
SM4国密算法的异构可重构计算系统研究
2023-10-18 23:14:21王腾腾柴志雷
计算机应用研究 2023年9期
关键词:现场可编程门阵列
王腾腾 柴志雷


摘 要:隨着互联网的数据量呈爆炸式增长,以纯软件方式运行的SM4算法速度慢、CPU占用率高,而基于Verilog/VHDL实现的现场可编程门阵列或专用集成电路存在灵活性差、升级维护困难等问题。为了解决上述问题,提出了一种SM4国密算法的异构可重构计算系统的设计方案,采用高层次综合和异构可重构技术,通过优化数据内存分配与传输、优化循环、矢量化内核以及增加计算单元等方式,设计了SM4算法电子密码本模式和计数器模式的定制计算架构,并将该系统部署在FPGA异构平台。实验结果表明:SM4-ECB和SM4-CTR两种主流工作模式的定制计算架构在Intel Stratix 10 GX2800上,吞吐率分别达到109.48 Gbps和63.73 Gbps,是Intel Xeon E5-2650 V2 CPU上对应模式吞吐率的232.63倍和141.62倍。以此核心模块(包含数据输入、加解密、输出)的整体异构可重构计算系统的性能也分别达到了纯软件方式的4.90倍和3.56倍。该方案不仅实现了针对特定模式进行定制加速,而且可以通过硬件重构灵活支持不同的计算模式,兼顾了系统的灵活性和高效性。
关键词:SM4;异构可重构;现场可编程门阵列;国密算法;硬件加速
中图分类号:TP309 文献标志码:A
文章编号:1001-3695(2023)09-042-2826-06
doi:10.19734/j.issn.1001-3695.2022.12.0832
Research on heterogeneous reconfigurable computing system of SM4 national security algorithm
Wang Tengteng1,Chai Zhilei1,2
(1.School of Artificial Intelligence & Computer Science,Jiangnan University,Wuxi Jiangsu 214122,China;2.Jiangsu Provincial Enginee-ring Laboratory of Pattern Recognition & Computational Intelligence,Wuxi Jiangsu 214122,China)
Abstract:With the explosive growth of the data volume of the Internet,there are problems such as the slow speed and high CPU utilization of the SM4 algorithm running in pure software mode.While the field programmable gate array or dedicated integrated circuit based on Verilog/VHDL has problems such as poor flexibility and difficulty in upgrading and maintenance.In order to solve the above problems,this paper proposed a design scheme of heterogeneous reconfigurable computing system based on SM4 algorithm.Using high-level synthesis and heterogeneous reconfigurable technology,
it designed the customized computing architecture of SM4 algorithms electronic cipher book mode and counter mode by optimizing the allocation and transmission of data memory,optimizing the loop,vectorizing the kernel and adding computing units.And the system was deployed on the FPGA heterogeneous platform.The experimental results show that the customized computing architecture of SM4-ECB and SM4-CTR,two mainstream operating modes,on the Intel Stratix 10 GX2800,has a throughput of 109.48 Gbps and 63.73 Gbps respectively,which is 232.63 times and 141.62 times throughput of the corresponding mode on the Intel Xeon E5-2650 V2 CPU.The performance of the whole heterogeneous reconfigurable computing system composed of this core module,including data input,encryption and decryption,and output,has also reached 4.90 times and 3.56 times of that of pure software mode.This paper not only realizes customized acceleration for specific modes,but also flexibly supports different computing modes through hardware reconfiguration,taking into account the flexibility and efficiency of the system.
Key words:SM4;heterogeneous reconfigurable;FPGA;secret algorithm;hardware speedup
0 引言
SM4算法是我国国家密码管理局发布的无线局域网标准的分组对称密码算法,是我国密码行业标准算法之一[1,2]。SM4算法主要承担安全通信过程中的加密和解密任务,随着大数据时代的来临以及无线局域网的广泛普及,其传输信息的安全性面临着巨大挑战[3],同时对数据传输速度提出了更高的要求。单一的加密模式以及使用纯软件运行SM4算法的方式已无法满足现今海量敏感数据传输过程中安全性和高效性的需求[4]。
目前,为了满足数据高效传输的应用场景,许多国内外学者已经在各种平台上实现该算法并取得了很多优秀成果。2017年,Cheng等人[5]设计的CPU-GPU模式的硬件加速架构,其中针对SM4算法并行优化,使其ECB(electronic code book)模式吞吐率提高到76.89 Gbps,其CTR(counter)模式吞吐率达到32.23 Gbps。
虽然此硬件架构使其吞吐率得到了极大提升,但是该工作存在耗能高、灵活性差的问题。因此,Guan等人[6]在2018年提出了多种基于FPGA的硬件设计,探索面积和速度之间的权衡,速度第一的设计通过结合状态机和32级流水线设计,其吞吐率达到了27.15 Gbps。2019年,刘金峒等人[7]设计了循环迭代结构和全并行流水结构,并提出了一种部分并行可裁剪式结构,在FPGA实现后,全并行流水结构吞吐率为12.89 Gbps,部分可裁剪式结构吞吐率则为3.2 Gbps。2022年,李建立等人[8]对SM4算法提出了一种基于复合域S盒的二次流水全展开硬件架构,SM4吞吐率最高达53.76 Gbps。上述基于FPGA的工作均采用传统的硬件描述语言Verilog/VHDL实现,虽然提供了更精确的时序设计并且降低了功耗,但是开发周期长且维护困难。其中多数工作仅实现了一种模式,缺乏灵活性,无法满足不同应用场景的安全需求。
综上所述,针对SM4算法兼具高效性和灵活性的计算方法和系统的研究,具有重要意义,并且随着大数据时代各种应用场景的增多,这一需求变得更加迫切。SM4算法的ECB和CTR模式具有简单、快速、并行性高的特点,可以满足目前人们对高吞吐率和不同应用场景的需求。本文针对SM4算法提出的异构可重构方法可以将SM4算法的ECB和CTR模式融合在一起,利用FPGA的可重构特性配置控制模块,按需加载不同的模式,以满足不同的安全需求。同时利用高层次描述语言OpenCL设计了两种模式的定制计算架构,通过流水线架构结合OpenCL中Kernel执行特点,提出了新的SM4算法两种模式的硬件加速优化思路,相较于传统Verilog/VHDL开发方式,缩短了开发周期、有利于更新和维护,且性能表现更佳。因此,本文设计的SM4算法的异构可重构计算系统,不仅利用FPGA提高了计算的高效性,还实现了主机端对两种加密模式的在线动态重构,使得该系统兼顾灵活性和高效性。
本文通过OpenCL设计的SM4算法的异构可重构计算系统,包含SM4算法的ECB和CTR两种加密模式的定制硬件加速框架,通过在Intel Stratix 10 GX 2800上硬件重构实现了SM4算法两种加密模式的切换。最终系统中ECB和CTR模式的整体加速效果与纯软件方式相比,分别获得了4.897和3.561的加速比,核心模块在FPGA片上的吞吐率分别达到了108.43 Gbps、63.73 Gbps。
1 SM4算法
SM4是我国自主设计的分组对称密码算法,其分组长度为128 bit,密钥长度也为128 bit。加密算法与密钥扩展算法均采用32轮非线性迭代结构,以字(32 bit)为单位进行加密运算,每一次迭代运算均为一轮变换函数F。SM4算法加/解密算法的结构相同,不同的是使用轮密钥相反,其中解密轮密钥是加密轮密钥的逆序。
1.1 SM4密钥扩展算法
将128 bit的初始密钥MK=(MK0,MK1,MK2,MK3)的每个字分别与128 bit的系统参数FK=(FK0,FK1,FK2,FK3)的每个字进行异或运算得到四个字(K0,K1,K2,K3),如式(1)所示。再把后三个字与固定参数CK0做异或运算后进行函数T′运算获得的结果C与K0做异或运算,就得到了第一轮的子密钥rk0,也是下一个密钥运算的K4,如式(2)所示。
1.3 SM4算法性能瓶颈分析
由于轮函数F需要做32轮迭代,其迭代部分包括异或操作、S盒变换、比特位左移、反序变换等操作,其执行效率是影响SM4算法性能的关键因素。所以,将SM4算法的轮函数F进行优化设计并运行在适合做大量数据并行运算的FPGA端,能够有效提高其运行速率、降低运行时间,从而大幅度提升SM4算法整体运行效率。将CTR模式中的算子自增计算利用FPGA提前计算,能够解决因为每一轮进行一次算子自增计算的数据依赖和计算延迟问题,进而提高算法整体运行效率。
在本文实验中,因为每个明文块使用的密钥相同,所以只需要将密钥扩展算法计算一次且计算量不大。将所有传入的明文块补充到16 Byte整数倍,其计算量也很小。因此,将密钥扩展算法和补充明文块的运算利用CPU运行,能够节省FPGA资源,最大程度利用FPGA加速性能。
2 基于OpenCL的异构可重构系统
2.1 异构平台编程框架OpenCL
开放设计语言(open computing language,OpenCL)[9,10]是一个灵活的异构平台的编程框架,具有强大的兼容性,可以将不同类型的硬件结合在同种执行环境中,支持各种异构平台(CPU、DPU、GPU、FPGA等)。同時,开发者可以使用高级语言对FPGA进行编程,不仅能够实现硬件可重构系统,同时可以降低开发门槛,缩短开发周期。
近年来,异构计算已经成为高性能计算的主流解决方案,CPU+GPU异构计算模式已经得到广泛的应用。自从2011年Altera公司发布支持OpenCL来开发FPGA的SDK以后,CPU+FPGA的异构架构也成为一种具有竞争力的高性能计算方案。OpenCL是第一个面向异构系统的并行编程的开放式标准语言,CPU端采用标准C/C++编写,设备端采用标准C编写Kernels,CPU可以通过OpenCL API来调用设备运行。利用OpenCL在更高层的设计抽象环境中迅速进行设计开发,跳过耗时的手动时序收敛及FPGA、CPU和外部存储之间的通信接口设计工作。在基于OpenCL的CPU+FPGA的异构设计中,将CPU不擅长的计算密集型任务使用FPGA处理,利用FPGA大量的计算资源和并行性提高计算速度,不仅解放了CPU,还充分利用了FPGA的计算能力,最大程度提高设备端的吞吐率。
本文所使用的是Intel Stratix 10 FPGA和面向 OpenCL 的英特尔 FPGA SDK。Intel FPGA SDK通过离线编译器编译Kernel创建优化硬件镜像,编译器将Kernel转换为Verilog形式后,通过Quartus Ⅱ软件编译为二进制镜像,运行程序时,将该镜像加载到FPGA,构建硬件加速系统。Intel FPGA SDK还支持在CPU端仿真FPGA特性,在FPGA构建前可验证设计性能,能够缩短检验设计正确性的时间。
2.2 异构可重构计算系统
2.2.1 异构计算系统总体架构
本文异构系统的总体架构是CPU+FPGA。其中主机端CPU是用于对主机端与外部环境和设备端数据交互的控制以及对Kernel的调度和管理,具有强大并行计算能力的设备端FPGA用于完成SM4算法的主要计算任务。如图3所示,CPU和FPGA通过PCIe连接。在FPGA中,处理元素是一个工作项的处理单元,一个处理单元完成一个SM4明文块的加密计算,其私有存储器用来储存运算中间产生的数据。由于全局存储器的最大带宽远小于局部存储器的最大带宽,FPGA的计算带宽远大于全局存储器的最大带宽。因此,通过调整数据的存储位置、优化数据传输,减少对全局存储器的访问次数,并且使用局部存储器和私有存储器等片上存储器执行内核计算,增加内核的内存带宽,极大提高内核的性能。对SM4算法加密模块,通过循环展开、循环流水的方式,充分利用FPGA的计算特点,形成流水线并行架构。将内核矢量化和增加计算单元结合使用,工作项可以同时访问和存取更多的数据,增加的计算单元可以计算更多的数据,使得FPGA的吞吐率得到了极大提高。
2.2.2 可重构设计
图4是基于Intel FPGA的可重构框架,其中两个主要部分为CPU和Intel FPGA,并通过PCIe总线通信。CPU管理相关事务、控制FPGA加速单元并处理简单的串行任务,FPGA具有硬件可重构能力和强大的并行计算能力,因此使用FPGA实现不同应用需求在线动态重构硬件模块或静态重构硬件模块并完成计算密集型任务。FPGA分为静态配置区与动态可重构区。静态配置区中有PCIe、DMA控制器等主要模块,静态配置区的主要作用是向FPGA外部的PCIe、DDR等提供通信接口,同时也向动态可重构区域的Kernel IP提供接口。静态配置区通过主动配置方式AS配置模式进行配置,FPGA上电后自动配置,配置完成后FPGA可以接收CPU发送来的指令,动态可重构区通过指令部署指定的模式SM4的Kernel IP并执行计算任务,Kernel IP是SM4算法的具体实现。当改变SM4算法的模式时,CPU通过PCIe下发新的Kernel IP,重新配置动态可重构区,这个过程不需要重启FPGA,整个重新配置过程耗时仅为毫秒级,完全实现了SM4算法多种模式的在线重构。
由于Kernel函数的编译时间过长,所以将Kernel函数进行离线编译,事先生成可执行文件。main函数的编译、运行以及对FPGA进行管理控制等由CPU完成,main函数的编译和运行需要OpenCL运行支持库支持。当应用场景改变,需要对FPGA进行动态可重构配置,CPU会将事先准备好的FPGA可执行文件通过PCIe总线传输给FPGA,以实现在线可重构功能[11]。
在实际的应用场景中,对于不同的应用场景有着不同的安全要求和加/解密速度要求,同一个应用场景下一般对应一种安全需求和吞吐率要求,因此一般应用场景不需要运行时动态重构。静态可重构和动态可重构结合使用可以使整个系统更具灵活性。
3 SM4异构可重构计算系统实现
3.1 主机端的程序与设计
对于OpenCL的主机端程序设计有一个相对固定的流程,主要步骤是利用Intel FPGA SDK提供的API来获取平台和设备、创建上下文以及命令队列,最后等到内核程序运行结束读取到内核运行结果后释放内存资源。图5便是主机端程序执行流程。除此之外,根据SM4算法原理,将计算量小和不利于并行计算的部分放在主机端运行,主要包括优化内存分配与创建、密钥和自增算子等数据的创建和初始化以及內核参数设定等。同时,CPU负责整个系统的调度和管理。
3.2 FPGA端硬件设计
3.2.1 优化数据内存分配与传输
OpenCL将内存抽象为五种类型的存储器[12],分别为主机存储器、全局存储器、常量存储器、局部内存以及私有存储器。如表1所示,各个存储器所在的位置不同,其吞吐率、容量和延迟都存在一定的差异,将数据存储在合适的位置能有效提高硬件架构的吞吐率。将存储器带宽的利用率提高,可以优化整体架构性能。全局存储器是容量最大以及传输数据时吞吐率最大的存储器。将主机端传输到FPGA端的明文、密钥等大量数据存储在全局存储器中,提高存储器带宽的利用率,从而提升整体性能。将加/解密模块运行时不变的系统参数FK、固定参数CK以及加/解密过程中访问频繁的S盒存放于常量存储器,能提升访问速度,避免访存冲突。与私有存储器相比,局部存储器为了保证数据一致性在同组工作项执行之后,会使用保护屏障导致延迟时间增加。因此,虽然在延时相当时,局部存储器的吞吐率更大且具有更大容量,但是仍然选择将SM4算法加/解密过程中参与运算的变量存储在私有内存中,此时延时更短、吞吐率也相对更高。
在本文设计中,CPU控制明文从全局存储器传输到片上缓存,加密后得到密文,最后将密文从片上缓存传输回全局存储器,需要两次数据传输。将一个工作项处理的数据位宽固定为和SM4明文长度相同的128 bit,也就是16 Byte,可以避免编译器为了调整数据长度而消耗资源,也可以减少优化程序的限制。
3.2.2 优化循环结构
Intel FPGA SDK通过循环展开形成并行计算和流水线架构。对于不存在数据依赖的循环可以将其完全展开形成并行计算。如SM4算法中ECB和CTR模式都存在的3次循环,轮密钥由CPU传输到FPGA的32次循环、初始化数组的36次循环、密文由FPGA传输给CPU的16次循环,以及只存在CTR模式中的2次循环,自增算子和明文由CPU传输到FPGA的16次循环和自增算子加密结果和明文异或的16次循环,上述循环均不存在数据依赖,可以将循环完全展开,形成并行计算,其架构如图6(b)所示。假设数据读取、数据处理和数据存储中的每一步操作都只需要1个cycle,在没有展开循环前内核在下次计算前延迟了3个cycle,而将循环展开后,则实现了并行计算。针对32轮非线性迭代,通过循环展开在加载内存数据模块和存储内存数据模块形成内存合并,将32轮加载内存数据和存储内存数据的操作降低为位宽更宽的数据加载操作和存储操作;在迭代计算模块,针对32轮迭代的S盒置换和左移等操作进行循环展开,通过指导编译器生成单次迭代所需的硬件架构形成有效流水,减少了迭代计算所需要的时间。其架构如图6(c)所示,假设数据读取、数据处理和数据存储中的每一步操作都只需要一个cycle,在没有形成流水线时,两次load操作间的延迟为3个cycle,而使用了流水线设计后,只有一个cycle的延迟。
表2是加密256 MB数据时SM4加密算法的ECB和CTR模式下32轮非线性迭代形成流水线架构时不同程度展开其他循环形成并行计算的优化效果对比。根据实验结果可知,循环展开越多,优化获得的效果越好。优化循环结构可以在很大程度上缩短SM4算法两种加密模式的加密时间。
3.2.3 矢量化内核和增加计算单元
单个指令处理多个数据称为SIMD(single-instruction multiple-data),利用该技术可以大大提高计算密集型算法的吞吐量。矢量化内核就是让多个工作项以单指令多数据的方式来进行SM4算法的运行。在SIMD方式下工作的工作项可以同时访存并处理多个数据。如图7所示,矢量化内核之后,编译器会合并内存访问,访问和存储的数据会是之前的数倍。矢量化内核时需要将工作组的大小固定为矢量化内核参数的整数倍。
选取本文对256 MB数据加密时设置不同矢量化内核和计算单元得到的吞吐率进行比较。由表3可知,在ECB模式下,计算单元相同,矢量化内核参数设置为4时与设置为1时相比,加密时间显著减少,继续将参数增大至8,仍旧有明显加速效果。CTR模式实验数据也有同样规律。实验结果表明,矢量化内核对于提高吞吐率可行且效果显著。
Intel FPGA SDK通过设置参数可以为内核增加多个计算单元,一个计算单元可以运行多个工作组,Intel FPGA可以将工作组分配到已经设置的且未使用的计算单元。计算单元的增加增强了片上计算能力,进而提高片上吞吐率。表4为系统对128 MB数据加密的实验数据,在两种加密模式下,矢量化内核参数都设为8时,计算单元由1个增加到2个,计算时间明显缩短,吞吐率显著提高。实验表明,增加计算单元对于提高吞吐率有显著效果。
4 实验结果与分析
4.1 实验环境
本实验所采用的实验环境为搭载Intel Xeon E5-2650 V2版本CPU的服务器,其操作系统为CentOS Linux Release 7.7.1908,其中使用的GCC版本为V4.8.5,支持OpenCL的SDK版本为Intel FPGA SDK for OpenCL 19.3,FPGA则是Intel Stratix 10 GX2800[13],该卡包含1 866 240个ALUT、3 732 480个FF、11 721个RAM以及5 760个DSP。
4.2 实验结果
本文对不同的优化方法进行了设计并通过模拟和上板测试,对不同设计的性能进行了测试。
4.2.1 内核定制计算性能
对两种模式的SM4算法,合理分配内存、展开循环后,再通过设置不同的矢量化通道数量使单个工作组获得多个矢量化通道,并且增加计算单元执行多个工作组。
表5为两种SM4加密模式分别对256 MB数据加密的时间和资源的对比。在两种模式中,同样使用两个计算单元,将矢量化内核参数设置为8时和设置为4时相比,虽然使用了更多的资源,但是节省了程序运行时间并且取得了更好的优化效果。表中其他數据也同样表明,在一定范围内使用更多的资源,可以缩短程序运行时间、提高吞吐率。
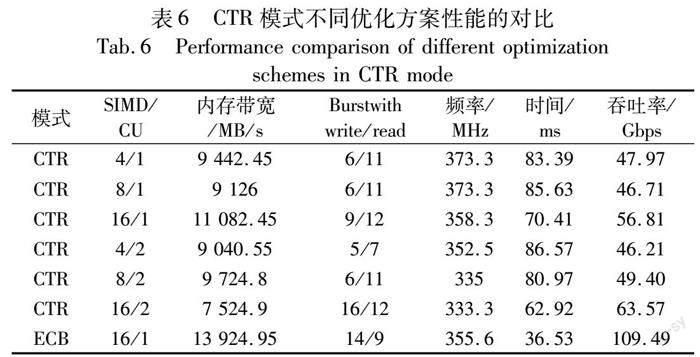
如表6所示,在使用CTR模式加密512 MB数据时,在同一工作频率下突发传输读写宽度相同且使用1个计算单元时,内存带宽更高的矢量化4个通道设计却比矢量化8个通道设计耗时更短、吞吐率更高。虽然增加了资源的使用,但是其带宽的利用率下降,此时对全局内存带宽的争用变得更加激烈,使得吞吐率下降。矢量化16通道并使用2个计算单元的设计,在内存带宽低于其他设计方案时,由于其突发传输读写宽度远大于其他设计方案,其吞吐率也是所有设计中最高的。由此可知,突发传输读写宽度也是影响吞吐率的重要因素。由表中可知,矢量化16个通道同时使用2个计算单元时,其全局内存带宽最大,其吞吐率也是所有设计方案中最大的。与ECB模式中矢量化16个通道和使用2个计算单元的设计相比,ECB中内存带宽利用率比CTR模式的设计高了将近一倍,而ECB中的突发传输读写宽度也只是稍微低于CTR模式,因此,ECB模式的最高吞吐率是CTR模式的1.72倍左右。实验表明,内存宽带利用率以及突发传输读写宽度都是影响吞吐率的关键因素。
本文为了测试不同方案下的最大吞吐率,对两种模式的不同方案进行了不同数据量的加密实验。图8是ECB模式中矢量化16通道使用1个计算单元以及CTR模式中矢量化16通道使用2个计算单元时的不同数据量加密的吞吐率走势图。如图中所示,在数据量为16 KB时,没有达到设备端的最佳性能,随着数据量的增大,设备端的吞吐率也随之快速增加,然后吞吐率趋于稳定;数据量超过64 MB以后,ECB模式在设备端的最大吞吐率稳定在109.49 Gbps上下,CTR模式在设备端的最大吞吐率稳定在63.73 Gbps上下。
本文使用OpenCL在更高层的设计抽象环境中进行设计开发,与表7中文献[7,8,14]等使用Verilog HDL或VHDL语言进行设计相比,在开发速度上有一定的优势,并且加速性能也存在很大的优越性。文献[15]采用ASIC方案实现CTR模式的SM4算法,但是仅在Altera Cyclone V FPGA验证其设计,实现了114.43 MHz下14.647 Gbps的吞吐率,以此预估其流片后CTR模式的吞吐率能輕松实现40 Gbps,甚至可能达到100 Gbps左右。与之相比在本文设计的系统中,CTR和ECB模式的吞吐率已经达到63.73 Gbps和109.49 Gbps,不仅系统的灵活性更高、适应场景更多,还能够大大缩短开发时间以及开发成本,同时又保证了系统的高吞吐率。总的来说,本文系统兼具高效率和灵活性,两种可以切换的模式也能够适应更多的场景。
与基于Intel Xeon E5-2650 V2 CPU平台上OpenSSL库中SM4国密算法的ECB和CTR模式在数据量为256 MB时其吞吐率分别为0.47 Gbps和0.45 Gbps相比,本文加速效果分别是其232.63倍和141.62倍。
4.2.2 系统整体性能
分别对SM4-ECB和SM4-CTR两种加密模式的系统整体性能进行测试,并将测试结果和OpenSSL标准加密库源码对相同数据加密进行纯软件对比。表8是本文中SM4-ECB和SM4-CTR两种模式对不同数据量加密系统整体耗时,包含OpenCL初始化时间、CPU和FPGA间的数据传输时间以及Kernel运行时间。根据实验数据分析,数据量小于8 MB时,OpenCL的初始化和创建Kernel等启动流程所用时间在系统运行的时间中占比较大,而随着数据量增大,数据传输和Kernel计算所用的时间占比也逐渐增大。当加密数据量增大到128 MB以及比其大时,系统运算效率也逐步增大。
图9是异构系统和OpenSSL标准库的纯软件系统的加密时间对比。图9表明,在明文数据量较大时,本文的异构可重构系统加密效率远大于纯软件加密,ECB和CTR模式的加速比最高分别为4.897和3.561。
5 结束语
本文针对国产加密算法SM4面向海量敏感数据交互时存在计算速度慢、CPU占用率和功耗过高以及使用传统Verilog/VHDL语言进行设计存在开发周期长、成本高、灵活性差等问题,设计并实现了一种SM4国密算法的异构可重构计算系统。基于OpenCL对SM4国密算法ECB和CTR两种模式分别进行硬件加速设计,同时基于可重构实现了两种模式加密模式的动态和静态切换。本文设计针对SM4算法的特点,合理利用OpenCL的内存模型优化数据内存分配与传输,通过循环展开的方式形成流水线架构,并将内核矢量化同时增加计算单元来提高设备端的吞吐率。因此,本系统兼具高效率和灵活性,两种模式的灵活切换也能够适应更多的场景。
虽然本文达到了较好的效果,但是仍然存在优化提升空间。增加计算单元时带宽的争夺变得更加激烈,同时伴随工作组大小的变化,会影响到吞吐率的变化,对此本文设计中没有过多深究。因此,将来可以将此作为一个优化方向,达到更高的吞吐率,以适应更多的应用场景。
参考文献:
[1]国家密码管理局.GM/T0002—2012,SM4 分组密码算法[S].北京:中国标准出版社,2012.(State Cryptography Administration.GM/T0002—2012,SM4 block cipher algorithm[S].Beijing:Stan-dards Press of China,2012.)
[2]吕述望,苏波展,王鹏,等.SM4分组密码算法综述[J].信息安全研究,2016,2(11):995-1007.(Lyu Shuwang,Su Bozhan,Wang Peng,et al.Overview on SM4 algorithm[J].Journal of Information Security Research,2016,2(11):995-1007.)
[3]杨伊,何德彪,文义红,等.密钥管理服务系统下的多方协同SM4加/解密方案[J].信息网络安全,2021,21(8):17-25.(Yang Yi,He Debiao,Wen Yihong,et al.Multi-party collaborative SM4 encryption/decryption scheme in key management service[J].Netinfo Security,2021,21(8):17-25.)
[4]郎欢,张蕾,吴文玲.SM4 的快速软件实现技术[J].中国科学院大学学报,2018,35(2):180-187.(Lang Huan,Zhang Lei,Wu Wenling.Fast software implementation of SM4[J].Journal of University of Chinese Academy of Sciences,2018,35(2):180-187.)
[5]Cheng Wangzhao,Zheng Fangyu,Pan Wuqiong,et al.High-perfor-mance symmetric cryptography server with GPU acceleration[M]//Qing Sihan,Mitchell C,Chen Liqun,et al.Information and Communications Security.Cham:Springer International Publishing,2017:529-540.
[6]Guan Zhenyu,Li Yunhao,Shang Tao,et al.Implementation of SM4 on FPGA:trade-off analysis between area and speed[C]//Proc of IEEE International Conference on Intelligence and Safety for Robotics.Piscataway,NJ:IEEE Press,2018:192-197.
[7]刘金峒,梁科,王锦,等.SM4加密算法可裁剪式结构设计与硬件实现[J].南开大学学报:自然科学版,2019,52(4):41-45.(Liu Jintong,Liang Ke,Wang Jin,et al.Cuttable structure design and hardware implementation of SM4 encryption algorithm[J].Acta Scientiarum Naturalium Universitatis:NanKaiensis,2019,52(4):41-45.)
[8]李建立,莫燕南,粟涛,等.基于国密算法SM2、SM3、SM4的高速混合加密系统硬件设计[J].计算机应用研究,2022,39(9):2818-2825,2831.(Li Jianli,Mo Yannan,Su Tao,et al.Hardware design of high-speed hybrid encryption system based on SM2,SM3 and SM4 algorithm[J].Application Research of Computers,2022,39(9):2818-2825,2831.)
[9]Jin Zheming,Finkel H.OpenCL kernel vectorization on the CPU,GPU,and FPGA:a case study with frequent pattern compression[C]//Proc of the 27th Annual International Symposium on Field-Programmable Custom Computing Machines.Piscataway,NJ:IEEE Press,2019:330.
[10]Mahony A O,Zeidan G,Hanzon B,et al.A parallel and pipelined implementation of a pascal-simplex based two asset option pricer on FPGA using OpenCL[C]//Proc of IEEE Nordic Circuits and Systems Conference.Piscataway,NJ:IEEE Press,2020:1-6.
[11]彭福来,于治楼,陈乃阔,等.面向国产CPU的可重构计算系统设计及性能探究[J].计算机工程与应用,2018,54(23):36-41.(Peng Fulai,Yu Zhilou,Chen Naikuo,et al.Reconfigurable computing system design and performance exploration towards to domestic CPU[J].Computer Engineering and Applications,2018,54(23):36-41.)
[12]Intel Corpration.Intel FPGA SDK for OpenCLTM Pro edition:programming guide 19.3[EB/OL].(2019-10-30).https://www.intel.com/content/www/us/en/docs/programmable/683846/19-3/introduction.html.
[13]Intel Corporation.IntelFPGA SDK for OpenCLTM:IntelStratix 10 GX FPGA development kit reference platform porting guide[EB/OL].(2022-03-28).https://www.intel.com/content/www/us/en/docs/programmable/683809/19-1/gx-fpga-development-kit-reference-platform-21662.html.
[14]Martínez-Herrera A F,Mancillas-López C,Mex-Perera C,et al.GCM implementations of Camellia-128 and SMS4 by optimizing the polynomial multiplier[J].Microprocessors and Microsystems,2016,45:129-140.
[15]王澤芳,唐中剑.SM4算法CTR模式的高吞吐率ASIC实现[J].电子器件,2019,42(1):173-177.(Wang Zefang,Tang Zhongjian.A high-throughput ASIC implementation of SM4 algorithm in CTR mode[J].Chinese Journal of Electron Devices,2019,42(1):173-177.)
[16]何诗洋,李晖,李凤华.SM4算法的FPGA优化实现方法[J].西安电子科技大学学报,2021,48(3):155-162.(He Shiyang,Li Hui,Li Fenghua.The FPGA optimization implementation method of SM4 algorithm[J].Journal of Xidian University,2021,48(3):155-162.)
[17]李晓东,胡一鸣,池亚平,等.基于通用计算平台SM4-CTR算法并行实现与优化[J].密码学报,2022,9(4):663-676.(Li Xiao-dong,Hu Yiming,Chi Yaping,et al.Parallel implementation and optimization of SM4-CTR algorithm based on general computing platform[J].Journal of Cryptologic Research,2022,9(4):663-676.)
[18]杨国强,丁杭超,邹静,等.基于高性能密码实现的大数据安全方案[J].计算机研究与发展,2019,56(10):2207-2215.(Yang Guoqiang,Ding Hangchao,Zou Jing,et al.A big data security scheme based on high performance cryptography[J].Computer Research and Development,2019,56(10):2207-2215.)
收稿日期:2022-12-23;修回日期:2023-02-20 基金项目:国家自然科学基金资助项目(61972180)
作者简介:王腾腾(1993-),男,江苏徐州人,硕士研究生,主要研究方向为计算机体系结构;柴志雷(1975-),男(通信作者),山西人,教授,博士,主要研究方向为计算机体系结构(zlchai@jiangnan.edu.cn).
猜你喜欢
江苏农业科学(2017年16期)2017-10-27 14:08:10
电脑知识与技术(2017年10期)2017-06-05 13:53:15
移动通信(2016年20期)2016-12-10 09:33:12
哈尔滨理工大学学报(2016年4期)2016-11-10 14:32:23
哈尔滨理工大学学报(2016年1期)2016-05-31 22:58:31
电脑知识与技术(2016年3期)2016-04-07 13:52:34
数字技术与应用(2015年12期)2015-12-28 12:21:19
现代电子技术(2015年15期)2015-08-14 22:02:46
现代电子技术(2015年10期)2015-05-29 12:31:25
光学仪器(2014年5期)2014-11-18 20:20:29
