
基于多尺度特征融合和残差混合注意力的点云配准算法
2023-10-12 01:27梁正友李轩昂
计算机工程与设计 2023年9期
梁正友,姚 强,孙 宇,李轩昂
(1.广西大学 计算机与电子信息学院,广西 南宁 530004;2.广西大学 广西多媒体通信与网络技术重点实验室,广西 南宁 530004)
0 引 言
点云配准是指求解对齐2个未知对应关系的点云之间的刚性变换,在计算机视觉和机器人技术等许多领域都有应用,如物体姿态估计[1]、三维物体表面重建[2,3]以及基于点云的图形绘制[4]等。Besl等[5]提出ICP算法,它通过在以下两个步骤进行迭代求解最优解:①为当前点云中的每一个点在另一个点云中找到其对应最近的点形成对应点对;②计算找到的对应点对之间最小二乘刚性变换矩阵。在ICP的基础上衍生出了许多变种方法,如Go-ICP[6]、tr-ICP等,它们采用优化算法增强算法鲁棒性,ICP类算法普遍存在对初始值敏感和计算复杂度高的问题。近年来,基于深度学习的点云配准方法被提出。Aoki等[7]提出PointNetLK模型,利用PointNet[8,9]提取点云特征,再使用改进后的Lucas&Kanade算法进行点云配准;Kurobe等[10]提出的CorseNet拼接点云局部特征和全局特征,再用MLP预测刚性变换,最后通过SVD求解刚性变换。Wang等[11]使用动态图卷积神经网络(dynamic graph CNN,DGCNN)[12]提取点云的特征,通过基于自注意力机制的预测模块来预测点云之间的软匹配,最后使用可微的奇异值分解计算刚性变换矩阵,但它仅利用了单一尺度的局部特征,配准精度仍有待提升。
本文提出一种基于多尺度特征融合和残差空间通道混合注意力机制的点云配准算法。相较于ICP、Go-ICP、PointNetLK和DCP等算法,本文提出的算法配准精度更高,鲁棒性更强,迁移能力更好。本文主要创新点有:①将多尺度特征融合的思想应用到点云特征提取,提取包含点云局部细节信息和点云整体结构的点云特征;②在特征提取模块中加入基于残差结构的混合注意力机制,分别在通道域和空间域对有效特征增强,进一步增加了模型对于有效特征的学习能力;③通过和其它方法在ModelNet40[13]公开数据集上进行对比分析,验证了本文算法在点云配准上的先进性。
1 本文工作
1.1 问题描述
假设源点云和目标点云分别表示为X={x1,x2,…,xi,…,xn}∈3和Y={y1,y2,…,yi,…,ym}∈3, 点云Y是由点云X经过未知的刚性变换{R,t}而来,其中R∈SO(3),t∈3, 点云配准问题就是要求解{R,t}使得Y=RX+t。 为方便表示,我们这里仅考虑m=n这种最简单的情况,因为MS-DGCNN、Transformer和Softmax等模块将输入作为无序的集合看待,对源点云X和目标点云Y中点的数量是否相等没有硬性要求,所以源点云X和目标点云Y中点的数量不相等的情况(即m≠n)非常容易推广。假设X,Y中的点xi,yi一一对应,则经过{R,t}变换后的点云和目标点云之间的误差可以表示如下
(1)

(2)
协方差矩阵H可以表示如下
(3)
定义协方差矩阵H=U∑VT, 对H进行奇异值分解可以得到
(4)
(5)
从X中每个点xi到Y中的对应点的映射m()由式(6)给出
(6)
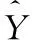
1.2 算法整体架构
本文提出的基于多尺度特征融合和残差混合注意力的点云配准算法整体结构如图1所示。主要由4个模块构成,它们分别是用于提取特征的多尺度动态图卷积(multi scale-dynamic graph CNN,MS-DGCNN)模块、用于交换源点云和目标点云的特征信息的Transformer模块、用于生成软匹配的软指针模块以及计算刚性变换矩阵的可微的奇异值分解模块。

图1 整体结构
1.3 MS-DGCNN特征提取模块
在点云特征中,小尺度特征包含了更多的点云局部空间结构的细节特征,大尺度特征则更注重于点云整体结构信息。不仅尺度不同的特征有不同的性质,卷积层次不同的特征也有类似的性质。浅层次卷积网络的感受野较小,对于细节的表征能力强;深层次卷积网络的感受野较大,对于语义信息的表征能力强。多尺度特征融合思想的精髓在于同时使用不同尺度的特征,充分发挥他们各自的优点,从而取得1+1>2的效果。在点云配准中,想要配准具有对称简单结构的点云,提取到的点云特征必须包含整体的结构信息;想要配准具有精细小巧结构的点云,提取到的点云特征必须包含局部细节信息。这就要求提取到的点云特征不仅能表征点云整体的结构信息,还能够包括丰富的细节信息。
为了提取到不同层次的点云特征,进一步丰富点云特征的内涵,来满足点云配准对于点云特征的要求。受到多尺度特征在2D图像处理[14,15]上取得显著成效的启发,针对点云特征的内在要求,本文创新性地将多尺度特征的思想应用在点云特征提取中。文本在DGCNN的基础上进行改进,提出了共享权重的多尺度动态图卷积(multi scale-DGCNN,MS-DGCNN)特征提取模块,MS-DGCNN结构如图2所示。分别选取k=10,k=20和k=30的k邻近图得到初始特征,再分别进行不同深度的卷积操作获得不同尺度的特征,最后将各尺度的卷积结果融合为一个综合特征。

图2 MS-DGCNN模块结构
1.4 残差混合注意力模块
综合特征中会包含部分重复冗余特征,它们对于后续配准会产生负面影响。为了尽可能地减小冗余信息带来的负面影响;增强有用特征在配准过程中的积极作用,提高点云配准精度和效率。
受CBAM[16]和DANet[17]启发,文本在MS-DGCNN模块中添加了具有残差结构的混合注意力模块(residual mixed attention,RMA),RMA模块结构如图3所示。
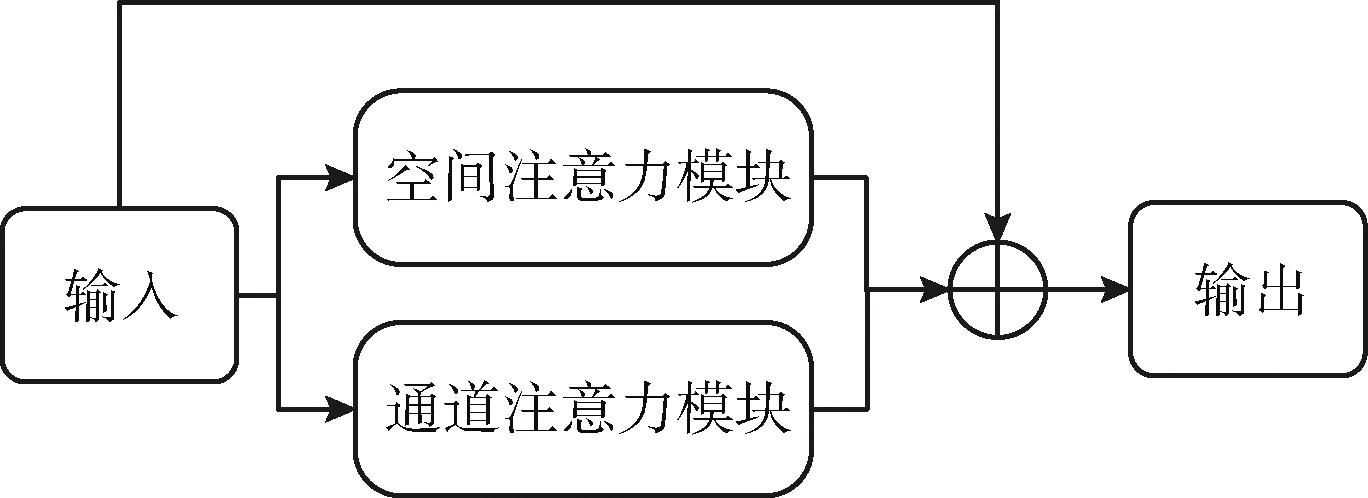
图3 RMA模块结构
层数过多的深度神经网络通常会出现模型学习能力不升反降的问题,这是由于梯度在反向传播过程中经过累计相乘之后变为了0,出现梯度弥散,导致模型训练不动。残差结构[18]通过巧妙地在输入和输出之间加入跳连接的方式,使模型转而学习输出和输入之间的残差映射,完美地解决了这个问题,从而提升了模型对样本的拟合能力。
RMA模块中包含了通道注意力[19]模块和空间注意力模块。其中,通道注意力模块结构如图4所示。

图4 通道注意力模块结构
通道注意力模块流程:对输入信息分别进行最大池化、平均池化操作,接着将池化后的特征经过一个共享权重的多层感知机,然后将卷积操作的结果进行元素对位相加,最后经过sigmoid激活函数得到最终的输出信息。通道注意力模块能够从通道域的维度根据目标任务的需要增强或抑制不同的通道的权重大小。空间注意力模块结构如图5所示。
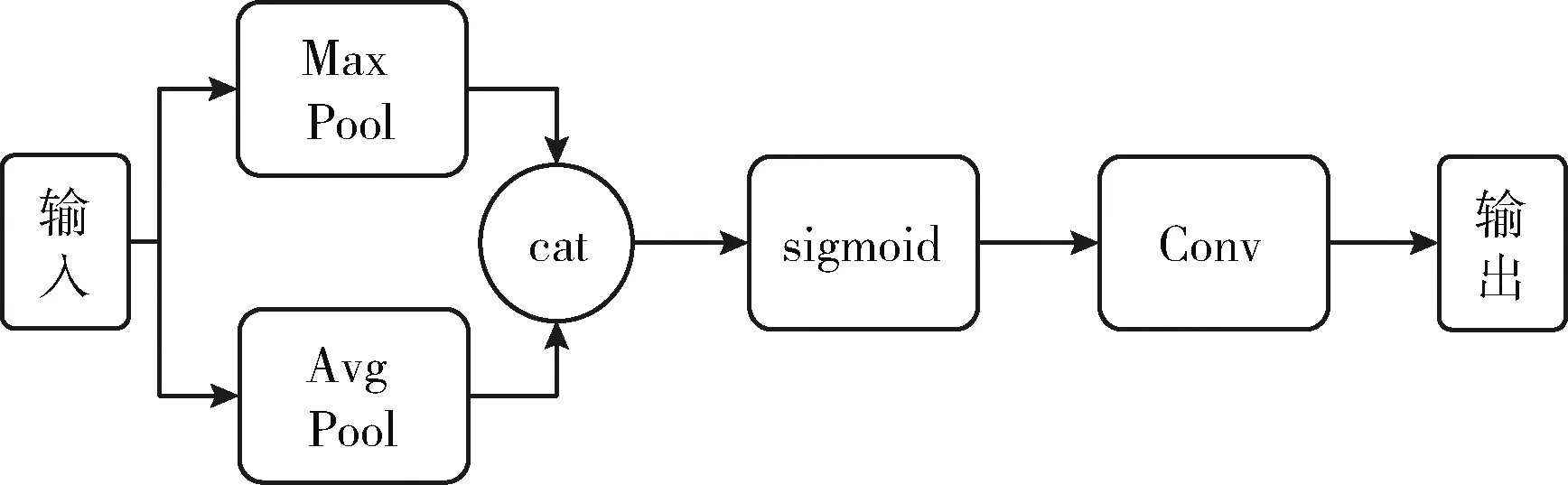
图5 空间注意力模块结构
空间注意力模块流程:对输入信息分别进行最大池化、平均池化操作,然后将池化的结果按通道维度拼在一起,再经过sigmoid激活函数,最后通过一个卷积层得到最终的输出信息。
源点云X和目标点云Y分别经过共享权重的MS-DGCNN特征提取模块后,得到点云原始特征FX={fx1,fx2,…,fxi,…,fxn} 和FY={fy1,fy2,…,fyj,…,fym}。
1.5 Transformer模块

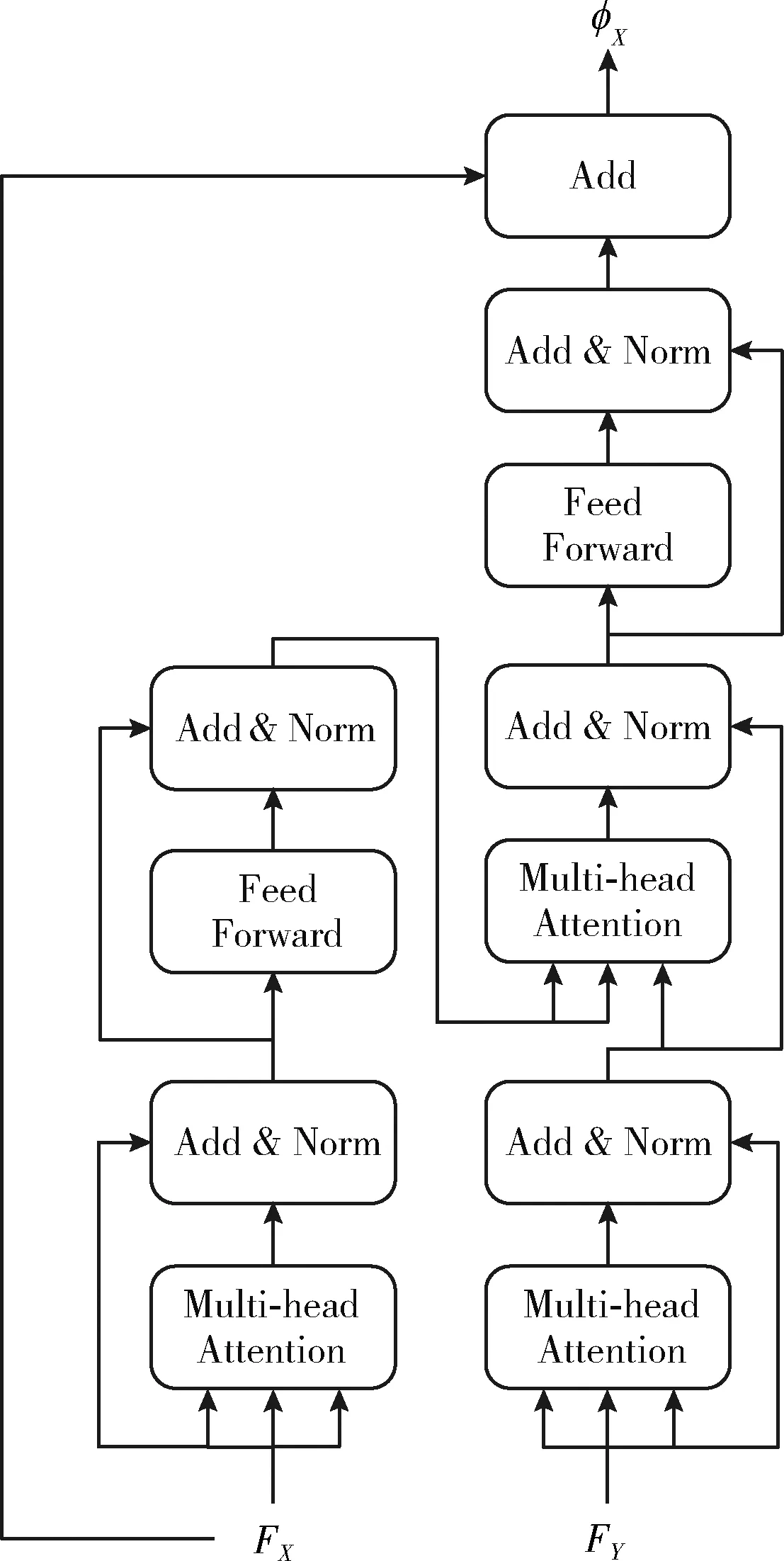
图6 类Transformer模块结构
φX=FX+φ(FX,FY)
(7)
φY=FY+φ(FY,FX)
(8)
1.6 软指针和SVD
软指针是使用基于概率方法生成待匹配点云到目标点云的软匹配:源点云X中的点xi通过
(9)
得到点与点的匹配关系。其中φY∈N×P表示目标点云Y新特征,φxi∈1×P表示待配准点云X中点xi的新特征,二者做点积得到点xi与目标点云Y中每个点的相似度,再利用softmax()将相似度转变为概率,m(xi,Y) 是点xi到目标点云Y中每个点的软指针。使用软指针为X中的每个点xi生成目标点云Y中的匹配平均点的坐标

(10)
其中,YT∈N×3表示目标点云Y中N个点的坐标。这样就得到预测出的点云最后对源点云X和预测出的点云使用SVD(式(4))求解得到R,t。
1.7 损失函数
本文损失函数定义如下
(11)
其中,Rgt和tgt分别表示源点云到目标点云之间的真实旋转矩阵和真实平移向量,I3是三阶单位矩阵。当R无限接近于Rgt,t无限接近于tgt时,R-1Rgt会无限接近一个三阶单位矩阵,二者之差会无限接近于0;t和tgt之差也会无限接近于0。
2 实 验
2.1 数据集及评价指标
2.1.1 数据集
本文在ModelNet40数据集上开展实验。ModelNet40数据集涵盖了40类对象,总共12 311个CAD模型。本文采取和PointNetLK和DCP中一样的数据预处理方式:先对数据集中的每个CAD模型表面均匀采样1024个点并只保留每个点的三维坐标信息 (x,y,z), 再将坐标缩放到单位球体中。
2.1.2 实验环境和参数设置
本文所有实验在一台配备Intel Xeon(R)E5-1620 3.6 GHz处理器,16 GB内存和1块Nvidia TITAN Xp显卡(显存12 GB)的工作站上进行。软件环境为Ubuntu 18.04,python 3.6.10,pytorch 1.4.0,Cuda 10.1。训练轮数为250轮,选用Adam优化器,动量大小为0.9,初始学习率为0.001,分别在第100、180、210轮将学习率下降10倍,batch大小设置为4,训练时间共计100 h。
2.1.3 评价指标
本文选取均方误差(mean squared error,MSE)、均方根误差(root mean squared error,RMSE)和平均绝对误差(mean absolute error,MAE)3种指标对所有算法进行评价、分析和比较。通过计算旋转矩阵的预测值R和真实旋转矩阵Rgt之间的MSE(R)、RMSE(R)和MAE(R)来反映点云配准算法的旋转精度好坏;计算平移向量的预测值t和真实平移向量tgt之间的MSE(t)、RMSE(t)和MAE(t)来反映点云配准算法的平移精度好坏。如果它们的值越小,则表明相应的误差越小,配准结果的精度越高;反之,它们的值越大,则表明相应的误差越大,配准结果的精度越低。
2.2 实验结果与分析
为测试本文所提算法的有效性,噪声鲁棒性和迁移能力,本文分别在以ModelNet40为基础的3个人工子数据集上进行了对比实验。分别同传统的点云配准算法ICP、Go-ICP以及基于深度学习的点云配准算法PointNetLK和DCP进行了对比,其中ICP算法的实现采用Open3D库的默认参数,Go-ICP、PointNetLK和DCP等点云配准算法的实现分别采用相应作者公开的源代码。
2.2.1 在Clean数据集上训练和测试
为测试本文算法的有效性,本小节在Clean数据集上同其它点云配准算法进行了对比实验。Clean数据集随机将ModelNet40中所有点云随机分为训练集和测试集,选取其中9843个模型作为训练集,其余2468个模型作为测试集。训练期间,对源点云X进行随机的刚性变换得到目标点云Y,具体操作是:分别围绕3个坐标轴随机在[0,45°]范围内旋转,同时沿着每个坐标轴随机在[-0.5,0.5]范围内平移。在Clean数据集上训练和测试的实验结果见表1,结果表明本文算法的配准精度明显高于ICP、Go-ICP、PointNetLK和DCP等点云配准算法。本文算法的配准效果如图7所示,其中黑色的是源点云,灰色的是目标点云。
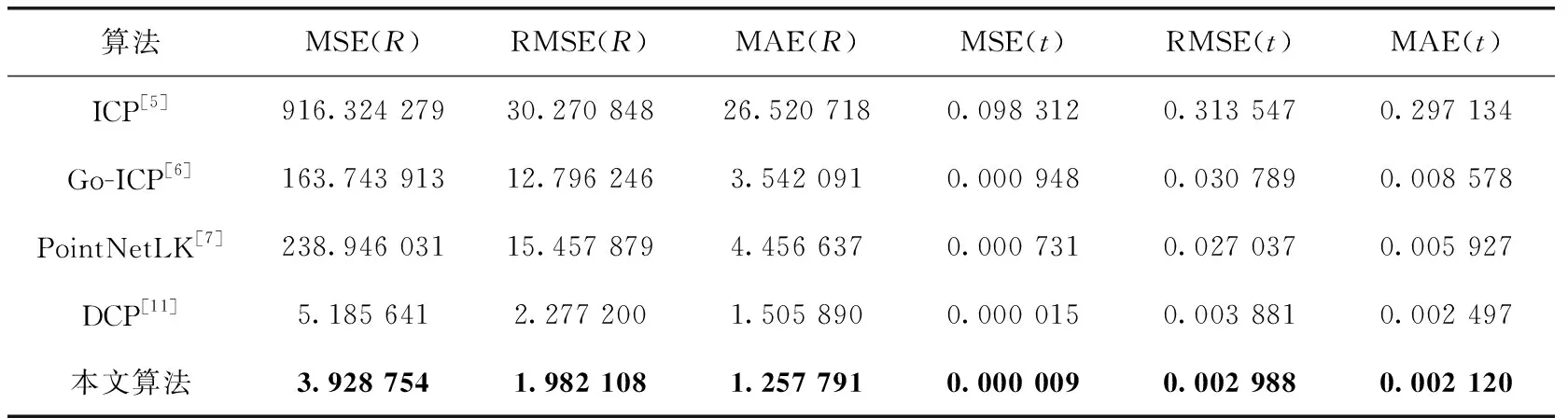
表1 在Clean数据集上测试的结果

图7 本文算法配准效果
2.2.2 在Noise数据集上测试
为了测试和比较各算法对于噪声的鲁棒性,在本小节中采用Noise数据集进行实验,该数据集是以Clean数据集为基础,并在其中加入了服从均值为0.01,方差为0.05的高斯噪声。本小节实验采用2.2.1小节中训练的模型进行测试,它是在Clean数据集上训练出来的。实验结果见表2,结果表明:ICP算法通常会收敛到一个较远处的局部最优解,而Go-ICP、PointNetLK和DCP等点云配准算法对高斯噪声仍具有一定的鲁棒性,本文算法则对高斯噪声有较强的鲁棒性。

表2 在Noise数据集上测试的结果
2.2.3 在Unseen数据集上训练和测试
为测试和比较各算法的迁移性,本小节实验在Unseen数据集上进行,Unseen数据集把ModelNet40按照物体类别平均划分为了两部分。训练阶段使用ModelNet40的前20个类别的点云数据,测试阶段则使用后20个类别的点云数据。需要说明的是:ICP和Go-ICP算法直接在后20个类别的数据上进行测试。实验结果见表3,数据表明:本文算法相较于ICP、Go-ICP、PointNetLK和DCP等点云配准算法在未参与过训练的点云数据上进行测试仍具有相对较高的配准精度,说明本文算法具有更好的迁移能力。

表3 在Unseen子集上训练和测试的结果
2.2.4 PointNet、DGCNN和MS-DGCNN特征提取模块比较
本小节实验将配准网络中的点云特征提取模块分别替换成PointNet、DGCNN和MS-DGCNN这3个特征提取模块,其它设置都保持一样。PointNet特征提取模块仅提取了点云的全局特征,却忽略了非常关键的点云局部特征;DGCNN特征提取模块利用k邻近图和边卷积提取点云局部特征再聚合为全局特征,但是提取到的特征结构单一;MS-DGCNN特征提取模块在DGCNN的基础上融合了多种尺度的特征再利用混合注意力增强有效特征,抑制冗余特征,从而可以有效地学到更加丰富语义的特征,进一步增强特征的表征能力。下面对比了分别使用 PointNet、DGCNN和MS-DGCNN作为特征提取模块的配准结果。实验结果见表4,结果表明使用本文提出的MS-DGCNN模块作为特征提取模块的算法配准精度更高。

表4 PointNet、DGCNN、MS-DGCNN特征提取模块比较
3 结束语
本文提出了一种基于多尺度特征融合和残差混合注意力机制的点云配准算法。通过提取点云中不同尺度特征并融合为综合特征,再使用具有残差结构的混合注意力机制模块增强有效特征抑制冗余特征,然后通过Transformer和软指针预测出配准点云,最后利用SVD求出刚性变换。实验结果表明,本文所提算法具有更高的配准精度,更强的鲁棒性以及更好的迁移性。本文后续重点工作将考虑引入交叉注意力机制,以在残缺不完整或低重叠度的点云配准任务中也能取得良好的配准结果。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2018年19期)2018-11-14
外语学刊(2017年3期)2017-12-07
数学物理学报(2017年5期)2017-11-23
自动化学报(2017年11期)2017-04-04
陕西理工大学学报(社会科学版)(2017年1期)2017-03-02
噪声与振动控制(2015年4期)2015-01-01
新课程学习·中(2013年3期)2013-06-14
轴承(2010年2期)2010-07-28
