
运动特征激励的无候选框视频描述定位
2023-10-24 13:57郭义臣李坤郭丹
中国图象图形学报 2023年10期
郭义臣,李坤,郭丹
1.合肥工业大学计算机与信息学院,合肥 230601;2.大数据知识工程教育部重点实验室(合肥工业大学),合肥 230601;3.智能互联系统安徽省实验室(合肥工业大学),合肥 230601
0 引言
互联网上的视频数量正经历爆发式的增长,准确理解和分析视频内容在计算机视觉领域中有重要意义。视频描述定位作为视觉领域中的一项重要任务,目标是从一段未修剪的视频中,定位出与给定自然语言描述语义匹配的视频片段。与单一视频模态的研究相比,视频描述定位需要同时从视频和文本两个模态中挖掘信息,因此具有更广泛的应用场景和潜在的应用价值。然而,视频描述定位面临着极大的挑战,一方面,视频具有场景复杂以及活动多样性的特点,相比图像,视频的内容和背景更加复杂多变,一个几分钟的视频往往由多种活动组成,而每一个活动又由不同的人物、目标和运动组成;另一方面,人类的自然语言存在多义性和主观性,而且存在多个活动之间的约束关系,如活动发生先后的时序约束关系。因此,如何构建合适的视频—文本多模态特征是解决自然语言描述与目标视频片段匹配的关键所在,这要求模型能够在自然语言查询中挖掘出重要的语义线索,同时抑制视频中冗余且复杂的背景信息、激励出与语言查询语义匹配的运动特征。
现有的视频描述定位任务主要有基于候选框和无候选框两种方式。基于候选框的方法通常使用滑动窗口生成候选框然后匹配自然语言描述(Gao 等,2017;Hendricks 等,2017),这类方法会首先生成一系列候选视频片段,然后通过度量候选片段与文本查询的语义距离来选取最佳的目标片段;滑动窗口算法虽然能够选出一些可以覆盖目标的候选片段,然而这类方法未能对视频细粒度进行建模,忽略了视频与语言查询之间存在的丰富的动作信息。为了对视频与语言模态进行细粒度的建模,一些研究人员聚焦于从语言模态中挖掘出重要的动作概念(Ge等,2019;Zhang 等,2019b),这类方法通常使用注意力等方法对句子中的语义概念进行编码,获得句子中动作概念的嵌入特征表示,对动作概念的引入很好地解决了传统方法中对视频与语言查询的建模不够细粒度的问题,有效提高了视频与文本模态之间的对齐准确性。
然而,基于候选框的多数方法通常使用滑动窗口算法枚举可能出现的目标片段,这样的方法需要耗费大量的内存空间以及计算资源。在该问题的驱动下,另一种无候选框的方式应运而生,Yuan 等人(2019)和Rodriguez-Opazo等人(2020)引入注意力机制实现视频与语言描述之间的跨模态信息交互,学习视频与文本的联合特征表示,以一种端对端的方式直接预测出目标片段的始末时刻。Mun 等人(2020)和Li 等人(2021)则关注不同尺度下的上下文信息,最后使用时序注意力回归的方法预测出目标片段。上述的无候选框模型在兼顾效率的同时取得了令人满意的性能,然而,这些工作忽略从视频中挖掘运动线索,所以难以构建出细粒度的视频—文本多模态交互特征。
针对上述的弊端及挑战,本文提出一种新颖的基于运动特征激励的无候选框视频描述定位模型。具体来说,本文首先使用基于注意力机制的方法提取自然语言描述中的多个短语级特征,分别与视频特征进行跨模态融合,从而得到视频—文本多模态特征表示。其次,本文从时序维度和特征通道两个方面优化多模态特征表示,从而增强多模态特征中的运动语义的表征能力。一方面,本文使用跳连卷积从时序维度上建模运动特征的局部上下文信息,将语义短语与相应的运动特征对齐;另一方面,本文通过计算相邻特征向量之间的特征通道级的差异,得到连续特征中的运动语义信息,以区分表示运动语义的特征和静态背景的特征。进而,本文使用门控机制(Hu 等,2018)动态调整不同特征的强度,增强特征中运动语义的表征能力。换言之,先通过相邻两帧多模态特征之间的通道差异,再生成特征通道上的权重,从而自适应地校正通道的强度,激励其中蕴含运动信息的特征通道。最后,本文采用非局部神经网络和时序注意力池化模块对优化表示的多模态特征进行融合,以无候选框的方式预测出目标片段的始末时间。
本文的主要贡献是:1)基于运动特征激励的方法优化多模态特征表示中的运动语义信息,有效增强了运动信息语义的表征能力;2)以一种无候选框的方式实现了细粒度的视频描述定位,在确保预测精度的同时避免生产大量无效候选框;3)在Charades-STA(Gao 等,2017)和ActivityNet Captions(Krishna 等,2017)两个基准数据集上的对比实验验证了本文方法性能优于对比模型,消融实验进一步验证了本文方法的有效性。
1 相关工作
1.1 视频描述定位
Gao 等人(2017)首次提出视频描述定位任务,该任务的难点在于视频与查询之间的模态差异,因此需要对视频和语言查询构建合适的特征表示,从而实现视频与语言两个模态之间的匹配。早期方法的思想多来自于目标检测任务基于候选框的方法,首先提出丰富的目标候选框,然后选出与语言查询语义相关度最高的候选框作为预测结果。Liu 等人(2018a,b)提出的注意力跨模态检索网络(attentive cross-modal retrieval network,ACRN)和跨模态时刻定位网络(cross-modal moment localization network,ROLE)聚焦于自然语言查询中包含时间线索的单词,希望通过利用文本与视觉之间的相关性,联合学习视频片段与查询的特征表示,是基于候选框方法的典型代表。Chen 和Jiang(2019)认为传统方法采用朴素的滑动窗口方法,未考虑到如何生成有效的目标候选框,这导致候选框数量冗余且模型低效,因而提出语义活动提议(semantic activity proposal,SAP)的方法,将语言查询中的语义信息融合到候选框生成过程中,提升了目标候选框的质量。Zhang等人(2020)提出二维时序邻接网络(2D temporal adjacent network,2DTAN),认为基于候选框的方法未能考虑不同候选框之间的关系,提出一种基于二维时间图的网络模型,能够对相邻的候选框进行编码,从而学习到对多模态匹配更有区别性的特征表示。
近年来,为解决基于候选框方法中的计算量过大的问题,一些无候选框的模型相继提出。无候选框模型直接回归出目标片段的起止时间戳,不存在候选框的生成和排序。Yuan 等人(2019)提出基于注意力定位回归(attention based location regression,ABLR)的方法,通过学习视频与文本之间相互的注意力,得到包含全局信息的特征表示,并在视频中定位出语言查询对应的目标片段。Rodriguez-Opazo 等人(2020)提出使用基于注意力的动态过滤器,使模型根据语言查询动态响应不同片段的视频特征,不依赖于候选区域的生成和排名,而是端对端地预测出目标片段。Mun等人(2020)进一步研究了视频与文本的交互,首先基于注意力机制提取语言查询中的不同语义实体(如人物、目标、动作),并从视频片段、局部尺度上下文和全局尺度上下文3 个层级进行语义短语与视频之间的对齐,最后融合视频—文本特征并使用无候选框的方式预测最终的结果。CPNet(contextual pyramid network)(Li 等,2021)使用层级金字塔的方法提取多尺度的二维时序上下文关系图,通过扩大时序上的感受野来精确定位语言查询在视频中对应的位置。本文致力于优化视频—语言多模态特征的运动语义表征能力,基于无候选框的直接回归方式实现更精准的视频描述定位。
1.2 运动激励
运动信息是视频相对于静态图像的显著区别,因此在视频理解的相关任务中,运动信息扮演着至关重要的角色。为了对视频中的运动信息进行编码,时序片段网络(temporal segment network,TSN)(Wang 等,2016)通过计算原始视频中相邻两帧的RGB 差异,提取出视频中的光流特征,然后送入基于二维卷积神经网络(2D convolutional neural network,2D CNN)的双流网络框架中,以用于运动识别。然而,这类基于光流特征来提取运动信息的方法常常存在占用计算资源过大的问题。Jiang等人(2019)提出的通道运动模块(channel-wise motion module,CMM)可对视频中的运动信息编码,在激励运动特征敏感通道的同时,避免了预计算光流特征的使用。
为了激励特征表示中的重要信息,研究人员展开多种探索。Hu 等人(2018)聚焦于视频序列特征图中不同通道权重的修正与重要特征图的激励,提出SENet(squeeze and excitation network),通过显式地对通道之间的依赖进行建模,自适应地修正特征表示中不同通道的响应。受SENet 的启发,Li 等人(2020)提出运动激励模块对视频的时空特征图中的运动信息进行建模,利用相邻两帧的时空特征图差异激励运动敏感的特征通道。对视频描述定位任务来说,如何激励多模态特征中的运动特征同样重要,因此本文将运动激励模块插入到多模态特征提取模块之后,进行细粒度的视频片段与文本描述交互,从而实现更精准的视频描述定位。
2 本文方法
如图1 所示,本文方法由3 个部分组成:特征提取模块、特征优化模块和边界预测模块。其中特征提取模块用于对视频和语言查询的特征提取以及特征的融合;特征优化模块主要由运动激励和跳连卷积两部分组成,运动激励用于动态调整多模态特征中不同特征通道之间的依赖关系,而跳连卷积则用于对运动信息的局部上下文进行建模,在时间维度上对齐语义短语与视频片段;边界预测模块采用非局部块将关注于不同语义短语的多模态特征进行融合,并进一步采用时序注意力池化模块将特征融合为一个特征向量,从而回归出与语言查询匹配的视频片段的起止时刻。

图1 运动特征激励的视频描述定位模型Fig.1 Video grounding model based on motion excitation
2.1 问题定义
视频描述定位的目标是从一段未修剪的视频中定位出与语言查询语义匹配的片段,本文将视频记做V,并将自然语言描述记做Q,将视频片段的开始/结束时间戳记做τs,τe。本文目标是训练一个模型,通过对训练数据集V,Q,τs,τetrain的学习,能在测试集V,Qtest上正确预测出与语言查询语义相关视频片段的开始与结束时刻
2.2 特征提取模块
对于视频特征的提取,本文参考LGI(localglobal video-text interactions)(Mun等,2020)的特征提取方法,对于一段未修剪的视频V,本文首先基于预训练模型提取视频的特征向量,并将该过程记做fV(⋅),并在视频特征中融入位置嵌入信息,本文将得到的片段级的视频特征记做V′=∈Rc×T,具体为
式中,Nw表示语言查询中单词的个数,c表示特征向量的维度和分别表示Bi-LSTM 编码器的正向和反向隐状态。为获取句子级的特征表示,本文将Bi-LSTM 编码器的第Nw个正向隐状态和第1 个反向隐状态拼接,句子级特征向量记做q∈Rc,具体为
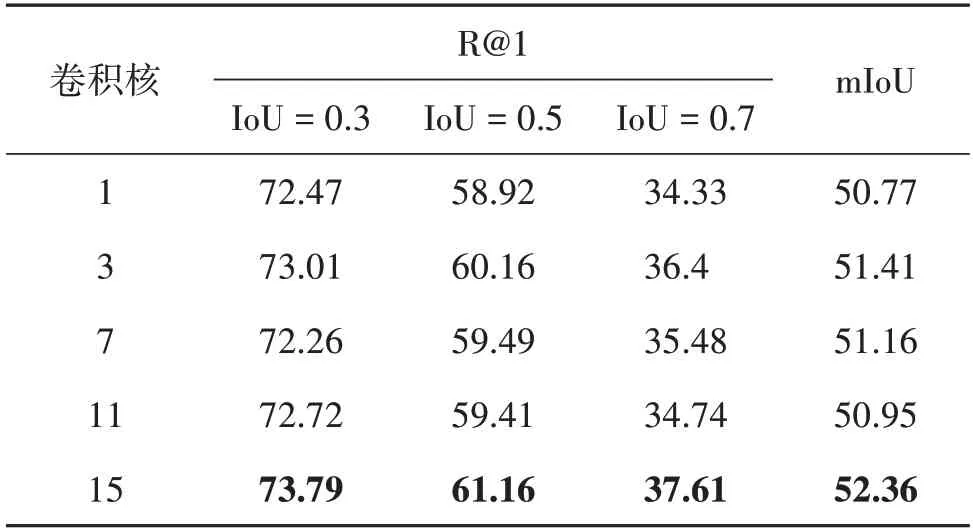
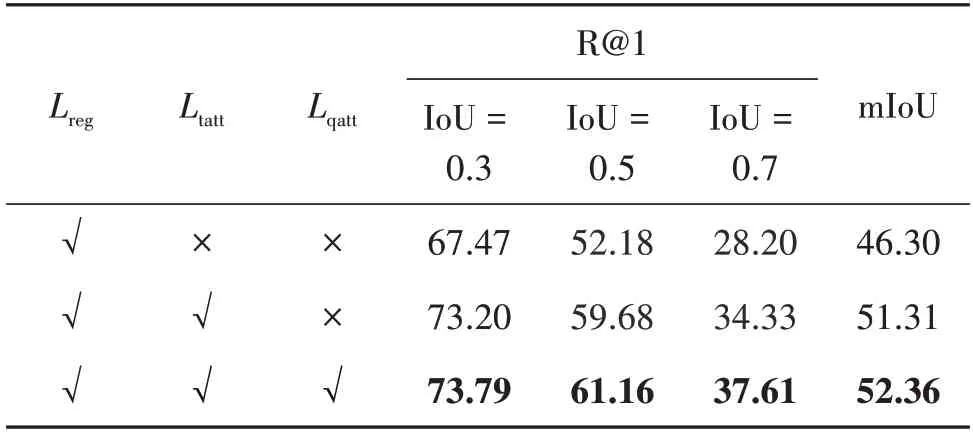
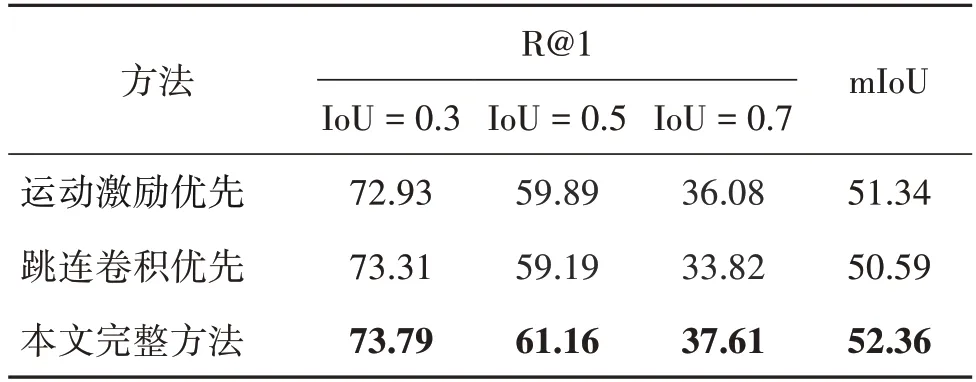
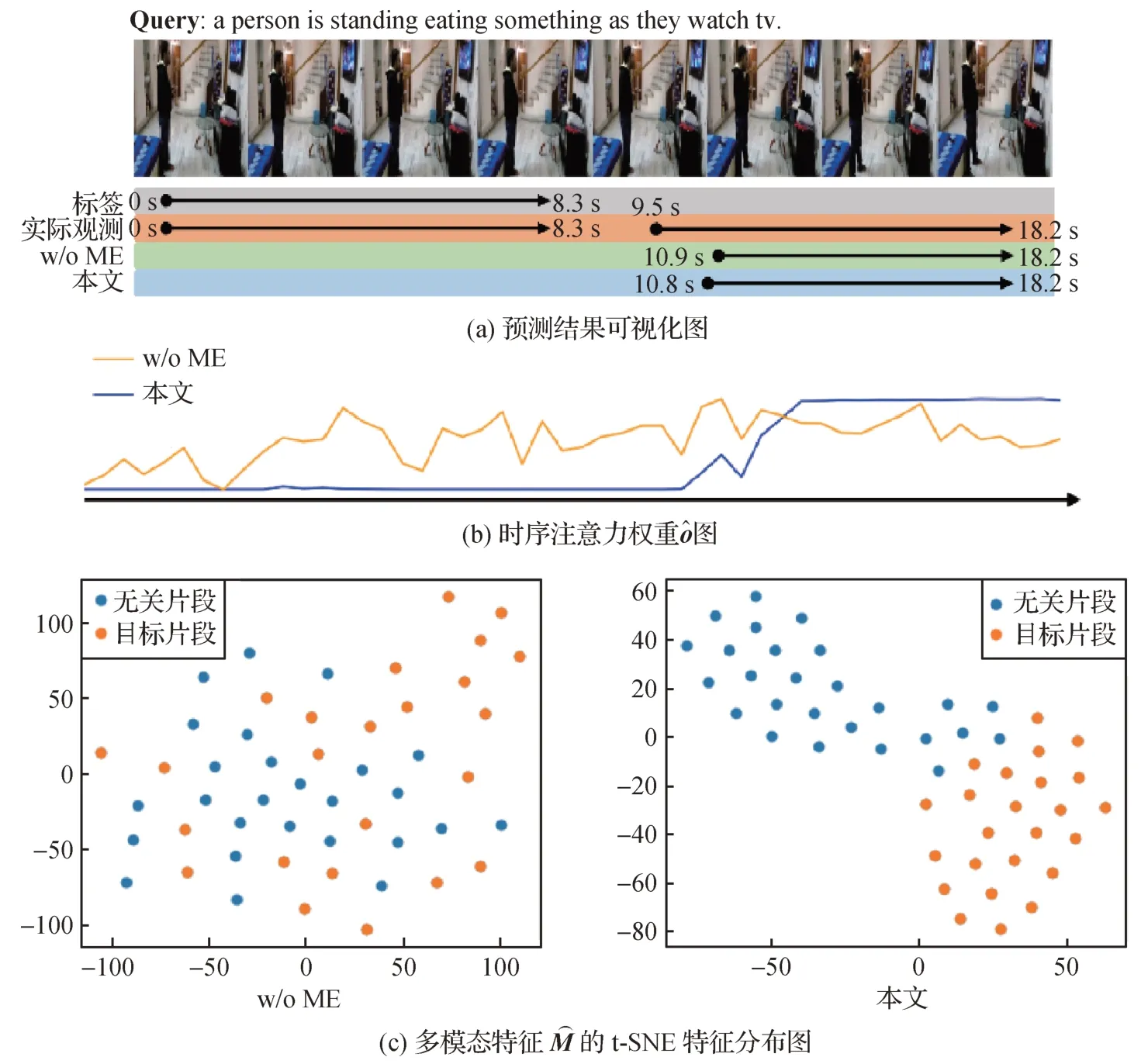
视频描述定位任务需要从语言查询中发掘出重要的语义线索,语言查询通常描述了人物和动作以及行为对象,例如在语言查询“a person walks in a doorway drinking some coffee”中,包含了人物“a person”、动作“walks”和“drinking”、以及对应的行为对象“doorway”和“some coffee”。本文基于注意力机制,设计了多轮渐进式短语级语义发现机制。具体来说,计算第n轮的语义指导向量g(n)∈Rc以及短语级向量p(n)∈Rc,其中1 式中,Wqatt,Wα1,Wα2表示可学习的参数矩阵。于是,本文得到了语言查询的短语级特征表示P=能够覆盖到语言查询中不同的语义线索。 视频的特征表示中包含丰富的运动信息,若仅仅简单地将视频特征与语言查询的短语级特征融合,一方面,模型难以从多模态特征中挖掘出重要的运动信息;另一方面,模型也较难在时序上根据上下文的运动信息对齐语义短语与对应的视频片段。因此,本文使用多模态特征优化模块分别从特征通道维度和时序维度两方面构建优化的多模态特征表示,其中主要包括运动激励和跳连卷积。 2.3.1 运动激励 运动激励块用于强化语义短语对应的运动特征并抑制无关的信息,通过计算多模态特征中时序相邻的特征向量之间的差异,构建出对不同的运动信息响应的通道权重分布,动态调整特征通道之间的依赖关系,从而促使Np个多模态特征能关注于语言查询中所包含的不同运动信息。具体来说,对于多模态特征M(n)∈Rc×T,基于减少网络模型计算量的考虑,本文首先使用一维卷积将特征的通道维度降低为原来的r倍,并将降维后的多模态特征记做M′(n)∈Rc/r×T,具体为 式中,conv1(⋅)表示一层一维卷积。在特征表示中,某时刻的运动信息可由时序上相邻的特征向量差异反映出来,为了在提取运动信息的同时也将时序上下文信息包含进来,本文没有直接将时序相邻的特征向量相减,而是首先使用一维卷积融合t+1 时刻特征向量的上下文信息,然后减去t时刻的特征向量∈Rc/r,从而得到t时刻包含运动信息的特征向量∈Rc/r,本文将运动特征表示记做M″(n)∈Rc/r×T,具体为 为了激励多模态特征中的运动信息,本文基于门控机制优化特征多模态M(n)∈Rc×T,通过使用sigmoid 函数激活运动特征M‴(n),得到响应不同的运动信息的通道权重分布,并与输入的多模态特征M(n)相乘,从而动态调整特征表示中的通道间依赖关系,得到运动激励后的多模态特征表示,同时,本文使用跳连相加以加快模型的收敛速度,具体为 运动激励框架如图2所示。 图2 运动激励框架图Fig.2 The architecture overview of motion excitation 2.3.2 跳连卷积 不同的语义短语所包含的运动信息与视频中不同的运动片段相匹配,所以每个多模态特征应该关注不同的上下文信息,从而对齐语义短语与视频片段。因此,本文采用一维时序卷积对运动信息的局部上下文进行建模,在时序维度上对齐语义短语与视频片段。具体来说,本文在跳连卷积中使用了两层一维卷积,为了加快模型的收敛速度,本文使用了跳连相加的方法,并将输出特征记做具体为 式中,conv2(⋅)表示两层一维卷积。 最后,将从时序上和特征通道两个层面上优化的运动特征激励的多模态特征进行拼接融合,本文将优化后的多模态特征表示记做,具体为 式中,c′=2c为优化后的特征维度。 式中,MLP(⋅)为含两层全连接层的多层感知机,nonlocal(⋅)表示非局部神经网络模块。本文采用与传统的注意力方法不同的时序自注意力池化,将多模态特征融合为一个特征向量。具体来说,给出融合后的多模态特征表示,时序自注意力池化关注语言查询与视频片段匹配的多模态特征,使用多层感知机生成关注匹配片段的时序注意力权重∈RT,并使用时序注意力权重进一步将T个多模态特征向量池化融合为一个特征向量z∈Rc′,具体为 最后,本文使用含两层全连接层的多层感知机预测出目标视频片段的始末时间即 本文使用3 个约束函数对上述网络进行优化,分别为预测边界约束Lreg、时序注意力权重约束Ltatt和短语级语义发现权重约束Lpatt,并将3 个约束函数计算得到损失的加权和作为模型的总损失,具体为 式中,k1和k2分别为时序注意力权重约束和短语级语义发现权重约束的权重。 2.5.1 预测边界约束 式中,SL1(⋅)表示Smooth L1 损失函数,τs与τe分别表示开始与结束归一化的时间标签。 2.5.2 时序注意力权重约束 在视频时序变化中,本文重点关注目标片段,不匹配的片段可以忽略不计。因此,设置权重标签o∈RT,来约束时序注意力预测权重∈RT。以目标片段的开始至结束时间为基准,若t时刻位于匹配片段开始与结束时刻之内,ot=1,否则ot=0,时序注意力权重损失为 2.5.3 短语级语义发现权重约束 在多轮渐进式短语级语义发现机制中,本文基于注意力机制得到Np个注意力权重A=,为了避免每轮语义发现的注意力权重无差异,引入正则项使每轮语义发现的注意力权重矩阵A 更有区分性,从而使模型充分挖掘语言查询中不同的短语语义信息(Mun 等,2020)。具体来说,给定Np个注意力权重A=,本文计算语义发现权重损失Lpatt。具体为 式中,I 表示单位矩阵,λ∈[0,1]控制不同短语权重的重叠程度,当λ趋近于1 时,注意力权重所关注单词趋近于不重叠,‖ ⋅ ‖F表示矩阵的Frobenius范数。 为了验证基于运动激励的方法在视频描述定位任务上的有效性,本文在两个基准数据集上进行实验,并针对模型中不同模块进行消融实验。 3.1.1 数据集 本文使用的两个基准数据集分别为Charades-STA(Gao 等,2017)和ActivityNet Captions(Krishna等,2017)。 Charades-STA 数据集是Gao 等人(2017)基于Charades(Sigurdsson 等,2016)扩展得到的。Charades-STA 数据集共标注得到16 128 个语言描述—视频片段对,其中12 408个用于模型训练,3 720个用于模型测试。平均每个视频划分出2.4 个视频片段注释,每个视频片段平均长度为8.2 s。 ActivityNet Captions 数据集原本用于视频描述任务,Chen 等人(2018)在视频描述定位任务上使用该数据集。ActivityNet Captions 数据集来自于You-Tube 在线视频,在内容上更加复杂且场景更加开放,数据集共有19 209 个未修剪的视频和71 953 个视频片段—语言查询对,其中37 417 个用于模型训练,另外17 505 和17 031 个划分为验证集1 和验证集2。数据集中视频的平均长度为2 min,每个视频平均有3.65 段语言查询,每个语言查询平均有13.48 个单词。由于ActivityNet Captions 官方没有给出测试数据集,按照Mun 等人(2020)的方法,将验证集1 和验证集2 合并作为模型的测试集。 3.1.2 评价指标 为了公平对比,本文采用Gao 等人(2017)的模型评估指标进行模型性能测试,即R@n,IoU=m(Recall@n,intersection over union=m),表示top-n的预测片段中与真实标注之间在时间上的交并比大于m在测试数据集上所占百分比,本文中设置IoU阈值m∈{0.3,0.5,0.7},由于本文方法是一种无候选框的视频描述定位,因此将n设置为1。除此之外,计算mIoU(mean intersection over union)指标评估模型性能,即在测试集上所有预测结果的交并比平均值。本文同时采用GFLOPs(giga floating point operations)和模型参数量大小以及模型推理时间3个指标来衡量模型复杂度。 在特征提取模块(2.2节)中,对于Charades-STA数据集,使用I3D(Carreira 和Zisserman,2017)预训练模型提取视频特征,对于ActivityNet Captions 数据集,使用C3D(Tran 等,2015)预训练模型提取视频特征,本文均匀采样128个视频片段,即T=128。本文使用预训练的全局词向量(GloVe)(Pennington 等,2014)表示语言查询。对Charades-STA 和ActivityNet Captions 数据集,分别将单词数量截断为最大10 个单词和25 个单词,并分别编码得到3 个(Np=3)和5个(Np=5)语义短语。在运动激励(2.3.1节)中,将3 次一维卷积conv1(⋅)的卷积核大小依次设置为1、15 和1,将降维和升维的倍数设置为4,即r=4,对Charades-STA 和ActivityNet Captions 数 据集,本文分别将nonlocal 层数设置为1 层和2 层。在跳连卷积(2.3.2 节)中,将两层卷积conv2(⋅)的卷积核大小设置为15。对Charades-STA 和ActivityNet Captions 数据集,将模型优化函数(2.5 节)中的式(19)的λ分别设置为λ=0.3 和λ=0.2。在 整个模型中的特征通道数c=512,c′=1 024,模型优化器使用Adam(Kingma 和Ba,2015),学习率为0.000 4。 3.3.1 实验结果 与本文方法进行性能对比的模型有MCN(moment context network)(Hendricks 等,2017)、CTRL(cross-modal temporal regression localizer)(Gao等,2017)、TGN(temporal groundnet)(Chen 等,2018)、SMRL(semantic matching reinforcement learning)(Wang 等,2019)、ABLR(attention based location regression)(Yuan 等,2019)、ExCL(extractive clip localization)(Ghosh 等,2019)、MAN(moment alignment network)(Zhang 等,2019a)、GDP(graph-FPN with dense predictions)(Chen 等,2020)、CBP(contextual boundary-aware prediction)(Wang 等,2020)、TMLGA(temporal moment localization using guided attention)(Rodriguez-Opazo 等,2020)、LGI(localglobal video-text interactions)(Mun 等,2020)、DRN(dense regression network)(Zeng 等,2020)、MABAN(multi-agent boundary-aware network)(Sun等,2021)、SSMN(single-shot semantic matching network)(Liu等,2021)、BPNet(boundary proposal network)(Xiao等,2021)和CPNet(contextual pyramid network)(Li等,2021)。 表1 和表2 分别展示了在Charades-STA 数据集和ActivityNet Captions 数据集上的对比结果,由对比结果可见,本文方法在多数评估指标上优于其他方法。在Charades-STA 数据集上,与经典的无候选框方法LGI 相比,本文方法在R@1,IoU=0.5 和mIoU指标上分别高出1.70%和0.98%。ActivityNet Captions 数据集有更复杂的视频和更多样的语言查询,这给模型精确预测目标片段带来巨大的挑战,然而本文方法能够超过其他方法。具体来说,与最新的无候选框方法CPNet 相比,本文方法在R@1,IoU=0.5 和mIoU 指标上分别高出2.17%和2.36%。可以看出,通过挖掘视频中所存在的运动语义信息,可以更准确地定位目标视频片段。 表1 Charades-STA数据集上不同方法的性能对比Table 1 Performance comparison with different methods evaluated on the Charades-STA dataset /% 表2 ActivityNet Captions数据集上不同方法的性能对比Table 2 Performance comparison with different methods evaluated on the ActivityNet Captions dataset /% 此外,在Charades-STA 数据集上,本文同时与2DTAN(Zhang 等,2020)、DRN(Zeng 等,2020)和LGI(Mun 等,2020)对比了模型所需计算力和推理时间消耗,结果如表3 所示,其中2DTAN 和DRN 是基于候选框的方法,本文方法和LGI为无候选框的方法。由表3 可以看出,无候选框的方法在参数量和推理时间上优于两个基于候选框的方法,DRN 在GFLOPs指标上取得了最优值,然而由于其庞大的候选框数量导致其模型难以并行计算,在推理时间上不理想。本文方法在参数量、GFLOPs 和时间3 个指标均较为理想的情况下,在评价指标R@1,IoU=0.5上优于其他模型。 表3 Charades-STA数据集上不同模型所需计算力对比Table 3 Comparison of computing power required by different models evaluated on the Charades-STA dataset 3.3.2 消融实验 本节对本文方法中所使用的不同模块进行消融实验,从而验证不同模块对性能的贡献。本文主要进行了如下几个消融实验: 1)多模态特征优化模块中各部分的作用。本文的多模态特征优化模块由运动激励和跳连卷积两部分组成,本文分别对比有无运动激励及跳连卷积对模型预测结果的影响性能差异,结果如表4 所示,其中“√”表示相应的模块参与模型的训练,“×”表示没有参与训练。实验结果表明,特征优化模块中的运动激励和跳连卷积都对多模态特征的优化起到了积极的作用。然而,单独进行运动激励或单独进行跳连卷积都无法准确地挖掘出视频中的运动信息,在运动激励和跳连卷积的共同作用下,在Charades-STA 数据集上的召回率在交并比阈值为0.3、0.5 和0.7 时分别提升了4.25%、5.81%和6.48%,而且评价指标mIoU 提升了4.27%,这表示两个模块有效优化了多模态特征表示,增强了目标片段和文本查询的语义对齐效果。 表4 Charades-STA数据集上特征优化模块的不同部分消融实验Table 4 Ablation studies of each component in feature optimization module on the Charades-STA dataset /% 2)运动激励中卷积核大小对性能的影响。在运动激励的式(8)中,计算某一时刻的运动信息时,采用一维卷积的方式融合该时刻的上下文信息,为了研究不同卷积核大小对模型性能的影响,本文进行了如表5 所示的消融实验。其中分别将卷积核大小设置为1、3、7、11、15,由实验结果可以看到,对于评价指标R@1,IoU=0.5,卷积核大小为15 的性能比卷积核大小为1 的性能高出2.24%,这表明当卷积核较小时,模型难以整合上下文的信息。 表5 Charades-STA数据集上运动激励卷积核大小的影响分析Table 5 Analysis on convolution kernel size of motion excitation on the Charades-STA dataset /% 3)模型优化函数中不同约束对性能的贡献。为了研究时序注意力权重约束和短语级语义发现权重约束对模型结果的影响,进行了如表6 所示的消融实验。其中“√”表示使用该损失函数约束模型,“×”表示未使用该损失函数约束模型。在表6中,第1行为对照组,仅使用预测边界约束Lreg计算损失,第2行为实验组,在约束预测边界的同时使用了时序注意力权重约束,第3 行同时使用预测边界约束Lreg、时序注意力权重约束Ltatt和短语级语义发现权重约束Lpatt计算损失,即本文的完整方法。对比第1 行与第2 行的实验结果,可见时序注意力权重约束Ltatt的加入极大程度地影响了模型性能,原因是Ltatt促使模型更趋于关注重要的目标视频片段并忽略掉不匹配的片段,进而使模型可以回归得到正确的目标开始/结束时刻。对比第2行和第3行的实验结果,在加入短语级语义发现权重约束Lpatt后,在IoU 阈值较高(即IoU=0.7)的情况下,召回率提升了3.28%,有显著提升,说明与没有Lpatt的情况相比,预测出的时间边界值更加精确,其原因为通过Lpatt的约束,模型能更加细粒度地从文本中挖掘出语义信息,因此预测结果的边界更准确。 表6 Charades-STA数据集上不同损失函数的消融实验Table 6 Ablation studies of different loss functions on the Charades-STA dataset /% 同时,为研究损失函数中的两个超参数k1和k2对模型性能的影响,本文采用控制变量法进行实验,如图3 所示的实验结果表明,当k1=1,k2=1 时,模型取得较好的性能,两组实验共同说明了不同损失函数对模型的约束起到了同等重要的作用。 图3 Charades-STA数据集上损失函数权重的影响分析Fig.3 Analysis on weight of the loss functions on the Charades-STA dataset 5)运动激励与跳连卷积的作用时机。为了研究在多模态特征优化过程中的两个模块作用时机对模型性能的影响,本文进行了3 组实验,分别比较运动激励先于跳连卷积、跳连卷积先于运动激励,以及两个模块并列(即本文方法)3 种方法的性能差异,实验结果如表7 所示。通过对比前两组实验,在Charades-STA 数据集上,当交并比阈值为0.5 和0.7时,运动激励优先的方法比时序卷积优先的召回率高出0.70%和2.26%,这表明当运动激励优先时,模型的预测结果的边界更加准确。然而在运动激励块与时序卷积块并行(即本文方法)的情况下,预测准确度在所有指标上都有所提升,这表明运动激励与跳连卷积两个模块同等重要,当两个模块同时作用时,多模态表征可以得到有效优化。 表7 特征优化模块中运动激励块的不同位置在Charades-STA数据集上对视频描述定位性能的影响Table 7 The effect of different sequences of motion excitation block in feature optimization module for video grounding on the Charades-STA dataset /% 3.3.3 视频描述定位结果可视化 图4 和图5 分别展示了本文方法在Charades-STA 测试集上的预测成功样例和失败样例的可视化结果。如图4(a)和图5(a)所示,本文用灰色框标注出了数据集标签中的目标片段,绿色框为运动激励模块不参与(w/o ME)训练的预测结果,蓝色框为本文完整方法的预测结果,在图5 所示的样例中,由于数据集标签不全面,即存在0~8.3 s 和9.5~18.2 s两段目标片段,因此本文用橙色框标注出实际观测下的目标片段。对于运动激励模块不参与训练以及本文完整方法两种情况,将式(14)中所预测时序注意力权重可视化后如图4(b)和图5(b)所示,将式(13)中得到的多模态特征表示使用t-SNE 降维,其特征分布图如图4(c)和图5(c)所示。从可视化样例中可以看出,在运动激励模块不参与训练的情况下,多模态特征难以表示出目标片段与无关片段的差异,且时序注意力权重无明显规律,因此最终无法预测出准确的结果。与之相对,本文完整方法在运动激励模块的作用下,模型可以利用视频中所包含的运动语义优化多模态特征的表征能力,得到差异化的特征表示,同时时序注意力权重关注视频中包含运动信息的片段,从而更精确地预测视频与语言查询的匹配关系。在图5所示的标签不全面的情况下,本文方法依然预测出其中一个匹配的目标片段,这进一步说明了本文方法的有效性和鲁棒性。 图4 Charades-STA测试集的成功样例可视化Fig.4 Visualization of a successful prediction case on the Charades-STA testset((a)visualization of the localization results;(b)temporal attention weights ;(c)t-SNE embedding of the multi-model feature) 图5 Charades-STA测试集的失败样例可视化Fig.5 Visualization of a failure case on the Charades-STA testset((a)visualization of the localization results;(b)temporal attention weights ;(c)t-SNE embedding of the multi-model feature ) 针对视频描述定位任务中视频—文本多模态表征所存在的挑战,本文提出一种使用运动语义信息优化多模态表征的新方法。为了构建细粒度的语言查询表征,基于自注意力机制学习多个语义短语特征,并分别与视频特征融合得到细粒度的多模态特征表示。为了充分挖掘视频—文本多模态表征中目标片段的运动信息,使用时序卷积块对运动语义的上下文信息建模,并使用运动激励块构建出响应运动语义信息的通道权重分布,从时序维度和特征通道两方面增强了多模态特征运动语义的表征能力。最后采用非局部模块以及时序注意力池化模块,将多模态特征融合一个特征向量,以一种无候选框的方式实现了更精准视频描述定位。 本文在视频描述定位的两个基准数据集Charades-STA 和 ActivityNet Captions 上验证了方法的有效性,并与现有其他方法进行对比。实验结果表明,本文方法在多数评价指标上超过其他方法,这证明了运动语义信息优化多模态表征方法的有效性。此外,通过消融实验验证了通过挖掘视频中的运动语义信息,可以构建更具有表征能力的多模态特征,有效提高模型定位目标片段的准确性。2.3 特征优化模块

2.4 边界预测模块
2.5 模型优化函数
3 实验及结果分析
3.1 数据集和评价指标
3.2 实验细节
3.3 实验结果分析






4 结论
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
中国农业信息(2021年3期)2021-11-22
计算机工程与科学(2021年4期)2021-05-11
开放教育研究(2020年2期)2020-03-31
火力与指挥控制(2018年3期)2018-04-19
电子制作(2017年13期)2017-12-15
电子制作(2016年15期)2017-01-15
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
