
基于知识蒸馏与目标区域选取的细粒度图像分类方法
2023-10-18 00:46:12赵婷婷高欢常玉广陈亚瑞王嫄杨巨成
计算机应用研究 2023年9期
关键词:深度学习
赵婷婷 高欢 常玉广 陈亚瑞 王嫄 杨巨成


摘 要:细粒度图像分类任务由于自身存在的细微的类间差别和巨大的类内差别使其极具挑战性,为了更好地学习细粒度图像的潜在特征,该算法将知识蒸馏引入到细粒度图像分类任务中,提出基于知识蒸馏与目标区域选取的细粒度图像分类方法(TRS-DeiT),能使其兼具CNN模型和Transformer模型的各自优点。此外,TRS-DeiT的新型目标区域选取模块能够获取最具区分性的区域;为了区分任务中的易混淆类,引入对抗损失函数计算不同类别图像间的相似度。最终,在三个经典细粒度数据集CUB-200-2011、Stanford Cars和Stanford Dogs上进行训练测试,分别达到90.8%、95.0%、95.1%的准确率。实验结果表明,该算法相较于传统模型具有更高的准确性,通过可视化结果进一步证实该算法的注意力主要集中在识别对象,从而使其更擅长处理细粒度图像分类任务。
关键词:细粒度图像分类; 知识蒸馏; Transformer; 深度学习
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2023)09-048-2863-06
doi:10.19734/j.issn.1001-3695.2022.12.0809
Fine-grained visual classification method based onknowledge distillation and target regions selection
Zhao Tingting, Gao Huan, Chang Yuguang, Chen Yarui, Wang Yuan, Yang Jucheng
(College of Artificial Intelligence, Tianjin University of Science & Technology, Tianjin 300457, China)
Abstract:Fine-grained visual classification (FGVC) is extremely challenging due to the subtle inter-class differences and the large intra-class differences. In order to learn the embedded features of fine-grained images efficiently, this paper attempted to introduce the idea of knowledge distillation to FGVC, and proposed TRS-DeiT, which was equipped with the common advantages of CNN models and Transformer models simultaneously. Besides,it proposed a novel target regions selection module in TRS-DeiT to obtain the most discriminative regions. It employed a contrastive loss function that measured the similarity of images to distinguish the confusable classes in the task. Finally, it demonstrated the effectiveness of the proposed TRS-DeiT model on CUB-200-2011, Stanford Cars and Stanford Dogs datasets, which achieved the accuracy of 90.8%, 95.0% and 95.1% respectively. The experimental results show that the proposed model outperforms the traditional models. Furthermore, the vi-sualization results further illustrate that the attention learned by the proposed model mainly focuses on recognizing objects, thus contributes to fine-grained visual classification tasks.
Key words:fine-grained visual classification; knowledge distillation; Transformer; deep learning
0 引言
在計算机视觉中,图像分类是一个基础问题,无论在学术界还是工业界都有着广泛的研究需要和应用场景。根据图像粒度不同,图像分类可划分为粗粒度图像分类和细粒度图像分类。粗粒度图像分类即传统意义的图像分类,如猫和狗属于不同种类,在类别间存在的类间差距是相当明显的。对比粗粒度图像分类,细粒度图像分类聚焦于区分相同大类中多个附属子类下的不同对象[1],如区分狗的品种[2]、车的款式[3]等。类间差别小和类内差别大的特点使得细粒度图像分类更具挑战性。细粒度图像分类实例如图1所示,该图表示视觉上相似的狗,其中每行表示一个种类,要识别的对象会受到背景、光照、遮挡、对象的姿态等因素的干扰,从而进一步加大了细粒度图像分类的难度。为了解决上述问题,大量基于深度学习的细粒度图像分类方法被提出来,主要分为强监督方法[4~7]和弱监督方法[8~15]两大类。强监督方法依赖额外的手工信息比如标注框(bounding box)、部分信息注释(part annotation)来获得识别对象的位置和大小,这有助于提高部分特征与全局特征的关联,进而产生更好的分类效果。然而,由于获取这些标注信息的代价十分昂贵,从某种程度上限制了这类方法的实际应用。弱监督方法只利用图像级别的注释指导模型学习,即图像标签,无须手工注释信息就能自动学习到区分性区域特征,且在性能上逐渐超过了强监督学习方法,因此,弱监督方法逐渐成为细粒度图像分类领域的主流方法。
根据模型框架的不同,弱监督方法可划分为基于CNN(convolutional neural network)的方法[8~12]和基于Transformer的方法[13~15]。基于CNN的方法常用的典型骨架网络有ResNet[16]、DenseNet[17]等。这些骨架网络的CNN过滤器被视做局部描述器,具有局部性和空间性两个属性,能学习图像的局部区域并编码空间信息。在基于CNN框架的基础上,现有细粒度图像分类方法通过注意力机制作为子模块来寻找最具区分性区域,提出了RA-CNN[10]、MA-CNN[18]、PA-CNN[19]方法。然而,上述方法都存在定位区域过大、涵盖背景等干扰信息的问题,且在数据集规模较小的情况下,注意力机制容易过拟合[1]。在基于Transformer的方法中,Transformer结构的自注意力模块具有捕获长距离依赖的能力,能够在最初的几层里定位到图像的细微区别和空间关系[14],并且Transformer的残差连接结构能够有效地将图像特征从网络的较低层传递到较高层[20],因此,Transformer自身结构更适用于细粒度圖像分类任务,使得基于Transformer的方法成为此领域的新兴方法。通常,基于Transformer的方法使用ViT[21]作为其骨架网络,然而,ViT的局限性在于不能同时兼顾CNN方法和Transformer方法的优点来更全面地学习细粒度图像特征。
DeiT[22]模型借助知识蒸馏能实现同时结合CNN方法和Transformer方法的优点,且在粗粒度图像分类任务中获得巨大成功,然而其在细粒度图像分类任务中的表现尚未被探索。
受此启发,本文首次将DeiT模型应用在细粒度图像分类领域,提出基于知识蒸馏与目标区域选取的细粒度图像分类方法(DeiT based on target regions selection,TRS-DeiT)。具体地,本文首先使用细粒度图像分类模型TransFG[14]和CAL[12]分别作为教师模型指导DeiT模型做特殊领域数据集的任务;其次,为了找到最具区分性区域,提出新型目标区域选取模块,其在注意力权重上利用综合性策略充分考虑令牌间的关系。为了区分图像中的易混淆类,本文提出利用对抗性损失函数学习图像间的相似度[14]。最后,通过大量任务集验证本文模型的有效性。本文首次探索将DeiT模型用于细粒度图像分类任务上的蒸馏方法;提出新型目标区域选取模块(target regions selection module,TRSM)用来选取最具区分性的区域,并且能够去除无关和干扰区域。
1 相关工作
细粒度图像分类领域的主要方法包括基于CNN的方法和基于Transformer的方法。基于CNN的方法是经典的主流方法,基于Transformer的方法是近年来应用在细粒度图像分类中相对较新的方法。本章将详细介绍这两类算法。
1)基于CNN的方法 传统细粒度图像分类方法需要如标注框、部分注释等额外辅助信息帮助模型学习图像特征。如Part-based R-CNN[7]借助R-CNN算法在对象层面和局部区域检测细粒度图像,其需要依赖标注框和部分注释。PS-CNN[5]方法和Mask-CNN[6]方法同样需要额外标注信息完成特征学习。此类学习方法被划分为强监督方法。然而,由于获取注释信息费用昂贵,强监督方法在实际应用中就受到了限制。目前,细粒度图像分类的一个明显趋势是当模型训练只用到图像级别的信息而不再使用额外标注信息时也能够取得与强监督方法相当或者更高的分类准确率,即弱监督方法。Attention for FGVC[23]是基于GoogLeNet的弱监督方法,其在每个时间步处理一个多分辨率图像补丁,然后利用该图像补丁更新图像的表示形式,并与之前的激活值相结合,输出下一个注意点的位置或输出最终的分类结果。RA-CNN[10]方法提出新型循环注意卷积神经网络,使用相互增强的方法递归学习图像中重要区域的注意力和基于此区域的特征表示。DCL[9]引入destruction and construction机制打乱图像的全局结构后又重组来学习重要特征。最近,Rao等人[12]提出CAL方法,通过反事实的因果关系学习注意力,这种反事实的因果关系能帮助网络衡量注意力质量并提供强大的监督信号指导学习过程。鉴于CAL在一系列基准上的良好表现,本文将使用该模型作教师模型。上述方法取得了一定的成果,但都存在较大的区域定位范围问题,而该范围包含背景和其他干扰因素,将影响最终分类的准确性。鉴于细粒度图像分类任务中细节的重要性,本文将使用目标区域选取模块对准更加重要和细微的区域帮助模型进行更好的分类。
2)基于Transformer的方法 TransFG[14]方法首次将Transformer框架应用在细粒度图像分类上,用ViT[21]作为骨架网络并在三个标准集上的准确率达到当时的最新水平,其中ViT模型是谷歌团队提出用于解决传统分类任务的经典模型。然而,TransFG用重叠的图像补丁作为输入,使得计算成本过高。本文研究与TransFG有相似之处,如两者都设计子模块用于寻找图像中最具区分性区域,但骨架网络和模块设计都各有不同。FFVT[15]提出基于Transformer框架的特征融合方法,将来自Transformer各层的重要令牌集合在一起,以补偿局部、低层和中层信息,称为相互注意权重选择(mutual attention weight selection, MAWS)。PIM[13]设计单独的插件模块,可以嵌入到多种常用的骨架网络中,包括基于CNN和基于Transformer的网络。
3)知识蒸馏方法(knowledge distillation,KD) 上述提到的方法均不能同时结合CNN和Transformer方法的优点。针对此问题,本文尝试蒸馏模型在细粒度图像分类任务中的可行性,拟借助基于Transformer的学生模型对基于CNN的教师模型进行知识蒸馏,从而结合CNN和Transformer的各自优势。知识蒸馏是基于教师—学生网络思想的一种训练方法。Hinton等人[24]首次提出KD训练范式,即学生模型根据真实标签和教师模型给出的软标签进行特征学习,软标签是教师模型通过softmax层的输出。知识蒸馏能够将归纳偏置(inductive biases)[25]以软方式的形式传递给学生模型。软标签的好处在于它包含正标签和负标签两种信息,正标签提供分类的正向信息,而负标签也携带丰富信息。如教师模型给出的软标签能告诉学生模型图像中的小汽车更像垃圾车而不像胡萝卜,但真实标签只能提供正向信息。DeiT是基于Transformer框架的知识蒸馏模型,研究表明使用基于CNN的模型作为教师模型可能会将归纳偏置传递给学生模型[22]。本文拟借助DeiT优势,将其作为骨架网络,探索其在细粒度图像分类任务中的可能性,并结合基于CNN的模型作为教师模型提高整体性能。
2 基于知识蒸馏与目标区域选取的细粒度图像分类方法
本章将详细介绍本文所提基于知识蒸馏与目标区域选取的细粒度图像分类方法,TRS-DeiT。其主要包括四部分:a)骨架网络DeiT作为本模型框架用于学习图像基本特征;b)知识蒸馏的模型设计用于有效学习教师模型知识;c)目标区域选取模块用于获取图像中最具区分性区域; d)损失函数总体设计用于高效监督模型学习。TRS-DeiT模型整体结构如图2所示,最左侧是模型的输入,包括图像补丁(image patches)和两个额外的令牌,即分类令牌(class token)和蒸馏令牌(distillation token);中间是骨架网络DeiT,在倒数第二层插入目标区域选取模块;最右侧是通过分类令牌和蒸馏令牌对三个损失函数值进行计算。
2.1 骨架网络DeiT介绍
本文最大的创新在于首次将蒸馏型Transformer方法用于细粒度图像分类任务中,使用教师模型指导学生模型完成分类任务。DeiT在传统图像分类领域性能超过ViT达到最新性能,本文将探索DeiT在细粒度图像分类中的可行性,并使用DeiT作为骨架网络完成蒸馏模型设计。
DeiT模型以Transformer为框架,包含L层Transformer层,每层Transformer包括多头注意力(multi-head self-attention,MHSA)和前馈神经网络(feed forward network,FFN)。除补丁令牌外,输入令牌还包括分类令牌和蒸馏令牌,它们都是可训练向量,分类令牌在首层Transformer前被附加到输入令牌中,并在每个Transformer层与其他令牌交互,最后分类令牌通过线性层计算后得到最终预测结果。蒸馏令牌是为了做知识蒸馏任务添加的令牌,它的功能与分类令牌类似也是与其他令牌交互,但其目标是让DeiT学习教师模型的知识,并复现教师模型的预测结果。DeiT使用的教师模型有卷积神经网络教师模型和Transformer教师模型两种类型。DeiT的实验发现,使用卷积神经网络教师模型比使用Transformer得到更好的性能表现,其原因在于蒸馏过程中Transformer所继承的来自卷积神经网络教师模型的归纳偏置。因此,本文采用DeiT作为骨架网络,用蒸馏方法实现同时利用CNN模型和Transformer模型的优势。DeiT的计算过程如下:给定输入图像,首先将其预处理成一系列图像补丁,输入图像尺寸用H×W表示,补丁尺寸用P来表示。图像补丁的数量可表示为
N=H×WP2(1)
3 实验结果及分析
本章通过实验验证本文模型中知识蒸馏方法、目标区域选取模块和对抗损失函数及其组合对TRS-DeiT模型分类准确率的贡献。具体地,本文在三个国际标准细粒度图像数据集上与已有先进的细粒度图像分类方法进行比较,并分析实验结果。通过消融实验验证知识蒸馏方法、对抗损失函数和目标区域选取模块对模型准确率的贡献度。最后通过可视化注意力权重展示不同模型的注意力分布情况,从而进一步证明目标区域选取模块的有效性。
3.1 实验数据集
本文选取三个经典的细粒度图像分类数据集验证TRS-DeiT模型的有效性,分别是CUB-200-2011[27] 、Stanford Cars[3] 、Stanford Dogs[2] 。 CUB-200-2011数据集包含11 788张鸟类图片共200个类;Stanford Cars數据集包含来自196个类的16 185张车的图片;Stanford Dogs数据集包含20 580张狗的照片共120个类别,各数据集具体信息如表1所示。
3.2 实验环境及参数设置
为了建模TRS-DeiT,本文采用DeiT-B作为本模型的骨架网络,并加载官方DeiT-B模型的预训练权重[22]。本模型的训练使用两块NVIDIA RTX 2080 GPU,在PyTorch平台上进行实验。
训练参数设置:数据集的图像尺寸调整为统一的448像素×448像素,数据增强方法为随机翻转、随机裁剪、随机锐度、归一化。CUB-200-2011和Stanford Cars数据集的学习率均设置为0.003,Stanford Dogs数据集的学习率设置为0.000 5,学习率调度器设置为step,训练优化器设置为AdamW,批大小(batch size)设置为4,整个训练过程最大迭代次数为100。根据实验统计验证,在CUB-200-2011和Stanford Cars数据集上,蒸馏损失函数阈值α均设置为0.5,在Stanford Dogs数据集上,α设为0.1,在三个数据集上对抗损失函数的β阈值均设为0.4。
测试参数设置:批大小设为4,图像尺寸调整为448像素×448像素,统一将图像标准化。
教师模型设置:在CUB-200-2011数据集上,分别测试基于CNN的教师模型CAL[12]和基于Transformer的教师模型TransFG[14]的表现,并分析两种教师模型的优劣。最终,鉴于CAL作为教师模型在CUB-200-2011任务中的突出表现,在Stanford Cars和Stanford Dogs数据集上只选择CAL作为教师模型。
3.3 性能对比实验
本文模型在数据集CUB-200-2011、Stanford Cars、Stanford Dogs上完成训练和测试,并与其他同期先进方法进行准确率的比较。
在CUB-200-2011数据集上对比不同方法,所得准确率如表2所示。本文模型TRS-DeiT对比基准网络DeiT提升1.9%,与其他基于Transformer的模型相比,精度略低,但超过基于CNN的模型和DeiT模型。原因分析如下:TransFG采用重叠的补丁作为输入,且骨架网络ViT的准确率比DeiT高1.4%,因此更适合做该数据集任务。PIM的骨架网络模型Swin Transfor-mer[28]在基本框架Transformer中加入了CNN结构,这无疑引入了更多的模型参数,结构更为复杂,骨架网络Swin Transformer在该数据集的准确率高达91.9%。然而,上述两个方法都需要较高的计算和时间消耗。与此相比,本文模型结构保持了简单性,只使用Transformer框架,具有更低的计算复杂度。FFVT方法的重要区域选取模块更为复杂,在每层Transformer均需要进行特征区域选取,而本文模型只需做一次选取。因此,本模型在CUB-200-2011数据集上以较简单的模型结构和较低的计算复杂度的前提下,获得了相对优势的性能结果。
TRS-DeiT模型与其他方法在Stanford Cars数据集上的准确率对比结果如表3所示,本方法对比DeiT有1.2%的提高,对比TransFG有0.2%的提高。准确率没有超过教师模型CAL的原因可能是Cars数据集不同于其他两个数据集,分类效果更多依赖全局特征,而本文所提模型TRS-DeiT更专注于局部细微区域。以Transformer为框架的模型中,本文模型表现最佳。
相比于上述两个数据集,Stanford Dogs数据集有相对多的图像和相对少的类别数,这有利于模型训练。通过表4结果可见,本文所提模型TRS-DeiT取得了最好的性能结果(95.1%),其中基线模型DeiT表现相当(94.0%)。上述结果表明骨架网络的选择对细粒度图像分类任务的准确性有重要影响,这与PIM[13] 的观察结果一致。
综上所述,本文模型TRS-DeiT在三个数据集的准确率分别达到了90.8%、95%和95.1%的良好性能结果,表明本文所提模型的有效性。
3.4 消融实验
本节通过消融实验验证知识蒸馏方法、目标区域选取模块和对抗损失函数对模型准确率的贡献度,同时展示本模型与其他模型的计算复杂度对比情况。
首先,以CUB-200-2011数据集作为任务,研究不同框架模型作为教师模型对最终性能的影响,其中以TransFG方法作为Transformer模型的代表,CAL方法作为CNN模型的代表,如表5所示(正确率指左侧对应模型的正确率),TransFG模型作为教师模型,最终结果相对来说没有显著提升,而CAL作为教师模型,结果具有0.2%的相对提升,原因可能是TransFG作为教师模型提供知识有限,CAL作为教师模型给学生模型传递了归纳偏置知识。
为了分析本文构建的目标区域选取模块的有效性,本文对CUB-200-2011、Stanford Cars、Stanford Dogs数据集进行可视化,结果如图4所示,分别展示了三个模式的三类图像。第一行表示原始图像,第二行和第三行借助热力图分别展示基线模型DeiT以及本文模型TRS-DeiT在图像上的注意力权重值,颜色越鲜艳的地方表示注意力权重越大,通过观察可见,基线模型DeiT的注意力遍布在图像的识别对象和背景上,而本文模型TRS-DeiT的注意力更关注识别对象,其专注于区分性区域而去除了对背景等区域的关注。图中第一列的图片来自CUB数据集,本文模型的注意力专注于重要区域如鸟的头部、颈部和脚,在Stanford Cars和Stanford Dogs数据集可以发现同样的现象。
为了进一步分析目标区域选取模块对本文模型所做贡献,笔者观察了准确率的消融实验结果,如表6所示,添加目标区域选取模块后,准确率从90.6%提升到了90.8%,结合图4可视化结果,进一步说明本模型确实选取了图像中的重要区域。表6中,KD表示知识蒸馏方法;CL表示对抗损失函数;TRSM表示目标区域选取模块。此外,添加知识蒸馏模块和对抗损失函数后本模型的准确率分别提升1.4%和0.3%,可以得出两部分是有效可行的,且能带来微幅提升。
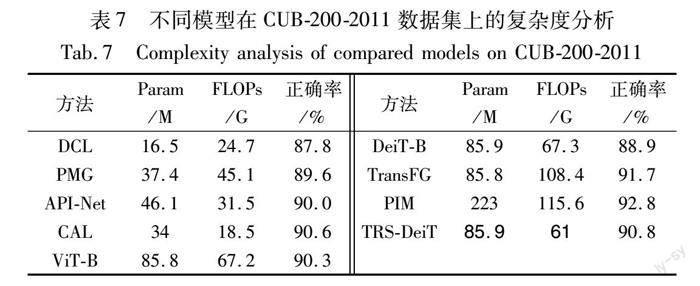
不同模型的复杂度分析如表7所示。TRS-DeiT在參数量与基线模型ViT-B和DeiT相当的前提下,准确率分别提高0.5%和1.9%,计算量降低了约6 G;在参数量与TransFG相当的前提下,计算量降低了47.4 G;与PIM模型相比,参数量与计算量都远远小于PIM模型。因此,本文模型在参数量和计算量上总体优于其他基于Transformer的基线模型。
本文方法仅使用图像标签作为训练标签,在弱监督下通过端到端的训练得到分类结果。表2~4的实验结果可得本文模型分类准确率有着不低于传统方法的效果。表5、6和图4的消融实验可得本文所提模型各组成部分对提高模型分类准确率是有效的,表7模型复杂度分析可知本模型在参数量和计算量总体优于以Transformer为框架的模型。
4 结束语
本文提出知识蒸馏和目标区域选取模块相结合的细粒度图像分类方法TRS-DeiT。所提方法借助知识蒸馏结合CNN模型和Transformer模型的各自优势,更好地学习细粒度图像的潜在特征。此外,针对细粒度图像分类任务中存在的类间差距小和类内差距大的问题,在模型中插入目标区域选取模块选取最具区分性区域,同时通过在损失函数中引入对抗性损失函数让模型关注不同类别图像间的区别和同种类别图像间的相似性,从而有效监督模型训练。实验结果表明本文方法在CUB-200-2011、Stanford Cars和Stanford Dogs数据集上的准确率分别达到了90.8%、95%、95.1%,优于对比模型,可视化分析结果进一步表明本文模型选取了图像中的重要区域而排除无关区域的干扰,从而使得本文方法在处理细粒度图像分类任务上更具优势。本文方法在知识蒸馏过程中,教师模型会极大程度地影响学生模型的结果。针对此问题,如何进一步优化知识蒸馏模型,打破教师模型的限制,从而进一步提高模型准确率,是未来工作的重要研究内容。
参考文献:
[1]Wei Xiushen, Song Yizhe, Mac Aodha O, et al. Fine-grained image analysis with deep learning: a survey[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2021,44(12): 8927-8948.
[2]Khosla A, Jayadevaprakash N, Yao Bangpeng, et al. Novel dataset for fine-grained image categorization: Stanford Dogs[C]//Proc of CVPR Workshop on Fine-grained Visual Categorization. Piscataway NJ: IEEE Press, 2011: 3-8.
[3]Krause J, Stark M, Deng Jia, et al. 3D object representations for fine-grained categorization[C]//Proc of IEEE International Conference on Computer Vision. Washington DC: IEEE Computer Society, 2013: 554-561.
[4]羅建豪, 吴建鑫. 基于深度卷积特征的细粒度图像分类研究综述[J]. 自动化学报, 2017,43(8): 1306-1318. (Luo Jianhao, Wu Jianxin. A survey on fine-grained image categorization using deep convolution features[J]. Acta Automatica Sinica, 2017,43(8): 1306-1318.)
[5]Huang Shaoli, Xu Zhe, Tao Dacheng, et al. Part-stacked CNN for fine-grained visual categorization[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society, 2016: 1173-1182.
[6]Wei Xiushen, Xie Chenwei, Wu Jianxin. Mask-CNN: localizing parts and selecting descriptors for fine-grained bird species categorization[J]. Pattern Recognition, 2018,76(4): 704-714.
[7]Zhang Ning, Donahue J, Girshick R, et al. Part-based R-CNNs for fine-grained category detection[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2014: 834-849.
[8]毛志荣, 都云程, 肖诗斌, 等. 基于ECA-Net与多尺度结合的细粒度图像分类方法[J]. 计算机应用研究, 2021,38(11): 3484-3488. (Mao Zhirong, Du Yuncheng, Xiao Shibin, et al. Fine-grained image classification method based on ECA-Net and multi-scale[J]. Application Research of Computers, 2021,38(11): 3484-3488.)
[9]Chen Yue, Bai Yalong, Zhang Wei, et al. Destruction and construction learning for fine-grained image recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2019: 5157-5166.
[10]Fu Jianlong, Zheng Heliang, Mei Tao. Look closer to see better: recurrent attention convolutional neural network for fine-grained image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society, 2017: 4438-4446.
[11]Zheng Heliang, Fu Jianlong, Zha Zhengjun, et al. Learning deep bilinear transformation for fine-grained image representation[J]. Advances in Neural Information Processing Systems, 2019,32: 4277-4286.
[12]Rao Yongming, Chen Guangyi, Lu Jiwen, et al. Counterfactual attention learning for fine-grained visual categorization and re-identification[C]//Proc of IEEE/CVF International Conference on Computer Vision. Washington DC: IEEE Computer Society, 2021: 1025-1034.
[13]Chou Poyung, Lin Chenghung, Kao Wenchung. A novel plug-in module for fine-grained visual classification[EB/OL]. (2022-02-08).https://arxiv.org/pdf/2202. 03822.
[14]He Ju, Chen Jieneng, Liu Shuai, et al. TransFG: a transformer architecture for fine-grained recognition[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 852-860.
[15]Wang Jun, Yu Xiaohan, Gao Yongsheng. Feature fusion vision Transformer for fine-grained visual categorization[EB/OL]. (202202-28). https://arxiv.org/pdf/2107.02341.
[16]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society, 2016: 770-778.
[17]Huang Gao, Liu Zhuang, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society, 2017: 4700-4708.
[18]Zheng Heliang, Fu Jianlong, Mei Tao, et al. Learning multi-attention convolutional neural network for fine-grained image recognition[C]//Proc of IEEE International Conference on Computer Vision. Washington DC: IEEE Computer Society, 2017: 5209-5217.
[19]Zheng Heliang, Fu Jianlong, Zha Zhengjun, et al. Learning rich part hierarchies with progressive attention networks for fine-grained image recognition[J]. IEEE Trans on Image Processing, 2019,29: 476-488.
[20]Raghu M, Unterthiner T, Kornblith S, et al. Do vision transformers see like convolutional neural networks?[J]. Advances in Neural Information Processing Systems, 2021,34: 12116-12128.
[21]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-01-03). https://arxiv.org/pdf/2010.11929.
[22]Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//Proc of International Conference on Machine Learning. 2021: 10347-10357.
[23]Sermanet P, Frome A, Real E. Attention for fine-grained categorization[C]//Proc of International Conference on Learning Representations. 2015.
[24]Hinton G,Vinyals O,Dean J. Distilling the knowledge in a neural network[EB/OL]. (2015-03-09) https://arxiv.org/pdf/1503.02531.
[25]Abnar S, Dehghani M, Zuidema W. Transferring inductive biases through knowledge distillation[EB/OL]. (2020-10-04) https://arxiv.org/pdf/2006. 00555.
[26]Abnar S, Zuidema W. Quantifying attention flow in Transformers[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 4190-4197.
[27]Wah C,Branson S,Welinder P, et al.The Caltech-UCSD birds-200-2011 dataset,CNS-TR-2011-001[R]. Pasadena, CA: California Institute of Technology, 2011.
[28]Liu Ze, Lin Yutong, Cao Yue, et al. Swin Transformer:hierarchical vision Transformer using shifted windows[C]//Proc of IEEE/CVF International Conference on Computer Vision. Washington DC: IEEE Computer Society, 2021: 10012-10022.
[29]Ji Ruyi, Wen Longyin, Zhang Libo, et al. Attention convolutional binary neural tree for fine-grained visual categorization[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway NJ: IEEE Press, 2020: 10468-10477.
[30]Du Ruoyi, Chang Dongliang, Bhunia A K, et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2020: 153-168.
[31]Zhuang Peiqin, Wang Yali, Qiao Yu. Learning attentive pairwise interaction for fine-grained classification[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 13130-13137.
[32]Luo Wei, Yang Xitong, Mo Xianjie, et al. Cross-x learning for fine-grained visual categorization[C]//Proc of IEEE/CVF International Conference on Computer Vision. Washington DC: IEEE Computer Society, 2019: 8242-8251.
[33]Hu Tao, Qi Honggang, Huang Qingming, et al. See better before looking closer: weakly supervised data augmentation network for fine-grained visual classification[EB/OL]. (2019-03-23). https://arxiv.org/pdf/1901.09891.
收稿日期:2022-12-04;修回日期:2023-02-01 基金項目:国家自然科学基金资助项目(61976156);天津市企业科技特派员项目(20YDTPJC00560)
作者简介:赵婷婷(1986-),女(通信作者),内蒙古赤峰人,副教授,硕导,博士,主要研究方向为机器学习算法、强化学习及机器人控制(tingting@tust.edu.cn);高欢(1994-),女,河北唐山人,硕士研究生,主要研究方向为计算机视觉、图像分类;常玉广(1997-),男,河北张家口人,硕士研究生,主要研究方向为图像处理、跨模态图文检索;陈亚瑞(1982-),女,河北邢台人,教授,硕导,主要研究方向为概率图模型、机器学习算法及近似推理算法等;王嫄(1989-),女,山西万荣人,教授,硕导,主要研究方向为数据挖掘、机器学习及自然语言处理等;杨巨成(1980-),男,湖北天门人,教授,博导,主要研究方向为图像处理、生物识别、模式识别及神经网络等.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
