
视觉Transformer识别任务研究综述
2023-10-24 13:57周丽娟毛嘉宁
中国图象图形学报 2023年10期
周丽娟,毛嘉宁
郑州大学计算机与人工智能学院,郑州 450001
0 引言
计算机视觉(computer vision,CV)涉及对图像或视频中有用信息的提取和分析。在所有CV任务中,识别任务占有很大的比重。随着深度学习技术的引入,经典的方法是利用卷积神经网络(convolutional neural network,CNN)来解决此类问题。CNN 通过局部感知和参数共享,降低了网络模型的复杂度,并且可以直接将图像数据作为输入,避免了人工提取特征的过程。但由于CNN 擅长关注局部特征,难以很好地利用对结果同样十分重要的全局信息,使得该领域的发展受到了一定的阻碍。
Transformer(Vaswani 等,2017)是一个从序列到序列(sequence to sequence)的模型,最大特点是抛弃了传统的卷积神经网络和循环神经网络(recurrent neural network,RNN),采用注意力机制组成网络,使模型可以并行化训练,而且能够关注全局信息。Transformer 提出后,在自然语言处理(natural language processing,NLP)领域大放异彩,例如,备受关注的基于Transformer 的双向编码器表示(bidirectional encoder representations from Transformers,BERT)模型(Devlin 等,2019),以及生成式预训练Transformer(generative pre-training,GPT)系列模型GPT1(Radford 等,2018)、GPT2(Radford 等,2019)和GPT3(Brown等,2020)。
这些基于Transformer的模型表现出的强大性能使NLP 研究取得了重大突破,同时吸引了计算机视觉研究人员的目光,他们将Transformer 移植到视觉任务中,并发现了其中的巨大潜力。如首次使用纯Transformer 进行图像识别的方法ViT(vision Transformer)(Dosovitskiy 等,2021),以及解决目标检测问题的DETR(detection Transformer)模型(Carion 等,2020)。
随着越来越多的视觉Transformer模型被探索出来,关于此研究的综述论文也逐渐出现。按照分类标准的不同,目前的综述论文从不同的角度总结现有方法,包括输入数据(Han 等,2022)、网络结构(Khan 等,2022)和应用场景(Liu 等,2022b,刘文婷和卢新明,2022,Khan 等,2022)。其中,从应用场景角度进行总结的论文占大多数。Liu等人(2022b)分别从计算机视觉领域的3 个基础任务(分类、检测和分割)总结现有方法。除了这3 个基础任务外,刘文婷和卢新明(2022)、Khan 等人(2022)又增加了在图像识别、视频处理、图像增强和生成应用场景下的方法总结。然而,这些不同的应用都是孤立存在的,不能形成一个系统的各种方法的总结。此外,现有的综述论文多关注视觉Transformer 模型与传统CNN模型结果的比较,对不同Transformer 模型间结果的比较分析较少。
为了解决以上问题,本文从视觉识别的角度出发,总结比较了视觉Transformer 处理多种识别任务的代表性方法。按照识别粒度的不同,可以分为基于全局识别的方法和基于局部识别的方法。基于全局识别的方法,即对视觉数据(图像、视频)整体进行识别,例如图像分类、视频分类。基于局部识别的方法,即对视觉数据中的部分进行识别,例如目标检测等。考虑到现有方法在3 种具体识别任务的广泛流行,本文也总结对比了人脸识别、动作识别和姿态估计3 种识别任务的方法。在每类任务下,对不同方法的特点和在公共数据集上的表现进行了对比分析,并进一步总结了该类方法的优点和不足,以及不同识别任务面临的问题和挑战。
本文与现有的综述对比,具有以下优点:1)本文从识别的角度分类,可以更系统地将现有方法联系起来;2)虽然一些综述论文(刘文婷和卢新明,2022;Khan 等,2022)也对识别任务的方法进行了总结,但是涉及的内容不全面,而本文不但对基础识别任务的方法进行了总结,还总结了3 种具体识别任务的方法,并且对于每类任务方法,在对比分析公共数据集结果的基础上,总结了其发展现状和不足。
综上所述,近年来CNN 的局限性以及Transformer 研究的突破性使得视觉Transformer 已广泛应用于CV领域,而关于视觉Transformer的综述论文还不够丰富,特别是对其应用场景的总结存在着较为孤立的现象。又因流行的CV 应用场景大多能够以视觉识别的角度分析,所以本文系统地对用于识别任务的视觉Transformer进行综述具有必要性,同时,本文通过每类任务对应的基准数据集上的实验对比分析,反映各类Transformer 模型间的区别与联系也是十分必要的。最后,本综述带来了更系统的总结和更全面的内容,将为相关领域读者快速了解和认识Transformer 在视觉识别任务中的应用提供重要帮助。
1 基于识别的方法
本文从识别的角度出发,对现有的视觉Transformer 方法进行分类总结对比。根据识别粒度的不同,现有方法可以分为基于全局识别的方法和基于局部识别的方法。基于全局识别的方法,即对视觉数据整体进行识别。按照输入视觉数据的不同,基于全局识别的方法分为图像分类和视频分类两种。基于局部识别的方法,即对视觉数据中的部分进行识别。基于局部识别的方法,主要包括两种:1)对视觉数据中出现的物体或人进行定位和分类,这种方法称为目标检测;2)对图像或视频帧在像素级别进行分类,这类方法称为视觉分割。另外,为了对基于全局识别和局部识别的方法进一步举例说明,本文也对3 种流行的具体识别任务下的Transformer 方法进行了总结,包括:人脸识别、动作识别和姿态估计。最后,本文还总结了适用于全局识别和局部识别的通用方法。本节整理了上述5 大类方法的最新研究进展并对各类方法在公共数据集上的表现进行了对比分析,整体结构如图1所示。

图1 用于识别任务的视觉Transformer分类Fig.1 Classification of vision Transformer for recognition tasks
视觉Transformer应用于识别任务的整体处理流程如图2所示,大致包括以下流程:输入图像/视频数据;切分图像/视频帧补丁序列;提取特征和(或)标记化(类别、分块、位置等标记嵌入);输入 Transformer 编码器或CNN 与Transformer 的融合网络;计算空间/时空注意力或计算空间/时空卷积与注意力;输入解码器,如大多数目标检测、视觉分割,以及部分人脸识别、动作识别和姿态估计任务需要解码,则根据不同需求选择Transformer,CNN 或多层感知机(multi-layer perceptron,MLP)解码;输入前馈神经网络;输出识别结果。其中,对于视频的处理与图像处理相似,只是除空间信息外增加了对时间信息的处理。

图2 视觉Transformer应用于识别任务的整体流程图Fig.2 The overall flow chart of vision Transformer applied to recognition tasks
1.1 基于全局识别的方法
基于全局识别的方法,是对视觉数据整体进行识别。根据不同的视觉数据,基于全局识别的方法分为图像分类和视频分类两种。
1.1.1 图像分类
图像分类,即给输入的图像赋予一个类别标签,如猫、狗等。传统图像分类的惯例是将图像表示为像素数组并采用卷积神经网络,而视觉Transformer与图像标记的结合探索出了一条新的道路。Dosovitskiy 等人(2021)首次提出使用纯Transformer 进行图像识别的方法,称为视觉Transformer(ViT),模型结构如图3所示。该模型将图像解释为补丁(patch)序列,与原始图像中的位置信息编码相加,并向序列中添加额外的可学习的分类标记(token),用标准的Transformer 编码器对向量序列进行处理,彻底抛弃了CNN,避免引入与图像相关的归纳偏置(inductive bias)。
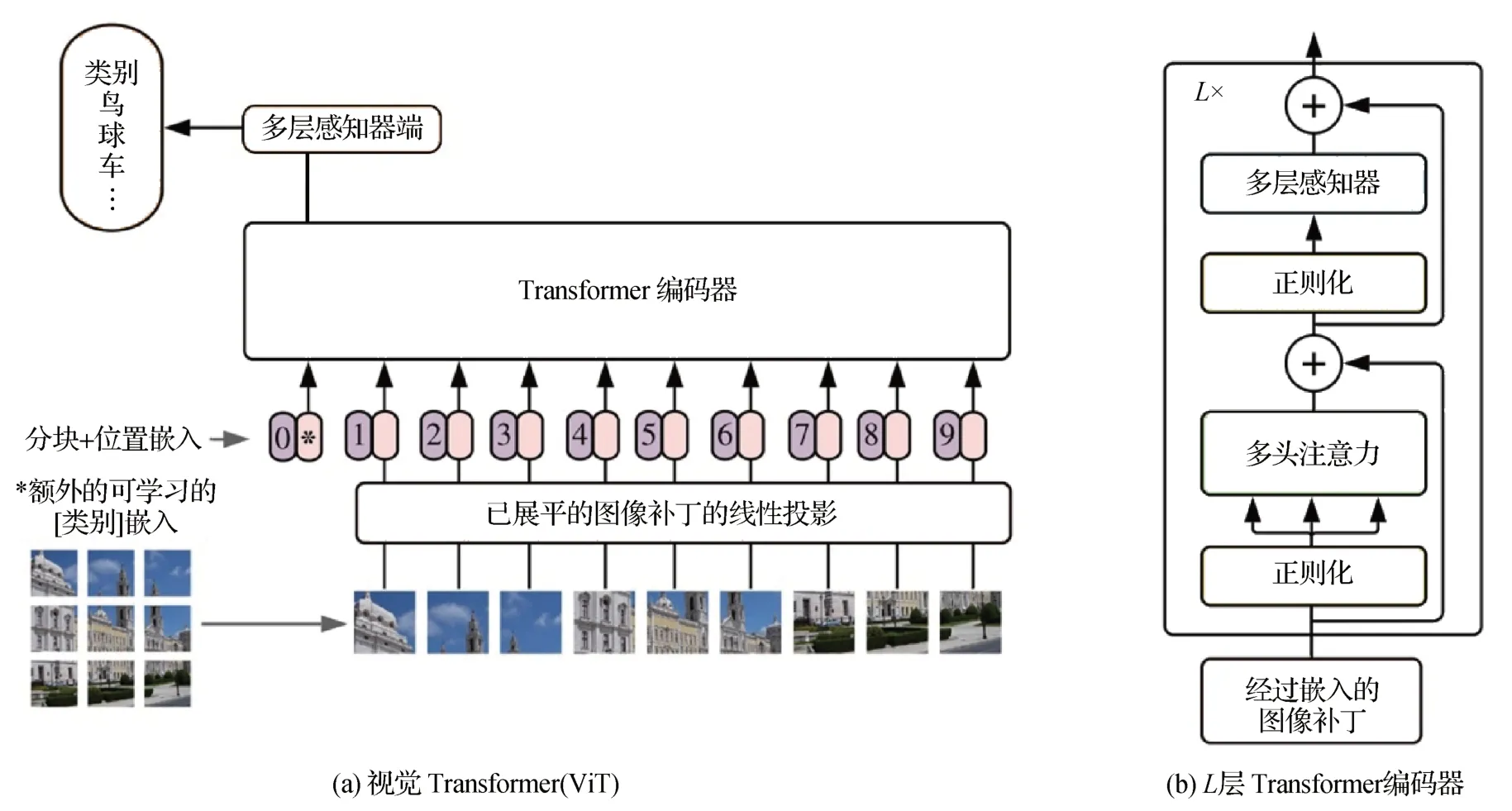
图3 ViT模型结构(Dosovitskiy等,2021)Fig.3 ViT model architecture(Dosovitskiy et al.,2021)((a)vision Transformer(ViT);(b)Transformer encoder with L layer)
在ViT 的基础上,一些方法相继被提出来解决ViT 的大规模数据需求、冗余、标记简单和训练性能不佳等问题。为了避免像ViT 那样使用大型数据集进行预训练,Touvron 等人(2021)提出了数据高效的图 像Transformer(data-efficient image Transformers,DeiT),它同样没有卷积操作,核心是引入一种针对Transformer 的师生训练策略,提出基于标记的蒸馏方法,确保学生通过注意力从老师那里学习。此外,DeiT 模型指出使用卷积作为教师网络进行蒸馏能够比使用Transformer 取得更好的效果。为了解决ViT 的标记数量和不同Transformer 层之间的注意力图的冗余问题,Chen 等人(2021a)提出一种基于标记池和注意力共享的ViT,减少了冗余度,有效地增强了特征表示能力。为了克服简单标记和冗余的局限性,Yuan 等人(2021)提出一种标记到标记视觉Transformer(tokens-to-token ViT,T2T-ViT),它通过递归地聚合标记,将图像结构化,从而可以对周围标记所呈现的局部结构进行建模,减少标记长度和参数量,同时提升了在ImageNet 上从头开始训练的性能。Yue 等人(2021)认为ViT 朴素的标记化会将网格分配到不感兴趣的区域,如背景,并引入干扰信号,进而提出迭代渐进的采样策略来定位识别区域,实现自适应地关注感兴趣的区域。Chen 等人(2021d)不使用预定义的固定补丁,提出可变形补丁模块,学习自适应地将图像分割成不同位置和比例的补丁,保留了补丁中的语义信息,并解决了标记简单的问题。Wu等人(2021a)使用视觉标记代表图像中的高级概念,运行Transformer 来密集建模标记关系。Xie 等人(2021c)提出二阶ViT,进一步改善视觉标记以解决ViT从头训练性能不佳的问题。
由于计算注意力可能需要较多的时间,一些研究通过修改注意力计算来提高模型的效率,以实现线性复杂度。Chen 等人(2021c)提出一种用于学习多尺度特征的双分支视觉Transformer,为了有效地结合不同尺度的图像块标记,进一步发展了基于交叉注意力的融合方法(cross-attention multi-scale ViT,CrossViT),在线性时间内有效地交换两个分支之间的信息,以提高图像分类的识别精度。
Xu 等人(2021)提出自激励慢速—快速标记演化方法(evolution ViT,Evo-ViT),通过全局类注意力来进行非结构化的实例式标记选择,用不同的计算路径来更新所选的信息性和非信息性的标记。在保持分类性能的同时,大大降低了计算成本。Song(2021)修改了自注意力中的几行代码,通过消除一些非线性来减少自注意力计算,提出单位力操作的视觉Transformer(unit force operated ViT,UFO-ViT),在不降低性能的情况下实现了线性复杂度。除此之外,还有一些研究通过加入卷积模块,来平衡模型的效率和精度。Chen 等人(2021b)逐步将基于Transformer 的模型转换为基于卷积的模型,提出了视觉友好Transformer,在计算复杂度相同的情况下,提高了分类精度,且当模型复杂度较低或训练集较小时,这种优势更加明显。将卷积方法应用于Transformer的混合神经网络(LeNet ViT,LeViT)(Graham 等,2021)优化了图像快速推理分类的精度和效率之间的平衡,特别是分辨率降低的激活图。与LeViT 类似,利用CNN 建模局部特征,利用Transformer 捕获远程依赖关系的一种混合网络,及对其进行缩放获得的一系列模型(CNNs meet Transformers,CMTs)(Guo等,2022)获得了更高的精度和效率。
除了一般的图像分类外,视觉Transformer 还应用于其他的图像分类任务,如细粒度图像分类、多标签识别和医学图像分类等。细粒度图像分类需要学习细微而又具有区分性的特征。基于纯Transformer的特征融合视觉Transformer(feature fusion vision Transformer,FFVT)(Wang 等,2022a)通过聚合来自各Transformer 层的重要标记来补偿局部、低层和中层信息。该模型设计了称为“互注意力权重选择”的标记选择模块,引导网络选择可区分的标记。细粒度识别Transformer(He 等,2022)将Transformer 的所有原始注意力权重整合到注意力图中,以指导网络有效准确地选择可区分的图像块并计算它们的关系。Zhang 等人(2022)提出自适应注意力多尺度融合Transformer 方法,选择性注意力收集模块利用ViT 中的注意力权重,并根据输入补丁的相对重要性自适应地对其进行过滤。
Zhao 等人(2021c)提出基于Transformer 的对偶关系图(Transformer-based dual relation graph,TDRG)框架用于多标签识别任务,通过对结构关系图和语义关系图的探索,构建互补关系。结构关系图通过开发一个基于转换的跨尺度体系结构,从对象上下文中获取长期关联。语义关系图用显式的语义感知约束动态地建模图像对象的语义。Lanchantin 等人(2021)提出一个多标签图像分类的通用框架,通过Transformer 来利用视觉特征和标签之间的复杂依赖关系。该方法的一个关键部分是标签掩膜训练目标,它使用三元编码方案来表示标签在训练期间的状态为正、负或未知。
用于胃组织病理学图像分类的多尺度视觉Transformer 模型(Chen 等,2022b)能够将显微胃图像自动分类为异常和正常情况。该模型由两个关键模块组成:全局信息模块和局部信息模块,用于有效提取组织病理学特征。Dai等人(2021a)提出用于多模态医学图像分类的Transformer(Transformer medical,TransMed)。TransMed 结合了CNN 和Transformer 的优点,可以有效地提取图像的低级特征并建立模态之间的长程依赖关系。多示例学习(multiple instance learning,MIL)是解决基于全视野数字切片病理诊断中弱监督分类问题的有力工具。目前的MIL 方法通常基于独立且相同的分布假设,从而忽略了不同示例之间的相关性,Shao 等人(2021)提出关联MIL,并给出了收敛性的证明。在此基础上设计了基于Transformer 的MIL,能够有效地处理不平衡/平衡和二元/多重分类,具有很强的可视化和可解释性。
总的来说,图像分类模型大多使用视觉标记和类标记进行特征表示和分类,还可以与语义信息相结合。表1 比较了上述部分图像分类模型在ImageNet(Deng 等,2009)数据集上的参数量(Params)与准确率(Top-1 Acc)表现并概述模型亮点。从表1中可以看出:
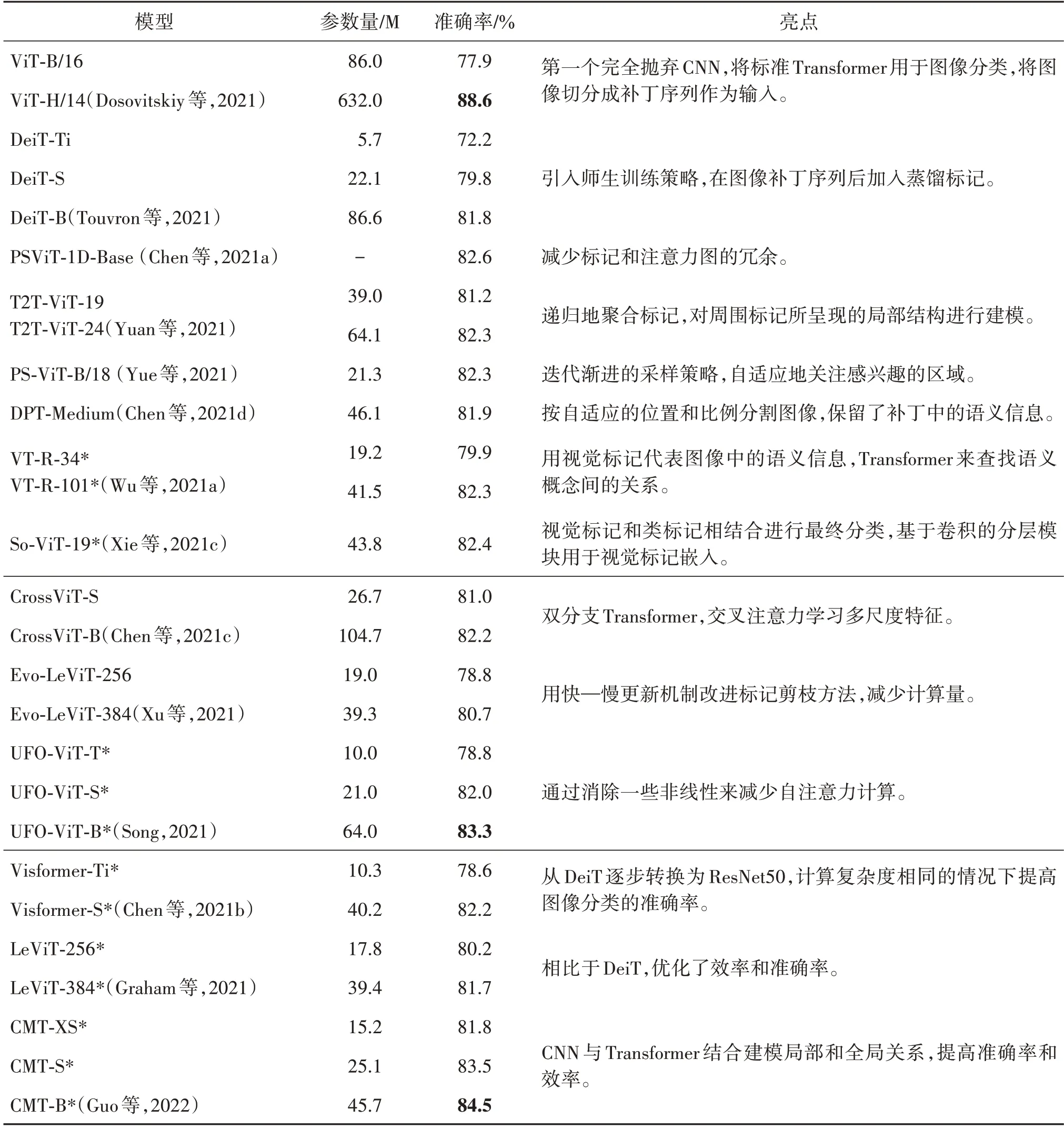
表1 比较图像分类模型在ImageNet数据集上的参数量与准确率并概述模型亮点Table 1 Compare the Params and Top-1 Acc of image classification models on the ImageNet dataset and outline the highlights of these models
1)原始的ViT 模型(Dosovitskiy 等,2021)采用巨型规模的网络结构(ViT-H/14)时表现较好,可以实现88.6%的准确率,但同时其参数量非常大(632 M),远超其他模型。而在基础规模的网络结构(ViT-B/16)上,原始ViT 只达到了77.9%的准确率,DeiT 及其他改进的ViT 系列模型都实现了更好的性能,均超过了80%,只有在小型(-S)甚至极小型(-Ti)网络结构上会出现低于80%的性能。证明了对图像标记的改进研究是有效的。
2)观察修改注意力计算的模型(CrossViT,EVOViT,UFO-ViT)可以发现,分类准确率最好时达到83.3%,其参数量为64 M,与ViT 模型相比,参数量降低很多,这说明了通过修改注意力计算部分可以降低计算的复杂度。
3)对比使用卷积网络的模型(*标注的模型)的准确率和参数量可以发现,总体来说,CMT 模型性能比较好。CMT-S 准确率为83.5%(仅次于CMT-B的 84.5%),参数量为25.1 M,比其他6 个模型的参数量少。同时,与ViT 系列模型或修改注意力计算的模型相比,也说明使用卷积网络可以平衡准确率和计算复杂度。
综上,目前用于图像分类的Transformer 具备以下优点和不足:1)完全基于Transformer 的效果可以等同于甚至优于以CNN 为主流的传统方法,此外,修改编码结构、自注意力计算方式能够平衡准确率与计算成本。但目前达到最高准确率的方法往往进行了超大数据集预训练,同时也需要超大的参数量与计算量。2)利用切分补丁使得图像输入序列化,为处理视觉数据提供了新思路,并进一步对如何切分图像补丁和改进图像标记进行了探索,例如保留图像补丁的相对结构及语义信息、减少标记传递的冗余,提升了训练性能。但目前的补丁多采用固定的尺寸,这样虽然统一了序列长度,便于位置编码等后续处理,然而当输入图像尺寸不同,或提取不同的特征区域作为补丁时,需要额外进行插值。
1.1.2 视频分类
视频分类,旨在为输入的整个视频赋予一个类别标签。当视频中只有人体动作时,视频分类相当于动作识别。为了保持与引用论文中的说法一致,若引文中提到的是视频分类任务,本文将其总结在本节;若是动作识别任务,本文将在1.4节总结。
图像分类中Transformer得到了大量的应用与探索,而在视频理解方面,除了与图像处理类似地需要关注空间信息外,还需要关注时间信息,完全基于Transformer 的架构被证明同样有效。首个无卷积的视频分类方法,即时空Transformer(time-space Transformer,TimeSformer)(Bertasius 等,2021)依次应用时间注意力和空间注意力,通过直接从一系列帧级补丁中学习时空特征,使标准的Transformer 架构适用于视频分类。几乎同时,Neimark等人(2021)也抛弃卷积网络,提出基于Transformer的视频识别框架,通过一个端到端通道,关注整个视频序列信息来进行分类。Arnab 等人(2021)同样提出纯Transformer视频分类模型(video vision Transformer,ViViT),从输入视频中提取时空标记,然后由一系列Transformer 层进行编码。为了处理视频中遇到的长标记序列,又提出了几种模型变体,分解输入的空间和时间维度。Zhang 等人(2021c)提出了标记移位模块(token shift,TokShift),一种零参数零计算量算子,用于建模Transformer 编码器内的时序关系。Tok-Shift 几乎不会在相邻帧之间来回移动部分标记特征。该模块可以密集地插入普通视觉Transformer的每个编码器中,以学习视频表示。还有一种可分离注意力的视频Transformer(Zhang等,2021d),能够通
过堆叠注意力聚集时空信息,并以更高的效率提供更好的性能,且更擅长预测需要长期时间推理的动作。
视频分类模型主要探索了如何使用Transformer建模时序关系以及如何学习时间和空间特征。不同视频分类模型在Kinetics-400 数据集(Kay 等,2017)上的参数量(Params)、准确率(Top-1 Acc)和视图(Views)比较以及模型亮点概述如表2 所示,Views中x×y代表x时间裁剪和y空间裁剪。从表2 中可以看出,纯Transformer 视频分类模型ViViT-L 取得最好的分类准确率(81.7%)。另外,采用多个视角数据的分类准确率要高于其他单视角的准确率。在参数量方面,所有模型参数量都高于85 M,与图像分类模型的参数量相比,视频分类模型的参数量有待降低。
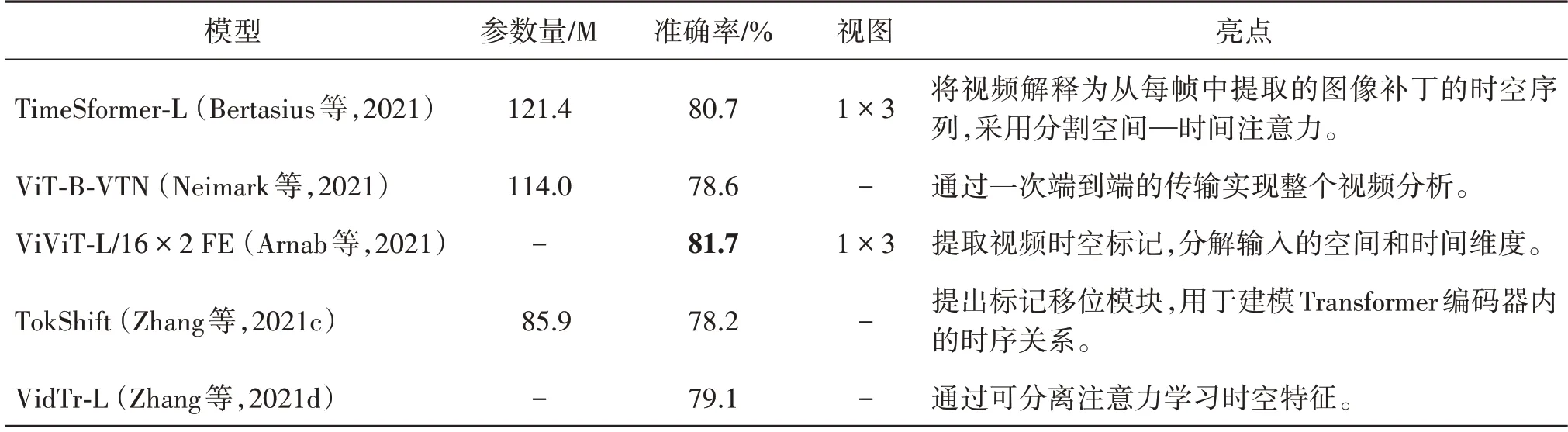
表2 不同视频分类模型在Kinetics-400数据集上的参数量、准确率和视图比较及模型亮点Table 2 Compare the parameters,accuracy and views of video classification models on the Kinetics-400 dataset and outline the highlights of these models
目前用于视频分类的Transformer 模型优点包括:1)相较于经典的CNN 模型具备更快的训练速度和更高的精度,相较于图像分类减弱了对大数据集预训练的依赖性;2)除了完整的视频帧输入外,也可以选择切分补丁输入,并能够使用线性嵌入,降低了输入预处理时对CNN 的依赖;3)为了捕捉视频的时空特征,提出了多种计算注意力的方式,例如同时计算时空注意力或怎样分解计算空间注意力和时间注意力;4)基于Transformer建模长期依赖的特性,该类模型对于较长的视频有更好的处理效果。然而,目前这些模型仍存在一些不足,如视频数据存在大量冗余,空间、时间注意力的分解顺序及后续整合需要更多的解释和损失估计。
1.2 基于局部识别的方法
基于局部识别的方法,旨在对视觉数据中的部分进行识别。基于局部识别的方法,可以分为两类:1)对视觉数据中出现的物体或人进行定位和分类,这类方法主要解决CV领域的目标检测任务;2)对图像或视频帧在像素级别进行分类,这类方法主要解决CV领域的视觉分割任务。因此,下文将按照这两个任务对基于局部识别的方法进行总结。
1.2.1 目标检测
目标检测任务需要从视觉输入中检测出感兴趣的物体,预测一系列边界框(bounding box)的坐标以及标签。Transformer 出现之前,大多数检测器通过定义一些候选框(proposal)、锚框(anchor)或窗口,将问题构建成一个分类和回归问题来间接地完成这个任务。在常见的两阶段和单阶段目标检测方法中,分类和回归通常分别采用全连接和全卷积的方式(曹家乐 等,2022)。而随着Transformer 的发展,Carion 等人(2020)将其引入目标检测领域,提出检测Transformer(detection Tranformer,DETR),模型结构如图4 所示。相比基于区域的卷积(region-CNN,RCNN)等做法,DETR 最大的特点是将目标检测问题转化为无序集合预测问题:图像经过CNN 进行特征提取后变成特征序列输入到Transformer的编解码器中,直接输出指定长度为N的无序集合,集合中每个元素包含物体类别和坐标。
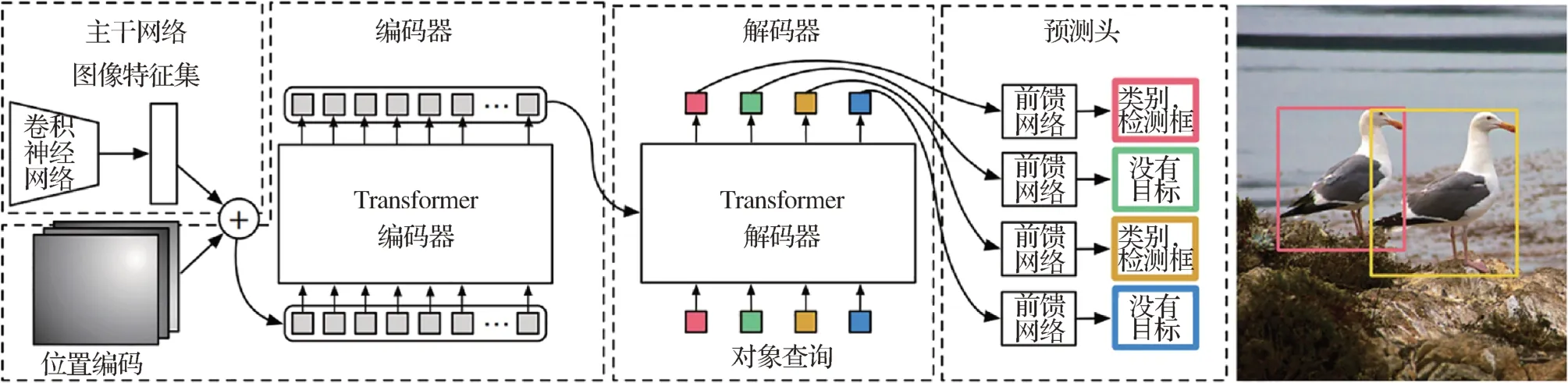
图4 DETR模型结构(Carion等,2020)Fig.4 DETR model architecture(Carion et al.,2020)
1)DETR 改进算法。DETR 开启了目标检测新范式,同时也意味着更多的改进空间。基于DETR的无主干检测器(DETR-based detector without backbone,WB-DETR)(Liu 等,2021a)证明基于Transformer 的检测器不需要依赖CNN 特征提取。WBDETR 只由1 个编码器和1 个解码器组成,直接序列化图像,并将输入的局部特征编码到每个单独的标记中。其中设计的“局部信息增强—标记到标记”模块,对每个标记展开后的内部信息进行调制,以弥补Transformer 在局部信息建模方面的不足。可变形DETR(deformable DETR)(Zhu 等,2021)被提出以解决收敛速度慢和特征空间分辨率有限的问题。其注意力模块只关注参考周围的一小组关键采样点,特别是在小物体上可以达到比DETR 更好的性能。DETR 直接将图像特征图转换为目标检测结果,但由于在某些区域(如背景)上的冗余计算,翻译完整的特征图成本较高,Wang 等人(2021d)将减少空间冗余的想法封装到一个轮询和池化(poll and pool,PnP)采样模块中,构建了一个端到端PnP-DETR 体系结构,自适应地分配其计算空间,以提高效率。为了降低高分辨率输入的计算量,Zheng 等人(2021b)提出自适应聚类Transformer(adaptive clustering Transformer,ACT),使用局部敏感哈希自适应地对查询特征进行聚类,并使用原型键交互来近似查询键交互,可作为插入式模块取代自注意力模块,降低自注意力的二次方复杂度。为了加快DETR 的收敛速度,Meng 等人(2021)提出了一种条件交叉注意机制,命名为条件DETR(conditional DETR),从解码器嵌入中学习条件空间查询,用于解码器多头交叉注意力,通过条件空间查询,每个交叉注意头能够关注包含不同区域的频带,这缩小了目标分类和框回归的不同区域定位的空间范围,从而减轻了对内容嵌入的依赖,减轻了训练。Sun 等人(2021b)提出了基于Transformer 的单阶段全卷积集合预测(Transformer-based set prediction with fully convolutional one-stage,TSP-FCOS)和基于Transformer 的RCNN 集合预测这两种方法来解决匈牙利损失和Transformer 交叉注意机制导致DETR 收敛缓慢的问题。Gao 等人(2021a)提出了空间调制协同注意力(spatially modulated co-attention,SMCA)机制来改进DETR 框架,通过引入高斯分布权重,将协同注意力的响应限制在初始估计的边界框附近,增强DETR中协同注意力的位置感知力。SMCA 通过替换解码器中原有的协同注意力机制来提高DETR 的收敛速度。Dai 等人(2021b)提出了一个名为“随机查询补丁检测”的前置任务(pretext task)来实现无监督预训 练DETR(unsupervised pre-training DETR,UPDETR)。从给定的图像中随机地裁剪出补丁,然后将它们作为查询提供给解码器。该模型经过预训练,从原始图像中检测出这些查询补丁,能够取得比DETR 更快的收敛速度。Bar 等人(2021)提出一种使用区域先验的Transformer进行检测的无监督预训练方法。除检测器主干外,还对目标定位和嵌入组件进行预训练,期间预测目标定位以匹配来自无监督候选区域生成器的定位,同时将相应的特征嵌入与来自自监督图像编码器的嵌入对齐。
对于DETR 的改进主要集中在其特征图、计算复杂度和收敛速度方面。表3 比较了上述目标检测模 型在COCO(common objects in context)(Lin 等,2014)验证集上的参数量(parameters,Params)、浮点运算数(floating point operations,FLOPs)、训练轮次(epochs)和一系列的平均精准度(average precision,AP)表现。评价预测准确性的指标包括:主要的挑战指标“平均精准度”(AP)、视觉对象的分类识别和检测的基准测试PASCAL VOC(pattern analysis,statistical modeling and computational learning visual object classes)挑战赛指标AP50、严格指标AP75以及分别用于小中大型物体的APsmall(APS)、APmedium(APM)和APlarge(APL)。从结果可以看出,相比于DETR,Conditional DETR 和SMCA 实现了所有指标上的较大提升。除此之外,在小物体检测方面,Deformable DETR 和TSP 取得了更大的进步。在大型物体检测上,WB-DETR 也实现了更好的精度,但是计算量普遍高于DETR。UP-DETR 同样实现了所有指标上的提升而保持了相同的计算量。基于知识蒸馏的ACT 在层数为32 时与原始DERT-DC5 相当,但是其计算量比DERT-DC5 更低。在收敛速度方面,多数模型无需像原始DETR 一样训练500 个轮次,便能达到与其相当的性能。

表3 目标检测模型在COCO验证集上的参数量、浮点运算数、训练轮次及平均精准度比较Table 3 Compare the Params,FLOPs,training epochs and a series of AP of the object detection models on the COCO validation set
除了改进目标检测算法DETR 外,研究人员还探索了其他的目标检测任务,如点云三维检测、少样本目标检测等。
2)点云三维检测。Pan 等人(2021)为三维点云有效学习特征设计了Pointformer 网络。局部Transformer 建模局部点之间的交互,在对象级别学习与上下文相关的区域特征。全局Transformer学习场景级别的上下文感知表示。局部—全局变换进一步捕捉多尺度表示间的依赖关系,从更高的分辨率结合局部和全局特征。Liu等人(2021e)提出一种直接从三维点云中检测三维对象的方法。不用将局部点分组到每个候选对象,而是借助Transformer 中的注意力机制从点云中的所有点计算对象的特征,其中每个点的贡献在网络训练中自动学习。Sheng 等人(2021)利用高质量的候选区域网络和通道级Transformer 提出有助于点云检测的一个两阶段三维目标检测框架,同时为每个候选框内的点特征执行候选框感知嵌入和通道级上下文聚合。基于多尺度特征金字塔的三维目标检测体系结构(multirepresentation,multi-scale,mutual-relation DETR,M3DETR)(Guan 等,2022),结合了不同的点云表示(原始点、体素和鸟瞰图)以及不同的特征尺度。M3DETR 是第1 种使用Transformer 同时统一多个点云表示、要素比例以及点云之间相互关系模型的方法。用于点云三维检测的端到端Transformer 模型3DETR(Misra 等,2021)需要很少的3D 特定归纳偏置。使用非参数查询和傅里叶位置嵌入是良好的三维检测性能的关键。3DETR 可以很容易地合并之前在3D检测中使用的组件,并可以用来构建更先进的3D检测器。
3)少样本目标检测。少样本目标检测旨在利用少量标注样本检测新目标。Meta-DETR(Zhang 等,2021b)将元学习的相关聚合结合到DETR 检测框架中,Meta-DETR 完全在图像级别工作,没有任何候选区域,这绕过了流行的少样本检测框架中不准确候选框的约束。Lin等人(2021b)提出一种通用的交叉注意力Transformer 模块,利用Transformer 机制全面捕捉查询像素和目标图像的双向对应关系,充分利用其语义特征在单样本目标检测中进行准确高效的语义相似度比较。
4)其他目标检测。一些模型被提出用于解决跨域对齐、任意方向目标检测、行人检测和医学领域的目标检测等问题。Zhang 等人(2023)采用单级检测器设计了一种域自适应目标检测网络(domain adaptive DETR,DA-DETR)执行域间对齐。DA-DETR 引入一个混合注意力模块,明确指出硬对齐特征,以便跨域对齐。
对于任意方向(arbitrary-oriented)目标检测问题,Ma 等人(2021)实现了端到端的面向对象Transformer 检测(oriented object DETR,O2DETR),通过Transformer 直接有效地定位对象,而不像传统检测器那样需要烦琐的旋转锚框,还设计了用深度可分卷积代替注意力机制的编码器,降低了原Transformer中多尺度特征的存储和计算成本。
Lin 等人(2021a)探讨了端到端检测器(end-toend detector,ED)在人群行人检测中的表现,提出了一种新的解码器。此外,为ED设计了一种利用行人较少遮挡的可见部分的机制,还引入了更快的二分匹配算法,使ED 在人群数据集上的训练更加实用。外部感知传感器被部署在自动驾驶车辆上来感知环境,使用自监督热网络(self supervised thermal network,SSTN)(Munir 等,2021)来学习特征嵌入,通过对比学习来最大化可见光和红外光谱域之间的信息,然后使用多尺度编码器—解码器Transformer 网络,将学习到的特征表示用于热目标检测。
使用结肠镜进行人工筛查的息肉漏检率很高,受DETR 的启发,Shen 等人(2021)提出用于端到端息肉检测的Transformer 卷积(convolution in Transformer,COTR)网络。COTR 由用于特征提取的CNN、用于特征编码和重新校准的交织卷积层、用于目标查询的Transformer解码器层和用于检测预测的前馈网络构成。
整体来看,目标检测Transformer 模型具有以下的优点:1)改变了使用分类和回归间接解决该问题的传统思路,利用特征提取主干网络以及具备特定先验知识的检测器进行端到端的预测;2)多头注意力机制相对于卷积能够更好地关注全局信息,对于检测遮挡目标更具优势,并可以保持相对较低的参数量;3)能够为多种目标检测任务提供解决方案。然而,该类模型也存在一些不足之处,例如对于特征图的处理会产生较大的计算量,包括翻译特征图时存在的冗余计算,对于高分辨率特征的计算,单尺度、多尺度特征图的存储和计算等。
1.2.2 视觉分割
另一类基于局部识别的方法,旨在图像或视频帧的像素级别上进行分类,主要解决视觉分割的问题。视觉分割通常包含两个子问题:语义分割和实例分割。本文将从这两个方面总结该类方法。
1)语义分割。语义分割任务需要把图像中的每一个像素赋予类别标签,而不是像目标检测仅预测出物体的矩形边界框。但是语义分割只能判断像素的类别,无法区分同类像素是否属于不同实例。语义分割在自动驾驶及医学图像等领域有着较为广泛的应用。
在医学图像分割问题中,U-Net是最常用的神经网络之一,它通过在编码器和解码器之间添加级联来保持原始特征,结合Transformer 对U-Net 进行改进吸引了不少的研究目光。Transformer-U-Net(Sha等,2021)算法通过在原始图像中添加Transformer模块来代替U-Net 的特征映射。TransUNet(Chen 等,2021e)将Transformer 和U-Net 相结合,通过恢复局部空间信息来增强更精细的细节。一方面,Transformer 对CNN 特征图中的标记化图像块进行编码,作为提取全局上下文的输入序列;另一方面,解码器对编码后的特征进行上采样,然后将其与高分辨率CNN 特征图结合,以实现精确定位。TransClaw UNet(Chang 等,2021)在编码部分结合了卷积操作和Transformer 操作。卷积部分用于提取浅层空间特征,便于上采样后图像分辨率的恢复。Transformer部分用于对补丁进行编码,自注意力机制用于获取序列间的全局信息。解码部分保留了下采样结构,以获得更好的细节分割性能。Swin-UNet(Cao 等,2021)是一种类似U-Net的纯Transformer。标记化的图像块被送入基于Transformer的U形编码器—解码器架构中,并带有用于局部全局语义特征学习的跳跃连接。UNET Transformer(Hatamizadeh 等,2022)利用Transformer作为编码器来学习输入量的序列表示,有效捕获全局多尺度信息,并遵循“ U 形”编码器解码器网络设计。Transformer 编码器通过不同分辨率的跳跃连接直接连接到解码器,以计算最终的语义分割输出。U-Transformer(Petit 等,2021)网络克服了U-Net 无法对长距离上下文交互和空间依赖性进行建模的问题。自注意力模块利用编码器特征之间的全局交互,而跳跃连接中的交叉注意力允许通过过滤掉非语义特征,在U-Net 解码器中进行精细的空间恢复。Chen 等人(2022a)提出医学图像语义分割框架TransAttUNet,联合设计了多级引导注意力和多尺度跳跃连接,以增强传统U 形结构的功能和灵活性。该框架可以有效学习编码器特征之间的非局部交互并聚合不同语义尺度的上采样特征,增强了多尺度上下文信息的表征能力,从而产生可区分的特征。
除了将Transformer 与U-Net 结合外,还有一些做出其他改进的Transformer 模型,如结合金字塔网络或卷积进行特征编码、修改自注意力机制以及设计不同的解码器。Zhang 和Zhang(2022)提出基于金字塔网络结构的多尺度注意力与CNN 特征提取相结合的新方法,即金字塔医学Transformer(pyramid medical Transformer,PMTrans)。PMTrans 通 过处理多分辨率图像来捕捉多距离关系。实现了自适应划分方案,以保留信息关系,并有效地访问不同的感受野。Wu 等人(2021c)提出一种金字塔组Transformer(pyramid group Transformer,PGT)作为逐步学习分层特征的编码器,同时降低了ViT 的计算复杂度。然后提出特征金字塔Transformer融合来自PGT编码器多个层次的语义级和空间级信息,以进行语义分割。Ji 等人(2021b)提出多复合Transformer,将丰富的特征学习和语义结构挖掘整合到一个统一的框架中,将多尺度卷积特征嵌入到表征序列中,实现尺度内和尺度间的自注意力。
Gao 等人(2021b)将自注意力集成到CNN 中,以增强医学图像分割,同时提出一种有效的自注意力机制,并结合相对位置编码,显著降低自注意力的复杂度。Segtran(Li 等,2021d)是一种基于Transformer的替代分割框架,核心是一种新颖的挤压和扩展Transformer。挤压块调节Transformer 的自注意力,扩展块学习多样化的表示。Valanarasu 等人(2021)提出一种门控轴向注意力模型,名为医学Transformer(medical Transformer,MedT),通过在自注意力模块中引入额外的控制机制来扩展现有架构。为了在医学图像上有效地训练模型,还提出了一种局部—全局训练策略,对整个图像和补丁进行操作,分别学习全局特征和局部特征。
SegFormer(Xie 等,2021b)框架将Transformer 与轻量级MLP解码器相结合。分层结构的Transformer编码器可以输出多尺度特征。该模型不需要位置编码,避免测试分辨率与训练分辨率不同而采用插值位置编码时导致的性能下降。此外,避免了复杂的解码器,用MLP 解码器聚合不同层的信息,结合局部和全局注意力呈现表示。Wang等人(2022b)引入Swin Transformer(Liu 等,2021d)作为主干来充分提取上下文信息,并设计了密集连接特征聚合模块解码器来恢复分辨率并生成分割图。Zheng 等人(2021c)将语义分割视为一个序列到序列的预测任务,部署了一个纯Transformer 来将图像编码为补丁序列。通过在Transformer 的每一层建模全局上下文,该编码器可以与简单的解码器结合以提供强大的分割Transformer 模型(segmentation Transformer,SETR),结构如图5 所示。图5(a)展示了将图像分为固定大小的补丁,线性嵌入每个补丁并添加位置嵌入,将生成的向量序列输入到标准Transformer 编码器。为了执行逐像素分割而引入了不同的解码器设计,如图5(b)展示的渐进式上采样和图5(c)展示的多级特征聚合,渐进式上采样产生称为SETRPUP 的变体,多级特征聚合产生称为SETR-MLA 的变体。在图5(b)中,考虑交替卷积层和上采样操作,为了最大限度地减轻对抗效应,将上采样限制为2 倍。因此,从尺寸为H/16 ×H/16 的某一变换层的特征达到全分辨率共需要4 次操作,其中,H和W分别指图像的高和宽的像素值。

图5 SETR 模型结构(Zheng 等,2021c)Fig.5 SETR model architecture(Zheng et al.,2021c)((a)feed the resulting sequence of vectors generated by an image to a Transformer encoder and decoder;(b)progressive upsampling;(c)multi-level feature aggregation)
Transformer 语义分割网络在其他的分割任务如肿瘤及息肉分割、透明对象分割和少样本语义分割等方面同样得到了应用。Wang 等人(2021e)首次将Transformer 融入3D CNN 来进行磁共振成像脑肿瘤分割(brain tumor segmentation,TransBTS)。为了捕获局部3D 上下文信息,编码器首先利用3D CNN 来提取体积空间特征图。同时,针对送入Transformer进行全局特征建模的标记,对特征图进行改造。解码器利用Transformer嵌入的特征并执行渐进式上采样来预测详细的分割图。PolypPVT(Dong 等,2023)利用金字塔视觉Transformer(pyramid vision Transformer,PVT)学习息肉(Polyp)分割的表示,级联融合模块从高层特征中收集息肉的语义和位置信息,伪装识别模块捕获隐藏在低层特征中的信息,相似度聚合模块将具有高层语义位置信息的息肉区域的像素特征扩展到整个息肉区域,从而融合跨层特征,有效抑制了特征中的噪声,提高了特征的表达能力。Ji 等人(2021a)为视频息肉分割任务提出渐进归一化自注意力网络,完全基于基本的归一化自注意力块,完全配备了递归和CNN,可以在单个RTX 2 080 GPU 上以实时速度有效地学习息肉视频的表征,无需后处理。
Xie等人(2021a)提出一种解决透明对象分割的方法Trans2Seg,其Transformer 编码器提供了全局感受野。通过将语义分割表述为字典查找问题,设计了一组可学习的原型作为Trans2Seg 的Transformer解码器的查询,每个原型学习整个数据集中一个类别的统计信息。Zhang等人(2021e)构建了一个具有双头透明Transformer 模型的可穿戴系统,该模型能够分割一般和透明物体并执行实时寻路,以帮助人们更安全地独自行走。
Lu 等人(2021)提出了一种基于元学习的少样本语义分割学习方法,只学习复杂分割模型的分类器部分,而冻结预先训练的编码器和解码器部分。为了解决类内变化问题,进一步提出一个分类器权重Transformer 以适应分类器的权重,它先在支持集上初始化以适应每个查询图像。Sun 等人(2021a)提出基于Transformer 的少样本语义分割方法(Transformer-based few-shot semantic segmentation,TRFS)。该模型由全局增强模块和局部增强模块组成。前者采用Transformer 块来利用全局信息,而后者采用传统卷积来利用局部信息,跨越查询和支持特征。
语义分割通常公式化为每个像素的分类任务,但也有一些将使用在实例分割中的掩膜分类用于语义分割的探索。Segmenter(Strudel 等,2021)允许在第一层和整个网络中对全局上下文进行建模,在ViT 的基础上将其扩展到语义分割。为此,依赖于与图像补丁对应的输出嵌入,并使用逐点线性解码器或掩膜Transformer解码器从这些嵌入中获取类标签。线性解码器已经可以获得很好的结果,但通过产生类掩膜的掩膜Transformer 可以进一步提高性能。Cheng 等人(2021)认为掩膜分类足够通用,可以用统一的方式解决语义和实例级分割任务,提出一个简单的掩膜分类模型MaskFormer,它预测一组二进制掩膜,每个掩膜与一个全局类别标签预测相关联。
图像分割的评价指标通常是像素精度(pixel accuracy,PA)及交并比(intersection over union,IoU)的变种。PA 为标记正确的像素占总像素的比例,IoU 计算真实值和预测值这两个集合的交集和并集之比,均交并比(mean IoU,mIoU)计算每个类的IoU后累加再平均。医学图像分割还有两种常用的评价指标,即Dice 相似系数(Dice similarity cofficient,DSC)和豪斯多夫距离(Hausdorff distance,HD)。DSC 计算两个集合的相似度,值越大两个集合越相似,HD 计算两个集合之间的距离,值越小两个集合相似度越高。表4 比较了4 个医学数据集和4个普通数据集上部分语义分割模型的表现。可以看出,Synapse multi-organ CT 医学图像数据集上Swin-UNet的分割效果最好,不同于TransUNet 和TransClaw U-Net 结合了CNN 进行特征提取,Swin-UNet 是一种类似U-Net 的纯Transformer 模型。此外,MedT 与其他一些模型相比表现不佳,可能是MedT仅引入控制机制来改进Transformer 自注意力模块,与之相比,TransAttUNet 模型则是将Transformer 自注意力与全局空间注意力相结合,能更好地模拟远程上下文交互。观察PASCAL Context(Mottaghi 等,2014)等4 个普通分割数据集内各模型的表现,可以发现同一模型的表现会随着规模的增大而有所提升,不同模型的结果总体来说相差不大,但SegFormer 可能略胜一筹。

表4 比较语义分割模型在4个医学图像数据集和4个普通分割数据集上的表现Table 4 Compare the performance of the semantic segmentation models on 4 medical image datasets and 4 general segmentation datasets
显著目标检测(salient object detection,SOD)即检测场景中最显著的目标区域,通常分为检测显著目标和分割目标的准确区域两步。本质上是对人眼注意点的预测和像素级二分类问题。所以虽然名为“目标检测”,但应属于目标检测和语义分割的结合任务。又因其最终结果更类似于分割的形式,且评价指标更接近于语义分割,故本文将其总结在本节。
Liu 等人(2021b)为RGB 和RGB-D 显著目标检测开发了一种基于纯Transformer 的统一模型,即视觉显著性Transformer(visual saliency Transformer,VST)。该模型利用多级标记融合并在Transformer框架下提出一种新的标记上采样方法,以获得高分辨率的检测结果。另外,该模型还开发了一个基于标记的多任务解码器,通过引入任务相关的标记和一个补丁任务注意力机制,同时执行显著性和边界检测。Qiu 等人(2022b)探索了Transformer 和CNN相结合的方法来学习SOD 的全局和局部表示,提出基于Transformer 的非对称双边U 网(asymmetric bilateral U-Net,ABiUNet)。非对称双边编码器具有Transformer 路径和轻量级CNN 路径,其中这两条路径在每个编码阶段通信以分别学习互补的全局上下文和局部空间细节。非对称双边解码器还包含两条路径来处理来自Transformer 和CNN 编码器路径的特征,在每个解码阶段进行通信,分别用于解码粗略的显著对象位置和查找粒度对象细节。CoSformer网络(Tang 和Li,2022)可以捕获多个图像中的显著和常见视觉模式,用于协同显著目标检测(co-salient object detection,CoSOD)任务。Transformer解决了输入顺序的影响,提高了CoSOD 任务的稳定性。还构造出一种对比度学习方案来建模图像间的可分性,并学习更具区分性的嵌入空间来区分真实的普通目标和噪声目标。
使用Transformer 的语义分割模型的优点如下:(1)由于克服了卷积结构应用于该任务的局限性,能够更好地建模全局上下文信息,因此在提升语义分割的性能方面要普遍优于含有卷积的模型;(2)通过结合经典的U 形架构或金字塔网络,能够学习多尺度、层次化的特征;(3)可适用于多种分割场景,满足医疗、行驶等广泛的现实应用。虽然使用更大规模的模型和更小的图像补丁能够取得较好的效果,但会增加计算时间和内存占用,此外对于预训练和大数据集也同样具有依赖性。
2)实例分割。实例分割类似于目标检测和语义分割的结合,相对于目标检测的边界框,实例分割输出的是掩膜,可以分割出物体的边缘,并能区分同类物体的不同实例,弥补了语义分割的不足。
Transformer 的应用使实例分割出现了许多端到端的框架。第一个端到端的实例分割Transformer(instance segmentation Transformer,ISTR)(Hu 等,2021b)预测低维掩膜嵌入,并将其与真实掩膜嵌入进行匹配,以获得集合损失。此外,ISTR 采用循环细化策略同时进行检测和分割,与现有的自上而下和自下而上的框架相比,提供了一种新的实现实例分割的方法。Dong等人(2021)基于DETR 提出端到端的实例分割框架,通过学习统一查询来分割对象(segmenting objects by learning queries,SOLQ)。学习的对象查询以统一的向量形式同时执行分类、框回归和掩膜编码。在训练阶段,通过对原始空间掩膜的压缩编码来监督编码后的掩膜向量。推理时,产生的掩膜矢量可以通过压缩编码的逆过程直接转换为空间掩膜。Yu 等人(2022)类比DETR 的思想,将实例分割看做集合预测问题提出端到端框架,使用实例感知Transformer 来分割对象(segments objects with instance-aware Transformers,SOIT),并消除了对许多手工组件的需要,如感兴趣区域(region of interest,RoI)裁剪、一对多标签分配和非极大值抑制。像素化掩膜由一组参数嵌入,以构建一个轻量级的实例感知Transformer,然后产生全分辨率掩膜,而不涉及任何基于RoI的操作。
两阶段方法(Mask RCNN 等)以及上述基于查询的实例分割方法(如ISTR,SOLQ 等)取得了显著的效果。除此之外,提高掩膜质量和简化模型方面也产生了新的研究。Mask Transfiner(Ke 等,2021)算法以较低的计算成本预测高度精确的实例掩膜。该方法不是对规则的密集张量进行操作,而是将图像区域分解并表示为四叉树,只处理检测到的容易出错的树节点,然后并行地自校正它们的错误。这些稀疏像素对最终掩膜质量是至关重要的。Transformer分割对象(segmenting objects with Transformers,SOTR)方法(Guo等,2021)简化了分割流程,该方法建立在CNN 主干上,并附加了两个并行子任务:通过Transformer 预测每个实例类别和通过多级上采样动态生成分割掩膜。SOTR 分别通过特征金字塔网络(feature pyramid network,FPN)和双Transformer 有效地提取底层特征表示,并捕获远程上下文依赖关系。
视频实例分割需要同时对视频中感兴趣的对象实例进行分类、分割和跟踪。Wang 等人(2021b)将该任务视为直接的端到端并行序列解码/预测问题,提出视频实例分割Transformer 框架(video instance segmentation Transformer,VisTR)。给定一个视频片段输入,直接输出其中每个实例的掩膜序列。核心是一种实例序列匹配和分割策略,它监督和分割整个序列级别的实例。VisTR 从相似性学习的相同角度对实例分割和跟踪进行帧处理,大大简化了整体流程。帧间通信Transformer(inter-frame communication,IFC)(Hwang 等,2021)是另一种端到端解决方案,它通过有效地编码输入片段中的上下文,显著减少了帧间信息传递的开销。
实例分割通常会使用到掩膜,评价实例分割模型可以参考掩膜平均精度(mask AP)和框平均精度(box AP),前者用于综合评价实例分割模型效能,后者用于综合评价目标检测模型效能。表5 比较了上述部分实例分割模型在COCO(Lin 等,2014)测试集上基于不同主干网络(backbone)的掩膜平均精准度(APm)和框平均精度(APb)的表现。COCO 数据集的评价指标AP等在1.2.1节已有介绍。从表5中可以看出,使用了Swin-L(Liu 等,2021d)作为主干网络的SOLQ和SOIT模型相比于使用ResNet的其他模型实现了较大的精度提升,表明了利用移动窗口计算分层Transformer表征的方法对分割任务具有较大的益处。另外值得注意的是,SOTR模型虽然在多数指标上不如上述模型,但在中型和大型物体检测掩膜平均精度上取得了最好的结果。

表5 实例分割模型在COCO测试集上基于不同主干网络的掩膜平均精准度(APm)和框平均精度(APb)比较Table 5 Compare the average precisions of mask(APm)and box(APb)based on different backbone networks of the instance segmentation models on the COCO test-dev set /%
Transformer 用于实例分割的模型不同于以往自顶向下和自底向上的方法,该类模型一般属于端到端的方法,能够同时进行检测和分割。此外,在视频实例分割方面可以实现帧间物体的关联和跟踪。然而,Transformer对底层特征不够敏感,大多模型需要结合CNN或FPN来提高在小物体预测上的表现。另外,一些端到端的方法使用低维掩膜会造成信息损失,学习更精细的掩膜或许能够令结果有进一步提升。
1.3 人脸识别
人脸识别旨在为图像或视频帧中的人脸赋予一个类别标签,相当于图像分类的一种特例。人脸识别技术已经较为成熟并广泛地应用于现实生活。与此同时,Transformer 在NLP 及其他视觉任务上表现出的优异性能、其端到端的模型特点、更强的表达能力和对大规模数据的适用性催生了一些优化人脸识别框架的研究。Zhong 和Deng(2021)研究了Transformer 模型应用于人脸识别的性能,证明在参数量和乘加运算量相似的情况下,Transformer 模型可以达到与CNN 相当的性能。Wu等人(2017)在CNN 中引入了递归空间Transformer(recursive spatial Transformer,ReST)模块,允许以端到端的方式将人脸矫正与人脸识别联合学习,成为一种有效的免矫正人脸识别解决方案。ReST 具有内在的递归结构,能够逐渐将人脸与标准人脸对齐,可以处理较大的人脸变化。为了对非刚性变换建模,将多个ReST模块组织成层次结构,以考虑人脸的不同部分,所提出的HiReST-9(hierarchical ReST)模型结构如图6 所示。种族因素已被证明是公平人脸识别的一个难题,因为受试者相关的特定属性会导致分类偏差,Li 等人(2021e)将人脸身份相关的表征抽象为一个信号去噪问题,并提出渐进交叉Transformer(progressive cross Transformer,PCT)方法,在达到最先进的人脸识别性能的同时,能够减轻种族偏差。可视化结果表明,PCT 中的注意力图能够很好地揭示与种族相关或有偏差的面部区域。Clusformer(Nguyen 等,2021)是一种基于Transformer的自动视觉聚类方法,通过无监督的注意力机制来实现大规模人脸识别和视觉地标识别。该方法能够很好地处理噪声或硬样本,在端到端框架中还可以灵活有效地与多种规模的不同深度网络模型进行协作。

图6 HiReST-9模型结构(Wu等,2017)Fig.6 HiReST-9 model architecture(Wu et al.,2017)
除了人脸识别外,一些研究注重于人脸的表情识别。人脸表情本身极其复杂,情绪重叠,这决定了表情数据集不可避免地带有错误标记或不确定的数据。为了解决这个问题,Zhao等人(2021a)结合贝叶斯理论为人脸表情识别(facial expression recognition,FER)任务提出一种基于Transformer 的架构,并对特征提取模块和训练策略进行改进,形成了自适应自愈网络(adapted self-cure network,Adapted-SCN)来抑制训练数据的不确定性。Li 等人(2021a)提出一种用于野外FER 的基于纯Transformer 的掩膜视觉模型,它由两个模块组成:基于Transformer的掩膜生成网络,用于生成能够滤除复杂背景和人脸图像遮挡的掩膜;动态重新标记模块,用于纠正野外FER 数据集中的错误标签。Ling 等人(2021)提出一种面向课堂智能学习的人脸表情识别系统。首先使用YOLO(you only look once)从高分辨率视频中提取多个学生的人脸图像;然后对人脸图像进行预处理,使用基于自注意力的ViT 模型来识别人脸表情;最后利用分类后的人脸表情辅助教师分析学生的学习状况,从而为提高教学效果提供建议。相较于上述先从视频中提取人脸图像再进行静态识别的方法,陈港等人(2022)采用端到端的学习方式,直接对视频序列进行表情识别。将视频序列分为固定帧数的片段,从每帧图像学习表情特征,从而生成固定维度的视频片段空间特征,再利用Transformer 模型学习其中的注意力特征,最后通过最大池化一个视频所有片段的分类数值实现该视频的表情识别。
比较上述部分模型在主流基准数据集LFW(labeled faces in the wild)(Huang 等,2008)和FERPlus(Barsoum 等,2016)上的表现,如表6 所示,其中ViT-P8S8和T2T-ViT 模型(Zhong和Deng,2021)引用了ViT(Dosovitskiy 等,2021)和T2T-ViT(Yuan 等,2021)。LFW 人脸数据集是人脸识别的常用数据集,该数据集的图像主要是从互联网中搜集来源于生活自然场景的人脸图像。FERPlus 是人脸表情识别常用的数据集。人脸识别通常是用准确率来评价算法性能。从表6 可以看出,无论是人脸识别还是表情识别,不同模型的结果相差不多。对于人脸识别,所有模型都取得较好的结果,准确率都在99%以上;对于人脸表情识别,不同模型的准确率在90%左右。

表6 比较LFW数据集上人脸识别模型和FERPlus数据集上人脸表情识别模型的准确率Table 6 The accuracies comparison of the face recognition models on the LFW dataset and the facial expression recognition models on the FERPlus dataset /%
Transformer 应用于人脸识别同样能够取得较好的结果,根据上述模型总结其优点如下:1)传统的人脸识别流程通常包括矫正和识别,即先将人脸对齐到预定义的模板上,再提取特征进行识别。使用Transformer 实现了以端到端的方式同时进行矫正和识别,其中的注意力机制关注面部区域,还能够处理丰富多样的人脸特征,并且为处理数据集中易引起偏见的种族属性、具有标签不确定性的人脸表情或其他噪声提供了更多解决方案。2)为识别任务提供了不同的训练策略,例如PCT 对人脸识别和种族分类以多任务方式训练,以及无监督训练、自适应自愈网络。然而,目前这类模型还存在一些不足之处,例如:在遮挡鲁棒性方面的表现并不优于CNN,无法在相对较小的数据集上发挥最佳效果,分层递归的中间输出可能存在冗余等。
1.4 动作识别
动作识别任务通常需要对给定图像或视频中的人体动作进行分类,是图像分类或视频分类的特例。动作识别研究已有几十年的历史,之前常用的深度学习网络,主要包括双流(two-stream)网络、三维卷积(convolutional 3D,C3D)和RNN。由于Transformer可以更好地建模长时间的时空依赖关系,最近两年采用Transformer 进行动作识别的方法也逐渐增多。动作识别的输入可以是单种模态如RGB 视频、骨架视频、深度图或是多种模态的结合。目前,尚无单独使用深度图采用Transformer 进行动作识别的方法。因此,本文接下来将分别介绍其他几种输入下使用Transformer进行动作识别的研究进展。
RGB 视频易于获得,也是最常用的动作识别模态,网络模型可以从其中包含的形状、颜色和纹理等信息提取动作特征。Girdhar 等人(2019)提出Action Transformer 模型用于识别和定位视频片段中的人体动作,如图7 所示。通过使用高分辨率、因人而异的以及与类别无关的查询,该模型可以自发地学习跟踪单个人,并从其他人的行为中提取语义上下文。此外,它的注意力机制学习强调手和脸,这往往是区分动作的关键。

图7 Action Transformer(Girdhar等,2019)识别人类动作,如“牵手”和“看着一个人”Fig.7 Action Transformer(Girdhar et al.,2019)recognizes human actions such as “holding hands” and “watching a person”
Jiang 等人(2021)关注视频动作识别中外观和运动信息间的关系,提出一种双路径Transformer 网络(two-pathway Transformer network,TTN),使用基于记忆的注意力来探索这种关系。解码器将一条路径的特征作为查询(q),而将另一条路径的特征作为关键字(k)和值(v)。然后根据q 和k 估计的相似度矩阵,从v 中选择相关信息,对最终的分类任务进行查询增强。Jin 等人(2021)改进了Transformer,以改善特征之间的依赖关系,减少特征表示的误差。该改进的模型采用ResNet(2+1)D 卷积来捕获输入视频序列的低层局部时空特征,并作为其输入以获得全局注意力。同时,采用类似于通道注意力的方法动态更新序列数据的潜在时域维权重,从而更好地将特征映射到类别标签。Cai 等人(2021)提出Action-Transformer,主要由3 个模块组成:时空变换模块将分割的短视频映射成空间和时间特征;混合特征注意力模块从空间和时间特征中提取细粒度特征并产生混合特征;残差变换模块结合注意力、前馈网络和残差机制,从混合特征中提取局部和全局特征。Mazzia 等人(2022)提出了一种简单的、完全自注意力的架构,其性能优于混合了卷积、递归和注意力层的更复杂的网络。
由于未剪辑的视频中可能包含若干个动作,一些研究者采用Transfomer 进行动作检测,旨在定位视频中的动作。Zhao 等人(2022)提出第一个基于Transformer 的端到端动作检测网络:边界框序列Transformer(Tubelet-Transformer,TubeR),其编码器和解码器针对建模可变长度和纵横比的动作边界框序列进行了优化。TubeR 不依赖于手工设计的边界框序列结构,自动学习一组与动作相关的边界框序列查询。通过学习动作边界框序列嵌入,TubeR 以灵活的空间和时间范围预测更精确的动作边界框序列。Liu等人(2022a)构建了基于Transformer 的端到端时间动作检测框架(temporal action detection Transformer,TadTR),它将所有动作实例同时预测为一组标签和时间位置。TadTR 能够通过选择性地关注视频中的多个片段,自适应地提取进行动作预测所需的时间上下文信息。
上述方法的动作识别往往是识别单人或双人的动作,还有一类动作识别旨在识别3 人以上的动作,称为群体动作识别。一些研究者也采用Transformer模型尝试进行群体动作识别。Li 等人(2021c)提出了一种群体动作识别网络GroupFormer,为推理群体动作的时空上下文表示建模。同时,引入了聚类注意力机制来对个体进行分组,并利用群体内和群体间的关系来实现更好的群体信息特征提取。Zhang等人(2021a)采用视频Transformer,提出了一种视频和图像联合训练(co-training video Transformer,CoVeR)的方法。该方法一方面可以对不同视频数据集和标签空间联合训练以获得语义信息(例如,Kinetics 数据集侧重于外观,而something-something数据集侧重于运动);另一方面通过与图像(如单帧视频)协同训练,更好地学习视频表示。
随着基于RGB 视频的动作识别准确率不断提升,一些研究者开始研究基于3D 数据的动作识别。三维骨架数据是运动动力学的有效表示,不容易受到光线、场景变化等因素的影响。Shi等人(2021)提出基于骨架的人体动作识别模型,该模型在空间维度上具有稀疏注意力,在时间维度上具有分段线性注意力。时空Transformer 网络(spatial temporal Transformer,ST-TR)(Plizzari 等,2021)使 用Transformer 自注意力建模关节之间的依赖关系。在STTR模型中,空间自注意力(spatial self-attention,SSA)模块用于理解不同身体部位之间的帧内交互,时间自注意力(temporal self-attention,TSA)模块用于对帧间相关性进行建模。两者的建模过程如图8 所示,自注意力通过为每一对节点计算一个代表它们之间关联强度的权重,从而评价每个身体关节ni的贡献度。
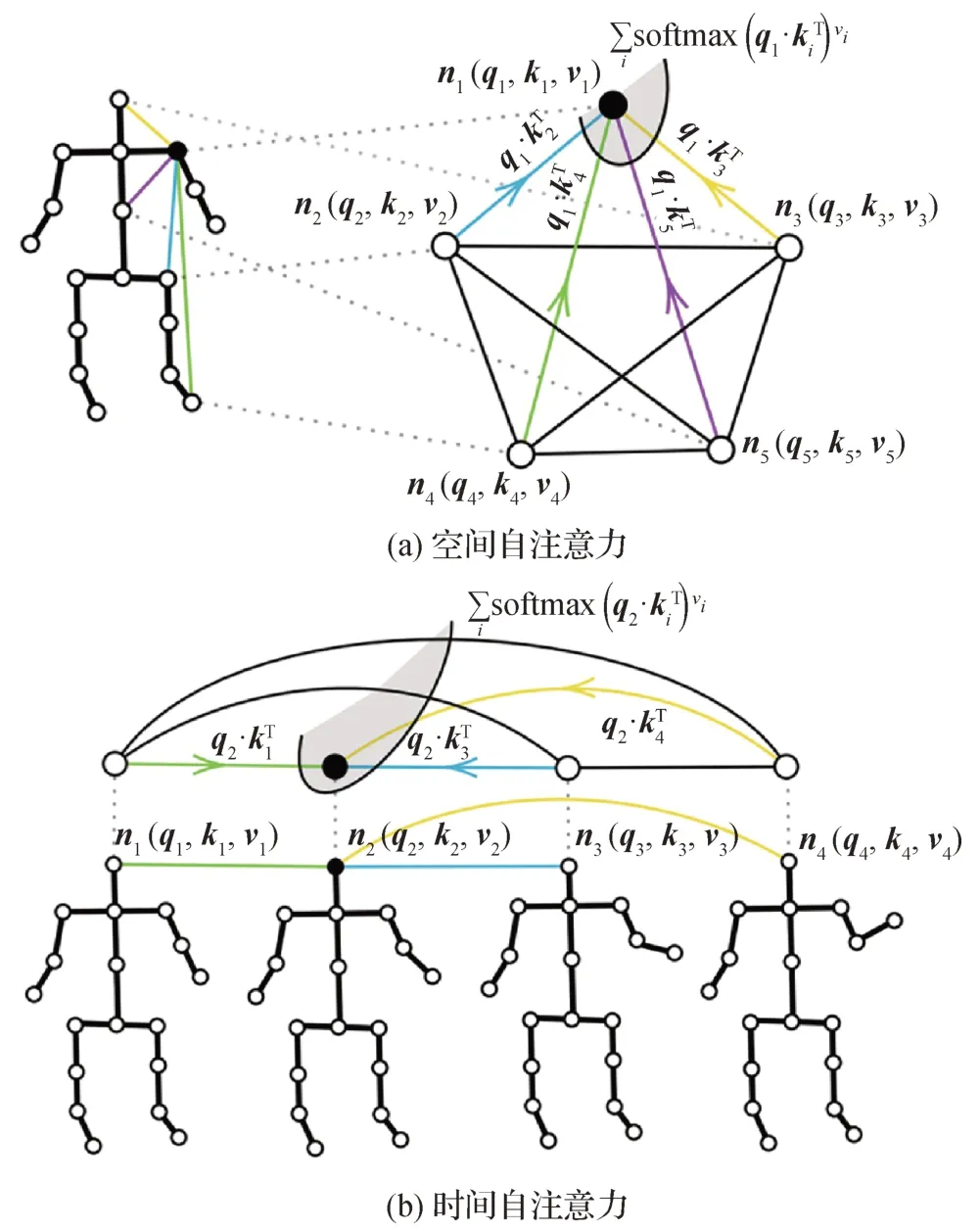
图8 空间自注意力和时间自注意力的建模过程(Plizzari等,2021)Fig.8 Modeling process of SSA and TSA(Plizzari et al.,2021)((a)SSA;(b)TSA)
时空元组Transformer(spatio-temporal tuples Transformer,STTFormer)方法(Qiu 等,2022a)将骨架序列分成若干部分,并对每个部分中包含的几个连续帧进行编码,同时使用一种时空元组自注意力模块来捕捉连续帧中不同关节之间的关系。此外,在非相邻帧之间引入特征聚合模块,以增强区分相似动作的能力。避免利用单个关节之间的交互,Wang等人(2021c)提出部件内—部件间的Transformer 网络(intra-inter-part Transformer,IIP-Transformer),同时合并身体关节和部件交互,可以高效地捕获关节级别(部件内)和部件级别(部件间)的依赖关系。该网络还引入了一种局部级骨架数据编码,降低了计算复杂度,对关节级骨架噪声具有更强的鲁棒性。
骨架数据其实就是一个动态的骨架图序列,每一帧的骨架构成一幅图。因此,研究者会在Transformer模型中加入图卷积网络(graph convolution network,GCN)用来编码骨架图。为了克服GCN邻域约束和纠缠时空特征表示的局限性,Bai等人(2022)设计了一个解纠缠时空Transformer 块,并提出了层次图卷积骨架Transformer(hierarchical graph convolutional skeleton Transformer,HGCT),以利用GCN(局部拓扑、时间动态和层次化)和Transformer(全局上下文和动态注意力)的互补优势。多尺度时间Transformer(Kong 等,2022)将原始骨架数据嵌入到GCN 块和多尺度时间嵌入模块以提取不同时间尺度的特征,并作为Transformer 编码器的输入进行动作识别。与前面方法不同的是,Meng 等人(2022)将Transformer 提取的图像特征作为GCN 的输入,采用引入自适应图卷积层的ST-GCN网络进行动作识别。
单模态动作识别得到了广泛的研究,但单一数据模态各有优势和局限性;而多模态的分析可以更好地研究多种模态的互补特性,例如融合RGB 和深度(depth)数据或其他易获得的数据,达到更高的性能水平。Li 等人(2022a)提出以自我为中心的动作识别框架(Transformer-based egocentric action recognition,Trear),采用自注意力机制对来自RGB 和depth 两种模态的数据的时间结构进行建模。Chen和Ho(2022)提出融合RGB 视频和音频的多模态视频Transformer(multi-modal video Transformer,MMViT)。与仅使用解码的RGB 帧的其他方案不同,MM-ViT仅在压缩视频域中操作,并利用所有容易获得的模态,即外观(I帧)、运动矢量、残差和音频波形。
表7 显示了基于RGB、骨架及多模态数据的不同动作识别方法的结果。其中,使用来源于现实生活场景的动作识别数据集UCF 101(Soomro 等,2012)评价基于RGB 或多模态的模型性能,使用大型人体骨架动作识别数据集NTU 60(Shahroudy 等,2016)及NTU 120(Liu 等,2020)评价基于骨架的模型性能。表7 中X-Sub,X-View 和X-Set 表示不同的实验设置。从表7 可以看出,基于RGB 的动作识别模型中,3 个结合卷积的模型结果明显优于纯Transformer 的模型。同时在基于骨架的动作识别模型中,结合图卷积的HGCT 基本上在所有指标上取得了最好的结果,纯Transformer 模型STTFormer 和IIPTransformer 也实现了与HGCT 相当的性能。或许Transformer 与卷积网络相结合更有利于进行动作识别,但纯Transformer 动作识别模型仍有很大的探索空间。另外,融合RGB 视频和音频的多模态动作识别模型(MM-ViT)准确率要比单纯使用RGB 模型的最好结果(TTN-I3D)高出1%,这也说明了融合多种模态在动作识别方面具有优势。

表7 比较UCF 101数据集以及NTU 60和NTU 120数据集上动作识别模型的准确率Table 7 Comparing the accuracy of action recognition models on UCF 101,NTU 60 and NTU 120 datasets /%
上述应用于动作识别的Transformer模型的优点可以概括为以下几点:1)Transformer 与卷积或图卷积相结合可以捕获低层局部特征和高层全局特征,从而减少特征表示的误差;2)Transformer 能够更好地融合不同类型的特征(如外观和运动特征),并建模两者间复杂的交互;3)对于包含多个动作的视频,Transformer 实现了端到端的动作检测和识别;4)利用一些新的训练方法(如CoVeR),能够改进Transformer 依赖预训练的问题,并为训练可泛化的通用动作识别模型提供了解决思路;5)多模态动作识别Transformer 模型利用自注意力建模单种模态内的特征,并利用互注意力融合多种模态间的特征,能够实现比单一RGB数据输入更好的效果。
同样地,该类模型也存在一些缺点。例如:1)Transformer 需要一些其他的辅助才能发挥更好的效果。例如,Girdhar 等人(2019)表示添加光流作为输入可能会提高模型性能,Jiang 等人(2021)也表示将运动特征显式输入到Transformer中优于其本身对时间关系的自学习。2)一次性地处理具有多人动作的长视频时,模型需要大量查询,这会导致自注意力层出现记忆问题,影响识别性能。3)卷积主干通常使用到大部分的计算量和内存占用量。
1.5 姿态估计
姿态估计旨在找出人体关键点的位置并确定部位间空间关系。通常可以采用自上而下,或自下而上的方法进行姿态估计。自上而下的方法一般涉及两个任务:人体检测和关键点确定。自下而上的方法一般需要完成身体部位预测和人体模型拟合两个任务。其中,人体检测和身体部位预测需要用到目标检测的技术,因此,姿态估计可以归为局部识别任务的一个实例。本节将对姿态估计中采用Transformer 的方法进行总结。根据输入数据的不同,姿态估计任务可以划分为:2D 姿态估计和3D 姿态估计。前者一般是确定身体部位,如头、手、膝盖等的二维坐标,后者在二维坐标的基础上增加了深度信息。本节分别介绍在2D 和3D 姿态估计以及一种特别的手势姿态估计中Transformer的应用。
在2D姿态估计中,常用的是对关键点坐标进行回归的方法或基于热图的方法。基于回归的方法精度一般,基于热图的方法受制于各种启发式设计,于是结合Transformer来优化模型的研究取得了一定的进展。Li 等人(2021b)提出了一种基于回归的使用级联Transformer 的姿态识别方法(pose regression Transformers,PRTR)。利用Transformer 中的编解码器结构来执行基于回归的人员和关键点检测,展示了关键点假设(查询)在不同自注意力层次上的细化过程,揭示了Transformer 中自注意力的递归机制。如图9 所示,在解码过程中,PRTR 通过增加置信度和减少相对真实值的空间偏差来预测关键点,从而将图像无关的查询转换为最终的预测。
图9 PRTR(Li等,2021b)跨不同Transformer解码器层逐渐细化关键点的图示Fig.9 Illustration of PRTR(Li et al.,2021b)gradually refining the keypoints across different Transformer decoder layers
Mao 等人(2021)也提出了基于回归的Transformer 人体姿态估计框架(Transformer-based pose estimation,TFPose),将该任务转化为序列预测问题。框架绕过了基于热图的缺点,能够自适应地关注与目标关键点最相关的特征,这克服了以往基于回归方法的特征不匹配问题,大大提高了性能。Stoffl 等人(2021)提出端到端的多实例姿态估计方法(pose estimation Transformer,POET),结合CNN 和Transformer 结构,能够利用二部匹配方案直接回归所有个体的姿态。使用基于集合的全局损失进行训练,该损失由关键点损失、可见性损失和类别损失组成。POET 推理检测到的个体与完整图像上下文之间的关系,可以直接并行预测姿态。TransPose(Yang 等,2021b)模型中内置的注意力层使其能够有效地捕获远程关系,还可以揭示预测的关键点依赖于什么。为了预测关键点热图,最后一个注意力层充当聚合器,收集图像线索并形成关键点的最大位置。
本节在COCO(Lin 等,2014)验证集和测试集上对比了上述2D 姿态估计模型采用不同输入分辨率(input size)的参数量(Params)、浮点运算数(FLOPs)、平均精准度(AP)和平均召回率(average recall,AR),如表8 和表9 所示。COCO 数据集的评价指标AP 等在1.2.1 节已有介绍,平均召回率(AR)评价找到所有正样本的能力。综合来看,以HRNet 作为主干网络进行姿态估计的模型(PRTRHRNet-W32,TransPose-H-A4,TransPose-H-A6)要优于ResNet 作为主干网络的模型(PRTR-ResNet50,PRTR-ResNet101,TransPose-R-A4,TransPose-R-S),因为前者可以保持高分辨率表征,这对于关键点检测是十分有利的,但这也带来了更高的计算复杂度。然而,无论是以HRNet 还是ResNet 作为主干网络,TransPose 模型在这两种数据集上都取得了最好的结果,并保持了较低的计算复杂度。

表8 比较COCO验证集上不同2D姿态估计模型采用不同输入分辨率的参数量、浮点运算数、平均精准度和平均召回率Table 8 Compare the Params,FLOPs,AP and AR of different 2D pose estimation models using different input size on the COCO validation set

表9 比较COCO测试集上不同2D姿态估计模型采用不同输入分辨率的参数量、浮点运算数、平均精准度和平均召回率Table 9 Compare the Params,FLOPs,AP and AR of different 2D pose estimation models using different input size on the COCO test-dev set
应用于2D 姿态估计的Transformer 模型具有以下几个方面的优点:1)通过可视化注意力对关键点的建模,可以解决特征错位的问题,也能够发现身体关节间的上下文和结构化关系,如对称关节、相邻关节更容易相互关注;2)Transformer 中注意力逐层细化特征匹配的优势,能够提高基于回归的姿态估计性能;3)在解码器配置方面,从宽度上看,使用更多的通道特征图能获得更高的精度,从深度上看,性能在前3 层增长并在第4 层达到饱和(Mao 等,2021),平均性能在3~5层后趋于稳定(Stoffl等,2021)。
虽然使用Transformer很大程度上提高了基于回归的姿态估计的性能,但完全避免热图计算可能会造成速度和精度上的不足,难以达到最优,正如与基于回归的模型PRTR、TFPose、POET 相比,仅使用编码器进行纯热图预测的TransPose 通过更少的参数和更快的速度,实现了最先进的性能。然而,Yang等人(2021b)的实验结果显示即使有较长的训练周期其性能,也不如微调过的模型,这是目前姿态估计Transformer的另外一点不足。
3D 姿态估计同样存在使用Transformer 优化特征学习和全局关系建模的研究。Lifting Transformer(Li 等,2022c)将一系列2D 关节位置提升到3D 姿态,应对从冗余序列中学习具有鉴别性的单姿态表示的挑战性。Zhao 等人(2021b)提出结合图卷积的Transformer架构GraFormer,用于3D姿态估计。Gra-Former 包含两个重复堆叠的核心模块:图注意力和切比雪夫(Chebyshev)图卷积。图注意力使所有2D关节能够在全局感受野中进行交互,而不会削弱关节的图结构信息。切比雪夫图卷积使二维关节能够在高阶球面上进行交互,从而表达了关节之间隐藏的隐式关系。由于三维人体姿态估计面临多个可变因素,包括观看次数、视频序列长度、是否使用摄像机标定等,因此,Shuai 等人(2022)提出了一个统一的框架,称为多视图和时间融合Transformer(multiview and temporal fusing Transformer,MTFTransformer),自适应处理变化的视图数和视频长度而无需校准,由特征提取器、多视图融合Transformer和时间融合Transformer 组成。PoseFormer(Zheng等,2021a)是一种完全基于Transformer 的3D 人体姿态估计方法,不涉及卷积架构。其中的时空Transformer 结构全面建模每一帧内的人体关节关系以及帧间的时间关联,然后输出中心帧的准确三维人体姿态。
Human3.6M(Ionescu 等,2014)是3D 姿态估计常用的数据集,该数据集包括360 万幅3D 人体姿态和相应图像,由11 名专业演员模拟了讨论、吸烟、拍照等17种情景。表10比较了上述3D姿态估计模型在Human3.6M 数据集上的表现。其中,Dr、Ds、Ea、Gr、Pn、Pt、Ps、Pu、St、Sd、Sm、Wi、Wd、Wk、Wt 分别代表指示方向、讨论、吃、问候、打电话、拍照、摆姿势、购买、坐在椅子上、坐着活动、吸烟、等待、遛狗、行走、一起行走等训练动作情景。3D 姿态估计常用的评价指标有“每个关节位置误差均值”(mean per joint position error,MPJPE),通常称为协议1,此外还有协议2(P-MPJPE),先经过旋转、对齐等变换再计算MPJPE,指标越小,则算法表现越好。从表10 中可以看出,使用协议1作为评价指标的模型中,MTFTransformer 实现了各个情景下的最佳表现,说明多视图融合的Transformer模型能更好地适应多变的人体姿态估计场景。Lifting Transformer 和PoseFormer模型在协议1的结果不相上下,而后者在协议2的表现更好,这说明纯Transformer 模型对于变换可能更具鲁棒性。

表10 分别使用协议1和协议2定量比较3D姿态估计模型在Human3.6M上的表现Table 10 Use protocol 1 and protocol 2 to quantitatively compare the performance of 3D pose estimation models on Human3.6M /%
3D 姿态估计通常是经2D 姿态估计后再提升到3D 姿态(2D-to-3D pose lifting)。Transformer 处理长期依赖的能力使其可以更好地利用时间信息,进而减少2D 到3D 映射时产生的深度歧义。在网络结构方面,注意力与图卷积结合不仅可以融合所有节点的信息,还可以对隐式和显式拓扑结构进行建模,平衡了性能和参数量。Transformer 模型对多变的姿态估计场景还具有鲁棒性,如MTF-Transformer和Pose-Former。
虽然Transformer在一定程度上减少了二维坐标向深度映射的歧义,但仍存在模糊性,例如生成了多个假设但是没有建立不同假设特征之间的联系。另外,将每帧的2D 姿态视为标记来处理时,如果遇到长帧序列则会产生大量的内存和计算量。
Transformer 的识别能力也被手势姿态估计的研究者所关注。Hampali 等人(2021)提出一种用于从单色图像中估计密切交互的双手的3D 姿势。该方法首先提取双手关节的一组潜在2D 位置作为热图的极值,使用这些位置的外观和空间编码作为Transformer 的输入,利用注意力机制来整理关节的正确配置并输出双手的3D 姿势。该方法结合了Transformer 的识别能力与基于热图的方法的准确性。Hu 等人(2021a)引入了第一个带有手部先验知识的自监督预训练SignBERT 用于手语识别。将手部姿势视为视觉标记,被嵌入手势状态、时间和手性信息。SignBERT 首先通过掩膜和重构视觉标记进行自我监督的预训练,结合几种掩膜建模策略,将手部先验知识加入到模型感知方法中,以更好地建模层次上下文,然后加上预测头,对SignBERT 微调来执行识别。
1.6 多任务方法
在NLP领域已经出现了如GPT(Brown等,2020)这种可以处理多个不同类型下游任务的大规模Transformer 模型,但目前CV 领域提出的视觉Transformer 模型多数是针对单一任务使用,视觉领域同样期待能够统一多种任务的Transformer 模型的出现。本节整理了一些可以用于图像分类、目标检测及语义分割等多种视觉任务,或可以用于语言和视觉领域的通用模型。
Yang 等人(2021a)提出了聚焦自注意力,一种结合细粒度局部交互和粗粒度全局交互的机制。每个标记以细粒度处理周围最近的标记,以粗粒度处理远的标记,从而可以高效地捕获短程和长程视觉依赖。基于此机制提出一种视觉Transformer模型变体,称为聚焦Transformer,可用于图像分类、目标检测及语义分割任务。PVT(Wang 等,2021a)是一种用于密集预测任务(如目标检测和语义分割)的纯Transformer 主干网络。其中提出的渐进收缩金字塔和空间缩减注意力层,使得在有限的计算/内存资源下获得高分辨率和多尺度的特征地图。Zhang 等人(2021f)提出了一种新的ViT 结构的多尺度视觉Longformer,以解决普通ViT 模型无法应用于需要高分辨率特征图的视觉任务的计算和存储效率问题,并在图像分类和目标检测方面优于多条基线模型。Heo 等人(2021)研究了空间维度转换在基于Transformer的架构中的作用及其有效性,并在原ViT模型的基础上提出了一种合并池化层的模型(poolingbased vision Transformer,PiT)。与ViT相比,PiT实现了改进的模型能力和泛化性能,在图像分类、目标检测和鲁棒性评价等任务上,PiT优于基线模型。从语言到视觉的转换面临的挑战来自于两个领域之间的差异,例如视觉实体规模的巨大差异以及图像中像素相对于文本中单词的高分辨率,Liu 等人(2021d)提出了一种分层Transformer(Swin Transformer)来解决上述差异,其表示是用移动窗口计算的。移动窗口方案将自注意力计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了效率。这种分层结构具有在不同尺度下建模的灵活性,并且相对于图像大小具有线性计算复杂性。Swin Transformer的这些特性使其能够与广泛的视觉任务兼容,包括图像分类、目标检测及语义分割等任务。Hu 和Singh(2021)提出了一个统一的Transformer模型(unified Transformer,UniT),可以应用于多个领域,在一个统一的编码器—解码器模型中共同处理多个任务。UniT 模型同时处理8 个数据集上的7 个任务,在单个训练步骤中学习它们,并通过一组紧凑的共享参数在每个任务上实现强大的性能。通过领域无关的Transformer 架构,模型能够处理包括目标检测、自然语言理解和多模态推理等任务。
此类Transformer 模型为多种下游任务提供了Transformer 主干网络的选择,改进了模型泛化性能。对于普通ViT 无法直接适用于需要高分辨率和多尺度特征图的下游任务的问题,探索出了向Transformer 中加入分层结构的解决方案。目前各种视觉任务下的先进模型已广泛使用到Swin Transformer主干,其移动窗口方案大大提高了建模灵活性和计算效率。同时,一些能够处理视觉和语言差异的模型也为多模态任务提供了融合或互相转化的方法。然而,目前领域主要探索了通用于图像分类、目标检测和语义分割任务的模型,对于是否还能加入其他任务的研究较少。另外,这些通用模型需要对特定任务微调,难以在多个任务间共享参数。
2 挑战及未来展望
视觉Transformer 展示出了巨大的潜力,为处理多种视觉任务提供了新的解决思路,可以将Transformer 与CNN 结合使用,也可以使用纯Transformer模型。而视觉Transformer的潜力尚未得到充分的开发,还无法完全颠覆CNN 的主导地位,为了促进其发展,本节总结了现有的研究挑战,并对未来的研究方向提出了一些建议。
1)位置编码是一个尚待研究的问题。Transformer 模型核心是自注意力机制,但该机制本身是没有位置信息的,而位置信息对于序列来说十分重要,Transformer 的提出者使用位置编码来弥补这个缺陷。根据编码方式的不同,可以分为绝对位置编码和相对位置编码,现有一些相对位置编码方法已被证明在NLP 领域普遍有效,而CV 领域还有待研究。例如iRPE(Wu 等,2021b)是现有的一种针对二维图像的相对位置编码方法。此外,相对于显式地设置位置向量,还有一些隐式位置编码方式值得研究。例如CNN 本身便可以隐式地编码位置信息(Islam 等,2020),利用卷积获得像素级注意力来编码位置(Zhang 和Yang,2021)能更好地适应于输入序列长度不一的场景。分析位置编码在视觉Transformer 中应用的优缺点,探索有效的编码方法是一个值得研究的方向。
2)兼顾性能和成本的研究。视觉Transformer模型不具备CNN 的归纳偏置能力,需要使用足够多的训练数据才能表现出高性能,而在数据集较小的情况下,CNN 更为有效,Dosovitskiy 等人(2021)证明了这一点。此外,从第1 节公开数据集上的实验结果可以看出,Transformer 模型使用大量参数,自注意力的运算量非常大。大数据训练需要更严格的设备条件,高运算量影响了速度,限制了一些实时应用,如何降低部署Transformer 模型的资源成本,提高速度又能维持精度也是研究的重点。
3)更多的自监督学习方法。由于Transformer模型对大数据的依赖,通常使用大规模无标签数据集进行预训练,然后学习到的表示以监督的方式在下游任务上进行微调,提高了性能并减少了人工标注成本。Atito 等人(2021)研究了自监督学习对预训练视觉Transformer 的优点,然后将其用于下游分类任务。他们提出了自监督视觉Transformer,并讨论了几种自监督训练机制,以获得一个前置模型。计算机视觉中自监督学习的重要问题是使用怎样的前置任务,使得模型可以学习到更好的数据特征。一些前置任务设计方法如图像着色、图像修复、相对位置预测和帧排序,诸如此类的自监督学习方法也将吸引更多的研究目光。
4)处理多模态数据。Transformer 因其端到端的结构特性和强大的自注意力机制,具备很强的多模态融合能力,任何模态的信息都可以转化为向量序列在输入端进行融合。多模态任务主要是挖掘不同模态之间的互补性,例如预训练的视觉和语言BERT 模型的目标是学习结合两种模态的表征,Frank 等人(2021)提出一种跨模态输入消融诊断方法来评估这些模型学习使用跨模态信息的程度,发现在去除视觉信息时预测文本的相对难度要比在去除文本时预测视觉信息的相对难度大得多,这表明这些模型的跨模态不是对称的。特别地,对于一些零样本识别任务,单纯地利用视觉模态的方法可能无法获得较好的结果,未来需要提出更多融合其他模态(如文本)的方法进行识别。因此,Transformer多模态模型还有很大的进步空间。
当视觉Transformer 模型应用于识别任务时,也存在着不同的研究挑战或问题,基于此类问题本节也给出了一些未来研究方向。
1)全局识别任务。诸如图像分类、视频分类的全局识别任务面临以下几种挑战:(1)对大数据预训练存在过分依赖的问题,该问题可以通过更多更先进的训练方式来解决,例如蒸馏学习、自监督学习。(2)输入序列长度不一时,经典的位置编码难以直接适用,Zhang 和Yang(2021)将位置编码构造为空间注意力,避免了插值或微调。如何提供更有效的位置编码是一个亟待解决的研究挑战。(3)多数研究仅使用Transformer 编码器来解决此类任务,而解码器能否在其中发挥作用也可以作为一种研究方向。例如,Liu 等人(2021c)提出的Query2Label 方法使用Transformer解码器来解决多标签图像分类问题。
2)局部识别任务。以目标检测、语义分割和实例分割为代表的局部识别任务面临的挑战可以分为以下两个方面:(1)目标检测模型通常需要一个任务无关的主干网络来提取特征,虽然WB-DETR 证明了无主干的可行性,但对于主干网络的探索仍值得关注。原始的ViT 难以直接作为目标检测、分割等下游任务的主干,因此Transformer 在目标检测中更多用来探索特定于任务的检测器,若要作为下游任务的主干使用,更多是重新设计以引入分层结构,例如PVT(Wang 等,2021a)和Swin Transformer(Liu 等,2021d)。而 Li 等人(2022b)指出传统卷积主干的多尺度和分层架构会影响检测器的设计,进而探索了如何使用非层次化的ViT 主干进行目标检测。诸如此类对上下游任务通用主干的研究是具有挑战性的。(2)虽然目标检测、分割任务具有较强的实际应用价值,而目前研究的Transformer 模型大多难以部署到现实场景,例如以FLOPs 和参数量衡量计算效率可能是片面的并且对硬件不敏感,不能反映推理速度或延迟。Xia 等人(2022)直接将特定硬件上的TensorRT延迟作为效率指标,能够反馈计算能力、内存成本和带宽,以此指标重新平衡准确率与效率,降低了多种任务的延迟。诸如此类通用且易于部署在实际场景中的解决方案也是一个研究挑战。
3)人脸识别。虽然已有一些对于人脸表情识别的研究,但光照、遮盖物、年龄和拍摄角度等因素会影响识别性能,如何进一步提高Transformer 模型在人脸识别中的性能和效率是未来研究面临的挑战。
4)动作识别。整体上来看,解决动作识别任务主要面临着3 个挑战,即空间特征表示、时间信息表示以及模型的计算复杂度。此外,尽管已有一些能够处理长视频的模型,但还存在一些限制使得无法一次性输入非常长的视频。最后,对于多模态Transformer 模型的研究较少,未来Transformer 可以利用哪些模态、不同模态又该如何利用也是具有挑战性的研究问题。
5)姿态估计。不同的CNN 特征提取器对模型的依赖偏好不同,例如HRNet 基于多尺度融合并可以保持高分辨率表征,在获取远程依赖关系方面优于ResNet,因此未来对于强大的主干网络以及灵活的结合方式的研究将会是一个挑战。多实例姿态估计模型POET 对关键点预测做出了贡献,但没有达到最先进的性能,这一点也是一个研究难点。将2D姿态估计提升到3D时,简单的线性投影难以较强地表达局部关节坐标间的运动学关系,因而如何优化关节坐标从二维到三维的映射是3D 姿态估计面临的一个挑战。另一方面,人体的自遮挡也会为其关键点检测带来挑战。
6)多任务方法。目前多任务通用的Transformer模型通常从单个领域或特定的多模态域(如视觉和语言)着手,探索更多类似UniT 能够联合学习多领域任务的通用模型,同时减小对特定任务的微调成本具有一定的挑战性。
3 结语
为了将Transformer 应用于视觉领域,探索出了将视觉数据序列化或将原有问题转化为集合预测问题等方法,例如ViT 和DETR。视觉领域Transformer尝试的成功激起了更大的研究热情,不论是基于ViT、DETR 等已有模型进行改进,还是针对不同任务设计适配模型,都取得了可观的进展。本文从视觉Transformer 处理多种识别任务的角度出发,整理了其在视觉分类、目标检测和视觉分割3 种基础的识别任务,以及人脸识别、动作识别和姿态估计3 种具体的识别任务中的应用,涵盖了百余种最新模型。其中有些通过改进图像标记、融合语义信息等优化Transformer 特征学习,或是将Transformer 与经典的网络结构如卷积、U-Net 以及金字塔网络等相互借鉴,优化局部与全局的空间或时间关系建模;有些通过修改注意力机制或编码器解码器结构改进了Transformer 计算量大、所需数据量大、收敛速度慢等不足;有些利用Transformer 构建出了新的端到端模型;还有一些适用于多种任务的通用模型。
对于不同任务中的模型,对比分析了它们的特点和在公共数据集上的表现。整体来看,对这些基于Transformer的模型进行特征表示的改进有利于提升性能。图像分类中改进标记表示、目标检测中改进特征图、语义分割中结合U-Net 结构进行特征编码、实例分割中利用移动窗口计算表征、动作识别中结合图卷积表示骨架特征和姿态估计中高分辨率表征的有效性综合证明了上述观点。纯Transformer结构的模型在一定程度上实现了不错的效果但存在很大的挑战,适当地结合卷积结构更容易达到优秀的效果,尤其是在动作识别任务方面。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
