
结合语义分割与模型匹配的室内场景重建方法
2023-10-24 13:58宁小娟巩亮韩怡马婷石争浩金海燕王映辉
中国图象图形学报 2023年10期
宁小娟,巩亮,韩怡,马婷,石争浩,2,金海燕,2,王映辉
1.西安理工大学计算机科学与工程学院,西安 710048;2.陕西省网络计算与安全技术重点实验室,西安 710048;3.江南大学人工智能与计算机学院,无锡 214122
0 引言
随着虚拟现实技术、智能机器人技术、计算机视觉技术以及人工智能技术的飞速发展,对各种场景的三维重建已经成为一个具有重要研究意义和应用价值的课题(杨淼和陈宝权,2022),特别是精确的场景三维模型在城市规划、文化遗产保护与修复、公共场所的精细化管理和机器人室内导航等领域发挥着非常重要的作用。然而,室内复杂点云场景由于物体的种类多样性、物体的结构复杂性以及物体之间的遮挡性,使得语义理解异常困难,增加了计算机对室内场景自动重建的难度。因而针对室内场景的三维重建研究仍然是一个富有挑战性的前沿课题。
室内场景的三维重建是将三维场景中的目标对象转化为相应的三维模型(胡芳侨 等,2020)。典型的场景重建工作主要依赖基于学习的方法来获得场景语义分割结果,然后基于局部匹配来检测和替换经过分割的对象,通常在此过程中多依赖于语义信息的获取、训练数据的准确性和数据量的大小。但是由于室内场景相对狭窄和杂乱,特别是输入的数据是室内场景的单侧点云,通常会由于遮挡和透明反射问题而产生变形、噪声以及数据缺失等,这对于室内场景的三维重建算法是灾难性的。
现有的多数重建方法都是基于语义模型的重建,即在几何信息的基础上还包含了场景的语义信息。通常在语义信息的获取上多基于三维数据的手动语义标记方法和利用图像语义分割映射到三维数据上的方法。但是前者过分依赖人工,不够智能化;后者在映射的过程中存在数据的丢失和重复计算,效果也很大程度上依赖映射算法的设计。采用PointNet(Charles 等,2017)系列获取语义信息的方法直接处理点云数据,经过训练之后的网络模型基本具有智能化的性质,多数研究者致力于提升其准确率。而室内场景的三维重建方法中最为典型是基于深度学习的自动重建方法和基于模型匹配的方法。基于深度学习的自动重建方法对完整的数据进行学习,训练网络补全物体的能力,从而完成重建,但是对训练数据量和质量要求都很高;基于模型匹配的重建方法在获取场景的语义信息后,将场景物体替换成正确的模型后完成重建。这些方法中仍存在许多问题:1)点云场景数据量大,在计算和存储过程中处理开销大,耗费存储资源,影响场景处理效率和效果;2)由于点云数据的离散性和非规则化,导致点云的特征提取、语义分割的效率和准确率不高;3)由于点云数据存在噪声和残缺,现有的方法很难重建出高质量的三维场景模型。
针对以上问题,本文提出了一套室内点云场景的重建方法。该方法主要包含以下内容:1)提出了一种基于尺度不变特征变换(scale invariant feature transform,SIFT)特征点提取与体素滤波融合的场景下采样算法,有效弥补单一的体素滤波造成的关键点损失;2)提出了一种基于平面特征增强的PointNet室内场景多层次语义分割方法,准确地从场景中分割出单个物体的点云数据,提高了分割的准确率;3)实现了一种基于模型匹配与平面拟合的三维场景模型重建方法,有效改进了基于内容的模型检索方法中的语义缺失问题,提高了模型匹配的效率和准确率。
1 相关工作
1.1 室内场景的语义分割
室内场景的语义分割指根据点云内部的空间几何结构和形状信息,将点云分成具有不同语义标签的点集(龙霄潇 等,2021)。按照输入数据处理过程的不同,主要分为基于体素的方法与基于点云数据的方法。
基于体素的方法受二维图像分割方法启发,在采用深度学习方法处理点云时,一般将其转换为体素网格这种更为规整的数据格式,以便于定义权重共享的卷积操作。Maturana和Scherer(2015)提出的VoxNet 网络,展示了三维卷积网络学习体素数据邻域特征的潜力。Wu 等人(2015)基于卷积深度信念网络构建了3D ShapeNet 网络模型。早期基于体素的网络虽然成功将卷积网络运用到了三维场景中,但是仍然存在着问题,如计算时间复杂度高、计算时会受到内存大小的限制等。因此,Wang等人(2017)设计了基于八叉树的卷积神经网络(octree-based convolutional neural network,O-CNN),用八叉树表示三维模型,并对其形状边界进行卷积操作。Meng 等人(2019)提出的VV-Net(voxel variational autoencoder(VAE)net)模型,通过一个变分自编码器模块,对体素中点的分布进行编码,提高了将卷积应用于稀疏的体素数据时的计算效率。基于体素的方法需要将3D点云转换成体素后再进行分割,这不可避免地会增加算法额外的计算量,同时还会丢失一些关键信息。
基于点云数据的方法是直接以点云数据作为输入进行分割操作。由于点云数据的离散性和不规则性,传统的卷积神经网络无法直接应用。于是Charles 等人(2017)提出了PointNet 网络,首次直接将原始点云作为神经网络的输入,通过多层感知机和对称函数提取点云特征,利用端到端的方式得到点云分割的结果。PointNet 是第一个基于点云的语义分割网络,但是其对于邻近点的相互关系并没有充分考虑,所以为了解决局部特征的学习不够充分这一问题,研究者基于PointNet 网络提出了一系列改进。PointNet++(Qi 等,2017)网络使用球半径查询算法或K 近邻算法构造局部邻域,并提取局部特征。Zhao 等人(2019)提出了PointWeb,通过自适应特征调整模块实现信息交换和点的局部特征学习。这些方法都使用最大值对局部邻域特征进行聚合,忽略了局部邻域内的其他邻域特征。为了有效利用点云的局部特征信息,RandLA-Net(Hu 等,2020)使用了随机采样法,通过局部特征聚集模块捕获和保留局部特征,提高了计算效率。Qiu 等人(2021)提出了一种双边扩充结构来有效处理多分辨率点云,并利用自适应融合方法表示点对特征,解决了点云冗余特征问题。因为点云数据的离散性和非规则化,导致点云的特征提取较为困难,语义分割方法的准确率还有提升空间。
1.2 室内场景的三维重建
点云室内场景重建的方法主要有基于模型匹配的重建方法和基于学习的自动重建方法两类。
基于模型匹配的方法需要建立模型库,再对待匹配场景物体和模型进行特征提取,然后检索模型库,找到特征匹配度最高的标准模型将场景物体替换,从而完成场景的重建。Nan 等人(2012)假设室内物体竖直摆放,使用分类器将场景数据进行初步分割,将场景物体模型在竖直方向上分为三段,并且分析每段的分布特征。再根据场景物体模板的三段分布特征矫正分割结果,并在该过程中匹配到场景模型,完成室内场景重建。Li 等人(2015)提出了一种实时的基于形状的模型检索与匹配的重建方法,该方法在实时扫描的过程中,根据扫描到物体的关键点在模型库中进行检索与匹配。这两种早期方法的特点在于提取物体时,用的是传统的手工特征,因此方法局限性较大。Avetisyan等人(2019)提出了一种新颖的端到端方法,以计算机辅助设计(computer aided design,CAD)模型和3D 扫描的场景为神经网络的输入,用目标检测的方法从3D点云场景中检测可能与CAD 模型相同的场景元素,将CAD 模型与场景的物体关键点对齐并替换。Nie 等人(2020)设计了一种基于三维形状知识图的检索方法,利用物体模型的基本形状进行检索和匹配。基于模型匹配的重建方法在复杂场景中提取场景元素的过程很容易造成过提取或欠提取,在不知道精确的场景元素与其语义信息的情况下会导致很多模型与场景元素的误匹配,从而影响重建结果。
基于深度学习的自动重建方法一般通过学习场景数据中的某些基本规律,如构成要素的一般位置、要素的上下文结构等,对测试场景应用学习到的通用规律进行重建。Zhang 等人(2018)提出一个深度强化学习框架,集成了一个三维卷积神经网络、一个深度Q 网络和一个残差递归神经网络,采用数据驱动的2.5 维双等高线方法,合并点云生成城市建筑模型。Dai 等人(2018)提出了ScanComplete,将不完整的TSDF(truncated signed distance functions)作为输入,使用3D卷积网络,采用由粗到精的策略,对场景进行补全重建操作,但是碍于体素的分辨率,补全精度受到限制。Wang 等人(2018)将原始点云作为输入,设计了一种基于背包式激光扫描的场景建模方法,通过构建条件生成对抗网络(conditional generative adversarial network,cGAN)对场景结构线框架进行优化输出布局完成重建。Liu 等人(2020)提出一种基于学习的深度图补全和基于几何一致性滤波相结合的补全方法,有效解决了传统的多视点立体(multiple view stereo,MVS)算法往往难以处理大规模的室内场景重建的问题。这类基于学习的自动重建算法需要大量训练数据来学习,导致训练周期比较长。
2 方法概述
本文方法的整体框架如图1 所示。以室内点云场景数据集S3DIS(Stanford large-scale 3D indoor spaces dataset)作为输入,输出对应的场景三维模型。具体的方法包括:

图1 本文方法框架图Fig.1 Overview of our method
1)提出了一种SIFT 特征点与体素滤波融合的数据下采样方法,该方法以场景的局部特征为引导,首先通过体素滤波方法(Miknis 等,2015)对原始室内场景点云数据进行下采样,利用3D SIFT(Rister等,2017)方法获得场景数据的局部特征点,将局部特征点与下采样结果进行融合,从而获得优化的场景下采样结果。
2)提出了一种基于平面特征增强的PointNet 室内场景多层次语义分割方法。该方法以场景下采样后的点云数据为输入,首先基于RANSAC(random sample consensus)方法(Fischler 和Bolles,1981)对场景数据进行平面提取,构造增加平面特征后的场景数据作为训练和测试网络模型的数据集,然后通过PointNet 网络实现端到端的场景语义分割,最后用一种基于投影的区域生长优化方法实现室内场景中物体的细分割。
3)提出了一种基于模型匹配与平面拟合的三维场景模型重建方法。该方法在场景语义分割的基础上,建立了场景物体的模型库,结合基于启发搜索的模型匹配方法,以分割后场景元素的语义标签和局部特征为索引,从模型库中进行粗检索,使用检索到的最优匹配模型进一步细匹配,实现了场景中物体的匹配与表示。对墙面等外环境元素,依次用平面拟合的方法进行重建,最终实现室内场景的完整重建。
3 基于平面特征增强的语义分割
3.1 基于SIFT特征点与体素滤波融合的数据采样
激光雷达等设备获取的点云数据通常具有数据量过大、密度不一致等问题,因而本文使用体素滤波方法对数据进行下采样,从而降低计算成本。然后使用3D SIFT 特征点来弥补体素滤波下采样的过程中可能造成的关键点损失。最后进行融合操作,去掉体素滤波的下采样点与SIFT 特征点重复的点,去重后合成一个完整的点云数据,从而完成场景的下采样。
3.1.1 基于体素滤波的室内场景下采样
对于密集的点云数据,基于体素滤波的下采样方法简单、直观且算法效率高。首先,根据需求选择合适的体素栅格边长L,将整个点云数据分成若干个边长为L的体素栅格。然后,逐一统计体素栅格内全部的点,计算这些点的重心作为这些点的代表。最后,用这些计算出来的重心点代替整个栅格内的点云,完成对整个场景的下采样。
假设将场景划分成n个体素栅格,用体素内所有点的坐标均值表达该体素内点云的重心,如某一个体素栅格中包含m个点,这m个点的重心(X,Y,Z)计算为
式中,xi,yi,zi表示体素内任意一点的坐标。
3.1.2 SIFT特征点提取
由于体素滤波方法的下采样效果很好但是采样结果的精度不高,所以本文用3D SIFT 特征点来弥补下采样过程中可能造成的关键点损失。3D SIFT是将二维图像中的SIFT 算子调整后扩展到3D 空间的SIFT 算子的实现,具有一些良好的特性,如尺度不变性等。本文以RGB 特征做为强度信息,输入数据为X、Y、Z坐标值和RGB特征。
首先,构造出三维点云的尺度空间S(x,y,z,σ),高斯核表示为G(x,y,z,σ),三维点云坐标与其中一个变化尺度的高斯核的卷积运算为
式中,σ为尺度空间因子,它的值为,⊗表示卷积运算。高斯核G(x,y,z,σ)在三维空间中的函数表示为
接下来,构建高斯差分金字塔,描述高斯差分(difference of Gaussian,DoG)算 子D(x,y,z,σ),具体为
式中,m是比例系数。
然后,在尺度空间上搜索点云的局部极值,这时所获得的所有极值点即为具有尺度不变性的SIFT特征点。
3.1.3 融合采样
原始场景分别经过体素滤波下采样和SIFT 特征点处理后,其结果中可能存在重复的点,不能直接进行融合处理,否则会影响平面提取的效率以及语义分割的准确率。
去除重复点需要设置最小距离阈值作为约束,本文设置距离阈值为0.001,以SIFT 特征点为基准,在体素滤波的点云中以距离阈值为半径搜索近邻点,有则删除所有的近邻点,对重复的采样点只保留一个点作为有效点,将所有的SIFT 特征点搜索完成后,把过滤掉重复点的滤波下采样的点云与SIFT 特征点输出到同一个文件中,完成数据融合。融合采样方法如图2所示。

图2 融合采样示意图Fig.2 Schematic diagram of fusion sampling
3.2 基于平面特征增强的PointNet语义分割
经过融合采样后的数据在保留关键点的同时,数据量大大减少了。在此基础上,本文通过对数据使用RANSAC 算法提取场景的平面特征,以确保共面点具有相同的特征,从而对场景点的局部特征进行增强。最后将带有平面特征的点输入PointNet 网络训练,实现场景的语义分割。
3.2.1 平面特征提取
针对PointNet 网络无法很好地提取数据局部特征这一问题,本文使用RANSAC 算法提取场景平面特征,从而强化每个点的局部特征。
首先从全部点中随机选取3个点作为局内点,构成一个平面,然后通过设置加入局内点的条件,迭代地筛选出符合加入局内点条件的局外点加入当前局内点组成的平面,并更新平面。当迭代过程中再无局外的点符合加入当前平面的条件时,判断当前平面包含的点是否满足设置的平面点数阈值,若满足,则得到一个平面。最后通过上述步骤迭代地在剩余的局外点中获取符合条件的平面,当剩余局外点的数量小于设置的平面点数阈值时,表示已经得到了全部平面。图3 为RANSAC 方法提取平面的示意图,其中p1、p2、p3为局内点。n 为3 个局内点所构成的平面法向量。q为局外点,需要判断条件,如法向量偏差是否小于阈值,从而决定q是否能加入内点。

图3 RANSAC方法提取平面Fig.3 Extracting plane by RANSAC method
本文使用RANSAC方法进行平面提取的效果很大程度上得益于3.1 节的下采样处理操作,减少了噪声点和冗余点,在效果和效率上都有不同程度的促进作用。
经过融合采样和平面提取后,点云丢失了原场景色,即场景点云的RGB 特征。为了使处理后的数据集对原数据集具有更好的包容性,本文用基于K-D(K-dimension)树的K 近邻搜索算法,在体素滤波下采样后的场景数据中找出平面提取后数据中该点的8 个近邻点的RGB 均值作为该点的RGB特征。
3.2.2 语义分割
相比于PointNet 网络,本文为场景中的每个点增加了一个特征维度用于表征其所属的平面,该特征即在3.2.1 节平面特征提取方法后得到的。语义分割网络架构如图4所示,关键流程如下:

图4 语义分割网络架构图Fig.4 The framework of semantic segmentation network
1)输入为全部点云数据及其特征的集合,表示为一个n× 10 的二阶张量,其中,n表示点云数量,10对应3个坐标维度和7个特征维度;
2)为了实现模型对特定空间转换的不变性,先将输入数据用T-Net计算一个变换矩阵,把场景旋转到一个对分割最有利的角度;
3)通过多层感知机对各点云数据进行特征提取,然后再通过与T-Net学习到的转换矩阵相乘将特征对齐;
4)在特征的各个维度上执行最大池化操作,获取整个点云最终的全局特征;
5)对于语义分割任务,将全局特征和之前学习到的局部特征进行特征融合,再通过多层感知机得到每个点对应于每个类别的分数,进而得到该点的语义分割结果。
3.3 基于投影优化的区域生长实例分割
语义分割得到的分割结果仅能分割出不同物体的大类别元素,如椅子、桌子等,而对同一类物体元素中的多个子元素无法进行精细分割,如将椅子类分成椅子1、椅子2等。因此需要使用区域生长算法对语义分割的结果进行实例分割处理。本文使用了一种基于投影的区域生长优化算法,该算法的本质是通过转换三维空间距离到二维平面距离来解决不同物体由于粘连或同一物体由于缺失导致分割结果较差的问题。
对相对独立的物体分割时,首先将三维点云投影到XOY平面上,将点对之间的空间距离转换到共面点之间的距离,然后对投影到平面上的点云用区域生长算法进行聚类,最后将区域生长聚类的结果恢复到点云。
对距离很近的多个物体分割时,如多把椅子紧密放置时,使用上述方法无法将其分开,因此本文用以下方法进行分割,步骤如下:
1)将粘连的物体元素投影到XOZ平面上,根据实验结论设置步长l为0.05 m。记录x的最小值xmin,从xmin开始,沿x轴以步长为l分别计算各个数据段z轴最大值,记录为zi,i=1,2,3,…。
2)从xmin向xmax依次遍历每个数据段,若zi小于zi+1,即当前数据段z轴最大值小于下一个数据段z轴最大值,则表示这个数据段有可能是物体的边界,需要记录其对应的xi的值。
3)对得到的xi进行筛选。去掉“波动点”,即数据缺失导致的突变点,如图5(b)中红圈部分,方法是对每个xi分别计算左右两侧2个不同的zi(相同的值继续向左或向右搜索),如果左侧2 个数据点不是递减的或右侧2 个数据点不是递增的,则删除xi,最终剩下的为物体边界的候选x坐标。

图5 一组椅子的实例分割结果Fig.5 Instance segmentation results for chairs((a)projection;(b)section;(c)instance segmentation result)
4)确定最终物体边界的x坐标。主要思路是先确定第1 个物体的边界x,得到该物体的宽度,并以该宽度为基准遍历xi,判断两两边界间的距离是否与基准宽度相近,如果xi都满足条件,则剩下的xi就是最终的边界坐标。具体方法为:假设有k个xi,首先计算xmin与x1之间的距离dis,用x轴的最大值xmax和最小值xmin的差除以k+1 并向上取整,若结果与dis的差大于2l,k减1,重复上述步骤。若找到符合条件的xi,标记为x1,否则,删除x1,以下一个xi继续重复以上步骤,直到找到符合条件的x1。确定x1后遍历xi,依次计算xi-xi-1与dis的差值是否小于2l,若都满足,则可以确定最终的xi。最后根据所有xi,即所有物体边界的x坐标,将连在一起的物体分成单个物体。图5 是一组粘连的椅子用基于投影优化的方法进行实例分割的结果,其中,图5(b)中红色竖线部分表示找到的物体边界。
4 基于模型匹配与平面拟合的重建方法
4.1 模型检索
目前已经获取待匹配场景元素的语义及实例信息,本文使用基于语义的模型匹配方法,将语义信息作为先验知识来决定匹配模型的语义类型,从而从模型库中找到该类模型,再进一步检索到该场景元素的最佳表示模型。
本文将桌子、椅子、书架等物体称为内环境元素,内环境元素和门元素采用模型匹配的方法重建。模型匹配的重建方法先要构建模型库。本文在公开的三维模型数据集ModelNet40(Wu等,2015)上选择本文重建所需要的数据模型,包括常见形态的桌子、椅子和书架各100 个,沙发、门的形态比较少,选取各20 个,杂物包含50 个常见的模型,图6 是本文构建的模型库中的部分模型。

图6 模型库的构建Fig.6 Construction of model library
模型库建立好后,还需要对模型库中的模型进行处理,因为点云数据不能直接与CAD 模型进行特征匹配,所以需要将模型点云化,本文使用均匀采样的方法将CAD 模型点云化,对选好的CAD 模型一一对应地进行均匀采样并保存,用于进一步的特征提取和模型检索及匹配。
然后对场景元素和CAD 模型进行尺度归一化操作,归一化的方法使用主成分分析(principal components analysis,PCA)(Park 等,2009)。计算待查询的元素数据和模型库中的模型的3 个主轴方向,计算变换尺度,使模型点云与元素具有相同的尺度。
最后进行模型检索操作。模型检索的过程如图7所示,主要步骤如下:

图7 模型检索过程Fig.7 Model retrieval process
1)分别计算待检索元素与点云物体的快速点特征直方图(fast point feature histogram,FPFH)(Rusu等,2009)特征。设从场景输入数据中任选点p,其FPFH特征计算为
式中,k表示点p的邻域个数,ωk为特征权重,SPFH(p)为点p和其k邻域内每个点之间的特征值的统计。
2)用采样一致性初始配准算法(sample consensus initial aligment,SAC-IA)(Rusu 等,2009)计算相似度。
3)输出刚性变换矩阵和最优匹配模型。
4.2 模型匹配
在获得最佳表示模型以及初始刚性变换矩阵后,下一步需要基于场景中的元素对该模型的位置、姿态迭代地进行精确匹配。
本文采用经典的迭代最近点(iterative closest point,ICP)算法(Besl 和McKay,1992)进行精确匹配,ICP 的目标是计算出从源点云P 到目标点云Q的变换矩阵,点云变换表示为P=R × Q+T,由旋转矩阵R 和平移矩阵T 共同将源点云向目标点云对齐。ICP 算法通过不断迭代计算出使两部分点云距离最近的变换,直到满足配准正确的阈值为止。
模型匹配后,将标准模型旋转到与模型点云相同的角度并缩放到相同大小,包括旋转、平移和缩放变换。用标准模型替换场景元素数据,完成场景重建。本文利用矩阵运算来实现模型变换。图8 是Office_1场景中的3把椅子和1张桌子的模型匹配和置换结果。
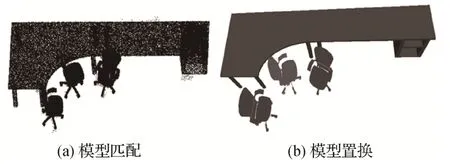
图8 模型匹配与置换Fig.8 Model matching and replacement((a)model matching;(b)model replacement)
4.3 平面拟合
模型检索与匹配的方法主要用于复杂物体的重建,对于其余形状简单的物体,本文采用平面拟合的方法。本文称天花板、地板、墙面、窗、门、梁、柱子、面板等为外环境元素,这些外环境元素除了门以外都可以用平面拟合方法进行重建。在3.2.1 节已经用RANSAC 方法检测出了构成平面,得到了每个平面的AABB(axis-aligned bounding box)包围盒(Gao等,2014),用包围的8 个顶点可以完成这些元素的平面拟合。图9 是除了门和墙壁以外全部外环境元素的重建。

图9 非墙非门外环境元素重建Fig.9 Reconstruction of non wall and non door external environmental elements((a)non wall and non door external environmental elements;(b)reconstruction result)
由于部分墙面元素有门窗,为了保证墙面重建的真实性,需要对有门窗的墙面建立孔洞区域。实例分割后每个点都有自己的语义和坐标,按照门窗元素点坐标的最大最小值划分出孔洞区域。在数据采集过程中,存在遮挡以及数据处理过程中难免的数据损失,数据缺失比较严重,墙面重建部分除了明确的门窗部分以外其他都当做缺失的墙面来处理,图10是墙面元素的重建。

图10 墙面元素重建Fig.10 Wall element reconstruction((a)wall elements;(b)reconstruction result)
5 实验结果分析
本文实验数据为S3DIS 数据集(Armeni 等,2016),由美国斯坦福大学开发并开源给研究者使用,是带有像素级语义标注的三维点云场景数据集。
本文实验运行于Ubuntu16.04 操作系统,硬件设备为Intel(R)Core(TM)i9-9900K 和NVIDIA GeForce RTX 2080Ti 11 GB。
5.1 场景采样结果分析
场景采样结果如图11 所示,采样方法可以结合平面提取的结果,从效果和效率两个方面进行分析。从效果上看,如图12 所示,场景采样前的平面提取结果损失了两个墙面,而且提取出了很多细长的平面,可以看出在未采样的数据上无法获取较好的平面提取结果。从时间效率上看,如表1 所示,采样后的平面提取时间约为采样前的15%,加上采样的时间约为采样前的38%,场景采样对于平面提取的效率也有明显的提升。

表1 采样前后的算法运行时间Table 1 Algorithms running time before and after sampling/s

图11 场景采样结果Fig.11 Scene sampling results((a)raw data;(b)voxel filter sampling;(c)SIFT feature points;(d)fusion sampling results)

图12 平面提取结果Fig.12 Plane extraction results((a)before sampling;(b)after sampling)
5.2 语义及实例分割结果分析
5.2.1 语义分割
本文语义分割方法用S3DIS 中场景Area1—Area5进行训练,使用场景Area-6进行测试。
对语义分割的结果主要从总体准确率(overall accuracy,OA)和平均交并比(mean intersection over union,mIoU)两个方面进行评价。用原PointNet 网络与本文方法进行对比。定量分析结果如表2 所示,可以看出,本文方法比PointNet 准确率和交并比都有所提升。

表2 S3DIS中Area_6场景测试的准确率和平均交并比Table 2 OA and mIoU of Area_6 in S3DIS /%
语义分割结果如图13 所示,由图中的标记框可以看出,本文方法的语义分割效果比PointNet 在细节上更准确。图13 的Opensapce_1 场景中左下方框是杂物、中间的方框是椅子,PointNet 将这两部分分别误识别成椅子和桌子;图13 的Office_1 场景中右方框为书架,PointNet 只分割出了一部分点。而本文方法对这两个场景的语义表达基本准确,如图13(c)所示。
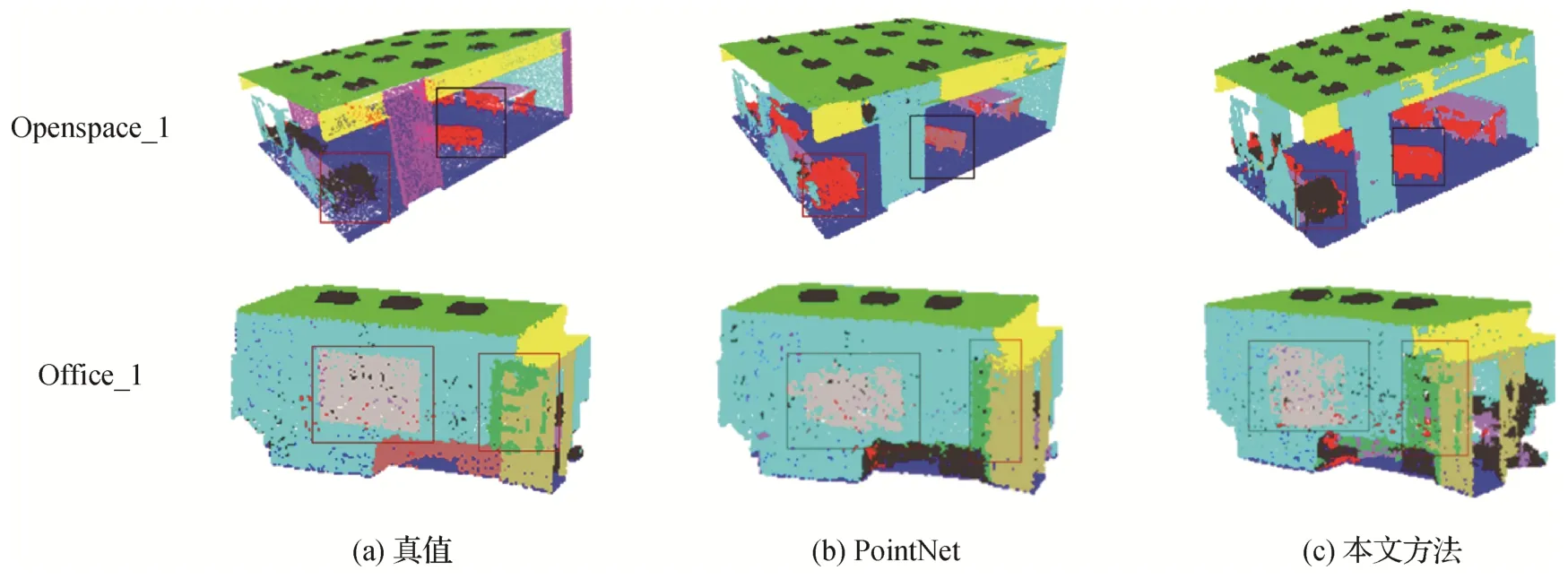
图13 语义分割结果Fig.13 Semantic segmentation results((a)ground truth;(b)PointNet;(c)ours)
5.2.2 实例分割
本文实例分割方法最难处理的数据是椅子类型的数据,这是因为在室内场景中,椅子类型数据数量最多,而且存在很多粘连数据,所以本文取出椅子类型数据的实例分割结果进行分析。如图14所示,Opensapce_1 场景存在很多连起来的椅子,但是本文的方法将它们都分开了;Office_1 场景中的椅子存在残缺,在本文区域生长结合投影的优化方法下,这3 把椅子分割得也比较完整。结果表明,本文实例分割方法在复杂室内场景下也能取得较好的效果。

图14 本文实例分割结果Fig.14 Segmentation results of our method((a)raw data;(b)semantic segmentation;(c)instance segmentation)
5.3 场景重建结果分析
图15为Office_1场景的内环境及外环境重建结果。Office_1 场景包含的内环境元素,如图15(a)所示,有椅子、桌子、沙发、书架和一些杂物,模型匹配的方法重建出的场景如图15(b)所示,结果比较符合实际场景的物体分布。Office_1 场景包含的外环境元素也比较丰富,如图15(c)所示,有天花板、地面、墙壁、梁、柱子、窗和面板以及门元素,根据实例分割的结果,用模型匹配的方法重建出门,平面拟合的方法重建出其他场景元素,最终结果如图15(d)所示,重建结果较为完整。

图15 重建结果Fig.15 Reconstruction results for Office_1((a)original internal environment;(b)internal environment reconstruction result;(c)original external environment;(d)external environment reconstruction result)
6 结论
本文实现了一种基于室内场景语义分割的场景重建方法。对于点云场景数据量大、下采样算法会造成关键点损失这一问题,提出了一种基于SIFT 特征点与体素滤波融合的下采样方法,在保留特征点的同时,减小了数据量。为了解决PointNet 网络欠缺对局部特征提取和处理的问题,提出了一种基于平面特征增强的PointNet 语义分割方法,对整个点云场景提取平面特征信息,使得共面的点尽可能具有相似的局部特征。随后将语义分割结果输入到本文设计的一种基于投影的区域增长优化方法中进行实例分割。最后将室内场景物体划分为内环境元素和外环境元素,针对不同元素分别使用模型匹配和平面拟合的方法进行重建,从而完成场景重建任务,并得到了较好的重建结果。
本文算法在S3DIS 数据集上进行了测试,结果表明,本文方法在全局准确率和平均交并比两个方面取得了较高精度,分别为84.02%和60.65%,比PointNet分别提高了2.3%和4.2%。
但是,由于RANSAC平面提取算法对椅子、书架等结构复杂的物体有较大的局限性,所以平面特征增强的策略对这类物体的语义分割准确率提升不明显,因此如何提高结构复杂物体的分割准确率还需要进一步研究。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
家庭医学(2022年3期)2022-04-07
计算机集成制造系统(2020年4期)2020-05-08
开放教育研究(2020年2期)2020-03-31
中学生数理化·高一版(2020年1期)2020-02-20
中国惯性技术学报(2019年1期)2019-05-21
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
现代语文(2016年21期)2016-05-25
科普童话·百科探秘(2015年4期)2015-05-14
大连民族大学学报(2015年2期)2015-02-27
