
基于Transformer网络的COVID-19肺部CT图像分割
2023-10-24 13:58:18樊圣澜柏正尧陆倩杰周雪
中国图象图形学报 2023年10期
樊圣澜,柏正尧,陆倩杰,周雪
云南大学信息学院,昆明 650500
0 引言
新型冠状病毒引起的急性感染性肺炎(Lu 等,2020)自2019 年12 月以来持续在世界各地传播,对全世界人民的生命健康造成了严重威胁和损失。快速而准确地诊断新型冠状病毒肺炎(corona virus disease 2019,COVID-19)患者,对切断病毒的传播路径,实现患者的动态清零,具有重要意义。
目前,核酸检测是诊断新冠肺炎的“金标准”,但容易受到样本采集质量的影响,也比较耗时。因此,常采用CT(computed tomography)、X 射线等影像学方法进行辅助诊断。在临床实践中,基于深度学习的方法正在成为新冠肺炎图像分割和识别的热点。
自Shelhamer 等人(2017)提出全卷积网络(fully convolution networks,FCN)以来,语义分割技术也在医学影像领域得到广泛应用。采用语义分割技术对病变进行自动分割,替代医生的人工标注,能够节省大量的人力和时间。Ronneberger 等人(2015)提出了包含压缩路径和扩展路径的对称U 形网络UNet,并在两个路径之间增加跳跃连接进行特征互补,已成为医学图像分割领域中最常用的网络之一。除此之外,也有大量的学者提出了用于COVID-19病变分割的语义分割网络。Fan 等人(2020)在Inf-Net中提出了边缘注意模块和反向注意模块,用于关注COVID-19 病变区域中的边缘信息和小病变区域。Zhao 等人(2021)利用由两个注意力模块组成的双重注意力策略细化特征图,提出了一种基于双注意策略和混合扩张卷积的新型扩张双注意U-Net 网络。Elharrouss 等人(2022)针对COVID-19 病变,提出了先分割可能被感染的肺部区域,然后再对这些区域的感染进行细分的方法。陆倩杰等人(2022)针对COVID-19病变多尺度的特点,提出了多尺度编码和解码的方式,提升网络对各尺度病变的关注。
基于自注意力的架构,Transformer 已成为自然语言处理(natural language processing,NLP)中的首选模型。受到NLP 成功的启发,许多方法将自注意力模块(self-attention,SA)替代卷积层应用于计算机视觉领域。Self-attention 是Transformer 的关键组件,它可以对所有输入标记(tokens)之间的相关性进行建模,从而使Transformer 能够处理长依赖关系。Dosovitskiy 等人(2021)提出了vision Transformer,通过将图像拆分为块(patch),类似于NLP 应用中的tokens,并将这些图像块的线性嵌入序列作为Transformer 的输入,以有监督方式训练图像分类模型,在大规模的数据集图像上取得了当时最先进的分类精度。与vision Transformer 不同,Swin Transformer(Liu等,2021)使用了类似卷积神经网络中的层次化构建方法,与ResNet(residual network)(He 等,2016)一样,在提取特征的过程中也经历了4倍、8倍、16倍和32倍的下采样,输出4级不同尺度的特征图,可作为语义分割、目标检测等领域的主干网络。
随着Transformer 在计算机视觉领域的发展,优异的全局上下文建模能力,让很多学者纷纷提出了基于Transformer 的语义分割网络,并成功应用于医学图像领域。基于U-Net 的结构,TransUNet(Chen等,2021)将来自卷积神经网络(convolutional neural network,CNN)特征映射的标记化图像块编码作为输入序列,用于提取全局上下文信息,很好地解决了U-Net 在显式建模远程依赖方面存在的局限。Swin-Unet(Cao 等,2021)利用Swin Transformer 中的窗口多头自注意力模块(window-multihead self attention,W-MSA)计算量少的特点,提出了基于U-Net 结构的纯Transformer网络,在多器官和心脏分割任务中,取得了最优的效果。
COVID-19 的病变纹理、大小和位置变化较大,与正常组织间差异较小,这些都为分割模型的构建带来了较大的挑战(陆倩杰 等,2022)。本文认为,充分利用Transformer在全局上下文信息方面的强建模能力,设计能够兼顾全局与局部信息的网络结构,在保证具有很好的假阴性关注度的同时,提升对假阳性的关注度,增强对细节信息的分割能力,构建多尺度预测,能很好地应对COVID-19病变的分割。因此,本文提出了一种用于COVID-19 患者肺部CT 图像分割的纯Transformer 网络:COVID-TransNet。在没有进行任何数据增强的情况下,在COVID-19 CT segmentation 数据集上实现了0.789 的Dice 系数、0.807 的灵敏度、0.960 的特异度和0.055 的平均绝对误差,达到了目前先进的水平。
1 方 法
1.1 网络的整体结构
针对现有语义分割方法在COVID-19 的病变分割方面存在低灵敏度、高特异度的问题,本文网络整体结构设计思路是:1)在较少参数量的前提下,充分利用Transformer 强大的全局上下文信息捕获能力,提升网络对假阴性的关注;2)在数据量不足的前提下,有效缓解过拟合问题;3)在保证具有高灵敏度的同时,提升网络对假阳性的关注,提升特异度。
与传统的基于CNN 的语义分割网络相同,COVID-TransNet 也是基于编码器—解码器的结构。如图1 所示,特征提取部分以Swin Transformer 为主干,为了尽量减少计算参数,总共只迭代了12 个Swin Transformer 模块,图像块划分层(patch partition)用于将输入图像按4 × 4 的大小进行分块操作,块合并层(patch merging)用于进行2 倍下采样。提取第2、4、10、12 个Swin Transformer 模块后的输出,总共输出4 个不同尺度的特征图。为了缓解网络的过拟合问题,提出了线性前馈模块用于调整特征图的通道维度。将主干输出的4个特征图的通道数均调整到96 维,以减少计算参数。轴向注意力模块(axial attention)用于取代跳跃连接,提升网络对全局信息的关注。上采样部分提出了对局部信息进行逐级细化的特征融合方式,并引入深度监督,对解码器部分输出的每个分支都接一个Swin Transformer 模块进行解码,通过多级预测,提升对假阴性的关注。

图1 网络的整体架构Fig.1 The overall architecture of the network
1.2 Swin Transformer
Swin Transformer使用了类似于卷积神经网络中的层次化构建方法,使得该网络能够很好地插入语义分割、目标检测等方法中;其次提出了窗口化的多头自注意力方法来减少网络的计算参数。
1.2.1 窗口多头自注意力(W-MSA)
在标准的Transformer 模块中,要对整个特征图都进行自注意力的计算,成本是非常大的。与标准的Transformer 模块不同,Swin Transformer 中采用了W-MSA。如图2 所示,首先将224 × 224 像素的RGB图像按4 × 4 进行分块操作,划分为56 × 56 个4 × 4的图像块;然后将图像块沿通道方向上进行展平,展平后的大小为4 × 4 × 3=48,得到 [3 136,48]的二维矩阵;在实现过程中相当于得到了一个尺寸为56 × 56、通道数为48 的特征图。之后再以7 × 7窗口对该特征图进行划分,得到64 个7 × 7 × 48 的特征图,对应64 个 [49,48]的二维矩阵,然后送入MSA,在7 × 7 窗口内进行自注意力的计算。计算过程中,首先通过全连接层对输入进行线性映射,分别得到查询矩阵Q、键矩阵K、值矩阵V,然后将Q、K、V按照Head 设置的个数进行均分操作,代入式(1)中并行地计算每个Head 的自注意力矩阵Ai,最后将得到的{A1,A2,…,An}进行拼接(Concat),得到最终的输出A。
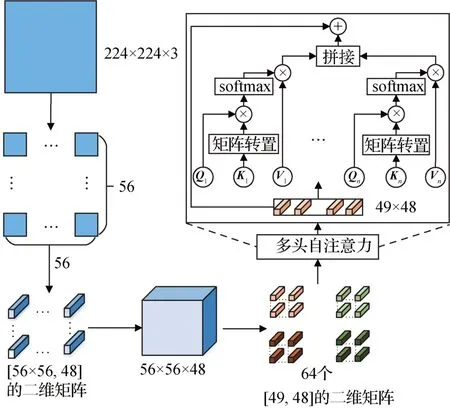
图2 W-MSA的计算过程Fig.2 Calculation process of W-MSA
1.2.2 移位窗口多头自注意力(SW-MSA)
相比MSA,W-MSA 能够减少大量的计算参数。但是只在每个窗口内进行自注意力计算,窗口与窗口之间无法进行信息交互。因此,SW-MSA 中采用了移位窗口划分方法。如图3所示,先通过窗口a中的方法对A、B、C、D 四个区域进行再次划分,然后采用窗口b—窗口d 中的方法对窗口a 进行窗口移动。首先将A 区域和C 区域移到最下方,然后再将A 区域和B 区域移到最右侧,移动完成之后就可以得到4个独立的窗口,然后再进行MSA 的计算,保证了与W-MSA同样计算量的同时,实现了信息交互。

图3 SW-MSA中窗口移动过程Fig.3 Window movement process of SW-MSA
1.3 轴向注意力模块
W-MSA 将自注意力的计算控制在固定大小的窗口内,通过增加SW-MSA,既减少了计算量,又兼顾了全局信息和局部信息。但在处理高分辨率图像时,Swin Transformer 模块的计算参数依然是比较大的,因此本文的主干部分总共只迭代了12 个Swin Transformer 模块。然而这又会导致缺少足够的全局信息。Ho 等人(2019)提出了轴向注意力模块,该注意力模块只在水平轴与垂直轴两个方向上进行自注意力的计算,通过堆叠两个方向的自注意力建立长依赖关系,因此具有更少的计算。与Swin Transformer 模块相比,轴向注意力模块的计算参数更少,因此本文将轴向注意力模块取代U-Net 中的跳跃连接,在仅增加少量计算参数的情况下,提升网络对全局信息的捕获能力,提高对假阴性的关注。图4 所示为行轴向自注意力的计算过程,对于形状为C×H×W的特征图(其中C为特征通道数),首先分别进行3次卷积操作,通过重塑(reshape)、转置(permute)处理之后得到3 个查询矩阵Q、键矩阵K、值矩阵V,在计算过程分别对应二维矩阵[W,C/2]、[W,C/2]、[W,C],然后代入自注意力的计算公式进行计算,最后再次进行重塑操作后得到原特征图的形状,并添加一个残差连接防止梯度消失。
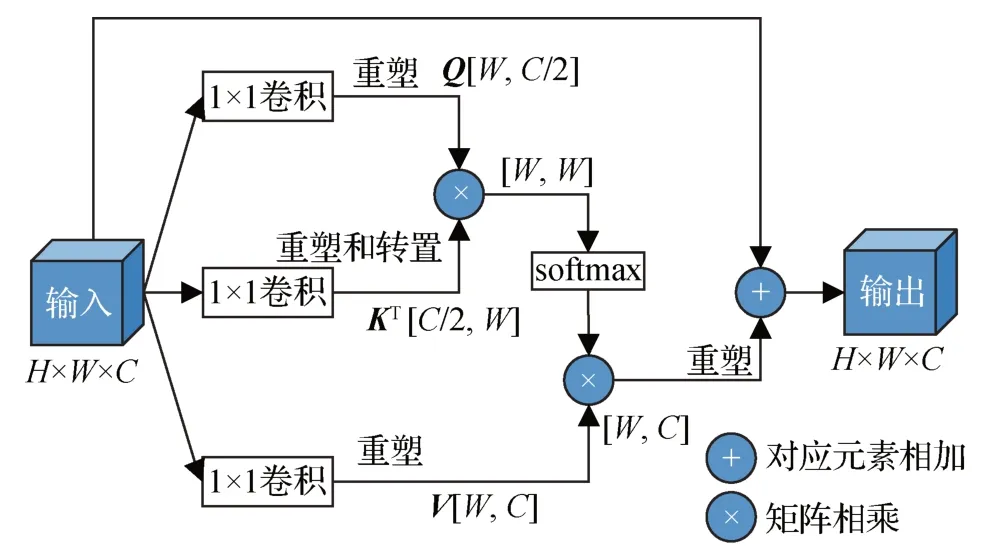
图4 行轴向自注意力的计算过程Fig.4 Calculation process of axial self-attention of rows
1.4 线性前馈模块
与传统卷积神经网络中采用卷积调整通道维度的方法不同,本文提出了线性前馈模块进行通道数的调整,如图5 所示,该模块主要由两个全连接层组成,为了防止过拟合,每个全连接层之前都接一个LN(layer normalization)层进行层归一化,模块的中间使用了一个残差连接防止梯度消失。由于全连接层只在通道上进行,计算量很少。实验部分将对该模块的计算参数,以及过拟合的抑制性能进行分析。

图5 线性前馈模块Fig.5 Linear feed forward module
1.5 解码器
Transformer 能够建立长距离的空间依赖关系,具有比较大的感受野,但是由于W-MSA 自注意力的计算限制在7 × 7大小的窗口内,因此浅层特征的感受野是不够的,包含局部信息的同时,也具有大量的肺部区域等噪声。底层特征既具有足够的感受野,又包含丰富的语义信息,但是分辨率太低。如图6所示,根据前景与前景相乘为前景、前景与背景相乘为背景的原理,能够从浅层特征中过滤出与底层特征相同的区域,并且细化底层特征中的边缘信息,抑制浅层特征中的噪声。通过这样的逐级细化方式,在不需要任何卷积的前提下,就能有效提升网络对局部信息的探索。

图6 相乘的原理Fig.6 Principle of multiplication
因此,本文在解码器部分提出了如图7 所示的特征融合方式进行逐级上采样。X0,X1,X2,X3分别表示主干与轴向注意力模块部分输出的4 个不同尺度的特征图,F0,F1,F2,F3分别对应每一层特征融合后得到的输出。对于某一层融合后得到的特征图Fi,可以表示为:Xi首先与前一层得到的特征图Fi-1相乘,利用Xi中的局部信息对Fi-1中的边缘信息进行细化,然后再与Fi相加,进行特征互补;同时,为了得到更多细化后的特征,Xi-1与Fi-2的细化特征Xi-1×UP(Fi-2)也进行2 倍上采样,与之前得到的输出相加,最终融合后的特征可以表示为

图7 解码器中的特征融合方式Fig.7 Feature fusion method in the decoder
式中,Fi表示第i层特征融合后输出的特征图,UP表示2倍上采样。
Wang 等人(2015)通过在深度神经网络中的某些中间层增加辅助分类器,作为网络分支来对主干网络进行监督,有效地解决了梯度消失和收敛速度过慢等问题。Lin 等人(2017)提出了特征金字塔网络(feature pyramid network,FPN),通过多级预测,证明了深度监督对提升灵敏度是有用的。为了降低网络的学习难度,提高收敛速度,提升网络对假阴性的关注,本文引入了深度监督进行多级预测。如图1所示,在解码器中每一层的输出后都接一个Swin Transformer 模块进行解码,然后用线性前馈模块降维,并上采样到原图大小与真实标签求损失。
2 实验
2.1 实验设计
2.1.1 数据集
本实验采用COVID-19 CT segmentation(Fan 等,2020)和COVID-19 infection segmentation dataset(Fan等,2020)两个数据集。COVID-19 CT segmentation数据集来自意大利医学和介入放射学会,包括60 名新冠肺炎患者的98 幅轴位CT 图像。COVID-19 infection segmentation dataset 数据集包含9 例新冠肺炎患者的638幅切片,其中353幅标记为阳性。
2.1.2 数据预处理
为了便于比较,以COVID-19 CT segmentation 数据集为主,按照Inf-Net 网络中的划分方法,将数据集划分为两部分,其中,训练集50 幅,测试集48 幅。由于训练数据比较少,为了提高网络的鲁棒性,降低过拟合,实验将数据缩放为512 × 512 像素,并进行归一化处理,引入多尺度策略(Wu 等,2019),按照{0.75∶1∶1.25}的比例重新采样训练图像。而COVID-19 infection segmentation dataset 数据集用于泛化性能分析。
2.1.3 评估指标
为了评估该模型的性能,本实验使用了4 个与Inf-Net(Fan等,2020)中相同的指标:Dice系数、灵敏度(sensitivity,SE)、特异度(specificity,SP)、平均绝对误差(mean absolute error,MAE)。其中Dice 系数用于评估预测结果与真实结果的重叠率,灵敏度用于衡量正确识别真阳性样本的比率,特异度用于衡量正确识别真阴性样本的比率,平均绝对误差用于评估预测图和分割标签之间的误差。
2.1.4 损失函数
本文将分割损失函数l定义为加权交并比(intersection-over-union,IoU)损失lIoU和加权二进制交叉熵(binary cross entropy,BCE)损失lBCE之和。具体为
式中,α 和β 分别为IoU 损失和二进制交叉熵损失的加权系数,这里均取1。
由于采用了多尺度监督,解码器每一层的输出都引入伴随目标函数,因此最终目标函数可表示为
式中,G 为真实标签,P 为预测值,l(G,P)为分割标签与解码器输出的分割损失为分割标签与解码器每一层输出的分割损失。
2.2 实验细节及结果
本文网络基于Pytorch 实现,并由RTX3060 GPU加速。使用Adama 优化器进行参数优化,学习率设定为10-4,batch size 设置为4。主干网络采用Swin-Transformer 在ImageNet-1K 上的预训练权重进行初始化。总共训练30 个epoch,大约需要12 min。在48 幅测试集上的评估结果分别为Dice 系数0.789、灵敏度0.807、特异度0.960和平均绝对误差0.051。
2.2.1 定量结果分析
如表1 所示,本文与目前在COVID-19 CT segmentation 数据集上的主流方法进行了对比。其中Inf-Net 提出了边缘注意力模块(edge attention,EA)和反向注意力模块(reverse attention,RA),取得了比较好的分割结果。MED-Net(multiscale encoding and decoding network)通过多尺度编码以及多尺度解码的方式,很好地提升了网络对假阴性的关注。Semi-Inf-Net 提出了半监督的方法解决数据量稀缺的问题。PVTA-Net(pyramid vision Transformer and axial attention network)(周雪 等,2023)首次将Transformer应用于COVID-19 CT segmentation 数据集的分割。Elharrouss 等人(2022)通过级联的方式,先分割可能被感染的区域,然后再分割感染区域,Dice系数和特异度在该数据集上取得了目前最好的效果。在分割精度比较靠前的网络中,除了MED-Net 和PVTA-Net通过自身的网络优势取得了较高的分割精度外,其他方法都不可避免地采用了比较复杂的方法进行数据增强。Semi-Inf-Net 利用了大量未标记的CT 图像生成伪标签,有效地扩充训练数据集,但是生成伪标签的过程非常复杂,且耗时。Elharrouss 等人(2022)通过旋转、缩放的方式将数据扩增到2 000 幅,并且提前分割可能被感染的区域,也是非常耗时。COVID-TransNet 通过充分利用Transformer 的优势,在没有进行任何数据增强的情况下,Dice 系数和灵敏度分别达到了0.789 和0.807,较Semi-Inf-Net 分别提升了5%和8.2%,平均绝对误差(MAE)下降了0.9%。与Elharrouss 等人(2022)取得的目前最先进的结果对比,Dice 系数和灵敏度分别提升了0.3%、9.6%,平均绝对误差(MAE)下降了0.7%,虽然特异度下降了3.3%,但是对于新冠肺炎病变的分割来说,灵敏度是更重的指标。除了特异度以外,均达到了目前最先进的水平。
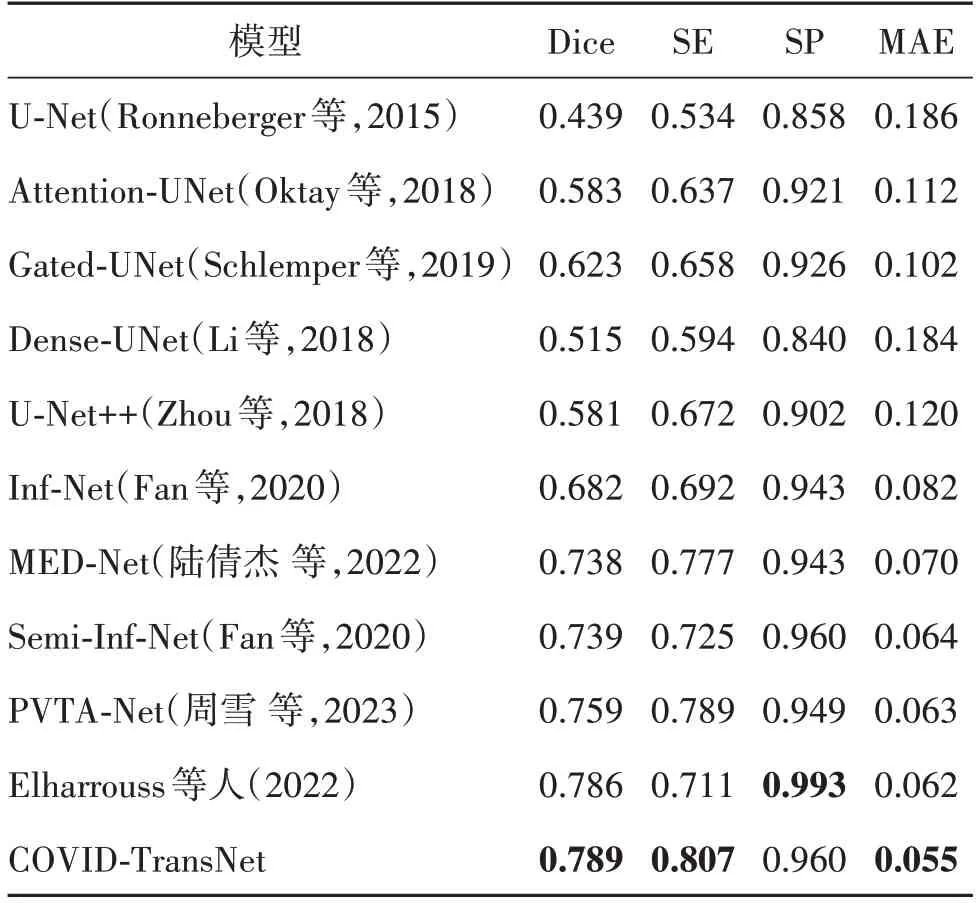
表1 不同模型在数据集COVID-19 CT segmentation上的定性结果Table 1 Qualitative results of different models on the COVID-19 CT segmentation
2.2.2 定性结果分析
为了进一步验证COVID-TransNet 的分割性能,实验结果分别与U-Net、U-Net++(Zhou 等,2018)、Inf-Net、Semi-Inf-Net 的定性结果做了对比。从图8可以看出,COVID-TransNet 表现出最接近真实标签的性能,虽然没有采用类似Transformer 与CNN 结合的方法去增强局部信息,但作为纯Transformer 的结构,依然分割出比较完整的细节信息;整体结构的完整性也证明了Transformer 在长距离依赖方面的优势。

图8 不同模型的定性结果Fig.8 Qualitative results of different models((a)CT slices;(b)U-Net;(c)U-Net++;(d)Inf-Net;(e)Semi-Inf-Net;(f)COVID-TransNet;(g)labels)
2.2.3 消融实验
为了验证解码器中多级预测、轴向注意力模块、Swin Transformer模块的有效性,本文做了消融实验。如表2 所示,通过引入多级预测,Dice 系数和灵敏度分别提升了0.1%、2.8%。灵敏度有较大提升,验证了前文中提到的、深度监督方法能够提升网络对假阴性的关注。在多级预测的前提下,增加Swin Transformer 模块为每个分支解码,Dice 系数和特异度分别提升了0.4%、0.6%。3 个模块同时使用时,Dice 系数和灵敏度分别提升了0.8%、2.5%。而对比整个网络,灵敏度在没有使用轴向注意力模块时下降了1.6%,因此也证明了轴向注意力模块能够提升网络对全局信息的关注。
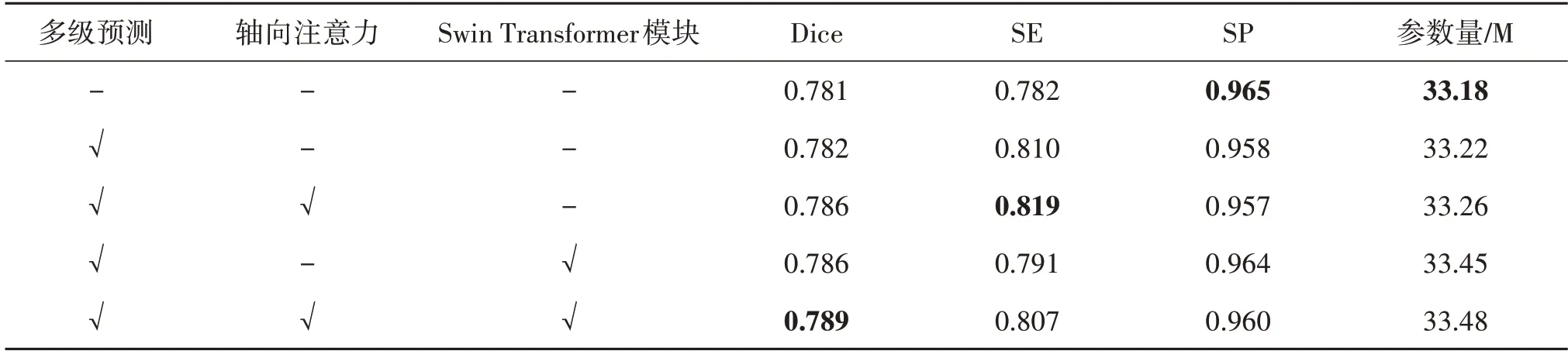
表2 消融实验结果Table 2 Ablation experimental results
为了验证解码器部分特征融合方式的有效性,实验中分别与相加、相乘、拼接的特征融合进行了对比。结果如表3 所示,虽然直接相加的方式灵敏度比较高,但同时也出现了更多的假阳性,局部信息没有得到很好的关注,导致特异度较低。拼接和相乘出现了低灵敏度、高特异度的情况,对于相乘而言,由于高层特征具有更多的细节信息,因此相乘可以从底层特征中过滤出更多的局部信息,但因此也导致丢失了一部分高级语义信息,出现了更多的假阴性,导致灵敏度比较低。本文首先通过相乘的方法细化局部特征,然后相加进行特征互补,最后再加上前一级细化后的特征;通过这样的方式兼顾全局信息与局部信息,灵敏度和特异度实现了比较好的平衡,最终提升了分割精度。

表3 不同特征融合方式的对比Table 3 Comparison of different feature fusion methods
2.2.4 线性前馈模块的参数及过拟合分析
虽然Swin Transformer 中提出了W-MSA,大大减少了计算参数,但是相比CNN,网络参数依然是比较庞大的。由于仅采用50 幅图像进行训练,模型的过拟合问题是难免的。本文提出了线性前馈模块来替换1 × 1卷积进行通道维度的调整,在提升分割精度的同时,有效地缓解了训练过程中的过拟合问题。表4 为3 种不同通道调整方式下的模型参数及分割精度的对比。线性前馈模块相比1 × 1的卷积,整体模型参数提升了0.8 M,但是比3 × 3 的卷积下降了0.21 M。因此相对来说,该模块的参数量并不高,并且分割精度较采用1 × 1卷积提升了1.1个百分点。
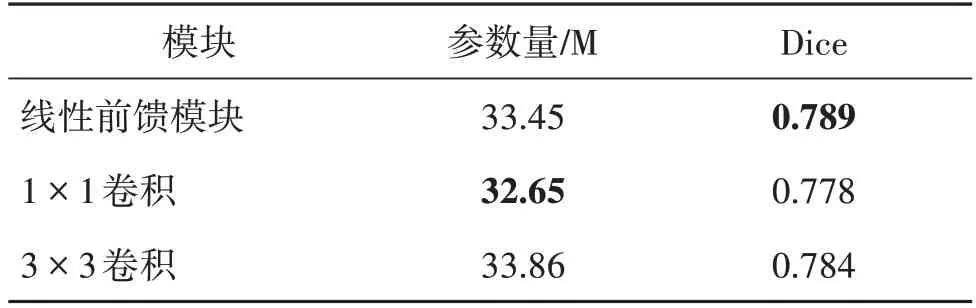
表4 不同特征通道调整方式的对比Table 4 Comparison of different feature channel adjustment methods
不同特征通道调整方式下训练及验证损失的曲线如图9所示。从图9可以看出,相比用卷积进行通道维度调整,线性前馈模块有效缓解了过拟合。1 × 1和3 × 3的卷积都出现了严重的过拟合问题,并且验证损失的波动幅度很大。而采用线性前馈模块时,验证损失的曲线并没有出现较大幅度的波动;在到达最低点后,随着epoch 的增大,损失上涨的趋势得到了较大的缓解。因此线性前馈模块在缓解过拟合问题上是有效的。

图9 不同特征通道调整方式下训练及验证损失的曲线Fig.9 Curves of training and validation losses with different feature channel adjustment methods((a)linear feed forward module;(b)convolution(1 × 1);(c)convolution(3 × 3))
2.2.5 与主流Transformer网络的对比
为了验证COVID-TransNet 在Transformer 领域的分割能力,本文选取了Swin-Unet、MIT-Unet(Wang等,2022)和Med-Net(Valanarasu 等,2021)3 个主流的基于Transformer 的语义分割网络进行实验对比。为了公平比较,将图像缩放到224 × 224 像素,取消{0.75∶1∶1.25}比例的重采样策略。结果如表5所示,与另外3 个基于Transformer 的语义分割网络相比,COVID-TransNet 在Dice 系数、灵敏度和特异度3 个方面都实现了比较大的提升,同时也证明了本文将Transformer 应用于新冠肺炎CT 图像分割的方法是成功的。
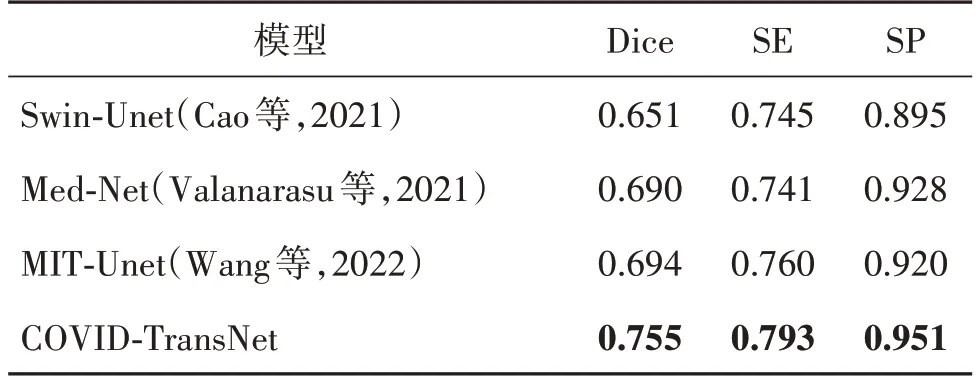
表5 主流Transformer网络在该数据集上的指标对比Table 5 Comparison of metrics of mainstream Transformer networks on this dataset
2.2.6 泛化性能分析
为了验证网络的泛化性能,本文与Semi-Inf-Net一样,选取COVID-19 infection segmentation dataset数据集进行泛化能力的测试。该数据集包含9 例新冠肺炎患者的638 幅切片,其中285 幅切片未感染。由于本实验只采用了COVID-19 CT segmentation 数据集进行实验,网络没有对未感染的切片进行学习,因此泛化能力的测试仅做了两组实验。
第1 组直接对COVID-19 infection segmentation dataset 数据集中感染的353 幅切片进行测试,结果如表6 所示,实现了0.703 的Dice 系数、0.667 的灵敏度、0.982 的特异度,即使在未训练过的数据集上也实现了比较高的分割精度。

表6 COVID-19 infection segmentation dataset数据集的测试结果(Ⅰ)Table 6 Test results for the COVID-19 infection segmentation dataset(Ⅰ)
为了能够与其他网络进行有效地对比,第2组采用Semi-Inf-Net中的伪标签进行训练,学习未感染切片的特征,然后对COVID-19 infection segmentation dataset数据集中的638幅切片都进行测试,结果如表7所示。Dice系数、灵敏度和特异度分别较Semi-Inf-Net提升了10.7%、0.1%和1.3%。结合表6和表7可以证明,COVID-TransNet的泛化性能是可靠的。
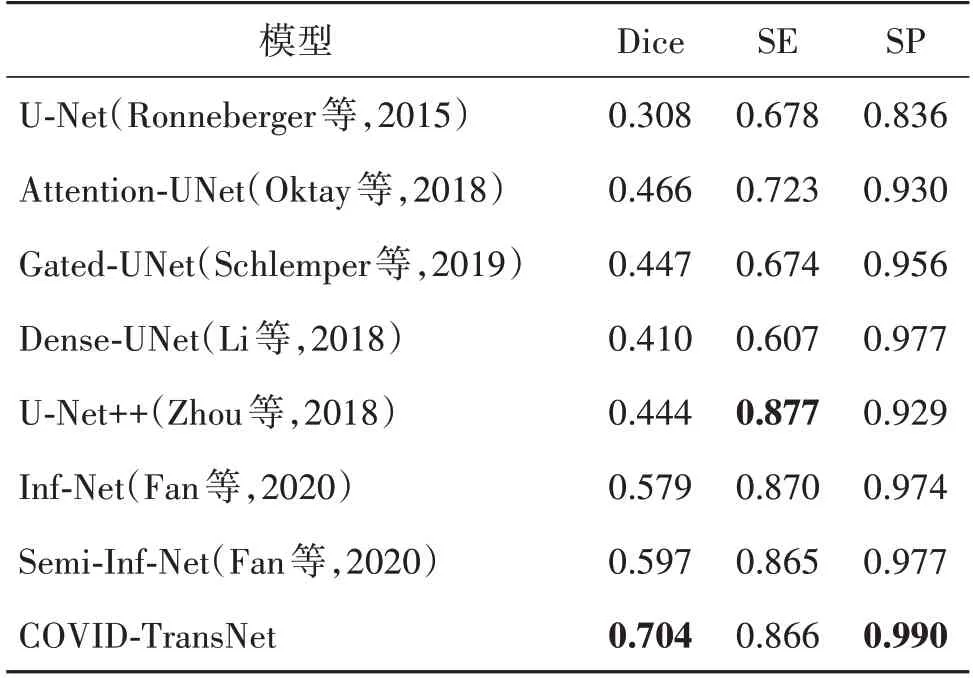
表7 COVID-19 infection segmentation dataset数据集的测试结果(Ⅱ)Table 7 Test results for the COVID-19 infection segmentation dataset(Ⅱ)
3 结论
当前新型冠状病毒肺炎(COVID-19)疫情在全球的蔓延依然很严重,利用深度学习的方法对COVID-19 患者肺部CT 图像中的病变区域进行自动分割,对帮助医生快速准确地诊断COVID-19患者具有重要意义。随着Transformer在计算机视觉领域的发展,它在上下文信息方面的强建模能力能够很好地应对医学图像中病变的多尺度问题,因此本文提出了一种用于COVID-19 患者胸部CT 图像分割的Transformer 网络。在编码器部分以Swin Transformer为主干,提取丰富的上下文信息;在解码器部分提出了先增强全局信息,再在上采样的过程中逐级细化局部信息的方法,很好地在灵敏度和特异度之间取得了平衡,在保持高特异度的同时,有效提升了灵敏度。在没有进行任何数据增强的情况下,Dice 系数和灵敏度在COVID-19 CT segmentation 数据集上均取得了目前最好的结果。为了解决小数据集存在的过拟合问题,提出了线性前馈模块,通过对验证损失曲线的分析及泛化能力的测试,证明了它能够有效地抑制过拟合问题,并且在泛化能力的测试中,Dice系数较Semi-Inf-Net提升了10.7%。
虽然COVID-TransNet 取得了比较好的分割结果,但还存在以下问题:1)由于受限于硬件设备,本文只选取了Swin Transformer 中最小的主干进行分析,Swin Transformer的优势没有得到充分发挥;2)没有在数据集的预处理方面进行研究,网络的潜力没有充分体现;3)在多级预测中直接将Swin Transformer 模块用于解码最后的输出,增加了较多的计算参数。在未来的研究中,将考虑如何对数据进行有效的扩充和增强,以充分挖掘本文网络的潜力;其次在多级预测部分探索轻量级的方法。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
制造技术与机床(2018年12期)2018-12-23 02:40:50
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
探测与控制学报(2015年4期)2015-12-15 15:00:48
