
基于卷积神经网络的人脸图像隐私保护
2023-10-13 12:13王祥根崔佳佳
沈阳师范大学学报(自然科学版) 2023年3期
沈 博, 王祥根, 田 澍, 崔佳佳
(1. 华北计算技术研究所, 北京 100083; 2. 北京信息科技大学 信息与通信工程学院, 北京 100192)
随着智能手机和高像素相机的发展,人们获取与共享人脸照片更加便捷。例如,社交媒体上的用户通过Facebook,Instagram,Twitter和YouTube等应用,实时发布手机或相机中拍摄的照片;谷歌、百度和微软等主要云服务商都为用户提供了基于图片的免费服务,用户可以保存和管理自己的照片,并随时下载到手机或电脑上。通过收集这些人脸照片,利用生物识别技术对大量图像进行处理和分析,可为企业与个人提供更具有个性化的服务。但由于人脸图像中通常包含敏感的个人信息,简单地共享或发布人脸图像数据后,攻击者对其进行身份推断得到的社会关系会造成个人隐私泄露。因此,设计面向人脸图像的隐私保护发布方法是十分必要的。
已有的人脸图像隐私保护方法包括基于传统图像处理[1]与基于深度学习[2]2类。基于传统图像处理的隐私保护方法通过混淆图像中的敏感信息来达到隐私保护的目的,如遮蔽、像素化和模糊化。虽然该类方法计算复杂度较低,但通常会降低原始图像的质量,产生较差视觉质量的图像数据,无法为人脸识别或分类任务提供有效数据。为解决传统图像处理方法的不足,基于深度学习的图像合成方法被提出,通过神经网络模型从面部数据中去除或隐藏生物特征信息,发布替代原始人脸的高质量合成图像,用于人脸识别模型的训练与应用。
给定一张人脸图像,如何生成一张与其具有相似外观和相同背景的图像,同时隐藏真实身份并且允许人脸检测器进行检测与识别是现有工作研究的核心问题。Hukkelas等[3]提出DeepPrivacy方法,利用条件生成对抗网络合成图像,在不破坏原始数据分布的情况下对图像中的身份信息进行匿名处理;Chen等[4]利用深度卷积生成对抗网络合成与原始图像属性匹配的高逼真人脸图像,同时采用定性与定量相结合的方式衡量合成图像的隐私性和可用性;Sun等[5]通过设计参数化的GAN人脸图像隐私保护模型,允许在合成图像中添加细粒度的脸部细节信息,产生具有更高视觉真实感的合成图像;Meden等[6]通过使用生成神经网络合成代替人脸确保隐私性,同时保留非身份相关方面数据以实现可用性;Maximov等[7]提出基于条件生成对抗网络的图像和视频匿名化模型,能够去除面部和身体的识别特征,同时生成可用于任何计算机视觉任务的高质量图像和视频;Xue等[8]利用深度神经网络提出在特征空间中使用对抗性扰动的新型人脸图像去识别框架,生成图像在有效保留与身份相关的信息的同时确保其他属性与原始图像保持一致。
上述基于深度学习的人脸图像隐私保护方法,可以帮助解决人脸图像发布和共享时引起的隐私问题,但仍存在一些有待解决的问题:一是现有方法没有提供形式化的隐私保证来证明合成图像的隐私保护效果;二是未考虑语义完整性,不能有效保持隐私性和可用性之间的优化权衡。导致上述问题的主要原因是基于对抗生成网络的方法通常只关注图像内容之间的转换,而忽略了训练图像的其他关键语义条件信息,包括人脸轮廓、身份等属性信息,因而无法有效引导网络生成具有高视觉保真度和准确身份属性的人脸图像。同时,在实际训练中,由于针对具有统一身份的人脸图像收集成本较高,训练效率不够理想,基于对抗生成网络的方法仍然面临着样本类别不均衡的问题,因而容易导致模型出现过拟合,影响人脸合成质量。此外,在没有高级条件语义信息的指导下,现有的人脸隐私保护方法对人脸图像身份隐藏的效率相对低下。针对以上问题,本文提出一种基于卷积神经网络的人脸图像隐私保护方法,利用卷积自动编码器对原始人脸图像进行解耦,实现身份信息的差分隐私保护,并在卷积生成对抗网络的基础上添加分类器保持原始图像和合成图像间的语义一致性,代替原始图像发布。该方法在保留原始人脸图像的关键特征的基础上,可有效平衡隐私保护和数据可用性,保持图像的语义完整性,同时提供可证明的隐私保证。
1 预备知识
1.1 差分隐私
设数据集D和D′具有相同属性结构,二者的对称差记为D≃D′,|D≃D′|表示对称差D≃D′中的记录个数,若|D≃D′|=1,则D和D′称为相邻数据集。
定义1ε-差分隐私[9]。给定相邻数据集D和D′,若存在隐私算法M,Range(M)是M的取值范围,若算法M在数据集D和D′上的任意输出结果S(S∈Range(M))满足
Pr[M(D)∈S]≤eεPr[M(D′)∈S]
(1)
则称算法M满足ε-差分隐私。
其中,参数ε表示隐私预算,ε值越大,隐私保护强度越低值越小隐私强度越高。采用Laplace机制实现ε-差分隐私。
定义2 Laplace机制[10]。设函数f:D∈n→d,如果算法M的输出满足
M(D)=f(D)+Z
(2)
且Z∈n是服从位置参数为0,尺度参数为Δf/ε的Laplace分布,则算法M提供ε-差分隐私。Laplace机制引入噪声的大小与函数f的敏感度Δf和隐私预算ε有关,Laplace机制的敏感度Δf由L1-范数定义。
定义3L1-敏感度。设函数f:D∈n→d对所有相邻数据集D和D′的L1-敏感度为
差分隐私具有以下2个重要的性质[11],它们是判断一个机制是否满足差分隐私的标准。
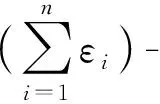
性质2 变换不变性。给定任意算法M1满足ε-差分隐私,对任意算法M2(不一定满足差分隐私),则有M(·)=M2(M1(·))满足ε-差分隐私。
1.2 自动编码器
1.3 生成对抗网络
生成对抗网络(generative adversarial networks, GANs)由生成器模块G和判别器模块D组成,生成器模块的目标是根据学习的概率模型生成图像内容。判别器模块的主要目的是判断生成的图像内容是真是假,并对此作出接受或拒绝图像内容的决定。GANs利用零和极小极大(G,D)=[logD(X)]+进行博弈完成对抗学习,其中为隐向量的先验分布,G(·)为生成函数,D(·)为输出范围为[0,1]的判别函数。当D(X)=0时表示判别器D将样本X分类为生成的,反之D(X)=1表示判别器D将样本X分类为真实的。在GAN网络的训练过程中,将判别器和生成器生成的人脸图像之间产生的期望值作为每一批次人脸质量判别的依据。为了使模型具有较高的人脸图像合成质量并保证其鲁棒性,通常会将训练模型分成多个小批量数据集,并将每个批评的样本取期望的平均值作为网络训练的依据,同时保证损失函数在一个小批量梯度下降的过程中交替地进行最小化和最大化,保证GAN网络模型的训练效率。
1.4 问题描述
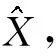
1) 对于身份属性x∈Xid,在训练期间未使用的属性分类器fx的性能降低;

2 基于卷积神经网络的人脸图像隐私保护模型
根据1.3节的问题定义及描述,本文结合生成对抗网络、自动编码器与差分隐私设计面向人脸图像发布的隐私保护模型。如图1所示,该模型包括预训练和图像合成2个部分。
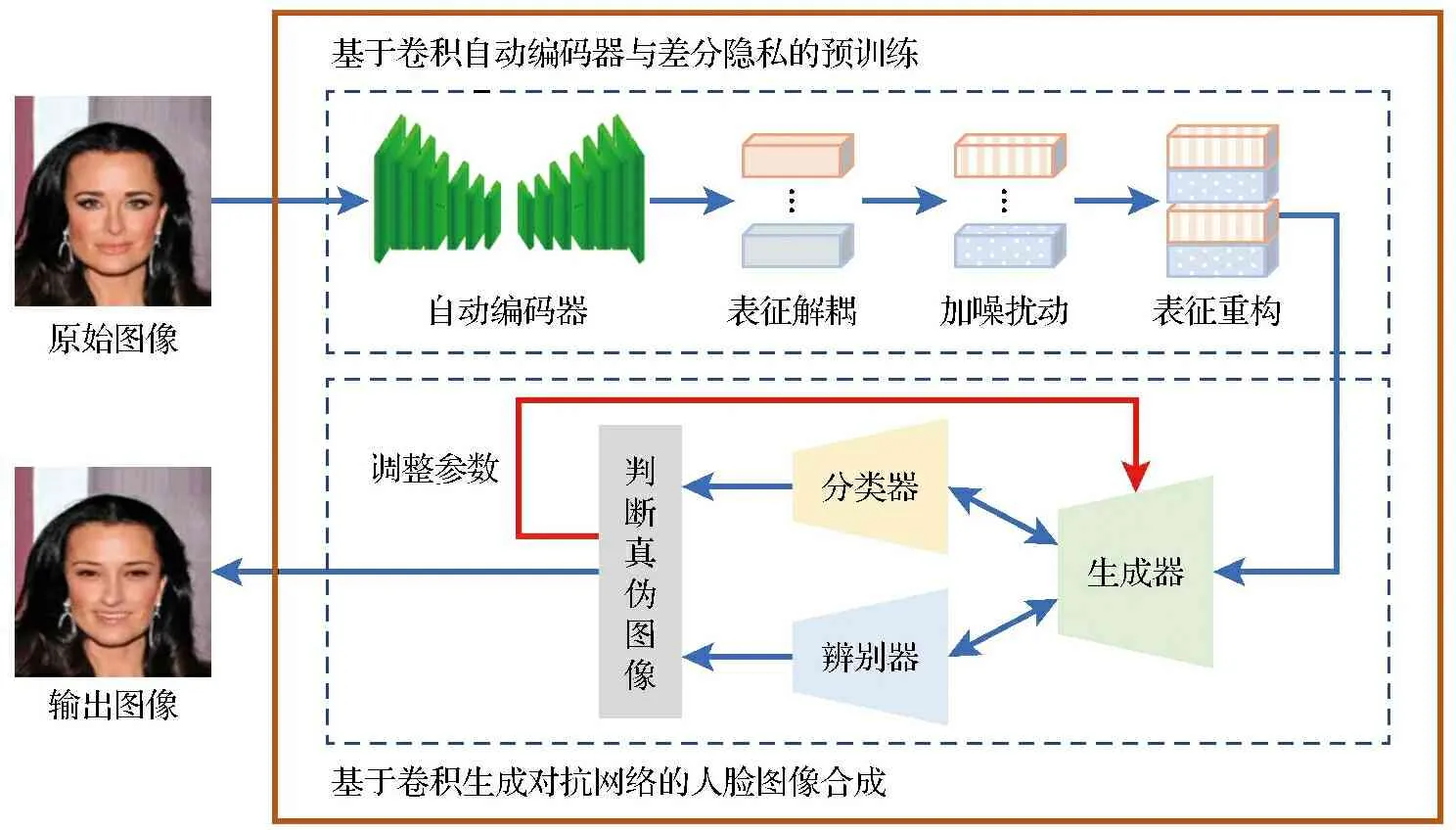
图1 基于卷积神经网络的人脸图像隐私保护方法框图Fig.1 Overview of privacy-preserving face images protection based on convolutional neural networks
1) 基于卷积自动编码器与差分隐私的预训练。首先,利用自动编码器来捕获人脸图像X中的身份属性和其他属性的隐空间信息表示;其次,根据身份属性的隐空间表示之间的距离对其添加Laplace扰动;最后,基于解码器人脸图像进行重构。
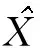
3) 人脸属性判别及输出。为了生成具有隐私保护属性的高质量的人脸图像,本文在生成对抗网络判别过程中引入了具有辅助引导功能的人脸属性分类器和人脸判别器,用于监督学习本文提出的基于卷和自动编码器与差分隐私的预训练网络框架。在训练过程中,辅助分类器被嵌入到判别器中,用于多个人脸属性的分类,然后将可控属性的约束反馈给生成器,以合成具有隐私保护功能的人脸图像,同时保证了人脸图像的实用性。同时,人脸判别器的目的是减少原始图像和合成面部图像之间的结构差异,使得生成图像域原始面部图像具有更相似的统计分布。最后,将合成后并具有隐私保护功能的人脸图像输出发布。
2.1 基于卷积自动编码器与差分隐私的预训练
该阶段由表征解耦、加噪扰动与表征重构3个子网络构成,通过卷积自动编码器和差分隐私实现预训练,使生成对抗网络在训练过程中满足差分隐私保护,在有效抵抗成员推断攻击的同时,实现可证明的隐私保护。
2.1.1 表征解耦
利用CACIAE人脸识别模型[12]将给定输入人脸图像X进行解耦成身份属性与其他属性(表情、光照、背景等信息),分别用隐空间信息x′id和x′att表示。将身份属性与其他属性的隐空间信息分别定义为Encid(X)=X′id、Encatt(X)=X′att,其中X′id,X′att表示人脸图像X的隐空间信息。
2.1.2 加噪扰动
通过根据图像中身份属性表征向量之间的距离度量控制噪声[13],提出一种基于距离度量的ε-差分隐私机制。
定义4 基于距离度量的ε-差分隐私机制。设距离函数d:n→n,若隐私算法M:n→n在图像X的表征向量X1与X2上的任意输出结果S满足
Pr[M(X1)∈S]≤eεd(X1,X2)Pr[M(X2)∈S]
(3)
则称算法M满足基于距离度量的ε-距离差分隐私。


证明 由公式(3)可得
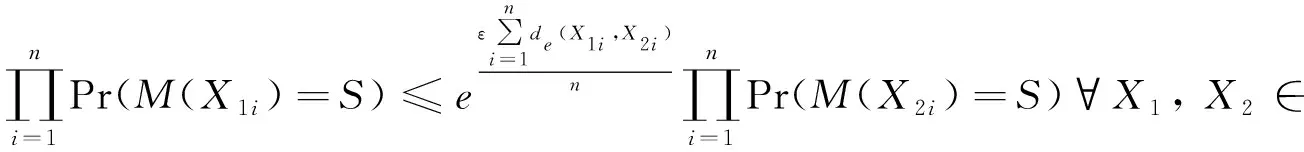
由Laplace分布可得

2.1.3 表征重构
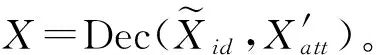
2.2 基于卷积生成对抗网络的人脸图像合成
根据定理,在预训练阶段已经通过添加扰动噪声的方式保护身份属性,该阶段算法满足差分隐私保护。因此,在图像合成阶段对数据做任何处理都不会对隐私保护有所影响,同时可有效抵抗在利用卷积生成对抗网络合成图像时的成员推断攻击。
在人脸图像合成阶段,为了避免经典的GANs存在训练不稳定、生成过程不可控以及不具备可解释性等问题,本文提出一种基于深度卷积生成对抗网络(Deep Convolutional GAN, DCGAN)的人脸图像合成模型SynthesisNet,该模型由生成器模块、判别器模块与分类器模块3个子网络组成。
2.2.1 损失函数
为了生成与原始图像相似的身份保护图像,设计生成器G的损失函数LG,tot并利用反向传播的方式进行训练:
LG,tot=LG,orig+LG,info+LG,class
(4)
LG,class=
其中:LG,orig,LG,info分别表示生成器网络原始损失函数、合成图像与原始图像之间的信息损失函数;LG,class表示衡量生成图像的标签与分类器为该图像预测标签之间差异的损失函数,l(·)表示返回输入记录的标签属性值函数;remove(·)表示去除输入图像标签属性函数;C(·)表示分类器神经网络预测标签函数。
判别器网络D用于分辨图像是真实图像还是合成图像,使用DCGAN中的原始损失函数LD,tot训练判别器网络。为了保持合成图像与原始图像之间的身份一致性,在原始DCGAN网络模型基础上,设计分类器C的损失函数LC,tot用于预测合成图像标签:
LC,tot=Lc,class+LG,class
(5)
其中Lc,class=[|l(X)-C(remove(X))|]。
因此,训练神经网络的总损失函数的加权和为Ltot=LG,tot+LD,tot+LC,tot=Lorig+λG,infoLG,info+λC,totLC,tot,其中λG,info,λC,tot为平衡不同项的权重参数。
在实际训练时,在预训练阶段随机抽取2个人脸图像提取其身份属性和其他属性,并在基于DCGAN的图像合成模型时需要根据实时的生成效果调整训练参数,将它们进行合成。
2.2.2 神经网络结构
如图2所示,SynthesisNet模型使用实例归一化(instance normalization, IN)[15]代替批量归一化,将ReLU激活函数、LeakyReLU激活函数分别用于生成器G和判别器D,并引入辅助分类器C[16]到判别器中。

图2 SynthesisNet模型的网络结构Fig.2 Network structure of face image synthesis model
1) 生成器网络G。由多个反向卷积层组成,用于生成与真实人脸图像具有相同分布的伪图像。它的输入是128×128的RGB人脸图像X,前2个反卷积层使用步长为2,由实例归一化层组成,并应用非线性ReLU激活函数计算每一层,最后将图像上采样到128×128。
2) 判别器网络D与分类器网络C。如图2所示,将判别器网络D和分类器网络C组合成一个网络,用于判别图像是生成图像还是真实图像,并保持真实图像与生成图像的语义一致性。分类器网络C与判断器网络D具有相同的神经网络结构,训练分类器从图像中判断标签与其他属性之间的相关性,保持生成器合成图像在语义上的正确性。例如,输入图像性别“性别=女,年龄段=青年,种族=白种人”,分类器可以确保输出图像的语义完整性,即为“性别=女,年龄段=青年,种族=白种人”。虽然DCGAN中的判别器D在一定程度上可以实现语义一致性,但其本身存在一些生成实例不正确的问题,为此引入分类器网络,帮助判别器提高语义完整性,减少分类错误。判别器D的输入是128×128的真实或生成图像,除最后一个卷积层外的所有层在2个网络之间共享参数,所有共享的卷积层使用LeakyReLU非线性激活函数。在最后一层,2个网络使用单独的卷积层,其中判别器D根据DCGAN计算损失,返回一个标量分数,同时分类器网络返回每个属性类的概率向量。
3 实验评估
本文采用的实验环境为8GB内存,Intel Core i5处理器,2.3 GHz;GPU为NVIDIA GeForce GTX 970。所有实验在Ubuntu 14.04操作系统上执行,分别采用Python和TensorFlow作为本实验的编程语言和机器学习库。
3.1 实验设置
3.1.1 数据集
本实验使用3种公开数据集:
1) MUCT数据集[17]。包含276位受试者的3 755张图像,其中1 844位为男性,1 911位为女性,使用5个网络摄像头在不同光照下捕获。
2) MORPH数据集[18]。MORPH数据集包含55 134张面部图像,涵盖13 000个独特的身份,其年龄跨度从16~77岁。同时,该数据集还包含多样的人脸图像属性信息,包括不同年龄、性别等。在具体的网络学习中,本文将MORPH数据集分为训练集和测试集,其中,训练集包含50 020张人脸图像,测试集中包含4 925张人脸图像,根据上述数据集比例进行实验对比分析,验证人脸图像的隐私保护性能。
3) CelebA数据集[19]。包含202 599张人脸图像,其中84 434位为男性,118 165位为女性。
由于CelebA的种族标签分布严重偏向白种人,而MORPH则严重偏向非洲血统的人,因此,在实验时将CelebA和MORPH数据集以留出法的方式分为训练集和测试集,训练出种族分布相对均衡的模型。MUCT数据集用于合成图像的隐私性和可用性评估。
3.1.2 评价指标
1) 可用性。使用IS(Inception Score)[20]和FID(Fréchet Inception Distance)[21]作为可用性评价指标。IS用来衡量GANs网络生成图像的质量,IS=exp(xDKL(p(y|x)||p(y))),其中x表示给定的图像,y为标签。IS值越高,图像质量越好。FID使用Inception network分别提取真实图像与合成图像中间层的特征,计算2个多维特征分布之间的距离,FID=+Tr(C+Cr-2(CCr)1/2),其中m,mr分别表示真实图像与合成图像的特征均值;C,Cr分别表示真实图像与合成图像的协方差;Tr表示矩阵对角线上的元素和。
2) 隐私性。采用基于Inception-Resnet backbone[22]的身份距离作为图像隐私性的评价指标,衡量真实人脸图像与合成人脸图像的身份差异。
3.2 实验结果与分析
本节对提出的SynthesisNet模型与DeepPrivacy模型[3],FaceDCGAN模型[4]、HybridGAN模型[5]在隐私性与可用性方面进行比较、评估与分析。
3.2.1 可用性评估
1) 视觉评估
首先将SynthesisNet与其他3个模型分别在MUCT数据集、MORPH数据集和CelebA数据集上训练生成合成图像,结果见表1。DeepPrivacy模型与HybridGAN模型利用匿名化的思想对原始人脸图像进行隐私保护处理,产生的合成人脸图像精度不高,结果容易发生面部错位的问题;而FaceDCGAN模型无法保证原始图像与合成图像之间的语义一致性;SynthesisNet模型在细节上的表现好于其他模型的结果。该模型在实验中使用预训练的方式解耦面部特征后对其进行合成处理,在保证原始图像与合成图像之间的语义一致性的同时,合成图像的视觉效果在精度方面也显著提升。

表1 SynthesisNet与其他模型在视觉评估方面的比较结果Table 1 Comparison between SynthesisNet and other models in visual evaluation
2) 定量分析
在3个数据集上对SynthesisNet模型与其他3个模型计算可用性评估指标IS和FID,结果见表2。从表2中可以看出,在3个数据集上SynthesisNet模型的性能明显优于其他3个模型,其原因是本文提出的方法使用卷积自动编码器提取图像更高维的隐空间信息来充分表示完整的人脸属性,将该属性作为输入可以缓解利用反向传播训练生成对抗网络时产生的梯度消失问题,提高模型的泛化能力。
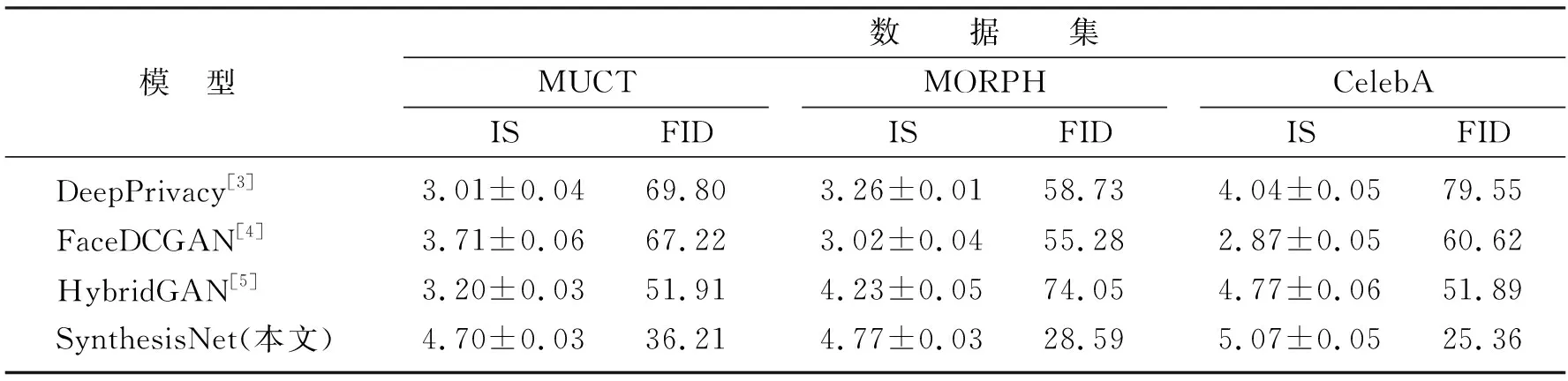
表2 SynthesisNet模型与其他模型的可用性比较结果Table 2 The results of SynthesisNet and other models in the utility evaluation
3.2.2 隐私性评估
为了在人脸图像数据集上评估身份差分隐私机制的隐私保护效果,首先提取每张测试图像的身份表征并计算敏感度,然后将隐私预算ε设置为0.01到1评估提出模型的隐私保护效果,实验结果如图3所示。从图3中可以看出,当ε从0.01增加到1时真实图像与合成图像的身份距离逐渐变小,这说明较小的隐私预算保证了更好的人脸图像的隐私性,通过调整ε的大小可得到理想的隐私保护效果。
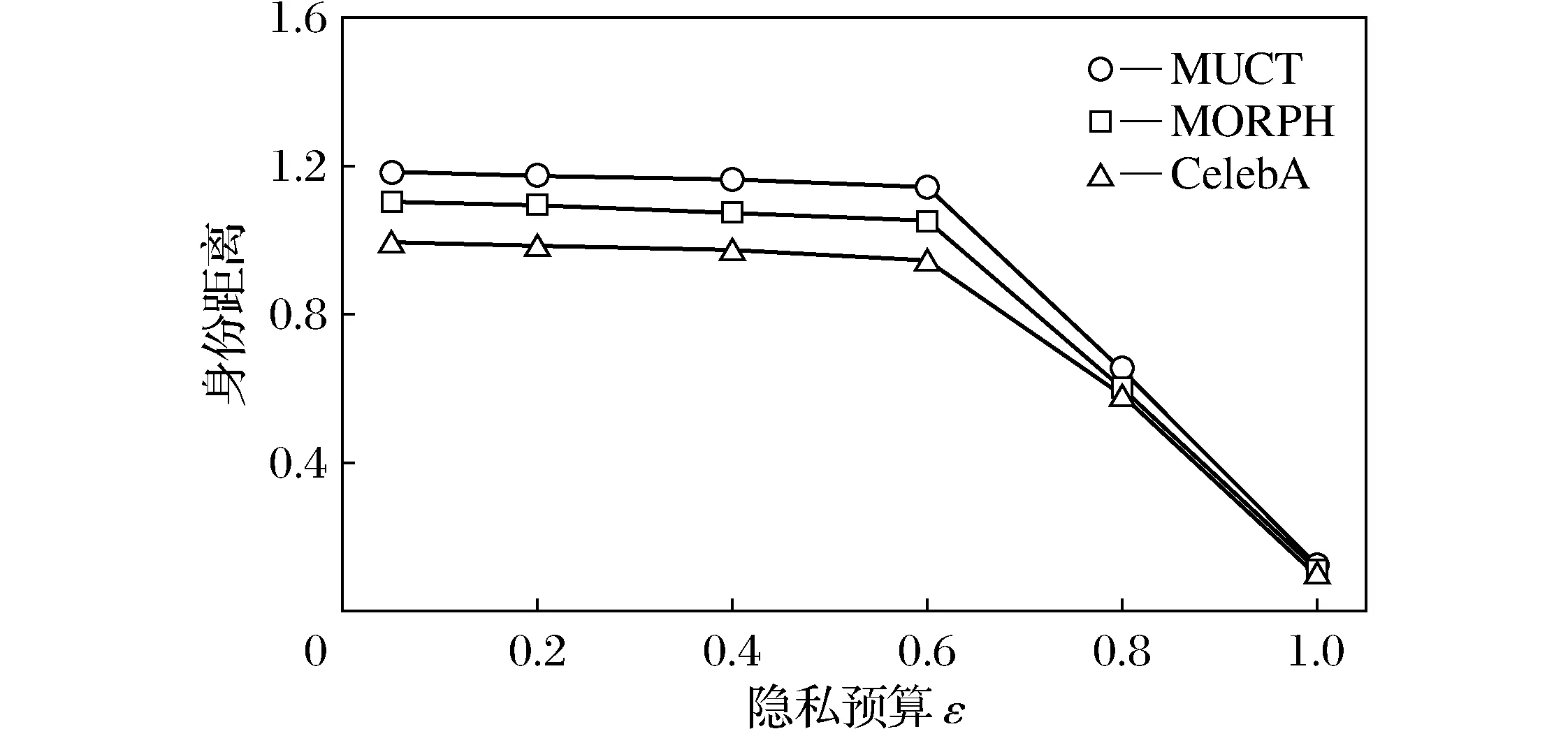
图3 SynthesisNet在3个数据集上的隐私性分析Fig.3 Privacy analysis of SynthesisNet in three datasets
4 结 语
人脸图像隐私保护问题是目前数据发布领域的研究热点。针对现有的方法缺少可证明的隐私性、无法在保持隐私性和可用性之间优化权衡的同时生成语义合理的图像的问题,本文提出一种基于卷积神经网络的人脸图像隐私保护方法,利用卷积自动编码器与差分隐私为生成对抗网络提供预训练后的人脸图像,并合成伪图像代替原始图像发布。该方法可有效平衡图像隐私性和可用性,在保持人脸图像的语义完整性的同时,为发布图像提供可证明的隐私保证。在未来的工作中,尝试将本文的方法进一步优化,将其应用于保护高分辨率的视频人脸图像。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
新世纪智能(数学备考)(2021年5期)2021-07-28
动漫星空(2018年9期)2018-10-26
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
信息安全研究(2015年3期)2015-02-28
发明与创新(2015年33期)2015-02-27
太空探索(2014年1期)2014-07-10
奇闻怪事(2014年5期)2014-05-13
