
基于WOA-VMD-ISSA-LSSVM的商业短期电力负荷预测研究
2023-10-21 05:52杨广亮万俊杰
现代建筑电气 2023年8期
杨广亮, 万俊杰
(1.江苏安科瑞电器制造有限公司, 江苏 江阴 214405;2.安科瑞电气股份有限公司, 上海 201801)
0 引 言
随着经济社会的快速发展,全国各地的用电量不断攀升。短期电力负荷预测的准确性对社会经济发展、人民安居乐业具有重要意义[1]。近年来,随着人工智能技术的快速发展,人工神经网络、支持向量机、随机森林等机器学习模型也受到了广大学者的关注[2]。商业负荷作为一种社会性的、人为特征突出的负荷,其具有代表性的负荷主要包括照明负荷和空调负荷。这些负荷和人的感官感觉直接相关,受人为因素影响大,而其又主要体现在人体本身对天气状况的感官感觉上。因此商业负荷对天气、气候的敏感度较高,与商业负荷相关的气象影响因素主要包括温度、湿度、风速、降雨量等。商业负荷预测即寻找商业负荷影响因素和商业负荷之间的函数关系式。
最小二乘支持向量机(LSSVM)作为20世纪60年代提出的一种机器学习算法,在处理商业负荷预测等回归问题上具有很好的应用前景,该模型不仅鲁棒性好,而且能防止过度学习,求解速度优于SVM,但是其参数选择具有一定的随机性,对模型预测精度影响较大,因此本文引入改进的麻雀搜索算法对其参数进行优化选择。
由于负荷序列数据具有随机性,其原始特征难以捉摸,简单的组合模型已经无法很好地解决该问题。目前大多数组合模型结合数据分解技术,变分模态分解(VMD)可以将多分量信号一次性分解成多个单分量调幅调频信号,避免了迭代过程中遇到的端点效应和虚假分量问题。但是VMD不具有适应性,对于核心参数(K和α)需要根据经验设置,具有一定的盲目性,因此,建立以样本熵为基础的WOA-VMD模型对商业负荷数据进行分解。
综上,本文提出一种基于WOA-VMD-ISSA-LSSVM的商业短期电力负荷预测模型。为了从原始商业电力负荷数据中获得更多有用信息,实现最佳的信号处理效果,采用WOA-VMD分解技术对原始负荷数据进行分解,得到最佳的分解子序列。然后考虑到麻雀搜索算法在迭代后期会出现种群多样性减少和易陷入局部极值的问题,引入了Tent混沌序列和动态自适应权重对麻雀搜索算法进行改进。接着采用改进后的麻雀搜索算法对LSSVM的模型参数进行优化建立ISSA-LSSVM模型。最后将经过WOA-VMD分解之后的子序列输入到ISSA-LSSVM模型中,得到每个子序列的预测结果,并进行叠加得到最终商业电力负荷预测结果。结合具体案例,验证了该模型具有更高的预测精度和准确性,为实现微电网能量管理中的经济调度、负荷管理提供一定的依据。
1 算法原理
1.1 变分模态分解
变分模态分解是一种自适应、完全非递归的模态分解和信号处理方法[3]。VMD可以将不规律的、非平稳的复杂原始商业电力负荷数据一次性分解为多个特征各异的模态分量。假设原始商业电力负荷数据为f(t),运用VMD进行信号分解的约束表达式定义如下:
(1)
式中: {uk}、{ωk}——分解后第k个模态分量表达式和中心频率;
K——模态分个数;
δ(t)——狄拉克函数。
分解所得所有模态分量与原负荷序列f(t)一致。运用Lagrange算子解决上述问题,公式(1)更新如下:


(2)
式中:λ——Lagrange算子;
α——二次惩罚因子。
采用ADMM寻优迭代后可得到模态分量uk,求出各自的模态频率ωk和Lagrange算法λ表达式如式(3)~(5)所示:
(3)
(4)
(5)
式中:γ——噪声容忍度。
1.2 基于鲸鱼优化参数的变分模态分解
VMD在进行分解时,需要预先设定IMF分解的个数,分解的数量不同,处理的结果也会不一样;国内外的研究表明,VMD算法中的惩罚参数α也会对分解结果产生较大的影响,因此这两个参数的优化尤为重要。鲸鱼优化算法作为一种群智能优化算法,具有较好的局部和全局搜索能力,因此本文采用鲸鱼优化算法对这两个参数进行优化选择。
鲸鱼在捕食猎物时主要分为三个阶段:环绕猎物、螺旋气泡攻击(开发过程)和寻找猎物(搜索过程)[4]。
(1) 环绕猎物。
在开发过程中,座头鲸将当前的最佳位置视为目标猎物,然后通过收缩环绕和螺旋更新位置来调整当前位置,以便达到局部最优。收缩环绕的数学模型描述如下:
D=|C·X*(t)-X(t)|
(6)
X(t+1)=X*(t)-A·D
(7)
式中:D——位置衡量参数;
X*——当前获得的最佳位置向量;
X——位置向量;
t——当前迭代次数;
A、C——两个控制参数向量。
通过计算可得:
A=2a·r-a
(8)
C=2·r
(9)
(10)
式中:r——0到1之间的任意向量;
a——线性的方式从2降到0;
T——最大迭代次数。
(2) 开发过程。
螺旋更新位置的数学模型描述通过螺旋方程来表示:
D′=|X*(t)-X(t)|
(11)
X(t+1)=D′·ebl·cos(2πl)+X*(t)
(12)
式中:D′——当前位置和最佳位置之间的距离;
l——-1到-1之间的随机数;
b——对数螺旋形状常数。
(3) 搜索过程。
座头鲸搜索猎物的过程是在全局范围里搜索,并且不断地更新最佳位置来达到全局最优,该过程用数学模型描述为
D=|C·Xrand-X|
(13)
X(t+1)=Xrand-A·D
(14)
式中:Xrand——当前一代中的随机位置向量。
利用控制参数|A|来决定位置更新方式,当|A|<1时,通过收缩环绕来进行局部最优的求解;当|A|≥1时|A|≥1时,通过搜索来进行全局最优的求解。
原始信号的稀疏特性可由包络熵来表示,因此本文的适应度值选择包络熵局部极小值,使用WOA对VMD分解的K和α进行优化选择。如下式所示:
(15)
(16)
式中:Ep——包络熵;
N——采样点数个数;
a(i)——k个IMF分量经过Hilbert解调后的包络信号。
WOA-VMD流程图如图1所示。
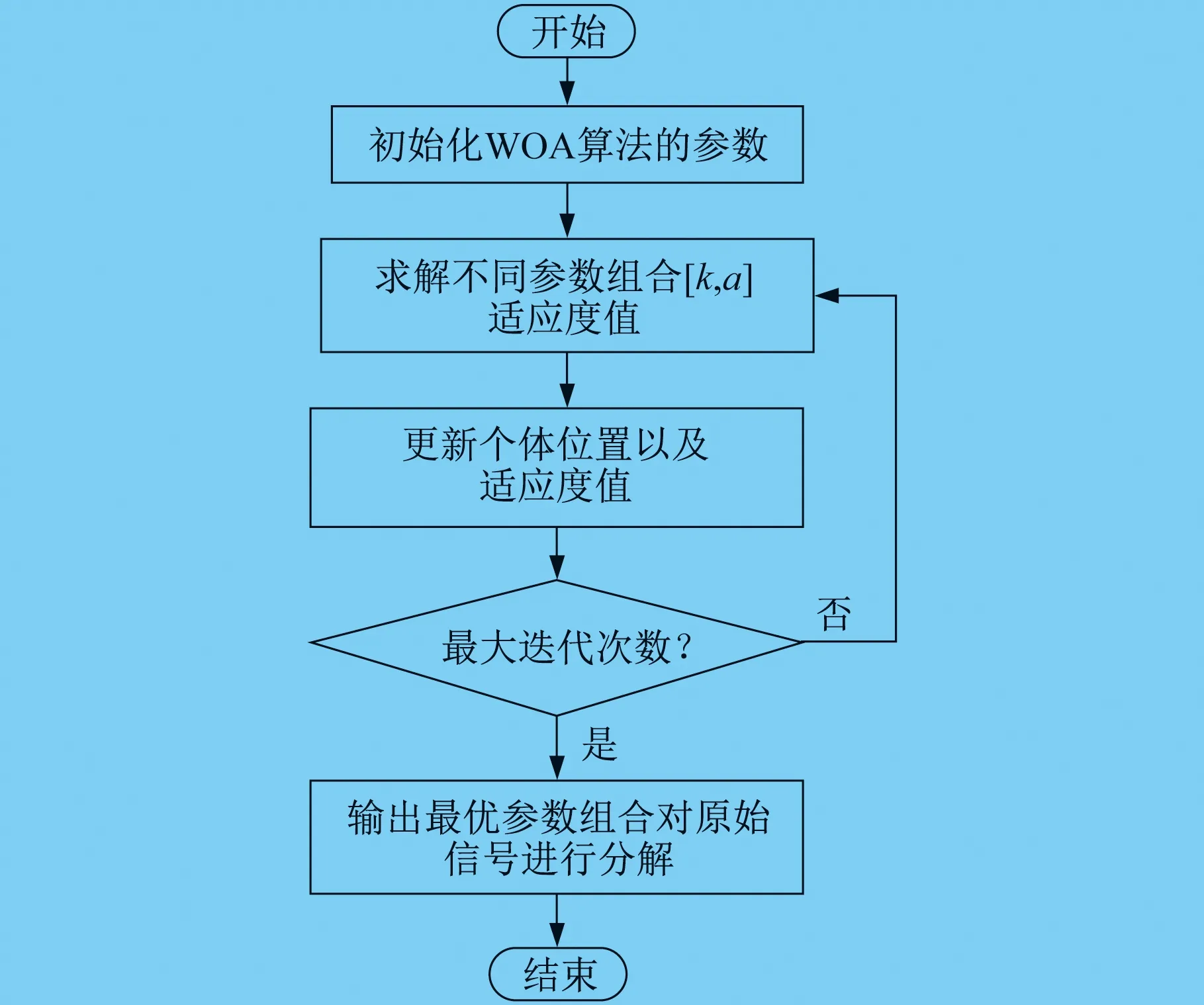
图1 WOA-VMD流程图
求解步骤如下。
(1) 设置WOA算法的初始种群以及参数[k,α]的优化区间,并将包络熵布局最小值作为适应度函数。
(2) 利用VMD对原始信号进行分解,并通过式(15)得到不同参数组合的适应度值。
(3) 利用WOA的寻能机制,不断更新个体的位置,同时比较Ep的值,找出最小适应度值。
(4) 循环(2)~(3)的步骤,当达到最大迭代次数时,输出最佳参数[k,α]。
(5) 将得到的最佳参数组合[k,α]对VMD进行参数设置,并对原始电力负荷数据进行分解。
1.3 麻雀搜索算法及其改进
1.3.1 麻雀搜索算法
SSA是于2020年由Xue等人提出来的一种新型智能优化算法,该算法主要受麻雀捕食和反捕食行为的启发[5]。麻雀集合矩阵如下:
X=[x1,x2,…,xN]T,
xi=[xi,1,xi,2,…,xi,d]
(17)
式中:N——麻雀种群的数量,i=(1,2,…,N);
d——变量的维度。
Fx=[f(x1),f(x2),…,f(xN)]T
(18)
f(xi)=[f(xi,1),f(xi,2),…,f(xi,d)]
(19)
其中,Fx中的每个值表示个体的适应度值。麻雀种群分为发现者、跟随者和警戒者。每次迭代中选取适应度值相对较优的一部分麻雀作为发现者,一般占种群的10%~20%,主要负责带领种群向有食物的地方前进,剩下为跟随者,而警戒者则是在整个种群中随机选取10%~20%。
发现者的位置更新方式如下:
(20)
式中:k——当前迭代次数;j=(1,2,…d);
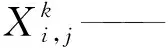
K——最大迭代次数;
R2——预警值,R2∈[0,1];
ST——安全阈值,ST∈[0.5,1];
Q——服从正态分布的随机值;
L——1个内部元素均为1的1×d的矩阵。
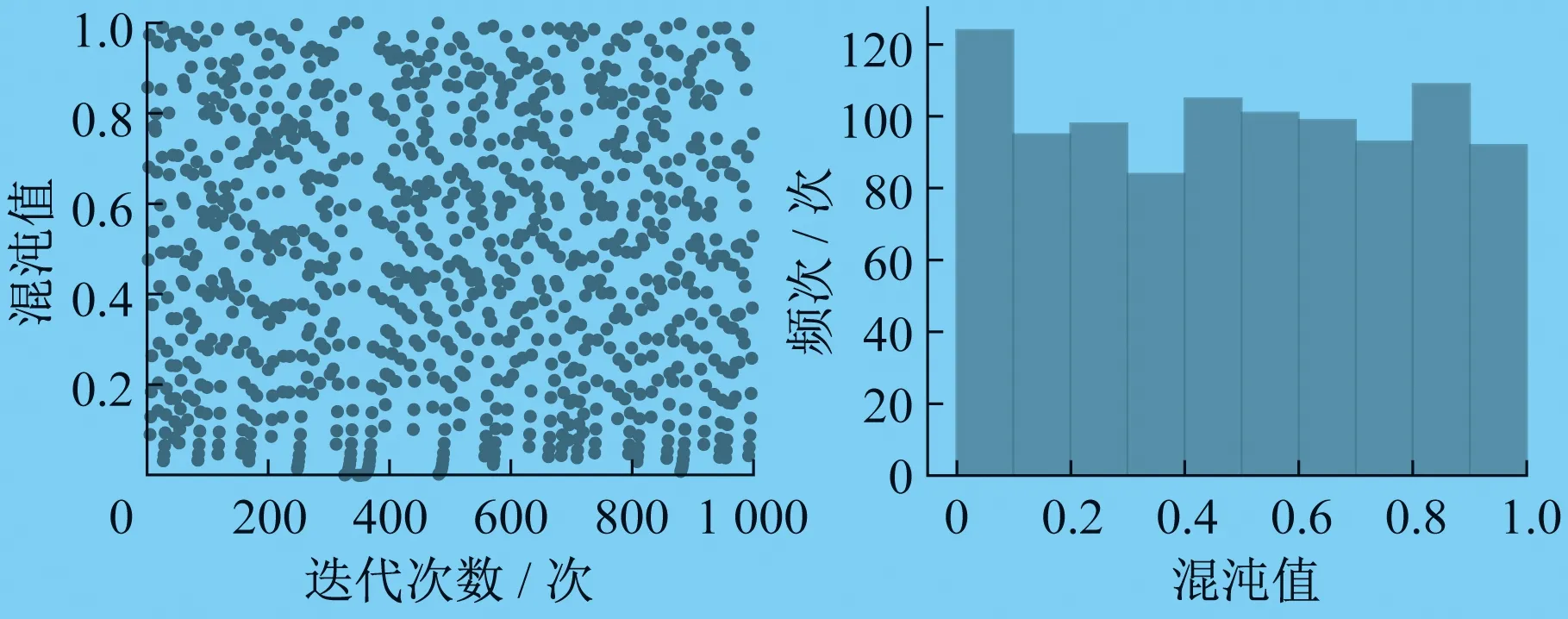
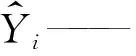
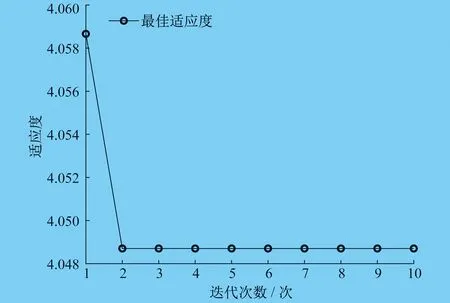
其中,z∈(0,1]中的随机数。当R2 跟随者的位置更新公式如下: (21) 式中:Xworst——当前全局最差的位置; XP——发现者的最佳位置; A——内部元素均为1或-1的1×d的矩阵。 其中,A+=AT(AAT)-1。当i>N/2时,表明第i个跟随者的适应度较差,需要去其他区域寻找食物。 警戒者的位置更新公式为 (22) 式中:Xbest——当前的全局最佳位置; β——麻雀运动的方位,是一个服从正态分布的随机数; fi——当前麻雀个体的适应度值; fg、fw——分别表示当前的全局最优和最差适应度值。 其中,m∈[-1,1]中的随机值。为防止(fi-fw)+ε=0使得分母为0,则将ε定为最小常数,本文设为10E-8。当fi>fg时,表明麻雀个体当前适应度值超过了目前的最优适应度值,麻雀位置处于种群的边缘地带,容易遭遇危险;当fi=fg时,表明麻雀个体当前适应度值为目前的最优适应度值,处于种群中心位置的麻雀察觉到了危险,需要转移到其他麻雀所在的位置。 1.3.2 改进的麻雀搜索算法 麻雀搜索算法在迭代后期会出现种群多样性减少和易陷入局部极值的问题,因此本文引入改进的Tent混沌序列和动态自适应权重对麻雀搜索算法进行改进,改进策略如下。 (1) Tent混沌映射。 由于基本的SSA对种群初始化采用的是随机生成的方式,会导致麻雀种群分布不均匀。混沌映射具有规律性、遍历性等特点,因此本文采用混沌序列对麻雀的位置进行初始化。Logistic映射和Tent映射[6]作为最常用的混沌映射,可以在一定程度上解决种群分布不均匀的问题,提高群智能算法初始解的质量。Logistic混沌序列分布如图2所示。Tent混沌序列分布如图3所示。由图2的Logistic混沌序列分布图可以看出,Logistic映射取值分布在[0,0.1]和[0.9,1]之间的概率较高,存在很大的不均匀性,从而会对算法的寻优效率产生很大的影响。由图3的Tent混沌序列分布图可以看出,相比Logistic映射,Tent映射分布更加均匀,因此本文采用Tent混沌映射对麻雀的初始位置进行初始化。 图2 Logistic混沌序列分布 图3 Tent混沌序列分布 (2) 动态自适应权重。 从发现者的位置更新公式可以看出,在算法刚开始迭代时,发现者就向全局最优解逼近,具有较小的搜索空间,容易陷入局部极值。因此考虑将惯性权重的思想引入麻雀中发现者的位置更新公式中并对其进行改进,即在发现者位置更新方式中引入动态权重因子ω。ω的值与最大迭代次数K和当前迭代次数k有关,并且随着当前迭代次数k的增加而减少。在迭代初期,迭代次数较小时,ω的值则较大,这样便能够很好地进行全局搜索;在迭代后期,迭代次数变大时,ω值则较小,此时便可以很好地进行局部搜索。 同时将上一代的全局最优解引入发现者的位置更新公式中,使得上一代发现者的位置和上一代全局最优解能够同时影响当前发现者的位置,由此便不会出现算法陷入局部最优的问题。权重系数ω的计算公式和改进后的发现者位置更新方式如下所示: (23) (24) rand——0到1之间的随机数。 最小二乘支持向量机是在SVM的基础上进行改进所提出来的机器学习算法,即为改进的SVM[7]。在最小二乘支持向量机处理商业负荷预测这一类回归问题时,通过非线性映射函数φ(·)将原先低维空间中的非线性问题转化为高维特征空间中线性回归,即在高维空间中,对样本的输入输出进行拟合。 y(x)=wTφ(x)+b (25) 式中:w——权值向量; b——偏置量。 定义优化问题时采用结构风险最小化原则,如下式所示: (26) 其中,C为惩罚参数,C的值越高越容易出现过拟合的现象,反之则容易出现欠拟合的现象,因此需要对C进行合理的选择。ei为拟合误差。 为了解决上述优化问题,用拉格朗日函数求解优化问题: b+ei-yi] (27) 其中,αi∈R表示拉格朗日乘子。 根据KKT[8]的条件,对上式进行优化,即对w、b、ei和αi的偏导数等于0,得 (28) 这样,在消除变量w和ei之后,上述优化问题就变为求解线性方程问题,如公式(29)所示: (29) 其中,α=[α1,α2,…,αl],Q=[1,1,…,1],Y=[y1,y2,…,yl]T,I表示单位矩阵,K(xi,xj)表示选择的核函数,定义核函数K(xi,xj)=φ(xi)·φ(xj)满足核函数充要条件Mercer原理,则预测模型可表示为 (30) 式中,αi和b可由式(30)方程求解可得。最小二乘支持向量机的结构图如图4所示。 图4 最小二乘支持向量机结构图 核函数采用的是径向基核函数,公式如下: (31) LSSVM模型的预测性能由惩罚参数C和核参数σ决定,因此本文采用ISSA对这两个参数进行优化。 为了提高商业短期电力负荷的预测精度,本文提出了一种基于WOA-VMD-ISSA-LSSVM的短期电力负荷预测模型。首先考虑采用WOA优化VMD得到最佳参数组合[k,α],并对原始电力负荷数据进行分解,有效减弱电力负荷序列的非线性,提高预测精度;随后考虑构建ISSA-LSSVM预测模型,采用ISSA对LSSVM模型的惩罚参数和核函数进行优化,构建最佳预测模型;最后将经过WOA-VMD分解后的数据输入到ISSA-LSSVM模型中进行预测,并将预测结果进行叠加形成最终预测结果。WOA-VMD-ISSA-LSSVM建模流程图如图5所示。具体步骤如下: 图5 WOA-VMD-ISSA-LSSVM建模流程图 (1) 结合原始电力负荷数据,采用WOA对VMD的参数进行寻优,得到最佳参数组合[k,α]。 (2) 将最佳参数组合[k,α]导入到VMD中,并对原始数据进行分解。 (3) 对分解的k个分量分别构建ISSA-LSSVM模型并进行训练。 (4) 利用训练好的模型对各个分量单独进行商业电力负荷预测,并将每个分量的预测结果进行叠加形成最终预测结果。 为验证所提模型的优势,文章选用了均方根误差(RMSE)、平均绝对误差(MAE)和拟合度(R2)这三个指标作为模型的评价指标。各指标的计算公式如下所示: (32) (33) (34) 式中:S——测试数据样本总数; Yi——真实值; 本文实验数据选自浙江省某商业中心2009年1月1日~6月8日的负荷数据,共计160天数据,时间精度为15 min。将1月1日到6月7日的原始商业电力负荷数据及天气因素作为训练集对模型进行训练,模型训练好之后,将6月7日的数据及6月8日的天气因素输入模型,对6月8日的全天96个时间点的负荷数据(子序列)进行预测,并将预测结果进行相加。其中,ISSA-LSSVM预测模型的输入为前一天的最高温度、最低温度、平均温度、相对湿度、降雨量、96个负荷点(子序列)和预测当天的最高温度、最低温度、平均温度、相对湿度、降雨量,共计206个输入,输出为预测当天的96个负荷点(子序列)。 在使用VMD算法对电力负荷数据进行分解时,WOA种群规模为10,最大迭代次数为10,采用WOA算法确定最优参数k和α,k的优化区间为[2,100],α的优化区间为[10,5 000],最终优化结果k=5,α=814.43。VMD分解图如图6所示。WOA的适应度曲线如图7所示。 图7 WOA适应度曲线 本文将BP、ELM、LSSVM、VMD-LSSVM、WOA-VMD-LSSVM、WOA-VMD-PSO-LSSVM、WOA-VMD-SSA-LSSVM和WOA-VMD-ISSA-LSSVM预测模型的预测结果与真实值进行了对比分析,其中BP模型的迭代次数为100,学习率为0.001,隐藏层单元数量为[10,10];ELM模型隐藏层单元数量为30;LSSVM的参数C和σ的取值分别为10和10;VMD-LSSVM的参数k和α分别取值8和100;PSO、SSA和ISSA的种群规模为10,最大迭代次数为100,学习因子c1=c2=1.5,其余参数见1.3节所示。 实验结果显示,WOA-VMD-ISSA-LSSVM模型的预测结果最接近于真实值。将8个模型预测结果的评价指标值作了对比分析,测试数据误差对比分析如表1所示。由表1可以看出,WOA-VMD-ISSA-LSSVM模型的RMSE和MAE值均为最小,说明该模型预测结果的误差最小;R2值最大,说明该模型预测结果的拟合度最高。综上可知,采用WOA-VMD对数据进行分解之后,将分解后的数据输入到ISSA-LSSVM模型中,预测准确度在一定程度上得到提高。 表1 测试数据误差对比分析 本文提出一种基于WOA-VMD-ISSA-LSSVM的商业短期电力负荷预测模型。为了从原始商业负荷数据中提取信息丰富的信号分量,采用鲸鱼优化算法对VMD的参数进行寻优,构建WOA-VMD分解模型,并采用WOA-VMD对商业负荷数据进行分解,得到最佳的分解子序列。然后针对麻雀搜索算法在迭代后期会出现种群多样性减少和易陷入局部极值的问题,引入了Tent混沌映射和动态自适应权重对麻雀搜索算法进行改进。随后利用改进后的麻雀搜索算法对LSSVM的模型参数进行寻优,建立ISSA-LSSVM预测模型。最后将经过WOA-VMD分解的子序列输入到ISSA-LSSVM模型中得到每个子序列的预测结果,并将预测结果进行叠加得到最终的电力负荷预测结果。实验结果证明了该模型的有效性。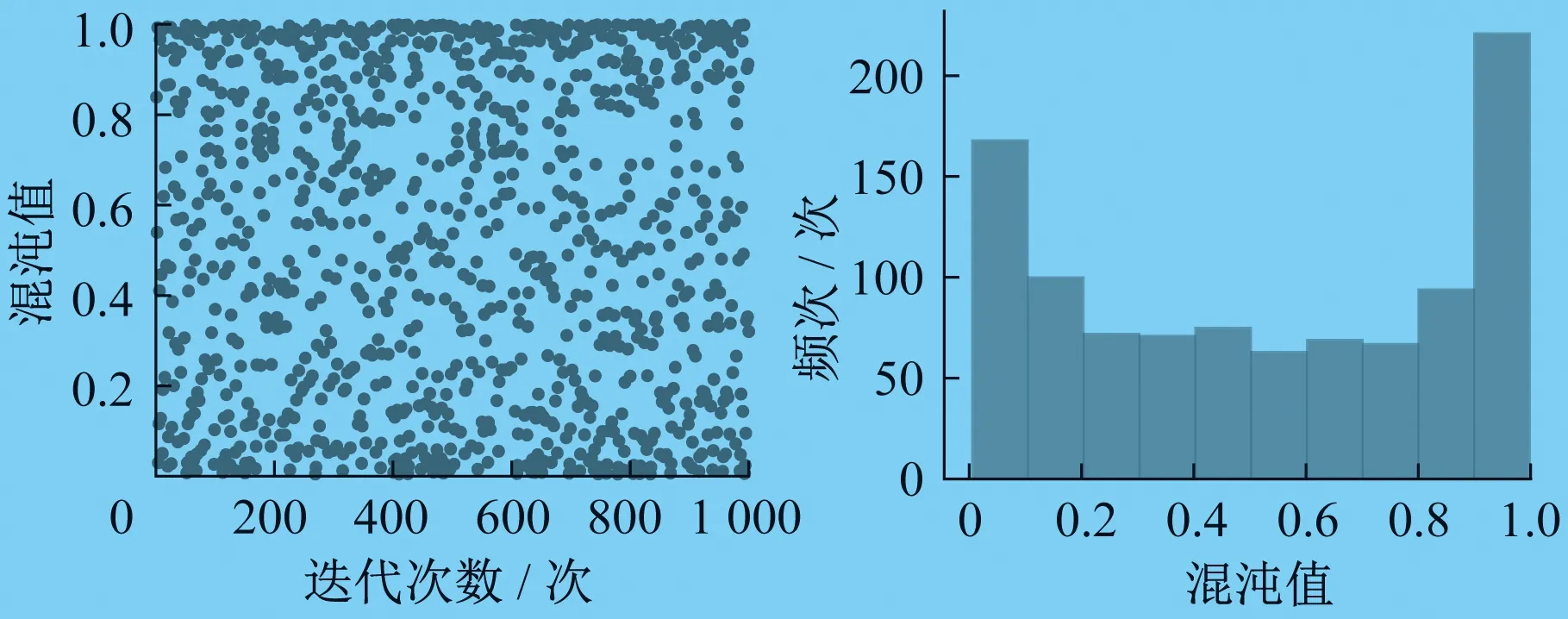

1.4 最小二乘支持向量机

2 模型构建
2.1 WOA-VMD-ISSA-LSSVM模型

2.2 模型评价指标

3 实验验证与分析
3.1 电力负荷数据分解
3.2 实验结果与分析

4 结 语
猜你喜欢
计算机仿真(2022年8期)2022-09-28
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
作文小学中年级(2019年10期)2019-11-04
新世纪智能(高一语文)(2018年11期)2018-12-29
趣味(语文)(2018年2期)2018-05-26
中国塑料(2016年11期)2016-04-16
山东青年(2016年1期)2016-02-28
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
中央民族大学学报(自然科学版)(2014年1期)2014-06-11
