
基于隐马尔可夫模型的在线视频个性化推荐研究
2023-10-19 11:00王新武
数字通信世界 2023年9期
王新武
(大连财经学院,辽宁 大连 116000)
0 引言
隐马尔可夫模型(HMM)是由Baum等人于1966年率先提出来的[1]。HMM是马尔可夫模型的延伸,是一个概率模型,可以用来预测序列问题。HMM最早应用于语音识别中,并获得了巨大的成功,之后被广泛应用于模式识别、图像识别、生物信息科学、故障诊断等领域,取得了可喜的成绩[2]。随着研究的深入,HMM的应用也越来越广泛。
1 隐马尔可夫模型建模
下面是以解码问题为例的隐马尔可夫模型建模过程:
(1)状态集:定义一个状态集合G={G1,G2,…,Gn}
(2)转移集:每个状态转移元素集合(gi→gi+1)
(3)观察集:输出的观察符号集:
从g1开始,转移到新的状态gi,可以观测到一个输出符号σi。经过转移到最终状态,会得到一个符号串:H=h1,h2,…,h i。每一个状态转移对应的概率为P(gi→gi+1)。在任意状态观测到特殊符号的概率P(H|g)。在一个隐马尔可夫模型O上,序列H被观测到的概率是所有可能路径的概率和,如式(1)所示:
建立隐马尔科夫模型的目的就是找到能使观察概率达到最大的状态序列Q(H|O),如式(2)所示:
HMM用图形表示如图1所示。

图1 HMM图形
任意时刻状态序列的产生:序列在某时刻的状态是a1,在该状态下得到的观察值是e1,从a1转移到a2,在a2状态下得到观察值e2。按照此种方法,会得到一个观察值序列E={e1,e2,…ei,…,et}。因为在任意时刻产生的观察值e只依赖于状态值a,所以可以得到在a状态下出现e观察值的概率为所有时刻状态转移概率和观测概率的乘积,
2 隐马尔可夫模型应用
(1)个性化推荐:基于隐马尔可夫模型的偏好进化学习和高维数据稀疏问题处理[3]。解决高维数据稀疏问题和因用户偏好学习困难而难以高效反应用户的个性化需求的问题,从而突破上下文感知推荐系统的应用瓶颈。利用评分分组,构造转移矩阵和观察矩阵。为防恶意刷分引入权重因子,完成隐马尔可夫的建模。
(2)文本分类:通过提取文本中的特征词、特征词频、文档数量、特征词语义等信息,利用信息增益的方法进行特征词的合并和分类,通过分类分别建立隐马尔可夫分类模。新文本的分类则是通过分类向量的交集,作为观察序列输入隐马尔可夫模型,预测各分类输出的概率,以概率大小作为分类标准[4]。
(3)舆情分析:以微博为平台,考虑微博用户的个人特征、感情走向,以具体的行为表现等为观察序列,以及舆情的发展、波动消亡等为状态序列,建立隐马尔可夫模型,预测和预警舆情的发展和一般规律,为最终决策提供科学高效的方法[5]。
(4)智能学习:假设用户拥有良好的学习习惯和效果,需要从用户的学习序列中找到一个最优的学习序列引导学习的目的。建立隐马尔可夫模型,对模型进行训练,寻找知识点间的关联概率,利用模型预测知识点的迁移序列,找到最优的状态序列,智能引导用户学习,提升用户的学习效率和学习效果[6]。
(5)时间序列预测:假设一系列的隐状态构成了一个时间序列,隐状态间的转换构成系统运行的根本。对时间序列分段后,根据先后发生的时间顺序和发生时间的相似性等进行聚类,以分类为隐含状态得到状态转移矩阵,建立隐马尔可夫模型,进行时间序列的预测。
3 基于隐马尔可夫模型的在线视频个性化推荐实现过程
3.1 模型参数准备
以在线视频的评分为状态序列,评分对应的视频内容即为观察序列。用户某一次对在线视频内容的评分只与前一次的评分有关,与下一次无关,所以用户的评分行为符合隐马尔可夫随机过程。
3.2 隐马尔可夫模型训练
利用无监督的学习法(EM算法),训练集中t时刻使用并给出所得到评分的用户观察集Y={Y1,Y2,Y3,…,Yt},隐含的状态序列X={X1,X2,X3,…,Xt},通过对训练集参数的训练,得到基于隐马尔可夫最大概率,即P(Y|λ)。训练方法如下[7]。
①根据向前-向后算法(训练HMM的标准算法是向前-向后算法(Forward-backward Algorithm)或者叫作鲍姆-韦尔奇算法(Baum-Welch algorithm),这是期望最大化(Expectation-Maximization algorithm,EM算法)的一种特殊情形),定义一个在T时刻处于状态i的前向变量概率是(i),如果T+1时刻的状态为j,根据前向算法,则有公式(3):
②根据向前-向后算法,定义一个在T时刻状态是Si的后向变量概率是ηT(i),代表如果T+1时刻到t时刻观察到序列Y={Y(T+1)Y(T+2)…Yt}的概率,根据向后算法则有公式(4):
③采用向前-向后算法完成计算后,计算P(Y|λ)见公式(5):
④假如已知某刻T的在线视频概率变量σT(i,j)。代表在这一时刻T对在线视频内容的Yi的评分是Si,在下一时刻T+1时刻对视频Yi+1的评分是Sj的概率,其中(1≤I,j≤m, 1≤T≤t)。把式(3)~(5)带入式(6)可得:
⑤假如已知用户在T时刻的在线视频概率变量是T(i,j)(1≤I,j≤m, 1≤T≤t),代表在T时刻在线视频Yi的评分是Si的概率。把式(3)~(5)代入式(7)可得:
⑥根据步骤④和⑤,得到Si转移得到Sj状态的期望值。评分值期望如式(8)所示:
由于Si转移到Sj状态的期望可以计算的出,那么Si转移到其他状态的方法也可以得到,如式(9)所示:
3.3 获取观察值序列
用户在视频网站上观看视频和评分的信息通过观看时间戳的方式记录,通过观看评分记录可以从中提取一个在线视频评分路径转移序列。定义该序列为A={a1,a2,a3,…,an}。假如用户选择评分的在线视频资源都是用户喜欢的内容,那么用户选择评分的某在线视频中必然存在某些吸引用户的信息,而吸引用户选择观看并评分的信息就可以定义为该用户的兴趣点。通过一系列的用户浏览记录,就可以提取用户的兴趣集。这个兴趣集就是隐马尔可夫模型“隐”的内涵。通过挖掘用户的兴趣集当中兴趣点并进行加权,找出符合用户兴趣点权重的视频内容,推荐给该用户,那么就可以获得好的用户体验。
用户在评分转移的过程中,每一个评分对应一个视频内容。而用户评分对应的在线视频内容就是隐马尔可夫模型的观察值,获得观察序列E={e1,e2,e3,…,en},观察序列示意如图2所示。
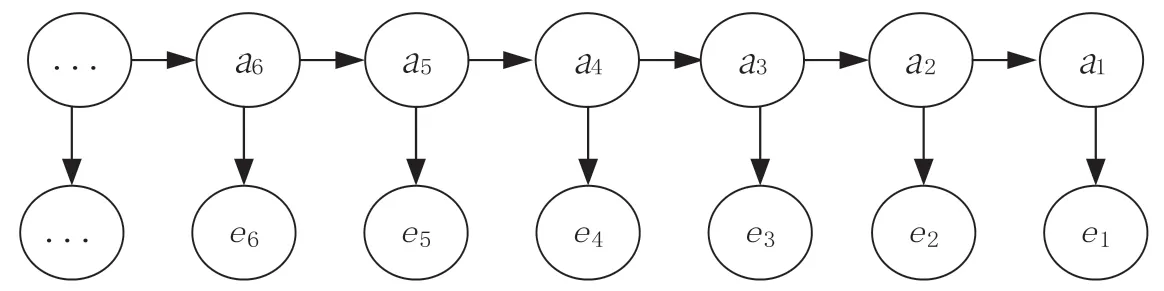
图2 观察值序列
3.4 关键字提取
在线视频网站上的某个视频内容简介,就是对该视频内容的简单概括,如图3所示。

图3 豆瓣网站图片
图3中展示的是豆瓣网站上电影《流浪地球》的页面截图,从图中可以发现每部电影的简介信息结构相同,但页面的关键字不同,用户选择观看电影会根据电影简介的关键字进行选择,喜欢科幻或灾难题材电影的用户可能会选择观看《流浪地球》。假设不同用户因为自己的喜好不同而选择不同,那么用户最终选择观看影片的出发点可能就是网页中不同的关键字。
一部电影的简介页面中包含多个关键字,那么一部电影可以用一个关键字集合来表征,用户最终所选择观看的某部电影,决定因素可能就是因为被某个电影中的关键词吸引。为了找到用户的兴趣关键词,决定采用Python定向爬取网站关键词信息的方式实现,具体步骤如下:
①确定爬取的目标信息。因电影简介页面的标准化程度较高,所以决定定向的爬取有用的特征词信息,建立兴趣关键词集。这里需要爬取的特征词主要包含:电影名,电影上映时间、评分、导演、演员、产地、语言、影片类型等信息。建立一个特征词集,F={f1,f2,f3,…,fn},fi(i表示自然数1…n)则表示视频网站上爬取的一个特征词,n表示特征词的数量。
②特征词出现的频率计算:采用爬取后的信息建立起的特征词集即为当前影片的表征形式。由于电影的结构化程度较高,关键词的使用频率较固定,所以用户如果只存在观看了一部影片记录,那么并不能发现该用户的关键词兴趣。所以需要用户的一系列的浏览记录集,建立一个多事务(观看的影片)的关键词集。通过观看记录关键词的提取计算,才能发现用户真正感兴趣的关键词。计算公式如下:
式中,Q1、Q2、Q3、Q4、Q5、Q6代表调整系数。
计算完特征词的出现频率,就可以算出每个特征词对该用户的权重值。计算公式如下:
通过公式(4)~(10),可以计算出每个特征词对该用户的兴趣权重,根据该权重就可以计算出该用户的对任何一部电影的感兴趣的概率,根据概率值得大小既可以预测该用户最可能感兴趣的视频资源。
豆瓣电影网的结构化的数据可以利用Python进行爬取。
3.5 三级推荐目标实现
基于隐马尔可夫模型的在线视频个性化推荐的最终目标是满足不同类型用户的使用需要。第一层级的个性化推荐:非注册用户的个性化推荐,主要解决的问题是非注册用户的冷启动问题。第二层级的个性化推荐:注册新会员用户的个性化推荐,解决的问题是新用户的用户稀疏问题。第三层级的个性化推荐:针对网站的资深会员用户的在线视频个性化推荐服务,提升用户的使用满意度。
3.6 模型实验结果
3.6.1 第一层级的个性化推荐结果(表1)

表1 第一层级的个性化推荐输出结果
3.6.2 第二层级的个性化推荐结果(表2)
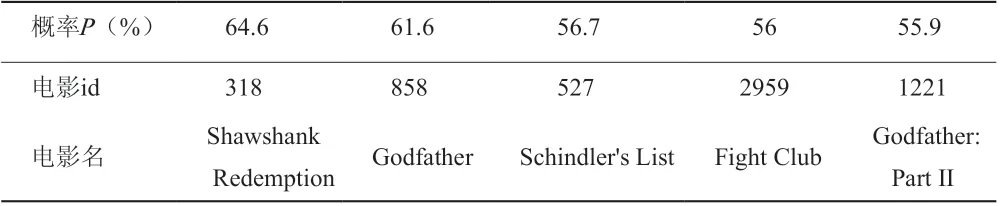
表2 第二层级的个性化推荐输出结果
本层的数据结果本应是6个不同年龄段的输出结果,但由于数据集中的年龄数据是随机生成的,而随机生成的数据对于各年龄段的输出结果几乎没有差别,所以本输出结果只对其中一个输出结果进行展示。
3.6.3 第三层级的个性化推荐结果(表3)

表3 第三层级的个性化推荐输出结果
表3是基于隐马尔可夫模型的个性化推荐结果展示,模型输出7 120个结果,本文只截取前5个结果作为展示。由表3可以发现,前5个用户的兴趣关键词各不相同,所得到的推荐电影也各不相同,得到相应预测评分的概率也相差较大。但各自获得相应预测评分的概率都是在各自兴趣关键词集中概率最高的结果。第三级个性化推荐完成。
4 结束语
基于对大型视频网站用户的观看记录数据的采集,建立基于隐马尔可夫模型的个性化推荐系统。推荐分成三个推荐层级,分别针对不同的用户类型,解决了不同用户的实际需求,并提出用户兴趣时间阈值观念,适时地满足用户的个性化需求,为在线视频网站的发展奠定基础。■
猜你喜欢
小学生必读(中年级版)(2020年6期)2020-08-29
计算机技术与发展(2018年8期)2018-08-21
家庭影院技术(2018年6期)2018-07-17
中国机械工程(2017年22期)2017-12-02
数学理论与应用(2016年3期)2016-05-17
电视指南(2016年1期)2016-01-18
核科学与工程(2015年3期)2015-09-26
中文信息学报(2015年4期)2015-04-21
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
创业家(2015年1期)2015-02-27
