
SA-TF-UNet:基于空间注意力机制和Transformer的MRI海马体分割
2023-10-24 13:58欧宇轩高敏赵地刘军
中国图象图形学报 2023年10期
欧宇轩,高敏,赵地,刘军
1.中国科学院计算技术研究所,北京 100190;2.北京邮电大学国际学院,北京 100876;3.中南大学湘雅二医院放射科,长沙 410011;4.中国科学院大学计算机学院,北京 100049
0 引言
阿尔兹海默症(Alzheimer’s disease,AD)是一种神经系统退行性疾病(McKhann等,1984),发生于老年和老年前期。主要临床表现为不同程度的记忆障碍,语言障碍,运动障碍等,总体表现为痴呆性局面(Clark 等,2021)。随着社会发展,我国老龄化速度加快(Jiang 等,2021),AD 患病率也逐渐上升(Zeng等,2021)。根据《世界阿尔兹海默症2018 年报告》,全球大约每3 s就有一位患者确诊阿尔兹海默症,目前全球至少有5 000 万AD 患者,到2050 年,这个数字将会增长至1.5 亿。而且,AD 的发病因素有很多(Tennakoon 等,2022),大部分AD 患者被查出确诊,已到达晚期(Du 等,2021)。因此,AD 的早期防治与诊断有很高的临床以及社会价值(Liu等,2022)。研究表明,阿尔兹海默症的发病与海马体的形态变化有关(Lukiw,2007)。
磁共振成像(magnetic resonance imaging,MRI)是一种无创的神经影像学技术(Pflugfelder 等,1985),它在AD 早期诊断研究中发挥着重要作用(Frisoni 等,2010)。图像分割是分析医学影像中解剖结构的第一步(Safaei 和HabibiAsl,2021),随着医学影像数据的增加,传统的处理方式,即由医生独立完成医学影像分析将面临巨大挑战,而基于深度学习的医学影像分析将有效解决这一难题(Ma 等,2021)。医学影像分割,即语义分割在医学影像上的应用,是当今计算机视觉中最重要的研究方向之一(陈弘扬 等,2021a)。它可以将目标区域从医学影像中分割出来(Bruno 等,2021),用于辅助医生进行后续诊断与治疗(赵春艳 等,2022)。
近年来,卷积神经网络(convolution neural network,CNN)在医学影像处理中大量应用(Gaur 等,2021)。在众多CNN 结构中,U-Net(Ronneberger 等,2015)提出一个编码—解码框架,编码器对输入图像进行特征提取,提取出feature map,再通过解码器恢复至原尺寸,进行逐个像素点的分类。为了弥补编码器下采样阶段丢失的信息,U-Net用跳跃连接层连接每层的编码器与解码器,使解码器在上采样时能够保留高层特征图中的高分辨率细节信息,从而更完善地恢复出输入图像中的细节信息,以此来提升模型对于细节信息的预测精度。attention U-Net(Oktay 等,2018)是基于U-Net 的一种改进结构,它在跳跃连接处加入了注意力门(attention gate,AG),可以有选择性地学习输入图像中相互关联的区域,抑制不相关区域。然而,卷积的感受野大小使卷积运算具有局部性。大多数医学分割的目标形态不规则,因此,CNN 在处理医学影像分割的任务上有一定局限性。自注意力机制(self-attention)(Vaswani等,2017)是一种考虑全局信息的注意力机制。基于自注意力机制的Transformer模型因其可以提取全局上下文信息的优势最早应用于自然语言处理(natural language processing,NLP)领域,在Vision Transformer(Alexey 等,2021)中首次应用于计算机视觉领域,之后广泛应用于各种视觉任务中(Song 等,2021)。
本文采用U-Net 的编码—解码结构,使用Transformer 模块作为编码器,先使输入图像转化成一个序列,利用自注意力机制融合全局信息的能力,基于全局信息建模,进而提取特征,从大量信息中筛选出少量重要信息并聚焦在这些重要信息上,有利于分割形状不规则的目标。使用AG 模块让网络自动聚焦在包含目标结构的像素上,增加小像素目标的分割精度。
1 方 法
1.1 网络的整体结构
本文提出了一个基于Transformer 模块与AG 模块的端到端的海马体分割网络SA-TF-UNet(hippocampus segmentation network based on Transformer and spatial attention mechanisms)。该网络可以输入任何像素大小的3 维脑部医学影像数据,输出与输入数据像素大小相同的预测结果,网络总体结构如图1 所示(Hatamizadeh 等,2022)。其中,所有的AG门控信号都由比特征图更深一层的Transformer 得到,输入图像中的4 个通道为H、W、D和4,代表高、宽、深和通道。

图1 SA-TF-UNet 结构Fig.1 Structure of SA-TF-UNet
SA-TF-UNet 采用Transformer 结构作为编码器,使用普通的反卷积结构(Lai 等,2017)作为解码器,对特征图进行上采样,并用带有attention gate的跳越连接结构连接每一级的编码器与解码器。SA-TFUNet网络共有4层,在解码器中,每层的浅层特征图与深层特征图都由AG 模块进行融合。每个AG 模块的门控信号都由比特征图更深一层的Transformer模块输出得到。AG可以突出目标信息,削弱冗余信息的影响,原因是门控信号(g)是由比特征图(xl)更深层的Transformer 层提取出的feature map,深层feature map 包含更多抽象特征(Natarajan 等,2020),更聚焦于目标区域。
1.2 Transformer模型
Transformer 可以处理数值型一维序列数据(Vaswani 等,2017)。假设输入图像尺寸为H×W×D×C,为了使输入数据符合Transformer 可以处理的数据结构,将原图x∈RH×W×D×C均匀切割为大小为P×P×P的小块(patch),且这些小块间两两不重叠,再将输入数据展开,得到一维序列xv∈其 中N为 patch 的个数,N=(H∙W∙D)/P3。此时,这些1D 序列只包含语义信息,不包含输入序列在原始输入图像中的位置信息,因此,需要一种方式将原图中的位置信息合并到Transformer 中。本文使用位置编码加入位置信息,其中,位置编码序列Epos∈RN×K为可学习的参数,并采用随机初始化的方式为位置编码赋初始值。利用向量E∈将输入序列xv映射到K维向量空间,再与位置编码相加,得到Transformer模块的输入z0。这样,z0既保留了原图中的语义信息,又保留了原图中的绝对位置信息(Zheng等,2020)。具体为
编码器使用12 个Transformer 模块提取特征。Transformer 模块的具体结构如图2 所示(Dosovitskiy等,2020)。

图2 Transformer 模块Fig.2 Transformer block
Transformer 模块由多头自注意力与多层感知机组成,其中最主要的特征提取结构是多头自注意力机制(multi-head self attention,MSA)。自注意力机制用于处理输入是一个序列、输出也是一个序列的编码问题(sequence to sequence)。假设输入序列为I=[x1,x2,x3,…,xn],即总输入I由x1,x2,x3,…,xn这n组向量组成。在self-attention 中,计算每两个输入向量x 之间的相似度,得到一组权重,进而得到用x1,x2,x3,…,xn来表示x 的加权值。具体做法为,每一个输入向量乘以一个矩阵W 得到嵌入向量a1,a2,a3,…,an,接着,每一个a1,a2,a3,…,an分别 与3 个变换矩阵Wq,Wk,Wv做点乘,生成查询(query,Q),键(key,K)与值(value,V)。以e1为例,具体为
通过Q 与K 做点乘可以得出每两个输入向量之间的相似度α,相似度再与V 做点乘,得到加权后的向量,具体计算为
式中,dk为Q、K矩阵的维度。总结self-attention 的计算方式是先根据query 和key 计算两者的相似性,对代表相似性的值进行归一化处理,得到权重系数。再根据权重系数对value 进行加权求和,得到attention value(SA(e))。
为了学习多重语义含义的表达,将输入序列映射到多个表示空间,Transformer 模块采用多头自注意力机制(MSA)的运算。MSA 由m个独立selfattention运算连接(concatenate),具体为
式中,a 为输入向量,SA1,SA2,…,SAm为m个独立的自注意力运算。
Transformer 模块的输出定义为
式中,zl-1,zl为第l层Transformer模块的输入序列与输出序列。MLP(multilayer perceptron)为多层感知机,由输入层、隐藏层与输出层构成,相邻层所包含的神经元之间通常用“全连接”方式进行连接。在多头注意力与多层感知机前使用layer normalization,加快模型收敛速度。
1.3 Attention Gate
在编码器与解码器之间的连接,应用attention gate(AG)结构来自动提取感兴趣的区域,AG 模块的结构如图3所示(Schlemper等,2019)。

图3 SA-TF-UNet中AG模块结构Fig.3 Attention gate structure in SA-TF-UNet
传统的语义分割网络中,小目标分割任务的表现不佳。一种常见的解决方法是网络叠加,即先用一个目标检测网络定位目标区域,再使用分割网络在该区域中分割目标。这样做会导致重复特征提取,造成计算资源浪费(陈弘扬 等,2021b)。AG 模块可以在不增加计算量的条件下使网络自动强调特征区域,削弱不含分割目标的背景区域。AG使用输入特征图(xl)与门控信号(g)计算注意力权重α∈[0,1],α越大则表明目标越有可能存在。α与输入特征图相乘得到AG模块的输出。
AG模块的具体做法为
式中,Up为将g上采样至与xl大小相同,σ1和σ2分别为ReLU 函数与sigmoid 函数。本研究聚焦于像素级海马体分割,故AG中卷积核大小为1 × 1 × 1。
2 实 验
2.1 数据集
本文实验用到的医学影像数据集是中南大学湘雅二医院提供的脑部MRI 临床数据,共104 幅,图像大小为256 × 256 × 256像素,其中52幅为原始脑部MRI 影 像,52 幅为由医生用3D Slicer(Pieper 等,2004)软件制作的类别标签,标注区域为左侧海马体与右侧海马体以及背景。数据格式均为.nrrd文件。标注结果经医生审核并通过。标注结果如图4 所示,其中绿色部分与黄色部分为海马体的标签,标注及审核由医生完成,绿色、黄色标签分别为左海马与右海马,棕色为右侧内嗅皮层,蓝色为左侧内嗅皮层(本研究并未涉及内嗅皮层)。由于本数据集为三维数据集,且覆盖了具有代表性的规模样本,因此本数据集的数据量适合本研究。

图4 实验中临床脑MRI数据集的海马体标注切片图Fig.4 Hippocampus annotation of clinical MRI scans in this experiment
2.2 实验流程
将数据集划分为训练集与测试集,按8∶1划分成48 幅训练集与6 幅测试集。划分方式为由1~52 这52个数中随机得到6个数的方式(Xu和Tamir,2019)划分。为了验证本文模型的有效性,使用SETR(segmentation Transformer)(Zheng 等,2020)和UNETR(UNet Transformers)(Hatamizadeh等,2022)模型为对照。每个模型的分割分别进行3组独立实验。
训练过程中采用的损失函数为DiceCELoss,DiceCELoss 为Dice 损失函数(Dice loss)(Milletari等,2016)与交叉熵损失函数(cross entropy loss)的结合。Dice 损失函数最先由Milletari 等人(2016)在VNet 中提出,后广泛应用于医学影像分割任务中。医学分割目标像素较小,而Dice 损失函数在输入图像中正负样本数量不均衡的情况下有不错的性能,训练过程中侧重对前景区域挖掘,因此适用于海马体分割任务。Dice损失函数的定义为
式中,y 为真实标签的集合,p 为网络预测值的集合,ε是一个极小的常数,防止分母为零,并且平滑损失函数。交叉熵损失函数的定义为
式中,M为类别数,yc是一个one-hot 向量,元素只有0和1两种取值,如果预测类别与标签中类别相同则取1,反之取0,pc表示预测样本属于c类的概率。DiceCELoss的计算式为
式中,λ1和λ2为权重系数,在本实验中,λ1=λ2=1 。
通过随机剪裁,获得大小为96 × 96 × 96 的输入图像,MSA 采用12 头自注意力机制,迭代次数为50 000,每250 轮验证一次。实验采用GPU 为1 张Nvidia Tesla V100,显存为32 GB,batch size=1,学习率初始值为0.000 1,weight decay 为0.000 01,使用AdamW作为优化器。
2.3 评价指标
本文实验中评价指标使用集合相似度度量函数Dice系数。Dice系数通常用于计算和评估两个样本的相似度。在医学图像分割中,最好的分割结果Dice 系数是1,最坏的分割结果Dice 系数是0。Dice系数的计算式为
式中,|y∩p |表示真实标签的集合与预测值的集合的交集,|y∪p|为真实标签的集合与预测值的集合的并集。
本研究的主要目的为验证SA-TF-UNet 算法在海马体分割任务上的有效性,并不聚焦于医学诊断,所以采用Dice 系数作为评价指标,用以有效反映预测结果与本研究真值的相关程度,体现算法在本任务上的准确性。
2.4 实验结果
不同网络在脑MRI 数据集上左、右海马体分割的Dice 系数对比如表1 和表2 所示。由表1 和表2中的实验结果可知,在左右海马体分割任务中,分割效果最好的网络是SA-TF-UNet,左侧海马平均分割精度是0.900 1,高于UNETR 2.82%,右侧海马平均分割精度是0.909 6,高出UNETR 3.37%,且SA-TFU-Net 均方差最低,说明加入AG 对于海马体的分割有显著提升。而SETR 则与UNETR 和SA-TF-U-Net相比Dice系数差别较大。与传统CNN 方法U-Net比较,在左右海马体分割任务中,SA-TF-UNet 分割结果Dice系数均比3D-UNet高。

表1 不同网络在脑MRI数据集上左海马体分割的Dice系数对比Table 1 Comparison of Dice coefficient of left hippocampus among different networks

表2 不同网络在脑MRI数据集上右海马体分割的Dice系数对比Table 2 Comparison of Dice coefficient of right hippocampus among different networks
图5 为不同网络输出的分割结果的切片,其中有两个突出边缘,分别由红色、白色箭头所指,黄色为左侧海马体,蓝色为右侧海马体。可以看出,在切片区域右海马(蓝色标注区域)呈现不规则形状,用白色箭头与橙色箭头分别标出了该区域的两个突出不规则轮廓,SA-TF-UNet 与真值比较,边缘最相似,也呈现了与真值相同的形状,由箭头所指两个区域轮廓分割准确。而UNETR 则只分割出了部分边缘,由橙色箭头所指,白色箭头所指区域未能准确分割,而SETR 分割的轮廓则非常模糊。
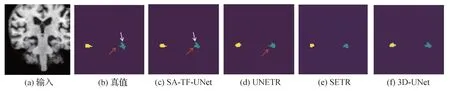
图5 各网络分割结果切片Fig.5 Slicing of segmentation results for different networks((a)input;(b)ground truth;(c)SA-TF-UNet;(d)UNETR;(e)SETR;(f)3D-UNet)
图6为网络输出结果中不同样本的不同切面,在每组图像中,分割效果最好、与真值最相似的均为SATF-UNet分割结果。综合以上分割结果,SA-TF-UNet表现出了较高水准,相比其他网络显著降低了误分割的像素个数。

图6 不同样本分割各网络分割结果Fig.6 Visualization of segmentation results of different segmentation methods((a)input;(b)ground truth;(c)SA-TF-UNet;(d)UNETR;(e)SETR;(f)3D-UNet)
2.5 消融实验
为了验证在每层网络均加入AG 的必要性,设计了一组消融实验。为了与SA-TF-UNet 进行对比,设计了3 个仅在单层加入AG 的网络模型,如图7 所示。3 个网络称为layer2、layer3 与layer4,分别代表其仅在第2、3、4 层加入AG。结果如表3 和表4 所示。可以看出,仅加入单层AG 效果与SA-TF-UNet有一定差距,原因是仅加入1 层AG,网络对浅层网络提取出来的信息没有进行足够的复用,前景没有得到有效的强调。

表3 单层AG与多层AG网络在脑MRI数据集上左海马体分割的Dice系数对比Table 3 Comparison of segmentation results of networks with single layer AG and multi-layer AG on left hippocampus

表4 单层AG与多层AG网络在脑MRI数据集上右海马体分割的Dice系数对比Table 4 Comparison of segmentation results of networks with single layer AG and multi-layer AG on right hippocampus
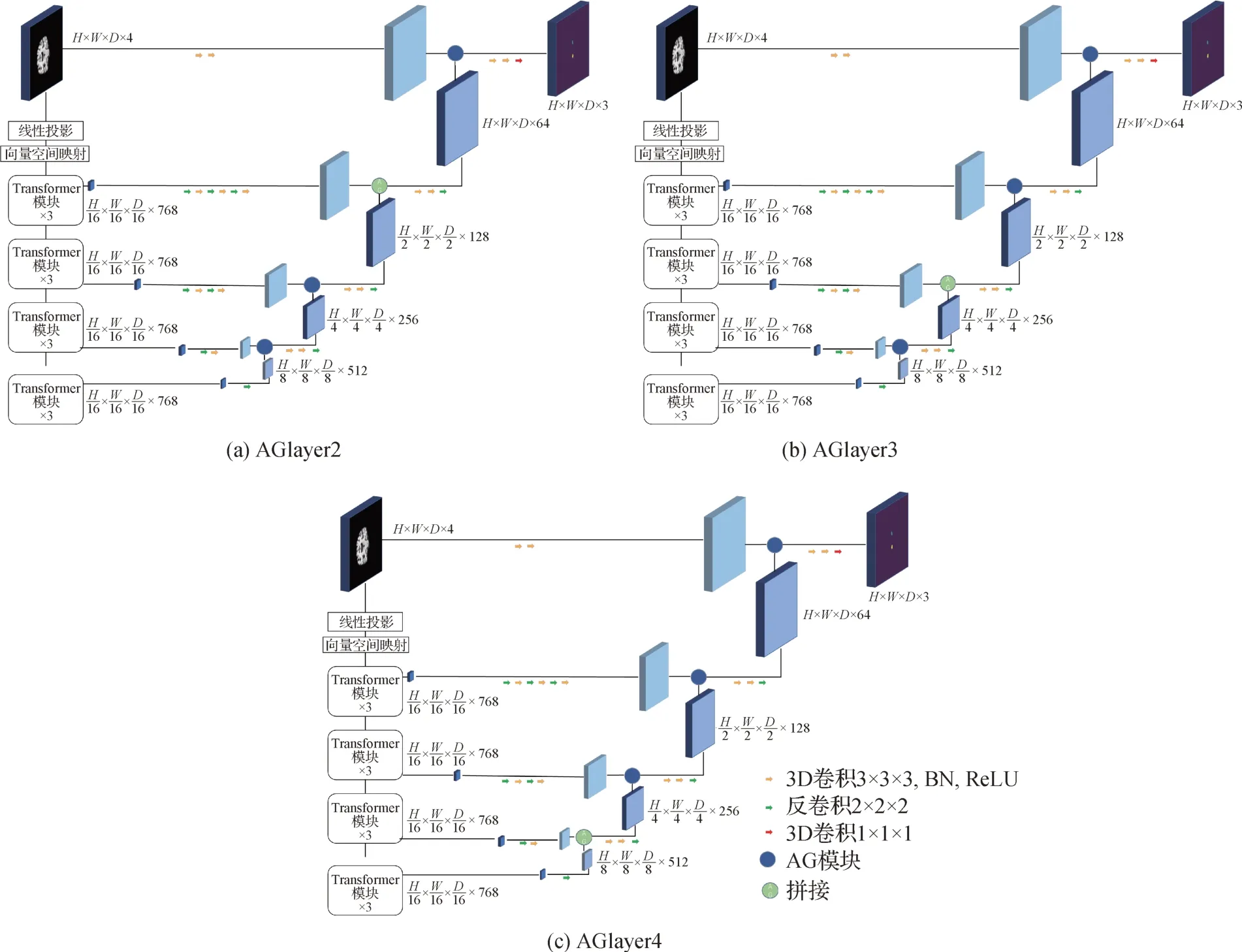
图7 仅加1层AG的网络结构图Fig.7 Network structures for only one AG((a)AGlayer2;(b)AGlayer3;(c)AGlayer4)
第1 组消融实验验证AG 的门控信号来源。为了保证门控信号是由比特征图所在层更深的Transformer 层提取出来的,设计了两种SA-TF-UNet 的变体,如图8 所示。在这两种结构中,通过改变AG 中的门控信号(g)来确定对于海马体分割任务的最佳网络结构,它们分别将从下向上第2 和第3 个AG 的门控信号替换为由最深层的feature map 上采样得到,实验结果如表5 和表6 所示。可以看出,两种变体的3 次实验的平均Dice 系数均低于SA-TF-UNet,且均方差大于SA-TF-UNet。这组实验验证了SATF-UNet 结构,其中所有AG 模块的门控信号都由比特征图更深一层的Transformer模块输出得到。

表5 SA-TF-UNet与变体网络在脑MRI数据集上右海马体分割的Dice系数对比Table 5 Comparison of segmentation results of SA-TF-UNet and its alternatives on left hippocampus

表6 SA-TF-UNet与变体网络在脑MRI数据集上右海马体分割的Dice系数对比Table 6 Comparison of segmentation results of SA-TF-UNet and its alternatives on right hippocampus
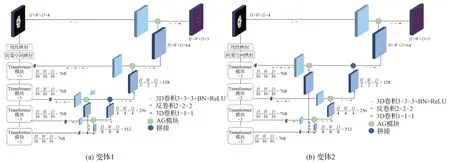
图8 两种SA-TF-UNet的变体Fig.8 Stucture of SA-TF-UNet for alternatives((a)alternative 1;(b)alternative 2)
3 讨论与分析
相关脑部研究证明了大脑左右半球分管任务的区别,即虽然大脑左右半球具有相似的结构,但在功能上却有所不同。左半球是处理语言、进行抽象思维、集中思维、分析思维的中枢。而右半球则是处理表象和进行具体形象思维、发散思维的中枢。因此本实验将左右海马体作为两个分割任务进行。在3 次独立重复实验中,右海马体分割Dice 系数最高的均是SA-TF-UNet。而且SA-TF-UNet 分割结果的样本方差最低,显著低于SETR 与UNETR。这一结果验证了将AG 加入由Transformer 为编码器的网络中,对于分割精度有较高的提升。AG中的门控信号为更深的Transformer 层的输出,深层Transformer 可以提取更抽象的特征,该深层特征标注了分割目标所在的位置,因此AG 使输入特征图强调前景,降低对背景的注意,达到自动提取感兴趣的区域的效果。AG 被加入到U 型网络中后,从编码器传递给解码器的显著特征通过跳跃连接被突出。从粗尺度中提取的信息用于门控信号,可以消除跳跃连接中传递的不相关信息和噪声为分割任务带来的干扰。由第1组消融实验可知,每一层网络都加入AG 模块,分割效果比只加入1 个AG 有显著提升。由第2 组消融实验可知,相邻层的两个Transformer 模块输出的feature map,分别作为特征图与门控信号的AG 结构效果最好,网络性能提升最明显,网络也最稳定。在这种AG 中,门控信号只被上采样了1 次,位置信息保留相对完整。而在两种变体中,AG中的门控信号分别被上采样了2次与3次,细节信息在多次上采样的过程中存在丢失现象,因此影响了AG 的效果。在SA-TF-UNet 以及UNETR 与SETR 的精度差可知,将编码器中输出的浅层特征连接到解码器中,有利于特征定位,产生更精确的分割结果。由分割结果图的边缘分割情况可知,SA-TF-UNet 分割的边缘最清晰,而UNETR与SETR对边缘的分割精确度较低。
4 结论
本文基于医学图像分割经典网络U-Net 的编码—解码网络结构,以及连接编码器与解码器的跳跃连接层,用Transformer 中的自注意力机制代替传统编码器中通过卷积层来提取特征,并结合attention U-Net 中提出的AG 模块,提出一种新的海马体分割网络SA-TF-UNet。为了验证该网络的有效性,在脑部MRI 数据集上进行了3 组独立重复实验,得出如下结论:
1)该网络中的自注意力机制可以有效地对全局信息和局部信息进行建模,提取全局和局部特征,有利于分割形状不规则,大小不确定的目标。
2)网络中的空间注意力机制通过自动使目标区域获得更大权重来有针对性地优化困难样本,提升小目标分割精度。该网络对于左海马体与右海马体的分割,3次实验平均Dice系数为0.900 1与0.909 1,实现了对海马体的精准分割。
3)在本临床数据集中,该网络的海马体分割表现最好,它在每一层中都加入了AG,有效融合了深层和浅层特征,并且在每一个AG 中使用了相邻两个Transformer模块的输出作为特征图和门控信号。
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09
作文周刊·小学二年级版(2022年20期)2022-05-05
中国临床医学影像杂志(2021年10期)2021-11-22
中国医学影像学杂志(2021年6期)2021-08-13
创新作文(小学版)(2019年10期)2019-09-25
成都信息工程大学学报(2018年3期)2018-08-29
小学生学习指导(低年级)(2017年5期)2017-05-04
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
