
融合多尺度语义和剩余瓶颈注意力的医学图像分割
2023-10-17 05:50徐蓬泉梁宇翔李英
计算机工程 2023年10期
徐蓬泉,梁宇翔,李英
(青岛大学 计算机科学技术学院,山东 青岛 266071)
0 概述
近年来,医学图像分析通常借助图像分割技术,例如,视网膜血管图像中的血管分割、结肠镜息肉图像中的息肉组织分割等[1-2],精准的分割大大提高了此类诊断和治疗的效果。然而,传统的分割算法[3-5]在处理计算机断层扫描(CT)、X 射线、磁共振成像(MRI)等的生物医学图像时,难以提取图像中的语义信息,鲁棒性较差。深度学习技术[6]解决了传统图像分割方法中语义信息缺失的问题[7-8]。例如,CHEN等[9]采用端到端的全卷积网络提取多层次的上下文特征,以便对组织学图像中的腺体进行精确分割。
U-Net[10]是深度学习网络[11-12],被广泛用于生物医学图像分割,核心是引入跳跃连接,通过连接编码器的低层次特征和解码器的高层次特征,实现图像语义分割,在2015 年的ISBI 细胞跟踪挑战赛中,U-Net 表现最优。U-Net 及其变体广泛应用于皮肤病变[13]、结肠组织学[14]、肾脏[15]、肺结节[16]、前 列腺[17]等医学图像分割。除了医学图像分割以外,U-Net 还广泛应用于计算机视觉中的其他任务。例如,TernausNet[18]将U-Net 中的编码器替换为VGG11[19],能在大型数据集上进行预训练[20]等。
尽管U-Net 模型在医学图像分割中具有较好的性能,但U-Net 中单一的感受野难以处理不同尺度的图像,编码器和解码器存在很大的语义差距且网络运行效率较慢。鉴于此,研究者们对U-Net 网络进行了改进。文献[21]提出U-Net++模型,引入嵌套和密集的跳跃连接,以降低编码器和解码器之间的语义差距。文 献[22]以U-Net 为基础提出Attention U-Net,在解码器部分引用注意力模块,关注目标区域,忽略背景区域。文献[23]提出R2U-Net,将循环神经网络嵌入U-Net 网络,并结合残差连接构建图像分割模型,提升了网络分割性能,用于分割视网膜血管图像和肺部CT 图像。文献[24]将U-Net级联用于图像分割,提升了分割性能,但也提高了模型复杂度。
然而,上述研究多数以增加模型参数量或提高模型复杂度为代价,从而提高了分割性能。鉴于此,本文构建一个轻量灵活的医学图像分割模型(LFUNet)。设计多尺度语义(Multi-scale Semantic,MS)模块,提取图像不同尺度的语义特征。相对于U-Net网络中的单一尺度卷积核,MS 模块集成了3×3、5×5、7×7 3种卷积核,以获得不同的感受野。此外,1×1 卷积应用灵活,无需简单地叠加更多层,增加了网络深度。设计剩余瓶颈注意力(Residual Bottleneck Attention,RBA)模块,将剩余瓶颈结构与可微分的柔性注意力机制相结合,消除每层编码器和解码器之间的语义差距,使神经网络更关注目标区域。
1 LFUNet 体系结构
基于U-Net 体系结构,设计轻量级的LFUNet 体系结构,如图1 所示(彩色效果见《计算机工程》官网HTML 版)。LFUNet 主要由两部分组成:1)MS 模块,采用3×3 卷积序列获得不同的感受野;2)RBA 模块,集成剩余瓶颈模块和注意力机制。
1.1 多尺度语义模块
细胞核、器官和组织等生物医学图像中需要分割的对象大小、形状各异。例如,息肉的内窥镜检查图像如图2 所示,不同图像中的息肉具有显著性差异。因此,分割模型需要在各种尺度和类型下具有鲁棒性。受文献[25-27]的启发,构建多尺度语义模块[28],包含多个分支,用于提取不同层次的语义特征,如图3 所示(彩色效果见《计算机工程》官网HTML 版)。分支1 是1 个3×3 卷积核操作,捕获图像的局部空间信息。事实上,多个小卷积核连续卷积可达到单个大卷积核卷积相同的感受野,提取图像更大邻域范围的信息。此操作不仅可以大大减少参数和计算量,而且生成更深的网络结构,提取高维特征。分支2 采用2 个连续的3×3 卷积核操作,达到1 个5×5 卷积核操作的感受野的效果。分支3 采用3 个连续的3×3 卷积核操作,达到1 个7×7卷积核操作的感受野的效果。需要注意的是,3 个分支都有1×1 卷积。1×1 卷积相当于1 个多层感知器,通过使用ReLU 激活函数增加了更多的非线性,提高网络表达能力,减少相关空间信息丢失。分支4 先是3×3 池化,再是1×1 卷积,通过池化操作删除一些冗余信息,1×1 卷积操作补偿了一些额外的空间信息。

图2 医学图像中的实例尺度差异Fig.2 Example scale differences in medical images
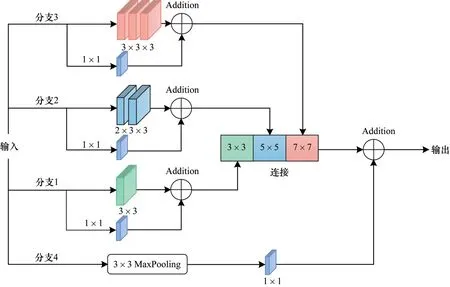
图3 MS 模块结构Fig.3 Structure of the MS module
为了控制参数量,每个分支采用不同数量的卷积核进行卷积操作。假设C表示通道集合,|C|是输入特征图的通道数。如果前3 个分支的卷积层分别配置3 个滤波器,那么前3个分支的特征图拼接后与第4 个分支的特征图具有相同的通道数。通过将前3 个分支的拼接特征图与第4 个分支的特征图叠加,获得输出特征图。
1.2 剩余瓶颈注意力模块
U-Net 编码器中的特征图都具有较低的语义,而解码器中经过多次卷积运算的特征图具有较高的语义。在跳跃连接运算时,较低语义和较高语义的不兼容降低了模型的分割性能。因此,通过嵌入剩余瓶颈模块消除编码器和解码器间的语义差距。同时,为了更多关注与分割目标相关的信息,引入注意力机制。通过集成剩余瓶颈模块与注意力机制,设计RBA 模块,如图4 所示(彩色效果见《计算机工程》官网HTML 版),其中,d表示输入和输出维度。RBA 模块在关注目标区域的同时,消除了语义差距。
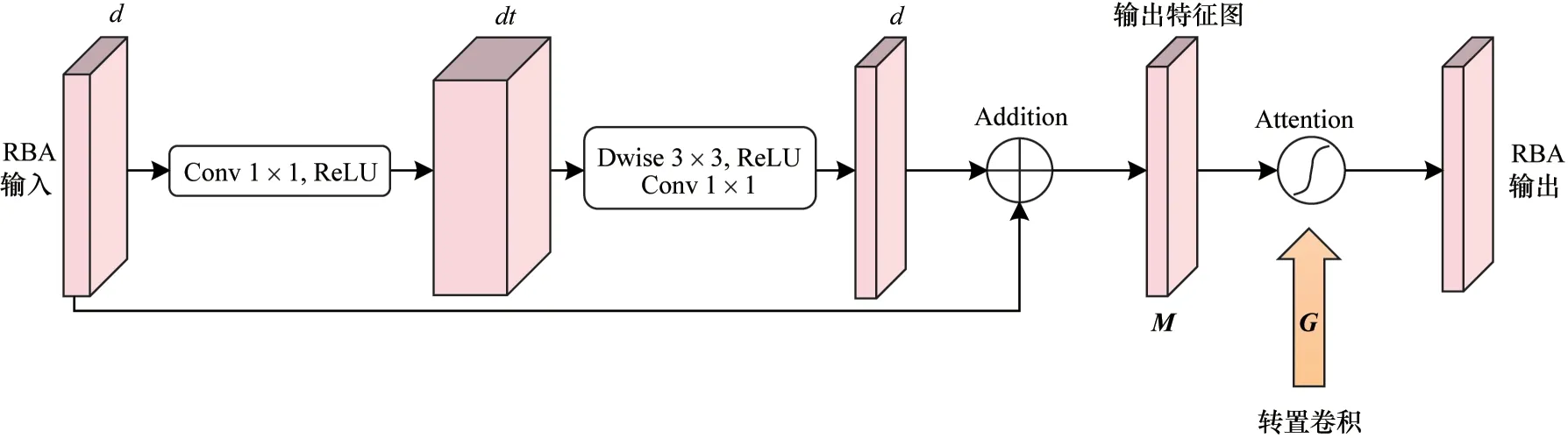
图4 RBA 模块结构Fig.4 Structure of the RBA module

图5 注意力机制结构Fig.5 Structure of attention mechanism
剩余瓶颈块包括线性逆残差结构和剩余连接结构。线性逆残差依次包括1×1 逐点卷积、3×3 深度可分离卷积和1×1 逐点卷积3 个部分[29]。第1 个1×1 逐点卷积扩展了通道数,可提取更多特征信息。第2 个3×3 深度可分离卷积可减少参数量[30-31]。第3 个1×1逐点卷积能够保留特征信息,并减少通道数。
假设剩余瓶颈块将通道数量增加了一个因子t,值得注意的是因子t的值因网络层次结构而异。由于编码器和解码器之间存在较大的语义差距,在MS Block 1 和MS Block 9 之间的第1 层网络中选择一个相对较大的值t=4。这表明使用1×1 卷积将通道数扩大了4倍。同样地,从第2 层到第4 层设定t=3,2,1。
注意力机制能使神经网络在训练时对环境更加敏感。假定M和G分别是注意力模块的较低和较高语义输入。由图1 和图4 可知,剩余瓶颈块的输出作为注意力机制的输入M,多个卷积层的转置卷积生成注意力机制的输入G。G中包含的语义信息揭示了注意力机制的方向。因此,M和G同时输入注意力模块后可使网络中M专注于学习的空间区域。
其中:σ是Sigmoid 函数;N表示批标准化操作;f1×1表示1×1卷积运算;fReLU表示ReLU 激活函数。前 面2 个1×1 卷积运算调整特征图的通道数,后面1 个1×1滤波器减少通道数。
为了更好地理解RBA 模块,以LFUNet网络的第1 层为例进行说明。将MS Block 1 的输出特征图输入RBA 模块生成新的特征图。该新图与MS Block 8的上采样结果连接,然后输入MS Block 9。LFUNet在U-Net 架构的每一层中拥有相同数量的通道。从MS Block 1 到MS Block 5 的滤波器数量依次对应64、128、256、512、1 024。相反地,从MS Block 5 到MS Block 9 的滤波器依次对应1 024、512、256、128、64。由于深度可分离卷积优化了参数量,且注意力模块没有额外的参数,LFUNet中的参数量相对较少[31]。
2 实验数据集及设置
2.1 数据集
考虑成像设备成本、图像采集渠道以及专家注释等因素[33],使得生物医学图像数据集的获取比传统计算机视觉数据集更具挑战性。因此,只有少数公共生物医学图像数据集能够用于评估分析。选择4 个具有不同分割难度的生物医学图像数据集用于测试LFUNet结构的性能。数据集简要信息如表1所示。

表1 数据集信息Table 1 Dataset information
2.1.1 皮肤镜检查图像数据集
ISIC-2018 皮肤镜检查图像数据集包含2 594 张不同类型的皮肤病变图像[34],随机挑选2 000 张图像,其中,1 600 张用于训练,400 张用于测试。图像分辨率统一调整为256×192 像素。如图6 所示,数据集中图像对比度差,病变区域与背景相似程度高,图像的背景和前景存在不同的纹理,皮肤病变形状和大小各异。上述问题皆增加了分割难度。

图6 对比度差和纹理不同的皮肤镜检查图像Fig.6 Dermoscopy examination images with poor contrast and different texture
2.1.2 内窥镜检查图像数据集
CVC-ClinicDB 内窥镜检查图像数据集来自29 个结肠镜视频序列[35],使用612 张病变的息肉图像进行实验,图像分辨率统一调整为256×192 像素。在数据集中边界模糊、息肉组织小的内窥镜图像为分割工作带来了很大的挑战,如图7 所示。在某些极端情况下,专家无法准确地区分背景和结肠息肉。

图7 边界模糊、息肉组织小的内窥镜检查图像Fig.7 Endoscopy examination images with vague boundary and small polyp tissue
2.1.3 细胞核图像数据集
Data Science Bowl 2018 分割挑战赛提供了细胞核图像数据集。该数据集由670 个带注释的细胞核图像组成。图像分辨率统一调整为256×192 像素。数据集中图像的细胞核数量各不相同,细胞核形态和大小各异,多个细胞核相互重叠和交叉。上述图像特征给分割带来了巨大挑战,如图8 所示。

图8 数量不同和相互重叠的细胞核图像Fig.8 Nuclei images with different numbers and overlaps
2.1.4 电子显微镜图像数据集
ISBI-2012 电子显微镜图像数据集仅包含30 张果蝇幼虫腹侧神经索连续切片透射电子显微镜图像[36-37],图像原始分辨率大小为512×512 像素,受到计算资源限制,调整数据集图像分辨率的大小为256×256 像素。为了保障评估的真实性和可靠性,未进行数据扩充。ISBI-2012 电子显微镜数据集的分割具有相当大的挑战性,如图9 所示,例如整张图像充满细胞、细胞间相互重叠、细胞边界、非边界区域的对比度差和噪声过多等,过多噪声的干扰易使图像过度分割。

图9 边界不清晰且噪声大的电子显微镜图像Fig.9 Electron microscopy images with unclear boundary and excessive noise
2.2 实验设置
使用Python 3[38]作为编程语言,并使用Keras 作为深度学习框架。实验运行环境是装有Ubuntu 18.04、NVIDIA RTX 2080 Ti(12 GB 和1.545 GHz)GPU 的台式计算机。
为了测试LFUNet 的性能,将其与U-Net、Attention U-Net、Attention R2U-Net、U-Net++和ResUNet++进行实验对比。采用计算机视觉中常用的Jaccard 和Dice系数[39]作为评估标准。实验采 用Adam[40]优化器作为最小化损失函数。该优化器具有AdaGrad 和RMSProp 的优势,能够根据训练数据迭代更新神经网络的权值。由于网络在150 个epoch 后基本收敛,因此基于Adam 优化器使用150 个epoch训练数据集。利用交叉验证方法[41]确保评估的可靠性。在实验中,每个数据集被划分为80%的训练集和20%的测试集,实施5 倍交叉验证测试。
3 实验结果
3.1 LFUNet 及对比模型的分割性能
LFUNet与其他5 种模型的对比结果如表2 和表3所示,其中Jaccard 和Dice 系数都给出均值和误差范围,结果表明LFUNet 优于其他5 种模型。

表2 不同模型在4 个数据集上的分割结果(Jaccard 系数)Table 2 Segmentation results(Jaccard coefficient)by different models on four datasets %
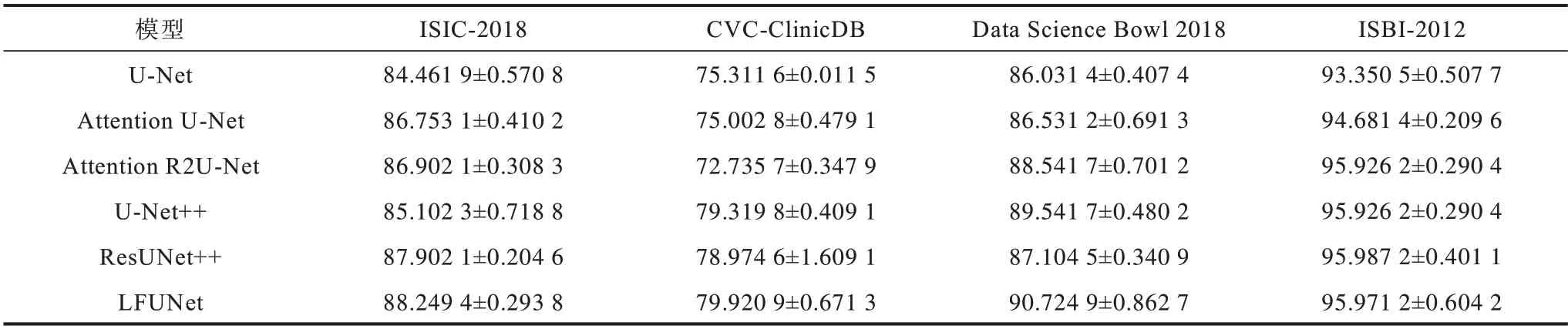
表3 不同模型在4 个数据集上的分割结果(Dice 系数)Table 3 Segmentation results(Dice coefficient)by different models on four datasets %
由表2、表3 可以看出:在最具挑战性的CVCClinicDB 数据集上,LFUNet 的Jaccard系数均值相较于U-Net 提高了11.936 6 个百分点。对于仅有30 张图像的ISBI-2012 数据集,LFUNet 也极具竞争力。可见,LFUNet 在大规模数据集和小规模数据集上均具有良好的鲁棒性。
LFUNet 结合了不同大小的卷积核提取更多的空间特征,提高了系统抗噪能力,如图10 所示。在第1 行的皮肤镜病变检查图像中,一些病变区域看起来像背景区域,专家也难以准确地识别皮肤病变。U-Net 由于计算单一特征,因此无法克服大量噪声的干扰。U-Net 将其分割为两个前景,并没有完全识别出皮肤病变,Jaccard 系数为0.677 1,而且分割的前景中包含一些分散的区域被错误地识别为背景。其他4 种对比模型分割时仍漏掉病变的中间部分,Jaccard 系数分别为0.634 1、0.652 2、0.767 3、0.714 3。LFUNet大大提高了分割精度,Jaccard 系数高达0.800 6,能识别连续的整个病变区域。在第2 行的内窥镜息肉检查图像中,该息肉组织图像与其他图像相比,形状怪异,不易识别,U-Net 及其变体很难完全分割息肉,尤其是图中标记的区域在分割过程中易被忽略,难以识别。由分割结果可知,LFUNet 成功地分割出标记区域,Jaccard 系数高达0.956 6。
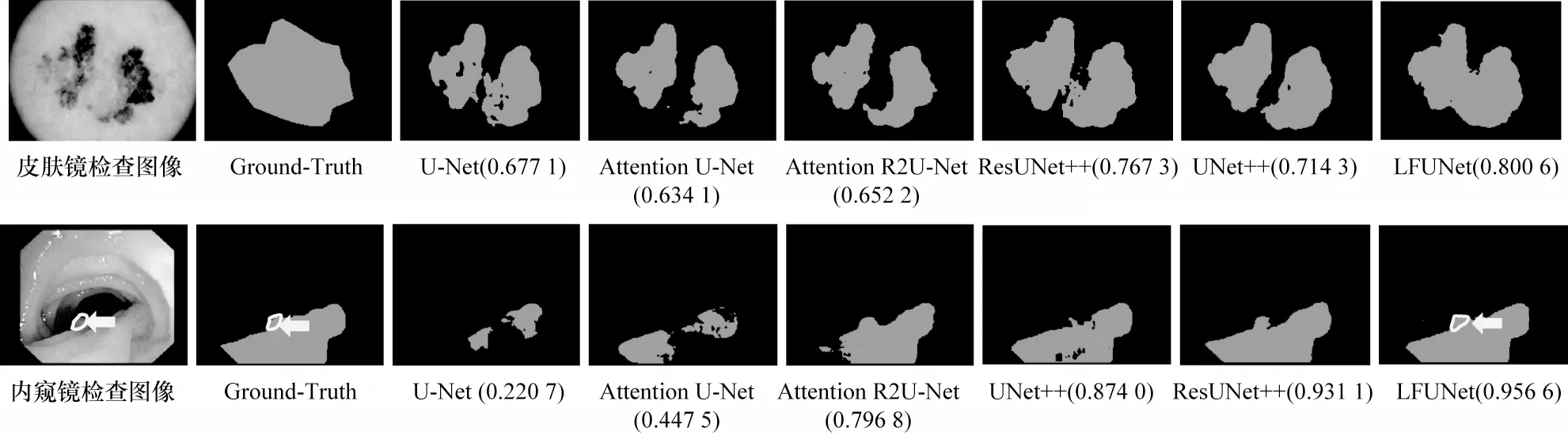
图10 皮肤镜与内窥镜检查图像的分割效果(Jaccard 系数)Fig.10 Segmentation effect(Jaccard coefficient)of dermoscopy and endoscopy examination images
3.2 LFUNet 组成模块的分割性能
进一步研究LFUNet 中各模块的分割性能。选择最具挑战性的CVC-ClinicDB 数据集作为实验数据,并采用U-Net 作为对比模型。表4 和表5 展示了5 倍交叉验证的实验结果。与U-Net 相比,仅采用MS 结构的模型(Only MS)的Jaccard 系数均值提高了约10 个百分点。MS 模块集成注意力机制或剩余瓶颈结构(MS and attention 或bottleneck)后,Jaccard系数略有提高。集成3 种结构的LFUNet 具有最优分割性能。

表4 LFUNet不同组成模块的分割结果(Jaccard系数)Table 4 Segmentation results(Jaccard coefficient)of different components of the LFUNet %
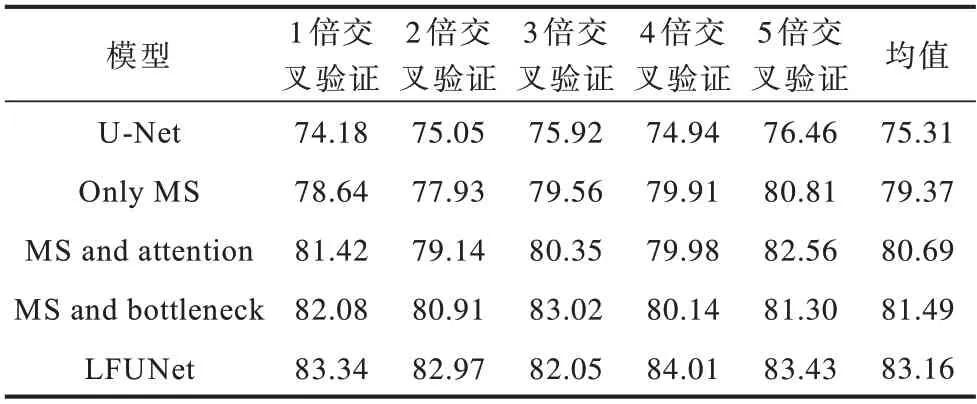
表5 LFUNet 不同组成模块的分割结果(Dice 系数)Table 5 Segmentation results(Dice coefficient)of different components of the LFUNet %
结合图10 可以看出:U-Net 对于一些结肠息肉图像几乎失去了分割能力;MS 结构集成多尺度卷积核,具有不同大小的感受野,能够提取更多的语义特征,并且集成剩余瓶颈结构能够有效地消除编码器和解码器之间语义差异对分割性能的负面影响,明显提高了分割精度,几乎分割出整个息肉组织的轮廓;LFUNet 表现最优。这与表4 和表5 的实验结果一致。
3.3 时间和空间复杂度
为了分析模型训练时的收敛性,将Jaccard 系数变化可视化,如图11 所示。由图11 可以看出,LFUNet 通常收敛较快。对于皮肤镜检查和细胞核数据集,LFUNet 能稳定收敛并且波动小。这归因于LFUNet 中两个MS 和RBA 模块之间的协同作用。虽然LFUNet 在电子显微镜数据集上开始收敛性稍弱,但随后趋于稳定。表6 展示了LFUNet 及其5 个对比模型的参数量,可以看出LFUNet 大大减少了参数量。综上,LFUNet 具有相对较低的时间和空间复杂度及较高的可靠性。

表6 模型参数量Table 6 The number of model parameters
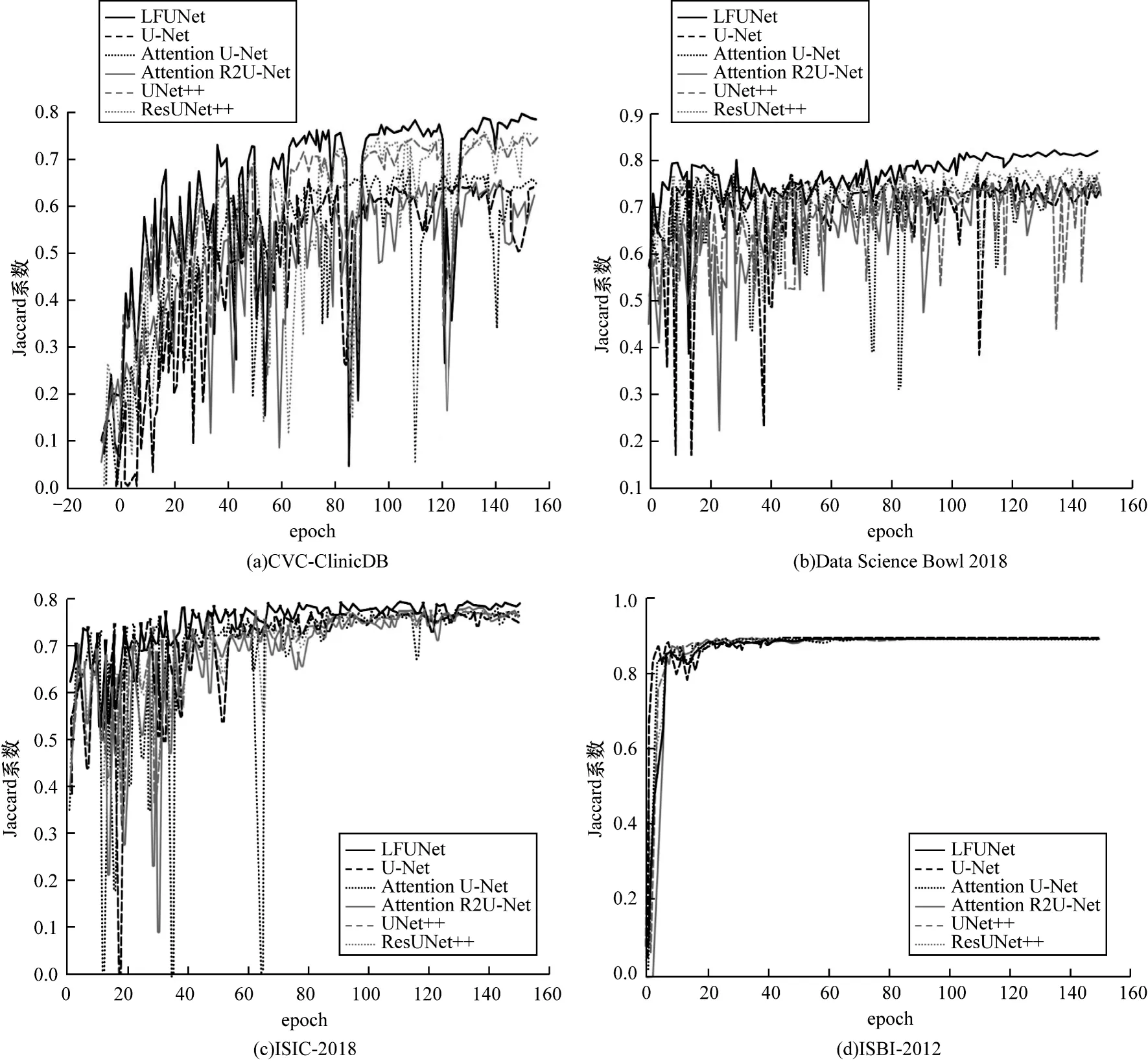
图11 训练过程中不同模型的Jaccard 系数变化Fig.11 Change of Jaccard coefficients of different models in the training process
4 结束语
本文分析主流的U-Net 体系结构及其变体,发现U-Net 存在提取特征单一且鲁棒性不强的问题。尽管U-Net 的一些变体克服了U-Net 的弱点,但涉及的参数量过大。为此,提出一种集成MS 和RBA 模块的LFUNet 模型。参数相对较少的MS 模块融合了不同尺度的卷积核,提高了分割性能。RBA 模块由剩余瓶颈和注意力机制组成,消除了编码器和解码器之间的语义差距,并更加关注目标区域。在4 个公共生物医学图像数据集上的实验结果表明,LFUNet 模型具有很强的鲁棒性,能够适用于不同的应用场景。随着更多医学图像的公共数据集的发布,后续将进一步扩展LFUNet 的适用范围及提高分割性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
家庭医学(下半月)(2020年3期)2020-05-30
开放教育研究(2020年2期)2020-03-31
中国生殖健康(2019年3期)2019-02-01
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
中国当代医药(2015年31期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
中华皮肤科杂志(2014年3期)2014-12-19
