
多尺度特征融合技术在弱信息图像分割的运用
2023-10-21 01:53:44殷梓YINZi
价值工程 2023年28期
殷梓YIN Zi
(南京信息工程大学,南京 210044)
0 引言
近年来随着卷积神经网络的飞速发展,基于全信息学习的语义分割网络在性能上取得了显著的提升。然而语义分割任务所需要的数据标注往往需要耗费大量的人力和时间成本,这成为其技术发展最主要的限制因素,弱信息语义分割方法应运而生,该方法只需类别标签的前提下完成语义分割的任务。本文设计了一个多尺度类激活图学习机制,该机制考虑了类激活图与特征图之间的学习。其机制中的多尺度注意力学习算法将生成不同尺度特征图与原尺寸类激活图学习得到的类激活图。同时,本文还进行了一系列的消融对比研究。实验结果表明,该方法在定性和定量上都优于许多现有模型。总的来说,本文的主要贡献可归纳如下:①提出了一种新的多尺度类激活图学习机制(Multi-scale class activation mapping learning mechanism,MCAM),通过机制进行多尺度类激活图结合。②多尺度注意力学习算法(Multi-scale attention learning algorithm,MA),来提高类激活图中对前景的挖掘能力。
1 网络结构
本文的网络模型如图1,采用了多尺度图片输入,其分别是原尺寸图片,原尺寸图片的0.5 倍,原尺寸图片的1.5 倍,将三种尺寸图片输入进模块1,模块1 将得到对应的一系列类激活图的输出,具体的类激活图生成过程将在本文的下一节进行详细说明。
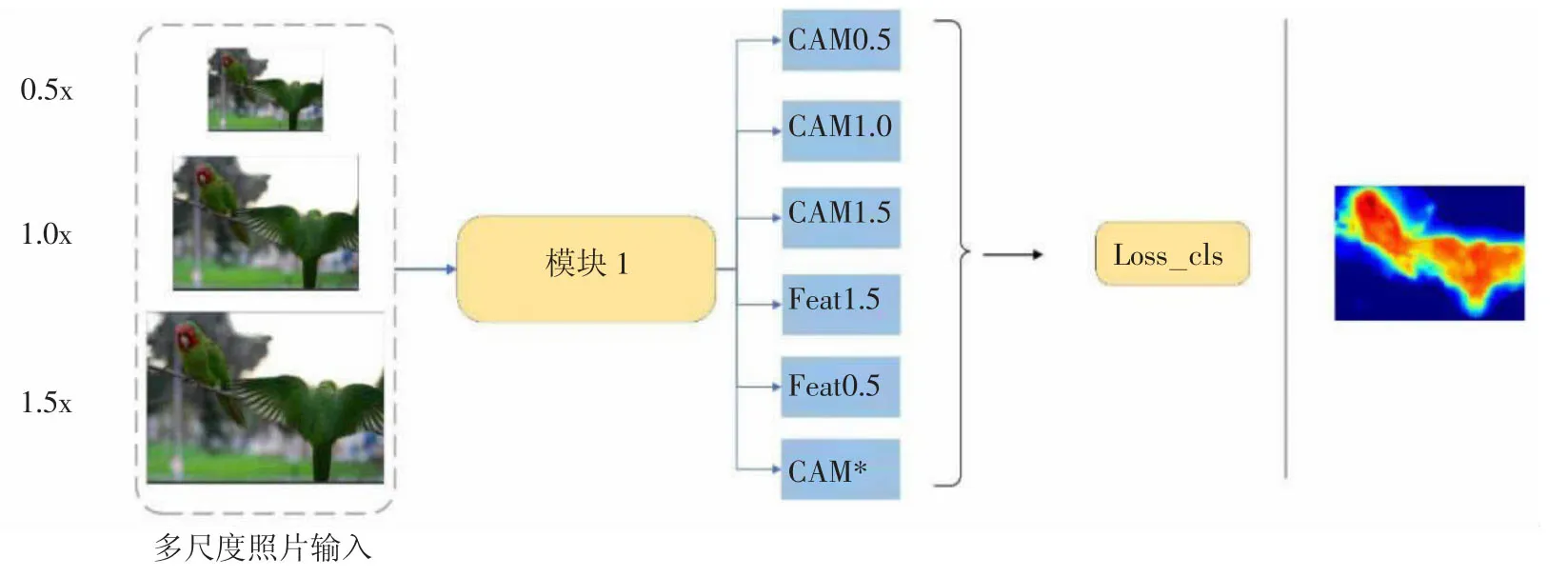
图1 模型结构总示意图
1.1 多尺度类激活图学习机制
特征图与类激活图之间存在的特征信息在弱信息语义分割任务中具有重要意义。本文将进一步利用不同尺度下的特征图与类激活图的信息,故将该模块命名为多尺度类激活图学习机制(Multi-scale class activation mapping learning mechanism,MCAM),结构图如图2 所示。Feature map(1.0х)、Feature map(0.5х)、Feature map(1.5х)分别表示原尺寸产生的特征图、原尺寸0.5 倍产生的特征图、原尺寸1.5 倍产生的特征图。接着,利用分类网络全连接层的权重以类激活图的传统始生成方式生成各尺寸特征图对应的类激活图CAM(1.0х)、CAM(0.5х)、CAM(1.5х),在下分支,如图2 中虚线框所示。将Feature map(0.5х)、Feature map(1.5х)和CAM(1.0х)作为模块2 多尺度注意力学习算法的输入来生成强化CAM*all,再将两者结合生成CAM*all,最后通过融合算法(下文将对其算法进行详细说明)使CAM(1.0х)、CAM(0.5x)、CAM(1.5х)与CAM*all进行有效结合。结合之后的结果为最终的输出。
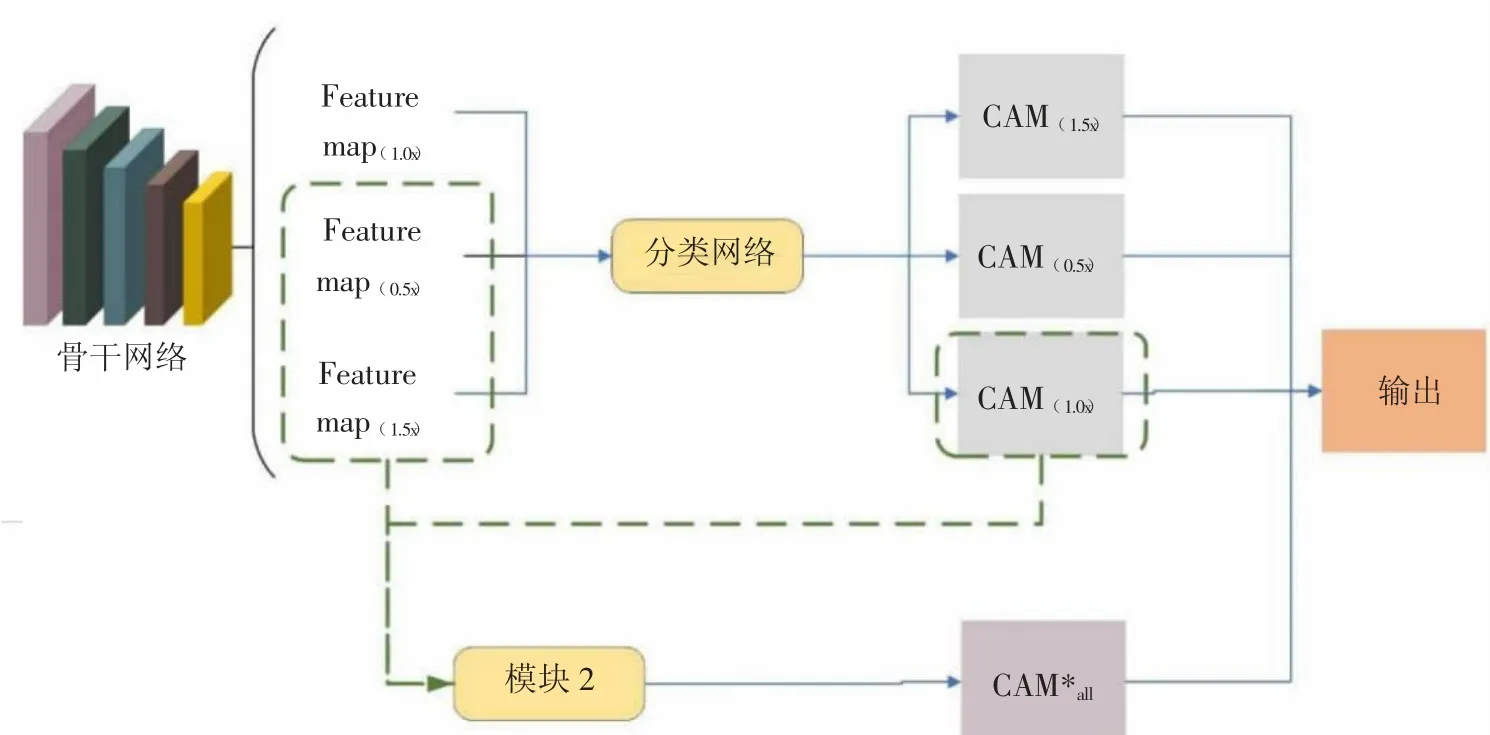
图2 多尺度类激活图学习机制
1.2 多尺度注意力学习算法
本文的模块2 是提出的多尺度注意力学习算法(Multi-scale attention learning algorithm,MA),该模块嵌入在模块1 的整体框架中,用于进行不同尺度之间的特征信息学习。如图3 所示,多尺度注意力学习算法模块(MA)主要是原尺寸的类激活图结果与Feature map(1.5х)进行结合,Feature map(1.5х)与CAM(1.0х)通过卷积g 学习参数,卷积g为1x1 的卷积,最后经过相乘得到CAM*all,该算法利用不同尺寸之间的信息相关性生成增强类激活图,能够更有效地挖掘前景区域。
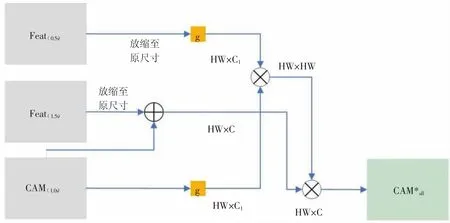
图3 多尺度注意力学习算法模块结构图
2 实验分析
本文的方法主要由多尺度类激活图学习机制(MCAM),多尺度注意力学习算法(MA)组成。本文的分割网络VGG-16[2]在实验前已经由ImageNe 数据集进行了预训练。为了探究各个模块和算法的有效性,在本节将对模型以不同的设置条件下进行实验。本节中的所有模型都是在PASCAL VOC 2012[1]数据集上进行训练的,本小节均以数据集中训练集产生的类激活图与真实标签来进行质量比较,以平均交并比(mean intersection-over-union,mIoU)指标作为判断准绳。表1 显示了多尺度类激活图学习机制(MCAM)的成类激活图CAM*all和融合之后的最终输出在mIOU 指标上的表现。从表1 可以看出得到的类激活图CAM*all要比原始类激活图CAM 的mIoU 提升约7%,最终输出结果要比原始类激活图CAM 的mIoU 提升约8.4%,这表明MCAM 对模型性能都具有一定的提升。
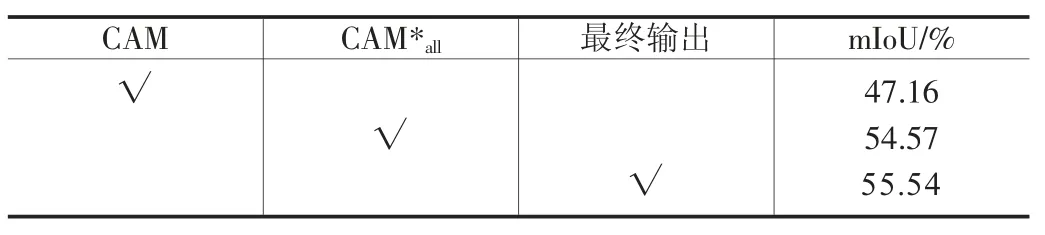
表1 模型各个模块在训练上的性能表现,最佳结果以粗体显示
2.1 多尺度类激活图学习机制实验分析
上一部分通过指标验证了其算法能带来性能的提升,为了进一步证明多尺度类激活图学习机制的有效性,本部分将针对该机制上下分支输出结果CAM*all进行可视化分析,CAM*all如图4 所示,第一行是在单类别目标图像,CAM*all相比于CAM 能够挖掘到更丰富的前景信息,同时对目标的边缘也较为敏感。第二行和第三行是相同图片在不同类别(分别是人和飞机)做出的特征反应。可以发现,CAM*all挖掘到更多背景的同时把部分背景和其他不属于此类的信息挖掘了出来,对结果带来了一定干扰。
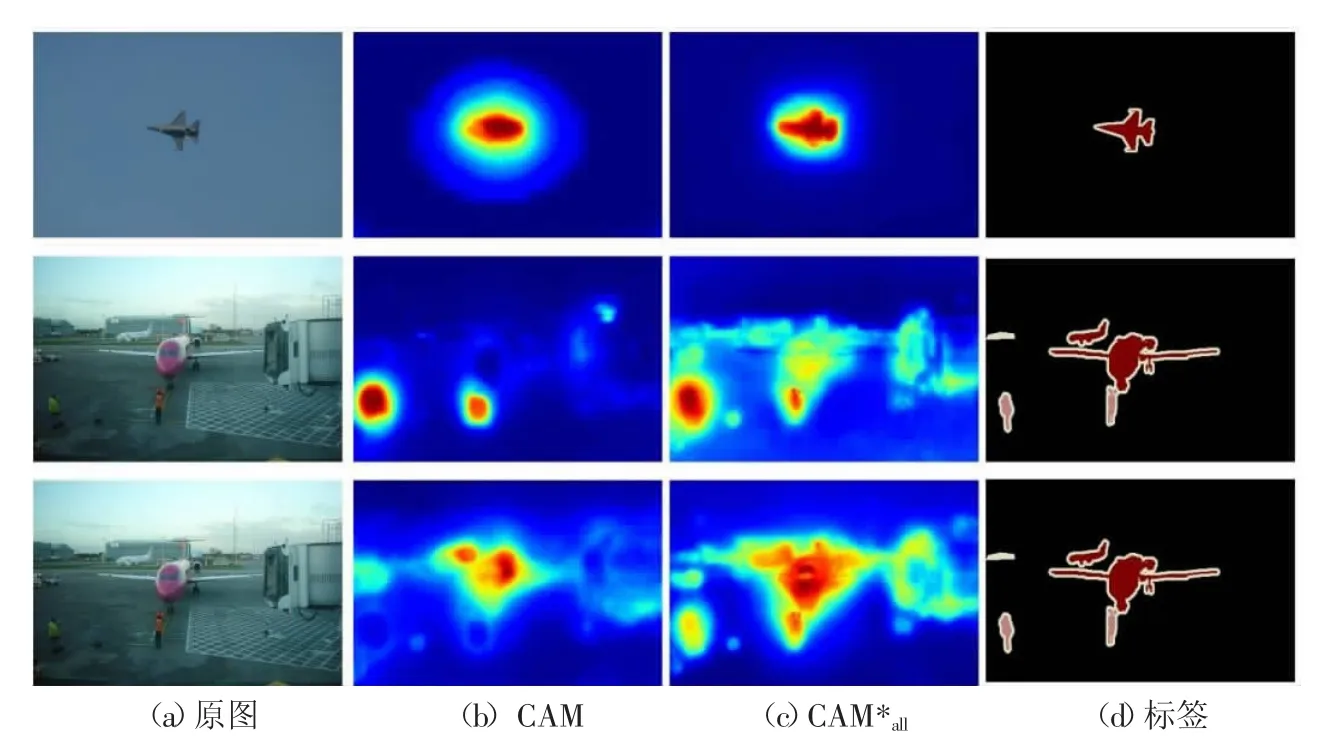
图4
2.2 不同尺度条件下类激活图的性能
本文研究了不同尺度对多尺度类激活图学习机制(MCAM)的影响并寻得最为有效的一组尺度输入。在本文模型结构中,默认输入的多尺度为{0.5,1.0,1.5}这三种尺度。本节例举试验的三种配置(即{0.25,0.5,1}、{0.5,1,1.5}、{1,1.5,2}),其结果在表2 中进行了展示。通过表中指标可以直观发现,b 组{0.5,1,1.5}获得了最好的性能55.54%。a 组组合是全部为缩小尺寸输入其结果要比b组低1.4%,c 组是全部为放大尺寸的输入其结果要比b 组低1.7%。
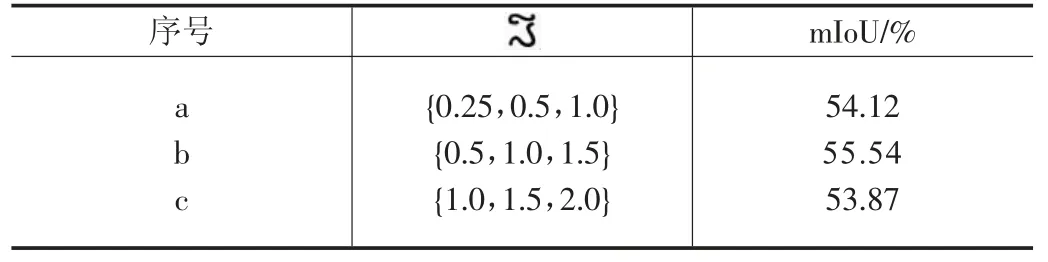
表2 不同尺度组合的性能表现,最佳结果以粗体表示
2.3 与其他实验性能对比
本文提出的弱信息语义分割方法与其他最先进的模型进行了比较,如表3 所示包括MCOF[3]、SeeNet[4]、DSRG[5]、FickleNet[6]、CIAN[7]、EME[8]、MCIS[9]、OAA++[10]、ECS-Net[11]。
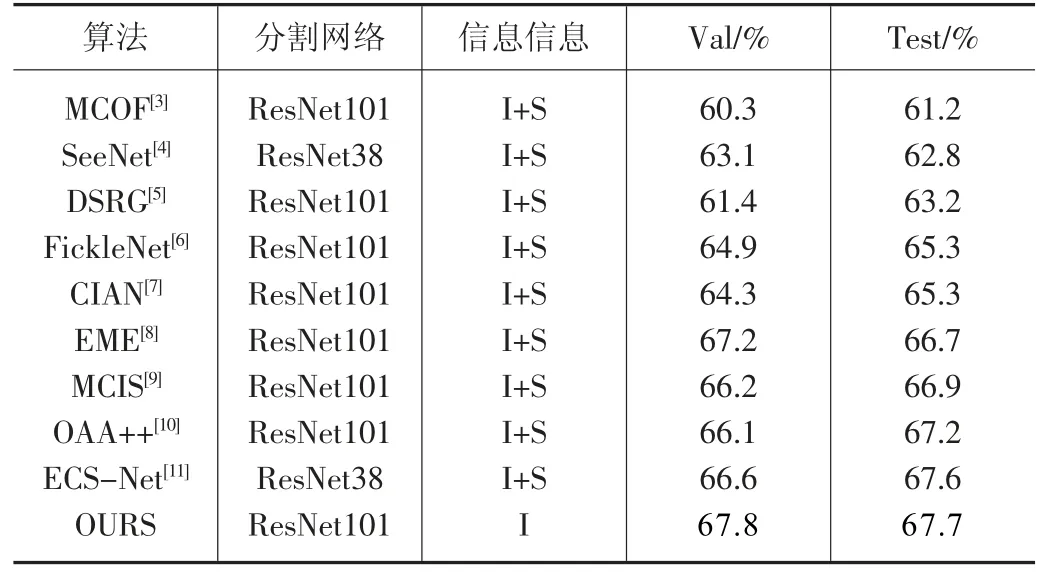
表3 与近年先进算法的对比,最佳结果以粗体表示
为了与各个先进算法模型进行公正的比较,表3 中所有数据均来源公开论文的指标。从表中可发现,本文的方法取得了验证集67.8%,测试集67.7%的指标,在PASCAL VOC2012 数据集[1]的验证集和测试集中都优于近年部分最先进的方法,意味着本文的方法具有更佳的性能表现。
3 结语
本文提出了一种新的用于弱信息语义分割任务的多尺度特征融合网络算法,其算法具有高性能的判别性区域挖掘能力,并使得模型在各种情况下都具有一定的有效性。对于今后的工作,我们将改善在多类别情况下前景挖掘不够充分的问题,并重点研究如何以一种更加轻量化的网络来实施特征的提取,同时保持较高的精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
开放教育研究(2020年2期)2020-03-31 01:54:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
时代英语·高三(2014年5期)2014-08-26 17:01:17
外语学刊(2011年1期)2011-01-22 03:38:33
