,本文提出的基于CNN 和Transformer 的双编码器融合的手术器械分割网络在Endovis2017数据集的6个视频序列上都达到了最高的分割精度,以平均mIOU 为92.5%的超高指标名列前茅。在另外2 个视频序列上,本文方法虽然没有达到最高的分割精度,但是也达到了第2 高的分割精度,且与对应视频序列上分割精度最高的方法相差无几。与整体分割精度第2 高的MIT 相比,本文方法将mIOU 提高了3.5%。总之,与竞赛中的其他方法相比,本文方法在手术器械分割精度方面实现了巨大提升。

表1 Endovis2017数据集上与MICCAI挑战赛其他分割方法的对比实验结果Table 1 Comparison experimental results with other methods in the MICCAI challenge on the Endovis2017 dataset
其次,选用了几个其他研究者提出的新分割模型作为对比实验,在相同实验环境和参数设置的基础上,比较本文方法与对比方法的分割性能,具体的实验结果如表2所示。

表2 与其他先进方法在Endovis2017数据集的对比结果Table 2 Comparison experimental results with other advanced methods on the Endovis2017 dataset /%
从表2 可以看出,相比于对比实验选用的其他方法,本文方法在Endovis2017数据集上达到了最高的分割精度,Dice 分数为96.27%,mIOU 为92.55%,比表现次优的RASNet 分割网络(Dice 分数为94.65%,mIOU 为90.33%)分别高出1.62% 和2.22%。与U-Net(Dice 分数为89.37%,mIOU 为79.44%)相比,本文方法实现了分割精度的大幅提升,Dice 分数提升了6.9%,mIOU 提升了13.11%。综上所述,本文方法在Endovis2017数据集上取得优秀的分割性能,在分割精度方面超越了很多较先进的分割方法。以上为Endovis2017 数据集上对比实验结果的定量分析。为了更直观地阐述本文方法在该数据集上的分割效果,测试集上的部分图像作为测试样本,给出了不同模型的可视化结果,具体分割结果如图4 所示。从图4 的可视化结果中可以明显看出,相比于其他方法,本文方法的分割结果最接近真实值,而其他对比方法的分割结果普遍存在边界不清晰、局部细节误分的问题。

图4 Endovis2017数据集上对比实验的可视化结果Fig.4 Visualization results of comparative experiments on the Endovis2017 dataset((a)raw images;(b)ground-truth;(c)ours;(d)U-Net;(e)U-Net++;(f)attention U-Net)
结合定性分析和定量分析,可以得出结论,本文提出的基于CNN 和Transformer 的双编码器融合的手术器械分割网络具有十分优秀的分割效果,相比于其他网络模型,可以更准确地分割出目标边界和检测出局部细节。
4.1.2 消融实验
在Endovis2017 数据集上的对比实验结果证明了本文提出的基于CNN 和Transformer 的双编码器融合的手术器械分割网络在分割精度方面取得了明显提升。本文方法相比于U-Net 的改进主要集中在双编码器结构、多尺度注意融合模块和attention gate模块。为了说明每个模块的有效性,针对提出的3 个子网络模块,设置了4 个消融实验,分别为基准网络(其为去除本文设计的3 个子网络模块后的分割网络)、w/o Transformer 模块、w/o 多尺度注意融合模块和w/o attention gate 模块。其中w/o 表示从本文网络中移除对应网络模块。w/o Transformer 模块是指将双编码器结构换成仅使用ResNet34 的单分支的CNN 编码器的编码器结构。基于Endovis2017 数据集,具体的消融实验的定量分析结果如表3所示。

表3 在Endovis2017数据集上的消融实验结果Table 3 Ablation experiment results on the Endovis2017 dataset
可以看出,基础网络RNet 在不使用任何子模块的情况下,对于Endovis2017 数据集可以获取89.11%的Dice 分数和83.03%的mIOU 值。另外3 个消融实验的分割结果表明,去除任何一个子模块都会对最终分割精度造成损失,但是,其均高于基准网络。除此之外,同时使用3 个子模块的本文方法在两个指标上都得到了最高的分数,说明本文提出的3 个子模块对于最终分割精度的提升都有或多或少的贡献,其中,w/o Transformer 模块的分割指标是最低的,相较于本文网络,Dice 分数降低了1.39%,mIOU 值降低了0.78%。由此可以说明,在Endovis2017 数据集上,双编码器模块对于最终分割精度的提升效果最明显。
为了进一步说明3 个子网络模块对于最终分割精度的提升都有贡献,与对比实验中的定性分析相同,本文展示了消融实验的可视化结果。以测试集中的4张随机样本作为实验对象,具体消融实验的可视化实验结果如图5所示。可以看出,可视化实验结果与消融实验的定量分析相互印证,同时,应用3 个子网络模块的网络的分割结果最接近真实值,取得了最高的分割精度。其他3 个消融实验或多或少存在局部误分割的情况,其中w/o Transformer模块的分割效果最差,不能准确分割出手术器械一些小的关节,对于较大器械的内部像素也产生了一定程度的误分。相比其他两个消融实验,w/o Transformer模块产生了更大面积的误分割,很好地证明了双编码器模块对整体分割性能提升的作用。

图5 Endovis2017数据集上消融实验的可视化结果Fig.5 Visualization results of ablation experiments on the Endovis2017 dataset((a)raw images;(b)ground-truth;(c)ours;(d)w/o Transformer;(e)w/o muti-sacle attention fusion block;(f)w/o attention gate)
4.2 Kvasir-instrument数据集上的实验结果
4.2.1 对比实验
单一数据集上模型的分割性能验证并不能很好地说明模型的分割性能和模型的通用性。为了使实验结果更具说服力,排除偶然性等因素的影响,本文在另一个胃肠道手术数据集Kvasir-instrument 上同样进行了对比实验和消融实验,且从定量和定性两个方面分析本文分割网络的性能。
首先,将本文提出的分割网络与其他研究人员提出的先进分割方法进行对比,用于性能比较,实验结果如表4 所示。毫无疑问,本文提出的基于CNN和Transformer的双编码器融合的手术器械分割网络在Kvasir-instrument 数据集上取得的各项指标名列前茅,Dice 分数达到96.46%,mIOU 值达到94.12%,分割精度远远高于表4 中其他研究人员提出方法。相比于对比实验中最优分割网络DRR-Net(Dice 分数为96.27%,mIOU 值为92.82%),本文方法将Dice分数提升了0.19%,mIOU 值提升了1.30%。此外,从表4 中还可以看到,U-Net 的Dice 分数为91.58%,mIOU 值为85.78%。与U-Net 相比,本文提出的分割网络的分割精度有明显提升,Dice 分数提升了4.88%,mIOU 值提升了8.34%。由此可以说明,本文提出的分割网络对U-Net 基础网络做的改进是十分有效的,另外,本文提出的3 个子网络模块的合理结合可以大幅度提升分割精度。本文方法可以有效增强分割网络对于局部细节和全局上下文信息的提取能力。

表4 与其他先进方法在Kvasir-instrument数据集上的对比实验结果Table 4 Comparison experimental results with other advanced methods on the Kvasir-instrument dataset /%
与Endovis2017数据集上的实验相同,在Kvasirinstrument 数据集上选取几个样本作为实验对象,将不同模型的对比实验的可视化结果展示在图6 中,以便于更直观地理解本文方法的优越性。从图6 中可以明显观察到所有对比实验中,本文方法的分割结果最趋近与真实值,基本能够清晰地分割出手术器械的边界和关节处的具体细节。而其他几个对比实验对于边界的分割十分模糊,且基本不能分割出手术器械关节处的小孔等细节特征。

图6 Kvasir-instrument数据集上对比实验的可视化结果Fig.6 Visualization results of comparative experiments on the Kvasir-instrument dataset((a)raw images;(b)ground truth;(c)ours;(d)U-Net;(e)U-Net++;(f)attention U-Net)
综上所述,Kvasir-instrument 数据集上的对比实验结果与Endovis2017数据集上的实验结果一致,都有效证明了本文提出的分割网络可以有效提升手术器械的分割精度。
4.2.2 消融实验
为了更进一步验证本文应用的3 个子网络模块各自对于提升分割精度的贡献,在Kvasir-instrument数据集上进行消融实验,消融实验的设置与Endovis2017 数据集上一致。消融实验的定量分析结果如表5 所示。可以看出,整体的分割结果与Endovis2017 数据集上的实验结果基本完全一致,同时应用了3 个子网络模块的本文方法两个评价指标都是取得了最优值。其他4 个消融实验的分割精度相比于本文方法都有一定程度的损失,其中,去掉双编码器结构对于分割精度的影响最大,多尺度注意融合模块次之,attention gate 模块的影响最小。使用双编码器模块可以将Dice分数提高1.84%,mIOU值提高2.05%。

表5 在Kvasir-instrument数据集上的消融实验结果Table 5 Ablation experiment results on the Kvasir-instrument dataset
为了更直接地显示消融实验的效果,图7 展示了Kvasir-instrument 测试集上4 幅示例图像的消融实验可视化结果,与消融实验的定量结果相互印证,可以更直观地展示出每个模块对于提升最终分割精度的贡献。从图7中可以明显观察到,3个子网络模块对于分割精度的提升都有贡献,只不过影响力不同。其中,双编码器结构对于手术器械的提升影响最大。

图7 Kvasir-instrument数据集上消融实验的可视化结果Fig.7 Visualization results of ablation experiments on the Kvasir-instrument dataset((a)raw images;(b)ground truth;(c)ours;(d)w/o Transformer;(e)w/o muti-sacle attention fusion block;(f)w/o attention gate)
4.3 效率分析
对于手术器械分割任务,除了分割精度外,推理速度也是分割网络性能评判的一个重要指标。结合具有24 GB 内存的NVIDIA Geforce RTX-3090 GPU平台,在本文使用的2 个器械分割公开数据集Kvasir-instrument 和Endovis2017 数据集上,对本文分割网络在手术器械图像分割上的计算效率进行测试。统计本文提出的分割网络在这两个数据集上平均推理时间,具体的效率分析的实验结果如表6所示。
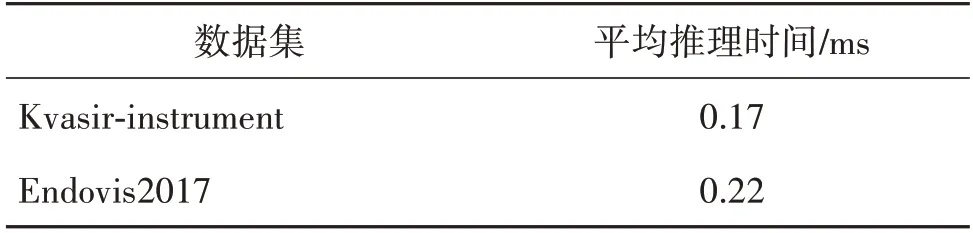
表6 本文分割网络的平均推理时间Table 6 Average inference time of proposed network
基于表6 中的实验结果,可以计算出本文提出的分割网络在Kvasir-instrument 数据集的平均推理速度为59 帧/s,对于Endovis2017 数据集的平均推理速度为45 帧/s。结合精度分析和计算效率分析,本文提出的分割网络在保证良好的分割精度的基础上,取得了很好的分割效率。因此,本文分割网络在手术器械分割任务上兼具分割效率和分割精度,可以实现手术器械的准确、快速分割。
4.4 编码器性能的影响
除上述实验之外,为了更充分地说明本文设计的双编码器结构中Transformer分支对于提升分割精度的作用,在Kvasir-instrument 数据集上单独对使用双编码器和使用CNN 单分支编码器的网络分割性能进行测试。不同网络配置的热图如图8 所示。颜色越靠近红色的像素点表示目标像素点的概率越高。反之,颜色越靠近蓝色的像素点表示背景像素点的概率越高。
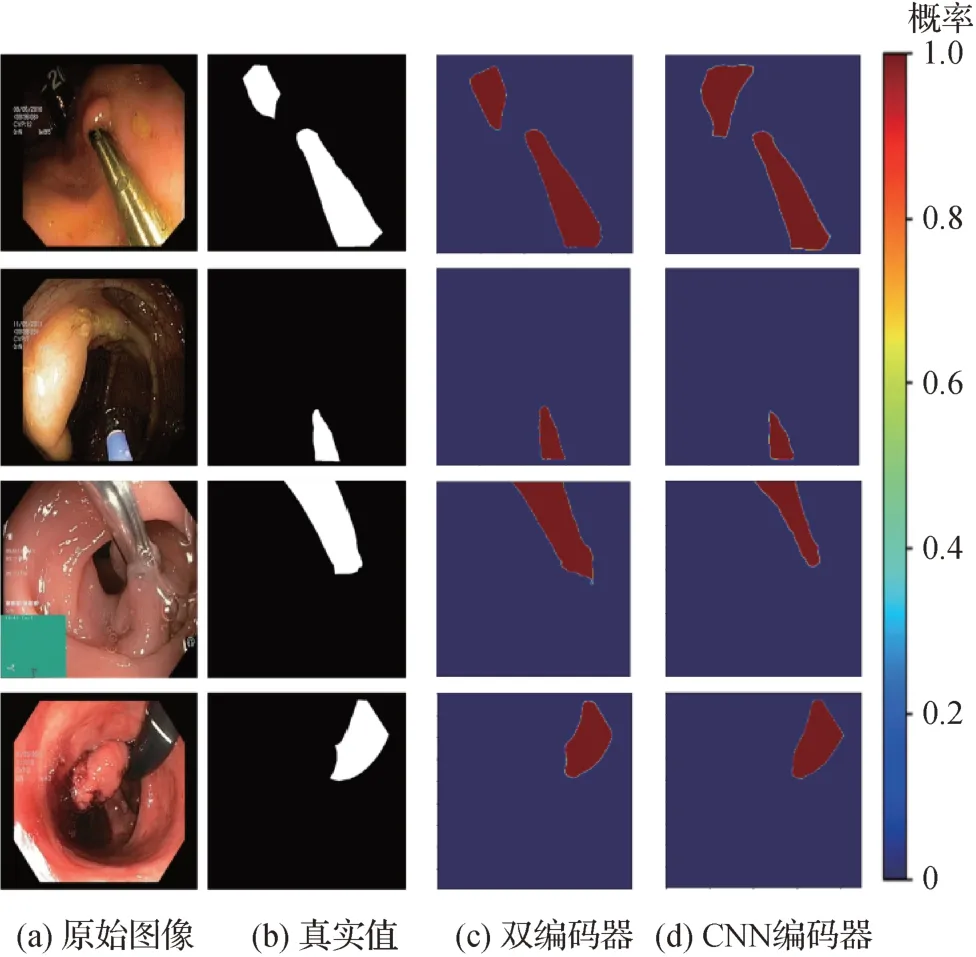
图8 Kvasir-instrument数据集上不同编码器下的热图Fig.8 Heat maps for different encoders on Kvasir-instrument dataset((a)raw images;(b)ground truth;(c)dual-encoder;(d)CNN encoder)
如图8 所示,应用双编码器的分割网络完全将注意力集中在目标像素,无论对于目标的内部像素还是边界像素都具有优秀的分割能力,与单分支CNN 编码器相比,可以获得更接近真实值的分割结果。图8 直观有效地表明了融合Transformer 和CNN的双编码器结构可以很大程度地提高手术器械的分割精度,通过双编码器信息的融合,可以有效地获取上下文信息提取,使手术器械分割网络获取更加清晰的边界信息。
5 结论
为了提升手术器械分割的精度,以编码器—解码器为基础架构,本文提出了一种用于手术器械分割的端到端的基于CNN 和Transformer 的双编码器融合的手术器械分割网络,实现手术器械的自动准确分割。为了实现内窥镜图像的有效表征,提出了基于Transformer 和CNN 融合的双编码器模块,以增强分割网络对于局部特征和全局上下文语义信息的学习能力。同时,基于深度可分离空洞卷积,提出了多尺度注意融合模块,在产生较少参数的前提下,实现多尺度语义信息的有效提取,增强网络的特征表达。另外,引入全局注意力单元,以减少类不均衡问题对分割性能的影响。实验结果表明,本文提出的分割网络在Endovis2017 和Kvasir-instrument 数据集上都获得了优异的分割性能,可以快速准确地分割出手术器械,并获得准确清晰的边界,分割精度远远超越了对比的手术器械分割方法。
虽然本文的工作已经在很大程度上提升了手术器械分割的精度,但是仍有提升的空间,未来会仍然专注于手术器械分割,期望设计出更精确高效的手术器械分割方法。
猜你喜欢
世界最新医学信息文摘(2021年12期)2021-06-09 08:37:52
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
数学物理学报(2017年5期)2017-11-23 07:51:31
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
中国卫生质量管理(2014年5期)2014-02-28 17:42:26
医学研究杂志(2014年3期)2014-01-29 10:06:12
