
面向网络舆情分析的多任务学习策略时间卷积网络
2023-10-17 05:50张会云黄鹤鸣
计算机工程 2023年10期
张会云,黄鹤鸣
(1.青海师范大学 计算机学院,西宁 810008;2.藏语智能信息处理及应用国家重点实验室 西宁 810008)
0 概述
在多目标学习领域,CARUANA[1]提出的多任务学习(Multi-Task Learning,MTL)使用单一模型,并同时学习包含在多个相关联任务中的信息,通过共享表示层参数实现信息共享,提高模型在多个任务上的泛化性[2]。
近年来,多任务学习越来越成熟并被广泛应用到人脸表情识别[3]、无人驾驶[4]等诸多领域,但在网络舆情分析领域应用不多,主要的研究有:文献[5]提出交互式的多任务学习模型,通过一组共享的隐变量迭代地传递给不同任务,能够在标记层和文档层学习多个相关任务;文献[6]利用门控循环单元(Gated Recurrent Unit,GRU)捕捉对话的全局上下文信息,通过注意力机制实现模态间的交互,最后结合多任务学习预测情感类型;文献[7]提出一种对抗性多任务学习架构,减轻了共享和私有潜在特征间的相互干扰,该方法在16种分类任务中具有明显优势。
本文根据不同信噪比和噪声类型对基线数据集EMODB 进行数据扩充,在扩充的数据集上提取融合的特征集,同时提出用于情感分类、说话人辨识和性别识别的策略时间卷积网络(Diplomatic Temporal Convolutional Network,DTCN)来增强多任务学习性能。
1 数据集与特征提取
DTCN 模型的性能主要在德语语音情感数据集EMODB[8]上进行验证。数据集EMODB包含10 位说话人(5 男5 女)和7 类情感,即中性(Neutral/N)、愤怒(Anger/A)、恐惧(Fear/F)、高兴(Happiness/H)、悲伤(Sadness/S)、厌恶(Disgust/D)和无聊(Boredom/B),每类情感包含的样本数量依次为79、127、69、71、62、46、81。
为了充分验证DTCN 模型的鲁棒性和泛化性,本文对数据集EMODB 进行扩充。首先,根据数据集EMODB 分别在-10、-5、0、5 和10 dB 信噪比(Signal-to-Noise Ratio,SNR)下利用噪声库NoiseX-92[9]中的15 种噪声进行扩充,得到5 个单信噪比含噪数据集,分别记为EMODB-10、EMODB-5、EMODB0、EMODB5 以及EMODB10,每个数据集中的样本数是数据集EMODB 中样本数的15倍;其次,合并5个单信噪比含噪数据集,构建多信噪比含噪数据集EMODBM,EMODBM 的样本数是数据集EMODB 样本数的75倍。基线数据集EMODB 及相应的扩充数据集中各类样本数量占比相同,如图1所示。
具体来说,在SNR=-10 dB 条件下,首先采用Babble 噪声对基线数据集EMODB 中的每类情感(如愤怒、开心等7 类)样本依次加噪,这样将获得包含Babble 噪声的含噪数据集EMODB,记为B-EMODB,该数据集与基线数据集EMODB 中的样本数量相同。此时,由于对每类情感的每条样本只是添加了Babble 噪声,因此各类情感样本数量并未增加,情感类别也未发生改变。相应地,依次向基线数据集EMODB 添加White、Pink、Factory1 等剩余的14 种噪声,同样,每添加一种类型的噪声,就会形成包含某一类型噪声的含噪数据集,依次记为W-EMODB、P-EMODB、F-EMODB等。在每种噪声下构建的含噪数据集中的各类样本数量均相同,只是噪声类型不同。其次,将不同类型噪声的含噪数据集按照情感类别合并,此时构建的数据集称为EMODB-10。该数据集是对各类情感的所有样本均进行加噪,样本数量增加的倍数等于噪声的种类数,即各类情感样本数量随噪声种类的增加等比例增加。
韵律特征和谱特征是语音的主要特征。首先提取5 维的韵律特征,即音高(Pitch)和过零率(Zero Crossing Rate,ZCR)的低级描述符(Low-Level Descriptor,LLD),并计算这些LLD 的高级统计函数(High-level Statistic Function,HSF)。然后提取214 维的谱特征:即频谱平坦度(Flatness)、梅尔频率倒谱系数(Mel Frequency Ceptrum Cofficient,MFCC)、谱重心(Centroid)、色谱图(Chroma)、幅度(Amplitude)、梅尔频谱(Mel)以及谱对比度(Contrast)等特征的LLD,并计算这些LLD 的HSF。如表1 所示,融合这些韵律特征和谱特征的HSF 作为DTCN 模型的输入。
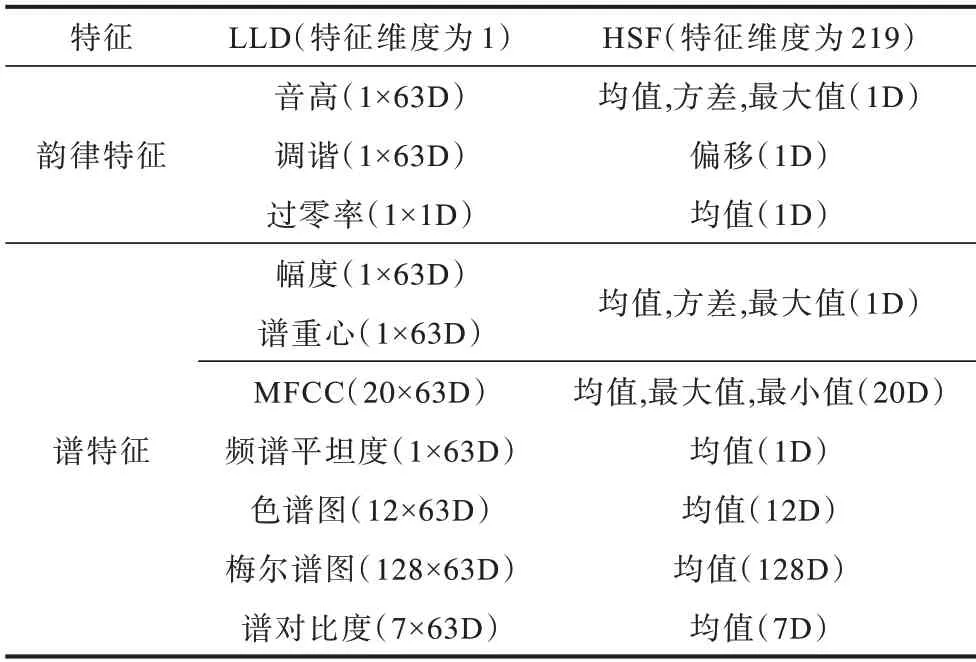
表1 低级描述符与高级统计函数特征Table 1 Low-level descriptor and high-level statistical function features
2 策略时间卷积网络
循环神经网络(Recurrent Neural Network,RNN)通过门控结构保留历史信息,实时更新模型参数[10],但RNN 存在模型训练时间较长、模型构建时定性参数较多、内存消耗较大、梯度消失或梯度爆炸等缺点。文献[11]提出的时间卷积网络(Temporal Convolutional Network,TCN)有效地避免了时间序列建模中出现的梯度消失或梯度爆炸问题[12],在时序预测方面引起了巨大反响。
模型TCN 的结构简单,参数较少,对单任务的学习能力较强,但对多任务的非线性映射能力较弱。本文提出的基于模型TCN 的策略时间卷积网络能够有效提升模型在多任务学习中的并行处理能力。DTCN 模型结构如图2 所示。
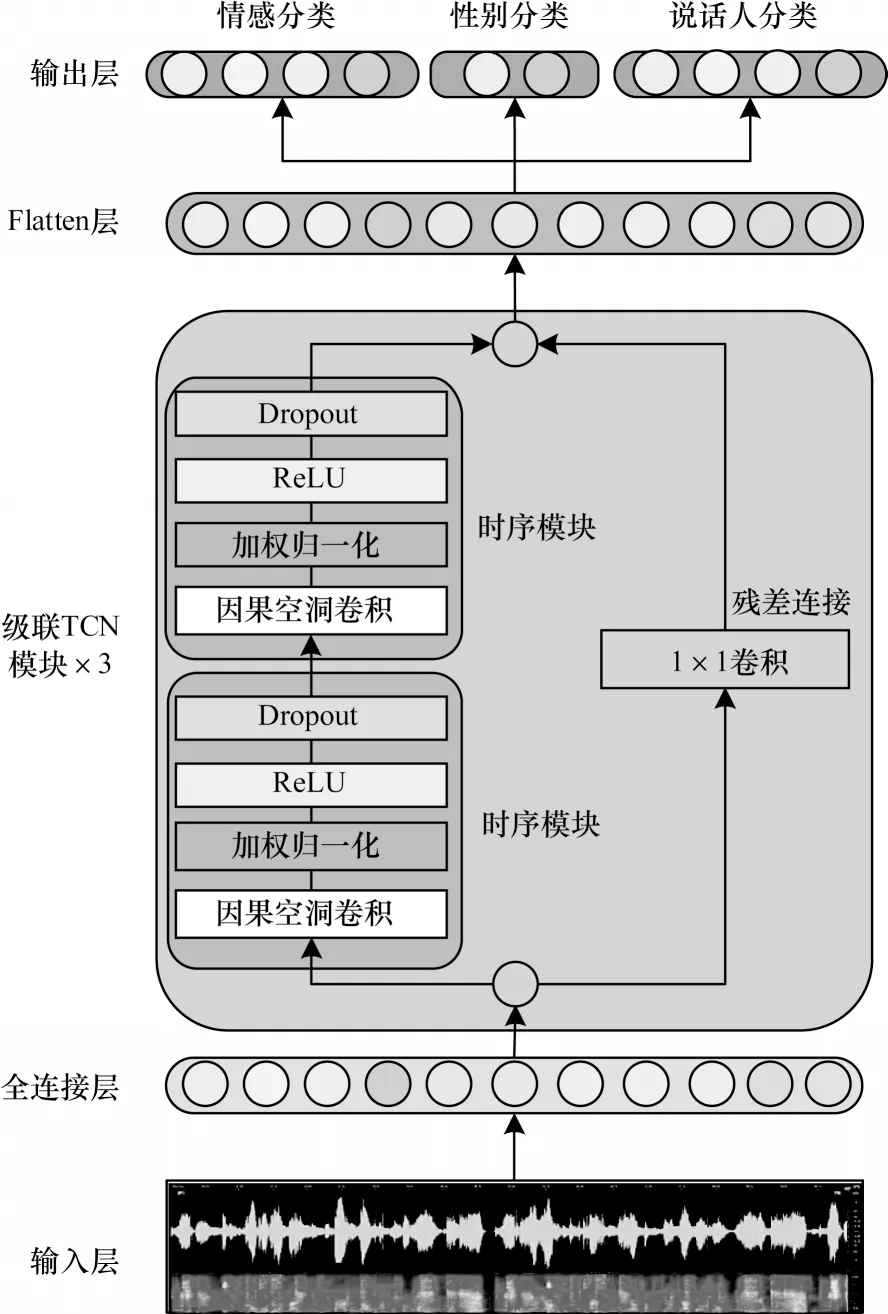
图2 DTCN 模型的结构Fig.2 Structure of the DTCN model
DTCN 模型由全连接层、级联TCN 模块、Flatten层以及多任务输出层构成。其中,级联TCN 模块由3 个堆叠的TCN 构成,核心结构是时序模块和残差连接。时序模块由因果空洞卷积、加权归一化、ReLU 和Dropout构成。
通过硬参数共享、残差模块、激活函数ReLU 以及Adam 优化器等机制,可有效提升DTCN 模型对多任务的并行处理能力。通过硬参数共享机制,DTCN 模型减少了参数,保证了各个任务互相充分挖掘有用信息;残差模块[13]在很大程度上避免了网络层数加深引起的梯度爆炸或梯度消失问题;通过使用激活函数ReLU[14]使DTCN 模型避免了单纯的线性组合,具有较强的非线性映射能力,提升了模型的整体表达能力;Adam 优化器[15]能够避免网络学习进入局部最优或鞍点。
2.1 因果卷积
因果卷积[16]是指DTCN 模型中时序模块的上下层神经元之间存在因果关系,而且当前网络层t时刻的值仅与先前时刻的值有关,这意味着数据信息的传递是单向的,如图3 所示。
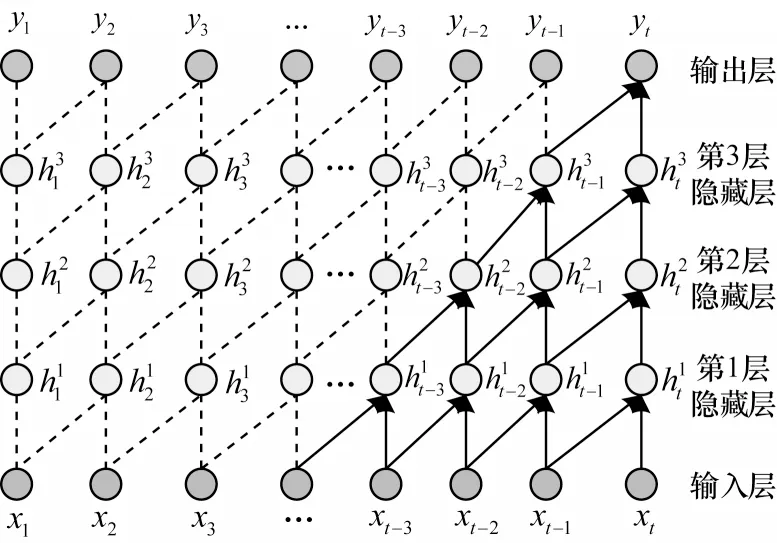
图3 因果卷积的可视化Fig.3 Visualization of causal convolution
DTCN 模型中的因果卷积能较好地处理时序问题,它能根据时间序列X=(x1,x2,…,xt)预测输出Y=(y1,y2,…,yt)。令滤波器F=(f1,f2,…,fK),K为卷积核大小,则xt的因果卷积如下:
假设输入层最后两个节点为xt-1和xt,第1 个隐藏层的最后一个节点为,滤波器F=(f1,f2),则根据式(1)有:时刻t的输出来自前一层中的时刻t和更早时刻的元素卷积,是一种严格的时间约束模型。此外,时序模块中隐藏层越多,追溯的历史信息越多。例如,第2 个隐藏层的最后一个节点关联了输入的3 个节点,即xt-2、xt-1和xt;输出层最后一个节点关联了输入层的5 个节点,即xt-4、xt-3、xt-2、xt-1和xt(实心箭头关联的节点)。
2.2 因果空洞卷积
单纯的因果卷积对时间的建模长度受限于卷积核大小。线性堆叠更多的层能够扩大感受野,从而捕获更长的依赖关系,但这会增加网络层数,加大反向训练难度,导致梯度消失、训练复杂、拟合效果差等问题。为此,在DTCN 模型的时序模块中引入了空洞卷积[17-18]。
空洞卷积允许对输入进行间隔采样,通过设置空洞系数d将每两个相邻层之间卷积神经元的数量减少为原来的1/d。随着网络层数的增加,有效窗口的数量大幅增长。这意味着引入空洞卷积后,相同深度的网络可以获得更大的视野。图4 所示为空洞卷积计算过程。
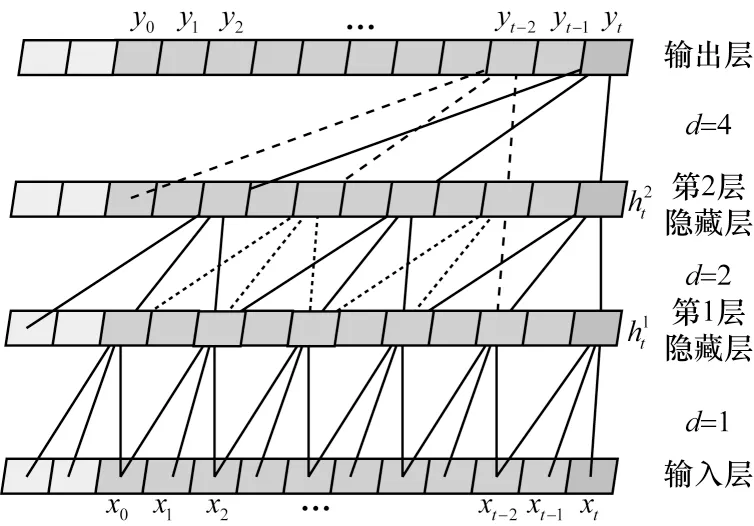
图4 空洞卷积的可视化过程Fig.4 Visualization process of dilated convolution
因果空洞卷积[19-20]允许卷积时的输入存在间隔采样,采样率受空洞率d的控制。输入层的空洞率为d=1,表示输入时每个点都采样;第1 个隐藏层的空洞率d=2,表示输入时每2 个点采样1 个作为输入。一般来讲,层数越高对应的空洞率d越大。空洞卷积使得有效窗口的大小随着网络层数的增加而呈指数型增长,从而用比较少的层获得更大的感受野。
令输入序列X=(x1,x2,…,xt),滤波器F=(f1,f2,…,fK),当空洞率为d时,xt处的因果空洞卷积如下:
具体来说,当空洞率d=1时,因果空洞卷积是简单的因果卷积,此时第1 个隐藏层的最后一个节点关联了输入的3 个节点;当空洞率d=2时,第2 个隐藏层的最后一个节点关联了输入的7 个节点,关联了第1 个隐藏层的3 个节点,根据式(2)有=f1xt-2d+f2xt-d+f3xt(d=2)。通常,因果空洞卷积的感受野大小为(K-1)d+1。其中,K表示卷积核大小,d以2 的指数增长,依次取1、2、4。由于采用了空洞卷积,每一层都要填充,填充大小为(k-1)d。
2.3 残差模块
残差网络[21-22]具有非常强大的表达能力,使得网络以跨层跳跃的方式传递信息,解决了深层网络训练时存在的梯度问题。因此,在DTCN 模型中引入残差模块结构,如图5 所示。残差模块由左右2 个分支构成:左分支由2 个时序模块构成,右分支由1×1 卷积构成。每个时序模块由卷积和ReLU 非线性映射构成,并在每层中引入了权重归一化和Dropout 来正则化网络。若输入通道的数量与第2 个时序模块中空洞卷积的滤波器数量不同,则启用右分支,将卷积输出和输入元素相加,确保残差连接有效。
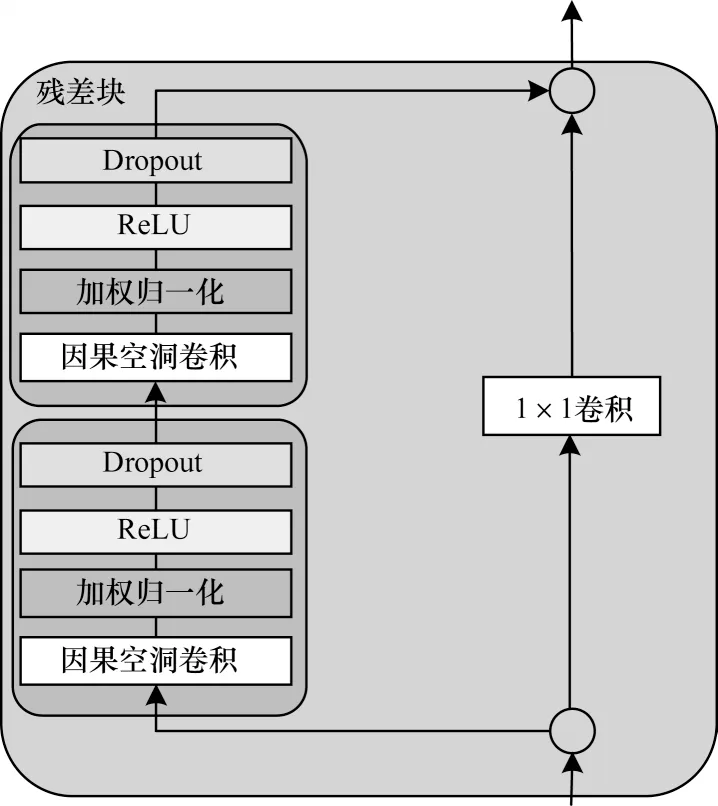
图5 残差块的结构Fig.5 Structure of residual block
级联TCN 模块使用残差连接构建深层网络。对左分支中输入残差块的序列yt按照式(3)进行计算:
其中:Wa、Wb分别表示两个时序模块中卷积层权重向量;右分支是残差块中的一维全卷积操作,确保输入序列yt和输出序列yt+1具有相同长度。残差块计算如下:
3 实验结果与分析
3.1 实验设置
实验采用一台服务器进行计算,CPU 为40 核80 线程,内存为64 GB。通过深度学习框架Keras[23]搭建模型DTCN,使用RTX 2080 Ti GPU 进行训练。
在本文研究中,优化器为Adam[24],迭代周期(Epoch)为100,批处理(Batch Size)为256,损失函数为交叉熵,用5 次实验结果的平均值来刻画模型的整体性能。
DTCN 模型同时对情感类别、说话人和性别进行多任务学习。其中,情感类别数为7,说话人类别数为10,性别类别为2。当特征维度为219时,DTCN 模型的参数量为532 883;当特征维度增加到233 时(增加了谱对比度的最大值和方差特征),模型DTCN 的参数量为566 931。
3.2 结果分析
为了验证模型DTCN 在多任务学习中的效果,依次进行消融研究、泛化性验证和鲁棒性验证,并与同类模型的性能进行对比。
1)消融研究:选择最优模型,特征维度为219,通过在数据集EMODB0 上进行多任务识别,选择最优DTCN 模型,取5 次实验的均值和标准差衡量模型的分类性能。
2)泛化性验证:验证DTCN 模型在用不同方法扩充后的数据集上的性能,特征维度分别为219和233。
3)鲁棒性验证:选 择NoiseX-92中的Babble、Pink、White 以及Factory1 噪声,分别验证这4 种噪声及由它们构成的混合噪声对模型性能的影响。
4)对比DTCN 模型与同类模型AHPCL、HMN、MA-CapsNet 的性能。
3.2.1 消融研究
表2 所示为模型TCN1、TCN2、TCN3、Dense1、Dense2、Dense3 及DTCN 在数据集EMODB0 上的多任务分类性能(表中数据为Avg±Std)。图6 所示为上述模型在数据集EMODB0 上进行5 次实验的分布。其中,TCN1 模型中滤波器的数量为32,核大小为4,空洞率依次为1、2、4、8;TCN2 由两层TCN1 构成;TCN3由三层TCN1构成;Dense1模型由一层 包含128 个神经元节点的全连接网络构成,模型Dense2 由两层Dense1构成,Dense3 模型由三层Dense1构成;DTCN 由一个全连接 层、3 个级联的TCN 模块、Flatten 层及输出层构成。
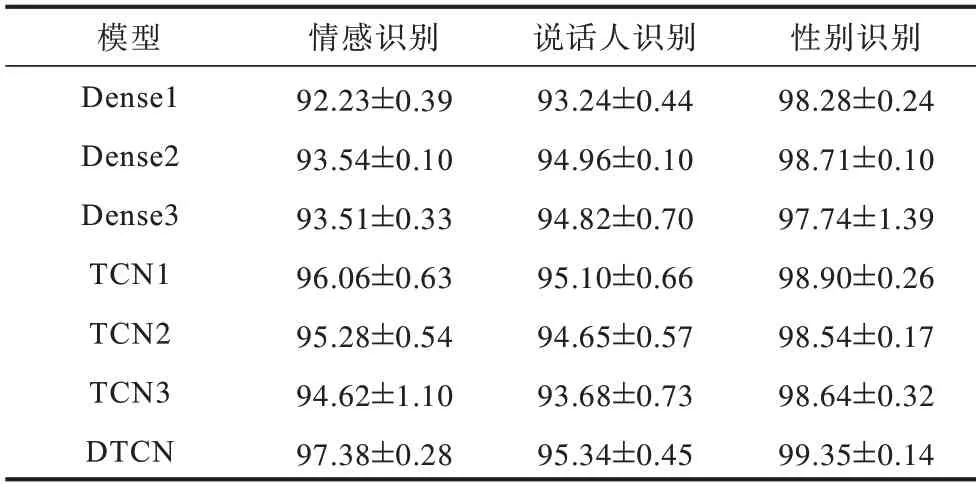
表2 不同模型在数据集EMODB0 上的多任务识别结果Table 2 Multi-task recognition results of different models on the dataset EMODB0 %

图6 不同模型在数据集EMODB0 上的多任务识别准确率Fig.6 Multi-task recognition accuracy of different models on dataset EMODB0
从表2 和图6 可以看出:
1)在多任务学习过程中,所有模型的稳定性均较好,且对多任务学习的性能均达到了90%以上,对性别的分类性能优于对说话人和情感识别的性能。其中,全连接网络对说话人的区分能力优于对情感类别的区分能力,而TCN 及其相关衍生类模型则相反;结合全连接层和TCN 的模型能更好地区分情感类别和说话人。
2)绝大多数模型对说话人识别的鲁棒性较低,对性别识别的鲁棒性最高。因为说话人类别数较多(包含10 个类别),识别难度较大;而性别仅有两类,识别难度大幅降低。
3)在7 类模型中,DTCN 模型的多任务学习性能最好,对情感、说话人以及性别的识别准确率依次为97.38%、95.34%、99.35%,这是一个非常理想的结果。
3.2.2 模型的泛化性
为验证DTCN 模型的泛化性,分别采用219D 特征和233D 特征详细对比DTCN 模型在基线数据集EMODB 和扩充数据集EMODB-10、EMODB-5、EMODB0、EMODB5、EMODB10 及EMODBM上的性能,如表3、图7 所示,其中,图7 横坐标表示在不同SNR 下构建的数据集。从表3 和图7 可以看出:
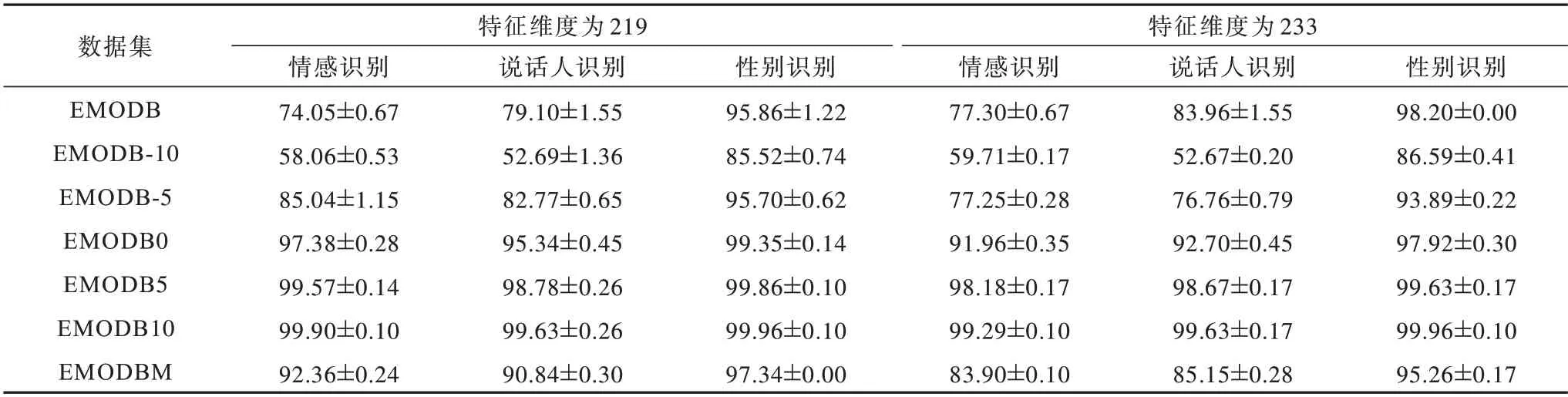
表3 DTCN 模型在基线数据集EMODB 及其扩充数据集上的性能对比Table 3 Performance comparison of DTCN model on baseline dataset EMODB and its augmented datasets %
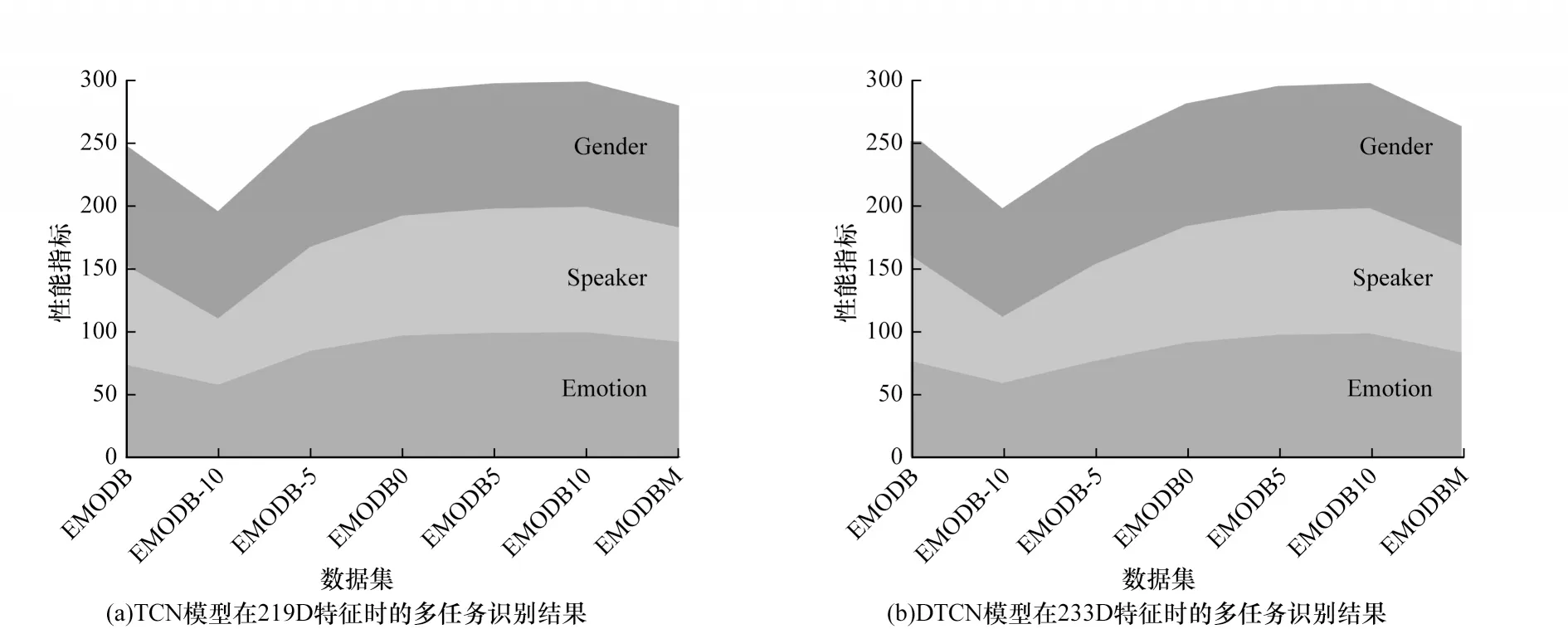
图7 DTCN 模型在扩充的数据集EMODB 上的多任务识别结果Fig.7 Multi-task recognition results of DTCN model on the augmented dataset EMODB
1)在基线数据集EMODB 和扩充数据集EMODB-10上,DTCN 模型在233D 特征上的性能较大程度上优于219D 特征上的性能,而在其他扩充数据集上,模型在219D 特征上性能较好。
2)DTCN 模型的性能与信噪比成正相关:使用不同SNR 对数据集进行扩充时,随着SNR 的增大,模型的性能线性提升;当SNR 为10 dB时,无论采用219D 特征还是233D 特征,模型的多任务学习能力均取得了非常理想的效果。其中,在233D 特征下,DTCN 模型对多任务学习的稳定性最高。
3)从图7 可以看出,无论采用哪一种特征向量,模型的多任务学习能力随SNR 的变化趋势相同。其中,当采用219D 的特征向量时,模型在不同SNR 下对情感的区分能力优于对说话人的区分能力;当SNR≥-5 dB时,模型对情感和对说话人的区分能力非常接近。
3.2.3 模型的鲁棒性
为了验证不同类型噪声对模型性能的影响,在限定SNR 为10 dB 条件下,对数据集EMODB 分别添加Babble、Pink、White 及Factory1 噪声,当特征维度为233时,模型DTCN 在这些含噪数据集上的性能对比分别如表4 和图8 所示,其中,No 表示未加噪声的情况。从表4 和图8 可以看出:
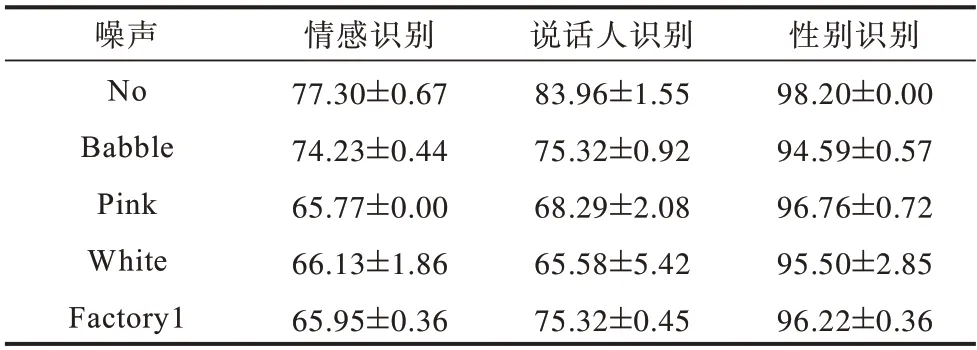
表4 DTCN 模型在SNR=10 dB 下对数据集EMODB 使用单一噪声的实验结果Table 4 Experimental results of the DTCN model using single noise on the dataset EMODB under the SNR=10 dB %
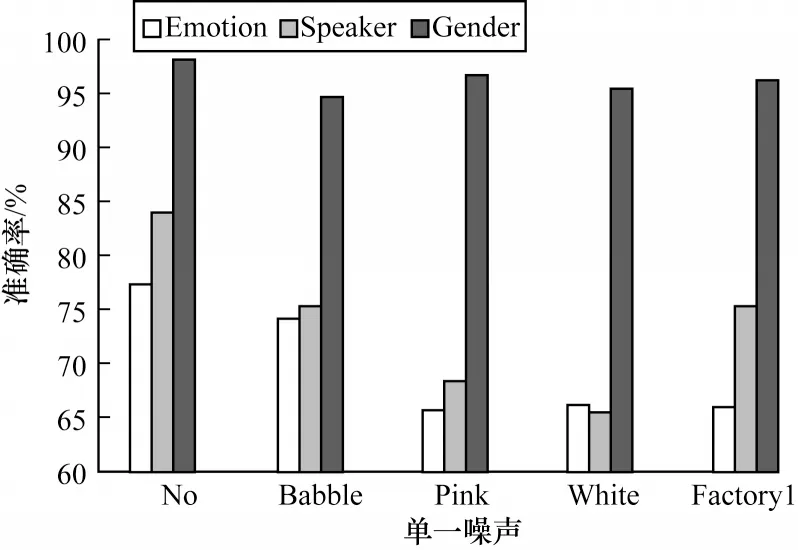
图8 不同噪声下DTCN 模型对多任务的识别结果Fig.8 Results of DTCN model for multitask recognition under the different noise
1)不同噪声对模型性能的影响程度不一,Babble噪声对模型性能的干扰较小,Pink 噪声对情感识别的影响较大,White噪声对说话人识别的影响较大。
2)DTCN 模型在Pink 和Factory1 噪声下进行多任务学习时的鲁棒性较好,而在White噪声下鲁棒性较差。
3)DTCN 模型对性别的识别性能最高,对情感识别的性能最差。
为进一步验证噪声对DTCN 模型性能的影响,当SNR 为10时,对数据集EMODB 分别添加Babble、Pink、White 及Factory1 噪声,通过合并得到的含噪数据集,构建了10 种混合噪声下的样本数据集。表5 和图9 所示为DTCN 模型在这些混合噪声下的识别性能。其中,特征向量维度为233,B、P、W和F 分别表示对数据集EMODB 添加Babble、Pink、White 和Factory1 噪声。BP 表示对数据集EMODB添加了Babble 噪声和Pink 噪声后的混合而成的数据集,PW、BW、PF、BF、WF、BPW、BPF、BPWF 与BP 定义相似。从表5 和图9 可以看出:

表5 DTCN 模型在混合噪声数据集上的识别精确率Table 5 Performance of the DTCN model on the hybrid noisy datasets %

图9 混合噪声下DTCN 模型对多任务识别的影响Fig.9 Performance of DTCN model for multitask recognition under the hybrid noise
1)随着噪声种类的增加,DTCN 模型的多任务学习能力明显提升。对情感、说话人以及性别的识别精确率最高可达95.87%、97.86%和99.54%,这可能是因为随着噪声种类的增多,训练样本数量成倍增加,模型能够得到更充分的训练。
2)随着噪声种类的增加,模型的鲁棒性逐渐增强。在绝大多数情况下,模型对说话人的识别效果优于对情感的识别效果,这可能是因为说话人之间的特征差异较大且所提取的特征能够更好地区分说话人。
3.2.4 与同类模型的性能对比
为了全面评估DTCN 模型的多任务学习能力,表6 对比了特征维度为233 时DTCN 模型与同类模型HMN[25]、AHPCL[26]、MA-CapsNet[27]、CNN[28]、LSTM[29]、GRU[30]、BiLSTM[31]以及BiGRU[32]对多任务的分类性能。从表6 可以看出:与上述研究的同类模型相比,DTCN 模型的性能均优于其他几种模型且复杂度较低,说明DTCN 模型能够更有效地捕获数据的时序信息,而且DTCN 模型所花费的时间最少。另外,CNN 比各种循环网络的变体(如LSTM、GRU、BiLSTM、GRU)更有效。
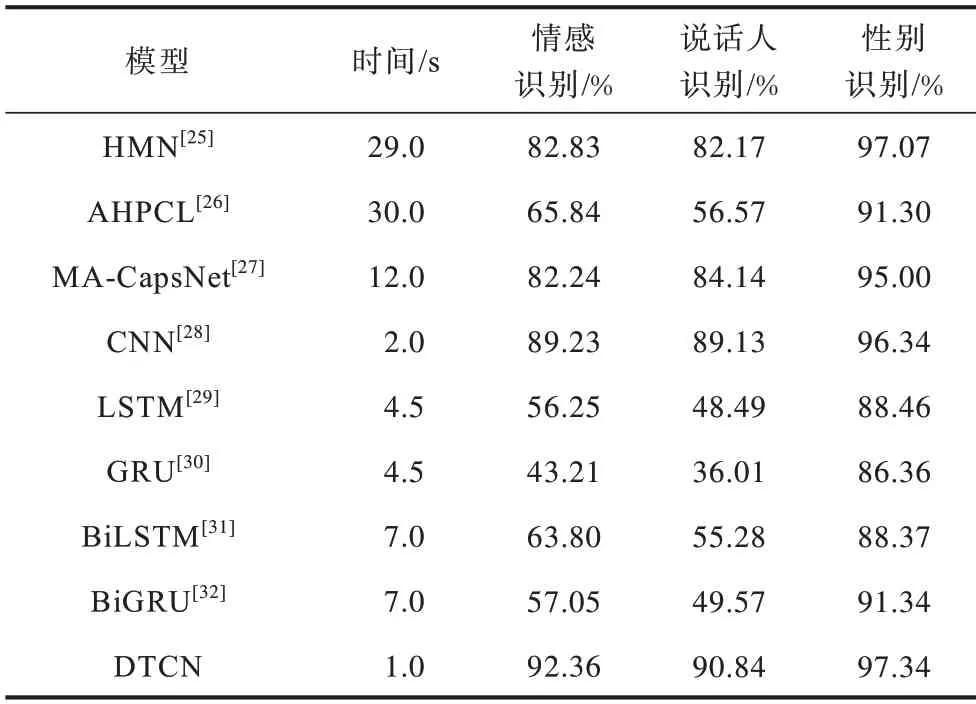
表6 在数据集EMODBM 上使用不同模型进行多任务识别的性能Table 6 Multi-task recognition performance of different models on the dataset EMODBM
4 结束语
本文提出一种新的用于情感分类、说话人识别和性别识别的DTCN 多任务学习模型,并设计数据增强技术,在不同信噪比下采用加噪的方式对数据集EMODB 进行扩充,验证不同噪声对多任务学习能力的影响。实验结果表明,DTCN 模型在多任务学习中取得了较好的效果,当SNR>0时,DTCN 模型的多任务学习能力优于基线,且随着噪声种类的增多,DTCN 模型的多任务学习能力越来越强,在混合噪声下,DTCN 模型的鲁棒性和泛化性更好。下一步将研究DTCN 模型在数据集CASIA 和SAVEE 上的多任务学习能力,并探究更有利于多任务学习的特征。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中国生物医学工程学报(2019年6期)2019-07-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
新闻传播(2015年20期)2015-07-18
电视技术(2014年19期)2014-03-11
计算机工程(2014年6期)2014-02-28
