
基于激光雷达的实时铁路轨道提取方法
2023-10-22 16:01:34胡智豪杜嘉豪
智能计算机与应用 2023年8期
胡智豪, 杜嘉豪
(上海工程技术大学机械与汽车工程学院, 上海 201620)
0 引 言
目前,作为现代主要运输方式之一,铁路运输不仅安全,而且也最具成本效益。 随着人们对铁路网络运输速度及安全性要求的不断提高,列车运行自动化技术也在不断发展,包括:列车车载定位技术,判断列车行驶方向和占用股道;铁路轨道中基础设施的维护及保养的数据记录和处理,为后期维护提供数据支持等;而轨道空间数据信息采集、轨道检测,对于上述自动化技术改进及增强具有重要意义。 传统的铁路检测方法包括:现场检测和半自动化图像和视频数据分析,既耗时又低效。 而在时下的自动化提取方式中,应用于检测的多种传感器,主要基于点云及影像两种数据类型。 Stein 等学者[1]从基本原理对摄像头及激光雷达等传感器进行了对比分析,认为激光雷达具有的高精度及可靠性是轨道检测的最优选择。 近些年移动激光扫描系统(Mobile Laser Scanning, MLS)的发展,使其在城市及铁路环境中对于各项目标的检测、提取等方面具有显著的优势。 而铁路网络本身错综复杂,存在道岔等变轨设施,同时运行环境中树木及山体等大量环境点云及许多细长的物体靠近轨道(如电缆沟、护轨等)或在轨道之上(如悬链线、桅杆臂、交叉电力线、跨越桥梁、接触轨等),对于要实现实时轨道检测且具有足够高的灵敏度及准确性的要求同样具有一定的挑战性。
现如今,在点云数据中实现铁轨检测相关工作主要分为:数据驱动和模型驱动方法、基于机器学习的方法、基于多源数据融合方法,包括RGB 相机、激光雷达等[2]。 数据驱动和模型驱动方法主要基于点的高程跳变特征和几何关系的局部特征和全局特征。 Hackel 等学者[3]以轨道截面的几何特征为基础,在单帧激光雷达点云数据中进行铁轨关键点的检测,后采用模型匹配算法对检测结果中的剔除误检关键点实现铁轨点云提取。 Yang 等学者[4]主要通过滑动窗口内点云高程差波动和相对几何关系初步提取铁轨点,随后根据研究中所提出的点云线条形状参数值进行线性轨迹的筛选。 上述算法在提取过程中需要大规模的邻域计算,较难应用于实时场景[2]。 而Lou 等学者[2]在Yang 等学者[4]的算法流程上分析讨论了采集数据的铁轨数据分布特征,进一步简化提取流程,有效地减少搜索计算量,提高了提取速度。 以上方法都假设轨道铺设在相对平坦的区域,因此不同路段下的铁轨提取便难以提供统一的阈值。
同时,也有研究人员将点云数据转化为图像并使用图像相关算法对轨道进行分类和提取。 Zhu 等学者[5]直接将LiDAR 点云数据转换成图像,利用图像处理技术直接对其进行分类。 Demja'n[6]利用各点协方差矩阵,分析点高度方向分布情况后将三维数据投影为图像,使用霍夫变换进行线段提取和配对后再转为3D 数据完成轨道点云提取。 该方法为激光雷达数据处理提供了一种新的思路,将其他数据源与MLS 点数据相结合,可以提高铁路提取的准确性和速度。
当前,铁路基础设施点云检测表现最好、运用最多的是知识驱动方法。 在知识驱动方法中,模型驱动与数据驱动各有优势。 其中,模型驱动在低采样数据上的表现优于数据驱动,但需要依赖先验知识;数据驱动则不需要依赖先验知识,且相对于模型驱动,数据驱动的计算复杂度较小,这是因为数据驱动的方法通常会检测局部属性,从而仅需要处理少量点。 本文采用知识驱动的思路,基于铁路点云的几何关系特征,提出一种路基提取、轨面提取、枕木提取的新方法,本文研究旨在综合铁轨点云数据的点特征、线特征、平行性特征的几何关系特征展开分析,提出一种具有一定实时性、易于实现的轨迹检测方法。
1 基本原理
本文所提出的轨道检测算法流程如图1 所示,其主要内容包括:路基区域轨迹点的提取与线性轨迹筛选及连接配对。 由于轨道本身为一对在相对平坦路面上凸起、具有固定轨距的连续平行线。 首先根据铁轨点云的几何特征及总体点云的数据分布特性, 使用最低点代表算法 ( Lowest Point Representative, LPR)进行路基的选取并以铁轨点沿高度方向连续的高程差特征检测铁轨点云,聚类输出各点簇后,利用单条轨迹具有的线性形状在主成分分析(Principal Component Analysis, PCA)中的特征值特点,筛选出轨迹点簇并以距离阈值及向量角度阈值连接同一轨迹的点簇,最终输出轨道对对象级别的检测。
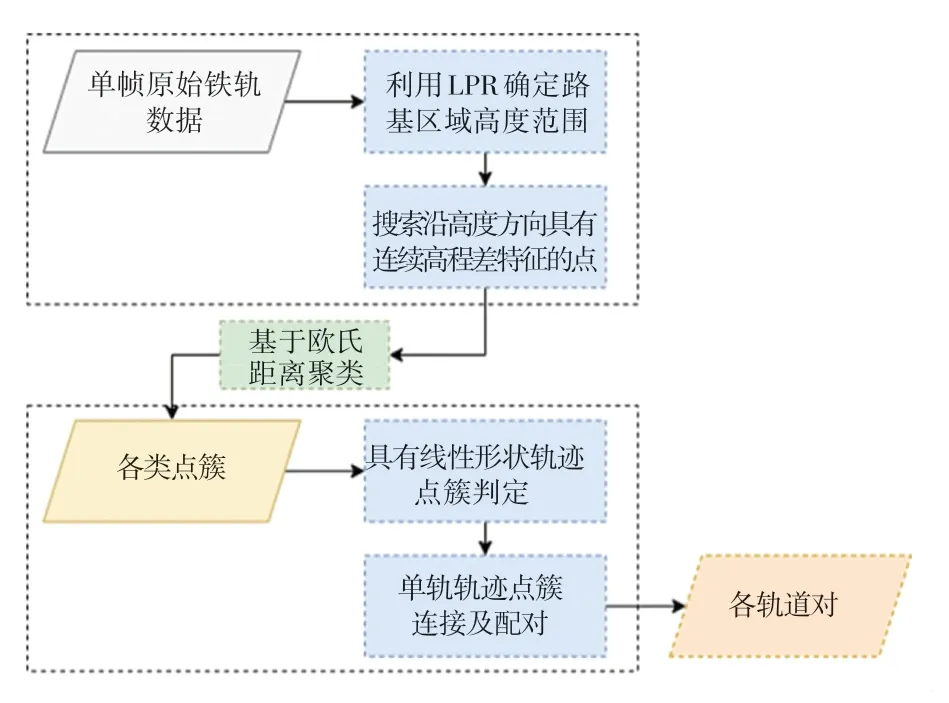
图1 整体流程图Fig. 1 Overall flow chart
1.1 铁轨点提取
在用于轨道检测采集的点云数据中,包含了树木、周边山体等无关数据点,其中包含轨道的路基区域点云占据绝大多数,同时还具有相对变化小的高程信息。 统计采集的单帧数据中各高度范围内点云数量如图2 所示,其中路基区域的点云高度范围为(-0.61 m, -1.57 m)。 由图2 可看到,该区域点云数量最多。
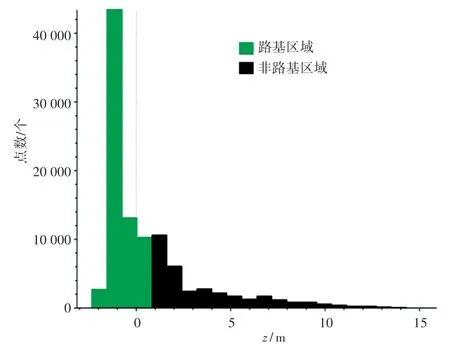
图2 单帧点云高度数量图Fig. 2 Number of point cloud heights in a single frame
因此对于路基区域的数据,引入了LPR 进行提取,其定义铁轨接地点高度为一定占比的最低高度值的平均值hlpr, 并通过轨高h以设定高度区间在(hlpr,hlpr+h) 来保留有效的路基区域。 不同于其他根据聚类处理得到最大连通区域[2]或重复获取点云高度求平均值[7]的处理,LPR 不仅能快速且有效地去除轨道上方的树木、建筑物等无关点,同时能筛选出主要包含轨道的路基点云,减少后续处理的数据量。
轨道区域数据视图见图3(a)。 铁轨在相对平坦的路基上具有凸起的形状特征形成遮挡效果,使得其点云具有连续的高程变化且与周边路基点云存在不同程度的间隔,利用该高程跳变特征与距离间隔对路基点云逐点进行高程判断,提取铁轨点云。

图3 铁轨点判定Fig. 3 Railway point determination
铁轨点判定细节见图3(b)。 利用k-d 树搜索点p邻域ε内的点集为T,计算T内各点与搜索点p的最大高程差绝对值Δzmax。 轨道点应满足邻域ε内的高程差条件,同时为避免偶然性造成的检测误差,增加对ε内满足高程差条件点的统计。 定义轨道点prail应满足:
其中,、分别表示搜索点pi及邻域中的第i个点pi在z轴高度方向的值;γ表示轨道点高程差阈值;N(T) 、eth分别表示邻域中满足高程差的点数及铁轨点判定阈值。 在提取过程中,确定γ对于避免对轨道与路基过分割至关重要,该部分可根据当搜索点为铁轨接地点时,ε内最高的铁轨点高程差而确定。
1.2 轨迹筛选及连接
经过上述筛选所得的铁轨点来自不同轨道,仍是混合离散化的。 为正确地区分铁轨点所属轨道,利用同一轨迹点云相近的特点,按照欧氏距离分析规则将其进行密度聚类为点簇集C,但数据中可能仍存在成团的游离噪声数据,如图4 所示。 图4 中的C1及C2, 以及因遮挡等因素导致其紧密程度不同,在聚类成簇过程中出现同一轨迹点云点不同簇的情况。 为保证算法最终的提取目标是对象级的识别,对所有点簇进行主成分分析(PCA),综合分析点簇在三维空间的分布情况,提取具有明显线性特征的轨迹点簇,并将同一轨道的轨迹进行连接。
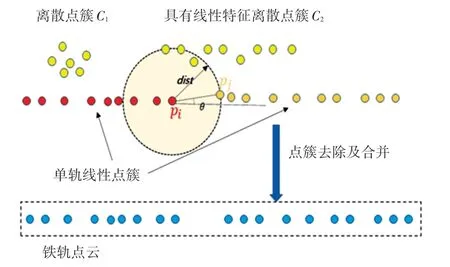
图4 去除假阳性轨迹点簇示意图Fig. 4 Schematic diagram of removing the false positive trajectory point cluster
各个点簇Ci中可由PCA 得到对称半正定的局部协方差矩阵Mi,Mi的具体公式为:
Mi的3 个特征值均为正,排列为λ1>λ2>λ3。 对于散乱的点簇,各点的特征值满足λ1≈λ2≈λ3,而对于有主导方向的线性轨迹点簇,相应的特征值则满足λ1>>λ2≈λ3的线性特征[8]。为获得更精确的线性点簇判断,参考文献[4]中用于判定邻域点具有线性形状特性的维度特征α1D=当其满足以下要求时,将该点簇标记为轨迹点簇:
其中,β1,β2,β3分别为判定线性轨迹点簇的阈值。
由此过滤去离散的假阳性点簇,余下点簇根据距离阈值和向量角度,将属于同一轨迹的点簇进行连接。 以前点簇Ci与后点簇Cj分别对应的最后点pi与最前点pj来计算对应的向量角度及欧式距离,见图4,同时满足:
其中,η为判定同一轨迹点簇的最大距离阈值;μ为判定同一轨迹点簇的最大角度阈值。
在获得数据中完整连续的各单条轨迹点簇后,可利用轨道对平行、具有固定轨距的特性,将间隔距离在轨距范围内的轨迹分为同一轨,最终提取出各轨道对点云。
2 分析与讨论
本文采用的轨道场景数据以双轨场景为主,分别为窄轨(G=1 m)、标准轨距轨道(G=1.435 m)的混合轨距轨道,在不同区域共采集2 份250 帧数据。 实验中,激光雷达传感器安装于铁路实验车辆前端顶部,距离地面高度为1.5 m,原始数据每帧点云数量约为10 万个。 本算法所有参数具体数值见表1。

表1 本轨道检测算法相关参数Tab. 1 Related parameters of the orbit detection algorithm
为有效评估轨道检测准确性,手动提取测试区域的铁轨点云作为数据正样本,将其与本文算法提取出的铁轨点云结果进行对比。 利用召回率r、 准确率p两个精度指标评估算法性能[7]。 研究推得的精度指标公式为:
其中,NTP表示提取的正确点数量;NFN为漏提取的正确点数量;NFP为错误提取点的数量。
2.1 路基区域及轨迹提取
测试场景数据如图5(a)、(b)所示。 采集的点云数据中的铁路周边场景设施,如:树木、电力设施、建筑,通过LPR 被有效去除,提取出路基区域,有效减少信息的损失。

图5 数据处理过程细节Fig. 5 Process details of data processing
在铁轨点提取部分,左侧标准轨距的轨道存在的同样具有连续高程变化及线性特征的接触轨被一同提取出,且其左侧轨道同一轨的点簇在聚类过程中由于点云稀疏性及遮挡等因素影响,被判定为不同类,此处用不同颜色直观展示点簇,细节如图5(c)所示;而在后续PCA 过滤及轨迹点簇连接中,该轨道的点簇在算法符合角度与距离阈值,被成功判定为同一轨迹,且有效去除两侧不符合轨距的接触轨,最终实现双轨道对的识别,结果如图5(d)所示,综上说明,本文所提出的轨道提取算法具有一定的鲁棒性。
为更好证明本文算法优势,将本文算法与Demja'n[6]提取的轨道提取算法进行对比实验。 该算法的主要思路为利用铁轨突出的形状特征,根据协方差矩阵判断在高度方向点的离散程度筛选关键铁轨点后将其投影至2D 图像,根据霍夫变换进行铁轨线段提取后再投影至3D 空间,最终提取出铁轨对。 将上述算法内容与本文算法内容在同一份混合双轨数据中进行处理,提取结果见表2。
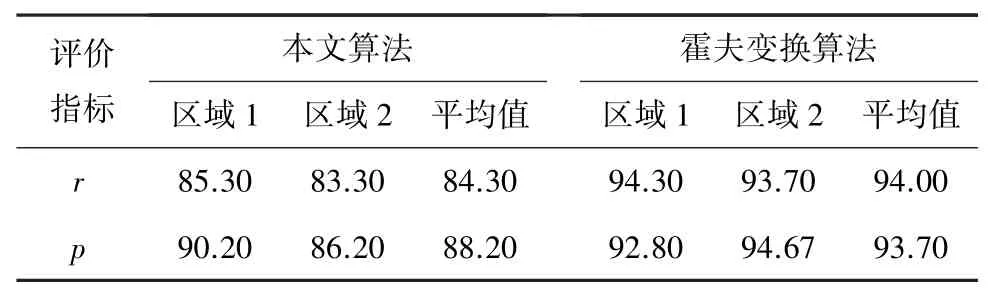
表2 2 种铁轨提取算法结果对比Tab. 2 Comparison of the results of two railway track extraction algorithms%
由表2 可看出,本文算法在铁轨提取整体效果上均优于Demja'n[6]提取的利用霍夫变换进行铁轨提取的算法。 值得注意的是,由于霍夫变换线段提取准确度受阈值影响较大, Demja'n[6]于是将阈值设置为较高数值不断降低至提取出轨道对线段,导致该算法稳定性较差且容易丢失轨道数据导致欠分割,而本文基于PCA 滤波及角度于距离阈值连接轨迹点簇则具有较好的稳定性,在2 份不同数据内,召回率及准确率均高于基于霍夫变换的提取算法,说明本文算法对不同数据适应性更优,有一定研究价值。
2.2 数据实时处理效果
为有效测试本文算法的实时性,在基于ROS(Robot Operation System)平台上完成各传感器的数据发布及接收处理等过程,将记录有原始轨道点云数据的ROS bag 进行回放,设置数据以10 Hz 的速度发布,测试数据在Ubuntu16. 04 系统及i5 -7300HQ CPU@2.50 GHz,运行内存为4 GB 的计算机上进行处理。
为更好地评估铁轨提取过程中每步骤的所需时间及算法流程的实时性,将算法提取过程分为2 部分。 第一部分处理内容为路基区域点云提取,另一部分处理内容包括:聚类、PCA 处理及同轨点簇合并,分别统计上述2 部分的每帧处理时间及点数,绘制为双y 轴图。 仿真后得到的路基提取时间与处理点数变化曲线如图6 所示,轨迹提取及合并时间与处理点数变化曲线如图7 所示。
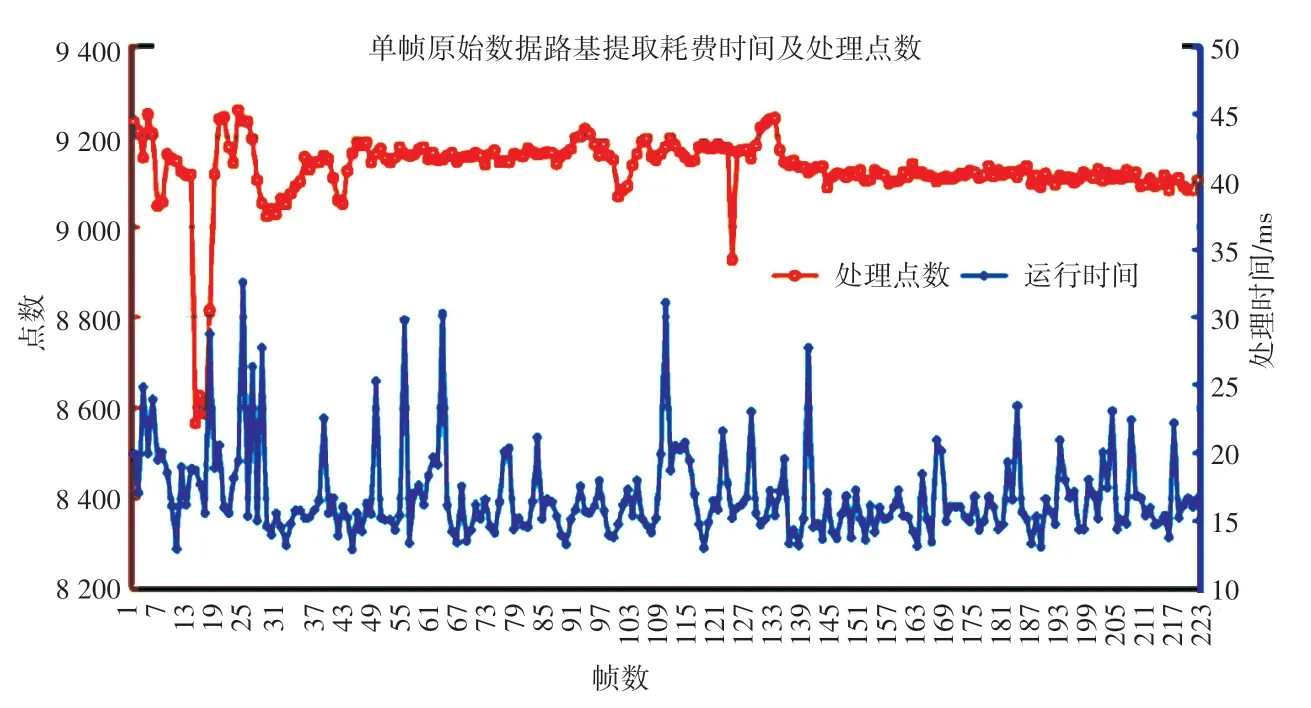
图6 路基提取时间与处理点数变化曲线Fig. 6 Curve of subgrade extraction time and number of treatment points

图7 轨迹提取及合并时间与处理点数变化曲线Fig. 7 Curve of trajectory extraction and merging time and processing points change
由图6、图7 的数据变化情况可知,算法在路基区域提取过程处理约9 000 个点,平均处理时长为16.8 ms;在轨迹提取过程处理约3 000 个点,平均处理时长为56.4 ms,算法总处理时间小于每次扫描间隔时间100 ms。 因此从上述数据可得,本文算法能实现10 Hz 的轨道提取速度,具有良好的实时性。
3 结束语
本文提出了一种基于车载点云数据,具有一定实时性的多轨道提取算法。 利用原始数据特征使用LPR 快速提取出路基区域,而后利用铁轨在路基上连续的高程差异特征提取铁轨点云,并利用PCA 过滤掉离散的假阳性非线性点簇,利用点簇距离及角度阈值实现同一轨迹点簇的连接,进一步简化提取流程,有效提高检测准确性。 在多轨道测试数据集中进行实验验证,结果显示检测的平均召回率及准确率分别为94%、93.7%。 此外,统计算法运行各主要步骤运行时间及对应处理点数,其每帧数据平均总处理时间小于80 ms,实际运行可达10 Hz,说明本算法具有良好实时性。
猜你喜欢
当代陕西(2020年23期)2021-01-07 09:24:44
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
英语文摘(2019年1期)2019-03-21 07:44:18
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
石家庄铁路职业技术学院学报(2017年4期)2017-05-25 13:26:41
小学阅读指南·低年级版(2017年1期)2017-03-13 20:10:52
文学港(2016年7期)2016-07-06 15:26:46
全球定位系统(2015年4期)2015-02-28 12:38:13
