
基于通道注意力和图卷积的激光三维目标检测
2023-10-12 01:10马庆禄黄筱潇孔国英
计算机工程与设计 2023年9期
马庆禄,黄筱潇,孔国英
(1.重庆交通大学 交通运输学院,重庆 400074;2.重庆奉建高速公路有限公司 工程管理部,重庆 401120)
0 引 言
现有的三维目标检测算法[1]分为两类:基于原始数据的方法和基于分区的方法。基于原始数据的方法是利用神经网络直接处理原始点云[2],目前基于此类方法的主要有PointNet[3]、PointNet++[4]、PointRCNN[5]等,此类算法推断通常需要很长的时间,不具备实时性[6]。基于分区的方法则是应用预定义的规则对三维空间进行分区构造,并通过使用CNN的变体来处理分区数据[7]。目前此类算法主要有VoxelNet[8]、Second[9]、PointPillars[10]等,此类算法能够减少大量的推断时间,在分区过程中生成单元特征应用于深度学习体系结构。如果通过网络学习单元特征,即使它们不会引起量化误差,基于分区的方法也会丢失一些信息。因此基于分区的方法不可避免地会丢失一些详细信息,称这种现象为分区效应。分区操作的缺点是固有的,为减少分区效应,提出了通道注意力图卷积(channel attention-graph convolutional network,CAT-GCN)框架,能够在分区操作后与基准网络级联形成一个额外的层,称之为特征增强(feature enhancement,FE)层,以增加极浅层的网络能力,捕获几何细节信息,减少分区效应。
1 基准网络的目标检测
为验证CAT-GCN的有效性,选取在各排行榜排名较高的PointPillars作为基准模型进行嵌入。在三维目标检测中,PointPillars接受点云作为输入,并为汽车、行人和自行车提供3D包围框。PointPillars主要利用柱特征网络(pillar feature net)将三维点云特征有效地转换为二维伪图像表示。柱特征网络首先将原始点云分解成柱状;然后,将柱子上的点存储在同一个阵列中,并记录这些点在原始空间点云中的位置。接下来,柱特征网络利用PointNet学习点柱中所有点的特征,通过MAX函数选取最突出的点,用所选点的特征替换整个点列中的特征,去掉Y轴信息。最后,利用记录点列的位置回归张量的位置,得到二维伪像。伪像是一个(C,M)大小的张量,其中C为卷积后的通道数,M为点的个数。柱特征网络层来学习局部点云特征。经过多层特征提取与融合,得到了具有丰富空间结构信息的单级目标检测网络,这是PointPillars网络中的重要的部分[11]。
实现目标检测的过程中主要包括3个阶段:①将点云转换为稀疏伪图像的特征编码器网络,即为将点云柱化;②二维卷积主干,用于将点云通过柱化后的伪图像进行多特征提取处理为高级表示;③检测头,其对目标进行检测,生成并回归3D框。
1.1 点云编码器
通过使用PointNet提取体素级特征,然后通过执行3D卷积执行对象检测,这非常耗时。PointPillars则首先通过将整个空间划分为支柱将点云转换为伪图像。二维卷积可以用于从伪图像中提取特征映射。将点云映射到伪图像要应用二维卷积结构,首先将点云转换为伪图像[12]。用坐标x,y,z和放射率r表示点云中的一个点。作为第一步,将点云离散到x-y平面上的等距栅格中,如图1所示。
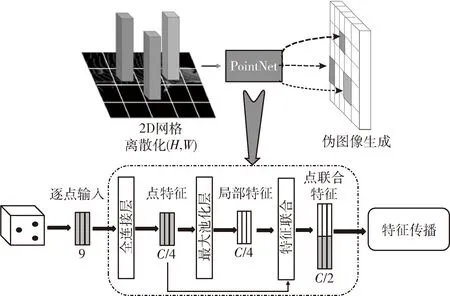
图1 Pillar特征提取层结构
图1中将落在一个栅格的点云数据被视为处于一个柱中。然后用每个柱的点增加xc,yc,zc,xp和yp,其中c下标表示到支柱中所有点的算术平均值的距离,p下标表示到支柱x,y中心的偏移量。由于点云的稀疏性,支柱大部分是空的,而非空支柱中通常只有很少的点。通过对每个样本的稀疏度(D)、非空柱数(F)和每个柱的点数(N)施加限制,可以利用这种稀疏性来创建大小为 (D,F,N) 的稠密张量。如果样本或支柱中包含的数据太多,无法拟合此张量,则会随机采样数据。相反,如果样本或支柱的数据太少,无法填充张量,则会应用零填充。接下来,使用PointNet中的特征提取模块,对于每个点应用线性层,然后是BatchNorm和ReLU,以生成 (C,F,N) 大小的张量。然后在通道上执行max操作,以创建大小为 (C,F) 的输出张量。最后创建大小为(C,H,W) 的伪图像,其中H,W表示图的高度和宽度。
1.2 伪图像卷积与检测头
使用与VoxelNet类似的主干,主干网有两个子网:一个自上而下的网络以越来越小的空间分辨率生成特征,另一个网络执行自上而下特征的上采样和串联。自顶向下主干可以由一系列块Block(S,L,F) 来表示。每个块的步幅为S(相对于原始输入伪图像测量)。每个块具有L层3×3的卷积层,具有F个输出通道数,每个通道后跟BatchNorm和ReLU。层内的第一个卷积步幅为S/Sin,以确保块在接收到步幅为Sin的输入后能在步幅上S运行。块中的所有后续卷积的步幅都为1。每个自上向下的块的最终特征通过上采样连接到网络Up(Sin,Sout,Fe),Sin为初始步幅,Sout为最后步幅,并得到最终特征Fe。接下来,BatchNorm和ReLU应用于上采样特征。最终输出特征是源自不同步幅的所有特征的串联。
在网络中使用单次激发检测器(SSD)设置来执行三维对象检测。每个添加的特征层可以使用一组卷积滤波器产生固定的预测集。重叠度(IoU)将先验框与地面真值进行匹配。边界框的高度不用于匹配,给定的2D匹配高度则会成为额外的回归目标。
2 CTA-GCN框架的特征增强
PointPillars在俯视图中对数据进行分区,并利用简化的PointNet块生成支柱特征。然后,将这些支柱特征投影到鸟瞰图上以生成伪图像。伪图像中的每个像素对应于原始数据空间中的一个小单元。不可避免地,有些实例被切成小块。这种现象类似于基于体素的方法的量化。由于这些特征是从分区单元中学习的,因此称这种现象为分区效应。对于大型对象,分割效应可能不会对3D对象检测任务造成严重影响,但是小目标在伪图像中容易丢失了几何形状,卷积运算不能有效地捕捉小目标的特征,同样基于体素的方法也存在同样的问题。因此,对于所有基于分区的方法,分区效应是提高小目标检测精度的主要障碍。
克服分区效应缺点的最直接方法是减小单元大小。这将增加空间和计算成本。因此,提出了一种在不改变单元大小的情况下提高每个单元的特征捕获能力的方法。通过在单元特征提取之后添加一个额外的特征提取层,以捕获更多的几何信息。这个额外的网络取代了CNN在浅层中的角色,后者捕获图像的纹理信息。称这种方法为特征增强,额外的层称为特征增强层(FE)。为了获得更多的几何纹理信息,特征增强(FE)层需要具备一些特性。①局部激活:应用FE层以提高对详细信息的检测能力。因此,FE层的神经元应仅通过局部场中的数据激活。②空间敏感:点云的信息存储在局部几何结构中。因此,神经元应该对几何形状敏感。因此基于以上条件,提出对于一种新的结构并嵌入PointPillars形成特征增强层,如图2所示。
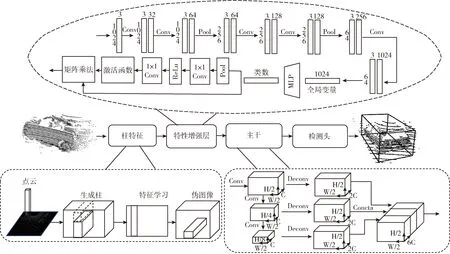
图2 三维点云目标检测网络框架
图2中Conv表示卷积,Deconv表示反卷积,Pool表示为池化,MLP为多层感知机。CAT-GCN通过与PointPillars级联形成FE层,其主要优化有:①在分区操作后添加额外的FE层。该额外层用于减轻3D对象检测中分割效应的负面影响。②为GCN添加了一种通道注意机制,该机制通过细化通道与通道之间的依赖性,学习不同通道的权重获取更多有有用信息的点云特征。③以通道注意图卷积(CAT-GCN)的新结构来形成FE层。CAT-GCN利用图卷积和通道注意机制有效地提取目标的详细几何信息。
2.1 特征优化处理
在卷积过程中出现了许多无效信息,导致网络性能降低。因此为了减少无效信息,在提取特征后加入通道注意力机制以增强网络处理能力,此处引入通道注意力机制[13],其能够通过网络自学习获取每个特征通道并根据其重要程度改进提取有用特征。在特征提取过程中有3个操作:Fsq为压缩操作,Fex为激发操作,Fscale为权重更改操作。
在提取特征到主干的输入过程中有输入特征图Ua∈H×W×C,Ua有C个通道,Uc表示特征图通道,每个通道空间大小为H×W,对每个通道进行全局平均池化对输入进行缩小,则通道权重Z的计算公式
(1)
式中:Z为通过压缩通道得到的权重,大小为H×W的特征图其横纵坐标用i和j表示,然后使用激活函数对各通道权重进行相关程度建模。得到1×1×C的输出如式(2)
SC=Fex(Z,W)=Sigmoid(W2×ReLu(W1,Z))
(2)
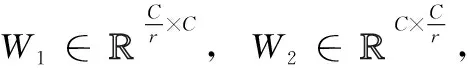
(3)
最终表现为特征图通道UC与通道注意力权重SC之间的通道元素互乘。在嵌入注意力机制后能够减少后续大量计算[14]。
2.2 卷积层网络改进
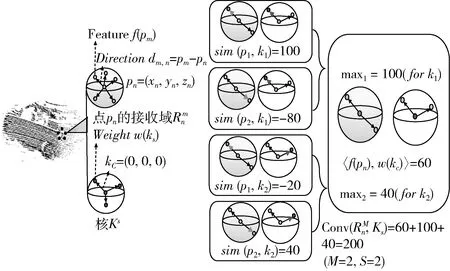
图3 相邻点的内积关系
通过余弦相似性计算出内积后,将获得相邻点云间最大的sim输出,再求和得到最终卷积输出,sim函数的定义为
(4)
根据上述定义,可以得到在3D-GCN中的3D图卷积运算计算如式(5)
(5)
其中,式(5)在内核ks中使用方向向量dm,n, 而不是全局坐标,这为3D-GCN模型引入了移位不变的性质。此外,相似性函数只计算dm,n和ks之间的余弦相似性,而不考虑它们的长度。因此,3D-GCN可以联合观察到尺度不变特性。
2.3 损失函数设计
参考基准网络设置损失函数。真实目标的边界框由 (x,y,z,w,l,h,θ) 表示,其中:x,y,z为边界框中心坐标;w,l,h分别为边界框的宽度、长度和高度;θ为边界框绕,z轴的偏航旋转角度。目标和锚点之间的线性回归残差定义为
(6)
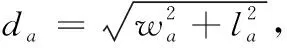
(7)
式中:SmothL1为L1的平滑函数,Δb∈(Δx,Δy,Δz,Δw,Δl,Δh,Δθ)。 而角度定位损失无法区分翻转的定位框,因此在离散方向上的损失使用softmax函数,对于分类损失使用focal loss函数
Lcls=-α(1-Ga)γlogGa
(8)
式中:Ga为锚点的概率,根据RetinaNe网络设定α=0.25,γ=2作为原始张量,总损失为
(9)
式中:Ldir=-logsj为离散方向损失,其中sj为输出向量的第j个值;Npos为正概率锚数;根据Second网络对常量权重进行设置βloc=2;βcls=1;βdir=0.2。 其中使用Adam优化器来优化200个时期的总损失函数。
3 实验设计
3.1 实验过程及分析
3.1.1 数据集准备与模型训练
实验中采用的激光点云数据和图像数据都来至KITTI公开数据集。该数据集在多种环境下采集,在训练过程中只使用KITTI中的点云数据,数据集中包含有7481个训练数据和7519个测试数据,训练过程中还需将训练数据分为3712个训练样本和3769个验证样本。其中激光点云数据使用的是线列机械转式激光雷达Velodyne HDL-64E,以10 Hz的频率进行采集得到。
实验环境为Ubuntu18.04操作系统,Python3.7,Pytorch1.5,处理器为Intel i5 CPU,显卡为Nvidia 2080Ti GPU。遵循KITTI提出的简单、中等、困难的分类,使用3D和鸟瞰图的AP评估检测结果。实验设置在KITTI上验证CAT-GCN的有效性。将柱边长设置为0.16 m,每个住的最大点数为100,最大柱数为P=12000:将所有编码器中线性层的输出通道设置为64,使用adam优化器优化函数,最大学习率为3×10-3,权重衰减为0.01,动量为0.85~0.95,训练批量选为16。
在实验选取基于分区的检测网络VoxelNet、Second和PointPillar作为对比网络以验证CAT-GCN网络的优越性。
3.1.2 实验结果对比分析
为验证加入CAT-GCN框架后的模型在检测小目标方面能够得到提升,因此选取场景与基准模型PointPillars进行对照实验,得到的小目标检测效果如图4所示。

图4 CAT-GCN与基准模型对比
图4中圈内为PiontPillars漏检目标,而CAT-GCN检测能够检测到的目标。可以看出在行人与自行车目标较为密集或离检测点太远时,出现了漏检情况,而CAT-GCN框架能够有效在卷积时减少重要信息损失,提高目标检测精度。
在训练结束后,通过对测试集的检验,评价指标选取为通过精准率与召回率计算得到的平均精度(AP),AP用于评估模型在单检测类上的精度,而AP值越高则证明目标检验精度越高,而平均精度(mAP)则能够表示整体检测精度,mAP越大则越能证明算法和模型的优越性。在将测试集通过模型检测后得出结果数据,实验最终以三维检测结果精度与鸟瞰图(bird’s eye view,BEV)检测精度展示。结果见表1、表2,其中APcar为汽车检测精度,APped为行人检测精度,APcyc为自行车检测精度。将VoxelNet、Second、PointPillar和CAT-GCN进行结果对比。
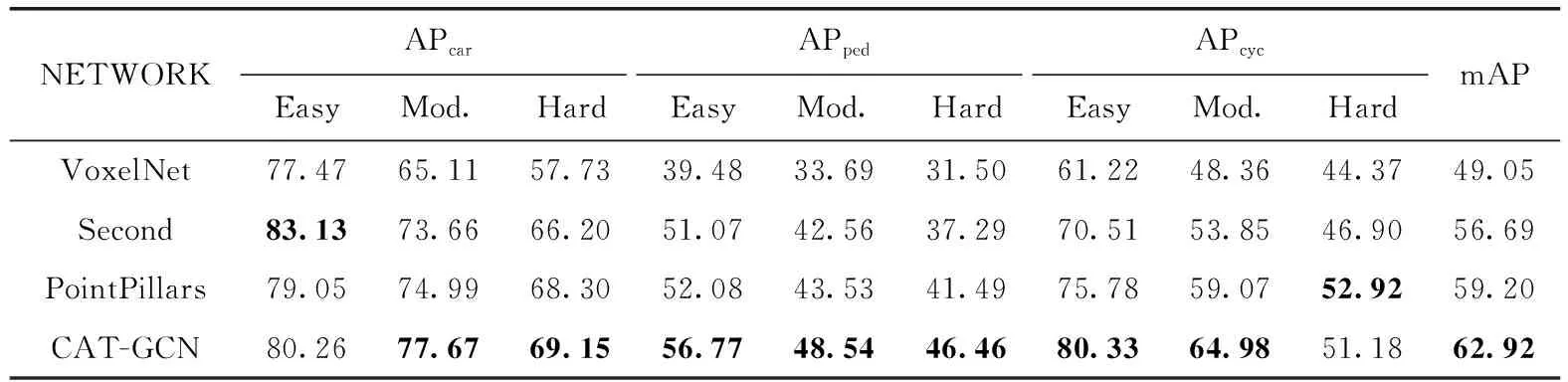
表1 3D检测结果精度对比/%
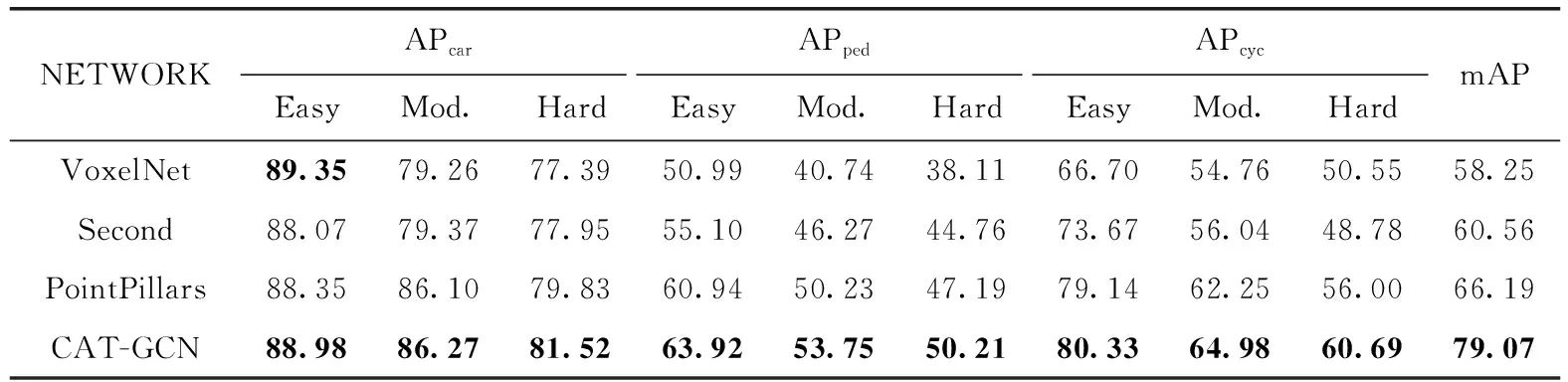
表2 BEV检验结果精度对比/%
从表1可以看出:GAT-GCN在所有类检测结果中均取得良好的结果,相对于PointPillars算法,三维模式下,mAP从59.20%增加到62.92%,并且在所有类的对比中GAT-GCN的检测精度多为最高的,验证了GAT-GCN模型的有效性。
从表1、表2可以看出CAT-GCN与其它模型的对比中,多种目标的检测精度都是最高的。CAT-GCN与其它模型的对比中在各种类别的目标检测中都展示了其优越性。CAT-GCN网络与其它网络模型AP的对比如图5所示。
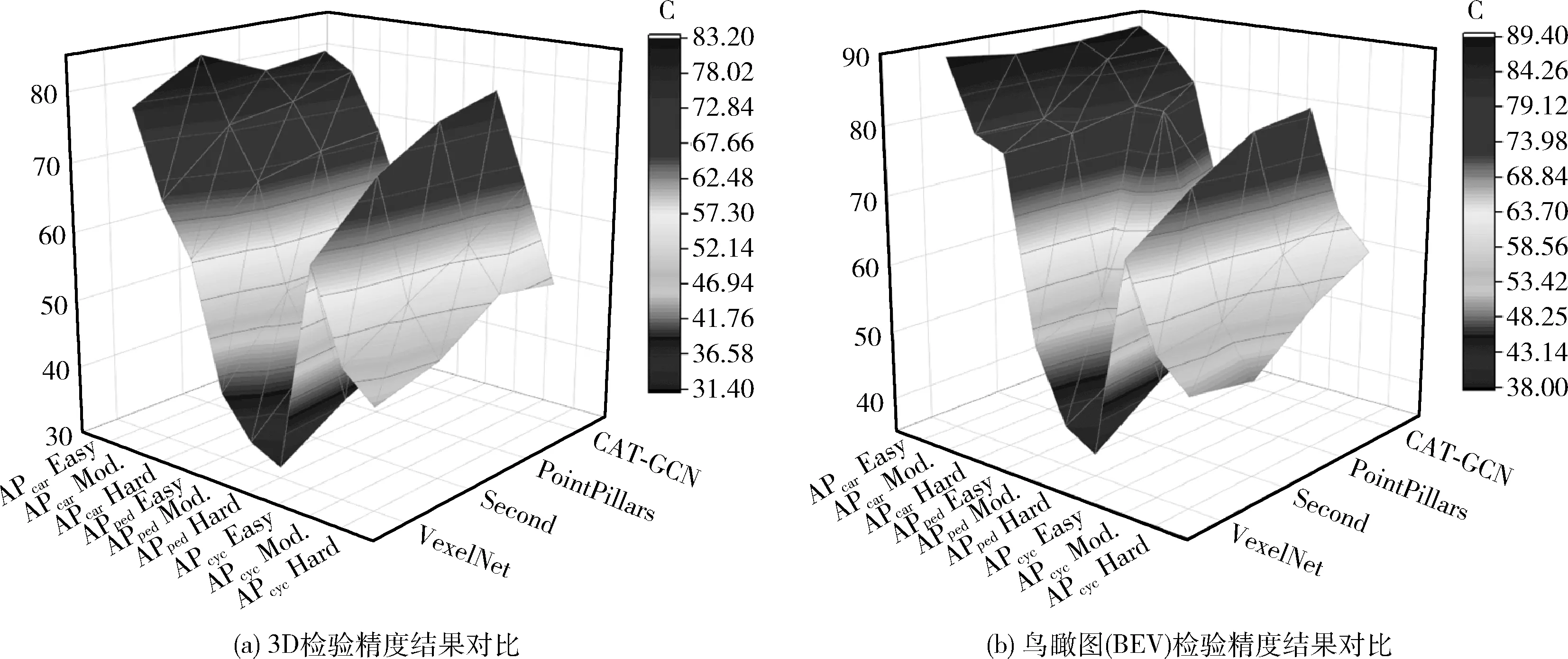
图5 检测精度对比
图5中X轴为类别检测难度,Y轴为不同的检测算法,Z轴为检测精度。可以看出在所有算法中CAT-GCN的三维与鸟瞰图所有类的AP大多是最高的,由此可看出在所有算法中CAT-GCN检测精度结果最为优异。在小目标的检测中改进网络CAT-GCN与基准网络对比如表3所示。
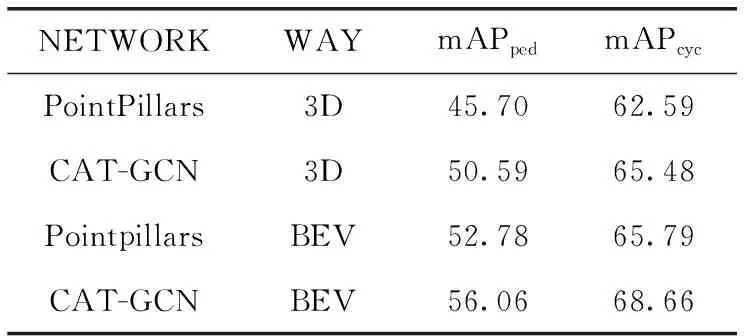
表3 小目标检测mAP对比/%
结合表1、表2、表3可以看出在CAT-GCN目标的检测中取得了良好的结果,并相对于基准模型,在3D模式检测中将mAP由59.2%提高到62.92%,行人的mAP由45.70%提高到50.59%,自行车的mAP由62.59%提高到65.48%。鸟瞰图模式下mAP由66.19%提高到69.07%,行人的mAP由52.78%提高到56.06%,自行车的mAP由65.79%提高到68.66%。验证FE层的有效性。网络与基准网络PointPillars相比将行人级检测性能提升4.25%,将自行车级检测性能提升2.88%。由此看出CAT-GCN能够提升检测精度,尤其是在小目标检测上提升明显。
表3实验结果,加入特征增强层后的基准模型,检测精度得到提升,尤其是小目标检测,因为特征增强层可以提高网络捕捉细节特征的能力。
3.2 模型可视化
在KITTI验证集和测试集的上进行3D目标检测和BEV目标检测。其中数据集分为:简易、中等和困难3个等级。检测目标分别为:车辆、行人和骑行者。在点云数据中,由于激光雷达本身检测的局限性,目标在空间离散分布且近密远疏,导致扫描到的目标点云有所缺失。点云图中含有太多无效信息,需要有效处理点云拓扑和特征提取,因此加入CAT-GCN的网络能够有效处理点云拓扑和有效特征提取。通过级联形成的FE层,并且FE层能够所提取的点云特征如图6所示。
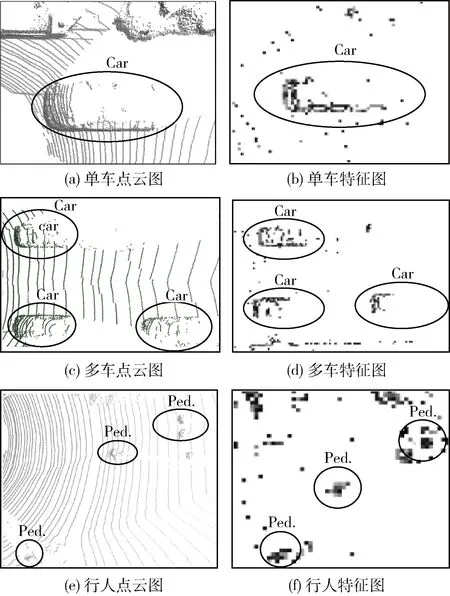
图6 点云特征
从图6中可以看出FE层在卷积后能够减少无用信息,使得网络对于检测目标的敏感性增强,能够提升点云的卷积效率。将测试集中的点云数据放在训练好的模型中进行检验,能够有较高精度的检验结果如图7所示,有RGB映射的点云鸟瞰图以及边框预测结果如图7所示。
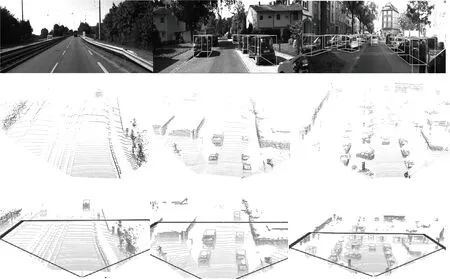
图7 实验结果
从图7中可以看出:检验结果中具有精准且定向的三维边框,对于汽车、行人、自行车的预测结果也比较准确,也没有明显的误检、错检等现象。由于点云数据本身的特性,在模型对行人、自行车进行检验时,检测精度无法与汽车相比。在CAT-GCN嵌入PointPillars后能够有效且准确地检验结果。能够在点云数据中快速获取目标的类别、位置。并通过检验头为目标提供3D包围框,实现对于目标的检测。
4 结束语
提出的通道图卷积(CAT-GCN)通过与基准网络级联来形成特征增强层,该层负责提取浅层中的详细几何信息。该方法利用图卷积和通道注意机制来保证局部激活,这对于克服分割效应具有重要意义。在KITTI数据集上的实验结果表明了该方法在三维目标检测中的优越性。并通过对比各类目标的检测精度,发现CAT-GCN能够有效提高检测精度,将行人级检测性能提升4.25%,将自行车级检测性能提升2.88%。但由于图卷积的一些局限性无法对汽车的检验精度实现大幅度提升,也是后续需要改进的地方。
猜你喜欢
环球时报(2022-03-29)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
知识经济·中国直销(2018年7期)2018-07-27
北京航空航天大学学报(2018年1期)2018-04-20
测绘科学与工程(2016年5期)2016-04-17
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
电子设计工程(2015年3期)2015-02-27
