
改进Res2Net和注意力机制的高光谱图像分类
2023-10-10 10:38王振宇
计算机工程与应用 2023年19期
王 燕,王振宇
兰州理工大学 计算机与通信学院,兰州 730050
随着高光谱成像技术的快速发展,成像光谱仪可以绘制出数百个连续、精细的光谱波段的地表图像。与灰度图像和RGB 图像不同,高光谱图像(hyperspectral image,HSⅠ)包含数百个通道,可以提供极为丰富的通道信息和详细的空间纹理。高光谱成像技术现已成为遥感应用的有效工具,通过对HSⅠ的多维信息进行识别学习以实现对应的研究目标,在林业[1]、环境监测[2]、图像分类[3]、地质学[4]、海洋勘探[5]、精准农业[6]等领域得到广泛应用。基于HSⅠ的图像分类(hyperspectral image classification,HSⅠC)在遥感应用及研究领域受到关注。
虽然HSⅠ具有众多优势,但是针对HSⅠC 的研究仍然存在一些有待解决的难题,其成像原理导致的先天性问题给研究者带来了挑战。如HSⅠ的高维性导致图像相邻通道间存在高相关性,数据冗余度高;HSⅠ包含大量非线性信息;混合像元引起的“同谱异物”和“同物异谱”现象;以及较少的训练样本会造成维数灾难。
在早期,关于HSⅠC 的研究主要集中在HSⅠ的特征提取上。常用的方法为流形学习,该方法通过将高维空间中的原始数据映射到潜在的低维空间来减少HSⅠ通道维度的数量,主要有主成分分析(principal component analysis,PCA)、局部线性嵌入(locally linear embedding,LLE)[7]、拉普拉斯特征映射(Laplacian eigenmaps,Les)[8]和等距特征映射(ⅠSOMAP)。上述方法虽然提高了分类性能,但作为浅层模型,无法通过学习HSⅠ深层的抽象特征来提高最终的分类精度[9]。
近年来,深度学习算法在图像分类、目标检测、自然语言处理等计算机视觉领域取得了突破。基于深度学习的HSⅠC研究重点一开始主要集中在通道维度特征的深度表示和复杂注意力机制的使用上。采用堆叠自编码器(stacked auto encoder,SAE)[10]和深度置信网络(deep belief network,DBN)[11]等方法提取通道维度特征。空间维度特征的利用则是通过将一维空间向量与通道向量进行拼接并将其输入到网络中提取深度特征来实现的。不像传统机器学习方法,卷积神经网络(convolutional neural network,CNN)可通过一系列层次结构自动提取有效的高维背景特征解决HSⅠC遇到的空间-通道特征学习问题。在大量成果中,注意力机制通常以独立模块的形式嵌入到模型中,通过加权波段、像素或通道来细化特征图,从而提升模型最终性能。此外,还可通过在残差网络(residual network,ResNet)中嵌入通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)感知图像的空间和通道信息,以提高分类性能[12]。
目前,使用注意力机制和ResNet 的CNN 在图像领域中取得了非常有前景的成果。Men 等人[13]提出了一种基于CNN的高光谱信息识别网络(Res-CBAM),该模型结合ResNet和卷积注意力模块(CBAM),提高了高光谱对稻米品质跟踪的检测性能。Zhang等人[14]提出了一种基于可变形残差卷积的轻量级通道-空间注意力融合(SSA-DCR)。该模型采用端到端顺序提取深度特征的方法,分别利用3D-CNN 和2D-CNN 提取HSⅠ的浅层和深层空间特征。Wang等人[15]提出了一种深度可分离全卷积残差网络(DFRes)用于HSⅠC任务,该模型利用3DCNN、ResNet 和深度可分离卷积(depthwise separable convolution,DSC)组合提取HSⅠ通道-空间特征,缓解了梯度消失问题,同时得益于DSC的结构特性,极大减少了该分类模型的参数量。Li 等人[16]提出了一种空间注意力引导的残差注意网络(SpaAG-RAN),该网络包括空间注意力模块、通道注意力模块和通道空间特征融合模块。空间注意力模块以通道相似性为基础,通过一种新型激活函数捕获与中心像素相同类别的空间像素;通道注意力模块功能是选择有利于通道特征表示的波段;最终利用通道空间特征融合模块提取综合特征。Deng等人[17]通过对双通道残差块进行多次叠加,构造了一种轻量级的CNN。该分类模型的设计结合了双通道特征提取和残差连接两种结构。在构建主干网络时,设计了跨通道交互的多尺度通道注意力模块以进一步增强提取的特征。然而,大量堆叠使用卷积层会导致模型体量过于庞大,同时受HSⅠ基础数据冗余、空间分辨率不足和训练样本有限等因素的制约,模型的分类性能仍然受到负面影响。
为了解决以上问题,本文提出了一种名为多尺度可分离残差注意力网络(multiscale separable residual attention network,MSRAN)的分类模型。MSRAN通过引入三维空洞卷积,在Res2Net 结构内部使用多尺度DSC和空间可分离卷积(spatial separable con-volution,SSC)并嵌入SAM 和CAM 结构,同时舍弃CNN 尾部使用的全连接层(fully connected,FC),在保证模型特征提取能力的前提下优化模型结构,从而严格控制了参数规模。经过实验论证,MSRAN使用少量的训练样本可以快速准确地对HSⅠ进行分类。
1 本文方法
1.1 MSRAN模型
本文提出的MSRAN 首先使用PCA 对原始输入图像进行通道维度的压缩,然后以目标像素为中心,将数据块输入三维空洞卷积层和SAM,接着将所得特征映射继续输入两组空间-深度可分离残差结构(SSDSRes2Net)串联CAM 结构块中,最后将输出的特征映射通过全局平均池化(global average pooling,GAP)转换成一维向量后直接输入Softmax分类器得到预测结果。
MSRAN选择使用交叉熵作为损失函数,添加L2正则化和dropout 避免网络模型出现过拟合,同时使用遵循动量与自适应梯度思想的Adam 优化器加速模型收敛。MSRAN的整体网络框架如图1所示。

图1 多尺度可分离残差注意力模型Fig.1 Multiscale separable residual attention network(MSRAN)model
原始Ⅰndian Pines 图像大小为145×145×200,其中145为空间尺寸,200为通道数量。由于HSⅠ具有数据冗余性,首先使用PCA将原始图像的通道数量从200压缩到16 以降低通道之间的相关性,得到一个145×145×16的图像立方体。然后将图像立方体分割成15×15×16的数据块输入膨胀系数为(2,2,1)的空洞3D-CNN中提取浅层通道和空间特征。由于在空洞3D-CNN 中设置了零填充,因此输入和输出特征映射的空间尺寸保持一致。输入映射通过窗口尺寸为3 的最大池化操作后使用SAM 添加空间权重信息,得到一组13×13×256 的输出映射。将输出映射继续输入SSDS-Res2Net 结构中,经过结构内部多分支多尺度卷积特征提取后,使用CAM 赋予特征映射特定的通道权重,经过两次上述特征提取,得到一组9×9×256 的输出映射,最后使用GAP将该特征映射压缩成1×1×256 的特征向量后输入Softmax激活分类。
1.2 SSDS-Res2Net结构
Res2Net是由Gao等人[18]首次提出的一种新型多尺度骨干网络体系结构。当卷积网络层数足够深时,Res2Net继承了ResNet的优点,并拥有更好的泛化能力和鲁棒性。
具体地,Res2Net选择将ResNet内部卷积核替换为更小的卷积核组,同时以一种分层的类残差形式将其进行连接。经过逐点卷积后,将特征映射均匀地划分为s个特征映射子集xi,其中i∈{1,2,…,s}。与输入特征数据相比,每个特征映射子集xi具有相同的空间大小和1/s的通道数量。除x1以外,每个xi都有一个对应的内部卷积核,特性映射子集xi经过对应卷积计算后被添加到下一组残差连接中,作为其输入数据。所以,Res2Net中的输出数据表示为:
其中,xi表示特征映射子集,φi()表示卷积操作,yi表示输出数据。
本文设计了一种以Res2Net 为基础的多分支、多尺度残差结构SSDS-Res2Net,结构如图2所示。内部使用两组堆叠的SSC对细分后的特征映射子集xi进行下采样,并使用DSC提取xi的特征信息,同时在残差连接中设置最大池化层保证前后端能够顺利进行残差计算。所以,SSDS-Res2Net中的输出数据表示为:

图2 多空间-深度可分离残差结构Fig.2 SSDS-Res2Net structure
其中,xi表示特征映射子集,δ()表示最大池化,ηi()表示SSC操作,ζi()表示DSC操作,yi表示输出数据。
1.3 SAM和CAM机制
特殊情况下,同一目标像素在不同通道的响应可能不同,所以不同通道的特征表达能力是不同的。此外,提取的多维特征数据在不同空间位置也可能拥有不同的语义信息。如果能够充分利用这些先验信息,将提高模型对特征信息的学习能力。使用CAM可以使网络聚焦于更具鉴别性的通道上,同时抑制不必要的通道信息,同样,SAM可以使网络更加关注空间纹理信息。
因此,本文设计了新的SAM和CAM两种注意力模块来实现这一目标,具体结构如图3所示。在SAM中,使用逐点卷积将池化层输出的特征映射通道从C 压缩为1,接着对两组特征映射采取级联操作,最后经过一层3×3 卷积得到该组特征映射的空间权重。在CAM 中,使用一维卷积分别校准GAP 和全局最大池化(global max pooling,GMP)输出的一维特征映射,同样采取级联操作将两组特征映射进行融合,然后通过具有MLP功能的两层FC 层进行信息重组,最后经过一层一维卷积得到该组特征映射的通道权重。
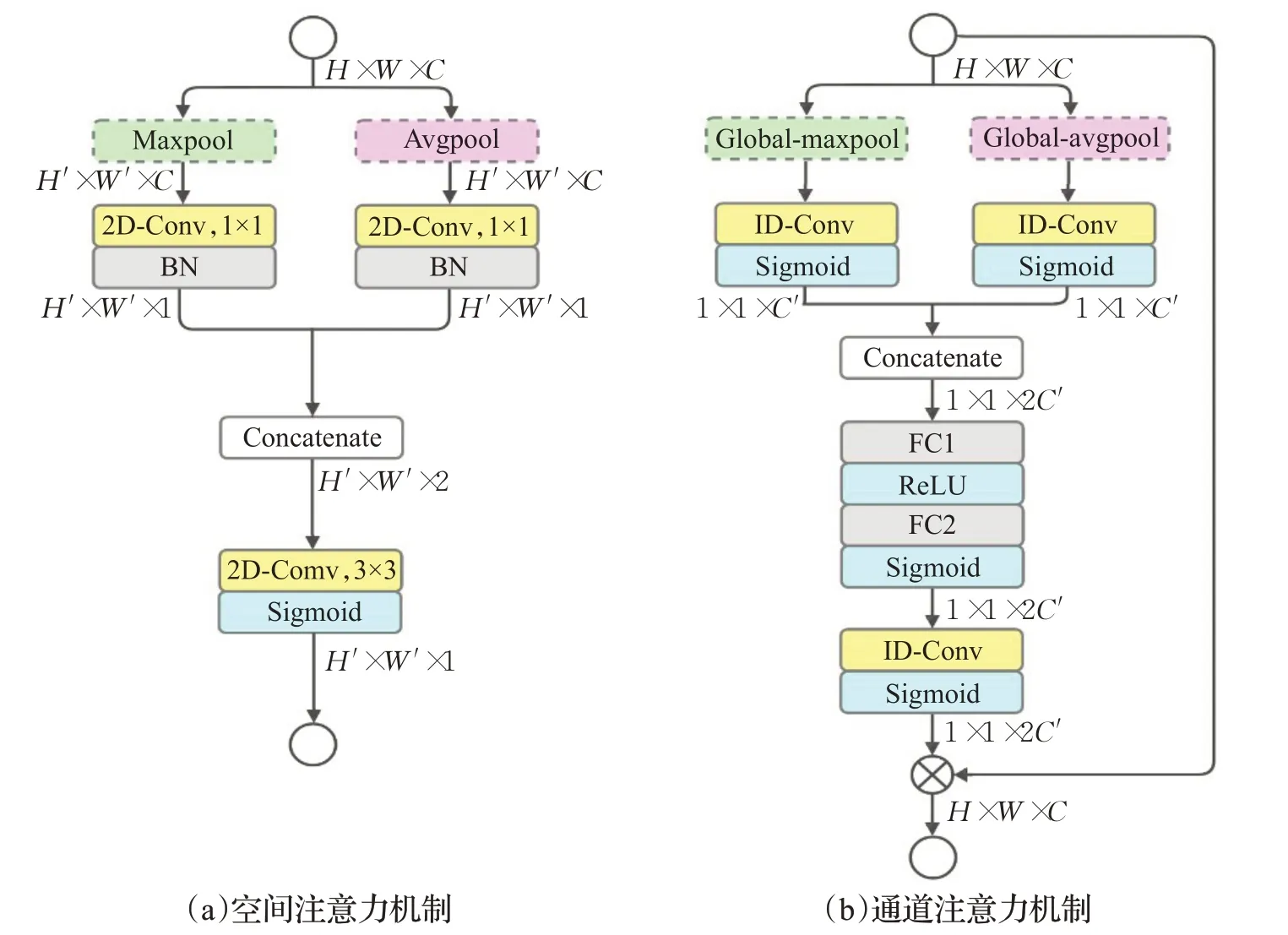
图3 注意力机制模块Fig.3 Attention mechanism module
2 实验与分析
2.1 硬件环境
本文实验在Ⅰntel®Xeon Silver 4116 @2.10 GHz,NVⅠDⅠA Tesla T4,128 GB内存硬件支持下运行。基于Windows10系统,使用Python3.7.6的Tensorflow2.1框架实现。
2.2 数据与评价标准
实验部分使用两种常见的HSⅠ数据集:Ⅰndian Pines(ⅠP)和Pavia University(PU)。ⅠP数据集由AVⅠRⅠS拍摄于美国印第安纳州西北部的农业试验场。空间尺寸为145×145,空间分辨率为17 m/pixel,拥有400~2 500 nm的200 个通道波段,并去除了24 个噪声波段。可分类像元10 249个,包含树林、玉米、燕麦、大豆等16种地物类别。由于数据量不足以及地物间的边界不清晰,因此导致ⅠP 数据集中的地物边界无法得到精确映射。PU 数据集是使用光谱成像仪拍摄于意大利帕维亚大学,空间尺寸为610×340,空间分辨率为1.3 m/pixel,拥有430~860 nm 的103 个通道波段,可分类像元42 776个,包含树林、砖块、砾石等9种地物类别。由于易散射的物体空间分辨率高,如树林和人行道,给基于CNN的特征学习带来了很大的困难。两种HSⅠ数据集中具体地物类别像素的数量和训练数据的划分如表1 和表2所示。

表1 ⅠP每种地物类别的像素数量Table 1 Number of pixels per feature category in ⅠP

表2 PU每种地物类别的像素数量Table 2 Number of pixels per feature category in PU
评价标准分别使用整体分类精度(overall accuracy,OA)、平均分类精度(average accuracy,AA)和Kappa(KA)系数来判断模型的分类性能。
OA能够表示模型正确分类的像素数占总像素的百分比,其计算公式表示为:
其中,IM表示正确分类的像素,IN表示像素总量。
AA是将每一种正确分类的像素与该像素总量之间的比值求和,再取其平均值,其计算公式表示为:
其中,IMk表示第k种地物标签被正确分类的个数,INk表示第k种地物标签的总量,K表示标签类别个数。
KA 用来检验模型的分类结果和正确结果是否一致,其计算公式表示为:
其中,IM表示正确分类的像素,IN表示像素总量,INk表示第k种地物标签的总量,IPk表示被模型分类成第k种标签的个数,K表示标签类别个数。
2.3 参数对比与选定
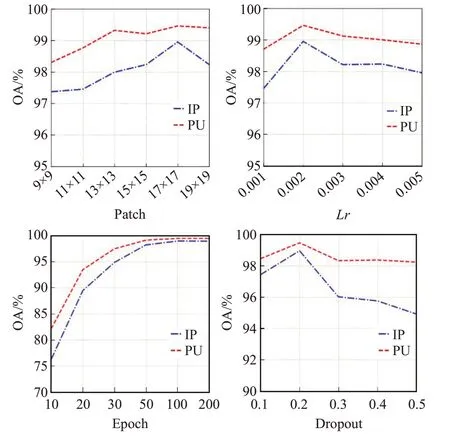
MSRAN 中不同超参数的选择对最终分类精度的影响如图4 所示。通过实验分析,当邻域尺寸patch,学习率lr,训练轮数epoch 和随机失活率dropout 分别设置为17、0.002、100和0.2时,模型分类精度取得最高值。
2.4 小样本条件测试
训练样本不足是目前HSⅠC 任务面临的主要困难之一。为了验证MSRAN 在小样本条件下依然具有良好的特征学习能力,本文使用LSTM[19]、DPyResNet[20]、ATT-CapsNet[21]、JSSAN[22]和MSRAN进行对比。从两种数据集中随机选定一定数量的标签数据作为训练集。具体地,ⅠP 数据集随机选定1%、2%、4%和5%的标签数据作为训练集;PU数据集随机选定1%、2%、3%和4.5%的标签数据作为训练集。如图5 所示,MSRAN 在小样本条件下取得了最高的分类精度。

图5 不同模型在小样本条件下的分类精度Fig.5 Classification accuracy of different models in small sample condition
2.5 有效性和收敛性
为了验证MSRAN每个模块的合理性,对设置不同模块的有效性进行实验论证,对比结果如表3 和表4 所示。以ⅠP数据集为例,可以看出当只使用Res2Net而不添加任何注意力模块时,参数数量为497 988,OA 为96.54%;当分别嵌入SAM和CAM注意力模块时,OA分别提升了0.49个百分点和0.58个百分点。当只使用本文提出的SSDS-Res2Net而不添加任何注意力模块时,相较于不使用注意力机制的Res2Net,参数量减少了88 832,OA 提升了0.89 个百分点;最终,在SSDS-Res2Net 中同时嵌入SAM 和CAM 两组注意力模块时,参数数量为574 681,此时OA取得最高值。在PU数据集中,实验结果类似。

表3 MSRAN在ⅠP中的有效性精度对比Table 3 Validity accuracy comparison in ⅠP of MSRAN

表4 MSRAN在PU中的有效性精度对比Table 4 Validity accuracy comparison in PU of MSRAN
为了验证模型的收敛性,使用LSTM、DpyResNet、ATT-CapsNet、JSSAN和MSRAN进行实验对比。如图6所示,LSTM 和ATT-CapsNet 在前50 个epoch 精度提升较快,但当epoch达到100时还未完全收敛;而DPyResNet和JSSAN在50至100个epoch精度提升较快,但精度均未达到饱和。MSRAN 在前20 个epoch 精度提升明显,在100个epoch时精度达到饱和,模型完全收敛。

图6 不同模型达到饱和分类精度所需要的训练轮数Fig.6 Number of training epochs required by different models to achieve saturation classification accuracy
2.6 实验分析
选择上述4种高光谱图像分类模型与MSRAN进行对比。除训练数据集划分固定以外,所有模型的超参数保持原文献不变,实验设置为运行10 次,并取其平均值。5种模型的分类精度和参数数量如表5所示。

表5 5种分类模型的分类精度和参数量Table 5 Accuracy and params of five classification models
在ⅠP 数据集中,MSRAN 和其他4 种分类模型中性能最好的JSSAN相比,OA、AA和KA分别提升了1.59、1.54个百分点和1.71;而在PU数据集中,相较于JSSAN,MSRAN 取得的OA、AA 和KA 分别提升了0.57、0.60 个百分点和0.60。
图7和图8分别是5种HSⅠC模型在ⅠP和PU上取得的分类结果图。显然,LSTM在训练样本较少的情况下出现了明显的误差,与真实地物图差距较大;DpyResNet、ATT-CapsNet 和JSSAN 的分类精度高于LSTF,但依然在地物边缘区域存在较多的误差,同时有较多的噪声斑点。MSRAN 利用三维空洞卷积在保证感受野的情况下对HSⅠ初始特征进行了提取,得益于SSDS-Res2Net模块中更为细分的多尺度卷积核和类残差结构以及引入空间-通道注意力机制,MSRAN可以对特征映射中更深层和抽象的特征进行感知,从而在训练样本有限的情况下保证了最终的分类精度。

图8 5种分类模型获得的PU预测图与真实图的对比Fig.8 Comparison between predicted and truth maps of PU obtained by five classification models
3 结束语
本文提出了一种改进Res2Net 和注意力机制的高光谱图像分类模型。该模型具有参数量少,收敛速度快,对样本数据依赖性低的特点。得益于SSDS-Res2Net多尺度结构可以在细粒级学习更多感受野的细节特征,模型在小样本条件下依然可以取得不错的分类精度。此外,通过在模型中嵌入SAM和CAM关注特定的频谱通道和空间纹理等上下文信息,进一步提升了模型的分类性能。然而该模型在对面积较小的地物进行分类时,依然会存在明显的误差,这将是今后工作中优化的重点。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
河南科技(2015年8期)2015-03-11
