
A Model Predictive Control Algorithm Based on Biological Regulatory Mechanism and Operational Research
2023-10-21 03:09:48JinyingYangYongjunZhangTanjuYildirimandJiaweiZhang
Jinying Yang, Yongjun Zhang, Tanju Yildirim, and Jiawei Zhang
Dear Editor,
This letter presents an intelligent model predictive control algorithm inspired by biological regulatory mechanism and operational research.In terms of overall architecture, based on biological regulatory system and operational research theory, priority factor module and central coordination module are innovatively added on the basis structure of heuristic dynamic programming to carry out overall regulation of the system.In internal structure, the neural network is integrated with the biofeedback mechanism, and a new multi-level feedback neural network that can obtain more feedback information is proposed.The network is applied to the model network, action network and critic network of the algorithm.The convergence speed is greatly improved and the predictive control speed for nonlinear timevarying systems is improved on the premise of ensuring the control accuracy.The effectiveness and superiority of the proposed algorithm in prediction and control are verified by experiment.
Related work: With the increasing nonlinearity and timely variation of the process control target, in order to meet the control requirements of complex controlled objects, some control algorithms inspired by computer technology have been developed.In 1978, Testudet al.[1] proposed the model predictive control algorithm (MPC)and established the concept of rolling time domain optimization.MPC have been widely used in various fields due to its good applicability and robustness, scholars from all over the world have produced a variety of MPC.According to the structural model, MPC can be roughly divided into non-parametric model prediction [2], [3],predictive control based on adaptive control theory [4]-[6], and predictive control based on structural design [7]-[10].With the development of science, the increasingly complex controlled objects make it difficult for traditional MPC to accurately control nonlinear and timevarying uncertain system.Zhanget al.[11], [12] combined MPC with other structures, such as neural network and load observer to improve the response speed and robustness of the algorithm.However, these algorithms are still in the theoretical simulation stage and need to be validated in practice.Yanget al.[13] used the distributed MPC to regulate the Yellow River Basin, and the control effect is stable.But, the model needs to set parameters such as river area in advance, which are difficult to measure.Islam applied the MPC to the flood control of Ukai dam in India, and the algorithm could predict the flood and implement the corresponding control strategy [14].Nevertheless, the system model was fixed and was not suitable for time-varying systems.The relevant research on the MPC in the biological regulatory mechanism and operational research has not gained adequate attention, which is one of the current research motivations.The algorithm proposed in this letter does not need to obtain the system’s physical parameters, it only needs the data of the controlled variables and related variables, and over time, the algorithm can update the model to avoid model mismatch.
The main contributions can be summarized as follows.1) A new intelligent MPC, called a biological-inspired intelligent heuristic dynamic programming (Bio-int-HDP), is proposed by integrating biological regulatory mechanisms and operational decision.2) The ultra-short feedback mechanism of the endocrine system and operational decision is innovatively incorporated into a neural network and algorithm’s new modules, its convergence speed and predictive control speed for nonlinear time-varying systems is increased by improving the structure of such neural network and algorithm’s modules.3)The Bio-int-HDP is applied to addressing a real-world challenge-regulating a multi-tributary system.Simulation demonstrates that the algorithm can successfully achieve high-precision, real-time flow controls in the upper tributaries of the Murray River, which provides an effective and accurate flood warning and control method for the flood prone multi-tributary area.
Proposed model prediction control:
Overall structure of algorithm: Considering that the system is controlled by multiple variables, based on the heuristic dynamic programming (HDP), the priority factor module is introduced to optimize the systems control process based on the operational research decision theory, and the priority factor is adjusted based on a biological system’s regulation mechanism.At the same time, inspired by the biological central nervous system, the central coordination module is introduced to make real-time correction to each module according to the deviation between the output value and the set value.The system structure diagram of the Bio-int-HDP is shown in Fig.1.The dotted box part in Fig.1 is the overall structure of the Bio-int-HDP.The model network module acts as the prediction model part of the controller.The action network module and the priority factor module act as the rolling optimization part of the controller.The critic network module acts as the feedback correction part of the controller.At the same time, the central coordination module coordinates the whole system according to the ultra-short feedback mechanism, making the predictive control more rapid, stable and accurate.Structural of multi-level feedback neural network: The traditional neural network only adjusts the parameters through the deviation between the output value and the real value.The feedback data is less, the convergence speed and accuracy of the network is not satisfactory.The ultra-short feedback mechanism of hormone regulation refers to the rapid regulation of gland hormone concentration on gland secretion, which can regulate the secretion of hormone before the regular feedback action.
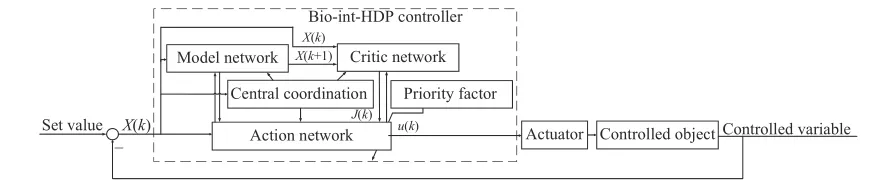
Fig.1.Structure diagram of the Bio-int-HDP predictive control system.
Based on the ultra-short feedback regulation mechanism, the structure of a BP neural network is improved.The structure of the improved network is shown in Fig.2.The improved neural network adds feedback information within and between layers, which enables the network to quickly perceive the internal information and improves the convergence speed and accuracy.In the Bio-int-HDP,the model network module, the action network module and the critic network module all choose the improved biological neural network.
Calculation of the proposed algorithm:
Model network module: The forward calculation of the module is divided into five steps
whereMmis the input variable,Wm1is the weight matrix from input layer to hidden layer,Wm2is the weight matrix from hidden layer to output layer,mh1is the inactive value of hidden layer,mh2is the activated value of hidden layer, andxˆ(k+1) is the pre-output,x(k+1) is the final output,αm1andαm2are the priority factors regulated by the priority factor module, andϑmis the optimization coefficient.

Fig.2.Structure of a three-layer self-feedback BP neural network.
Gradient descent method is used to adjust the weight matrix of the module.The error of the model network module is defined as
whereempis the error between the real value and the predicted value,andxp(k+1) is the real value of the system at the next moment.After forward calculation, the value of the weight matrix is adjusted according to following formulas:
wherelmp∈ (0, 1) is the learning rate of the module.In the process of system operation,lmpwill be regulated in real time by the central coordination module according to different states of the system.
Action network module: The forward calculation of the module is divided into four steps
wherex(k) is the input of the module,Wa1is the weight matrix from input layer to hidden layer,Wa2is the weight matrix from hidden layer to output layer,ah1is the inactive value of the hidden layer,ah2is the activated value of the hidden layer,ûis the pre-output,uis the final output,αa1andαa2are the priority factors regulated by the priority factor module, andϑais the optimization coefficient.
The goal of the module is to minimize the system performance indexĴ, and the gradient descent method is used to adjust the weights.
wherelap∈(0,1) is the learning rate of the module.In the process of system operation,lapwill be regulated in real time by the central coordination module according to different states of the system.
Critic network module: The forward calculation of the module is divided into three steps
wherexis the input,Wc1is the weight matrix from the input layer to the hidden layer,Wc2is the weight matrix from the hidden layer to the output layer,ch1is the inactivated value of the hidden layer,ch2is the activated value of the hidden layer,Jis the performance index andαcis the feedback coefficient of the hidden layer.
The objective function is the error function as follow:
The goal of the module is to minimize the following formula:
The gradient descent method is used to adjust the weights:
wherelc∈ (0, 1) is the learning rate of the module.In the process of system operation,lcwill be real-time regulated by the central collaborative module according to different system states.
Priority factor module: Priority factor module adjusts priority factors according to the importance of each variable, so as to improve the overall control effect of the control system.Priority factor module firstly obtains the average value of each input variable of the module as follow:
“速裁”而不“滥裁”,法律兼顾温情,李凌说:“法槌敲响的那一刻对社会应该有一种警醒和指引,达到法律效果与社会效果的统一。一起案件的审判,不应该仅仅只是为了把人‘关进去’。”
Calculate the variance of each variable
Calculate the covariance of variable and controlled variable
Finally, obtain the correlation coefficient between each variable and the controlled variable
According to the ultra-short feedback regulation rule of biological regulation mechanism, priority factors can be adjusted in real time.
that,
The priority factorsαm1,αm2,αa1,αa2are real-time regulated along with system control according to (29)-(35).
Central coordination module: In the traditional HDP, the learning rates are fixed values selected by experience.However, learning rate has the corresponding optimal value according to the different state.Based on the regulation mechanism of biological hormone secretion,the central coordination module adjusts the learning rate according to the control deviation of the control system, so as to improve the overall control effect.
whereαis the difference between the output value of action network module and the set value,βmis the basic learning rate of model network module andamis the constant coefficient of model network module learning rate.f(α) can be written as
so that,
whereδ1is constant whenα≥ 0, andδ2is constant whenα< 0.
The learning rate of critic network modulelccan be written as
wheref(α) is shown in (37),βcis the basic learning rate of the critic network module,αcis the constant coefficient of the critic network module learning rate.
The learning rate of action network modulelacan be written as
υ1is constant whenρXᵢY≥ 0, andυ2is constant whenρXᵢY< 0.
wheref(α) is shown in (37),βais the basic learning rate of the action network module,aais the constant coefficient of the learning rate for the action network module.
An illustrative example: In order to verify the predictive control effect of the Bio-int-HDP in a nonlinear time-varying system, the upper tributaries of the Murray River as shown in Fig.3 is selected as the research objects.

Fig.3.Simplified diagram of relationship between rivers.
After pretreatment of relevant watershed data, six groups of data were selected as input based on correlation coefficients: the flowBc(k-1) and levelBcl(k-1) of Bringenbrong, the flowPc(k-1) and levelPcl(k-1) of Pinegrove, the flowJc(k-1) and levelJcl(k-2) of Jingellic.The flowJc(k) was selected as output.A total of 3000 sets of data were selected as training data, and 300 sets of data were selected as test data.The flow prediction curve is shown in Fig.4,and the comparison of flow prediction is shown in Table 1.It can be seen that compared with the Bio-int-HDP, both self-feedback BP and BP have a large deviation in predicting the flow.The above results show that the prediction model in the algorithm can predict the future flow well and meet the requirement of predictive control.
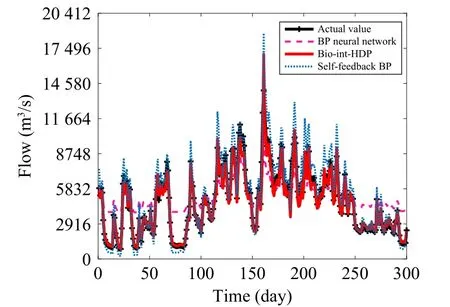
Fig.4.Comparison of prediction effect.

Table 1.Comparison of Flow Prediction
In this letter, Bio-int-HDP is compared with internal model control(IMC) and HDP.The results are shown in Fig.5.The end of the algorithm optimization process should satisfy one of the following termination criteria.1) The iteration number has reached the maximum generation number.2) The fitness value of global best solution is smaller than the set value, which is called iteration convergence.Based on the above termination criteria, the training time of the three algorithms is statistically analyzed under the same termination criteria.In order to eliminate the data contingency, the single point training time of three algorithms was carried out for 50 simulation experiments, and the averaged results are shown in Table 2.
It can be seen that the Bio-int-HDP responds quickly to the predictive control requirements of complex time-varying systems and is regulated in a timely manner.Therefore, Bio-int-HDP is a new intelligent algorithm superior to traditional MPC.
Conclusions: This letter proposed a model predictive control algorithm based on biological regulatory mechanism and operational research decision, called Bio-int-HDP.The structure of the neural network and HDP is improved by introducing a biological regulation theory and operational research decision theory.Experimental results show that the Bio-int-HDP can respond quickly to the predictive control requirements of complex time-varying systems and regulate in a timely manner.The algorithm has potential in flood warning and control since Bio-int HDP has higher prediction and control accuracy in multi-tributary watershed flow prediction and control.Due to the complexity of the actual system and difficulty in obtaining data,future research will focus on methods to reduce the amount of data and the complexity of controlled objects while ensuring the high accuracy and applicability of the algorithm.

Fig.5.Comparison of control effect.

Table 2.Comparison of Forecast Controller’s Training Time
Acknowledgments: This work was supported by the National Natural Science Foundation of China (U21A20483).
猜你喜欢
中国美术(2021年4期)2021-10-30 19:23:57
法大研究生(2020年1期)2020-07-22 06:06:10
方圆(2019年20期)2019-02-16 14:51:00
法大研究生(2017年1期)2017-04-10 08:55:26
山西省政法管理干部学院学报(2016年2期)2016-07-31 18:19:25
公民与法治(2016年18期)2016-05-17 04:17:50
政法论丛(2015年5期)2015-12-04 08:46:28
小说月刊(2015年10期)2015-04-23 08:51:45
小说月刊(2014年1期)2014-04-23 09:00:01
小说月刊(2014年4期)2014-04-23 08:52:25
 IEEE/CAA Journal of Automatica Sinica2023年11期
IEEE/CAA Journal of Automatica Sinica2023年11期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Multi-Objective Optimization for an Industrial Grinding and Classification Process Based on PBM and RSM
- Containment-Based Multiple PCC Voltage Regulation Strategy for Communication Link and Sensor Faults
- GraphCA: Learning From Graph Counterfactual Augmentation for Knowledge Tracing
- Adaptive Graph Embedding With Consistency and Specificity for Domain Adaptation
- The ChatGPT After: Building Knowledge Factories for Knowledge Workers with Knowledge Automation
- An Optimal Control-Based Distributed Reinforcement Learning Framework for A Class of Non-Convex Objective Functionals of the Multi-Agent Network