
基于图像降噪与压缩的对抗样本检测方法
2023-10-17 05:50王飞宇张帆杜加玉类红乐祁晓峰
计算机工程 2023年10期
王飞宇,张帆,杜加玉,类红乐,祁晓峰
(1.信息工程大学 信息技术研究所,郑州 450002;2.国家数字交换系统工程技术研究中心,郑州 450002;3.网络通信与安全紫金山实验室,南京 211111)
0 概述
近年来,深度学习[1]的发展十分迅速,被广泛应用于自然语言处理[2]、语音识别[3]、计算机视觉[4]等领域,特别是在许多图像分类任务中,深度学习的能力甚至能够超越人类。然而,深度学习的不可解释性导致输出缺乏可信性。因此,将深度学习模型应用于实际的生活场景中,如自动驾驶汽车[5]、生物医学[6]等,须着重考虑该模型的安全性和可靠性[7-8]。文献[9]提出对抗样本的概念。研究人员指出,在面对对抗样本时,深度学习模型会表现得非常脆弱。文献[5]中在“停止”的路牌上,攻击者添加一些扰动标记(不影响人眼判断)后,无人驾驶汽车会把该路牌识别为“限速”,从而可能造成严重的安全事故。因此,有效防御对抗样本已成为人工智能安全领域的重点。
图像分类中防御对抗样本的方法[10-11]可分为完全防御和检测防御。检测防御因其不影响模型正常工作的特点而得到研究人员的广泛关注。文献[12]提出对抗性检测网络(Adversary Detection Network,ADN),该方法在模型中附加ADN 来检测对抗样本。ADN 是二分类器,将模型某个中间层的输出作为输入进行训练。文献[13]从隐写术的角度分析输入来检测对抗样本,隐写分析通过对自然图像相邻像素间的相关性建模来检测由对抗攻击所引起的修改。该方法利用正常样本和对抗样本的隐写分析特征来训练分类器。文献[14]使用最近邻影响函数(Nearest Neighbors Influence Function,NNIF)来检测对抗样本,正常样本的最有用与最近邻的训练样本在PCA 嵌入空间中非常接近,但是对抗样本没有表现出这种特性。上述方法虽然检测性能较优,但是存在依赖已知的对抗样本或计算时间过长的问题。
针对以上检测方法的不足,本文提出一种基于图像降噪与压缩的检测方法,利用图像降噪或压缩方法破坏对抗扰动或提取必要特征的特性来压缩对抗样本可利用的特征空间,通过比较原样本与压缩特征空间后的样本在深度学习模型中的预测差来判断该样本是否为对抗样本。由于该方法未改变原分类模型,因此能够与其他防御方法相结合进行协同防御。
1 相关工作
1.1 对抗样本
对抗样本是由SZEGEDY等[9]发现并提出的。对抗样本是指在正常样本上故意添加细微的人眼难以察觉的扰动后形成的样本,而且该样本可以让目标模型高置信度地给出错误输出。生成的对抗样本使目标模型误判的攻击就是对抗攻击。
1.2 经典的对抗攻击方法
自L-BFGS 算法[9]提出以来,对抗攻击算法[15-16]发展迅速。目前经典的对抗攻击方法主要有快速梯度符号法(Fast Gradient Sign Method,FGSM)、BIM、C&W、DeepFool、JSMA。
文献[17]提出FGSM,该方法的原理是先对输入求出其损失函数的梯度,然后选择1 个超参数与该梯度的符号向量相乘,从而产生1 个扰动。该方法的攻击成功率与选择的超参数有关。FGSM 能快速产生对抗样本,但攻击性能难以保证,其生成的对抗样本可描述如下:
文献[18]提出BIM 攻击方法,该方法由FGSM衍生得出,沿着输入损失函数的梯度增加方向,迭代设计多步的小扰动,而且在完成每一小步后,都会重新计算该损失函数的梯度方向。该方法生成的对抗样本可描述如下:
其中:i为迭代次数;x0=x为正常输入;Clip 为裁剪函数,可将扰动限制在像素点的ε邻域内。相比FGSM,BIM 能生成更精准的扰动,但是计算量较大。
文献[19]提出C&W 攻击方法,该方法通过限制L0、L2 或L∞范数来优化扰动,其目标函数包含最大化损失函数和最小化扰动的优化问题。该方法生成的对抗样本可描述如下:
其中:D(·)为距离度量的函数;x为正常样本;t为对抗样本;δ为每次迭代所添加的扰动;参数c可控制添加的扰动值与错误分类置信度间的平衡;f(·)为设计的目标函数。f(·)定义如下:
其中:Z(·)为Softmax 前一层的逻辑值;i为标签类别;t为目标攻击的标签类别;参数k能控制对抗样本被误判的置信度,k越大,对抗攻击的成功率越高。该方法攻击效果较好,但成本较高。
文献[20]提出DeepFool 攻击方法,该方法根据正常样本到对抗样本决策边界的最小距离来设计扰动,在多次迭代后,正常样本会越过某决策边界,从而达到使目标模型分类错误的攻击目的。该方法生成的扰动比较精确,但它不能进行目标攻击。
文献[21]提出JSMA 攻击方法,认为不同的输入特征对目标模型输出的影响程度不同。该方法首先通过计算前向导数得到目标模型的雅可比矩阵;然后利用该雅可比矩阵构造对抗性显著图,该对抗性显著图可体现输入特征对目标模型输出的影响程度;最后选择对抗性显著值最大的像素来设计对抗扰动。该方法能进行目标攻击,但可迁移性较差。
1.3 现有的对抗样本防御手段
在图像分类中,对抗样本防御方法的研究主要包括完全防御和检测防御2 个方面。
完全防御是让模型在处理对抗样本时仍输出其正确的标签,主要分为对抗训练、梯度掩蔽和输入转换3类。对抗训练[17]是在模型的训练阶段加入带有正确标签的对抗样本。该方法实现简单,但是需要大量的对抗样本对原模型重新训练,成本较高。梯度掩蔽是通过遮掩模型的梯度来防御对抗攻击。文献[22]提出防御性蒸馏,该方法利用蒸馏算法为原模型训练蒸馏模型,可降低模型对输入扰动的敏感性,但是对抗样本具有可迁移性,这类方法依然能被攻破。输入转换是在测试阶段对输入样本进行转换以减少对抗扰动,并将处理后的样本输入到原模型中进行预测。文献[23]提出像素偏转,该方法首先利用语义图与随机化选择少量像素,然后将其替换为相邻像素,最后通过小波去噪消除噪声。该类方法不须改变原模型,但是会影响正常样本的分类。
检测防御是判断样本是否为对抗样本,主要分为基于度量的方法与基于预测不一致的方法。基于度量的方法是识别对抗样本与正常样本特征之间的区别,从而利用可区分两者的特征来训练检测器。文献[24]利用对抗样本的局部内在维度(Local Intrinsic Dimensionality,LID)值大于正常样本的特性来检测样本的对抗性,其中,LID 值可根据该样本与其邻近样本的距离来近似估计。但是此类方法依赖已知的对抗样本进行训练。基于预测不一致的方法是利用转换方法对样本进行处理,并将模型对处理前后样本的输出结果进行比较,若有显著变化,则视其为对抗样本。文献[25]首先随机擦除样本中的某些像素,然后利用修复技术进行恢复,最后通过分析原样本和经过该处理后样本的分类结果来检测对抗样本。研究发现,对抗样本在这种处理前后通常会有不同的分类结果,而正常样本没有。这类方法无须对抗样本来训练检测器且具有较优的检测效果,但其性能高度依赖设计的转换方法。
2 对抗样本检测方法
2.1 检测原理
文献[26]认为对抗样本的攻击面与输入特征的维度有关,即输入特征的维数越大,对抗样本的攻击面就越大。自编码器可以重构输入,在降维和去噪方面具有较优的性能。因此,本文引入2 种具有简单结构的自编码器,并让它们与像素深度压缩与非局部均值平滑方法一起来减少样本中不必要的特征。利用以上图像降噪或压缩方法对输入样本进行处理,使得对抗样本的可用攻击面减少,从而让处理前后的对抗样本在深度学习模型中的分类结果产生较明显的变化。由于在正常样本中不存在攻击者精心设计的对抗扰动,而且这些方法都是去除样本中的不必要特征,因此处理前后的正常样本在深度学习模型中的分类结果变化较小。基于上述原理,本文利用深度学习模型对压缩特征空间前后正常样本的预测差来训练检测器的阈值,若输入样本的预测差大于阈值,则为对抗样本。
通过不同的图像降噪或压缩方法删除样本中不必要特征的能力是有区别的,因此,各单一方法的检测效果不同。为提升检测器的检测能力,本文结合这些方法对输入进行处理,并在这几个经各单一方法得到的预测差中选择最大值来训练检测器。
2.2 图像降噪与图像压缩技术
图像降噪就是利用传统降噪方法或深度学习降噪方法对图像进行降噪,能够减少对抗扰动,从而去除图像中不必要的特征。常见的降噪方法有自编码器和非局部均值平滑。
自编码器是一类常用于半监督学习和无监督学习的人工神经网络,分为编码器和解码器2 个部分。编码器主要负责获取输入在隐含层的特征,解码器主要负责将编码器获取的隐含层特征尽可能地还原为原始输入。自编码器作为一种有损的数据压缩算法,能够压缩输入信息并提取有用的输入特征,常被用于数据降噪和降维。为减少图像或视频信号空间信息丢失且有效学习到鲁棒性较强的有用特征,研究人员提出卷积自编码器[27]和降噪自编码器[28]。卷积自编码器与传统自编码器类似,不同的是卷积自编码器利用卷积神经网络的卷积与池化对输入进行特征提取。降噪自编码器会给输入数据添加1 个随机的噪声扰动,从而使学习到的自编码器具有更强的泛化能力。本文设计的降噪自编码器与卷积自编码器的结构相似,不同之处在于:降噪自编码器在卷积自编码器的第1 层前加入Dropout层,而且它的输入是在卷积自编码器输入的基础上添加随机高斯噪声。本文设计的自编码器结构如图1 所示。

图1 本文自编码器结构Fig.1 Auto-encoder structures in this paper
非局部均值平滑的基本思想:对图像中像素的估计值是由图像中与它具有相似邻域结构的像素进行加权平均后得到的。非局部均值平滑执行过程如图2 所示。
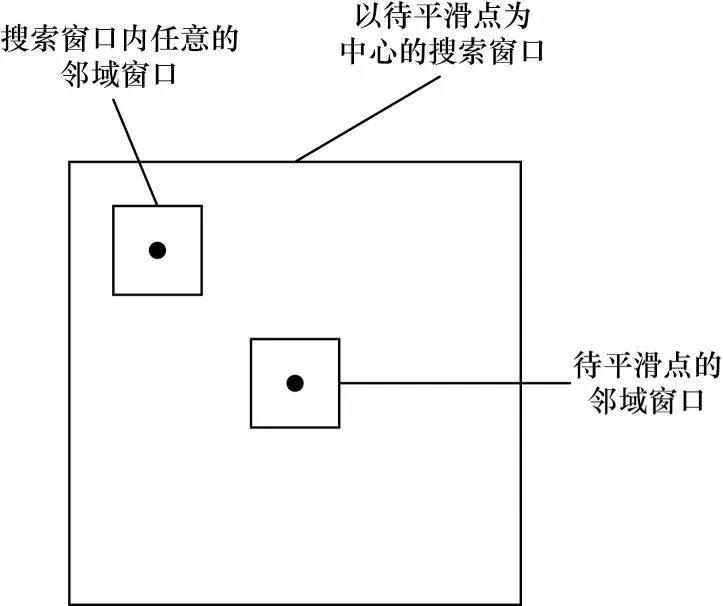
图2 非局部均值平滑的执行过程Fig.2 Executive process of non-local means smoothing
该方法利用整幅图像进行去噪,从效率方面考虑,通常会设搜索窗口和邻域窗口2 个固定尺寸的窗口。不以待平滑点为中心的邻域窗口会在以待平滑点为中心的搜索窗口中进行滑动。根据该邻域窗口与以待平滑点为中心的邻域窗口的相似程度来确定权值,相似程度越大则权值越大。该方法能够充分利用图像中的冗余信息,不仅可以有效去噪,而且可以较完整地保留图像的细节特征。
图像压缩可以去除图像中的多余数据,以及删除输入中的不必要特征。本文选用的压缩方法是像素深度压缩,其原理是减少表示图像像素的颜色深度,常见的深度有24 bit、8 bit等。在现实生活中,像素深度较大的图像与人眼中的自然图像更接近,但是识别图像并不需要很大的像素深度,例如,人们能识别很多黑白图像(像素深度为1 bit)。像素深度压缩的图像示例如图3 所示。本文将MNIST 的“5”和CIFAR-10“狗”的像素深度压缩至1~8 bit。图3 从右向左依次为压缩像素深度1~8 bit 的图像。从图3 可以看出,经合适的像素深度压缩后的图像仍能被人们识别。

图3 像素深度压缩的图像示例Fig.3 Image examples with pixel depth compression
2.3 检测器的实现
基于第2.1 节的原理,本文检测方法可分为2 个阶段,具体流程如图4 所示。在训练阶段,首先让深度学习模型预测用于训练的正常样本(训练样本),得到预测结果p0(可能类别的概率分布)。利用图像降噪或压缩方法对训练样本进行处理,并得到它们在深度学习模型中的预测结果p1,2,…,n。利用L1 范数衡量模型对压缩特征空间前后训练样本的预测差d1,2,…,n=‖p1,2,…,n-p0‖1。联合检测方法将某训练样本的max(d1,2,…,n)作为该样本的预测差。最后,各检测方法根据设定的假阳性率(低于5%)在得到的预测差中选择对应值作为阈值(各单一检测方法的阈值为T1,2,…,n,联合检测方法的阈值为Tmax)。在测试阶段,通过对测试样本(包含正常样本和对抗样本)进行与训练样本相同的处理,得到深度学习模型对压缩特征空间前后测试样本的预测结果为和,并 用L1 范数衡量它们 之间的预测差联合检测方法 将某测试样本 的max(作为该样本的预测差,最后将或max()分别与阈值T1,2,…,n或Tmax进行比较,若其大于阈值,则判断该测试样本为对抗样本,否则为正常样本。

图4 本文方法的检测流程Fig.4 Detection procedure of the proposed method
3 实验与结果分析
本节将在MNIST 和CIFAR-10 上验证本文方法的有效性。本节实验分为3 个部分:1)利用降噪或压缩方法对正常样本和对抗样本进行压缩特征空间的对比实验并分析;2)在2 个数据集上使用各单一检测方法和联合检测方法进行对比实验并分析;3)将本文方法与其他检测方法进行对比实验并分析。
3.1 实验设置
本文选用MNIST 数据集和CIFAR-10 数据集。MNIST 数据集包含60 000 张训练图像与10 000 张测试图像,其图像标签可分成10 个类别,即0~9 的数字。MNIST 数据集中的图像都为灰度图像,尺寸为28×28 像素。MNIST 数据集易于训练且运算量不高。CIFAR-10 数据集包含50 000 张训练图像与10 000 张测试图像,其图像标签也可分成10 个类别,即飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。CIFAR-10 数据集中的图像都为彩色图像,尺寸为32×32 像素。CIFAR-10 数据集的图像描述真实的彩色物体,更贴合对抗样本的应用场景。因考虑成本,本文从各数据集的测试集中选择前100 个被正确分类的样本,以生成各攻击方法的对抗样本。该检测器的数据集包含各攻击方法的对抗样本以及与对抗样本数量相同的正常样本,被随机分成训练集和验证集2 个部分。
分类模型:训练1 个7 层卷积神经网络[29]作为MNIST 数据集的分类模型,其分类准确率为99.43%,平均置信度为99.39%;训练1 个DenseNet[30]作为CIFAR-10 数据集的分类模型,其分类准确率为94.76%,平均置信度为92.15%。
对抗样本:设计的对抗攻击可以分为目标攻击和非目标攻击。目标攻击使用下一类(真实类的索引加1,记为next)和最不可能类(模型对某输入的预测概率最小,记为ll)2 种目标类。对于MNIST 的分类模型,非目标攻击有FGSM 和BIM;目标攻击有C&W0、C&W2、C&W∞和JSMA。对于CIFAR-10 的分类模型,非目标攻击有FGSM、BIM 和DeepFool;目标攻击有C&W0、C&W2、C&W∞和JSMA。以上针对二分类模型设计的FGSM、BIM 和JSMA 是用CleverHans库来实现的,DeepFool、C&W0、C&W2和C&W∞是用其作者提供的方法来实现的。
图像降噪与压缩方法:选用的图像降噪方法是非局部均值平滑和自编码器,自编码器包括卷积自编码器(CAE)和降噪自编码器(DAE);选用的图像压缩方法是像素深度压缩。上述方法的参数设置如下:非局部均值平滑将搜索窗口的尺寸设为13×13,邻域窗口的尺寸设为3×3,控制平滑程度的参数设为2,记为NLM_13_3_2;在MNIST 实验中,将图像的像素深度压缩到1 bit 或2 bit,在CIFAR-10实验中,将图像的像素深度压缩到5 bit,分别记为bit_depth_1、bit_depth_2 和bit_depth_5。MNIST 和CIFAR-10数据集的卷积自编码器和降噪自编码器中的Conv.ReLU均为3×3×3。MNIST 数据集的卷积自编码器和降噪自编码器中的Conv.Sigmoid 均为3×3×1,Dropout 为0.050。CIFAR-10 数据集的卷积自编码器和降噪自编码器中的Conv.Sigmoid均为3×3×3,Dropout 为0.075。对MNIST 自编码器和CIFAR-10 自编码器分别训练100 轮和400轮,优化方法都采用学习率为0.000 1 的Adam,batch_size 都设为256,添加高斯噪声的均值都为0 且其标准差都为0.01。Dropout 对MNIST 和CIFAR-10 的降噪自编码器方法的影响如图5 所示。从图5 可以看出,这2 个数据集的降噪自编码器方法对攻击成功的对抗样本的检测率分别在Dropout 为0.050 和0.075 时最高。

图5 Dropout 对降噪自编码器方法的影响Fig.5 Influence of Dropout on denoising auto-encoders
评价指标:对攻击成功的对抗样本检测率(SAE)和平均检测率(ASAE)、假阳性率(FPR)以及对攻击失败的对抗样本检测率(FAE)。
3.2 结果分析
3.2.1 输入样本在压缩特征空间前后的对比实验
正常样本和对抗样本在图像降噪或压缩方法处理前后的结果如图6 和图7 所示。第1 行都是未处理的图像,图6 中第2~5 行是分别经bit_depth_1、bit_depth_2、DAE1、CAE1 处理后的图像,图7 中第2~5 行是分别经bit_depth_5、NLM_13_3_2、DAE2 和CAE2 处理后的图像。从图6 和图7 可以看出,各方法去除对抗扰动的能力存在区别。为定量分析样本在经图像降噪或压缩方法处理前后的变化,本文列出了图6 和图7 对应的样本在处理前后的预测差,分别如表1 和表2 所示。从表1 和表2可以看出,通常深度学习模型对压缩特征空间前后的对抗样本的预测差比对相同处理前后的正常样本要大。经bit_depth_1、bit_depth_2、DAE1 和CAE1 处理正常样本的预测差分别为7.566×10-7、5.657×10-7、7.872×10-7和9.541×10-7。经bit_depth_5、NLM_13_3_2、DAE2 和CAE2 处理正常样本的预测差分别为3.284×10-4、3.388×10-5、9.219×10-4和1.803×10-4。

表1 经图像降噪或压缩方法处理前后的MNIST 样本的预测差Table 1 Prediction differences of the MNIST examples before and after image denoising or image compression

表2 经图像降噪或压缩方法处理前后的CIFAR-10 样本的预测差Table 2 Prediction differences of the CIFAR-10 examples before and after image denoising or image compression

图6 经图像降噪或压缩方法处理前后的MNIST 样本的效果图Fig.6 Effect imaging of the MNIST examples before and after image denoising or image compression

图7 经图像降噪或压缩方法处理前后的CIFAR-10 样本的效果图Fig.7 Effect imaging of the CIFAR-10 examples before and after image denoising or image compression
3.2.2 各单一检测方法与联合检测方法的对比实验
表3和表4所示为本文方法在MNIST和CIFAR-10数据集上的检测率,其中检测率是指对攻击成功的对抗样本检测率(SAE)。
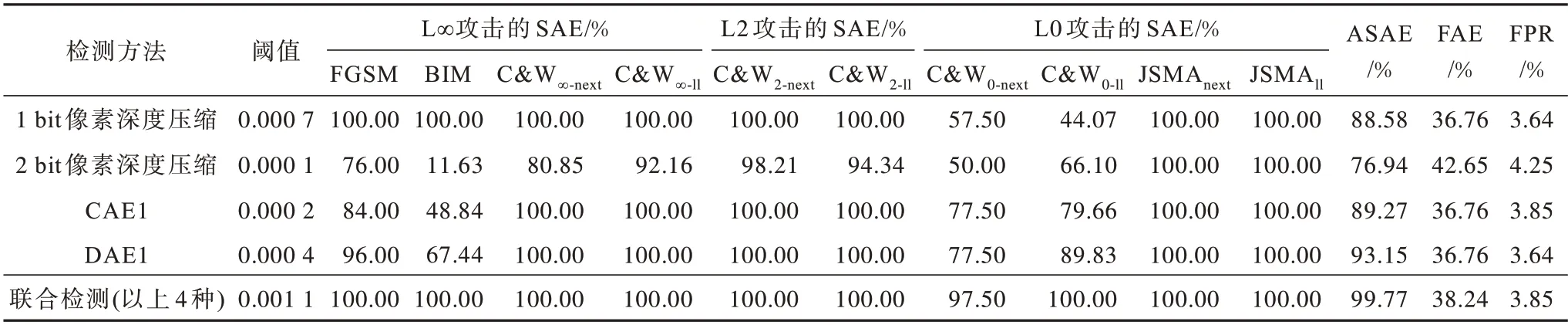
表3 在MNIST 数据集上不同检测方法的检测率Table 3 Detection rates among different detection methods on MNIST dataset
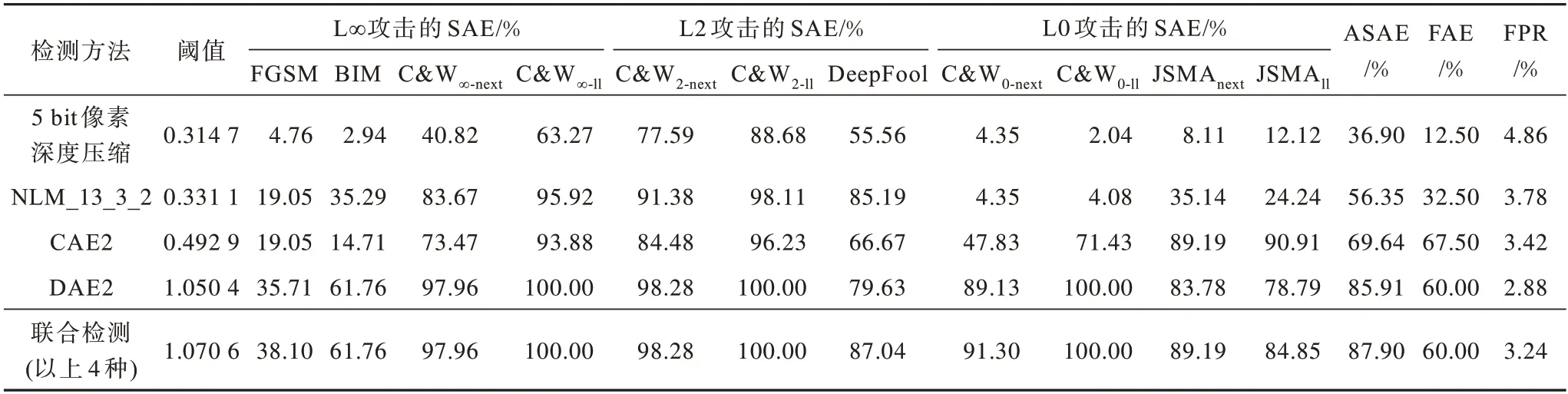
表4 在CIFAR-10 数据集上不同检测方法的检测率Table 4 Detection rates among different detection methods on CIFAR-10 dataset
从表3 可以看出,在MNIST 数据集上,检测效果最好的单一检测方法是DAE1,它对攻击成功的对抗样本的平均检测率(ASAE)为93.15%,对6 种攻击成功的对抗样本的检测率(SAE)达到了100%,而且其假阳性率为3.64%,对正常样本的影响较小,不足之处是它对BIM 攻击的SAE 较低。而1 bit 像素深度压缩方法对BIM 攻击的SAE 为100%。除此之外,在MNIST 数据集上的各单一检测方法都不能有效分辨出攻击失败的对抗样本。
从表4 可以看出,在CIFAR-10 数据集上,检测效果最好的单一检测方法是DAE2。DAE2 的ASAE为85.91%,对其中3 种攻击的SAE 高达100%,而且它的假阳性率是单一方法中最低的,对正常样本的影响最小。然而,包括DAE2 在内的各单一检测方法对较大扰动的BIM 和FGSM 攻击的检测效果都不佳,而且各单一检测方法的FAE 也普遍不高。
从MNIST 和CIFAR-10 数据集的单一检测方法效果中可发现它们各有所长。本文的联合检测方法就是为了在保证低假阳性率的同时,尽可能地去除样本中不必要的特征,从而达到更优的检测效果。本文对这2 个数据集进行多种联合检测方法的实验,得到性能最优的联合检测方法的检测结果。该联合检测方法不是简单地将某攻击检测效果最佳的单一检测方法的结果进行组合,MNIST 数据集上的各单一检测方法对C&W0攻击的检测率都低于联合检测方法对C&W0攻击的检测率。
从表3 和表4 可以看出,在MNIST 数据集和CIFAR-10 数据集上,联合检测方法的检测效果均最优,对各攻击的ASAE 分别是99.77%和87.90%,而且它们的FAE 都不低于性能最优的单一检测方法。虽然它们的假阳性率在可接受的范围内,但是都比性能最优的单一检测方法略高。此外,因为联合检测方法的阈值一般都比较大,所以导致部分对抗样本误判为正常样本。CIFAR-10 数据集上的联合检测方法对JSMAll攻击的检测率低于CAE2 对JSMAll攻击的检测率。
3.2.3 本文方法与其他检测方法的对比实验
不同方法的检测效果对比如表5 所示。本文方法(联合检测方法)与Feature squeezing[26]和MagNet[31]的检测效果进行对比。在MNIST 数据集上,虽然本文方法对攻击成功的对抗样本的平均检测率(ASAE)与MagNet 都为99.77%,但是本文方法的假阳性率相比MagNet 降低了9.11 个百分点,对正常样本的影响较小。在CIFAR-10 数据集上,本文方法的ASAE相比Feature squeezing 和MagNet分别提高5.16 和12.30 个百分点,而且本文方法的假阳性率是这3 种方法中最低的。因此,本文方法的检测性能优于其他2 种方法。

表5 本文方法与其他检测方法的检测效果对比Table 5 Comparison of the detection effect of the proposed method and other detection methods %
4 结束语
本文针对图像分类模型的对抗攻击问题,从预测结果不一致的角度出发,提出一种不依赖对抗样本的检测方法。使用图像降噪或压缩方法删除样本中的不必要特征,并通过比较处理前后的输入样本在深度学习模型中的预测差来检测该样本的对抗性。该检测方法易于部署而且无须对原图像分类模型进行调整,其普适性较强。实验结果表明,本文检测方法相比其他检测方法,能够在有效检测出对抗样本的同时降低对正常样本的影响。然而本文在CIFAR-10 的实验中对扰动较大的对抗样本检测效果不佳,而且在训练联合检测器时使用最大预测差选择阈值,影响对非正常样本的检测性能。后续将寻找可去除较大对抗扰动的方法,并设计新的策略训练联合检测器的阈值,以构建更有效的对抗样本检测方法。
猜你喜欢
艺术家(2023年8期)2023-11-02
数学物理学报(2022年4期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
数学物理学报(2019年4期)2019-10-10
红领巾·萌芽(2019年8期)2019-08-27
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
贵州师范学院学报(2016年3期)2016-12-01
CHIP新电脑(2016年3期)2016-03-10
电子器件(2015年5期)2015-12-29
