
机器学习在油气开发领域的应用及展望
2023-10-12 05:40:58吴湛奇李彦阅曹伟佳赵维义
西安石油大学学报(自然科学版) 2023年5期
谢 坤,吴湛奇,李彦阅,梅 杰,曹伟佳,赵维义
(1.东北石油大学 提高油气采收率教育部重点实验室,黑龙江 大庆 163318; 2.中海石油(中国)有限公司天津分公司 渤海石油研究院,天津 3004592)
引 言
自20世纪60年代以来,我国石油工业蓬勃发展,但目前大庆油田、长庆油田和胜利油田等主力老油田普遍进入高含水或特高含水后期开发阶段,剩余可采储量难以高效动用、原油产量降低[1],因此,寻找一种能够降低开采成本和进一步提高油气采收率的方法尤为迫切。各大油田在长期开采中保留有大量生产数据,通过有效的数据分析可以掌握储层物性、可采储量和开发参数等生产数据之间的内在联系,由此确立进一步开发方向,支撑开发决策调整[2]。然而,随着生产数据的持续增多,数据分析越发困难,传统人工经验分析难以满足油气田高效开发的需求。
随着计算机科学的发展,机器学习技术逐渐成熟,一方面,计算机利用机器学习算法可从数据内部学习到隐藏的规律,实现对未知数据的预测;另一方面,计算机直接从数据中学到知识,免去了人工总结知识输入计算机的过程,极大降低了人力物力成本[3]。机器学习适合海量数据的智能分析与计算,已在测井解释[4]、地震解释[5]和设备故障诊断[6]等方面初步应用,众多学者也将机器学习应用到了油气开发领域数据分析中。Nande等[7]根据给定油井的微型压裂数据,运用人工神经网络建立了水力压裂闭合压力预测模型,提出通过增加数据量可以增加模型预测精度,减少了人为因素对结果的影响。韩学辉等[8]利用最小二乘支持向量机(Least Squares SVM,LSSVM)建立储层岩性识别模型,测井识别岩性与岩心分析资料的符合率可达80%以上。可见,计算机通过机器学习可以提升数据分析精度、提高工作效率,是高效分析油气藏数据的理想工具。
目前,全球石油工业正朝着数字化、智能化方向发展,国内外各大油田企业向着数字化转型[9],机器学习的应用成为行业前沿技术之一。本文结合油气开发的实际需求,调研了机器学习在油气开发领域的应用现状,并从储层物性和流体分布识别、储层物性时变和油气产量预测、油气藏开发方法优化和提高采收率方法优选4个方面进行阐述,总结当前研究存在的不足,探讨机器学习未来的应用趋势。
1 机器学习概述
1.1 机器学习发展历程
机器学习(Machine Learning,ML)是人工智能的一个分支,本质上是计算机运用数学原理和算法分析大量数据,从中提取知识、构建学习模型并对新情境作出判断的过程。机器学习使计算机像人一样自发学习事物内部蕴藏的规律,使自身获得新知识,并将学到的知识用于分析新的事物,学习规律和分析新事物的过程,相当于人类大脑进行归纳与演绎[10]。
18世纪出现的贝叶斯统计和后来的最小二乘法、马尔可夫链等数学方法奠定了机器学习的数学理论基础。机器学习的起源可追溯至20世纪50年代的图灵测试,该测试证明计算机可以拥有与人类似的自主学习和思考能力,之后人们尝试将逻辑推理能力赋予计算机使其获得智能,感知机就此诞生[11],其应用多组人工神经元模拟人脑对客观事物的学习能力,但计算机知识储备不及人类丰富,未能获得真正的智能;20世纪70年代,科学家开始总结人类的知识授予计算机,但知识量过于庞大,无法将所有知识输入计算机,出现了“知识工程瓶颈”;此后,人们注重使计算机自主获取知识,真正意义上的机器学习出现。早在20世纪90年代,机器学习就已被应用于油气行业中,彼时一些大型石油公司联合成立了名为Petrotechnical Open Soft Ware Crop的非营利性组织,旨在解决石油工程中的数据孤岛问题,其核心工作就是建立数据模型和数据库。此后,随着学科交叉的逐渐深入,机器学习被用于解决油气开发领域的各种问题。21世纪以来,信息化和大数据迅猛发展,机器学习逐渐衍生出了深度学习(Deep Learning)这一分支。深度学习算法赋予了计算机更强的自主学习能力,能够解决更加复杂、计算量更庞大的问题,使得人工智能取得了极大进步[12]。如今,深度学习被广泛应用于油气开发领域,成为行业前沿技术之一,在智能油田的建设中起到重要作用。
1.2 油气开发领域常用机器学习模型
机器学习模型是算法的具体体现,它赋予了计算机自主分析数据、总结数据内部规律并进行未知数据预测的能力。常用于油气开发领域的机器学习模型及特点见表1。

表1 油气开发中常用机器学习模型及特点Tab.1 Common machine learning models for oil and gas development and their characteristics
2 机器学习在油气开发领域的应用现状
机器学习主要用于对油气开发过程中产生的各种数据进行分析,找出数据之间的关联并建立数学模型,实现数据预测、数据聚类等目的。国内外学者利用机器学习在储层物性和流体分布识别、储层物性时变预测、油气产量预测、油气藏开发方法优化和提高采收率方法优选等方面开展了诸多研究,均取了得良好效果。
2.1 储层物性和流体分布识别
2.1.1 储层物性识别
现阶段,油气藏储层岩石物性分析和识别方法主要有交会图版法和测井成像法,但随着研究逐渐深入,数据量不断增大、岩层条件也越发复杂,现有技术在应用过程中会出现对专家经验依赖过多、实验周期较长且精度较低等问题。随着计算机科学的进步,机器学习在解决多分类问题上展现出巨大优势,成为岩性识别重要研究工具之一。谷宇峰等[23]提出采用GS算法优化的LightGBM模型进行致密砂岩岩性识别,该模型在XGBoost的基础上对基础学习器的构建进行了优化,减少了样本冗余,预测精度最高可达92.61%,在现场应用中具有良好的适用性。王妍等[24]和马陇飞等[25]分别提出基于CART算法的RF模型和梯度提升树(GB-DT)模型,实现了对致密砂岩地层岩性的高效精确识别和分类。这两种模型都是由决策树改进而来,能够在复杂地层条件下对岩石物性进行精准分类,有较高的应用价值和较广泛的适用性。柴明瑞等[26]选取准噶尔盆地致密砂砾岩储层,利用SVM、RF与BP神经网络-Bagging等方法基于测井资料进行砂砾岩岩屑种类和含量预测,其中RF平均相对误差绝对值为17.17%,表明该方法在岩屑成分复杂、训练样本较小的情况下能够很好地进行岩屑成分识别。
针对缺少碳酸盐岩孔隙和矿物含量三维图像识别研究的现状,Alfarisi等[27]提出利用机器学习算法,通过分析微计算机断层扫描图像和磁共振成像计算孔隙度和储层岩性,并建立3D微观模型,研究运用高斯模糊算法优化微计算机断层扫描图像的分辨率,并通过随机森林算法对核磁共振图像进行识别。
2.1.2 流体分布识别
测井曲线人工解释等经典储层流体分布识别方法多依赖于专家经验,在强非均质性复杂储层中流体状态的识别中难免存在效率低下、精度不足等问题。为此,蓝茜茜等[28]建立了一套多种技术融合的复杂储层流体分布识别模型,该研究分别使用深度学习网络和混合采样技术进行特征提取和样本平衡优化,并通过在神经网络中添加Softmax层、引入ReLU激活函和Dropout正则化的方法优化网络结构,总体识别准确率超过80%,展现了深度学习在复杂储层流体分布识别中良好的应用效果。对于注水开发油藏,注水剖面是调整注水策略的重要依据,但有些注水井中注水剖面缺失,无法判断地层注水状态。赵艳红等[29]运用高斯混合模型(GMM)聚类方法,按注水强度、绝对注入量、相对注入量和有效厚度将地层吸水状态分为4类,实现注水通道状态高精度识别,极大地方便了后续注采调整等工作。
20世纪80年代以来,卷积神经网络(Convolutional Neural Networks,CNN)出现并迅速发展,其汲取了生物视觉原理,在传统人工神经网络的基础上构建了卷积层和池化层,能够实现图像特征提取和精准识别,在众多图像识别实验中取得了良好效果,被广泛用于计算机视觉等领域。Wang等[22]利用CNN的优势,引入基于深度学习的智能图像识别技术Mask R-CNN,实现了计算机从高分辨率剩余油图像中识别微观剩余油赋存状态和宏观剩余油分布状态,将蒸汽驱和化学驱在不同驱替阶段剩余油识别结果以像素图的形式展现,如图1所示。

图1 神经网络识别剩余油分布情况[22]Fig.1 Recognition of residual oil distribution by using neural network[22]
2.2 储层物性时变和油气产量预测
油气藏储层内部流体的状态在开发过程中会发生变化,进而导致储层物性参数发生变化,对原油的开采造成一定影响。掌握油气藏动态变化情况是制定开发方案的重要前提,对油气藏储层物性参数和产量作出分析预测可以更好地掌握储层情况,进而指导开发工作。机器学习凭借其在数据分析上高效、智能和低成本等优点,在储层物性参数预测和产量预测[30]等方面得到了广泛应用。
2.2.1 储层物性时变预测
孔隙度、渗透率和流体饱和度等是反映储层油气开发动态的重要参数,准确对这些参数做出预测,能够掌握油气藏开发动态走向,更好地进行开发方案制定和调整。常规储层参数预测方法是通过经验公式建立简化的数学模型,计算储层参数,在储层条件复杂的情况下预测精度有限[31]。相较于决策树等机器学习算法,人工神经网络算法往往具有更强的计算能力和更高的预测精度,众多学者运用神经网络展开了储层物性参数预测建模研究。
Chen等[32]开发了一种多层长短记忆网络(MLSTM)的孔隙度预测模型,该模型的隐藏层由多个LSTM组成(图2), 使用Adam算法优化连接权重,具有比传统LSTM神经网络更高的预测精度和鲁棒性,适用于不同深度油井数据分析。侯贤沐等[33]认为基于测井曲线预测碳酸岩储层孔隙度和渗透率的经验公式具有较大误差,而数字岩心等方法过程繁琐、条件局限性较大,因此采用LSTM预测孔隙度和渗透率,同时研究不同输入参数的改变对各个模型预测精度的影响,预测精度较高。Tariq等[34]在现有含水饱和度预测模型精度不高的情况下,基于神经网络建立了含水饱和度预测模型,并利用粒子群优化等算法进行模型优化,预测结果误差小于5%。
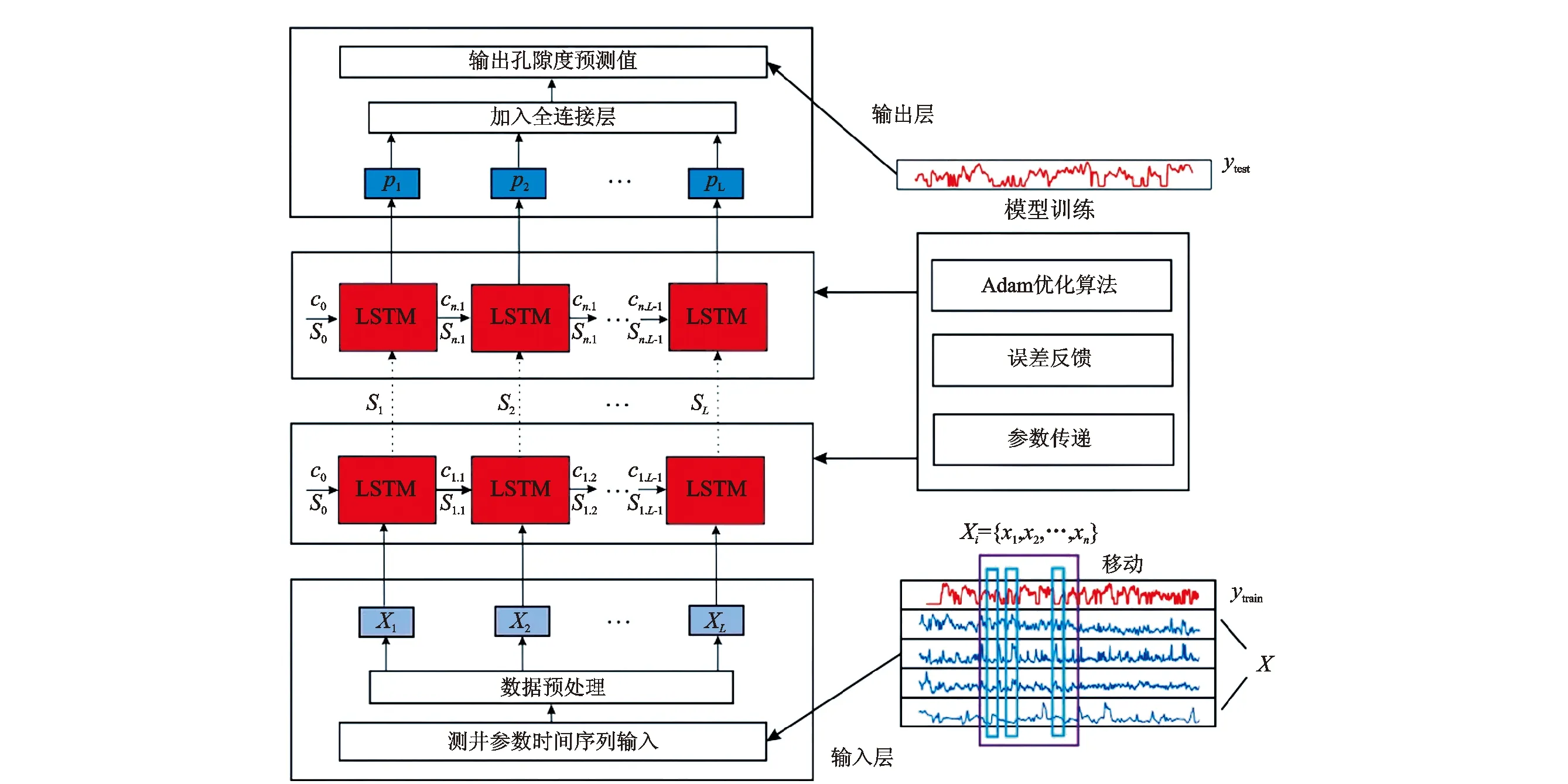
图2 MLSTM原理框架图[32]Fig.2 Principle framework diagram of MLSTM[32]
储层内的夹层可能改变注采井的连通性,对驱油过程和剩余油的分布产生影响,准确判断井间连通性对开发过程中实时井网调整等具有重要意义。Liu等[35]采用BP神经网络和卷积神经网络(CNN),采用原油产量、含水率和注水压力作为输入变量,实现了夹层平均渗透率和倾斜角度预测,进而由此计算井间连通系数,实现夹层影响下的井间连通性预测,面对3 600个样本,两种机器学习模型运行用时均不超过1 s。准确进行储层物性测井解释对石油勘探开发具有重要意义,陶静等[36]利用一对一支持向量机(OVO SVM)和RF进行油水层解释,并采用10折交叉验证法进行参数优化,解释准确率超过90%。机器学习能高效处理非线性问题,因此在非均质条件下依然能够准确进行储层物性预测,同时提高了预测时效性。
2.2.2 油气产量预测
BP 神经网络算法被应用于油气产量预测[37],但由于其采用梯度下降法最小化损失函数,不可避免地会陷入局部极小值、收敛速度慢等困境。许多学者尝试用智能优化算法优化BP神经网络模型,解决了局部极小值问题,加快了收敛速度。田亚鹏等[38]用遗传算法优化BP神经网络,获得更精确的节点间连接权重和阈值,建立了页岩气产量递减预测模型,提出此方法对页岩气产量递减预测优于单独的BP神经网络。
在油气藏开发中,原油产量信息具有一定的时序相关性,BP神经网络由于自身特性限制无法关联前后数据,导致预测精度不够理想。侯春华等[39]采用LSTM建立了原油产量预测模型,预测精度较BP神经网络高八个百分点以上。Song等[40]应用LSTM预测火山岩油藏压裂水平井的产量,并采用粒子群算法优化LSTM结构,取得了较好效果。
集成学习模型在数据分析中往往拥有较强的泛化能力,适合处理高维数据,越来越多研究者将集成学习融入油气开发领域。何佑伟等[41]用RF预测页岩气藏气井产量,建立了准确度达90%以上的模型,并提出压裂因素对预测结果影响较大的结论,该研究中收集的数据缺失值达34%以上,均值填补法不适用,因此通过已知数据建立线性模型预测要填补的数据。
2.3 油气藏开发方法优化
由于储层条件复杂、数据不足和依赖人为经验等原因,诸如数值模拟注采优化等经典方法难免存在精度不够高、效率较低等问题,这种情况下,机器学习成为优化开发方法的新选择。
在页岩油藏开发中,影响焖井时间的因素众多、计算过程复杂且数值模拟计算成本较高,难以在短时间内确定合理焖井时间,给页岩油高效开发造成困难。杨红梅等[42]运用线性回归、SVM和多层人工神经网络(MPN)方法建立焖井时间预测模型,确定焖井时间主要影响因素,并在此基础上进行焖井时间优化,证明了焖井时间经机器学习优化后,累产油较原先增长约8.5%,同时提出毛管力大小、入地液量以及原油黏度对合理焖井时间影响较大。该方法为现场明确焖井时间主控因素、合理焖井时间计算指明了方向,方便了页岩油藏开发方案优化设计。
王文东等[43]认为传统水驱油藏优化方法过于依赖专家经验,提出一种基于RF和径向基函数(Radial basis function,RBF)神经网络的井位及注采参数联合优化方法,研究采用RF筛选出影响注水开发效果的主控因素并作为RBF神经网络的输入,建立了注采井网开发效果预测模型,最后结合粒子群算法筛选出最优注采井网方案,实现了从参数部署到预测结果提取及保存的全过程自动化和智能化。贾德利等[44]结合机器学习算法和数据同化算法等算法实现了老油田中油藏的精细注水优化。其中,采用K-Means聚类算法将注水效果分为好、较好、中、较差和差5类,判断注水井组中增注、减注、维持注水量,并采用决策树定性分析注水调整方向(图3),最后用粒子群算法和小生境算法对注水井组配注量进行优化,实现提高区块产油量和降低区块含水率的目标。

图3 决策树调整注水方向示意图[44]Fig.3 Schematic diagram for adjusting water injection direction using decision tree[44]
处理复杂问题时,多种智能算法相结合往往可以获得很好的效果。在水驱开发油藏中,层间动用差异大、非均质性强和油水关系复杂等问题突出,传统注采井网优化方法面临过度依赖人力、周期较长及算力、精度不足等多种问题,且优化过程中往往涉及特征选择、参数预测、方法优化和效果评价等多个方面,采用多种机器学习模型、结合模型自身特点有针对性地处理问题是许多学者常用的研究手段。
2.4 提高采收率方法优选
目前,热采、化学驱和微生物驱等提高油气采收率方法均有应用,但不同提高采收率方法的油气藏适应性相差较大,选择适合特定油气藏的提高采收率方法成为油气藏开发研究的一个重要方面,若筛选错误,可能导致极大的经济风险和资源浪费。传统提高采收率方法的筛选对专家经验依赖较多,且备选方法难以涵盖所有的提高采收率方法。为了更好地进行提高采收率方法筛选,机器学习被一些学者用于该领域中。
Cheraghi等[45]在前人研究的基础上,用决策树、RF、ANN、朴素贝叶斯等算法筛选提高采收率方法,并比较了不同模型的预测效果,提出机器学习算法筛选结果比传统方法具有更高的可靠性,且RF效果最好,准确率达91%。Pirizadeh等[46]综合Boosting算法降低偏差和Bagging算法降低方差的优势,提出了一种RF与XGBoost结合的B2S模型,该模型第一层为两组独立的RF和XGBoost,每组有8个学习器,输出的结果传给第二层的神经网络元学习器(图4),很好地解决了提高采收率方法筛选中的类不平衡问题,同时该方法采用随机搜索法调整超参数,有效克服了贪婪搜索带来的局部最优解问题。

图4 提高采收率方法优选B2S模型[46]Fig.4 B2S model for optimization of enhancing oil recovery methods[46]
3 面临问题与展望
机器学习与油气开发的融合取得了系列创新成果,正推动油气工业迈向数字化和智能化。机器学习能够规避许多传统方法的缺陷,有效简化数据分析流程,降低工程设计的时间和资金成本,提升分析结果的可靠性,使油田企业实现真正的降本增效。然而,现有利用机器学习指导油气开发的研究也暴露出了一些问题。
3.1 面临的问题
由于我国相关的研究起步较晚,油气开发领域的机器学习研究还面临着一些挑战,主要问题有以下几方面[47-49]:
(1)缺乏适合机器学习模型的训练样本库。国内油气田矿场数据质量良莠不齐,缺少标签化的、可以用于机器学习模型训练的数据库。从现场收集到的数据或多或少都存在缺失值和数据噪声,分析原因为:①由于传感器未普及和网络限制等原因,很难将矿场数据直接入库,大量参数需要各种实验室模型或人工分析解释,得到的数据存在一定误差;②样本数据获取难度较大,非常规油气藏储层结构复杂,采集的数据具有缺失性、不确定性的特点,难以获得供机器学习的标签数据;③数据孤岛的现象仍比较突出,在搜集数据时,会出现数据不同源情况。
(2)机器学习和油气开发缺乏深入结合。目前,熟悉机器学习算法的专家或程序员不具备油气专业背景,难以用现场经验先验地指导模型选择和参数调整。油气行业专家又对机器学习中的各个环节缺乏足够的了解,无法为编程人员提供有效的数据信息。相关研究需要油气开发领域和机器学习专家深度合作,克服单一领域专家的知识局限性。
(3)适用于油气开发领域的整体化人工智能平台较少。目前,国内大多数研究都针对于解决具体问题,未形能成体系化突破,而国外石油企业纷纷运用人工智能技术建立了地质建模、数据分析一体化平台,如斯伦贝谢推出了一款多维环境软件,将人工智能与多种技术整合到一起,解决油气行业复杂技术问题;Noble Energy公司推出了专属数据分析平台,实现了钻机智能化实时控制、钻井策略快速调整[50]。中国油气开发一体化平台构建起步较晚,还没有统一的模式和标准,理论研究居多,实际应用偏少,有待进一步发展,未来需要为处于特定开发状态的油田建立预测系统和模型库[51],打造集成岩性识别、产能预测、流体可视化识别和开发方法优化等多功能的智能油田开发平台,实现油气开发全过程智能化。
3.2 未来发展
(1)提升数据治理能力。未来应当将数据治理放到首位,结合物联网技术和云储存技术统一数据标记、推动数据互联,构建完善、优质的大容量机器学习用样本云数据库,实现数据无障碍共享,使油田向数字化转型。在数据收集上普及传感器的使用,加强智能数据分析平台建设。石油企业可以和互联网企业、高新材料企业合作研发低成本、高精度、适用于油田开发作业的传感器,实时捕捉开发过程中的相关数据,节约人力成本和时间成本。在数据质量优化上,建立数据质量优化算法模型提高数据质量,使油田矿场数据真正可为机器学习所用,同时推动数据采集设备与优化算法模型、云数据库无缝衔接,将优化后的数据直接存入云数据库。
(2)加强学科融合。数值模拟技术被广泛用于油气开发仿真,在岩心分析、产量预测和开发工艺参数优化等方面发挥着重要作用。在岩心分析方面,3D数字岩心技术被广泛应用,但如何快速获取高分辨率岩心图像、重构近真实孔隙结构数字岩心的问题仍待攻克。可利用深度学习能够提取图片特征的优势,准确提取二维薄片中孔隙结构特征,获得高分辨率岩心图像,结合数字岩心技术实现近真实孔隙数字岩心重构。在产量预测和开发工艺参数优化方面,复杂储层和流体的仿真往往会消耗大量时间和计算资源,难以高效指导开发决策调整,应将机器学习与数值模拟有效结合,利用数值模拟生成的数据进行机器学习建模,充分发挥部分机器学习算法能够在进行生产状况预测的同时进行参数重要性分析的优势,分析数据之间的关联,实现数据预测和参数优化,辅助开发决策调整,减少对专家经验依赖,节约时间成本和人力成本。当前,Petrel、Eclipse等专业软件就通过不断引入人工智能技术,提高了智能化分析水平,实现了工程一体化模拟与设计,未来相关软件会强化人工智能模块,推动油田智能化程度进一步提高。
(3)加速一体化智能平台建设。将自动化、机器学习和数据挖掘等技术与油气田开发深度融合,构建具备自动数据采集、实时监测、自动化控制、生产趋势预测、方案优化等功能的智能油田开发系统,实现云数据库与机器学习智能算法互联,在数据监测的基础上进行实时生产状况预测和参数优化,有针对性地指导开发设计方案优化和开发决策调整。然而由于油气储层底下条件复杂,单一机器学习模型不具有普适性,机器学习的推广受到限制,因此,机器学习与油气田开发的结合还应从具体问题入手,分模块将多个机器学习模型整合进智能油田开发系统中,由点及面、逐步深入,打造少编程或无编程的油田开发一体化软件平台。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
——北美又一种非常规储层类型
石油与天然气地质(2021年5期)2021-10-29 01:30:08
加油站服务指南(2021年4期)2021-07-21 02:29:18
中国石油石化(2021年8期)2021-07-20 07:36:18
非常规油气(2021年2期)2021-05-24 03:23:36
西南石油大学学报(自然科学版)(2018年5期)2018-11-06 06:45:58
电影(2018年8期)2018-09-21 08:00:06
能源(2017年5期)2017-07-06 09:25:55
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
