
基于机器学习构建葡萄霜霉病预测模型及验证
2023-10-10 06:49边凤霞刘凯歌容新民
中国农业科技导报 2023年8期
边凤霞, 刘凯歌, 容新民*
(1.石河子农业科学研究院,新疆 石河子 832000; 2.石河子大学农学院,新疆 石河子 832003)
葡萄霜霉病是葡萄生产中传播快、危害大的真菌病害之一,如不及时防治将直接影响葡萄的产量和品质,造成严重的经济损失[1-2]。目前,农户常采用化学药剂进行防治,但大量、多次用药易造成农药残留、威胁食品安全,并导致环境污染等,因此,对该病害进行精准可靠的预测[3]将便于农户提前采取管理或防治措施,有利于减少田间农药用量,降低病害对作物和果实的危害,进而提高葡萄产量及品质。
气象数据是病害预测模型的主要驱动力[4-6],而葡萄霜霉病的发生与温、湿度等有极大关系。研究表明,温度在12~20 ℃、相对湿度在90%~95%并保持2~4 h 的黑暗条件利于发病[7-9]。近年来,国内外学者基于气象数据开展了霜霉病相关预测模型构建的研究,包括初侵染模型[10]、流行动态模型[11-12]、在早期微型计算机上建立的预测系统[13]以及利用数理统计法[14-15]和归纳逻辑程序设计法 (inductive logic programming, ILP)[16-17]等的多种病害预测方法,但由于气象因子间相互联系又相互制约,没有固定的变化速率(即具有非线性特点),且随着数据类别和规模的增加,模型变量的定义和建模效率会受到影响,很难充分对数据进行挖掘并构建高精度的预测模型[18-19]。随着物联网、大数据、机器学习等技术的不断发展及其在农业上的应用[20],为病害预测提供了更多解决方案。Mezei 等[21]基于低功耗的网络物联网技术开发了葡萄霜霉病预警系统;Volpi 等[22]和Chen 等[23]基于机器学习算法对霜霉病病害症状及发生严重程度进行预测,根据病害发生风险水平预测了病害的发生,并通过评估表明模型的应用降低了杀菌剂的施用量;吴宁[24]将灰色关联分析和机器学习算法结合,构建了葡萄霜霉病短期预测模型,通过设计开发的葡萄霜霉病预测系统实现了面向用户的发病程度预测、预警功能;Menesatti 等[25]构建的多元预测模型对葡萄霜霉病的合理防治管理进行了优化,验证了模型对不同杀菌剂施用量在病害防控中的可能性;Firanj等[26]依托病害预测模型开发了基于气象的预报系统,可预测未来10 d 左右的气象,能更好地掌握气象条件,进一步帮助农户采取防治措施。可见,利用这些技术对病害进行预测是可行且有效的,且对生产上的指导作用也将具有至关重要的意义。但目前将多个机器学习算法应用于新疆地区葡萄霜霉病预测模型构建的研究尚未见报道。
为降低葡萄生产中因病害带来的产量与经济损失,本文依托气象站采集的葡萄生长期间的气象数据,结合霜霉病发生调查情况,基于4 种机器学习算法,对新疆地区葡萄园构建霜霉病发生预测模型,并进行评价与验证,筛选出适宜用于对当地病害进行预测的模型,给大数据、机器学习等技术在葡萄病害预测上的应用研究提供参考,进而为葡萄霜霉病预警系统的开发奠定技术基础,以期为农户进一步采取管理或防治措施提供决策支持。
1 材料与方法
1.1 试验概况
试验于2020 年4 月—2021 年11 月在新疆石河子市石河子葡萄研究所试验地进行,供试葡萄树为5 年生树体,选用对霜霉病抗性较强的‘夏黑’葡萄品种作为试验材料,栽培架式为双厂“U”型架,株行距为3.0 m×0.8 m。该园为平地果园,土壤肥力中等,灌溉条件较好,园内所有葡萄栽培管理措施保持一致,均按常规高产优质栽培模式进行,其中2020年试验数据用于模型构建,2021年试验数据用于模型的验证与筛选。
1.2 数据采集
葡萄树生长期间的气象数据来源于田间安装的HOBO 小型自动气象站,采集时间间隔为1 h,病害发生数据通过人工调查获得,每周调查1 次。调查方法如下:在试验园随机选择5 个固定的观测点,每点随机调查10 个当年抽生新蔓,自上而下调查全部叶片,记录总叶数和病叶数;若果实发病,则在每点调查不同部位的果穗6 个,记录病穗数和病穗总果粒数及病果粒数,计算病穗率和病果率。当叶片首次出现淡黄绿色水浸状病斑、果梗/花序首次出现浅色水浸状斑点时[27]记录发病时间。其中2020 年首次发病日期为8 月29 日;2021年首次发病日期为8月14日。
1.3 变量选取及数据集构建
根据葡萄霜霉病的发生规律及传播特点,温、湿度及光照均影响孢子嚢的形成和萌发[2],病菌能在病叶残体和土壤中越冬或越夏,主要以气流、雨水为媒介进行扩散。本研究选取有利于病菌孢子嚢扩散与侵染的关键气象数据作为预测模型输入变量,分别为气象站采集的每小时空气温度、湿度、降雨量、风速、太阳辐照度、40 cm 土层土壤温度的平均值,霜霉病是否发病(二分类,是/否用1/0表示)作为模型输出变量。
使用PyCharm 2019.3 和Python 3.7.11 对采集的数据进行归一化处理及模型代码实现,进而将数据转化为0~1 的有监督无量纲数据,消除量纲数据间的相互影响,降低模型运算量,提高运算速度及模型精度和性能,归一化公式如下。
式中,Xi为所有样本数据(i=1,2,3,…,n),Xmin为所有样本数据中的最小值,Xmax为所有样本数据中的最大值,X*为归一化的结果。
由于病害是否发生为1/0 分类标签,已经符合位于[0, 1]之间,故不需进行归一化处理。归一化后得到病害发生预测模型数据集,将其70%作为模型训练集(用于模型对数据中包含的信息进行学习与记忆),剩余30%作为模型测试集(用于模型对数据的学习效果进行测试验证及分类预测)。
1.4 模型构建
选用在处理二分类问题时常用且效果较好的机器学习算法构建模型,包括二项逻辑斯蒂(binary logistic regression, BLR)模型[28]、支持向量机(support vector machine, SVM)模型[29]、决策树(decision tree, DT)模型[30]和K 最近邻(K-nearest neighbors, KNN)模型[31]。
1.4.1BLR 模型 BLR 模型由条件概率分布P(Y|X)表示,其中,X为样本值,Y取值为0或1,通过输入的X,得出Y为0或1的概率并比较,将X归至所得概率较大的一类。从而完成对输入变量预测后的是否发病(1/0)进行预测,需遵循以下条件分布。
式中,w为权重向量;b为偏置项。
1.4.2SVM模型 SVM模型是通过对样本数据的类别进行分割,以寻求超平面对所需分类问题进行划分,来确定各类别中与超平面间最短距离的点,而该点即为支持向量,原理如式(6)和图1所示。

图1 SVM模型原理Fig. 1 SVM model principle
式中,w为权重向量;b为偏置项;s.t.为约束条件;T为矩阵转置;Y为样本分类值(用于本研究的二分类问题时,Y为是/否发病的1/0 值);X为样本值;i=1,2,3,…,n。
1.4.3DT 模型 DT 模型是通过树形结构来对每个特征进行测试、响应的过程,在机器学习中常用于分类问题建模。目前已针对模型衍生出多种改进模型。原理如图2所示。

图2 Decision Tree模型原理Fig. 2 Decision tree model principle
1.4.4KNN 模型 KNN 是用特征空间中的K 个最邻近样本的大多数类别来代替目标样本类别的分类方法,其原理如图3所示。与BLR 相比,KNN是更具体的标签而不是概率;与SVM 相比,KNN去除了原理中公式对距离的运算过程,更加简便、快捷。

图3 KNN模型原理Fig. 3 KNN model principle
1.5 模型评价指标
病害发生预测模型采用受试者工作特征曲线(receiver operating characteristic,ROC)、AUC 值(area under the roc curve)、混淆矩阵(confusion matrix)、Kappa 系数(k值)、准确率(Accuracy)、精准率(Precision)、召回率(Recall)及F1分值(F1-score)对模型性能和分类预测指标进行评价[32]。
其中,ROC 曲线是以假阳性率(false positive rate,FPR)为横坐标、真阳性率(true positive rate,TPR)为纵坐标得到的的用于展示模型分类效果的曲线图;AUC 值是ROC 曲线下的面积,其值越接近1,表示模型的分类性能越好。计算公式如下。
式中,TP 指实际为阳性且预测为阳性的样本数;FP 指实际为阴性但预测为阳性的样本数;TN指实际为阴性且预测为阴性的样本数;FN 指实际为阳性但预测为阴性的样本数。
混淆矩阵是通过n行×n列的矩阵分别将样本真实值与预测值间的异同数量对比进行可视化的一个评价指标,用于展示模型分类预测情况,并通过对每个矩阵的数值计算得出k值、准确率、精准率、召回率和F1分值,以衡量模型整体精度。混淆矩阵列联表如表1所示。

表1 混淆矩阵列联表Table 1 Confusion matrix contingency table
Kappa 检验是一种一致性检验方法,计算得出的值通常在0 到1 之间,且越接近1,表明模型的整体性能越好。k值的计算公式如下,其一致性分类标准如表2所示。
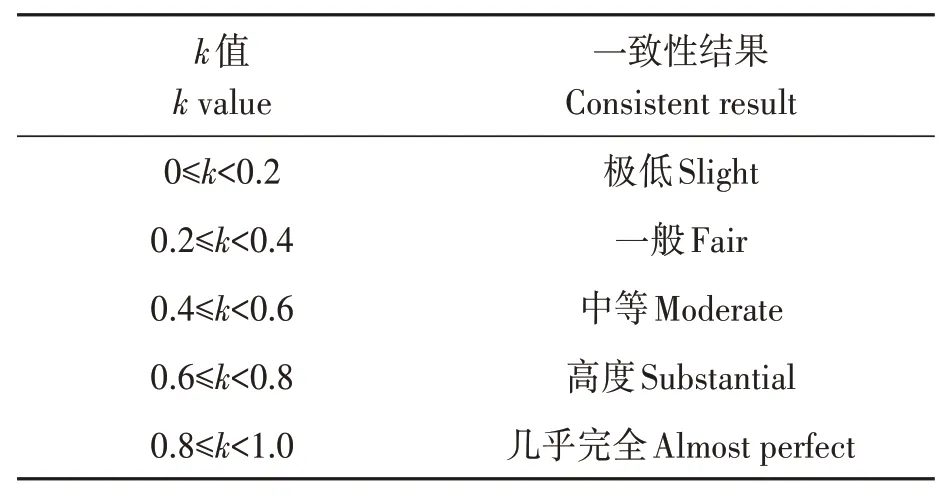
表2 k值一致性划分标准Table 2 The k value consistency classification criteria
式中,P0为观测一致率;Pe为机遇一致率。
准确率(Accuracy)表示预测正确的样本数占样本总数的比例;精准率(Precision)表示正确预测发病的样本数占预测发病样本数的比例;召回率(Recall)表示正确预测发病的样本数占实际发病样本数的比例;F1分值(F1-score)是综合了精准率和召回率的评价指标。计算公式如下。
2 结果与分析
2.1 病害发生不同预测模型比较分析
2.1.1不同预测模型分类预测指标分析 如图4A,BLR 模型分类预测的ROC 曲线下面积(AUC值)为0.817 9;根据混淆矩阵(图4B),4 个矩阵中的总数目为测试集1 395 条的数量,其中TN、TP、FN、FP 分别为875、321、135、64,由公式(9)~(15)得出k值为0.66,预测准确率、预测发生精准率、召回率和F1分值分别为86%、83%、70%、76%。由此表明,预测精度具有高度一致性,模型性能较好。
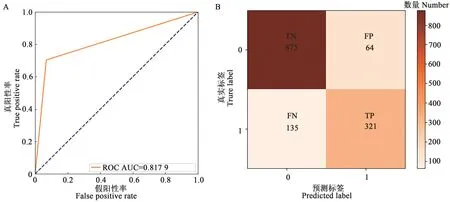
图4 BLR模型分类预测指标Fig. 4 BLR model classification prediction indicators
SVM 模型的预测结果中,AUC 值为0.813 6;TN、TP、FN、FP 分别为878、317、145、55;k值为0.66;预测准确率、预测发生精准率、召回率和F1分值分别为86%、85%、69%、76%,模型预测精度具有高度一致性(图5)。

图5 SVM模型分类预测指标Fig. 5 SVM model classification prediction indicators
DT模型的预测结果中,AUC值为0.928 8;TN、TP、FN、FP 分别为900、410、46、39;k值为0.86;预测准确率、预测发生精准率、召回率和F1分值分别为94%、91%、90%、91%,模型预测精度几乎完全一致(图6)。
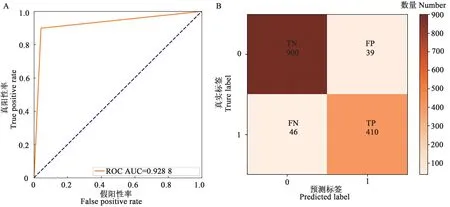
图6 DT模型分类预测指标Fig. 6 DT model classification prediction indicators
KNN 模型的预测结果中,AUC 值为0.923 7;TN、TP、FN、FP分别为879、416、41、59;k值为0.84;预测准确率、预测发生精准率、召回率和F1分值分别为93%、88%、91%、89%,模型预测精度几乎完全一致(图7)。

图7 KNN模型分类预测指标Fig. 7 KNN model classification prediction indicators
不同模型预测的AUC 值表现为DT>KNN>BLR>SVM,表明在关于预测葡萄霜霉病是否发病的问题上,DT和KNN模型表现较好,具有较高性能。
2.1.2不同预测模型分类预测结果对比 将BLR、SVM、DT、KNN 预测模型的评价指标进行对比,结果(表3)表明,在病害发生预测模型的构建上,DT 模型稍有优势,但此结果只是基于2020 年试验数据,因此还需对模型进行验证和评价,以选出总体相对最优的模型。

表3 不同预测模型的分类结果Table 3 Classification results of different prediction models
2.2 病害发生不同预测模型验证比较分析
2.2.1不同预测模型分类预测验证指标分析 使用2021 年试验采集数据对上述4 个模型进行验证,结果(图8)表明,BLR 模型的验证结果与根据上年数据所构建模型的预测结果相比,AUC 值为0.702 4,TN、TP、FN、FP分别为730、303、267、106;k值为0.42;预测准确率、预测发生精准率、召回率和F1分值分别为73%、74%、53%、62%。综上所述,各项评价指标降低,表明该模型鲁棒性较差。如图9 所示,SVM 模型的验证结果与BLR 模型验证结果类似,各项指标也均降低,其中AUC值为0.721 5;TN、TP、FN、FP 分别为731、324、228、123;k值为0.46;预测准确率、预测发生精准率、召回率和F1分值分别为75%、72%、59%、65%。结合病害发生预测模型构建结果,SVM 和BLR 模型的稳定性及分类预测性能均未能达到较高水平,表明并不适用于预测葡萄霜霉病是否发病的问题。
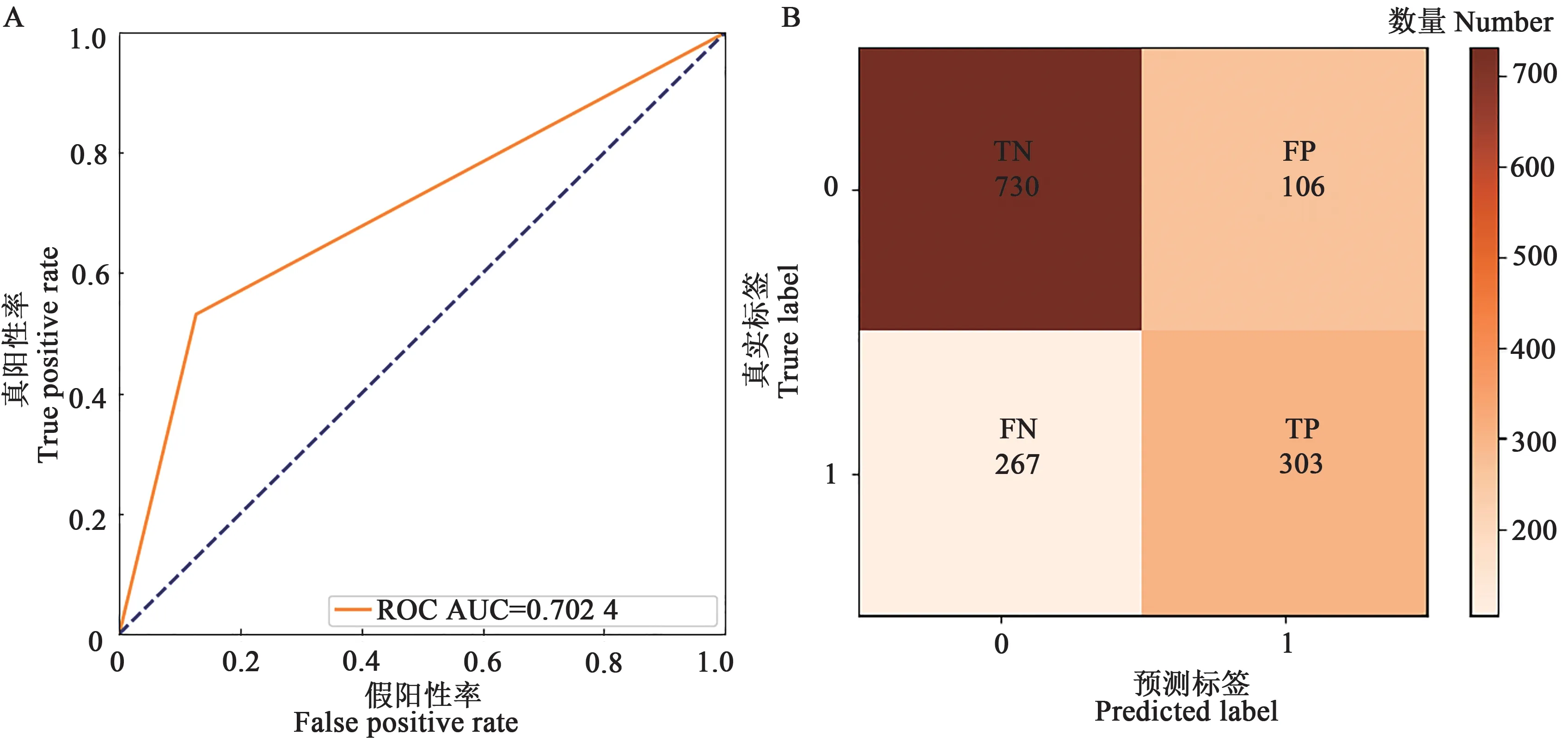
图8 BLR 模型分类预测2021年验证指标Fig. 8 BLR model classification prediction validation indicators in 2021
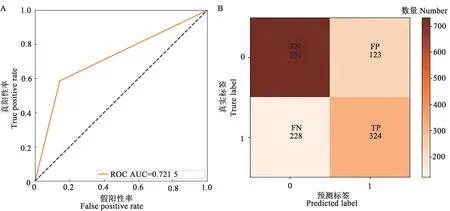
图9 SVM模型分类预测2021年验证指标Fig. 9 SVM model classification prediction validation indicators in 2021
如图10 所示,DT 模型预测结果中的AUC 值为0.897 0;TN、TP、FN、FP 分别为774、492、67、73;k值为0.79;预测准确率、预测发生精准率、召回率和F1分值分别为90%、87%、88%、88%。即模型预测精度具有高度一致性,评价指标均处于较高水平,具有较好的泛化性及鲁棒性。
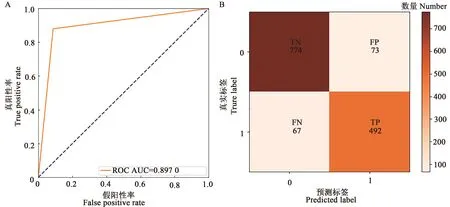
图10 DT模型分类预测2021年验证指标Fig. 10 DT model classification prediction validation indicators in 2021
由图11可知,KNN 模型的验证结果较预测结果也有所降低。其中,AUC 值为0.828 2;TN、TP、FN、FP 分别为725、450、121、110;k值为0.66;预测准确率、预测发生精准率、召回率和F1分值分别为84%、80%、79%、80%。从评价指标来看,模型性能总体仍处于较高水平。
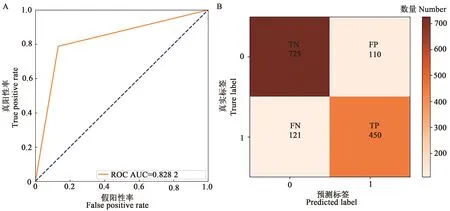
图11 KNN模型分类预测2021年验证指标Fig. 11 KNN model classification prediction validation indicators in 2021
不同模型的AUC 值表现为DT>KNN>SVM>BLR。即在预测及验证结果中,DT和KNN模型具有较强鲁棒性和泛化性; BLR模型的表现较差。
2.2.2不同预测模型分类预测验证结果对比 4个模型验证结果如表4 所示。DT 模型在病害发生预测模型的构建与验证上均表现最优;其次是KNN 模型。结合模型原理,表明在多变量作为输入的病害预测问题上,DT模型更适于挖掘特征与标签间的关系,同时在验证数据上也能保持较高稳定性和泛化性。

表4 不同预测模型分类验证结果Table 4 Classification validation results of different prediction models
3 讨论
本研究基于葡萄生长期间的气象数据,结合人工调查的葡萄霜霉病发生数据,分别利用4 种机器学习算法构建了葡萄霜霉病发生预测模型,并进行了评价与验证,结果表明,DT 模型在葡萄霜霉病发生预测模型的构建与验证结果均高于其他3 个模型。对于4 个模型分类预测结果的差异性及优劣原因,一方面是由于模型本身,不同模型在处理不同问题时的表现可能存在差异;另一方面是由于本研究中的数据为气象站每小时采集的数据,分类预测结果的偏差(假阳性、假阳性)可能是每小时间数据的特征信息过于详细或区别较小,使模型不易学习和分类,导致分类错误。总体来说,本研究构建模型的分类预测精度较高,综合性能较好。这与宋旺[33]、Volpi 等[22]、秦华[34]分别基于气象数据构建的SVM 模型、随机森林模型、自适应神经网络模型表现较好的结果不同,可能是由于模型对于数据集和时空尺度上的差异导致,且模型在构建手段、参数设置不同的情况下,也会对不同问题产生不同的适应性及结果。
本研究首次将4 种机器学习模型应用于预测新疆石河子地区葡萄霜霉病发生的模型构建,还存在一些不足,如没有考虑病原菌的致病性、没有探究品种抗性以及不同树龄植株对病害的抗性等,限制了模型的通用性。但由于本研究是根据葡萄是否发病构建的预测模型,因此,从适用性角度出发,在病害循环过程中,如能满足“病害三角”致病关系,导致寄主显症,则可用于发病预测模型的构建与验证,进而实现模型应用场景和范围的扩充。Rossi等[10]通过接种葡萄霜霉病病原菌来构建初侵染阶段发病症状的模型;Francesca等[9]构建了气候变化下预测葡萄霜霉病流行情况的模型。本研究与前人研究结果一致,均从单个水平探究其对病害的影响,即在提出假设(如假设病原存在或会由外界传播,且具备其生长、繁殖、侵染的气候条件及寄主非避病),并根据病害已经发生的事实,表明假设确实成立的基础上,确保病害发生理论和病害循环的完整性,对其中环节进行分析。
在未来的研究中,将在不同地点选用不同抗性品种进行验证,同时,考虑田间孢子囊密度带来的影响,通过监测、预测孢子数量[35-36]实现对葡萄霜霉病发生严重程度的预测,探索葡萄霜霉病发生各阶段机理模型[37-39]的构建,将其与本研究中模型融合使用,为预警系统的开发应用奠定技术基础,并通过预警系统短期预报结果为病害前期防治提供决策,进而更好地指导生产。[1] 芦屹,努尔孜亚·亚力麦麦提,付文君,等.新疆伊犁河谷地区葡萄霜霉病流行与气候条件的关系[J].新疆农业科学,2020,57(10):1855-1862.LU Y, Nuerziya Yalimaimaiti, FU W J,et al.. Research the relationship between epidemic of grape downy mildew and climatic conditions in Ili Valley of Xinjiang [J]. Xinjiang Agric.Sci., 2020, 57(10): 1855-1862.
猜你喜欢
今日农业(2022年4期)2022-11-16
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
烟台果树(2021年2期)2021-07-21
阅读(低年级)(2020年11期)2020-12-28
女报(2020年10期)2020-11-23
今日农业(2020年19期)2020-11-06
农药科学与管理(2019年7期)2019-11-29
吉林蔬菜(2017年4期)2017-04-18
河南科技(2014年8期)2014-02-27
