
基于发声特征和深度学习的白羽肉鸡全生命周期咳嗽检测方法
2023-10-17 09:26:28袁超沈明霞姚文刘龙申陈佳
南京农业大学学报 2023年5期
袁超,沈明霞,姚文,刘龙申,陈佳
(1.南京农业大学工学院,江苏 南京 210031;2.南京农业大学人工智能学院,江苏 南京 210031;3.南京农业大学动物科技学院,江苏 南京 210095;4.农业农村部养殖装备重点实验室,江苏 南京 210031;5.江苏智慧牧业装备科技创新中心,江苏 南京 210031)
肉鸡是我国主要消费禽类,高密度笼养模式下其呼吸系统疾病日益凸显[1]。发声作为其与外界沟通的一种重要渠道[2],其包含的数据信息经提取处理可应用于健康监测、行为分析等相关研究。
国内外学者在应用声学技术监测生物健康方面取得了一定的研究成果。Carpentier等[3]提取犊牛叫声的信噪比和能量包络等抗噪能力较强的特征,利用功率谱、频谱质心阈值实现小牛咳嗽声和非咳嗽声分类,识别准确率达94.2%。Rizwan等[4]提取梅尔频率倒谱系数(MFCC)特征作为算法输入,通过极端学习机和支持向量机(support vector machines,SVM)完成模型训练后鸡只的啰音发声进行检测分类,以此为依据区分患病鸡只,试验结果证明了针对鸡只异常发声实现自动监测的可行性。Mahdavian等[5]对比了罗斯和科布两种基因型肉鸡患呼吸系统疾病的发声数据,算法模型对健康鸡只的识别准确率为95%,对患病鸡只的识别准确率为72%,分析试验结果发现患病鸡只识别准确率偏低的原因是部分鸡只发声会被误检为非发声内容。赵建等[6]在小波阈值的基础上开发了一种多窗谱维纳算法,实现猪只发声的去噪处理,提取了所获得的39维MFCC,利用深度神经网络和隐马尔可夫模型(hidden markov model,HMM)搭建了猪只咳嗽声识别模型。徐亚妮等[7]使用模糊C均值聚类改进方法对梅山母猪的咳嗽声和尖叫声进行了聚类分析,取得了较好的分类效果,总体识别准确率分别约为83.4%和 83.1%。Liu等[8]以平养白羽肉鸡为试验对象,提取小波变换MFCC和相关距离Fisher准则作为特征指标,搭载HMM模型,平均识别准确率为93.8%。Sun等[9]从时域频域、MFCC以及稀疏表示等方面提取白羽肉鸡咳嗽信号特征,利用随机森林实现归一化处理,搭建基于Softmax分类器和SVM的分类模型,识别准确率分别达97.81%和98.71%。
鸡只的发声识别技术正向深度学习转变,且其发声特征与生长阶段具有相关性[10]。本文将生命周期引入鸡只咳嗽识别研究,细分为10~19日龄、20~29日龄和30日龄后,将提取发声信号的Filter Bank(FBank)、MFCC特征作为VGG16、ResNet18两种神经网络的输入,实现笼养白羽肉鸡在不同生长阶段的咳嗽检测。
1 材料与方法
1.1 试验对象和设备
试验数据于2021年7月3日至8月1日在广东省云浮市新兴县温氏悦塘高效养殖小区完成采集。试验对象为笼养白羽肉鸡,鸡笼尺寸800 cm×420 cm×2 100 cm,养殖密度为15~20只/笼。
音频采集设备为佳创乐4G-A400录音拾音器,内存64 GB,采集精度16位,采样频率48 kHz,每段音频时长1 h,命名格式为“年-月-日-时-分-秒”,存储格式为wav。搭配5 V、3 000 mA移动电池。
1.2 数据采集
在养殖舍同步采集10~19日龄、20~29日龄、30日龄后3个生长阶段的发声数据。10日龄前鸡只因对呼吸系统疾病不易感而未参与试验。为降低原始音频受噪声的影响,设置采集时间为每日00:00—03:00,该时段舍内熄灯,鸡只杂乱发声大幅降低。采集时将拾音器置于呼吸系统疾病发作严重的区域,记录当日日龄信息。共采集录音数据120 h,3个日龄阶段各40 h。数据采集设备如图1所示。
1.3 数据预处理及数据集划分
为避免后续试验受噪声影响导致关联性降低,需对原始音频数据进行预处理以提高数据可用性[11-12]。
1.3.1 滤波去噪对采集的音频进行时域分析,结合人耳侦听划分目标声音信号与背景噪声信号。各类声音信号时域波形如图2所示。其中,目标声音信号包括咳嗽声、鸣叫声、啰音、怪叫,背景噪声包括高频噪声(如音频噪声)以及低频噪声(如设施噪声)。

图2 各类肉鸡声音时域波形图Fig.2 Time-domain waveforms of various sounds of broilers
使用6阶巴特沃兹带通数字滤波器滤除低频噪声[13],设置截止频率为1 800和3 500 Hz。通过谱减法抑制高频噪声信号频率点,获取较为纯净的发声信号[14]。最终去噪效果如图3所示。
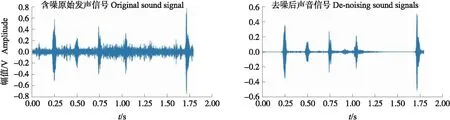
图3 去噪前后肉鸡声音对比Fig.3 Comparison of broiler sound before and after denoising
1.3.2 端点检测杂音干扰导致信噪比低是影响端点检测准确性的主要因素。在低信噪比条件下,使用频带能量与谱熵的比值作为参数实现端点检测[15],可抑制噪声的突发性干扰,检测结果如图4所示。依据端点检测结果切割去噪音频数据,获取单一发声段用以搭建数据集。
1.3.3 数据集划分对端点检测结果进行人耳侦听,依照咳嗽声(cough)、鸣叫声(chirp)、其他声(others)进行分类,获取的有效发声段为:10~19日龄3 329声,其中咳嗽声1 112声,鸣叫声1 217声,其他声1 000声;20~29日龄3 405声,其中咳嗽声1 151声,鸣叫声1 254声,其他声1 000声;30日龄后2 992声,其中咳嗽声966声,鸣叫声1 026声,其他声1 000声。数据集以8∶1∶1样本占比设置训练集、验证集与测试集。数据集结构如表1所示。
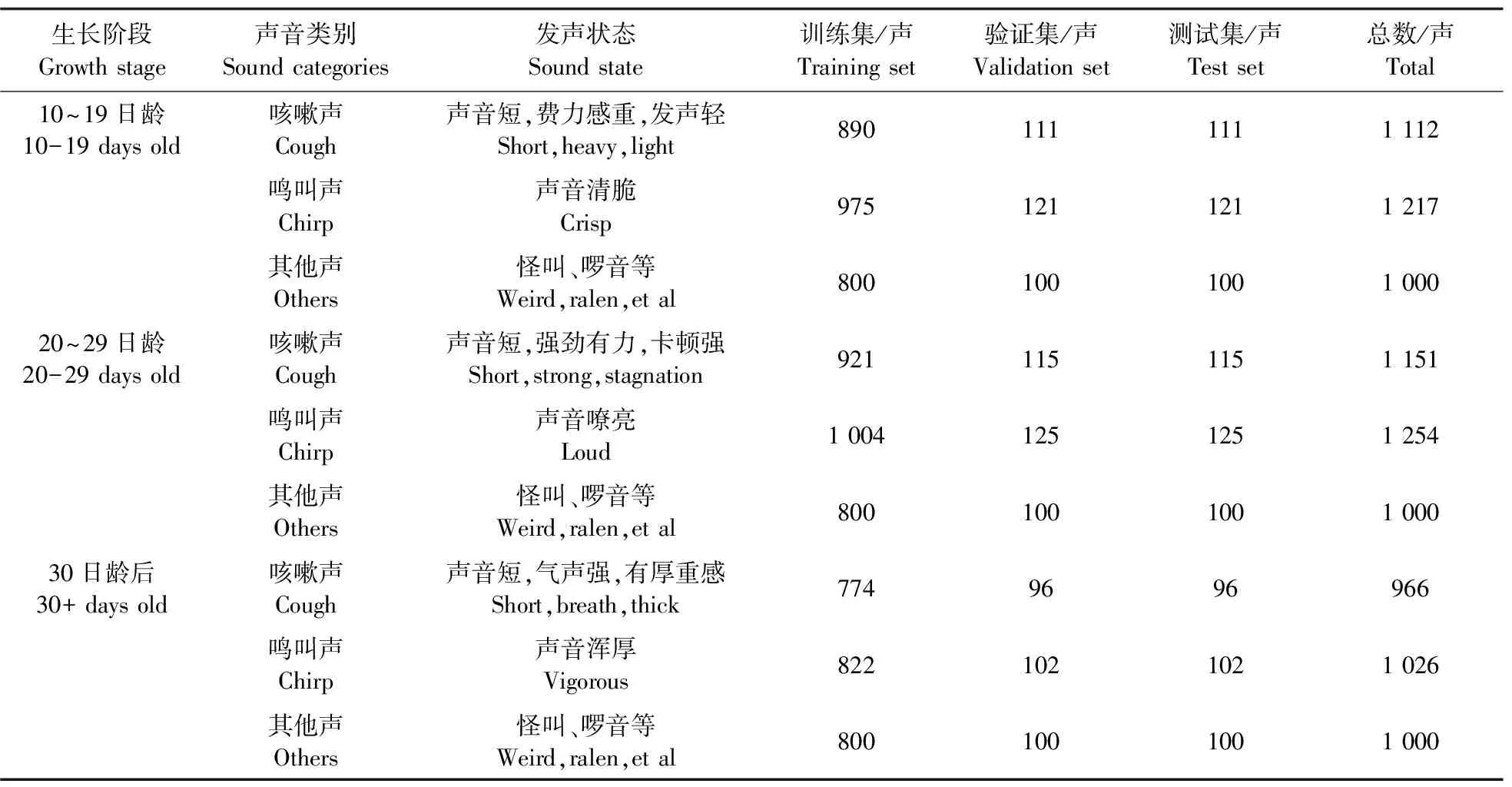
表1 数据集组成Table 1 Data set composition
1.4 发声特征提取
由于滤波器组间重叠,原始信息保留度高,相邻FBank特征间具有强相关性。进一步做离散余弦变换(discrete cosine transform,DCT)可得到MFCC特征,该特征辨别度更高,贴合人耳对声音感知的非线性特性[16-17]。
1.4.1 时频转换通过对声音信号进行预加重处理,可以降低频率损失,突出共振峰,使信号频谱在整个低频至高频的频带上维持平衡,提高输出信噪比。
(1)
式中:S(n)为n时刻采样值;预加重系数α设置为0.97。
根据奈奎斯特采样定律,设置采样频率为48 kHz,帧长(N)为25 ms,重叠区域(M)为10 ms,将声音信号切割为短时帧,保持帧段之间部分重叠,避免发生频谱泄漏。分帧完成后使用汉明窗增加单一短时帧起止点之间的连续性与平滑度。
汉明窗函数W(n)公式为:
(2)
式中:N为窗口长度。
将信号转换至频域进行分析,对分帧信号进行2 048点短时傅里叶变换(short time Fourier transform,STFT),提取频谱信息。短时傅里叶变换频域值Sn(W)公式为:
(3)
式中:s(n)为第n个采样点的采样值;m为汉明窗长度;w为角频率;R为窗口随时间滑动的距离;W为汉明窗函数。
在短时傅里叶变换的基础上对频谱取模后平方,提取信号的功率谱。功率谱值P公式为:
(4)
式中:si为第i帧信号。
1.4.2 特征提取使功率谱通过固定Mel刻度的三角滤波器组,提取频带并进行子带划分后利用对数变换可提取FBank特征,在此基础上通过DCT提取MFCC特征。特征提取流程如图5。
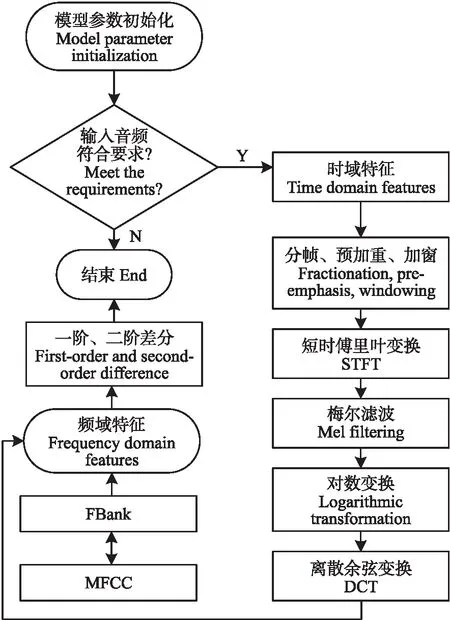
图5 鸡只发声特征提取算法流程图Fig.5 The flow chart of broilers vocalizationfeature extraction algorithm
对FBank、MFCC特征做一阶和二阶差分,经零-均值标准化处理后得到三维数组,保存为npy格式文件。图6为各日龄段内鸡只音频信号的发声特征,图中左列为FBank特征,右列为MFCC特征,横向从上至下分别为静态特征及其一阶和二阶差分图,其中使用⊿代表一阶差分,⊿2代表二阶差分。

图6 各日龄鸡不同发声类别FBank、MFCC特征及其一阶(⊿)、二阶差分(⊿2)示意图Fig.6 Schematic diagram of the sound FBank and MFCC characteristics of different vocalization categoriesand their first-order(⊿)and second-order(⊿2)differences in each age of broilers
观察发现,不同日龄段内同类别声音的FBank、MFCC特征差异明显,同一日龄段内不同类别声音间也存在较大区别。
1.5 咳嗽声识别模型设计与训练
将上述特征组合输入VGG16、ResNet18两种神经网络,搭建全生命周期鸡只咳嗽识别模型,完成训练后输出查准率、召回率、准确率等性能指标评价模型优劣。模型训练流程如图7所示。
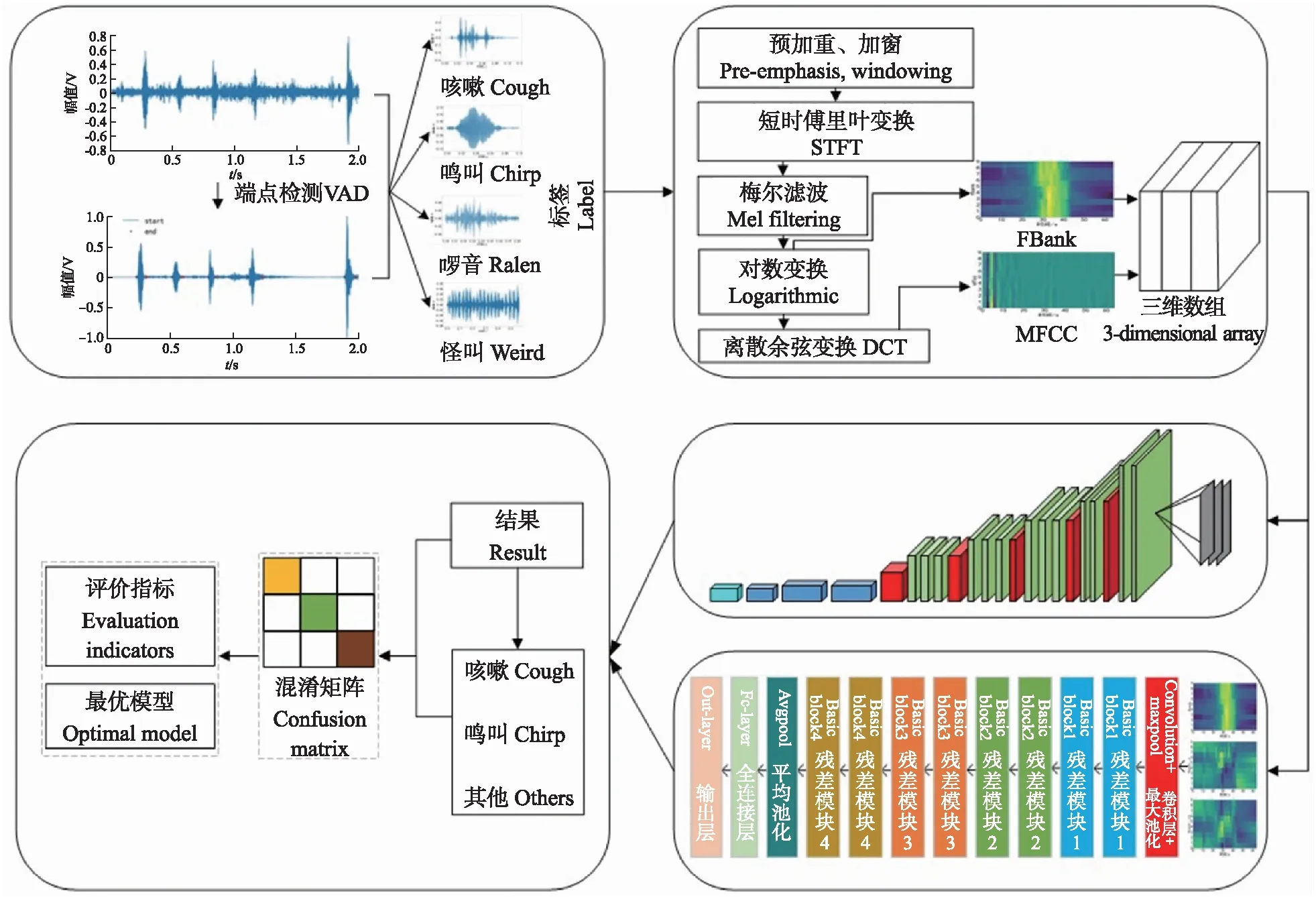
图7 鸡咳嗽声识别模型训练流程Fig.7 The training process of the cough sound recognition model of broilers
1.5.1 VGG16网络模型结构根据不同设计的VGG-block块,VGG目前存在6种结构,其中VGG16使用最为广泛[18],网络结构如图8。该模型中,13个卷积层与5个池化层交叉相接,激活层使用ReLU函数,最后由3个全连接层接入Softmax分类器构成完整的VGG网络结构。
VGG16在所有卷积层内均使用2次3×3小卷积核替代1次5×5的大卷积核,维持相同范围感受野的同时增强了特征提取能力。每个卷积层后使用1次ReLU激活函数提高表达能力。在2~3个卷积层后连接1个2×2池化核的池化层,对数据特征进行最大池化处理增加网络稀疏性。全部卷积层后使用3个全连接层进行分类计算,2个全连接层间通过Dropout处理降低参数量,优化网络结构,完成回归输出。
1.5.2 ResNet18网络模型结构残差神经网络(residual neural network,ResNet)用以解决模型训练过程中伴随误差逆向传播出现的梯度消失、梯度爆炸等问题[19]。针对网络深度加深时深层网络相较浅层网络反而表现更差的退化问题,ResNet利用残差网络实现优化,残差网络结构如图9-a所示。
通过残差网络,期望的输出H(x)由输入x经过两路运算后进行叠加,其中一路为输入x经恒等变换后直连至输出,另一路为输入x经卷积、激活等操作后得到F(x)。根据H(x)的计算方式,可以推断出网络由第n层传导至深层第N层的前向传播计算公式:
(5)
式中:HN(x)为第N层输出;xn为第n层输入;wi为第i层权重。
分析上式可知,残差网络中的前向传播采用了连加操作,根据逆向传播的导数链式法则,x的梯度和损失函数ε的关系可以表示为:
(6)
残差网络的逆向传播过程只有链式法则前部参与运算,且左边x的求导结果始终保持为1,使得残差网络在梯度很小或很大时仍可由第N层稳定传播至第n层,从而规避了梯度消失与梯度爆炸的出现。图9-b 所示为ResNet18的神经网络模型结构。
1.5.3 模型训练及参数设置神经网络模型训练的初始权值随机生成,在学习过程中根据算法设置学习率η以及迭代次数N,利用优化函数通过N次迭代不断调节权值来实现损失函数的最小化,进而提高模型性能。神经网络模型的训练过程如下:
1)统一模型输入:端点检测所得单段发声数据时长上存在浮动,分帧后总帧数目不一致。本文统计数据样本后规定输入音频长度保持45帧,控制模型的输入尺寸为40*64*3。
2)超参数初始化:随机生成初始权值打乱神经网络对称性,每一轮训练过程(Epoch)中使用Shuffle函数随机样本排序。单次训练使用数据样本64个,全部数据遍历完成记为一次Epoch结束。Epoch初始值设置100,学习率η设置0.001,动量设置0.9,学习衰减率设置0.98。优化器选用随机梯度下降(Stochastic Gradient Descent,SGD),公式为:
gt=θt-1f(θt-1)
(7)
Δθt=-η*gt
(8)
式中:θ为模型参数;η为学习率;gt为损失关于参数的梯度;f为代价函数。
损失函数选用交叉熵损失(cross-entropy loss function,CELF),公式为
(9)
式中:p为样本真实分布;q为模型预测的样本分布;p(x)为期望输出;q(x)为实际输出。
3)模型训练:通过损失计算在单次迭代后自调整参数设置,以50个Epoch为间隔进行一次学习率降低。全部轮次结束后根据训练集与验证集的结果分析,损失与精确率误差约为2%,正常结束训练。
2 结果与分析
算法基于Pytorch深度学习开发库搭建,模型训练使用的工作站有效内存31.1 GB,配置1块GTX1080Ti显卡、2块Xeon Gold 5118 CPU。
2.1 模型性能评价指标
模型训练结果以混淆矩阵形式输出。基于混淆矩阵对各类标签识别结果的个数统计,得出准确率(accuracy)、精确率(precision)、召回率(recall)以及F1-score,综合衡量各模型优劣[20]。
2.2 发声特征对模型性能的影响
从表2可见:各日龄4种识别模型均能较为准确进行鸡只发声的分类识别,总体准确率均在92%以上。同一神经网络结构,10~19日龄FBank-VGG16较MFCC-VGG16的总体准确率高1.14%,FBank-ResNet18较MFCC-ResNet18的总体识别准确率高1.74%。20~29日龄,FBank-VGG16较MFCC-VGG16的总体识别率高 5.51%,FBank-ResNet18较MFCC-ResNet18总体准确率高5.74%。30日龄后,MFCC-VGG16较FBank-VGG16总体准确率高1.8%,MFCC-ResNet18较FBank-ResNet18总体准确率高1.49%。可以看出,30日龄前FBank特征的识别效果更好,组合VGG16神经网络,总体准确率10~19日龄为94.29%,20~29日龄为97.65%,高于其他模型组合。2种特征的识别效果在20~29日龄差距最大,30日龄后MFCC特征的识别效果比FBank更好,组合ResNet18神经网络,总体准确率最高达98.66%。伴随日龄的增长各模型组合对鸡只发声分类的准确率均有所提高,增幅为3%~7%。

表2 各日龄鸡4种模型的识别效果Table 2 Recognition effect of 4 models under different age of broilers %
2.3 深度学习算法对模型性能的影响
为了验证深度学习算法对鸡只发声分类识别的性能提升,使用提取的FBank、MFCC特征作为支持向量机的输入,对比分析各日龄卷积神经网络模型与传统机器学习模型对鸡只发声分类的识别效果[21]。该分类器基于Scikitlearn库实现,分类决策函数g(x)为:
(10)
式中:αiyi为权值;x为输入;β为输入的截距;N为样本数目;K(xi,x)为决策函数。
核函数使用径向基核函数(radial basis function,RBF),泛化参数设置为1.0,学习率设置为0.001,正则化参数设置为0.01,训练轮次100次。训练结果对比如表3所示:使用SVM分类器通过提取2种特征在3种日龄条件下完成训练的识别模型总体准确率为82%~86%。3个日龄段,基于FBank特征,SVM较卷积神经网络总体准确率分别降低11.14%、13.53%、14.09%,基于MFCC特征分别降低10.86%、7.64%、12.08%。本方法较SVM具有更高的性能,在鸡咳嗽声识别中更具优势。
2.4 三分类对模型性能的影响
为了验证二分类模型与三分类模型在咳嗽声识别上的优劣,基于数据量均衡,在鸣叫声与其他声数据集中各随机抽取1/2合并为“非咳嗽类”(non-cough),与原咳嗽类(cough)一起作为二分类模型数据集。在10~19日龄、20~29日龄完成FBank-VGG16识别模型的二分类训练,30日龄后完成MFCC-ResNet18模型的二分类训练。从图10可见,“非咳嗽类”参与训练后识别模型在3个日龄段内的总体准确率和识别咳嗽声的精准率都出现了不同程度下降。3种日龄段二分类模型的总体准确率分别为88.24%、87.67%、83.25%,较三分类模型下降6.05%、9.98%、15.41%;随着日龄的增长,三分类模型准确率上升的同时二分类模型呈现下降趋势;二分类模型对咳嗽声识别的精确率分别为86.09%、87.18%、81.82%,较三分类模型降低8.5%、10.21%、17.14%。这表明,在肉鸡咳嗽声识别中三分类模型通过将“非咳嗽类”进一步的细分为子类“鸣叫类”和“其他类”,提高了模型整体的识别能力,针对咳嗽声的识别更具优势。
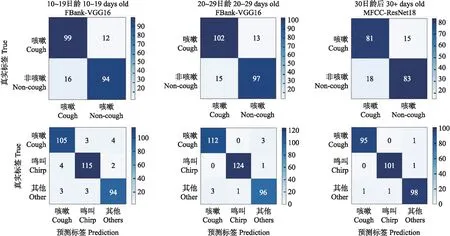
图10 各日龄鸡二分类(上)及三分类(下)识别模型的混淆矩阵Fig.10 Confusion matrices of two classification(up)and three classification(down)recognition models at different ages of broilers
2.5 生长阶段对模型性能的影响
鸡只在不同生长阶段对呼吸系统疾病的易感程度不同,不同生长周期患病鸡只的发声状态有所区别,模型在不同日龄段的识别性能也随之变化。从图11可见,随日龄增长,输入为FBank特征时2种识别模型准确率基本一致。该类模型在20~29日龄识别效果最好,较10~19日龄增加3%~5%,30日龄后略微衰退。MFCC-VGG16模型准确率增加约5%,在30日龄后识别效果优于FBank类模型。MFCC-ResNet18较其他识别模型识别准确率高,在30日龄后准确率增加最大,约为7%,总体准确率为98.66%。

图11 各识别模型在不同日龄鸡测试集上的准确率Fig.11 The accuracy of each recognition model on thetest set in different age of broilers
3 小结
1)本文通过谱减法与数字滤波处理原始音频噪声,利用能熵比例端点检测法切除无效声段,提取FBank、MFCC特征,输入VGG16、ResNet18两种神经网络,对比3个日龄段的各模型的识别效果。结果显示:4种识别模型均能准确实现发声分类。10~19日龄、20~29日龄FBank-VGG16识别效果最好,准确率为94.29%、97.65%,30日龄后MFCC-ResNet18模型识别准确率最高,为98.66%。鸡只日龄增长对各类模型的识别准确率都有一定的提升效果,总体上涨3%~7%。随着鸡只发育成熟,各类声音的发声特征更具明显性,提高了模型学习能力。30日龄后鸡只生长进入平稳期,各类模型识别准确率均达97%以上,对实际生产中笼养鸡呼吸系统疾病的预警具有一定的应用价值。
2)相同数据集下对比SVM分类器,本试验方法在3个日龄段基于FBank特征总体准确率分别提高11.14%、13.53%、14.09%,基于MFCC特征分别提高10.86%、7.64%、12.08%。与二分类模型相比,3个日龄段内三分类模型的准确率分别上升6.05%、9.98%、15.41%。
3)鉴于本研究对笼养白羽肉鸡咳嗽声、鸣叫声以及其他声的准确识别,可在此基础上细化鸡只的异常发声类别,探究鸡只异常发声与所患病种之间的关联性。
猜你喜欢
小主人报(2022年17期)2022-11-21 21:14:26
作文成功之路·小学版(2021年3期)2022-01-01 18:34:44
作文成功之路·教育教学研究(2021年3期)2021-06-06 08:52:36
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
养猪(2020年1期)2020-02-19 04:18:04
今日农业(2019年11期)2019-08-15 00:56:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
国外畜牧学·猪与禽(2018年11期)2018-05-14 11:14:22
