
类脑学习型自动驾驶决控系统的关键技术 *
2023-10-12 02:15李升波占国建蒋宇轩兰志前张宇航邹文俊李克强
汽车工程 2023年9期
李升波,占国建,蒋宇轩,兰志前,张宇航,邹文俊,陈 晨,成 波,李克强
(清华大学车辆与运载学院,汽车安全与节能国家重点实验室,北京 100084)
前言
智能化是汽车新四化变革的重要方向之一,自动驾驶技术因为具有提升交通安全、增强道路通畅、减少燃油消耗的巨大潜力,受到学界和业界的广泛关注[1]。麦肯锡报告显示[2]:自动驾驶的全面普及可将交通事故发生率降低至原来的十分之一。据兰德公司预测[3]:自动驾驶汽车可提升30%的交通效率,减少67%的碳排放量,潜在的经济与社会效益显著。因此,自动驾驶系统的应用与普及有望全面改变人类的出行方式与社会结构[4]。
从概念上说,自动驾驶汽车是指搭载先进车载传感器、控制器、执行器等装置,具备复杂环境感知、自主决策、运动控制等功能,可实现“安全、高效、舒适、节能”行驶,最终替代人类驾驶员并实现自主驾驶的新一代汽车[5]。我国2021 年制定了《汽车驾驶自动化分级》标准(GB/T 40429—2021),该标准根据自动化程度将智能汽车分为6 级:应急辅助(0 级)、部分驾驶辅助(1 级)、组合驾驶辅助(2 级)、有条件自动驾驶(3 级)、高度自动驾驶(4 级)和完全自动驾驶(5 级)。第1 级的LKS(lane keeping system)、ACC(adaptive cruise control)等系统属于部分驾驶员辅助级别,已实现大规模应用。目前诸多汽车企业已推进至第2 级系统的量产阶段,例如特斯拉AutoPilot、通用Super Cruise、蔚来NIO Pilot 等。这类组合驾驶辅助系统具备稀疏交通场景的车道保持、跟车巡航、主动换道等功能。为进一步将功能扩展至密集交通场景,如城市道路工况,部分企业已开始瞄准第3 级或第4 级自动驾驶系统,积极布局关键技术的研发。谷歌的高级别自动驾驶项目开始于2009 年,已经在美国10 个州超过25 个城市进行路测,截止到2021年,行驶里程超过2 000万英里。百度于2017年发布了全球首个开放自动驾驶系统Apollo,截止到2021年,路测里程超过1 600万km。
然而,面向城市交通场景的高级别自动驾驶系统仍然面临一系列高难度的技术挑战。首先,道路的拓扑结构高度复杂,不同于高速公路场景的标准多车道结构,城市交通路网中涵盖立交桥、交叉路口、环岛、进出匝道等各式各样的道路类型;其次,周围交通参与者混杂多样,不同于封闭园区场景仅需考虑固定路线的驾驶任务,道路场景的开放性使得自车需要考虑交通参与者,与周围的乘用车、公交车、货车、行人、骑行人等竞争道路资源;最后,交通参与者行为意图高度随机化,典型的异常行为包括骑线行驶、右侧超车、鬼探头等,导致大量难以预测的未知因素,对行车安全产生严重威胁。总体而言,道路结构的高度复杂性、交通流的高度动态性,交通参与者的高度随机性,使得城市道路场景的复杂程度和安全风险急速提升。另外,车载控制器的计算资源十分有限,能耗/成本限制与高计算负担之间存在强烈的冲突,这使得自动驾驶系统的算法设计受到车载计算资源的强制约束,不能像巨型服务器一样运行复杂的功能层算法。
环境感知、自主决策和运动控制是自动驾驶汽车的3 大核心功能[1]。环境感知是指通过GPS、惯性导航装置等对自车进行定位与姿态估计,利用摄像头、毫米波雷达、激光雷达、超声波雷达等主要车载传感器及V2X 通信系统感知周围交通路况和动静态障碍物等信息。自主决策是指对于周围交通参与者进行意图识别和轨迹预测,进而根据全局行车目标、自车状态、感知信息和预测结果,决定驾驶行为模式并规划期望参考轨迹。运动控制是结合车辆的运动学或者动力学特性,将决策结果转化为油门、制动和转向盘等底层执行机构的控制指令。由于自主决策与运动控制均可以建模为动态过程的最优化问题,且后者的输入高度依赖于前者的输出,因此这两个模块的设计具有较强的耦合性,二者可以集成为一个功能模块进行开发,即“决控系统”。一般来说,决控系统相当于自动驾驶汽车的大脑部分,决控水平的高低体现了自动驾驶汽车的智能性。
从发展历史看,自动驾驶汽车的研发历史可追溯至20世纪60年代,如斯坦福大学的Cart号。21世纪初,自动驾驶的研发热潮迅速升温,尤其是受美国DARPA 挑战赛鼓励,一批高科技公司涌入这一领域,极大增强了自动驾驶的工程化能力。作为行驶智能性的核心,决控系统一直是自动驾驶团队最为关注领域之一。到目前为止,这一领域的技术方案已发展了3 代,即专家规则型、监督学习型和类脑学习型。早期的决控功能均围绕专家规则进行设计。例如:2007 年卡耐基梅隆大学的Boss 号[6]获得了DARPA 城市挑战赛的冠军,它的决控系统预先对于车道保持、车道变更、U 型掉头等场景设计了专门的行为规则,在线进行最佳的行为选择,然后规划一条局部的参考轨迹,最后解算底层控制指令;同一年斯坦福大学的Junior号[7]获得了亚军,它的决控系统包含一个具有13 个状态的有限状态机,用于直行、停车等待、驶过交叉口、掉头等驾驶行为的选择,使用了前向预瞄方法进行期望参考轨迹的跟踪。这些设计都是典型的专家规则型方案,而监督学习型方案的出现则依赖于深度学习技术的兴起。2016 年英伟达公司[8]采集了72 h 的自然驾驶数据,建立了从摄像头图像输入到转向盘转角输出的标签数据集,以卷积神经网络构建模型进行监督学习,实现了车道保持功能。2017年苏黎世联邦理工大学[9]收集了真实换道工况下与周车的间距和相对速度数据集,使用支持向量机训练换道决策分类器。专家规则型和监督学习型这两种技术方案都采用被动式的设计思路,其中前者依靠人工设计的经验规则,后者模仿人工标注的示范动作。虽然可以较快实现车道保持等初级功能,但对于复杂场景的高级别自动驾驶任务仍然表现不佳,智能性的进一步提升存在瓶颈,难以达到人类驾驶员的水平。
自动驾驶的最终目标是替代人类执行驾驶动作,为了进一步提升智能性水平,从人脑学习机制中寻求启发是具有潜力的发展方向。对于生物学习机制的研究可追溯至19 世纪末,巴甫洛夫以狗为研究对象,提出条件反射机制,表明生物具有从奖励中“学习”的能力[10]。桑代克进一步研究了行为学习机制,关在笼中的猫经过多次重复尝试可以熟练掌握逃离迷笼获取食物的技能,表明生物的行为学习基于“探索试错”原理[11]。20 世纪末,剑桥大学提出了奖赏预测误差假说用于解释人脑的学习机制,指出人脑中的多巴胺激素正是外界输入激励所产生的奖励信号,可以刺激人脑中的神经元活动从而调整行为模式[12]。对于驾驶车辆这一具体任务,人类驾驶员并不是简单牢记专家规则,也不是以大量驾驶过程为示范进行直接模仿,而是主动式地通过驾驶动作在交通环境中进行探索交互,根据接收的反馈信号(例如偏离车道程度、与目的地的距离等)调整自身的行为策略,逐步熟练掌握驾驶技能。
类脑决控的发展动机正是从人脑学习机制寻求启发,其定义如下:类脑学习型自动驾驶决控系统以深度神经网络为策略载体,以强化学习为训练手段,利用车端与云端协同收集的环境交互数据更新自动驾驶策略,通过数据闭环持续进化的方式不断提升智能性水平。2016 年谷歌[13]使用深度确定性策略梯度算法,利用仿真平台实现了以摄像头图像为输入,以转向盘、加速度等连续控制量为输出的车道保持功能。从2018 年开始,清华大学提出并推动了集成式决控架构的设计与应用[14],将自动驾驶的决控任务统合为一个最优控制问题,通过Actor-Critic 强化学习算法进行求解,首次实现了红绿灯通行、无保护左转等交叉路口驾驶任务的实车验证[15-16]。总体而言,类脑决控技术不依赖于标签化的驾驶数据,通过与环境的交互探索实现策略的自我更新和自我进化,这是高级别自动驾驶系统的下一代发展方向。
本文将聚焦于类脑学习型自动驾驶决控方案以及关键技术的探讨,涉及界定策略设计的系统框架、支持交互训练的仿真平台、决定策略输入的状态表征、定义策略目标的评价指标和驱动策略更新的训练算法等5 个层面。首先梳理了自动驾驶决控的两类模块化架构以及3 种典型技术方案;概述了当前主流的自动驾驶仿真平台;分析了类脑决控的3 类环境状态表征方法;同时介绍了自动驾驶汽车的五维度评价指标;然后详述了用于自动驾驶的典型强化学习训练算法及应用现状;最后总结了类脑自动驾驶的问题挑战和发展趋势。
1 自动驾驶决控架构与技术方案
从设计思想看,自动驾驶决控系统分为模块化和黑箱化两个大类。前者将系统分解为一系列功能独立的模块,每一个模块单独设计,组合到一起实现自动驾驶的决策与控制功能;后者又称为端到端决控系统,它将决控系统视作一个黑箱,训练一个神经网络得到感知结果到控制命令的直接映射。从目前的行业应用看,模块化设计更适合团队分工合作,具有更好的工程落地能力,它的开发通常分为两个阶段:首先是确定体系架构,将决控任务划分为若干个具有独立性的功能模块,同时定义模块之间的信息传递关系;其次是确定技术方案,即核心模块所采用的算法及实现方式。
对于模块化设计而言,合理的体系架构是开发一个高可靠、易扩展决控系统的关键,有利于减少算法复杂度,降低工程实现的难度。模块化系统的典型架构包括两类:分层式决控(hierarchical decision& control ,HDC)和集成式决控(integrated decision &control ,IDC)。前者将自动驾驶的自主决策与运动控制严格分为两层单独设计,二者之间通过期望的行驶轨迹进行衔接;后者将自动驾驶决控任务整合为一个统一的约束型最优控制问题,仅包含一个性能指标、一个动力学系统,并求解一个最优策略。进入深度学习时代,部分学者试图采用黑箱化思想进行决控系统设计,即采用端到端架构(end-to-end,E2E),利用深度神经网络实现从感知结果到控制命令的直接映射。端到端架构虽然更加类似人类驾驶员的大脑工作机制,但目前受车载控制器算力的限制,神经网络的规模不大、智能性不佳,尚处于实验室研究阶段,难以工程落地应用。
与体系架构不同,技术方案是指自动驾驶决控系统核心功能模块的实现手段。常见的方案包括专家规则型、监督学习型和类脑学习型。专家规则方案以驾驶行为选择为核心模块,通过专家经验预先设计一定的规则条件,选择最合理的驾驶行为模式。监督学习方案,通常以深度神经网络为载体,通过专家驾驶数据构建关键模块的输入输出模型。类脑学习方案则以神经网络为载体,利用强化学习算法进行训练,通过自主探索环境进行策略的自我进化。表1 总结了典型设计思想之下的架构类型与技术方案。

表1 自动驾驶决控系统总结
1.1 两类典型的模块化架构
(1)分层式决控(HDC)架构
分层式决控架构的广泛使用可追溯至美国的DARPA 挑战赛,包括卡耐基梅隆大学的Boss 号[6]和斯坦福的Junior号[7],这也是目前工业界常见的系统开发架构。HDC 架构将自动驾驶的自主决策与运动控制严格分为两层,二者之间通过期望的行驶轨迹进行衔接,因此期望行驶轨迹既是决策层的输出,又是控制层的输入。为了便于工程化开发,一般进一步分解为周车行为预测、驾驶行为选择、动态轨迹规划、横向运动控制和纵向运动控制5 个功能模块,如图1所示。

图1 分层式决控(HDC)架构
各模块的基本功能如下:(1)周车行为预测模块对周围车辆、行人、骑行人等进行意图或轨迹预测,供之后的驾驶行为选择和动态轨迹规划模块使用;(2)驾驶行为选择模块根据包括安全、能耗、时效、合规、舒适等行车性能指标,选择最合理的当前行为模式,这一模块是自动驾驶智能性的核心,它的设计通常需要提前定义驾驶行为的集合,如车道保持、跟车、换道、超车、掉头等;(3)动态轨迹规划模块结合行为选择、预测轨迹以及路网约束,计算一条考虑行车性能且满足车辆动力学、行车安全性等约束的时空曲线作为参考轨迹,即期望行驶轨迹;(4)横向运动控制模块根据决策层给出的期望行驶轨迹,解算转向盘转角等横向控制指令;(5)纵向运动控制模块根据决策层给出的期望行驶轨迹,解算油门踏板角度、制动踏板角度等纵向控制指令。另外,部分HDC 框架将纵向运动控制和横向运动控制进行组合,称为纵横向联合控制。还有一些框架将控制层分解为路径跟踪和速度跟踪两个模块,分别设计控制器进行实现。
HDC 架构的优势十分明确,它具有问题可拆解、任务可拆分的优点,便于工程化开发时的团队分工和组织协调。但是,其模块间的信号传递不可避免地存在信息丢失的风险,而且各模块具备各自独立的优化目标,目标之间存在一定矛盾和冲突,不利于提升决控系统的整体智能性。同时,因为HDC 架构的模块分解比较平均化,缺乏一个主导性模块,不利于深度学习、强化学习等智能化算法的引入,过于依赖工程师的设计经验,难以获得理想的驾驶智能性。
(2)集成式决控(IDC)架构
为了更好地提升驾驶过程的智能性,清华大学于2018 年提出了用于高级别自动驾驶汽车的集成式决控(IDC)架构[14]。与HDC 架构不同,IDC 架构将自动驾驶决控任务进行了重塑,整合为一个统一的约束型最优控制问题(optimal control problem,OCP),仅包含一个性能指标、一个动力学系统,最终仅求解一个最优的决控策略。这一主导性模块的存在使得IDC 架构更适合引入以神经网络为基础的学习型算法,便于实现数据驱动的闭环训练流程(即车端采集数据、云端集中训练、策略远程升级),增强了对稀有交通场景的自我适应能力,有助于获得更高智能性的自动驾驶功能。
与HDC 架构不同,IDC 架构包括静态路径规划和动态优选跟踪两个功能模块,如图2 所示。前者是辅助性的,后者是主导性的。静态路径规划模块仅根据静态道路环境信息(如道路几何结构、路侧及地面指示标识等,但不包括红绿灯控制、交通参与者等信息),输出一套可被跟踪的备选路径集合。特别值得注意:这是一套备选路径的集合,而不是单条最优的参考轨迹,具体跟踪哪一条备选路径将由动态跟踪优选模块进行确定。动态优选跟踪模块作为主导模块,则构造为一个跟踪备选路径集合的约束型最优跟踪控制,通过强化学习求解为评价函数和策略函数两个模型。这两个模型通常都采用神经网络进行表示。训练之后的评价函数可评价不同备选路径的代价值,实现对静态参考路径的优化选择,达到类似于“自主决策”的功能。训练之后的策略函数则可根据优选得到的参考路径,输出油门、制动、转向盘等控制指令,实现类似于“运动控制”功能。

图2 集成式决控(IDC)架构
简单而言,IDC 架构虽然也存在路径规划模块,但它的规划算法是十分简单的,通过与地图绑定的道路几何结构、路面及路侧标识等信息进行制定,而不使用动态时变的红绿灯信号、交通参与者等信息,这是称之为“静态”的原因。这一做法的目的是为自动驾驶功能的实施提供一定的先验知识,降低后续最优控制问题的求解难度。决控过程的主体功能都集成于动态优选跟踪模块,通过求解统一的约束型最优控制问题,整合了自主决策与运动控制两项独立的功能,避免了模块之间性能指标冲突的难题。
IDC 架构的优点在于:(1)静态路径规划仅使用道路的静态信息,在线计算效率高,甚至可将预先制定的路径集合存入自动驾驶地图,应用时直接读取所需路径信息,极大提高在线应用的实时性,同时“静态化”的处理手段特别适用于结构化道路(如高速公路、城市道路等),且应用场景类型十分广泛(如交叉路口、环岛、多车道、进出匝道等);(2)动态优选跟踪本质是一个约束型最优跟踪控制问题,通过最优控制命令的求解体现了“自车跟踪参考路径”与“周车约束自车行为”的博弈过程,理论上具有较好的可解释性,对于最优控制问题,典型的求解方法如模型预测控制、近似动态规划、强化学习均可采用,尤其是后两者是可以先离线训练策略,再在线应用策略,这也极大降低了在线计算的负担。IDC 架构的挑战在于主导模块的集成度过高,性能指标与训练算法的设计十分复杂,对工程人员的理论功底和算法能力提出了更高的要求。受框架结构集成度高的影响,各设计要素之间强耦合,性能呈现典型的木桶原理特性,因此即使个别要素的设计不合理,会导致自动驾驶性能急剧下降,所以对于缺乏经验的设计者,很多时候IDC 呈现的自动驾驶水平反而不如HDC架构。
1.2 3种决控系统的技术方案
(1)专家规则型
专家规则型方案是围绕驾驶行为选择为核心的一套经验性设计技术,一般只用于分层式架构。典型特征是利用专家经验设计自车的行为选择模块,结合规划算法进行动态路径规划,利用误差反馈设计参考轨迹的跟踪控制器。一般来说,首先对场景进行分类,例如多车道、交叉路口、环岛、进出匝道等,然后根据专家经验对每一种场景定义专门的行为状态以及状态之间的转移条件。典型的设计形式是有限状态机,其节点是行为状态(例如车道保持、换道、超车等),边是状态转移的条件,如图3 所示。自动驾驶汽车在行驶时根据道路环境以及自车状态,按照预定规则确定当前最佳的驾驶行为。

图3 专家规则型方案
该方案的难点在于如何划分行为状态并确定状态之间的转移条件。对于高速公路等稀疏交通场景,通过少量行为状态便可以覆盖大部分行车工况然而对于城市道路等密集交通场景,行驶工况的复杂程度与安全风险大幅提升,仅依靠工程师的经验与规则难以穷尽所有可能性,因此开发迭代过程往往需要向状态机不断增加补丁,导致维护难度爆炸式增长。总体而言,该方案的优点在于直接使用道路交通规则与人类驾驶经验等先验知识,驾驶行为选择的可解释性好,但由于高度依赖人工设计,难以覆盖所有工况,严重缺乏特殊场景的适应性。特别是在高密度、高动态、高随机的城市道路交通环境下,其智能化水平远不及人类驾驶员,安全风险居高不下,还不能满足高级别自动驾驶的智能性要求。
(2)监督学习型
监督学习型方案一般以某一类型的深度神经网络为模型载体,如全连接神经网络、卷积神经网络或Transformer 网络等,利用大量的自然驾驶数据构建训练数据集,通过监督学习拟合决控过程的核心模型。图4 展示了一个端到端自动驾驶决控系统的案例,其中专家驾驶数据由驾驶状态(样本)和对应的驾驶操作(标签)组成,驾驶状态包括摄像头、毫米波雷达、激光雷达等传感器感知到的道路环境信息,驾驶操作包括转向盘转角、纵向加速度等控制命令。监督学习的基本原理是同等样本输入条件之下,通过最小化模型输出与标签的误差,对模型参数进行迭代更新。该方案既可用于HDC 架构,又可用于IDC 架构。对于HDC 架构而言,它用于解决各功能模块的设计,例如:对于周车行为预测模块,可预先采集大量真实车辆轨迹段,以轨迹段的前一部分为样本,剩余部分为标签构建训练数据集进行监督学习;对于运动控制模块,可预先收集大量规划好的期望行驶轨迹作为样本,通过某一类型的高性能运动控制器输出最优控制指令作为标签构建数据集进行监督学习。

图4 监督学习型方案
该方案不需要人工经验设计特定的规则,本质是通过离线数据集模仿专家驾驶员的行为。得益于深度神经网络强大的拟合能力,这一方法在训练数据集的样本空间内,可以取得不错的模仿效果,但无法超越专家驾驶员的性能表现。此外,随着自动驾驶性能要求的提升,所需驾驶数据量及驾驶场景丰富度迅速增长,据兰德公司预测,该方案要达到人类驾驶水平,所需标签数据量高达160 亿km[16]。同时,该方案还面临着样本分布不均衡、罕见工况数据难以获取等挑战,场景泛化能力不足,安全保障能力有限。
(3)类脑学习型
类脑学习型方案是一种模仿人脑试错学习的技术方案,基本原理是通过重复正向奖励的行为,避免负向惩罚的行为,以最大化累积奖励回报从而实现自动驾驶策略的自我进化与更新。具体而言,该方案以深度神经网络为策略载体,以强化学习为训练手段,通过与交通环境的交互探索实现策略的自我进化,最终获得从环境状态到执行动作的最优映射,即最优驾驶策略。如图5 所示,该方案包括反馈控制与策略更新两个闭环。反馈控制环中,自车观测反馈的环境状态,经策略函数输出控制动作,与环境进行交互;策略更新环中,自车根据当前执行动作与环境状态计算奖励信号,利用强化学习算法驱动策略参数更新。通过这两个闭环的循环迭代,最终收敛到最优的自动驾驶策略。

图5 类脑学习型方案
该方案与监督学习的主要区别在于:(1)类脑学习摆脱了对标签数据集的依赖,可通过在仿真平台或真实物理环境中的自我探索求解最优策略;(2)类脑学习并不是拟合给定的示范动作,而是在以获得更多的奖励回报为目标求解最优策略,因而具有超越人类驾驶员的潜力;(3)类脑学习不局限于标签数据集中的样本(状态)与标签(动作)空间范围,能够在交通环境中收集任意状态-动作对的样本进行策略求解。总体而言,该方案可实现一定程度的自主探索与自我学习,适合未知场景条件求解最优驾驶策略,但同时面临着策略训练效率低下、易对训练环境过拟合、在线探索环境安全性差等挑战。
2 自动驾驶仿真软件
自动驾驶系统的实车道路测试面临着安全风险高、成本高、效率低、重复性差等诸多方面的挑战,而利用自动驾驶仿真软件,研发人员能以极低的成本进行场景的灵活配置与复现重演,快速实现原型开发与性能评估。此外,对于类脑决控系统的训练过程,真实道路环境的数据采集依赖于探索试错机制,这往往意味着极低的采样效率与极高的安全风险,因此利用自动驾驶仿真平台进行训练与测试是开发高级别自动驾驶系统的必由之路。到目前为止,常见的自动驾驶仿真软件包括TORCS、CARLA、Prescan、Apollo、TADSim、Cognata、DriverGym、AirSim、MetaDrive、LasVSim 等。自动驾驶仿真软件如此之多,那么如何评价一款自动驾驶仿真软件的优劣呢?从自动驾驶工程化的角度看,关键点不在于驾驶场景3D渲染的美观程度,而在于各核心模块可否准确反映真实物理对象的主要特性,也就是自动驾驶关联要素的保真度,尤其是道路地图建模、交通参与者行为、环境传感器特性与车辆动力学特性、自动驾驶性能评估等。
一般来说,典型自动驾驶仿真软件至少包括道路场景模拟、交通参与者模拟、网联通信模拟、环境传感器模拟、车辆动力学模拟、驾驶性能评估,以及自动驾驶系统本身感知、定位、预测、决策与控制等算法模块。不同仿真平台的功能特点可从4 个方面进行对比评析:(1)界面渲染类型,即3D物理引擎渲染或2D俯视平面渲染;(2)地图自定义能力,即是否完备支持手动编辑、真实数据导入、随机生成场景等方式;(3)典型仿真要素的模拟准确度,包括车辆动力学、环境传感器、微观交通流等典型要素是否能够提供完备的高保真模型;(4)仿真计算效率,这对大规模仿真测试以及交互式训练至关重要。表2 总结了主流自动驾驶仿真软件的功能特点和维护机构(注:○越多,表示该项性能越好)。

表2 自动驾驶仿真平台
3 类脑决控的状态表征方法
监督学习和类脑学习两种技术方案均以深度神经网络作为策略载体,它的输入要求是一个长度固定的一维向量[32-33]。然而自车感知到的环境状态信息并不能直接满足这一要求,例如行驶过程周围交通参与者的数量总是动态变化的,且周车或行人之间不存在明确的空间顺序关系,导致不能拼接为定维向量,难以满足策略网络的输入要求。因此,通过状态表征(state representation)将环境状态信息表达为定维表征向量是使用神经网络策略的必然要求[34]。
对于类脑学习而言,自动驾驶决控任务属于典型的马尔科夫过程,即每一时刻的最优动作仅通过当前的环境状态得到,因此对应时刻的表征向量需要充分包含决控所需信息。表征向量的选取直接影响策略训练难度和训练效率,如何在有限的表征向量维度下有效抽取影响自动驾驶的关键特征,是状态表征的研究重点[33]。从原理上说,状态表征的本质是将复杂多元的环境感知信息压缩为一维向量,主要手段包括两个大类,即语义级别的“目标识别”和元素级别的“特征提取”。根据这两种技术手段的应用方式,自动驾驶决控策略的状态表征方法分为目标式(object-based)、特征式(feature-based)和组合式(combined design)3个子类,如图6所示。
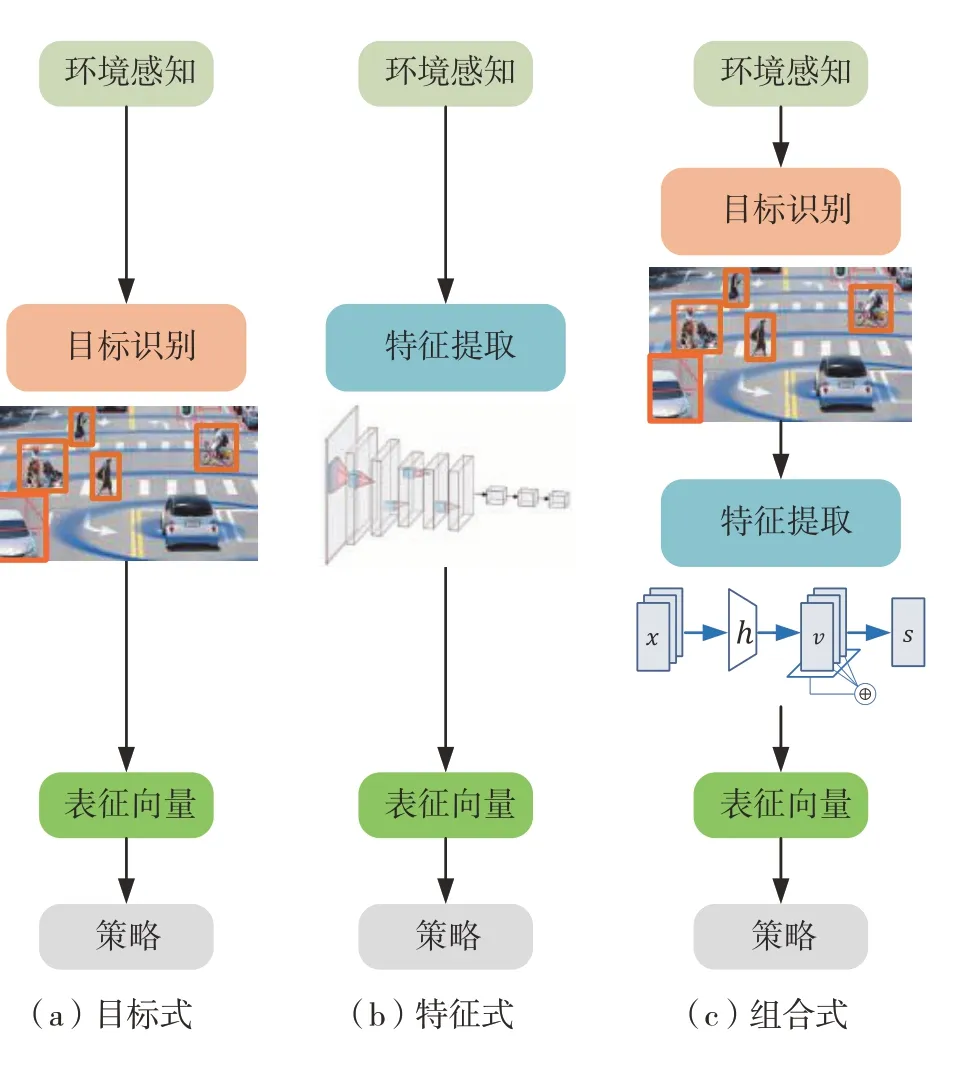
图6 类脑决控的3种状态表征方法
3.1 目标式状态表征
目标式状态表征首先需要指定待识别目标类别,并分别设计不同类别目标的状态;然后从感知信息中进行目标识别;最后将各识别目标的状态直接拼接为表征向量[35]。交通环境中的待识别目标主要包括自车、道路环境和周围交通参与者3类。
3.1.1 自车
自动驾驶汽车可近似为仅在平面运动,有横向平动、纵向平动和横摆转动3 个运动自由度,每个自由度的运动状态可由一个位置量和一个速度量表示。因此,自车状态包括6 项:横向位置、纵向位置、横摆角度、横向速度、纵向速度和横摆角速度[36]。
自车状态的表征按照坐标系可分为3 种:(1)大地坐标系,将6 项状态量直接作为表征,但是由于包含绝对位置,只适用于固定场景[23];(2)Frenet 坐标系,将各状态量投影至沿车道方向和垂直车道方向作为表征,便于直观表达与车道中心线的相对位置关系,一般适用于多车道场景,但难以应用于交叉路口等复杂开放场景[37-38];(3)自车坐标系,以自车为中心,只需平面,3 自由度的速度量作为表征。由于不需要输入位置信息,因此可与场景解耦,但道路环境、周围交通参与者等其他目标需表达为与自车的相对信息[39]。
3.1.2 道路环境
道路环境信息主要包括道路连通关系、道路边缘和交通信号灯。
道路连通关系指示行驶路径。一般表征为参考轨迹点序列,主要有两种方式[40]:(1)等时间距,相邻两点间距为参考速度与时间步长的乘积,每个轨迹点的信息包括横纵向坐标;(2)等空间距,相邻两点间距固定,但每个轨迹点的信息还应包括在该位置的参考速度。
道路边缘指示可行驶区域的边界。表征方式主要有:(1)最小间距式,即车辆质心与道路边缘的最短距离,仅需要计算一个变量,表征维数低[25];(2)固定方位式,即在自车坐标系下,计算车辆质心沿N个固定方向与道路边缘的距离。由于同时包含距离与方位信息,还额外表达了自车与可行驶区域的空间位置关系[41]。
交通信号灯指示通行规则,包括信号灯颜色和剩余时间。信号灯颜色一般独热(one hot)编码为三维向量,对应红黄绿3 种信号灯;再拼接剩余时间作为交通信号灯表征。前方无信号灯时,一般设为具有最大剩余时间的绿灯信号[23]。
3.1.3 周围交通参与者
周围交通参与者(周车)集合主要有以下特点[34]:(1)类型混杂,典型的城市道路环境中存在机动车、行人和骑行人等不同类型的交通参与者,其形状尺寸、活动范围、运动能力、行为模式及风险特征差异巨大;(2)数目时变,由于道路结构、车流密度、感知遮挡等因素,自车感知到的周车数量总是动态变化。
对于类型混杂、数目时变的周车集合,现有研究一般采用固定排序方案[34],即首先固定最大周车数量N,假定每辆周车的状态为m维,通过规则排序得到一个N×m维向量作为表征。排序规则的设计依据主要包括相对距离、相对方位和冲突关系等。这种方案简洁易操作,但是最大周车数量N难以选取:当实际周车数目大于N时,须将距离较远者剔除,导致信息遗漏,影响策略求解最优性;当实际周车数目小于N时,须在离自车较远处添加虚拟周车,导致信息冗余,增大策略求解难度。
总体而言,目标式状态表征的优势在于:(1)可解释性强,作为表征的目标状态一般具有明确的物理意义;(2)可迁移性好,无论是仿真环境还是实车平台,无论传感器如何搭配组合,只要能够提供识别目标的状态信息,便可对所学驾驶策略进行部署。劣势在于:(1)部分目标状态需要在线规划计算;(2)如何选取待识别目标、定义目标状态以及对目标进行排序严重依赖人工设计,存在扩展性难题。
3.2 特征式状态表征
特征式状态表征不进行目标识别,仅预先指定特征的维数,通过一个特征提取模块直接从感知信息(如摄像头图像、激光雷达点云等)中提取表征向量。目前,特征提取模块一般以深度神经网络为载体,训练方法主要可分为在线进化和自监督两种模式。
在线进化模式是指特征提取模块与策略函数同时进行训练,均以最大化环境反馈的奖励信号为目标,以强化学习为训练手段,实现自我进化,如图7所示。特征提取模块的典型网络结构包括多层感知机MLP[42]、卷积神经网络CNN[42]、点网络PointNet[43]和循环神经网络RNN[44]等。

图7 在线进化模式
自监督模式是指特征提取模块的训练与策略训练相解耦,采用自监督的方式预先训练。“编码器-解码器”是典型的自监督训练架构,它通过比较输入的环境状态与编解码之后输出的重建状态之间的误差,以自监督学习的方式训练一个编码器和一个解码器,其中编码器即为特征提取模块,如图8 所示。该架构的典型网络结构包括生成对抗网络GAN[45]、自 动 编 码 器AE[46]、变 分 自 动 编 码 器VAE[47]和Transformer[48]等。

图8 自监督模式
在线进化模式可同时训练特征提取网络和策略网络,结构清晰,但劣势在于容易对训练环境过拟合;自监督模式可利用来自多个环境的样本预先训练特征提取器,抑制对特定环境的过拟合,但劣势在于需要大量样本来构建训练数据集。
总体而言,特征式状态表征的优势在于信息损失少,直接从原始观测输入到表征输出。劣势在于:(1)可解释性差,特征提取过程是一个黑箱;(2)训练难度大,原始观测信息的维数较高,特征提取困难;(3)可迁移性差,仿真训练平台的传感器模型与真实道路的实际传感器通常存在较大差异,此外,传感器的安装位置、角度、型号不同也将造成观测空间的差异,导致所训策略难以向真实世界迁移。
3.3 组合式状态表征
为了摆脱对周车排序规则的依赖,同时加速特征提取,组合式状态表征融合了前两种方法的优势,即在目标识别的基础上,通过编码聚合函数对目标集合进一步提取特征,得到关于集合内元素排列不变的定维表征[49]。编码聚合过程可数学化描述为xset=Agg(X),其中X 为识别的目标集合,xi为目标集合中第i个目标的状态,xset为对该集合编码聚合后得到的表征向量,Agg(·)为编码聚合函数[50],由编码网络和聚合算子组成。
典型的编码网络结构包括多层感知机MLP 和卷积神经网络CNN 等,既可以采用自进化模式,也可以采用自监督模式进行训练;典型的聚合算子包括求极大(max)、求平均(mean)、求和(sum)、注意力(attention)等[50]。Duan 等[34]首先将求和式编码聚合网络用于周车集合的状态表征。如图9 所示,首先使用MLP的编码网络分别处理所有周车的状态xi得到单车编码vi,然后通过求和(sum)算子聚合。Guan等[15]设计了基于注意力(attention)机制[51]的编码聚合网络,可在特征提取过程中动态甄别不同周车的重要性,如图10所示。
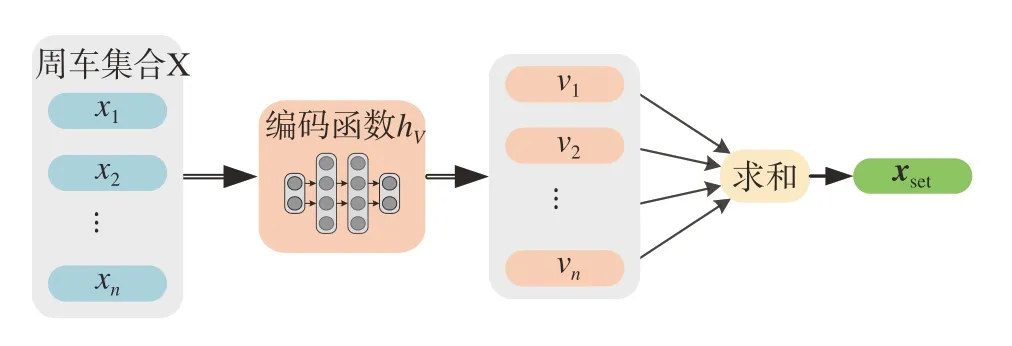
图9 求和式编码聚合[34]

图10 注意力式编码聚合[51]
总体而言,组合式状态表征方法的优势在于:(1)相比于目标式,不依赖于人工设计周车排序规则,通过编码聚合函数实现可变数目周车集合的排列不变表征;(2)相比于特征式,可迁移性好,可以复用成熟的目标识别模块,只要求提供待识别目标的状态信息,便可编码聚合得表征向量。劣势主要在于从环境状态输入到表征输出之间同时包含目标识别和特征提取两个过程,可能导致较大的信息损失。
4 自动驾驶性能评价指标
自动驾驶性能评价是系统功能测试以及策略训练改进的基础,关键在于建立准确可靠的评价指标体系。通常评价维度至少包括安全性(driving safety)、舒 适 性(driving comfort)、通 畅 性(travel efficiency)、经 济 性(energy efficiency)和 合 规 性(regulatory compliance)等,各个维度又包括评价当前时刻的瞬时指标和评价单次驾驶任务或单位驾驶里程的统计指标。统计指标一般为瞬时指标的均值或累积值。对于类脑学习系统而言,驱动策略更新的唯一信息来源于环境反馈的奖励信号,因此策略性能取决于以评价指标为基础的奖励函数设计。
4.1 安全性
保障道路安全是自动驾驶技术发展的重要挑战[52]。早期的安全性评价模型主要考虑与碰撞工况相关的物理性特征[53],例如车间距离、碰撞时间(TTC)、冲突时间差(PET)、避免碰撞的减速度(DRAC)等,然而这些指标与具体的碰撞事件紧密绑定,难以至一般性的无冲突场景。另一些安全指标基于运动场的概念进行设计,如驾驶员风险场(driver’s risk field)[54]等,可用于一般性的无冲突场景,但一方面该类模型的参数较多,标定困难,另一方面缺少客观的真实风险标准,难以对模型的准确性进行定量评估。为了实现安全风险的量化建模,清华大学于2021 年提出了潜在碰撞损伤风险(PODAR)模型,核心思想是以碰撞损伤度(包括人损和车损)作为行车安全性的客观标准,将当前的运动状态折算为未来某一时刻的碰撞损伤度[55]。PODAR 模型首先假定预测时域之内碰撞将会发生,考虑碰撞双方的质量、相对速度和相对方向等因素计算碰撞损伤值,这是被动安全领域十分成熟的模型;然后从空间和时间两个维度对未来时刻的碰撞损伤值进行折减,得到当前时刻的潜在碰撞损伤,用于衡量驾驶过程的安全性。
4.2 合规性
合规性是指自动驾驶行为是否符合交通法规。需要说明的是,不少行车风险模型将安全性与合规性两者混为一谈,实际上合规性与安全性并不等价,行车合规不代表安全,但行车安全也不一定合规。一个典型例子是如果当车辆在红灯前停止,且后方车辆高速逼近时,继续保持红灯等待状态虽合规,但可能导致后车追尾碰撞,损害了安全性;而提前加速起步虽闯红灯违规,但可能避免后车碰撞,提升了安全性。因此,将安全性和合规性进行解耦,分解为两个不同的评价维度,有利于解决自动驾驶的行车风险评估难题。一般来说,不同违规行为的严重程度可根据交通法规衡量,例如我国交通法明确规定:高速公路不按规定车道行驶扣3 分,城市路口场景中闯红灯扣6分等,这是合规性建模的基本原则。
4.3 舒适性
车辆行驶的过程中,乘客的舒适性主要与车辆纵横向运动的冲击特性相关。具体而言,人体乘坐舒适性可由纵向、横向两个维度的加速度值进行衡量,例如加权均方根值。一般来说,加速度的均方根值越大,舒适程度越低,反之更好。
4.4 通畅性
通畅性是指车辆经过一段道路的通行效率。一般可由自车速度与周围交通流平均速度(无车时可采用道路限速)的比值进行衡量。该比值越大,说明自车行驶的通畅性越好。
4.5 经济性
经济性是指车辆行驶过程的能量消耗水平。对于同样的驾驶任务,能量消耗越少则经济性越好[56]。根据动力能源形式,例如燃油汽车或电动汽车,可由燃油消耗率和电能消耗率等指标进行衡量。
5 类脑决控的强化学习训练算法
类脑决控系统以强化学习(reinforcement learning, RL)为训练手段,通过与交通环境的不断交互实现策略的更新优化。强化学习的设计思想源于生物的试错学习机制,即生物如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为模式。现代意义的强化学习属于人工智能和自动控制的交叉领域:从前者视角看,它是指智能体如何通过与环境交互试错,利用反馈的奖惩信号来改进自身策略的学习机制;从后者视角看,它是指用于最优控制问题的全状态空间求解器,获得从环境状态到执行动作的最优映射,即最优策略[57]。目前,车云协同训练是将强化学习应用于高级别自动驾驶任务的一个常见开发模式。它的基本原理如图11 所示,核心是训练以深度神经网络为载体的策略函数,其中训练数据的来源同时包括云端的海量存储和车端的数据上传。同时借助云端的高性能算力,实现高性能强化学习算法的离线应用,训练之后的神经网络通过OTA(on the air)模式远程下载至车端,升级自动驾驶功能。总体而言,车云协同训练的数据流动形成了反馈控制环和策略更新环两个闭环。前者是指自动驾驶系统根据传感器的实时感知数据,得到执行器动作,控制车辆持续行驶,形成反馈控制闭环。后者是指车端收集当前策略对应的环境感知与控制命令数据,上传至云端用于策略训练与OTA 升级,接着对更新后的策略继续收集行驶数据上传云端训练升级,形成策略参数更新闭环。
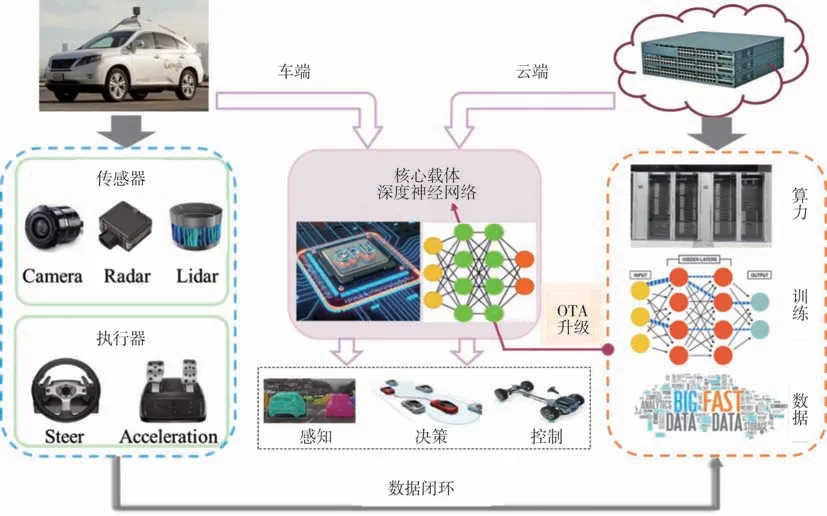
图11 车云协同训练架构
5.1 强化学习的基本原理
强化学习一般将待求解问题构造为马尔可夫决策过程(Markov decision process, MDP),求解过程主要包含4 个基本元素[57]:状态动作对(st,at)、策略π、奖励信号rt和环境模型f。每个时间步t,智能体根据状态st与策略π决定动作at,然后环境会给出下一时刻状态st+1与奖励信号rt(st,at)。强化学习的目标是学习到能够最大化期望累积回报的策略:
式中:d0(s)为t= 0 时的状态分布;γ∈[0,1]为折扣系数。目前,广泛使用的强化学习算法多属于Actor-Critic 架构。为了评估当前状态的优劣,通常引入状态价值函数V(s)或动作价值函数Q(s,a),估计未来的期望累积回报,因此称为评估器(Critic)。策略函数用于输出动作使得环境向更高价值的状态转移,因此也称为执行器(Actor)。值得一提的是,IDC 架构的评价函数和策略函数恰好可以对应于Critic 和Actor 的功能定位,这是IDC 架构设计的巧妙之处,也是它与强化学习算法特别匹配的原因[15]。
5.2 强化学习的算法进展
强化学习算法的发展历史悠久,但引起工业界的广泛关注始于深度化版本的开发。2015 年Mnih等人提出了DQN(deep Q network)算法[58],首次在Atari 游戏中超越了人类的表现,自此至今,DDPG(deep deterministic policy gradients)[13]、TD3(twin delayed deep deterministic policy gradient)[59]、PPO(proximal policy optimization)[60]、RMPC(recurrent model predictive control)[21]、SAC(soft actor critic)[61]、DSAC(distributional soft actor critic)[62]、MPG(mixed policy gradient)[63]等性能优异的深度强化学习算法层出不穷,令人眼花缭乱。
强化学习的算法种类如此繁多,急需合理的分类方式进行梳理,以便更为深入地理解原理。常见的分类方式包括:根据模型和数据的利用方式[64],分为模型驱动型(model-driven 或model-based)、数据驱动型(data-driven 或model-free)以及融合使用模型与数据的混合驱动型(mixed-driven);根据采样策略与目标策略是否相同[57],分为在轨型(on-policy)和离轨型(off-policy)。然而,这些分类方式都是根据训练过程的表象差异进行区分,不利于设计者深入了解算法的本质差别,进行更为合理的算法设计和选择。目前,更为基础的分类是根据最优策略的求解方式进行划分,将强化学习分为如下间接法和直接法两类[65]。
(1)间接法的基本原理是求解贝尔曼方程,即最优解的充分必要条件,将贝尔曼方程的解作为最优策略。按照迭代方式进一步可分为策略迭代(policy iteration,PI)和值迭代(value iteration,VI):前者的本质是使用Newton-Raphson 迭代法求解贝尔曼方程[57],通过交替策略评估和策略改进两个环节,不断改进当前策略以逐步逼近最优策略;后者则根据不动点迭代直接更新值函数,直至收敛到最优值,而最优策略即为最优值函数的贪心搜索。
(2)直接法将强化学习视为一种对目标函数求极值的迭代优化方法,典型求解方法可分为零阶梯度法、1 阶梯度法、2 阶梯度法等。以遗传算法为代表的零阶梯度法,可适用于非光滑问题,但收敛速度较慢,求解效率不佳。1 阶、2 阶等策略梯度方法均沿着梯度下降方向迭代逼近最优策略,适用于凸性较好的问题。理论上说,阶次越高收敛速度越快,但是2 阶导数的计算成本太大,反而会恶化训练速度,因此目前仍是1阶策略梯度法最为常用。
值得一提的是,Actor-Critic 作为一类广泛使用的强化学习架构,既可来源于间接法,又可来源于直接法[65]。从间接法角度看,Critic 和Actor 的更新分别对应了策略评估和策略改进两个环节的参数化近似,如图12 所示;从直接法角度看,Actor-Critic 可被视为一类带值估计的策略梯度(policy gradient)方法,其中Critic 是利用值估计机制构造目标函数,Actor 计算目标函数对策略参数的梯度并执行策略更新,如图13所示。

图12 间接法导出的Actor-Critic架构[57]

图13 直接法导出的Actor-Critic架构[57]
间接法和直接法分类的优势在于它区分了最优策略求解方式的本质原理,同时又均可衍生出Actor-Critic 架构,证明了两类方法在理论层面具有最优性等价关系,这对强化学习的原理理解具有重要意义。根据这一分类方式的理解:从直接法角度可致力于更综合的目标函数设计;从间接法角度可发掘更多最优解的等价或必要条件构造迭代方程,这为强化学习领域的新型算法设计提供了全新的视角。
5.3 类脑决控技术应用现状
随着车载控制器的算力增长以及对自动驾驶困难性的认识加深,类脑自动驾驶技术正得到越来越多的关注。到目前为止,这一技术已经能够解决多车道、交叉路口、环岛、进出匝道等诸多工况的决策与控制功能,正逐步迈向真实交通场景的工程应用和测试验证。典型的自动驾驶案例如表3所示。
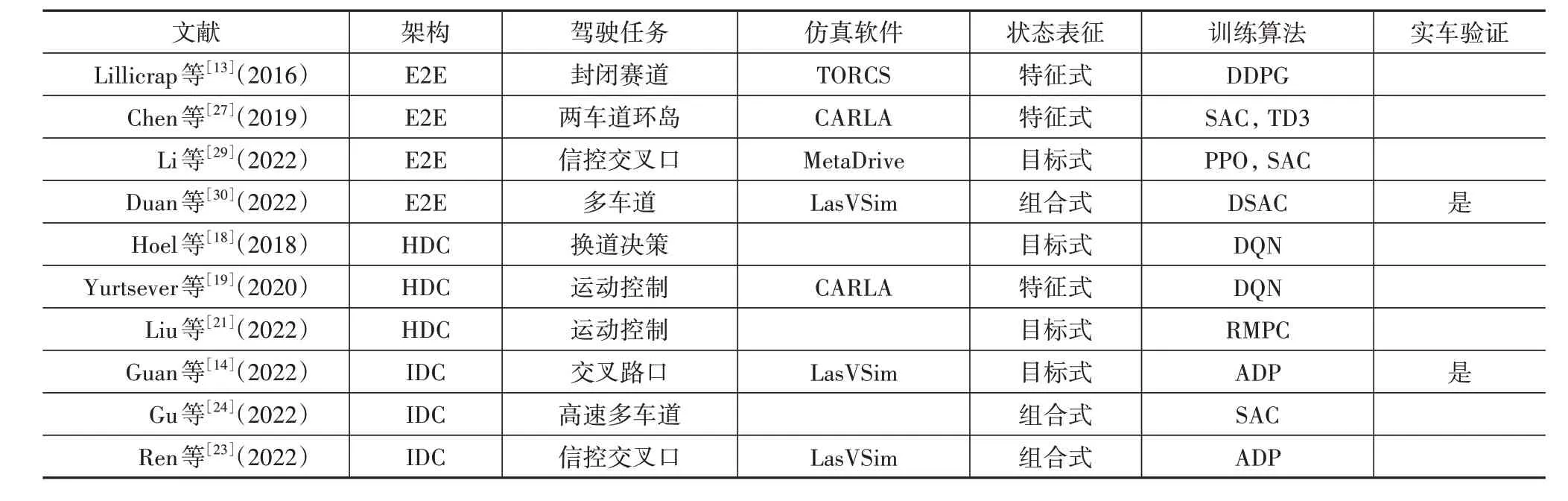
表3 类脑决控典型案例
早期的类脑自动驾驶主要采用端到端架构,直接利用深度神经网络实现从感知结果到控制命令的映射。例如:2016 年Lillicrap 等提出了DDPG 算法,利用TORCS 仿真平台实现了封闭道路的车道保持功能[13];2019 年Chen 等针对城市道路中的环岛场景,使用TD3 和SAC 等算法,使用CARLA 仿真平台实现了密集交通流工况的安全高效通行[27];2022 年Li 等设计了MetaDrive 仿真平台,可以自动生成随机拓扑结构的道路场景,使用PPO 和SAC 算法在大规模场景库中进行训练,提升了策略泛化能力[29];2022 年Duan 等将DSAC 算法应用于高速多车道场景,通过引入值分布有效抑制了值函数的过估计难题,超越了SAC 的性能表现,并进行了实车试验验证[30]。
类脑学习与HDC 架构的结合主要用于典型功能模块的开发,如驾驶行为选择、车辆运动控制等。2018年Hoel等设计了车道保持、左换道、右换道3种车辆行为状态,使用DQN 算法实现了高速多车道场景的换道决策[18]。2020 年Yurtsever 等以转向盘转角和纵向加速度构造离散的动作空间,使用DQN 算法在CARLA 仿真平台实现了对于给定轨迹的跟踪控制[19]。2022 年Liu 等针对连续动作空间的预测型车辆横纵向运动控制任务,设计了循环模型预测控制算法,可根据计算资源等约束条件动态调整预测时域的长度,离线训练得到的控制策略与经典的在线规划型MPC控制器的轨迹跟踪性能相当[21]。
与HDC 架构相比,IDC 架构更适合与类脑学习算法结合。作为主导模块,动态跟踪优选模块集成了选择最优路径和输出控制命令的任务,通过求解统一的约束型OCP 整合决策与控制功能。2022 年Guan 等依托IDC 架构设计了一种混合策略梯度算法,在交叉口场景完成了直行、右转和无保护左转等驾驶任务[14]。2022年Gu等采用IDC 架构,同时引入模型提升SAC 算法的训练效率,在高速公路场景实现了安全、高效、经济的驾驶表现[24]。2022年Ren等进一步考虑机动车、行人与骑行人混杂的交通流,将信号灯、限速、与不同交通参与者的安全距离等规则与经验作为先验知识融入IDC 架构,实现了信控交叉路口场景混杂交通流中的安全通行[23]。
6 总结与展望
针对高级别自动驾驶汽车的决策与控制功能设计,类脑学习提供了一种自主探索、试错迭代的策略求解机制,可在全状态空间上近似求解从环境状态到执行动作的最优映射,即最优策略。本文聚焦于类脑学习型自动驾驶决控系统开发,从系统框架、仿真软件、状态表征、评价指标和训练算法5个方面系统性探讨了它的关键技术及发展趋势。简要总结如下。
(1)面向落地应用的自动驾驶决策控制架构分为分层式(HDC)和集成式(IDC)两类。HDC 架构的模块解耦更细,便于工程化开发时的任务分工和组织协调,但不可避免地存在模块之间信息丢失的风险,且各模块具有自己的优化目标,不利于提升整体智能性。IDC 架构将自动驾驶决控任务进行了重塑,将二者整合为一个统一的约束型最优控制问题,仅包含一个性能指标、一个动力学系统,求解一个决控策略。这一主导性模块的存在使得IDC 架构更加适合类脑学习算法的应用,通过车云协同训练增强对稀有场景的适应性,以获得更高的驾驶智能性。特别值得指出的是,IDC 架构的策略函数和评价函数恰好对应于强化学习的Actor-Critic 训练架构,二者具有良好的适配度。
(2)从动态环境的状态信息提取定维表征向量是应用类脑学习技术的必然要求,也是提升策略训练效率与性能表现的关键之处。状态表征方法可分为目标式、特征式和组合式。目标式表征因物理意义明确、易迁移等优势被广泛采用,但依赖于人工设计目标识别模块以及目标集合中各元素的排列顺序;特征式表征直接从感知信息中提取表征,结构简单清晰,但仍面临训练效率低、可解释性差、难以向真实场景迁移等困境;组合式设计对于识别后的目标进行编码聚合得到表征,既可摆脱对目标排序规则的依赖,又可保障训练效率。状态表征的下一步发展趋势主要在于更好地融合先验知识和深度学习的特征提取能力,实现状态表征的高效提取,以及结合对抗学习、因果挖掘等手段提升泛化能力。
(3)强化学习是类脑学习系统的核心算法,驱动策略更新的信息来源于环境反馈的奖励信号,因此策略性能取决于以评价指标为基础的奖励函数设计。其发展趋势是围绕安全、合规、舒适、通畅和经济的五维度视角开展指标设计,重点建立客观性的量化评价模型,使用统一尺度评测各类行驶工况的驾驶性能表现。类脑决控系统以深度神经网络为策略载体,以强化学习为训练手段,目前已经能够实现多车道、交叉路口、环岛、进出匝道等诸多工况的自动驾驶功能,正逐步迈向真实场景的实车测试验证。下一步发展趋势主要在于如何提升策略训练效率与稳定性、融合模型与数据驱动策略更新。
(4)当前类脑学习型决控系统的实车应用仍面临安全性和泛化性等方面的诸多挑战。安全性是现阶段制约类脑决控实车应用的主要原因,典型的强化学习方法面对安全约束,均难以实现零约束违反。安全强化学习方法显式考虑安全约束,在保证约束满足的前提下最大化期望累积回报,能够从理论上保证策略的安全性,是目前值得攻关的重点子领域。对泛化性能的要求体现在面对不同场景以及扰动时,类脑学习策略应当能够保持合理的决控智能水平,而当前算法表现通常不够理想。采用对抗学习等技术并进行大规模多场景训练,有望增强类脑学习的泛化性能,实现更可靠的自动驾驶决控。总体而言,下一步发展趋势在于如何减少状态约束违反、保障在线安全探索以及增强环境泛化能力,同时通过车云协同闭环训练实现数据驱动的闭环进化,逐步增强自动驾驶汽车的智能性,破解稀有交通场景的行车安全困局。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
科学24小时(2021年1期)2020-12-24
学生天地(2020年5期)2020-08-25
中国惯性技术学报(2020年2期)2020-07-24
电子测试(2018年10期)2018-06-26
电信科学(2017年6期)2017-07-01
中小学信息技术教育(2017年6期)2017-06-23
汽车博览(2016年9期)2016-10-18
电测与仪表(2015年22期)2015-04-09
