
基于改进蜂群算法优化的支持向量机研究与应用
2023-10-22 16:01:44朱范炳
智能计算机与应用 2023年8期
朱范炳, 陈 泽, 张 翔
(信阳学院大数据与人工智能学院, 河南 信阳 464000)
0 引 言
支持向量机[1](Support Vector Machine, SVM)是一种应用广泛的机器学习方法,其基础是Vapnik[2]创立的统计学习理论。 可以解决小样本和非线性的实际问题,现已广泛应用于智能故障诊断[3]、图像识别[4]、负荷预测[5]等领域。 在使用支持向量机进行分类时,模型参数的选择对分类准确率影响很大。 如何选择模型参数以优化模型的性能是支持向量机研究领域的一个热点问题。 目前常用的模型参数优化方法有遗传算法[6]、高斯函数[7]、模拟退火算法[8]、粒子群优化算法[9]等。 在优化过程中,上述方法都不同程度地进入局部最优解,导致分类模型的性能不能最大化。 文献[10]提出了一种多维更新的人工蜂群算法,该方法很好地保持了挖掘搜索宽度和深度上的平衡,有效地避免了问题陷入局部最优解,但求解方法采用全维搜索策略会大大增加时间成本。
基于以上分析,本文提出一种进一步改进人工蜂群算法的方法,通过选择最优的搜索方向,在保证搜索精度的同时,能够降低算法的时间复杂度。 基于RBF 核函数,采用改进的人工蜂群算法对支持向量机模型参数进行优化。 本文首先通过在标准数据集上的分类实验,验证改进人工蜂群算法优化支持向量机的有效性;然后通过人体活动数据分类识别,说明所提方法的实用性;最后得出结论。
1 人工蜂群算法分析与改进
1.1 基本人工蜂群算法
人工蜂群算法[11-12]( Artificial Bee Colony Algorithm, ABC)是Karaboga 等学者于2005 年提出的一种仿生计算算法,主要应用于函数极值优化问题。 该算法模仿了蜂群的觅食行为,并将蜜蜂分为3 种不同的工作类型:采蜜蜂、观察蜂和侦察蜂。 采蜜蜂、观察蜂分别占蜜蜂总数的一半,一个蜜源对应一只蜜蜂。 蜜源优劣由适应度值评价,一个蜜源有最大开采次数。 算法通过迭代搜索蜜源,进行目标问题解的寻优,能够以较大的概率找到全局最优解。
人工蜂群算法的基本原理:设有N个蜜源{x1,x2,…,xN},每个蜜源xi(i=1,2,…,N) 有D个分量,即待优化问题的解空间包含N个可行解,每个可行解是D维向量。 设定蜂群循环搜索的最大次数和每个蜜源的可重复开采次数,同一蜜源开采超过可重复开采次数则放弃该蜜源。 人工蜂群算法包括以下阶段:
(1)蜂群的初始化阶段:利用式(1)对任一解的任一分量进行全局随机初始化:
其中,xidmin和xidmax分别表示可行解空间第d维分量的上下限,rand(0,1) 为[0,1]之间的随机数。
(2)采蜜蜂搜索阶段:采蜜蜂在初始蜜源邻域,通过式(2)搜索产生一个新解,作为候选蜜源进行开采:
其中,j∈{1,2,…,N},j≠i表示在N个蜜源中随机选取一个不同于xi的蜜源,rand(- 1,1) 是在[-1,1]之间均匀分布的随机数,决定采蜜蜂更新位置的扰动幅度。 计算新解的适应度fiti评价蜜源质量,在vi和xi之中采用贪婪策略进行选择。
(3)观察蜂跟随阶段:所有采蜜蜂完成搜索后,采蜜蜂会把解的信息及适应度分享给观察蜂。 观察蜂通过选择概率Pi决定每只采蜜蜂被跟随的概率:
或者
观察蜂通过轮盘赌策略选择采蜜蜂跟随。 如果采蜜蜂对应蜜源的选择概率值较大,则会被更多的观察蜂跟随,即适应度较大的蜜源附近会有更多的观察蜂进行搜索,蜜源对应解的邻域搜索范围更广。若新解的适应度比之前的好,观察蜂将会更新解;反之,观察蜂会将之前的解保留,同时解的迭代搜索次数会加1。
(4)侦察蜂阶段:所有观察蜂完成跟随搜索后,如果某一蜜源在被搜索最大开采次数后仍没有被更新,则认为该蜜源已被开采枯竭,对应的解陷入局部最优。 相应的采蜜蜂和观察蜂则会放弃该蜜源,转换为侦察蜂模式,按照式(1)进行全局随机搜索新蜜源。 这是人工蜂群算法跳出局部最优的有效手段。 然后返回到采蜜蜂的搜索阶段,3 种蜜蜂依次工作,重复循环搜索,最终找到目标问题的最优解。
1.2 改进人工蜂群算法
基本人工蜂群算法中,采蜜蜂和观察蜂随机选择蜜源的一个维度,按照式(2)进行搜索。 如果在这个维度上有更好的解,但下一次迭代随机选择另外一个维度,这可能会导致无法进一步开发当前维度更优的解,后因达到最大开采次数而放弃这个蜜源。 这会使算法错过很多寻找全局最优解的机会,增加算法的收敛时间,也会影响最终解的精度。
为此,本文提出了一种改进的多维搜索策略。该方法在第一次迭代时搜索蜜源的每个维度进行贪婪选择。 如果当前维度选择成功,则在保留当前维度更新的基础上,将该维度保存到外部文档Dim中,然后进行下一个维度的选择。 如果选择失败,更新将不会被保留,外部文档也不会存储该维度。 结合上述想法,本文将式(2)中随机更新一个维度替换为同时更新Dim中的维度,即可得到新的更新公式如下:
其中,m表示Dim中保存维度的个数。
每次搜索迭代搜索都会进行贪婪选择,将每个蜜源中有价值的维度存储到Dim中。 在下一次迭代中,对Dim中存储的维度执行上述操作。 多次迭代后,Dim存储维度的数量将减少,说明算法进化搜索的方向更加明确,直至算法达到稳定收敛。
2 支持向量机参数选择
支持向量机在面对非线性分类问题时,通过高维空间变换将非线性分类问题转化为高维空间的线性分类问题,并引入拉格朗日函数来解决不等式约束下二次函数的极值问题。 在使用支持向量机进行数据分类之前,应选择核函数类型、惩罚因子C和核函数参数[13]。 本文采用RBF 径向基函数作为核函数,以RBF 核函数中的宽度参数g和惩罚因子C为优化目标。 为了说明惩罚因子C和参数g对模型性能的影响,表1 和表2 给出了不同参数下数据分类准确率。

表1 C=2 分类结果随g 值的变化Tab. 1 Change of classification results with g when C=2

表2 g =2 分类结果随C 值的变化Tab. 2 Change of classification results with C when g =2
惩罚因子C起到控制错误子样本惩罚的作用,从而实现错误子样本比例与算法复杂度之间的权衡。 当C较小时,支持向量机对误差的容忍度较高,模型的精度会降低,但泛化能力增强。 当C较大时,模型的精度提高,但复杂度增加,泛化能力也降低。参数g决定了数据样本在高维特征空间中的复杂度,称为空间维数。 该维数决定在空间中可以构造的线性分类曲面的最大维数。 维数越高,线性分类面越复杂,经验风险越小,置信范围越大,反之亦然。 从表1 和表2 可以看出,惩罚因子C和参数g对分类准确率有显著影响。 因此,为了得到性能较好的支持向量机,需要选择合适的宽度参数g,并在确定的特征空间中寻找合适的惩罚因子C,使模型的拟合能力和泛化能力得到最佳的结合。
3 改进人工蜂群算法优化支持向量机参数
利用智能计算方法优化支持向量机需要设置适应度函数和寻优解空间。 由于使用算法对支持向量机进行优化的目的是为了获得更高的分类准确率,所以本文用分类准确率来设计算法的适应度函数;由前文的分析可知,惩罚因子C和宽度参数g会对支持向量机的分类性能产生很大的影响。 因此,设定惩罚因子C和宽度参数g为优化参数。
为了验证本文改进的人工蜂群算法的有效性和优越性,使用UCI 标准数据集中3 组数据集进行支持向量机的训练和测试验证。 使用的数据集名称、样本规模、维度信息,见表3。 本文设计了不同改进方法的人工蜂群算法优化支持向量机的纵向比较实验和不同算法优化支持向量机的横向比较实验。

表3 UCI 测试数据集信息Tab. 3 The information of UCI test data sets
3.1 不同方法改进蜂群算法优化支持向量机参数
分别采用本文改进的人工蜂群算法(IABC)、文献[10]提出的多维更新的人工蜂群算法(MABC)和基本人工蜂群算法(ABC)对支持向量机模型参数进行优化。 实验结果由10 次实验计算平均值所得。表4 记录不同人工蜂群算法优化的支持向量机在不同数据集下的分类准确率,表5 记录对应算法的运行时间。 由结果数据可以看出,本文改进人工蜂群算法优化的支持向量机在保证分类准确率的同时,能够有效降低算法收敛时间。

表4 改进蜂群算法优化支持向量机分类准确率Tab. 4 Classification accuracy of SVM optimized by IABC %
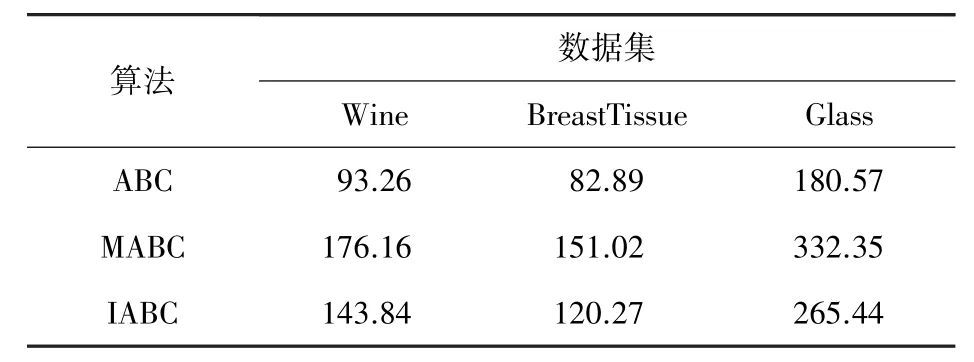
表5 改进蜂群算法优化支持向量机运行时间Tab. 5 Running time of SVM optimized by IABCs
3.2 不同算法优化支持向量机参数
为了进一步验证改进算法的性能,利用IABC算法与网格搜索算法(GS)、遗传算法(GA)和粒子群算法(PSO)优化支持向量机的参数。 分别进行10 次实验计算结果平均值。 表6 记录的是4 种算法在不同数据集下的分类准确率。 由结果数据可以看出,对于不同样本规模和维度的数据集,IABC 优化的SVM 模型都比其他算法具有更高的分类准确率。 因此,采用IABC 优化的SVM 模型将局部最优解的搜索与全局最优解的搜索结合起来,具有较好的收敛性。
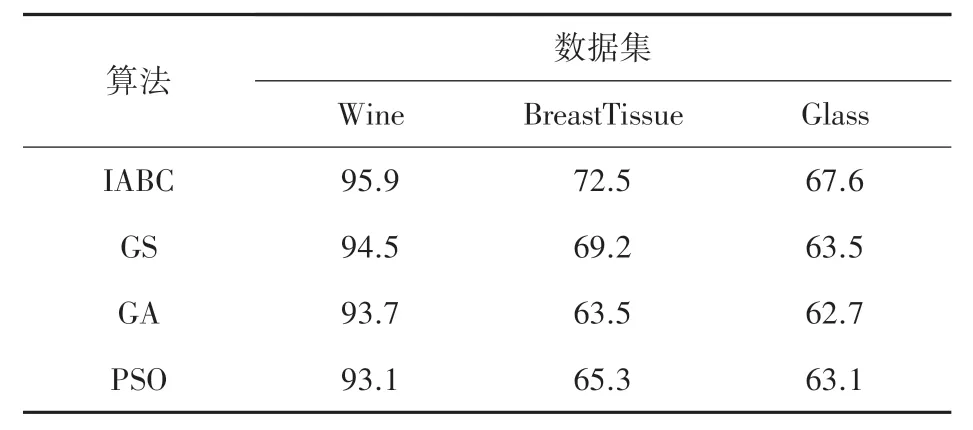
表6 不同算法优化支持向量机分类准确率Tab. 6 Classification accuracy of SVM optimized by different algorithms%
4 实例分析
4.1 实验方案设计
应用改进蜂群算法优化的支持向量机对人体活动的实测数据进行分类,验证改进算法的实用性。数据采集过程中参与者需佩戴带有加速度、温度和高度传感器的智能手表。 从加速度传感器采集的数据包括X,Y和Z方向的加速度。 温度和高度传感器的数据包括参与者的体表温度和佩戴手表距地面的距离。 采样频率设置为52 Hz,采集7 种不同的人体活动数据,数据的详细内容见表7。

表7 人体活动数据信息Tab. 7 Activity data information
4.2 实验与结果分析
在采集的人体活动数据中每类抽取100 组样本,共计700 组;在支持向量机训练和测试中,随机抽取490 个样本作为训练集,其余210 个样本作为测试集。 本文主要运用ABC 和IABC 算法对SVM模型参数进行优化,从而进行人体活动识别。 实验中设置蜂群算法的种群规模为20,最大迭代次数为500。 ABC 和IABC 算法优化的SVM 模型分类准确率的迭代变化曲线分别如图1 和图2 所示。
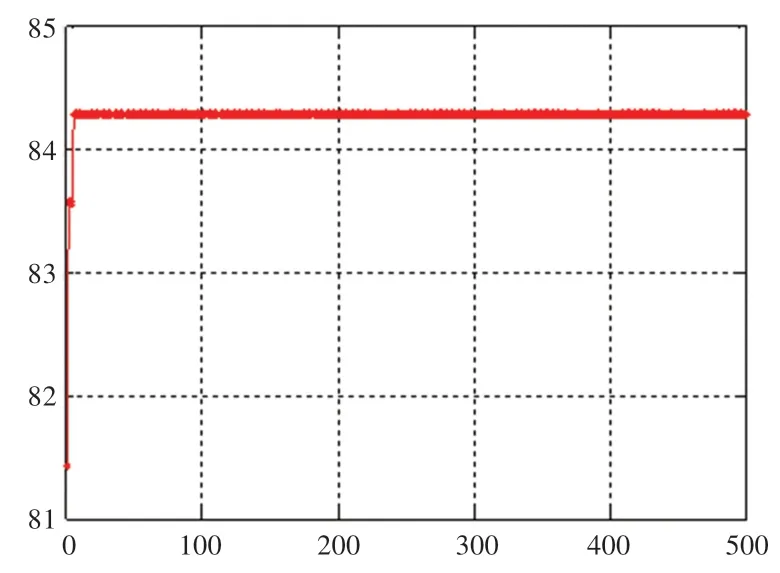
图1 ABC-SVM 分类准确率变化曲线Fig. 1 Classification accuracy curve of ABC-SVM

图2 IABC-SVM 分类准确率变化曲线Fig. 2 Classification accuracy curve of IABC-SVM
由图1 和图2 可见,在算法迭代次数均为500的情况下,ABC 算法优化的SVM 模型(ABC-SVM)分类准确率收敛速度快,最高可达84.31%;IABC 算法优化的SVM 模型(IABC-SVM)分类准确率收敛速度较ABC-SVM 慢,但分类准确率最高可达85.73%,有显著提高。 对上述实验数据分别采用SVM、ABC-SVM、IABC-SVM 进行10 次分类实验,计算分类准确率平均值记录于表8 中。

表8 不同算法模型的分类准确率Tab. 8 Classification accuracy under different algorithms
5 结束语
支持向量机模型参数是影响分类精度的重要因素。 针对目前支持向量机训练算法计算量大、运行时间长、分类准确率待提高的问题,本文提出了一种改进的人工蜂群算法对支持向量机参数优化的方法。 通过标准数据集的实验表明,改进的人工蜂群算法优化的支持向量机模型提高了分类准确率,降低了算法收敛时间。 将该方法应用于实测的人体活动数据分类,获得了良好的分类精度,说明改进人工蜂群算法优化的支持向量机具有较好的实际应用价值。
猜你喜欢
贵州科学(2023年6期)2024-01-02 11:31:56
林业与生态(2022年5期)2022-05-23 01:16:51
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
小哥白尼(军事科学)(2020年4期)2020-07-25 01:25:22
中国交通信息化(2018年5期)2018-08-21 03:37:40
高中生·天天向上(2018年1期)2018-04-14 09:24:38
现代计算机(2016年17期)2016-02-28 18:35:33
湖南农业(2015年5期)2015-02-26 07:32:30
