
基于CSPA-Informer的滚动轴承剩余寿命预测*
2023-10-21 09:00:02颜家威易灿灿
组合机床与自动化加工技术 2023年10期
颜家威,易灿灿,黄 涛,肖 涵
(武汉科技大学 a.冶金装备及其控制教育部重点实验室;b.机械传动与制造工程湖北省重点实验室;c.精密制造研究院,武汉 430080)
0 引言
滚动轴承是齿轮箱传动系统的核心部件,其一旦在运行过程中被损坏,就会导致设备停机进行维修,造成经济损失[1]。剩余使用寿命(remaining useful life,RUL)预测可以有效地预防并降低该类事件的发生次数,提前发现损坏的轴承进行维修与更换,提高机械设备运行的稳定性与设备的生产效率[2]。
滚动轴承RUL预测的方法一般分为基于物理模型和数据驱动的方法[3]。基于物理模型的方法旨在根据现场情况,建立对应的数学模型,通过模型描述数据的失效趋势[4]。在工业现场中,实际研究对象结构复杂、机理难以描述,建立准确的数学模型十分困难。基于数据驱动的方法,如卷积神经网络(CNN)[5]、循环神经网络(RNN)[6]、长短时记忆网络(LSTM)[7]等算法,使用各阶段传感器的历史数据进行预测,在工业应用中更适合、更容易。莫仁鹏等[8]选用CNN模型将轴承退化数据进行特征提取、融合后输入到前馈神经网络(FNN)模块进行训练,映射输出RUL预测值。LIU等[9]结合自动编码器形式的RNN和一种自带去噪功能的自动编码器(GRU-NP-DAE),通过上一周期的训练数据输入预测下一周期数据。舒涛等[10]提出一种改进的灰色模型,并与LSTM模型相结合,预测旋转机械轴承系统的未来工作状态。基于编码器-解码器结构的预测方法,如Transformer模型[11],利用结构中包含的注意力机制提高模型训练、迭代的速度,对并行计算的适应性高。XU等[12]提出了一种结合编码器、GRU回归模块和解码器的预测模型(HNCPM),通过该模型实现振动数据的预测。上述方法均在滚动轴承RUL方面做出了贡献,但仍存在计算速度缓慢和精度低等问题。
基于以上方法的不足,本文研究了Informer模型[13],并将其应用到滚动轴承RUL预测中。Informer模型中的概率稀疏自注意力机制内部结构复杂,导致其计算内存占比较大,计算效率不高。为此,本文提出一种基于跨阶段局部注意力机制(cross stage partial attention,CSPA)[14],将输入维度一分为二,一部分通过self-attention模块特征提取;另一部分通过1×1的卷积层的线性投影。内存占比约为传统self-attention模块的31.25%,大幅度减少了内存占用,缓解因内存瓶颈导致的计算效率不足和精度较差的问题。最后,通过对XJTU-SY轴承数据集的研究,利用绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)作为模型性能评价指标,验证了本文提出的CSPA-Informer模型的有效性。
1 理论分析
1.1 Informer模型
Informer模型是从规范Transformer模型派生的时间序列预测模型。Informer进行了多项改进,以增强类Transformer模型在长序列时间序列预测(LSTF)问题中的预测能力。类似基于注意力机制的规范Transformer模型,Informer模型也由编码器(Encoder)与解码器(Decoder)两个部分组成。
(1)Informer模型的输入。输入的定义如式(1)所示,在具有固定窗口大小的滚动预测设置下,t时刻的输入为:
(1)
式中:Lx为当前输入的长度,t时刻的预测输出为:
(2)
式中:Ly为当前输出的长度。针对长时间序列预测(LSTF)问题时,需使用更长的输出长度Ly。
(2)自注意力机制。首先,传统的自注意力机制(self-attention mechanism)将输入通过算法向量化,并嵌入位置信息与时序信息,对得到Query、Key、Value三个分量进行缩放点积,即:
(3)
式中:Q∈RLQ×d,K∈RLK×d,V∈RLV×d,dK为输入的维度,第i个Query分量的Attention系数的概率形式为:
(4)
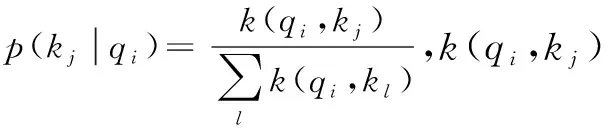
在上文公式中,传统self-attention机制计算概率p(kj|qi)时,采用二次时间复杂度的点积运算,并且需要计算出O(LQLK)的内存占用。因此,模型的预测能力受到了限值。此外,研究表明,self-attention的概率分布存在一定的稀疏性,在不显著影响机制的前提下,对每个概率p(kj|qi)都设定了“特定”的计数方式。因此,需要首先对传统self-attention的“稀疏性”学习模式进行定性评估,self-attention的分布为长尾式分布,可解释为只有少数点积会对主要注意有明显贡献,而其他点积的贡献不能起决定性作用,可以忽略。
本文引入KL散度计算Query分量的稀疏性,其中第i个Query分量的稀疏性的评价公式为:
(5)
式中:第一项qi对于每个Key分量的另一个取最大值的过程(log-sum-exp,LSE),第二项则是求算数平均值。基于上面的评价公式,能够得到概率稀疏自注意力(Probsparse self-attention)的公式,即:
(6)

如图1所示,Informer模型的整体结构分为两部分,左侧为训练部分,右侧为预测部分。训练部分将训练数据输入到Encoder模块中,经过浅蓝色梯形部分的多头Probsparse self-attention结构对数据进行特征提取,提取后的数据网络规模大幅减小,并通过多层卷积、池化与多头Probsparse self-attention结构的叠加,能大幅提升Encoder模块的鲁棒性。预测部分将预测数据输入到Decoder模块中,选取0元素填充所需的预测数据,多头注意力模块在特征图的加权下,快速生成解码元素,通过全连接层输出解码元素。

图1 Informer模型的整体构架
(3)编码器。为了提取长序列输入的关键特征,即数据的长期依赖性,设计了Encoder模块进行输入提取。作为Probsparse self-attention的结果,Encoder结构的特征映射由许多Value分量构成。因此,在对特征赋予权重时,distilling操作会判断所有特征的状态,对具有主导作用的特征赋予更多的权重占比,对其他特征赋予较少的权重占比,并在下一层生成对应的集中self-attention特征映射。从j到j+1层的distilling操作的过程如下:
(7)
式中:[·]AB包含了多头概率稀疏的自注意力(multi-head probsparse self-attention)以及其在注意块(attention block)中的关键操作。Convld函数表示对选定的数据进行一维时间序列上的卷积操作,其激活函数选取ELU函数。Informer模型在时间序列预测上采用的自注意力distilling机制,能够将输入数据的长度在每次编码之后缩短为原始的一半,Encoder模块在计算大幅度缩短长度后的输入数据时,所需的计算时间明显减少,并且释放了计算时的内存开销。
(4)解码器。Decoder模块结构由两个多头注意力层组成,两个注意力层结构一样。此外,Decoder模块独特的生成推理功能,在处理长期预测时,能够有效缓解预测速度下降的问题。Decoder模块输入向量如下:
(8)
其中,在Probsparse self-attention的计算过程中,引入了一种隐藏多头注意力(masked multi-head attention),能够阻止所有位置都能注意到下一个计算位置,以此避免了出现局部自回归的问题。最后,在编码器进行输出时,会经过一层全连接层进行整合,其输出维度与预测方式一致。Decoder模块的采用了生成式结构,能够一次生成所有预测序列,大幅度缩短了预测的解码时间。
1.2 CSPAttention机制
本文研究了一种CSPA结构,图2为该结构的一个块架构。输入分为两部分:第一个通过A模块传播,一个1×1卷积层,而另一个通过B模块传播,一个自注意力块。最后将两个部分的输出连接在一起,作为整个CSPA块的最终输出。
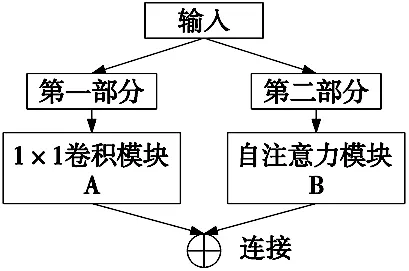
图2 CSPA机制结构图
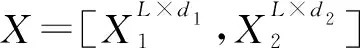
CSPA的一个阶段的输出矩阵由下式给出:
(9)
式中:A(X2h)是第h个自我关注块的缩放点积,Wh是一个dh×dh的线性投影矩阵,H是头部的数量,dh是每个头部的尺寸,假设每个头部具有相同的尺寸;Wc是1×1卷积层的d/2×d/2值权重矩阵。
受CSPNet[15]的启发,CSPA处理标记维度的方式反映了CSPNet处理图像通道的方式。整个输出Y可以写成一个子块矩阵,这样分割的两部分不包含属于另一部分的重复梯度信息。此外,为了在整个输出维度不等于整个输入维度时,将第一部分投影到合适的维度,该结构添加了一个额外的个卷积层。CSPA的权重更新如图(3)所示:
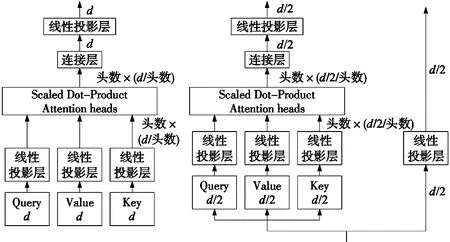
(a) 传统的多头self-attention架构 (b) CSPA结构图3 传统self-attention块和CSPA块的比较
(10)
(11)
式中:f为权重更新函数,g为传播到第i条路径的梯度。且分割部分的梯度是分别积分的。
设计CSPA的目的是为了缓解self-attention机制的内存瓶颈和计算效率问题。CSPNet已经展示了其在提高性能和减少基于CNN架构的计算方面的能力。CSPA还降低了self-attention机制计算时所需的的内存流量和因计算时间分配导致的计算复杂度。假设一个规范的self-attention块只存在一个输入标记,并且其输入、输出维度均为d。如图3a所示,正常情况下一个self-attention块中存在4个线性投影层(Query、Key、Value、Projection),各层的驶入、输出维度均为d。计算可得,其内存占用为4d2。然而,假设CSPA将输入维度分成两半,CSPA的第一部分只有一个线性投影层,而第二部分有四个。相应的架构如图3b所示。因此,一个CSPA块的内存占用是(4+1)×(d/2)2,是传统self-attention的31.25%。
图3a是一个传统的多头self-attention架构,假设每个头部具有相同的维度。图3b是一个CSPA结构,其按维度将输入一分为二。左侧实际上是一个具有一半输入维度的self-attention块,右侧是一个的卷积层。
1.3 基于改进CSPA-Informer模型的滚动轴承剩余寿命预测步骤
当向Informer应用CSPA时,原本注意力结构Probsparse self-attention将升级为Probsparse CSPA结构,从而组成CSPA-Informer模型。CSPA-Informer模型的预测流程图如图4所示。预测步骤如下:
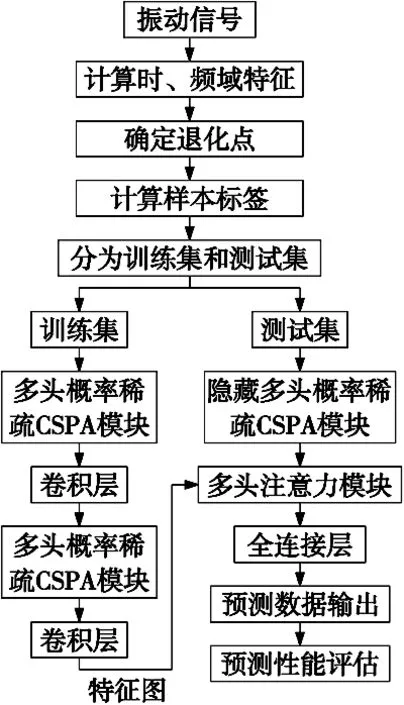
图4 CSPA-Informer模型预测流程
步骤1:计算原始振动信号的时域、频域特征,构建特征数据集;
步骤2:确定轴承退化点,并计算退化点之后的样本标签;
步骤3:将加入样本标签之后的新数据集划分为训练集和测试集;
步骤4:将训练集数据输入到CSPA-Informer模型的Encoder模块中训练模型;将测试集数据输入到训练好的模型的Decoder模块中进行预测;
步骤5:输出预测结果,并对结果进行性能评估。
2 实验数据
2.1 数据集简介
本文采用的实验数据为XJTU-SY轴承数据集,该数据集是“机械装备健康监测联合实验室”建立的,具有样本全、干扰大等特点,是测试模型性能的有效数据[16]。该数据集产生于故障试验台,该实验台主要分为动力输出装置、复杂工况加载装置以及测试轴承等。在该实验台上,能够通过控制液压加载系统对被测轴承施加径向力,从而产生不同的工况来满足实验要求。在上述不同工况下开展轴承加速寿命试验,即可获得本文所需要的轴承全寿命周期数据。本文共设计了3种试验工况,每种工况有5个测试轴承参与试验,测试轴承采用LDKUER204滚动轴承,其具体参数如表1所示。试验的采样频率设置为25.6 kHz,单次采样时长设置为1.28 s,采样间隔设置为1 min,详细实验过程参数如表2所示。最后采用2个PCB 352C33单向加速度传感器进行实验数据采集,分别在水平和竖直方向对测试轴承进行振动信号采集,实验装置图如图5所示。

表1 LDKUER204轴承参数
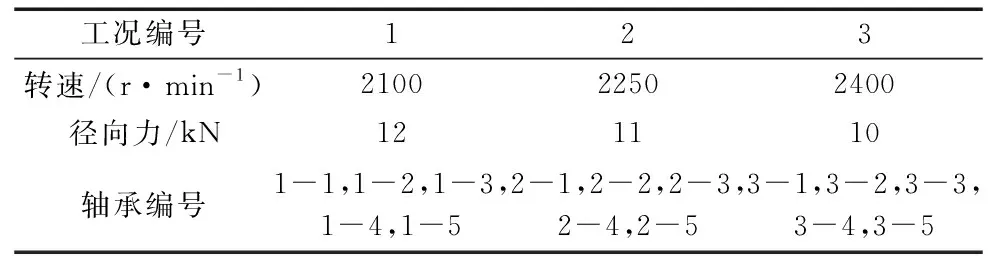
表2 轴承加速寿命试验工况
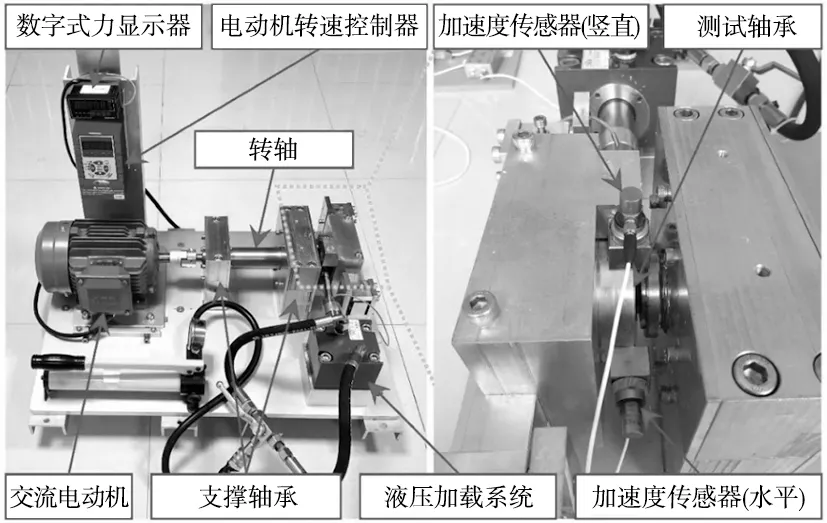
图5 轴承寿命试验台
2.2 数据预处理
本文选用数据集中的第3种工况的3-1轴承作为示例,进行数据预处理。该数据集以.csv的格式存储在2538个文件中。每个文件中存储了两列数据,分别为水平振动信号(horizontal vibration signals)和竖直振动信号(vertical vibration signals),除开第一行的标签,有效采集值有32 768个。实验时,该轴承运行了42 h18 min才出现明显的外圈故障失效现象,即该轴承的实际寿命为42 h18 min。实验期间,由于只对轴承施加了10 kN的径向压力,未施加轴向压力,因此水平方向受压力后的振动信号更能反映轴承的真实退化情况。本文采用3-1轴承的水平振动信号,研究其退化过程,其全周期数据示意如图6所示。
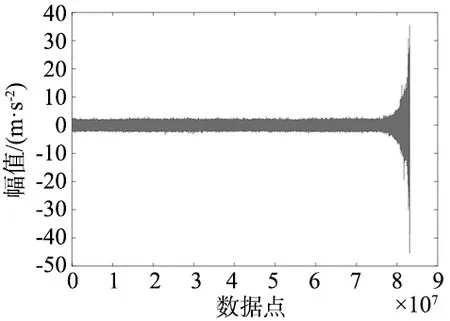
图6 XJTU-SY轴承数据3-1全寿命周期数据时域图
首先,对2538个样本文件进行数据预处理,并逐个提取其中有用的特征。具体方式为分别计算每个文件的3项时域特征和3项频域特征。其中,时域特征选取均方根、峭度和峰-峰值3项,频域特征选取平均频率、频率方差和频率标准差3项。其计算公式如表3和表4所示。时域特征中的重心频率(FC)公式为计算频率方差和频率标准差所需要用到的过渡公式。每种特征均计算2538次,组成新的特征数据集。划分新特征数据集时,本文将数据分为前2476个数据和后62个数据,取前者作为模型的训练输入,后者作为测试输入。

表3 时域特征

表4 频域特征

续表
通过观察实测信号的变化规律,在时域特征中找到轴承退化突变点,本文综合特征选取第2329组样本点作为突变点,将轴承分为正常工作阶段和快速退化阶段。采用分阶段方法给轴承实际剩余寿命建立标签y,其中,将轴承正常工作的标签值设置为1,彻底损坏的标签值设置为0。正常工作阶段数据平稳,不能有效反映轴承退化趋势,因此前2329组样本点的标签y均为1;快速退化阶段有209组数据,代表该阶段最大剩余寿命为209 min,以从1到0的等差标签y来表示剩余寿命标签,该阶段第100组数据的标签值为100/209=0.478 469,以此类推,构建该阶段的标签。
3 结果分析
3.1 模型参数设置
本文选取LSTM、Transformer、Informer和CSPA-Informer这4个模型进行预测结果对比。本文中的每个网络模型都是基于Python 3.9实现的。操作系统是64位Windows操作系统,配备16.00 GB RAM、第11代Intel(R)Core(TM)i5-14000F 2.60 GHz处理器与NVIDIA GeForce RTX 3070图形处理器。
本文选取XJTU-SY轴承数据集数据,考察4种模型在径向压力10 kN,转速2400 r/min条件下,对滚动轴承剩余使用寿命的预测能力。笔者选取3项指标对预测结果的精度进行评价,其中绝对误差(MAE)是用来描述实际寿命与模型预测寿命之间存在的平均绝对误差;均方误差(MSE)用来描述实际寿命与模型预测寿命的变化程度与精确度;均方根误差(RMSE)用来描述实际寿命与模型预测寿命的准确性。3个评价指标的计算值越小,表明该模型的预测结果与真实结果越贴合,预测效果越好。
各计算公式如下:
(12)
(13)
(14)

3.2 实验结果分析
本实验旨在验证CSPA-Informer模型在滚动轴承RUL系列问题上的预测能力,并计算其它3个模型,综合对比4个模型的预测效果。实验选取MSE做为整个过程中的损失函数,并选取Adam优化器对各个模型进行优化。
其中,LSTM模型的学习率设置为0.005,epoch总数设为500,神经元个数设为1000。Transformer模型的学习率设置为0.000 1,批量大小设置为8,epoch总数为15,并带有适当的提前停止。Informer模型学习率设为0.000 1,每个epoch衰减两倍;批量大小设置为8,epoch总数设为15,并带有适当的提前停止;解码器的起始令牌长度与编码器的输入长度保持一致。CSPA-Informer模型学习率设为0.000 1,每个epoch衰减两倍;批量大小设置为8,epoch总数设为15,并带有适当的提前停止;解码器的起始令牌长度与编码器的输入长度保持一致。
由于本文实验中使用的4个模型的epoch时间差异较大,因此只比较Informer及CSPA改进后模型的loss收敛曲线图,以此验证改进前后模型收敛的速度差异。图7为Informer与CSPA-Informer两个模型的测试集loss曲线图。可以看出,CSPA-Informer模型的loss曲线的收敛速度更快,并且极值更小。

图7 测试集loss曲线图 图8 不同模型在XJTU-SY数据集3-1上的对比图
图8为4种模型在XJTU-SY数据集工况3-1上的预测效果图。表5为4种模型在XJTU-SY数据集工况3-1上的评估数据。从图8可以看出,CSPA-Informer模型在XJTU-SY数据集3-1上的预测结果最符合实际剩余使用寿命,并且曲线的波动幅度较小。根据表5可以得出,CSPA-Informer模型相比LSTM与Transformer模型,其MAE、MSE和RMSE三项指标分别提升了55%、83%和59%以上。并且改进后CSPA-Informer与Informer模型相比,3项指标分别提升了46%、78%和53%左右。

表5 不同模型在XJTU-SY数据集3-1上的评估数据
此外,本文还选取了XJTU-SY数据集第1种工况下的1-2数据集和第2种工况下的2-3数据集,分别计算不同工况下CSPA-Informer模型的预测能力并与其他3种方法的预测效果对比。数据预处理的方式与上文对3-1数据集处理相同,在1-2数据集上,选取剩余31组数据作为测试集,不同结果的预测效果对比图如图9所示,可以看出CSPA-Informer模型的预测结果仍最符合实际剩余使用寿命。在2-3数据集上,选取剩余60组数据作为测试集,不同结果的预测效果对比图如图10所示,可知CSPA-Informer模型的预测结果曲线的波动幅度也仍更加平稳。由表6可以得出,CSPA-Informer模型相比其他模型在1-2数据集上的MAE、MSE和RMSE三项指标至少提升了28%、40%和23%;在2-3数据集上,3项指标至少提升了21%、32%和17%。
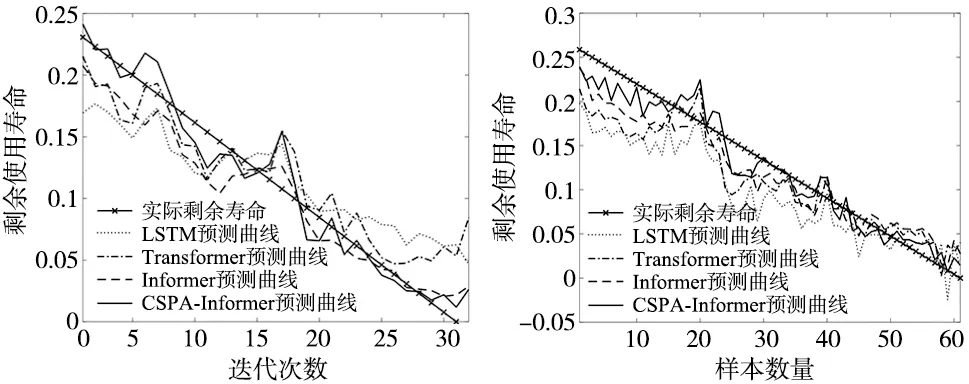
图9 不同模型在XJTU-SY数据集1-2上的对比图 图10 不同模型在XJTU-SY数据集2-3上的对比图

表6 不同模型在XJTU-SY数据集1-2和2-3上的评估数据
4 结束语
本文针对滚动轴承剩余使用寿命预测精度不足的问题,提出一种CSPA机制,并将其替换Informer模型的原始注意力机制,结论如下:
(1)本文创新性地将CSPA优化后的Informer模型引入滚动轴承RUL预测中,解决了传统预测模型因特征提取能力不足导致的难以进行长时间序列预测的问题。
(2)改进后的CSPA-Informer模型与常规LSTM和Transformer模型相比,其预测结果最符合实际剩余使用寿命,并且曲线的波动幅度较小。
(3)CSPA-Informer模型解决了原始Informer模型中因内存瓶颈导致的计算效率不足和精度较差的问题,提高了模型的预测性能,为滚动轴承RUL系列问题提供了一种新的解决思路。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22 06:39:32
哈尔滨轴承(2022年1期)2022-05-23 13:13:24
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中老年保健(2021年8期)2021-12-02 23:55:49
哈尔滨轴承(2021年2期)2021-08-12 06:11:46
哈尔滨轴承(2021年1期)2021-07-21 05:43:16
作文评点报·低幼版(2020年3期)2020-02-12 09:08:22
华人时刊(2018年17期)2018-12-07 01:02:20
奥秘(2017年12期)2017-07-04 11:37:14
传媒评论(2017年3期)2017-06-13 09:18:10
