
基于图卷积和注意力的方面级情感分类
2023-10-12 01:27窦贤锐
计算机工程与设计 2023年9期
窦贤锐,李 敏,赵 晖+
(1.新疆大学 软件学院,新疆 乌鲁木齐 830046;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;3.新疆大学 信号检测与处理重点实验室,新疆 乌鲁木齐 830046;4.新疆大学 多语种信息技术重点实验室,新疆 乌鲁木齐 830046)
0 引 言
图卷积网络(graph convolutional networks,GCN)具有很好的提取与句法相关的词信息能力[1-3]。然而,现有的GCN框架下卷积到同一结点的邻接结点的权重相同,不能有效获得关键节点信息。另一方面,固定卷积层数的方法不能自适应地获取情感词信息。
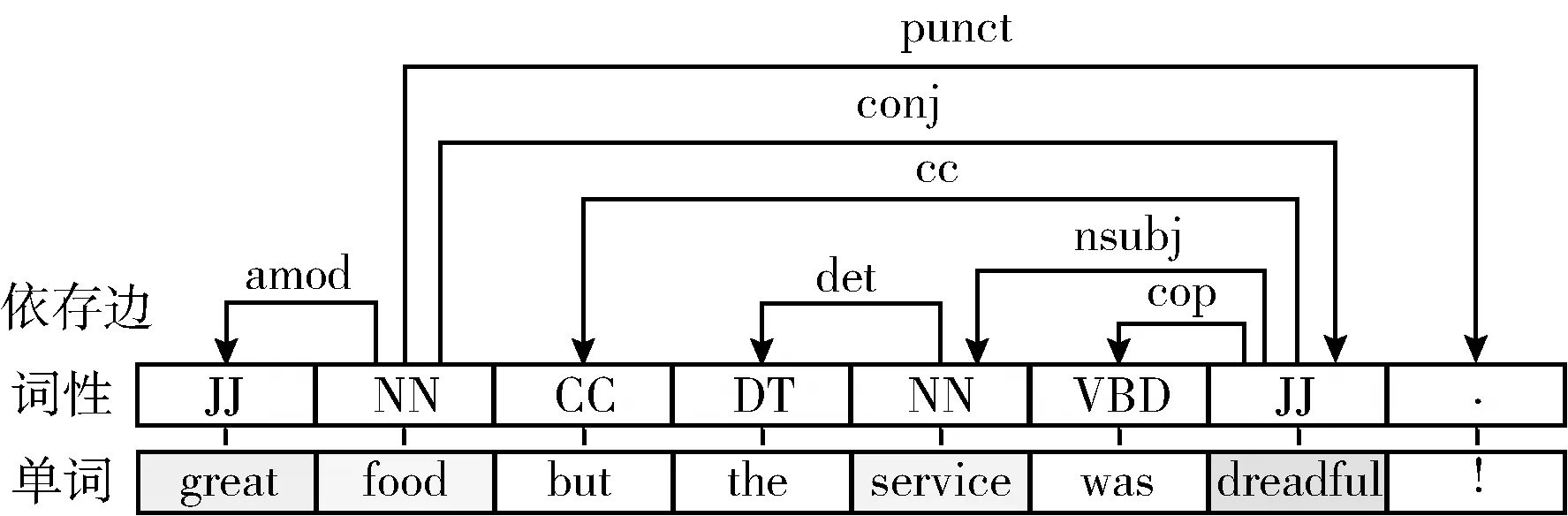
图1 依存句法信息示例
固定卷积层数(一般设定为2)的方法不能自适应地获取情感词信息是指:一是层数值设定小,方面词的感受野有限,进而无法获取长句法距离的词信息;二是层数值设定大,卷积到方面词的噪音多,影响对特定方面情感信息的提取,一些学者[5,6]认为当卷积层数增多后会造成特征信息过平滑,进而影响特征表示。为解决这个问题,一些学者[7-10]将注意力和语义信息融合到GCN中旨在挖掘更多的情感线索;一些学者[11,12]使用依存句法信息构建方面词与情感词的句法相关性,以自适应地捕获特定方面的情感词信息。
本文根据这些理论和方法,在GAT的基础上,加入句法边信息提高对不同结点的区分度。另一方面,本文设计一个迭代注意力机制用于建立方面词和句中所有词的关联关系,以自适应选择全局词信息。
1 方面级情感分类模型
基于图注意力的方面级情感分类模型(aspect-based sentiment classification with graph convolution and attention networks,ASGAT)的框架如图2所示。ASGAT模型由双向LSTM网络(bi-directional long short-term memory,Bi-LSTM)、带边标签的图注意力模块、迭代注意力模块和门机制组成,其中W3和W4是方面词。迭代注意力中的att是注意力计算;add是对应向量相加并求平均;Mask是掩盖对应位置向量后合并向量;Pooling是对多个向量平均池化操作。
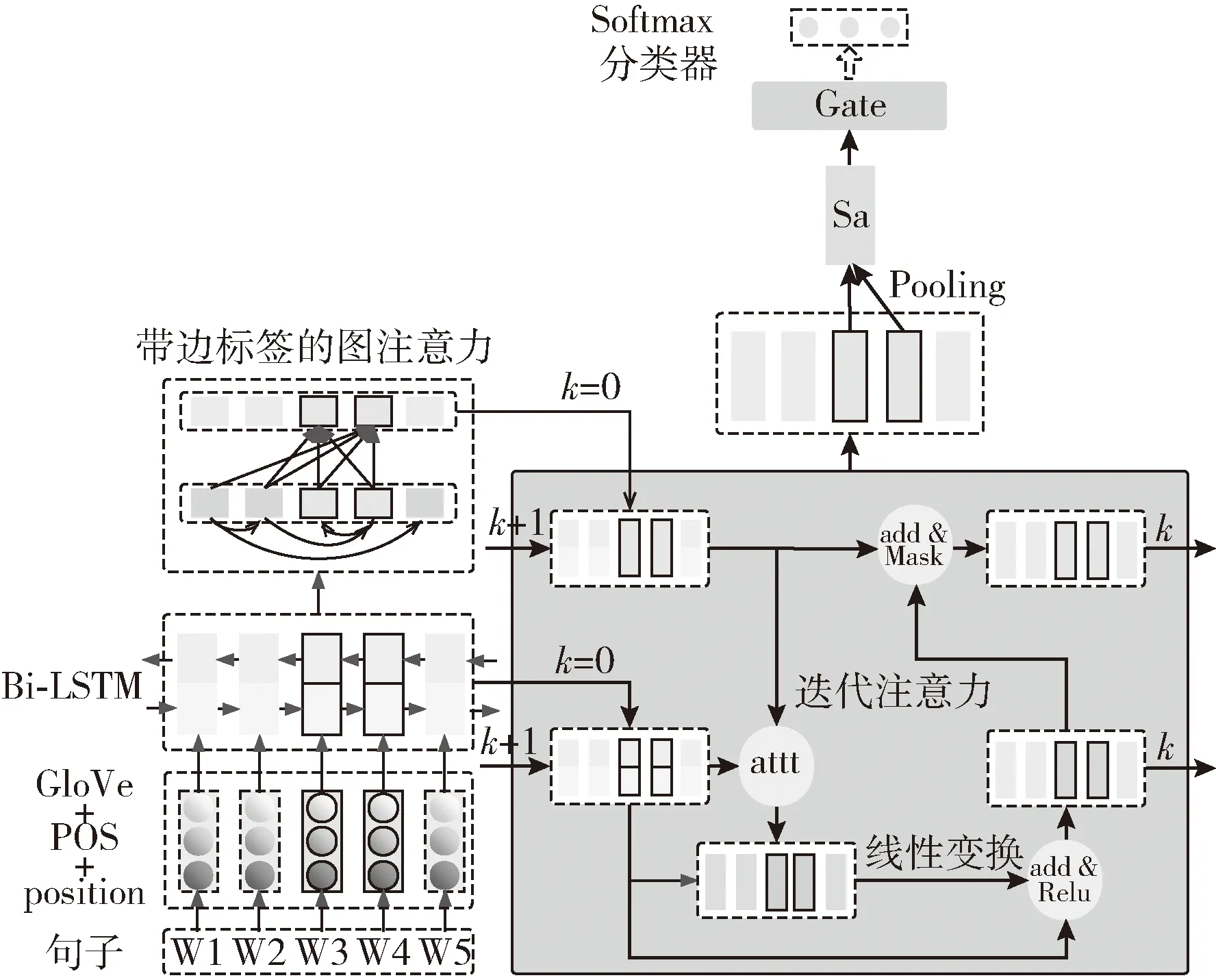
图2 模型ASGAT
其中,对于所有输入(方面词、句子)对,由Stanford[13]句法解析获得句子的带边标签的依存树矩阵以及每个词对应的词性(part of speech,POS)。在把数据输入网络前,将单词、词性、边标签和距离方面词的位置信息(position)用词典统计为对应的数字。对单词进行300维GloVe[14]词嵌入,对词性、位置信息和边标签参数学习分别获得30维词嵌入。然后将拼接的Glove、词性和位置嵌入输入到Bi-LSTM获取上下文信息,接着拼接词向量和边标签嵌入用以计算卷积因子。由上下文信息和卷积因子通过GCN捕获与方面词句法相关的词信息。接着用卷积后的方面词向量和上下文信息迭代获取特定方面词的情感特征向量,然后使用门机制对向量特征进行增强,最后用Softmax分类器获得情感分类。
1.1 Bi-LSTM网络
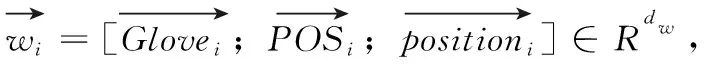
1.2 图注意力网络
1.2.1 图卷积网络
在一些研究者[1-3]使用的卷积中,卷积公式为
(1)
式中:φ是ReLU激活函数,Aij是依存矩阵(存在句法连接边的值为1,不相连为0;且设定为自循环,即Aii=1),ci是结点i度的倒数,ciAij即是卷积因子。由公式可知,聚合到i结点的不同结点j的卷积因子是相同的。但在实际语言中与当前结点句法相连的词对当前结点的重要性是不同的。
1.2.2 带边标签的图注意力
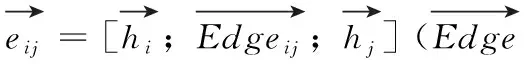
(2)
式中:参数We∈R2dh+de,be∈R1,de的值设置为30。获取表示连接边关系的标量值后使用Softmax函数计算卷积因子,公式如下
(3)
式中:Ei表示与结点i有句法连接边的结点集(包括自循环设定的结点i)。
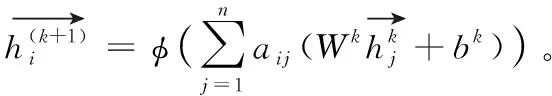
1.3 迭代注意力
GCN两层卷积后聚合到方面词的向量信息包含与方面词直接和间接句法相连的两跳内词信息,通过注意力方法可以自适应选择全局词信息。与Zhang等[2]选择的注意力机制相同,本文使用的是点积注意力。公式如下
(4)
(5)
本文根据注意力和残差思想[15]提出一种迭代注意力的方法将句法信息和全局信息结合起来,从而自适应选择全局词信息和训练神经网络。具体的迭代注意力算法如算法1所示:
算法1:迭代注意力算法
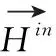
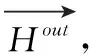
1.4 特定方面的向量表示
方面词向量中含有图卷积捕获的与方面词句法相关的两跳内词信息、通过迭代注意力自适应提取的句子中其它词信息。再使用Mask-pooling技术提取即可得到特定方面词的向量。公式如下
(6)
(7)
其中,m为方面词长度,τ+1是方面词的第一个单词,n是句子中的单词总数。
在获得特定方面词的特征表示后,本文使用门机制[16]对向量增强,公式如下
(8)
(9)
其中,σ是sigmoid激活函数,确保f的值在(0,1)区间。权重矩阵维度是Wf∈R2dh×dh,Wh∈Rdh×dh, 偏置bf∈Rdh,bh∈Rdh。
1.5 模型训练设置
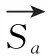
(10)
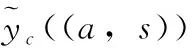
整个世界都在跟他作对,挣扎也是徒劳。还能抓住什么?没有一丝让人留念的东西,一直在考虑的问题,现在都想清楚了。原本要向父亲交待的话,看来已经没有必要。当活着成为痛苦的时候,死未尝不是一种解脱。
2 实验设计与结果分析
2.1 数据集和实验设置
为了验证模型的有效性,实验采用了与Zhang等[2]相同的5个数据集:一个是Twitter数据集,其它4个(Laptop14、Rest14、Rest15和Rest16)是SemEval任务中的笔记本电脑和餐馆两种类型的数据。对数据集数据的统计见表1。
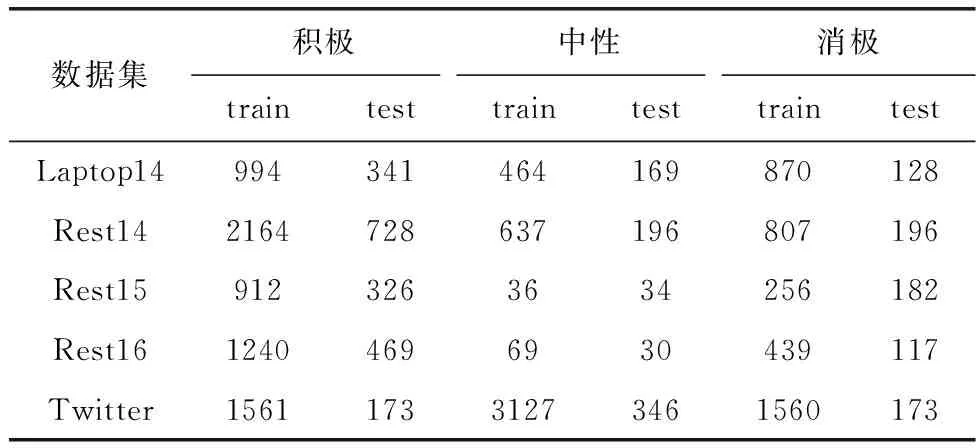
表1 数据集统计数据
为了更好地训练神经网络,本文在每一层随机剔除10%的神经元,在输入层约剔除70%的神经元。本文使用Adam优化器,学习率设为0.01,L2归一化系数设置为5×10-5。此外,模型训练设置为100批且使用提前结束技术,批次大小为32,窗口大小为10,GCN层数和迭代注意力层数均设置为2。
通过随机初始化运行,得到了以准确率(Accuracy,acc)和宏平均F1(Macro-Averaged F1,F1)作为评价指标的实验结果。
2.2 对比模型与实验结果分析
将ASGAT模型与以下研究工作所提出的模型进行对比:
AOA[17]。该模型使用Bi-LSTM获取上下文信息和方面词信息,接着用注意力机制建立方面词和句子词之间的关系交互获得特定方面词的特征向量。
ASGCN-DG[2]。该模型通过Bi-LSTM获取上下文信息,使用图卷积将与方面词句法相关的信息卷积到方面词,再用卷积后的方面词和句中所有词计算注意力,根据词之间的相似度计算所有词的权重,由权重加权求和得到特定方面词的特征表示。该模型将句法信息和上下文信息结合,同时由注意力调整获得全局信息,取得了较好的情感分类结果。
CDT[1]。该模型在Bi-LSTM获取上下文前拼接GloVe向量、词性嵌入和位置嵌入以获得更丰富、更具有语言环境的词向量表示。接着利用依存树可以建立词之间的句法关系而不论在句中的序列距离的特性,使用图卷积捕获方面词句法相关的句法信息,之后平均池化方面词向量得到特定方面词的特征表示。
DGEDT[18]。该模型使用有方向的依存矩阵,建立两个方向的图卷积,同时与transformer自注意力的全局功能交互获取全局信息。
R-GAT[12]。该模型通过重构和修剪依存树得到其它词与方面词的句法距离关系,根据句法关系(与方面词直接句法相连边类型和间接相关的句法距离)训练模型得到句中词对方面词的影响权重,结合GAT方法得到特定方面词的特征表示。
RepWalk[11]。该模型根据依存树的句法关系构建句中词与方面词句法相关的句法路径,由方面词出发随机游走到目标词,继而根据游走概率得出当前结点对方面词的重要性权重。该模型将句法边信息融合到模型中以便得到更准确的连接比重。
实验结果最高加粗,次高下划线标识,模型对比实验结果见表2。
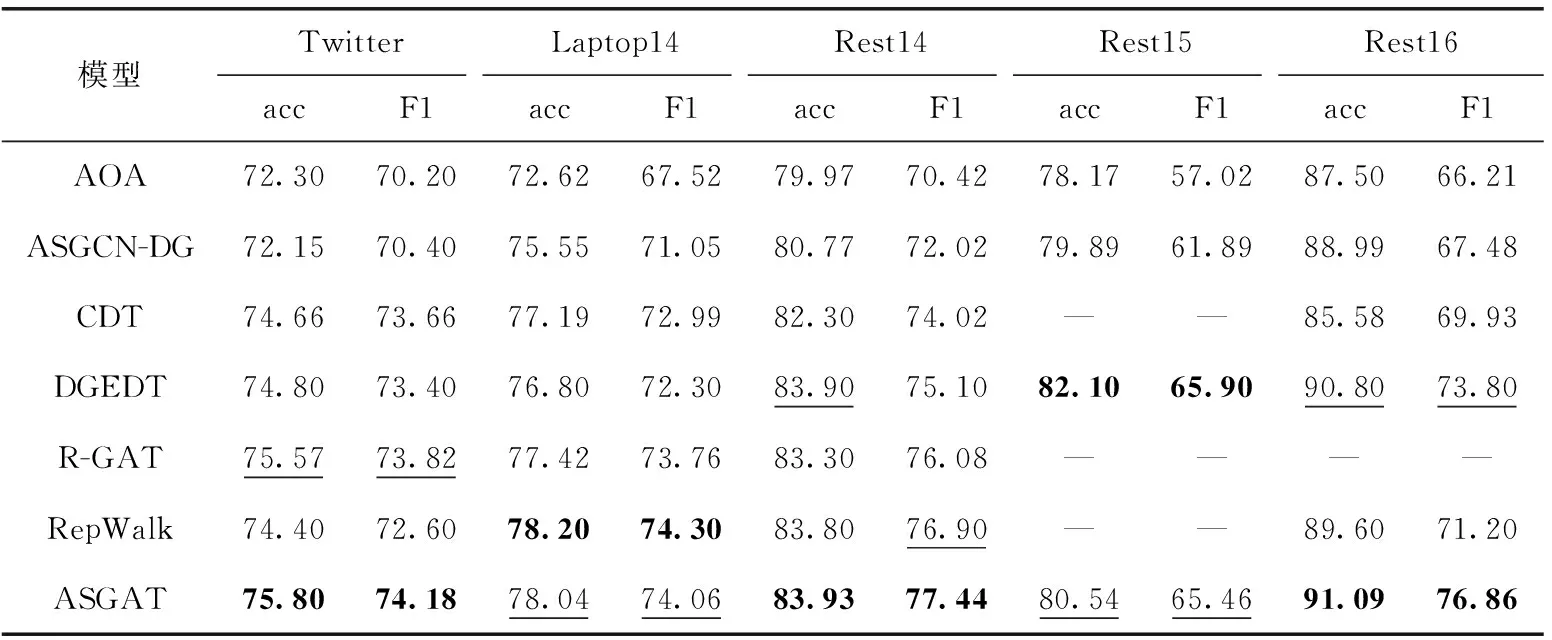
表2 模型对比实验结果
从表2的实验结果可以得出下列结论:
与AOA相比,ASGCN-DG在除了Twitter数据集上的其它4个数据集上都有更好的性能。具体地说,性能改进最小的是在数据集Rest14上0.8%的准确度和F1值1.6%的提高,最高是在数据集Laptop14近3%的准确性和F1值3%以上的提高,这表明句法信息有效地提高了情感方面的特征表示能力。CDT、DGEDT、RepWalk和R-GAT模型都在模型中添加了句法信息,表明句法信息捕获特定方面词情感信息的能力得到了学术界的认同并被引入使用。与CDT固定卷积网络层数只能获取方面词两跳句法内的词信息不同,RepWalkp和R-GAT建立方面词与其它多跳句法词之间的连接,实验性能进一步提高,说明自适应获取不同句法距离词信息的必要性。本文的模型是基于网络ASGCN-DG和CDT,通过与这些模型对比,本文的图注意力和迭代注意力机制获得了更好的实验性能。从表2的结果可以看出,本文的实验结果与最新的DGEDT、R-GAT和RepWalk在Twitter、Rest14和Rest16数据集上相比有一定的性能提升,这进一步验证了模型ASGAT的有效性。
2.3 消融实验与实验结果分析
与其它模型相比,本文模型有3个部分主要差异,分别是卷积因子计算、迭代注意力和用于增强特征的门机制。消融实验即围绕这3点,具体实验介绍如下:
(1)/GAT。该模型是删除边信息用GAT[4]方法计算卷积因子。
(2)w/oatt。该模型是删去迭代注意力模块,在图注意力网络后直接用Mask-pooling技术提取特定方面词的向量送入门机制中。
(3)w/ogate。该模型是删去门机制模块验证门机制对特征增强的作用。
实验结果最高加粗,次高下划线标识,消融实验结果见表3。
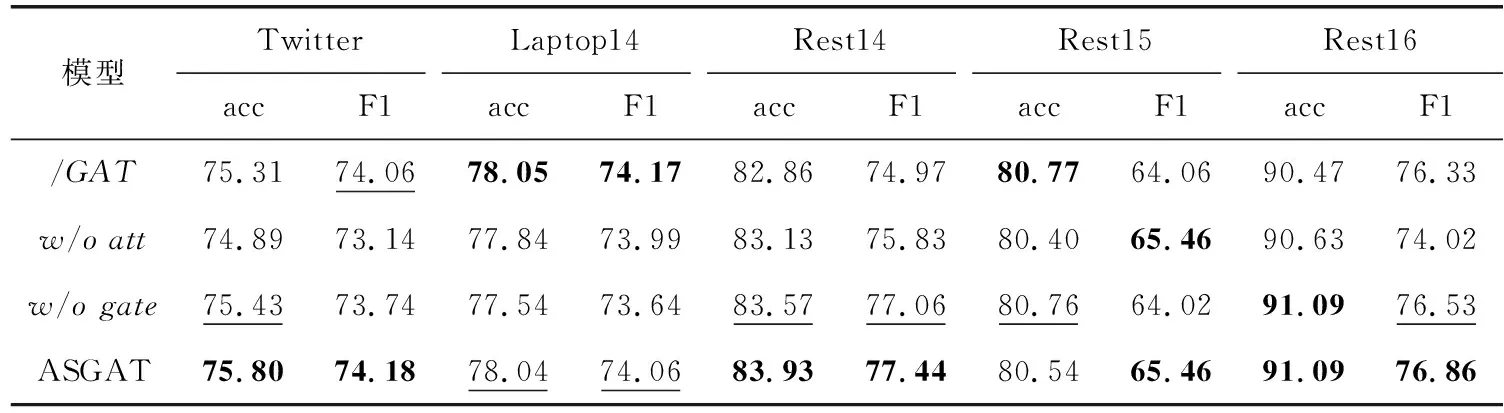
表3 消融实验结果
从表3的实验结果可以得出下列结论:
图注意力模块分析:在Laptop14数据集中,/GAT中性数据集分类正确的准确率较高,由数据集的分布可以发现,Laptop14数据集测试集中中性句子占比较高,二者实验结果相当是由数据不平衡造成的。本文统计数据集Laptop14、Rest14和Rest15中连接情感词的边信息,对比发现Rest15数据集对边信息不敏感,这是ASGAT在Rest15上准确率不高于/GAT的原因。 对比/GAT,ASGAT在其它3个数据集上实验效果均更好,可以得出加入边标签的信息比只用词向量计算卷积因子的方法效果好的结论。
迭代注意力模块分析:ASGAT在所有数据集上的效果不低于模型w/oatt,这有效说明GCN结合迭代注意力对特定方面的情感词信息更加敏感。
门机制模块分析:ASGAT在数据集laptop14、Rest14和Twitter上的效果均高于模型w/ogate,在数据集Rest15和Rest16上二者实验性能相当,说明门机制有效的提高了实验性能,验证了其有效性。分析分类句子发现,门机制在Rest15和Rest16中数据集中提高了中性句子正确分类的准确率,而在数据集Rest15和Rest16中中性句子占比较小,本文推测这是门机制在这两个数据集中效果不明显的原因。
2.4 词嵌入分析
为了进一步分析词嵌入方法对模型性能的影响,本文对不同的词嵌入向量做补充实验,实验结果见表4。
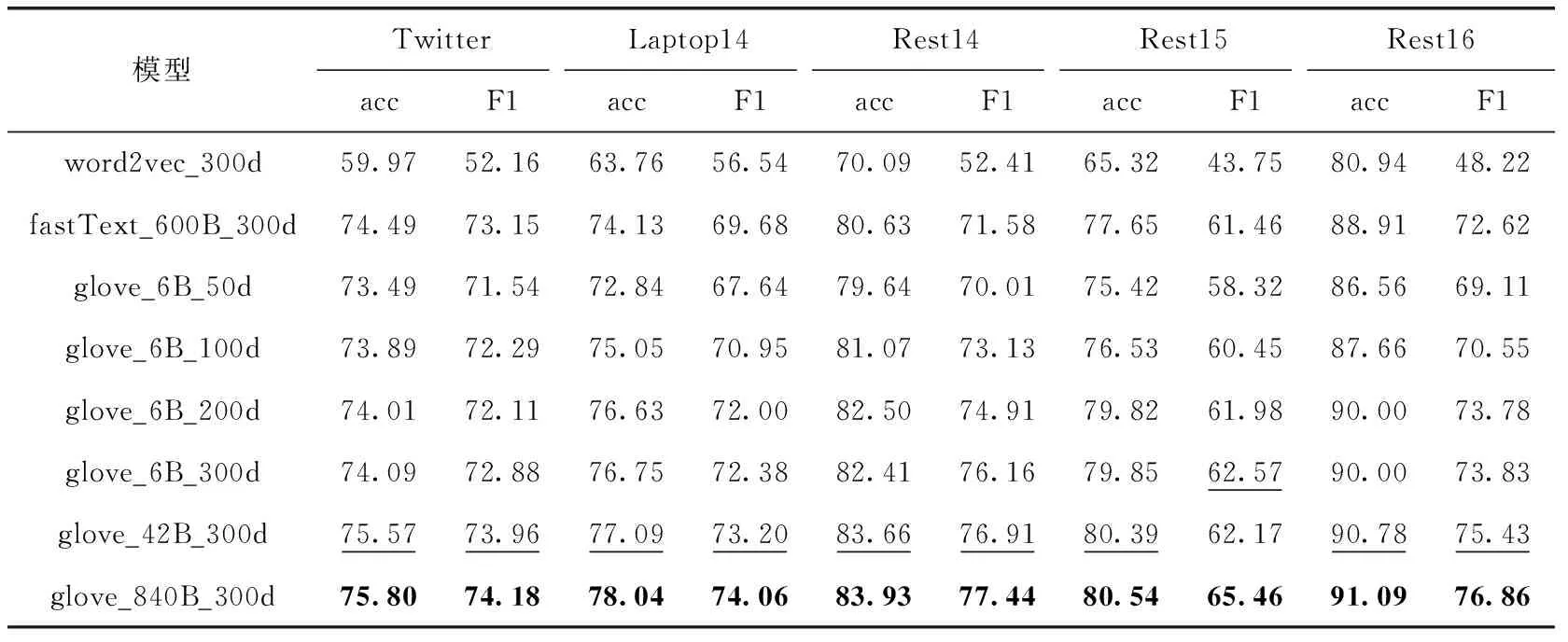
表4 词嵌入模型实验结果
从表4的实验结果可以得出下列结论:
不同词向量方法对比:在300维词向量对比中,除了Twitter数据集外的其它4个数据集中,使用glove比word2vec和fastText效果均要好。Twitter数据集的语料谈论的范围比较大,涉及的词较多,这是训练词向量的词汇相对少的glove_6B_300d效果差于fastText_300d的原因。
不同维度词向量对比:在glove_6B的4种不同维度词向量中,维度越高,实验结果越好,说明维度高能更好表示词信息。在200维和300维对比中,Rest14数据集上200维实验的准确率更高,在Twitter、Laptop14和Rest16数据集上二者实验结果相当,这说明一定的语料中维度对信息的保存并不是越高越好。
不同训练词汇量对比:对比6 B、42 B和840 B的词汇量可以发现,随着词汇量的增大,实验效果越好。可以得出参与训练的词汇越多,词向量对词义的表示越完整的结论。
综上对比,glove_840B_300d的词向量获得最佳实验结果,说明其对词义的表示最完整,这是本文选择该词向量用于网络训练的主要原因。
3 样例分析
为了进一步说明连接边对于图注意力的重要性,卷积因子示例如图3所示,当前聚合结点是词“food”,第一行是GAT的卷积因子,第二行是带边标签的卷积因子。可以发现,GAT对词“great”、“dreadful”没有较大的区分度。在带边标签的图注意力中,修饰“food”的情感词汇“great”有很大权重。

图3 卷积因子示例
为了进一步迭代注意力的重要性,注意力示例如图4所示。第一行是GAT的卷积因子自点积模拟两层后聚合到方面词的各个词的比重,第二行是迭代1次注意力的注意力值,第三行是迭代2次的注意力值。当前的方面词是“internal cd drive”,句中的主要情感词是“complaint”和“no”。可以看到,仅用GAT不一定能给关键情感词分配高权重,尤其是两跳外的词“complaint”。使用1次迭代注意力即能结合句法信息和全局信息,使用2次后“complaint”和“no”得到更大的注意力值。三者信息结合一起作为方面词的向量从而得到更准确的特定方面词的特征表示。
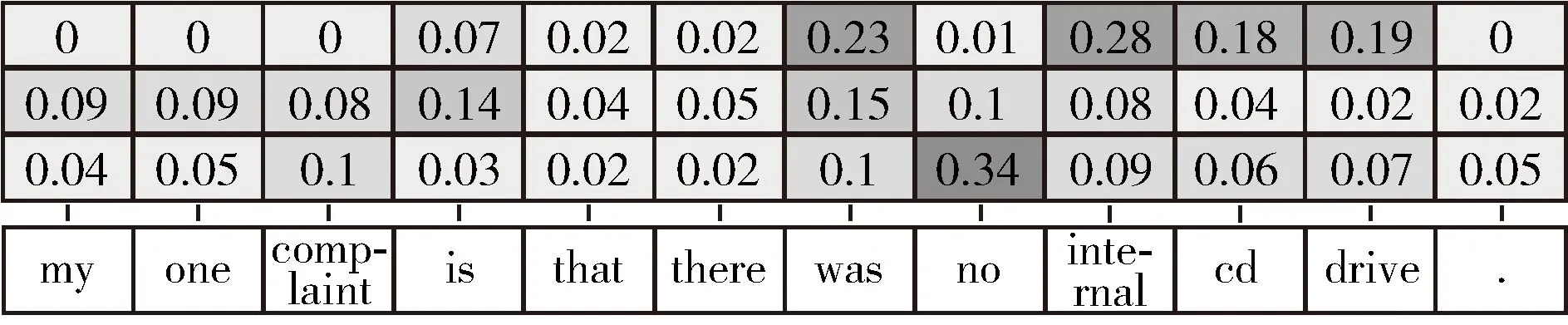
图4 注意力示例
为了进一步说明注意力层数对实验结果的影响,注意力层数实验结果统计见表5。
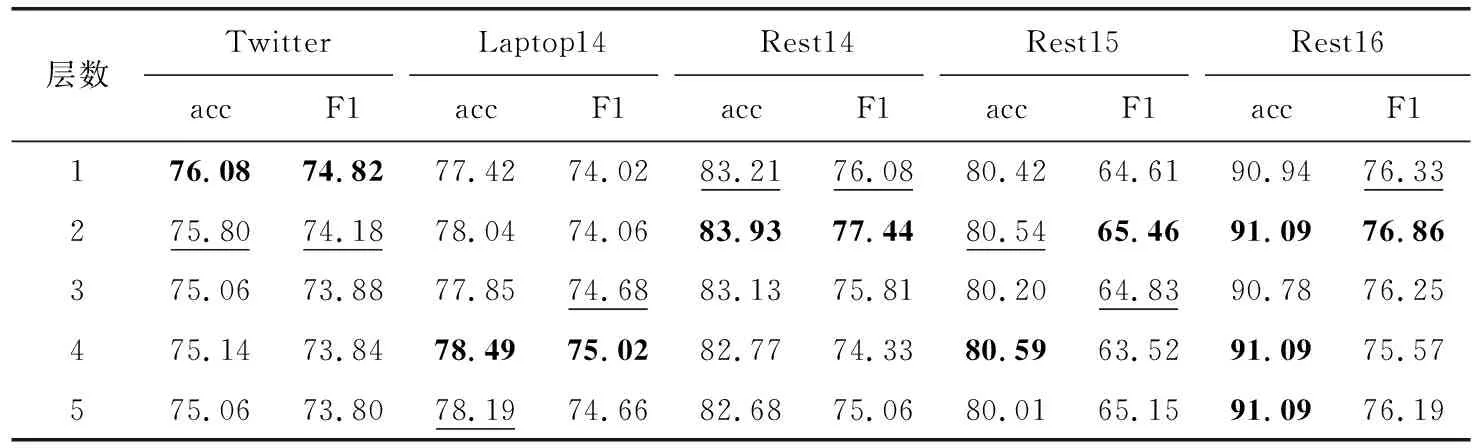
表5 注意力层数实验结果
由实验结果可知,层数为2时模型综合表现最佳。本文迭代注意力的设计核心是迭代方面词向量表示。层数为1时,方面词向量由图卷积获得的句法信息、句法与所有词通过注意力获得的信息构成,其它词则通过自注意力进行特征更新。在层数2时,再做注意力即可获得自注意力后的全局信息。结合句法信息、所有源词信息以及自注意力全局信息是层数为2时综合表现最佳的原因所在。同时可以看到,迭代注意力模型固定后,单纯的增加层数只能在部分数据集上提高实验性能。通过分析,Twitter数据集中的句子只有一个方面词,一层注意力即可获得特定方面词的全局信息,增加注意力层数反而会引入噪音。在Laptop14数据集中,层数在4和5时提高的关键是多分对中性的句子,由数据集的分布可以发现,Laptop14数据集测试集中中性句子占比较高,所以模型的注意力层数与数据集的情感样本不平衡有关系。
4 结束语
对于方面级情感分类而言,句法信息有助于捕获情感特征,本文提出基于图卷积和注意力的模型ASGAT。在5个公开数据集的实验结果显示,模型ASGAT在GAT的基础上考虑边信息提高了对关键词的识别度,同时表明GCN结合迭代注意力对特定方面的情感词信息更加敏感。本文的研究比较依赖句法解析器获得的依存句法信息,而依存句法信息也含有一定的噪音和错误,在今后的研究中可以试着构造融合多种句法解析结果的方法以减少这种噪音。
猜你喜欢
东北水利水电(2022年6期)2022-06-28
小雪花·成长指南(2022年1期)2022-04-09
康复(2022年31期)2022-03-23
中华诗词(2021年3期)2021-12-31
大连民族大学学报(2021年2期)2021-07-16
电子制作(2019年11期)2019-07-04
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
