
深层特征聚合引导的轻量级显著性目标检测
2023-10-10 10:38:30李俊文张红英
计算机工程与应用 2023年19期
李俊文,张红英,韩 宾
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.西南科技大学 特殊环境机器人技术四川省重点实验室,四川 绵阳 621010
在深度学习还未广泛应用之前,早期的显著性目标检测(salient object detection,SOD)方法主要是依靠手工制作的特征信息对像素进行搜索并检测显著对象。这种传统方法不仅费时又费力,而且手工制作的特征主要是低层特征信息,缺乏高层语义信息的表征能力,这会导致对于复杂场景下的图像很难保持高精度的预测。近年来,卷积神经网络(convolutional neural network,CNN)在计算机视觉中取得了巨大的成功,特别是全卷积神经网络(fully convolutional network,FCN)[1]的出现,为SOD 研究开辟了新的道路。目前基于深度学习的SOD 研究相比于传统方法已经取得了巨大的进步,可以获得更为精确的预测结果图。SOD 作为一种有效的图像预处理技术,在计算机视觉中得到了广泛的应用场景,例如图像分割、图像理解、视觉跟踪[2]、物体检测[3]等。
自FCN和U-Net[4]提出以来,利用编码器-解码器的结构将特征信息恢复到原始输入图像大小,实现了端到端的操作,并且网络中逐次将低层特征信息和高层特征信息进行相加或拼接的特征融合操作,已被证明了其对于最终性能有很大的帮助。现有的研究大都受此启发,Feng 等人[5]引入全局感知模块来获得丰富的上下文信息,并将低层信息和高层信息进行有效融合来细化预测图。Qin等人[6]受U-Net的启发,构造了一种新残差模块RSU(residual U-blocks)来获得多尺度信息。Zhao 等人[7]利用渐进融合方式将全局信息和局部信息进行互补,能够更加有效地定位显著目标。Liu等人[8]在特征金字塔(feature pyramid network,FPN)[9]结构的基础上,引入了一个全局池化模块来获得更加丰富的语义信息,并设计了一种新的池化模块来更好地融合各层特征。Pang等人[10]将编码阶段相邻特征全都进行交互融合,以获得更丰富的特征信息,并将融合后的特征进行残差优化,来适应目标尺度变换。Wei 等人[11]提出一种级联反馈解码器,来迭代细化特征融合后的信息,以获得更精细的预测图。Chen等人[12]在U-Net的基础上,提出一种上下文感知特征信息聚合模块,能够有效地将全局上下文信息、低层细节信息和高层语义信息进行融合。Zhang 等人[13]设计了一个自动搜索框架,使网络能够获得更棒的多尺度特征融合。
上述方法都获得了相当不错的检测精度,但由于其繁重的特征提取网络以及复杂的解码结构,不可避免地增大了参数量和计算成本,这种繁重的网络很明显不适用于实时以及资源有限的应用,如机器人应用、用户界面优化和自动驾驶等。随着深度学习的发展逐渐成熟,落地应用的需求也逐渐增加,网络效率开始成为最近的研究热点。Liu 等人[14]模仿灵长类动物的视觉层次结构,提出了层次视觉感知网络来进行更好的多尺度学习。Zhou 等人[15]提出一种交互式双流解码器来探索网络中的各种信息,并学习特征之间的相关性来达到更好的预测结果。Wu 等人[16]只利用高层特征相互细化,舍弃编码部分的低层特征来获得更高的效率。Liu等人[17]提出一种基于立体注意力机制的轻量级网络用于SOD任务。以上研究虽然对网络效率有了较大的提升,但相比之下网络性能却逊色许多。为此,本文对性能与效率进行综合考虑,旨在设计一种能够在精度、速度和参数量之间达到平衡的网络模型。
此外,显著性目标和背景之间的边界问题一直是SOD 任务的一大难点,近年来许多研究也正在关注该点。目前对于边界的研究方法大致可以分为两种:一种是对于训练损失函数的改进,如Qin 等人[18]提出一种可用于边界感知的混合损失函数,主要由BCE、ⅠOU 和SSⅠM 组成。Feng等人[5]采用一种边界增强损失来对显著性目标进行更好的边界分割。另一种是设计额外的边界细化模块,如Zhao等人[7]使用轮廓信息来单独作为一个监督分支,来提升低层网络对于边界信息的感知能力。Wang等人[19]构建了一个残差分支来进行边缘的预测。以上的研究都对最终性能取得一定的优化,同时也证明了边缘信息的重要性。但边界损失函数未考虑到显著性目标的空间相关性,边缘细化模块仅利用边缘信息来细化预测图,效果通常有限。
因此,综合上述分析,为了在精度、速度和参数量之间来达到平衡,本文提出一种基于深层特征聚合和边界优化的轻量级显著性目标检测模型。该方法首先针对当前轻量级特征提取网络MobileNetV3[20]存在网络深度较浅、结构简单、提取信息不足的问题,构造一种回环特征复用模块(loop feature reuse module,LFRM)来增强网络高层语义表达,并减少特征信息的流失;其次,对于不同层级存在的信息差异,提出一种跨层交互聚合模块(cross-layer interactive aggregation module,CⅠAM)来降低特征融合时噪声信息的干扰,可以更好地利用各个层级的有效信息;此外,对于边缘轮廓信息,本文首先对网络浅层进行轮廓监督训练,来增强浅层网络对边缘信息的关注度,其次构建了一种边缘细化模块(edge refinement module,ERM)来改善融合后的特征图,并且考虑到网络整体的空间相关性,使用一种渐进式自引导损失(progressive self-guided loss,PSG loss)[21]作为辅助训练监督来逐渐指导网络生成更完整的显著对象。如图1 展示了本文方法和当前最先进方法的性能与效率。本文所提出的模型参数只有3.48×106,对于尺寸大小为352×352的图片,在单个1080Ti显卡上运行速度能达到108 FPS,并且能够达到与当前最先进SOD方法相当,甚至更好的性能。

图1 性能与效率对比Fig.1 Performance vs.efficiency
1 本文算法结构
如图2 所示,本文将特征提取网络分为五个阶段E1、E2、E3、E4、E5,先将E3、E4、E5传入回环特征复用模块(LFRM)中来充分增强高级特征表达,其结果一边与浅层特征E1来进行有效融合,并通过显著目标轮廓监督训练来获得边缘信息。一边输入到跨层交互聚合模块(CⅠAM)中与E2有效融合空间信息和语义信息,并降低噪声干扰。最后将边缘信息和CⅠAM 的输出一起输入到边界细化模块(ERM)来得到更为精确的预测图。为了优化网络训练,对LFRM和CⅠAM的输出额外使用两个分支来进行监督训练。此外,引入PSG loss作为辅助损失来逐步引导各训练阶段,来获得更完整的预测图。接下来将详细介绍各个部分。
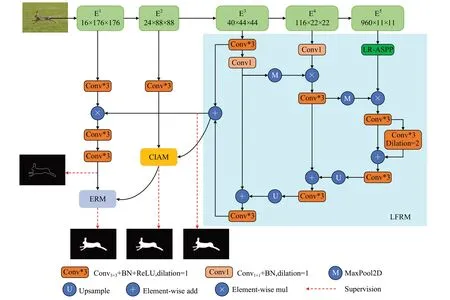
图2 整体算法结构框图Fig.2 Overall algorithm structure block diagram
1.1 回环特征复用模块
对于SOD这种像素级任务来说,感受野不够,会导致上下文信息的缺失,从而影响网络对于多尺度目标的表征能力。为此,许多研究工作都会选择在特征提取网络顶层后添加一个全局信息模块来获得更大的感受野以及更丰富的全局上下文信息。而对于轻量级特征提取网络而言,由于其网络结构相比之下较浅、较简单,会导致不仅顶层实际感受野过小,而且深层的特征信息提取有限,即使在网络顶层再加上一个全局信息提取模块,也很难充分使网络理解上下文信息。此外,特征提取网络各个阶段信息存在差异,如感受野不同。直接让各阶段的特征进行跨层融合,会由于其差异性而带来许多干扰信息,其有限的特征信息和诸多干扰信息是导致最终性能不理想的关键之一。为了解决上述问题,本文提出一种回环特征复用模块。它主要有两种作用:一是聚合相邻输入特征,因为相邻特征具有一定的相似性,而相似特征往往就是需要的有用信息。通过有效聚合,可以增强有用信息的特征表示,并降低干扰信息。二是进行特征细化,与其他方法不同,不将聚合后的特征直接进行自顶向上的操作,而是先重用聚合特征进行进一步的特征提取,来获得更为有效的高级语义信息。此外,在后续的特征融合中,由于之前进行的相邻特征聚合和重用特征提取的操作,用于融合的两个特征图基本都包含了共同的有用信息,故融合后的特征图拥有更强的表征能力,而直接与骨干网络的特征图进行融合,会因为差异过大,干扰信息较多,而造成融合后的特征图存在诸多问题。同时考虑到参数和计算量,降低了通道数,但通道数的减少会导致一些重要信息的丢失,为此本文和大多数研究一样,在网络顶层采用全局信息模块来保留有效信息,这里采用的是轻量级的LR-ASPP。
本文提出的回环特征复用策略并没有用太过复杂的模块,保持着网络的轻量化。具体来说,对于编码网络阶段E3,输入两个3×3 卷积层,而后使用最大池化maxpool来降低特征图分辨率,然后与E4进行乘法聚合操作来获取相同的有用特征信息,减少干扰信息。随后经过一个3×3卷积层来平滑聚合后的特征,再进行最大池化maxpool与经过全局上下文模块的C5进行乘法聚合,并使用两个3×3卷积层进行平滑操作。随后使用类似于FPN的结构将这些特征进行逐层细化融合,同时从连续高级聚合特征中生成一个初始粗糙显著预测图,与标准FPN结构相比,其预测图对显著对象的定位更加完整,后续可以更好地帮助CⅠAM进行空间信息与语义信息的融合以及ERM进行显著对象边缘轮廓信息的提取。CⅠAM 和ERM 将在后续章节进行详细介绍。LFRM的更多的细节如图2所示。
总体来说,LFRM通过像素相乘的方式来提取相邻深层特征之间的共同信息,并以下采样的方式再次处理这些高级特征,可以进一步增强高级特征信息的提取;随后将各相邻层融合后的特征信息通过像素相加和上采样的方式来进行聚合,以进一步细化高级特征。使用聚合后重用特征来代替骨干网络的特征来进行融合,这种设计可以在减少各阶段特征信息的跨层差异,有利于在各层特征融合时获得更加有效的多尺度信息,并减少全局上下文信息的丢失,增强特征信息表征能力。由于大多数操作都在下采样特征图上,且减少了一定的通道数量,该设计的计算开销很小,跟常规FPN 结构加上LR-ASPP 相比,使用更小的计算量获得更好的性能,详细数据在下面实验部分给出。
1.2 跨层交互聚合模块
浅层特征包含着更具体的空间结构信息,但同时也会有许多像背景这一类的噪声存在;深层特征包含更丰富的语义信息,但带来了空间上的粗略分辨率,这都会对后续特征融合造成一定的混叠影响。因此,本文设计了一种跨层交叉聚合模块来更加有效地融合各阶段的特征信息,具体结构如图3所示。首先为了减少各层之间存在的差异,先使用更加有效的乘法运算来分别增强各阶段的显著信息,同时抑制干扰信息。为了乘法运算的一致性,先将浅层特征输入到一个下采样两倍的3×3卷积层中,再与高层特征信息相乘,随后经过一个普通3×3 卷积层进行平滑,以此来增强浅层特征的显著对象。另一边将高层特征上采样两倍后再与低层特征相乘,随后同样经过一个普通3×3 卷积层进行平滑,以此来弥补高层特征丢失的一些与显著对象相关的细节信息。之后将处理后两个特征逐元素相加得到融合特征图,再把它依次经过一个全局平均池化层、1×1 卷积和softmax函数,来生成一个权重向量,然后把该权重向量与融合特征图相乘,再经过一个3×3 卷积,得到最后的加权特征图。上述过程可以描述为:
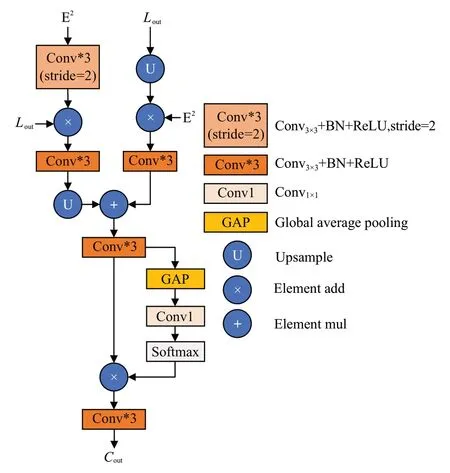
图3 跨层交互聚合模块Fig.3 Cross-layer interactive aggregation module
其中,Down3×3和Conv3×3分别表示下采样两倍的3×3卷积层和普通3×3 卷积层,都包含一个3×3 卷积、batch normalization 和ReLU 激活函数,upsample 是通过双线性插值的上采样操作,⊙和⊕分别表示逐元素相乘和逐元素相加,GAP是全局平均池化操作,δ表示softmax激活函数。总体来说,依靠上节LFRM所获得的初始显著目标预测图,CⅠAM首先将其与浅层特征信息通过像素相乘的方式来突出彼此的共同特征,由于初始显著目标预测图已经具备较为完整的显著对象,故进一步增强其共同特征可以减少浅层特征所包含的干扰信息。同时两个阶段的特征信息通过像素相乘的方式可以减少彼此之间的差异,后续再通过像素相加的方式来进行融合,增强显著特征表达能力,再对融合特征图进行全局平均池化的加权操作,让显著特征元素得到更大的权重,充分实现让最后的输出特征图保留更多有效显著特征信息。
1.3 边界优化
1.3.1 边缘细化模块
之前的研究是将浅层特征直接进行边缘轮廓监督训练,但由于其有效的感受野,浅层特征对所有目标几乎是一视同仁的,而这里只想要网络关注需要的显著性对象。为此,本文先将浅层特征与具有高级语义信息的回环特征复用模块的输出特征相乘,再经过两个3×3卷积层,以此来突出显著目标的空间信息,更好地进行边缘轮廓监督训练,具体细节如图4 所示。此外,自然场景图像中往往拥有许多尺寸不一的复杂对象,受局部卷积运算的限制,每个卷积层仅具有处理特定尺度的能力。因此,提出一种边缘细化模块,将上述经过边缘轮廓监督训练后的边界信息与CⅠAM 的输出特征图进行有效互补后,引入多尺度通道注意力机制思想[21]来获得多尺度特征,从而缓解显著对象尺度变换的影响。先将上述模块分别获取的两个特征图进行逐元素相加,然后分别传入两个分支,一个使用全局平均池化层、1×1 卷积和batch normalization 来获得全局上下文信息,另一个使用1×1 卷积和batch normalization 来保留局部信息,两个分支再融合得到更全面的特征信息。随后经过Sigmoid 激活函数与原始特征逐元素相乘进行特征加权,从而获取更加全面的特征表达。上述过程可以描述为:
其中,Conv3×3表示3×3 卷积层,包含一个3×3 卷积、batch normalization和ReLU激活函数,upsample是通过双线性插值的上采样操作,Conv1×1包含一个1×1 卷积和batch normalization,⊙和⊕分别表示逐元素相乘和逐元素相加,δ是Sigmoid激活函数。ERM通过融合边缘轮廓信息来补充在训练期间获得的多尺度特征信息,丰富的多尺度信息又可以反过来帮助更好地定位目标边界,从而获得更加精细的特征图。
1.3.2 渐进式自引导损失
之前对边界信息的优化大都是一种“强制”操作,只对网络最终输出特征图进行细化,相当于一种强行矫正,而网络自生对空间边界的敏感度并没有得到多大提升。一种解决方案是对解码部分的每一层都加入边缘细化模块并进行监督训练,来全程引导网络关注空间信息,然后这种方法会带来大量的计算复杂度,这违背了本项工作的初衷。相反,引入一种渐进式自引导损失,先让网络生成的预测图进行最大池化膨胀操作,将前景像素添加到边界上,然后将膨胀后的预测图与其对应的标签图进行相交的并集操作,从而获得一个跟原始预测图相似,但更加完整、精确的结果。利用这个结果与原始预测图进行监督训练,可以指导网络从训练开始到结束一直逐步探索当前预测的目标边界区域,增强网络自身的对显著对象的空间依赖性,从而提升模型性能。上述的描述可以表示为:
其中,ℓ(⋅,⋅)表示本文使用的训练损失函数,Mpred是预测图,Mgt是对应的groundtruth。可以把渐进式自引导损失看作是一种辅助损失函数,在提升模型性能的同时也不增加网络的推理速度。
1.4 损失函数与深度监督
在SOD 任务中,广泛使用的二元交叉熵损失函数(BCE loss)仅仅只是累积整个批次的像素损失,忽略了图像的整体结构。Qin 等人[18]引入了交占比损失函数(ⅠoU)来弥补BCE的不足,使网络更关注整体结构。为此,本文模型的损失函数定义为:
其中,β是超参数,根据文献[22]将其设置为0.6来让网络更加关注整体结构。此外,本文采用深度监督来判断隐藏层特征图质量的好坏,以提高各层之间的学习能力。具体来说,对于解码部分各层融合后的特征图,依次通过单个输出通道的3×3卷积、Sigmod激活函数以及上采样到与输入图片一样大小,即输出多个预测图。边界监督分支只使用ℓbce,其余监督分支结合上述的PSG loss使用ℓmain,其网络的总损失表达式如下:
其中,Mp-edge和Me-dget分别表示边界预测图和对应groundtruth,αi表示各监督分支所占的权重比例。
2 实验结果与分析
2.1 数据集
为了充分证明本文网络的有效性,在SOD 领域中最常用的5个公开基准数据集上进行评估。这5个数据集分别为DUTS、DUT-OMRON、PASCALS、HKU-ⅠS 和ECSSD。其中DUTS 数据集包含两部分:DUTS-TR 和DUTS-TE。DUTS-TR有10 553张图像,均是从ⅠmageNet DET训练集和验证集中收集的,是目前显著性目标检测研究领域中最大且最常用的训练集;DUTS-TE 包含5 019 幅具有复杂背景与结构的图像,这些图像都是从ⅠmageNet DET 测试集和SUN 数据集中收集的。DUTOMRON 包含5 168 幅背景复杂、内容丰富的图像。PASCALS包含拥有多个目标且具有复杂场景挑战性的图像。HKU-ⅠS由4 447张具有复杂场景的图像组成,这些场景包含多个显著目标和相似的前景与背景外观。ECSSD包含1 000幅具有结构复杂的自然图像。
2.2 评估指标
为了综合评估本文所提出的模型,使用3个指标来作为性能度量:平均F-measure (Favg) 、mean absolute error(MAE)和E-measure(Em)。具体来说,平均F-measure可以评估整体性能,Favg越大,表示性能越好。MAE表示预测显著图与groundtruth 之间的平均绝对误差,MAE越小,性能越好。Em将局部像素值和图像的全局平均值相结合,用于评估显著性概率图与groundtruth之间的相似性,Em越大,性能越好。此外,本文还采用Params和FPS来评估模型大小和推理速度。
2.3 实施细节
本文提出的模型基于PyTorch 框架实现,GTX 1080Ti GPU用于加速。使用DUTS-TR来作为训练集,将输入图像统一调整为352×352,并且采用多种策略(包括对图片进行不同尺度的扩张与收缩、随机裁剪、随机翻转等)来进行数据增强。使用在ⅠmageNet 上进行了预训练处理的MobileNetV3 作为backbone 网络。把backbone 网络的学习率设置为0.005,其他部分设置为0.05,并采用预热和线性衰减策略。使用随机梯度下降(SGD)优化器,其中batchsize 设置为32,momentum 和weight decay 分别设定为0.9 和0.000 5,在40 个epoch后结束训练。
2.4 实验对比
为了展现所提方法的优越性,与近年来最先进的显著性目标检测方法进行比较,包括AFNet、U2Net、EGNet、PoolNet、MⅠNet、GCPANet、PFSNet、ⅠTSDNet、SAMNet、BASNet、PSGLNet、DFⅠ[23]和BANet[24]。为了公平比较,对于所有方法都使用同样的评估代码来进行计算,且测试所需的显著性预测图都是由作者提供或由公开源代码生成。
2.4.1 定量比较
表1展示了5个数据集上3个评估指标的定量比较结果,此外,还展示了各方法的模型大小与运行速度。可以看出,本文所提出的方法表现出了非常好的性能与效率。在模型大小上,本文所提出的网络只有3.48×106,远远小于其他方法,而对比SAMNet,虽然它的模型(1.33×106)更小,但其网络性能远远无法与本文以及其他方法相比。在效率上,本文所提出的模型以108.7 FPS 的速度领先于其他方法,与本文接近的PSGLNet拥有73.4 FPS,但其模型参数量(25.55×106)是本文的8倍左右。在性能上,本文的方法也保持着极强的竞争能力,跟其他先进方法相比,在3 个指标上都具有相当甚至更好的结果,尤其是Favg和MAE,本文方法在DUT-OMRON、HKU-ⅠS、DUTS-TE、PASCAL-S、ECSSD 数据集上都能获得最优或者次优的结果(黑体为最优,下划线为次优)。
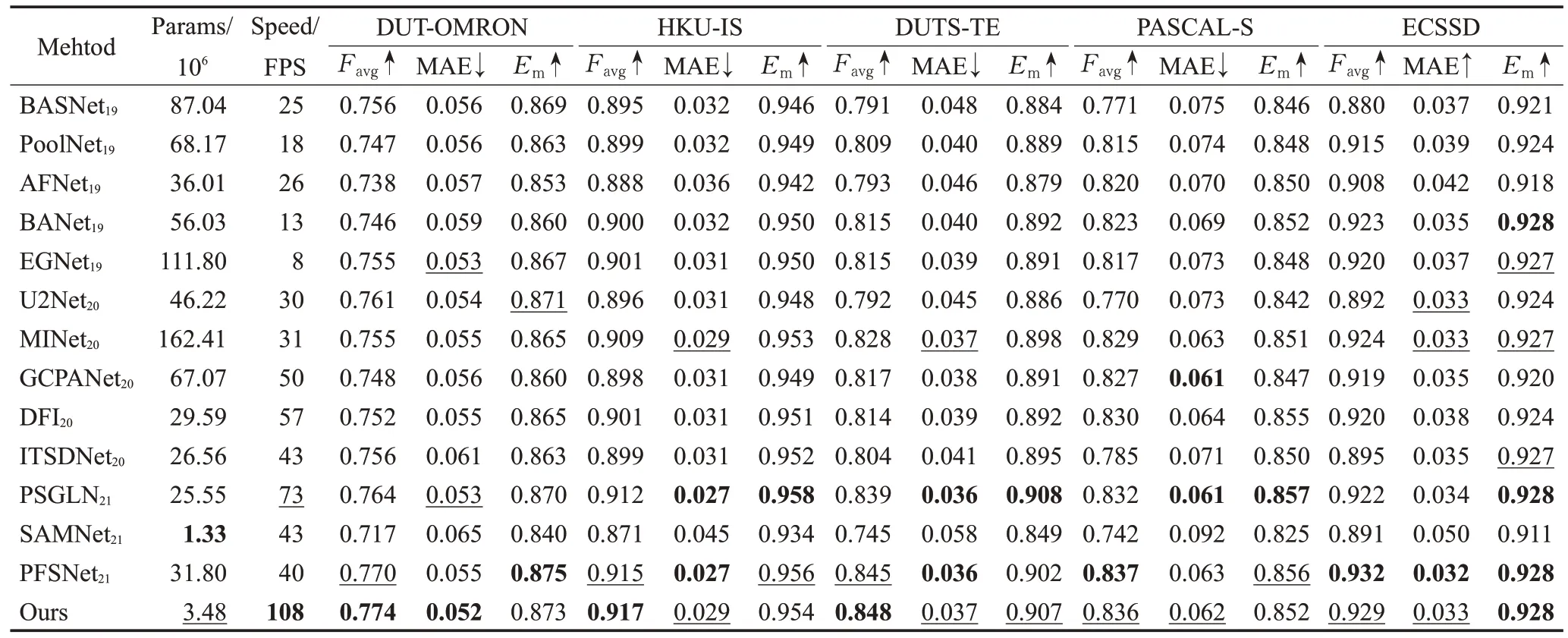
表1 各数据集定量对比结果Table 1 Quantitative comparison results of each dataset
2.4.2 定性比较
为了进行更好的直观感受,提供一些不同场景下的可视化例子,如图5所示。本文所提出的方法能够良好处理各种具有挑战性的场景,从图5第一行和第二行可以看出,对于显著对象所占比例较大的图像场景中,本文方法相较于其他方法,能够分割出更加完整的显著对象;图5 第三行给出了难以区分边界的前景与背景,其他方法虽然可以准确定位到显著对象,但其中草遮掩住猫部分的边界却很模糊,而本文方法可以获得边缘轮廓更为精细的显著对象;图5第四行给出了强光影响下的场景,由于狗身上的颜色会与太阳光进行反射影响,其他方法都难以进行准确定位,而本文方法可以在连续的高级特征聚合中精确定位显著对象;图5第五行和第六行给出了易于混淆的前景干扰场景,可以看出,鸟脚下的树枝和狗旁边的盘子都很容易被判定成显著对象,而本文方法可以有效抑制这些干扰信息,并得到精确的显著对象。

图5 定性比较Fig.5 Qualitative comparison
2.4.3 消融实验
在本小节进行一系列的对照实验,来证明研究工作中每个模块的有效性。采用FPN 这种自顶向上地将高层特征与低层特征逐元素相加的结构作为本文的基线模型(basic)。在该基线模型上,逐步加入各个模块,结果如表2 所示。可以看出,当只在网络顶层使用LR-ASPP时,各项指标相比于基线网络并没有太大的提升,这证实了对于轻量级特征提取网络,单单使用全局信息模块并不足以解决深层信息提取能力不足的问题。相反,当使用本文提出的LFRM 时,与使用LR-ASPP 相比,不仅网络性能得到了提高,模型参数还有所下降,而推理速度也只略微下降。具体来说,Favg、MAE 和Em分别提升了0.012、0.004 和0.003,模型参数减少了0.03×106,推理速度减低了12 FPS,这充分证明了LFRM的高效性。其次,在后续的各阶段特征融合使用CⅠAM,让各层特征信息可以更为高效地融合,并同时抑制干扰信息,其中Favg、MAE 和Em分别提升了0.010、0.003 和0.003,参数量增加了0.02×106,速度降低了23 FPS。之后将第一个浅层阶段的CⅠAM 换成ERM 来进行边界细化,Favg、MAE 和Em分别提升了0.003、0.002和0.003,参数量增加了0.04×106,速度降低了17 FPS,这是由于浅层阶段特征图分辨率较大,不可避免地带来了一定的计算复杂度。最后,再加上PSG来辅助监督训练,增强网络自身的对显著对象的空间依赖性,能够在不影响模型大小和速度的情况下有效提升性能。当使用本文研究所提的所有方法(即LFRM、CⅠAM、ERM、PSG)时,模型表现出最佳性能,这表明了每个模块对于网络的必要性。
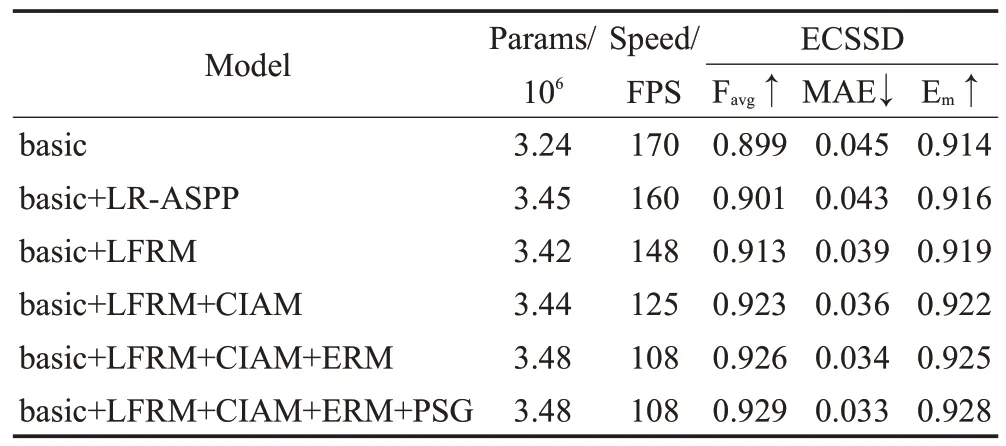
表2 模块消融实验结果对比Table 2 Experimental results comparison of architecture ablation
3 结束语
本文针对当前SOD 方法普遍存在效率较低的问题,提出了一种快速而准确的轻量级显著性目标检测模型。为了使用轻量级网络也能获得充足的高层语义特征信息,设计了一种回环特征复用模块(LFRM)来作为特征提取子网络,同时高效聚合语义特征信息来为指导后续浅层特征进行目标定位。然后,跨层交互聚合模块(CⅠAM)被用于让LFRM的高层语义特征与浅层空间细节特征进行更加有效的交互学习。最后,利用边界细化模块(ERM)和渐进式自引导(PSG)损失来增强边界相关性,进一步细化最终输出显著预测图。本文方法与当前最先进的SOD 研究相比,以更少的参数和更快的速度达到了相当甚至更好的性能。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
证券法律评论(2018年0期)2018-08-31 02:33:08
劳动保护(2018年5期)2018-06-05 02:12:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
华人时刊(2018年23期)2018-03-21 06:26:16
中华建设(2017年3期)2017-06-08 05:49:29
装备环境工程(2015年4期)2015-02-28 01:20:04
外语学刊(2014年6期)2014-04-18 09:11:49
