
基于流形学习的句向量优化
2023-10-21 07:05吴明月周栋赵文玉屈薇
计算机应用 2023年10期
吴明月,周栋,赵文玉,屈薇
基于流形学习的句向量优化
吴明月1,2,周栋1*,赵文玉1,2,屈薇1,2
(1.湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201; 2.服务计算与软件服务新技术湖南省重点实验室(湖南科技大学),湖南 湘潭 411201)( ∗ 通信作者电子邮箱dongzhou1979@hotmail.com)
句向量是自然语言处理的核心技术之一,影响着自然语言处理系统的质量和性能。然而,已有的方法无法高效推理句与句之间的全局语义关系,致使句子在欧氏空间中的语义相似性度量仍存在一定问题。为解决该问题,从句子的局部几何结构入手,提出一种基于流形学习的句向量优化方法。该方法利用局部线性嵌入(LLE)对句子及其语义相似句子进行两次加权局部线性组合,这样不仅保持了句子之间的局部几何信息,而且有助于推理全局几何信息,进而使句子在欧氏空间中的语义相似性更贴近人类真实语义。在7个文本语义相似度任务上的实验结果表明,所提方法的斯皮尔曼相关系数(SRCC)平均值相较于基于对比学习的方法SimCSE(Simple Contrastive learning of Sentence Embeddings)提升了1.21个百分点。此外,将所提方法运用于主流预训练模型上的结果表明,相较于原始预训练模型,所提方法优化后模型的SRCC平均值提升了3.32~7.70个百分点。
流形学习;预训练模型;对比学习;句向量;自然语言处理;局部线性嵌入
0 引言
在网络文本呈指数增长的互联网时代,需要处理大规模的无标签文本,同时更准更快地给用户提供感兴趣的相关内容。其中,句向量(sentence embedding)[1]是一个重要的研究方向,挖掘句与句之间的语义关系(如语义相似度、语义相关性等)对数据挖掘[2-3]、多模态[4-5]、信息检索[6-7]等领域意义重大[8]。
传统的句向量生成方法[9-12]因存在数据稀疏、未考虑上下文语境信息和无法高效处理大数据等缺陷[13],已经无法满足目前的应用需求。为解决上述问题,研究者们提出了基于预训练语言模型(Pre-trained Language Model, PLM)。其中,以BERT(Bidirectional Encoder Representation from Transformers)[14]为代表的预训练研究取得了重大的进展,使用BERT模型预训练的句向量可以处理很多的自然语言工作,如分类、聚类、机器翻译等[15]。然而,BERT所生成的句向量仍面临着以下问题:1)语义信息不充分,指BERT直接取[CLS]特征值作为句向量,会丢失部分语义信息;2)在文本语义相似度(Semantic Textual Similarity, STS)任务上性能差,指句向量无法精准表征句子之间的语义信息[15-19]。
流形学习(manifold learning)[20]旨在获取非线性数据的内在本质结构,是一种从高维数据中获取低维流形的方法,可以从现象中寻找事物的本质特性。在图像领域中,流形学习已经被证实能够观测图像数据中的内在本质规律,有效解决语义鸿沟问题。与图像数据类似,文本数据中也存在天然的低维流形结构,如果低维流形无法观测,则句向量不仅难以理解文本中潜在的语义特征,而且难以进一步推理句与句之间的全局语义关系。因此,本文提出了一种基于流形学习的句向量优化方法,该方法可以通过流形学习获取语义特征在低维流形中的本质分布特性,帮助句向量更好地推理句与句之间的全局语义关系。
1 相关工作
1.1 基于BERT的句向量生成及其优化方法
为解决BERT生成的句向量在文本相似度任务上性能差这一问题,研究者提出了一系列的句向量生成和优化方法。相关方法大致分为两类[19]:有监督方法和无监督方法。
有监督方法旨在利用句子之间更为细粒化的关系,如蕴涵、因果、转折等语义关系,推理更高层次的语义特征。文献[17]中提出一种基于孪生网络的方法SBERT(Sentence BERT),该方法利用孪生网络和三胞胎网络的结构,设置相同的两路模型分别编码句子,以两个编码向量的相似度最小为目标进一步推理句向量。有监督方法,通常只适合特定的任务,并不具备良好的迁移性能。
无监督方法又可分为基于空间映射[15-16]的方法和基于对比学习[18-19]的方法等。空间映射的方法旨在建模某种重映射关系,把原始向量空间映射到一个均匀、光滑的新空间中,提升句向量的性能。常用的重映射方法有高斯变换[15]和线性变换[16]的方法,其中:高斯变换的方法在推理时需耗费额外的计算开销,导致该方法性能受限;而线性变换的方法虽然在一定程度上解决了时间开销的问题,却难以推理句与句之间的全局语义关系,导致句向量在语义相似性度量上仍存在一定误差。基于对比学习的方法通常以数据增强的方式构建正样本,在句向量领域中,较为经典的方法主要有两种:一种是文献[19]方法,该方法通过模型不同的Dropout,分别对同一句子抽取两次不同特征,构建对比学习的正样本对;另一种是文献[18]方法,该方法通过在模型的池化层上加以微小扰动的方式,构建两个语义相似的句向量,作为正样本对。但是,对比学习的方法更偏向于建模句与句之间局部的语义关系,始终无法显式地建模全局句与句之间语义关系。
1.2 流形学习在文本领域中的应用
流形学习旨在获取非线性分布数据的内在结构。在文本领域,向量的高维表示会导致数据样本更复杂,使得文本向量无法直接观测数据内在本质的分布。为解决该问题,文献[20]中提出基于流形的词向量优化方法,并论证流形学习是词向量相似性度量恢复的有效范式之一。此后,相关研究基本都以此方法为理论依据,并集中于以下两个领域:1)在词向量领域,利用局部线性嵌入(Locally Linear Embedding, LLE)[21-22]、局部切空间对齐[23]等流形学习方法建模词向量空间的重映射,优化了词与词在欧氏空间中的相似性度量;2)在句向量领域,首先利用句向量(Sent2Vec)模型[24]生成初始的句向量,其次使用局部保持投影(Locality Preserving Projection, LPP)[25]的流形学习方法建模句向量空间的重映射,提升了句向量在特定任务上的性能。
上述研究主要针对词与词级别的语义关系,而本文拟解决的关键问题是句与句之间的全局语义关系。为了方便讨论,假设句子间的相似程度可以用数值衡量,该值为0~1的实数,值越高表示句子越相似。在极端情况下,值越接近为1,则视为两者语义基本一致;反之,值越接近0,则视为语义相反。由上述易知,当句子1为“orient,be positioned”、句子2为“be opposite”时,两句之间的真实语义相似度应为0.50左右;然而,通过现有的句向量模型计算的相似度为0.83,高估了句与句之间的语义相似度。
针对上述问题,文献[20]中提出一种基于流形学习的词向量优化方法,认为在局部上,将词与词的欧氏距离作为词与词之间的语义相似程度可以真实反映词之间的语义相似程度;然而在全局上,直接将词与词之间欧氏距离作为词与词之间的语义相似程度并不符合人类的真实评估。受到文献[20]启发,本文进一步详细定义了句与句的语义关系,认为句关系也可分为两类:一类是局部关系,指句与句之间语义信息相近时,直接计算句之间的距离度量,表征它们的语义相似程度是合理的;另一类是全局关系,指句与句之间语义信息相反时,则需要通过建立句与句之间的局部邻接关系,以精准推理句与句的全局语义关系。不同于词级别的优化,句子的语义特征抽取难度更高,句与句之间语义关系表征也更复杂多变。因此,文献[20]方法不能直接应用于句与句之间语义关系,主要存在以下问题:1)特征抽取句时,句向量容易丢失句子语义信息;2)难以挖掘句与句之间的局部关系,即已知某个句子在欧氏空间的位置时,难以高效地挖掘该句子与它语义相邻的句子集合;3)在欧氏空间中,已知句子的局部邻接关系,较难推理句与句之间的全局关系,更好地表征句与句之间的语义关系。为解决上述3个问题,本文提出了一种基于流形学习的句向量优化方法。
本文的主要工作为:
1)利用预训练模型并结合池化,按照单词组成句子的层次结构或利用最先进的句向量生成模型对句子编码,解决句向量丢失部分语义信息的问题。
2)提出一种基于词频信息的句频采样方法,该方法可以高效地获取任意句子的相邻句子集。
3)利用局部线性嵌入(LLE)对句子与它语义相似句子进行两次加权局部线性组合,在保持句子之间的局部关系的同时,能根据句子之间的局部邻接关系进一步推理句与句之间的全局语义关系。
2 本文方法
本文方法共包含编码层、采样层和重映射层这3个模块,结构如图1所示。编码层包含一种文本向量化的表示方法。首先,利用已经训练好的预训练模型初步提取上下文相关的语义特征,获取上下文相关的词表示;其次,结合池化1融合模型不同层之间的语义特征,生成动态词向量;最后,利用池化2挖掘词与词之间的互信息,生成上下文相关的句向量。采样层包含一种基于词频信息的句频采样方法。该模块结合词袋假设的思想,把句频信息定义为词频信息的线性组合,通过句频信息高效挖掘句与句之间的局部关系。重映射层包含一种基于局部线性嵌入的语义特征再抽取方法,利用LLE对测试句子与它语义相邻的句子进行两次加权局部线性组合,在保持句子局部邻接关系的同时,进一步推理句与句之间的全局语义关系。

图1 基于流形学习的句向量优化方法
2.1 编码层
2.1.1词表示
文本表示是自然语言处理的基础工作之一,其中将句表示成固定长度的向量,称之为句向量,又叫句嵌入。句向量大幅提高了神经网络处理文本数据的能力。以Transformer作为主干的一类预训练模型不仅能从大规模的语料数据中充分挖掘潜在的语义特征,还可以很容易地迁移到其他任务上,具有良好的推广性能。针对句子语义的信息抽取,本文使用了基于Transformer的预训练模型(如BERT、GPT-2(Generative Pre-trained Transformer 2)等)初步提取的特征,生成上下文相关的词表示。
假设预训练模型由层Transformer作为特征提取器。将句子输入已经训练好的模型中,便可推理具有上下文相关的词表示,计算如式(1)所示:

2.1.2池化
传统方法通常直接取预训练模型的[CLS]标记作为句向量,然而该取法在语义表征上仍存在一些问题,导致句向量语义信息表征不充分,而且难以捕捉句与句之间的全局语义关系,影响了句向量的表征能力,制约了句向量的发展。为了解决上述问题,本文引入池化提升句向量表征能力,引入池化后,句向量不仅能捕捉词与词之间的互信息,还能抽取上下文模型中不同层之间的语义特征[26]。其中,比较具有代表性的池化为平均池化,它能抽取词向量中每个维度的平均值,使得句向量融合所有词的互信息,语义特征更突出。
具体地,池化分为两步。首先,利用池化1融合模型不同层之间的语义特征,生成动态词向量;其次,使用池化2挖掘词与词之间的互信息,生成上下文相关的句向量。两个步骤分别如式(2)~(3)所示:


2.1.3句编码器
本文的句编码器如图2所示。

图2 编码层图
首先,利用预训练模型,生成上下文相关的词向量表示;其次,结合池化1,抽取上下文相关模型中不同层之间的语义特征,生成动态词向量;最后,结合池化2,按照单词组成句子的层次结构,生成上下文相关的句向量。算法1为句子编码的迭代过程。
算法1 基于预训练的句编码器方法。
输入 无监督语料库;
输出 原始句向量空间。
Repeat
预处理句子
根据式(1)计算词表示
根据式(2)计算动态词向量
根据式(3)计算句向量
Until无监督语料库中的句子已全部编码
2.2 采样层
在大规模语料库中,精确寻找某个句子以及与它语义相邻的个近邻句子非常困难:不仅需要计算该句子和其他所有句子的语义相似程度,还需要按相似程度排序,才能找出个近邻句子。以前的方法主要通过随机采样解决这一问题,但随机采样的方法始终无法精准采集与测试句子语义相邻的句子集,反而容易采集一些语义信息生僻的句子,引入噪声,导致流形学习难以推理句与句的全局关系。
为解决上述问题,本文提出了一种基于词频信息的句频采样方法,可以实现在大规模语料库中,高效地采集某句子以及与它语义相邻的句子集合。该方法的主要思想为如果某句子对中两者都包含同样的词,则表示两者语义相似的程度越高。基于此假设,本文认为当某句子包含多个高频词时,则该句子与其他句子语义相邻的可能性也会有所提高;此外,本文从词频角度出发,设计了一个评价指标,记为句频信息,该指标能在某种程度上反映某句子与其他句子语义相邻的概率。由上述分析可知,某个句子的句频信息越高,则该句子与其他句子语义相邻的可能性越大。
句频采样的主要过程为:首先,计算语料库中所有句子的句频信息,如式(4)所示;其次,利用句频信息生成降序排列的句向量空间;最后,结合候选参数,随机选取个句子得到采样空间,作为流形学习的局部邻域候选集。

2.3 重映射层
与图像数据类似,文本数据在欧氏空间中也存在天然的流形结构。为了更好地挖掘文本数据中的低维流形,本文提出一种基于局部线性嵌入的特征抽取方法,在保持文本数据局部关系的基础上,进一步推理句之间的全局语义关系。
局部线性嵌入的主要思想为:采集的高维数据样本点都可以利用局部邻域的点线性表示。在保持局部邻域权值不变情况下,可以通过最小化重构误差在低维空间中重新构造原来的数据点。重映射模块的主要实现步骤如下。









s.t. 式(9)
其中:tr代表矩阵的迹;代表一个稀疏矩阵。

综上所述,利用局部线性嵌入推理句与句之间全局关系的整个过程可以归纳为:
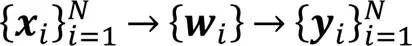
2.4 基于流形学习的句向量优化方法
本文方法的具体迭代过程如算法2所示。
算法2 基于流形学习的句向量优化方法。
输入 句向量空间,测试句向量,近邻参数,采样参数;
输出 流形学习后的新向量。
初始化 词频信息表。
Repeat
根据式(5)计算候选集
根据式(6)计算个近邻句子
根据式(7)保持句子的局部邻接关系
根据式(8)推理句子的全局关系
根据式(10)计算重映射后的句向量
Until任务中的测试句子已全部重映射
3 实验与结果分析
3.1 数据集
本文在维基百科爬取了新闻、教育和科技等多个领域的文本数据,共1 100 000条句子,制作了无监督语料库。
根据文献[27],本文选择了7个国际通用的文本相似度任务数据集用于评估本文方法。这个系列的公开数据集是目前语义文本相似度领域最为常用的公开数据集。数据集中任务的标签分数是通过众包技术所得,最终的标签得分是统计10个人的平均分数所得,每个人的评分等级为1~5,评分等级越高,表示两者的语义相似度或语义相关性越高。任务样本标签值,又称为语义相似度或语义相关性,是取值为[0,5]的实数。具体介绍如下:
1)SICK-R(Sentences Involving Compositional Knowledge Relevance)。该评测任务包含了句与句之间更高层次的语义关系,如蕴含、矛盾和中性多种语义关系,共包含9 927个句子对。
2)STS-B(Semantic Textual Similarity Benchmark)。该任务是国际公开数据集,也是最新SemEval Task之一,共包含3 210个句子对。提供了跨语言的文本相似度任务评估,如英语、土耳其语和西班牙语等。
3)STS12~STS16(Semantic Textual Similarity 2012—2016)。该类评测任务包含了句与句之间的基本语义关系,如句与句之间的语义相似关系。
3.2 评价指标

3.3 对比基线
本文的对比基线如下:
1)句向量生成模型。包括USE_TF(Universal Sentence Encoder for English)[28]、Skip_Thoughts[10]、InferSent_FastText[29]、SBERT(Sentence-BERT)[17]、SimCSE(Simple Contrastive learning of Sentence Embeddings)[19]和ConSERT(Contrastive framework for self-supervised SEntence Representation Transfer)[18]。
2)句向量优化模型。包括Glove_WR(Glove Weighed Removal)[9]、BERT_flow[15]和BERT_whitening[16]。
本文采用的主流预训练模型[30]如下:
GPT-2(版本为gpt2-base),维度为768,是一种单向自回归的语言模型的预训练技术。
BERT(版本为bert-base-uncased),维度为768,是基于Transformer编码器的降噪自编码语言模型,Transformer的编码器负责接收文本作为输入,不负责预测。
Roberta(版本为roberta-base),维度为768,是一种精调的BERT模型。
XLNET(版本为xlnet-base-cased),维度为768,是一种排列语言模型,主要采用了PLM、双流自注意力机制和改进的Transformer特征提取器。
BART(版本为bart-base),维度为768,是一种结构由序列到序列(Sequence to Sequence, Seq2Seq)组成的预训练模型,Seq2Seq的注意力机制是建立在编码器的最后输出上,获得更全面完整的全局整合信息。
T5(Text-to-Text Transfer Transformer)(版本为t5-base),维度为768,是一种探索迁移学习边界的模型,它的核心思想是对自然语言处理任务建模,将所有预训练任务构造成异步的Seq2Seq模型。T5多任务主要有完形填空、去噪自编码等预训练任务。
3.4 实验设置
本文方法根据编码层的设置不同,大致可分为两类:
1)SimMSE。编码层使用最先进的句向量生成模型SimCSE,详细实验设置参考文献[19]中的基本设置。
2)Model_MFL。Model代表3.3节中的6个主流预训练模型,MFL代表本文方法,编号(1)表示该模型使用顶层池化,编号(2)表示该模型使用加权池化,编号(3)表示该模型使用平均池化。
采样层均设置为句频采样,采样范围为[1,10 000],随机参数的取值范围为[2 500,3 500]。重映射层设置为局部线性嵌入作为流形学习的方法,近邻参数的范围为[300,1 024]。
本文所有的实验均使用SRCC评估,对比实验主要分为以下两个部分:
1)为了验证本文方法(SimMSE)可以优化最新句向量生成模型SimCSE。本文在SimCSE的基础上生成初始的句向量,再利用局部线性嵌入进一步优化,并与其他句向量优化方法如Glove_WR、BERT_flow和BERT_whitening对比。
2)为了验证本文方法的可推广性,本文在其他的主流预训练模型上进行了可推广性实验。
3.5 对比实验结果与分析
表1~2列出了不同方法在7个测试任务数据集上的性能,其中:表1主要对比了句向量生成模型和句向量优化模型;表2展示了本文方法在其他主流预训练模型上的推广性实验结果,并与原始预训练模型结合池化的方法进行对比。实验结果表明,本文方法在保持句与句局部关系的情况下,可以进一步推理句与句之间的全局语义关系,提升句向量的性能。

表1 句向量优化模型的实验结果对比 单位:%

表2 主流预训练模型的实验结果对比 单位:%
根据表1,可以得出以下结论:
1)本文的句向量优化方法可以优化欧氏空间中句与句之间的语义相似关系。在SICK-R、STS12-16和STS-B任务上,相较于次优的SimCSE,SimMSE的SRCC平均值提升了1.21个百分点,表明流形学习可以优化句与句之间的基本语义关系,修正句与句之间在欧氏空间中的语义相似度。
2)本文的句向量优化方法无法更高效地捕捉句与句之间更高层次的语义信息,如蕴涵、因果、转折等语义关系。SimMSE在SICK-R任务上,虽然优于Glove_WR、BERT_flow等大部分句向量优化模型,但性能比USE_TF、SBERT等4个句向量生成模型差。不同于句与句之间的基本语义关系,更高层次的语义关系通常需要结合监督信号才能取得更优的性能。
表2列出了本文方法在主流预训练模型上的优化效果,由表2结果可以得出以下结论:
1)本文方法具有极高的可推广性。相较于原始的预训练模型,经过本文方法优化后的BERT_MFL、Roberta_MFL等方法的性能有显著提升。
2)池化和句与句之间语义关系推理有着密切的关系,且在不同预训练模型呈现较大的差异。在大部分预训练模型上,相较于其他池化,加权池化取得了良好的性能,如BERT(2)、Roberta(2)等模型;顶层池化只在BART(1)和XLNET(1)上取得了优势,在其他预训练模型上效果不佳;平均池化则表现得更为均衡,在BERT(3)和Roberta(3)中,性能介于加权池化和顶层池化。
3)模型自身的预训练任务对句与句之间语义关系推理有着决定性的作用。经过本文方法优化后,基于T5优化后的句向量模型T5_MFL取得了最优的性能;而基于GPT-2优化后的句向量模型GPT-2_MFL性能依旧极差。表明相较于其他预训练任务而言,基于完形填空和去噪自编码等预训练任务更利于句向量理解句与句之间的语义关系。
4)本文方法对预训练模型的优化效果与预训练任务有关,且在不同预训练任务上呈现较大差异。相较于原始的预训练模型XLNET,XLNET_MFL的SRCC平均值至少提升了7.01个百分点;相较于原始的预训练模型GPT-2,GPT-2_MFL的SRCC平均值至少提升了7.70个百分点;而相较于原始的预训练模型BART,BART_MFL平均值至少提升了3.32个百分点,提升较少。这一现象表明,本文方法对随机排列的预训练任务所生成的句向量优化效果较为显著,而对BART一类的预训练模型而言优化效果并不明显。
3.6 消融实验
本文的消融实验主要分为两部分:
1)验证单层的有效性。实验设置遵循单一控制变量法,分别验证采样层和重映射层的有效性。
2)验证各层部件的组合性能。实验设置编码层固定,采样层和重映射层可变,分析采样层和重映射层的组合性能。
3.6.1采样层的有效性分析
本节实验设置如下:编码层分别使用BERT、Roberta、XLNET、GPT-2、BART和T5等模型编码;采样层分别设置为None(表示不进行任何采样操作)、随机采样、拒绝采样和句频采样;在重映射层,均设置为局部线性嵌入。评测任务为STS-B,评价指标为SRCC。
表3列出了不同采样方法在STS-B测试任务上的性能结果。从表3可以看出,相较于其他的采样方法,本文设计的句频采样能够采样、测试句子语义相邻的句子集合,并且在多个主流的预训练模型上都得到了有效的验证。

表3 不同采样方法在STS-B测试任务上的性能对比 单位:%
采样层的目标是更高效地挖掘句与句之间的局部邻接关系,即给定一个测试句子,尽可能在最短的时间内找出与它语义相邻的句子集合。然而,随机采样虽然速度很快,但是难以采集与测试句子语义相近的句子集,反而容易采集一些语义信息生僻的句子,给后续的重映射层引入了一定的噪声,增加了模型推理的难度,导致模型性能下降。
3.6.2重映射的有效性分析
本节实验设置如下:编码层分别使用BERT、Roberta、XLNET、GPT-2、BART和T5等模型对无监督语料库编码,采样层均设置为句频采样,重映射层包括无重映射层None、等度量映射(Isometric mapping,Isomap)[31]和局部线性嵌入(LLE)。评测任务为STS-B,评价指标为SRCC。
图3展示了流形学习在STS-B测试任务上的性能。实验结果表明,在多个主流的预训练模型上,相较于其他流形学习方法,LLE建模句向量的重映射都取得了较佳的性能。

图3 不同流形学习方法在STS-B测试任务上性能对比
一方面,由图3可知,除GPT-2以外,相较于Isomap,LLE的性能更为优异;另一方面,从算法的机理分析可得,在相同样本数的前提下,LLE的时间复杂度远低于Isomap,因此LLE更高效。其次,Isomap受近邻范围的影响较大,近邻范围太宽和太窄,都不利于推理句与句之间的全局关系;而LLE受近邻范围的影响较小,在很多情况下,依旧可以对样本映射,故LLE适用范围更广。
综上所述,利用LLE建模句向量的重映射更具优势。
3.6.3模型部件组合分析
本节的实验设置如下:
编码层设置BERT模型作为句子编码器;采样层分别设置为None(表示不进行任何采样操作)、随机采样、拒绝采样和句频采样。重映射层分别设置为None(表示不进行流形学习)、Isomap、LPP和LLE。评测任务为STS-B、STS2012~STS2016和SICK-R,评价指标为SRCC。
图4列出了组合方法在7个测试任务上的SRCC平均值结果。实验结果表明,采样层设置为句频采样、重映射层设置为LLE的组合方法效果最佳。

图4 采样层与重映射层的组合性能结果
由图4可以看出:
1)采样层和重映射层是相辅相成的,两者缺一不可。如果不设置采样层,而直接进行流形学习建模句向量的重映射,句向量的性能不但没有得到优化,反而有所下降。
2)高效采样方法能提升句向量的优化效果。前期使用越高效的采样方案,后期越有助于流形学习推理句与句之间的全局关系。
3)流形学习方法结合不同采样方案的性能差距较明显。例如,Isomap方法结合句频采样有利于句向量的优化,呈现积极作用;而Isomap方法结合随机采样不利于句向量的优化,呈现消极作用。
综合以上实验结果和分析可以得到如下结论:
1)相较于其他预训练模型,句向量生成模型BART和T5更利于句子在欧氏空间中的语义相似性度量。
2)利用句频信息,不仅可以高效地挖掘句子及其语义相邻的句子集合,还可以帮助后续的流形学习,更好地推理句与句之间的全局语义关系。
3)采用句频采样结合局部线性嵌入的组合方法得到的句向量优化效果最佳。
4 结语
本文主要研究当前主流预训练模型所生成句向量,并提出一种基于流形学习的句向量优化方法。首先,在预训练模型基础上结合池化,按照单词组成句子的层次结构编码句子,形成原始句空间;其次,利用句频采样得到语义较丰富的采样空间;最后,利用局部线性嵌入构建原始空间到新空间的重映射,推理句与句在全局上的语义关系。在7个国际通用的文本语义相似度任务上的实验结果表明,相较于基线方法,本文方法的性能提升明显;此外,将本文方法运用到6种主流的预训练模型上,也取得了优异的性能。
未来的研究工作中,将从以下3个方面展开:1)设计更高效的采样方案,挖掘更优质的采样空间,提升采样效率;2)研究更高效的流形学习方法,建模句与句之间的全局关系3)尝试将流形学习运用于句向量相关的下游任务,如文本分类、情感分析和文本摘要等任务,提升句向量在下游任务中的迁移性能。
[1] 赵京胜,宋梦雪,高祥,等. 自然语言处理中的文本表示研究[J]. 软件学报, 2022, 33(1): 102-128.(ZHAO J S, SONG M X, GAO X, et al. Research on text representation in natural language processing[J]. Journal of Software, 2022, 33(1): 102-128.)
[2] RAJATH S, KUMAR A, AGARWAL M, et al. Data mining tool to help the scientific community develop answers to Covid-19 queries[C]// Proceedings of the 5th International Conference on Intelligent Computing in Data Sciences. Piscataway: IEEE, 2021: 1-5.
[3] SASTRE J, VAHID A H, McDONAGH C, et al. A text mining approach to discovering COVID-19 relevant factors[C]// Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine. Piscataway: IEEE, 2020: 486-490.
[4] BOATENG G. Towards real-time multimodal emotion recognition among couples[C]// Proceedings of the 2020 International Conference on Multimodal Interaction. New York: ACM, 2020: 748-753.
[5] BOATENG G, KOWATSCH T. Speech emotion recognition among elderly individuals using multimodal fusion and transfer learning[C]// Companion Publication of the 2020 International Conference on Multimodal Interaction. New York: ACM, 2020: 12-16.
[6] ESTEVA A, KALE A, PAULUS R, et al. COVID-19 information retrieval with deep-learning based semantic search, question answering, and abstractive summarization[J]. npj Digital Medicine, 2021, 4: No.68.
[7] LIN J. A proposed conceptual framework for a representational approach to information retrieval[J]. ACM SIGIR Forum, 2021, 55(2): No.4.
[8] LI R, ZHAO X, MOENS M F. A brief overview of universal sentence representation methods: a linguistic view[J]. ACM Computing Surveys, 2023, 55(3): No.56.
[9] ARORA S, LIANG Y, MA T. A simple but tough-to-beat baseline for sentence embeddings[EB/OL]. (2022-07-22) [2022-07-20].https://openreview.net/pdf?id=SyK00v5xx.
[10] KIROS R, ZHU Y, SALAKHUTDINOV R, et al. Skip-thought vectors[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2015: 3294-3302.
[11] WIETING J, BANSAL M, GIMPEL K, et al. Towards universal paraphrastic sentence embeddings[EB/OL]. (2016-03-04) [2022-07-20].https://arxiv.org/pdf/1511.08198.pdf.
[12] ZHANG M, WU Y, LI W, et al. Learning universal sentence representations with mean-max attention autoencoder[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 1532-1543.
[13] LIU Z Y, LIN Y K, SUN M S. Representation Learning for Natural Language Processing[M]. Berlin: Springer, 2020.
[14] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186.
[15] LI B, ZHOU H, HE J, et al. On the sentence embeddings from pre-trained language models[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 9119-9130.
[16] SU J, CAO J, LIU W, et al. Whitening sentence representations for better semantics and faster retrieval[EB/OL]. (2021-03-29) [2022-05-23].https://arxiv.org/pdf/2103.15316.pdf.
[17] REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using siamese BERT-networks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3982-3992.
[18] YAN Y, LI R, WANG S, et al. ConSERT: a contrastive framework for self-supervised sentence representation transfer[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 5065-5075.
[19] GAO T, YAO X, CHEN D. SimCSE: simple contrastive learning of sentence embeddings[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 6894-6910.
[20] HASHIMOTO T B, ALVAREZ-MELIS D, JAAKKOLA T S. Word embeddings as metric recovery in semantic spaces[J]. Transactions of the Association for Computational Linguistics, 2016, 4: 273-286.
[21] HASAN S, CURRY E. Word re-embedding via manifold dimensionality retention[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA: ACL, 2017: 321-326.
[22] ZHAO D, WANG J, CHU Y, et al. Improving biomedical word representation with locally linear embedding[J]. Neurocomputing, 2021, 447: 172-182.
[23] ZHAO W, ZHOU D, LI L, et al. Manifold learning-based word representation refinement incorporating global and local information[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 3401-3412.
[24] NASER MOGHADASI M, ZHUANG Y. Sent2Vec: a new sentence embedding representation with sentimental semantic[C]// Proceedings of the 2020 IEEE International Conference on Big Data. Piscataway: IEEE, 2020: 4672-4680.
[25] ZHAO D, WANG J, LIN H, et al. Sentence representation with manifold learning for biomedical texts[J]. Knowledge-Based Systems, 2021, 218: No.106869.
[26] BOMMASANI R, DAVIS K, CARDIE C. Interpreting pretrained contextualized representations via reductions to static embeddings[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 4758-4781.
[27] 韩程程,李磊,刘婷婷,等. 语义文本相似度计算方法[J]. 华东师范大学学报(自然科学版), 2020(5):95-112.(HAN C C, LI L, LIU T T, et al. Approaches for semantic textual similarity[J]. Journal of East China Normal University (Natural Science), 2020(5):95-112.)
[28] CER D, YANG Y, KONG S Y, et al. Universal sentence encoder for English[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: ACL, 2018: 169-174.
[29] CONNEAU A, KIELA D, SCHWENK H, et al. Supervised learning of universal sentence representations from natural language inference data[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 670-680.
[30] 岳增营,叶霞,刘睿珩. 基于语言模型的预训练技术研究综述[J]. 中文信息学报, 2021, 35(9): 15-29.(YUE Z Y, YE X,LIU R H. A survey of language model based pre-training technology[J]. Journal of Chinese Information Processing, 2021, 35(9): 15-29.)
[31] ROWEIS S T, SAUL L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290(5500): 2323-2326.
Sentence embedding optimization based on manifold learning
WU Mingyue1,2, ZHOU Dong1*, ZHAO Wenyu1,2, QU Wei1,2
(1,,411201,;2(),411201,)
As one of the core technologies of natural language processing, sentence embedding affects the quality and performance of natural language processing system. However, the existing methods are unable to infer the global semantic relationship between sentences efficiently, which leads to the fact that the semantic similarity measurement of sentences in Euclidean space still has some problems. To address the issue, a sentence embedding optimization method based on manifold learning was proposed. In the method, Local Linear Embedding (LLE) was used to perform double weighted local linear combinations to the sentences and their semantically similar sentences, thereby preserving the local geometric information between sentences and providing helps to the inference of the global geometric information. As a result, the semantic similarity of sentences in Euclidean space was closer to the real semantics of humans. Experimental results on seven text semantic similarity tasks show that the proposed method has the average Spearman’s Rank Correlation Coefficient, (SRCC) improved by 1.21 percentage points compared with the contrastive learning-based method SimCSE (Simple Contrastive learning of Sentence Embeddings). In addition, the proposed method was applied to mainstream pre-trained models. The results show that compared to the original pre-trained models, the models optimized by the proposed method have the average SRCC improved by 3.32 to 7.70 percentage points.
manifold learning; pre-trained model; contrastive learning; sentence embedding; natural language processing; Local Linear Embedding (LLE)
This work is partially supported by National Natural Science Foundation of China (61876062), Natural Science Foundation of Hunan Province (2022JJ30020), Scientific Research Project of Hunan Provincial Education Department (21A0319).
WU Mingyue, born in 1999, M. S. candidate. His research interests include natural language processing, deep learning.
ZHOU Dong, born in 1979, Ph. D., professor. His research interests include information retrieval, natural language processing.
ZHAO Wenyu, born in 1993, Ph. D. candidate. Her research interests include information retrieval, natural language processing.
QU Wei, born in 1991, M. S. candidate. Her research interests include source code summarization, natural language processing.
1001-9081(2023)10-3062-08
10.11772/j.issn.1001-9081.2022091449
2022⁃09⁃30;
2023⁃01⁃24;
国家自然科学基金资助项目(61876062);湖南省自然科学基金资助项目(2022JJ30020);湖南省教育厅科研项目(21A0319)。
吴明月(1999—),男,湖南娄底人,硕士研究生,CCF会员,主要研究方向:自然语言处理、深度学习; 周栋(1979—),男,湖南长沙人,教授,博士,CCF高级会员,主要研究方向:信息检索、自然语言处理; 赵文玉(1993—),女,湖南衡阳人,博士研究生,CCF会员,主要研究方向:信息检索、自然语言处理; 屈薇(1991—),女,湖南湘潭人,硕士研究生,CCF会员,主要研究方向:源代码摘要、自然语言处理。
TP391.1
A
2023⁃02⁃01。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
数学物理学报(2020年2期)2020-06-02
开放教育研究(2020年2期)2020-03-31
数学年刊A辑(中文版)(2019年3期)2019-10-08
数学物理学报(2019年1期)2019-03-21
计算机技术与发展(2019年1期)2019-01-21
现代语文(2016年21期)2016-05-25
振动工程学报(2015年2期)2015-03-01
