
基于轻量级CNN-Transformer 混合网络的梯田图像语义分割
2023-10-08 07:19程兴豪
农业工程学报 2023年13期
刘 茜,易 诗,李 立,程兴豪,王 铖
(成都理工大学机电工程学院,成都 610059)
0 引言
中国耕地面积19.18 亿亩中,超过1/4 是梯田,主要分布在江南山岭地区。梯田是一种传统的农业种植方式,发挥着稳定作物生产与水土保持效能[1],修筑梯田是发展农业生产的重要措施之一。由于梯田修建时质量好坏的影响以及管理养护不善,梯田面临被破坏的风险,因此如何快速、准确地对梯田区域分布信息进行采集,对提高粮食产量、治理水土流失以及规划区域生态等方面具有重要的作用与意义[2]。传统的梯田信息获取主要通过实地调查实现,而梯田地形复杂,人工统计费时费力。在智慧农业领域,无人机因其体积小、操作方便等特点成为“新农具”[3],利用无人机航摄系统获取高分辨率遥感影像具有一定的优势。随着信息化技术的快速发展,基于深度学习的语义分割是计算机视觉的一项基本任务[4],推动了多个领域的发展[5-10]。通过梯田区域语义分割技术,可以进一步获取梯田的形状、位置、轮廓等信息,及时准确地掌握梯田边缘信息为预防和修护加固梯田提供重要的依据,同时有助于梯田区域种植面积和范围的统计,推动梯田和旱作区农业建设的发展。
相较于传统图像处理的农田区域分割算法,基于深度学习的语义分割方法不论在分割性能上还是在分割速度上均占优势,因此其在农田场景中的应用也愈加广泛。在近年来的研究中,杨亚男等[11]提出了基于全卷积神经网络和条件随机场的梯田区域语义分割模型,引入DenseCRF 结构对 FCN 模型进行改进,平均总体精度达到 86.85%,对梯田的分割取得了较好的识别效果。邓泓等[12]在Deeplabv3+网络结构部分通过减小ASPP 采样率组合,改进解码器融合更多浅层特征并采用深度可分离卷积解耦图像深度信息与空间信息,提出了一种基于改进 Deeplabv3+模型的无人机农田图像分割方法。李云伍等[13]改进了空洞卷积神经网络,构建了包含有前端模块和上下文模块的语义分割模型Front-end+Large,在无阴影道路和有阴影道路训练集上的平均区域重合度分别为 73.4%和 73.2%,对阴影干扰有良好的适应性;易诗等[14]在实时双边语义分割网络的空间信息路径上进一步融合了红外图像的低层特征,使用全局最大池化层替换该结构部分模块的全局平均池化层,实现了对夜间农田场景的实时语义分割。杨丽丽等[15]通过在Unet 编码器网络中添加残差连接并使用池化卷积融合结构完成下采样实现了农田道路的高精度识别,分割交并比为 85.03%;ZHANG 等[16]提出了一种低空遥感农田图像的语义分割网络,其编码器以 IResNet 为骨干网络并结合SPM 和MPM 模块提取特征,解码器将 IResNet 主干网络的输出特征图与编码结构的输出图相结合,加强了对图像的场景解析,准确率和平均交并分别为95.6%和77.6%,提高了对农田作物和空位分割的准确性。刘尚旺等[17]通过构造多维度特征融合的金字塔池化结构,使用MobileNet 作为主干特征提取网络,构建了基于改进PSPnet 的无人机农田场景语义分割模型,使农田的分割结果更加精确和高效,平均像素准确率和平均交并比分别为 89.48%和 82.38%。上述研究,虽然对无人机农田图像的分割有了一定的提升,但参数较多,计算量较大,无法达到移动视觉任务轻量化、低延迟的需求,故而很难应用在复杂梯田区域所需的类似无人机这种移动设备中。轻量级的卷积神经网络虽然无此限制,但它在空间上是局部建模的,无法学习全局表征。在无人机图像梯田分割中,由于部分网络是在方形窗口内探测输入特征图,因此会限制它们广泛存在的各向异性背景方面的灵活性,不可避免地包含来自不相关区域的污染信息[18],不能很好地捕获孤立区域的远程关系,部署在无人机上,无法准确地分割出远距离具有条状结构的梯田道路。
无人机图像梯田环境复杂多变,具有较长的带状结构,使得远距离卷积提取到的信息之间没有相关性,因此本文提出了基于轻量级CNN-Transformer 混合构架网络的无人机图像梯田区域语义分割,该框架引入了条形池化[19](strip pooling)和轴向的注意力机制[20](axial attention),能够有效地捕获远程依赖关系,以简单的训练方法和较少的参数更有效地从大量语义信息中提取出最关键的部分;引入了空洞空间金字塔池化[21](atrous spatial pyramid pooling,ASPP)模块,可以从多个尺度上捕获上下文信息,增大模型的感受野,得到更密集的语义特征图;无人机图像梯田道路边界模糊,本文利用解码器对编码器提取到的多尺度特征图进行采样和卷积操作,在无人机图像中对梯田区域的分割与识别时,可以得到具有梯田道路边缘细节特征的结果图,以期实现对复杂梯田区域的准确分割。
1 材料与方法
1.1 数据获取
为了验证本文模型的精确度,以无人机为图像采集平台,无人机的视野广阔,航拍可以包含大量的地面信息[22]。本研究的采集地点为云南省红河州元阳县(23°22′28″N,102°83′26″E),采集时间为2022 年7 月至9 月,台风Q500 4K 无人机尺寸为565 mm×420 mm×210 mm(长×宽×高),视频分辨率为3 840×2 160 像素,无人机以 5 m/s 的速度,飞行高度区间为15~25 m 从多个角度进行拍摄。摄像头采集多段梯田场景真实视频数据后存储,再剪辑选取帧图像,提取多个场景和环境条件的 2 000 张512×512 图像。
为了获得精确的语义分割数据集,使构建的模型算法适应多种环境特征,依据田间实际情况和自然光照,在多种复杂条件下进行图像采集。采集过程中梯田存在房屋、树木、阴影遮挡等情况。此外,由于提取的数据图像无法完全覆盖梯田的每个场景,可能会出现数据集不平衡的情况,通过网络爬虫得到不同场景的梯田图像300 张。经过图像和视频数据处理,共得到 2 300 张不同环境下的梯田数据集图像。
1.2 数据处理和标注
为了验证本文模型的鲁棒性和泛化能力,进一步扩大测试集和训练集,对采集的无人机梯田区域图像集进行数据增强来提升数据质量、增加数据特征多样性,而不同的数据增强策略对模型性能提升效果也不同[23],通过翻转、颜色变换(亮度、对比度)以及随机裁剪等处理对梯田数据集进行扩增[24-26]。如图1 所示,本文增强后的无人机梯田图像共包含13 200 张,其中训练集、测试集、验证集分别为8 400 张、3 600 张、1 200 张。然后利用Lableme[27]工具对其进行语义标注,通过批量转换文件将以.json 格式存储的标注文件转换为.png 格式的标签图像。

图1 数据集增广效果Fig.1 Dataset augmentation effect
根据梯田区域环境中的对象进行类别划分,标注共包含5 个类别,即田埂,农作物,房屋,行人,树木,对应的颜色是红色,绿色,黄色,蓝色,紫色,这5 个类别之外的对象设置为背景类,标注颜色为黑色。每种类别标注的 RGB(red-green-blue)3 通道值如表1 所示,数据集样例如图2 所示。

表1 无人机图像梯田区域分类的标注颜色Table 1 Labeling colors for terraced area classification of UAV images

图2 数据集示例Fig.2 Examples of dataset
2 梯田区域分割模型构建
DOSOVITSKIY 等提出了 Vision Transformer(ViT)[28]模型,但当训练数据集较小时,ViT 的表现不如同等大小的ResNets,ViT 是heavy-weight 且适用于大数据集和大模型。此外,ViT 模型无法学习到图像的结构信息,为了消除这些限制,Sachin Mehta 提出了轻量级模型MobileViT[29]。
MobileViT 在不同的移动视觉任务中有更好的泛化能力和鲁棒性,但无人机图像梯田环境复杂多变,且田埂边界模糊、具有长程带状的结构、离散分布等特点,使用方形窗口探测输入特征图限制了它们在捕捉条形梯田中存在的各向异性上下文方面的灵活性,因而可能会包含来自不相关区域的污染信息。因此,本文提出了基于轻量级CNN-Transformer 混合构架网络的语义分割模型。在模型的编码器部分引入了条形池化模块(strip pooling block,SPB),它既能更好地捕获局部上下文信息又能避免不相关区域干扰标签预测,并利用空洞空间池化和轴向注意力机制来扩大模型的感受野,增加模型不同层次信息的多样性,再通过设计摆放各模块的位置顺序来实现局部与全局的视觉表征信息交互,得到完整的全局特征表达;最后利用解码器对编码器提取到的多尺度特征图进行采样和卷积操作得到语义分割结果图,实现对复杂梯田区域对象的准确分割。
2.1 MobileVit 网络模型
移动视觉任务由于设备的资源约束,用于部署的模型须具有轻量化、高精度及低延迟的特点。MobileViT 引入的MobileViT block 使它可以有效地将局部和全局信息进行编码。MobileViT 主要由普通卷积,MobileNetV2中的逆残差模块,MobileViT block,全局池化以及全连接层共同组成。MobileViT block 使用Transformer 将卷积中的局部建模替换为全局建模,其结构如图3 所示。

图3 MobileVit 网络结构图Fig.3 MobileVit network structure diagram
MobileViT 块首先用3×3 和1×1 卷积获得局部信息表示,并且特征图尺寸仍保持不变,3×3 卷积用于学习局部的空间信息,1×1 卷积用于调整通道数,然后通过展开、局部处理和折叠3 种操作进行全局的特征建模,再通过1×1 卷积将通道数变回原始大小后与原始输入特征图沿着通道方向进行拼接,最后使用3×3 卷积进行特征融合得到输出。
2.2 基于轻量级CNN-Transformer 混合构架网络模型
为了提高MobileViT 模型在类似于梯田这种复杂的区域中的分割准确度,本文融合空洞空间卷积及条形池化的优点,在MobileViT block 中引入了轴向注意力机制,提出了基于轻量级CNN-Transformer 混合构架网络的无人机图像梯田区域语义分割模型,具体的框架如图4 所示。

图4 基于轻量级CNN-Transformer 混合构架网络结构Fig.4 Lightweight CNN-Transformer based hybrid architecture network structure
CNN-Transformer 混合构架网络分为解码器和编码器两部分,其中,编码器负责提取高层次语义的特征图,将原始图像首先用3×3 卷积获取局部的信息特征,再经过MV2 Block 模块和轴向注意力机制模块增强其特征提取能力得到解码器第一阶段输出的特征图Y1。图5 所示为模型处理后的各中间层输出的可视化特征图,可以看到输入数据在网络中是如何被分解的。从第一个输出层的可视化特征图Y1 中,能明显地看到原图像的大概轮廓和形状。接着,特征图Y1 经过编码器的第二、三阶段,分别输出特征图Y2、Y3,轴向注意力模块可以帮助模型更加关注重要对象的特征,提高分割的精度和鲁棒性。从可视化特征图Y2、Y3 可以看到,随着模型越来越深,提取的通道数越来越多,特征也更为抽象。最后,特征图Y3 经ASPPSPB 和Axial Attention 模块操作后输出特征图Y4,从第四个输出层的可视化特征图可以看到,深层网络提取的特征具有更强的语义信息,但是分辨率很低,对细节的感知能力差。解码器部分将每个阶段输出的不同尺寸大小的特征图Y1、Y2、Y3、Y4 融合得到包含低级纹理特征和高级上下文特征的输出图,最后通过上采样将特征图恢复到原图大小后输出分割结果图。

图5 中间多通道可视化特征图Fig.5 Intermediate multi-channel visualization feature image
2.2.1 Axial Attention 模块
轴向注意力[30]将二维自注意分解为两个一维自注意,降低了计算复杂性,并且允许在更大区域内执行注意力。因此,本文将轴向注意力机制引入语义分割网络以保证全局的关系建模和低计算量。Axial Attention 在图像的每个轴上应用独立的 attention 模块,每个 attention 模块沿着输入张量的单轴施加一系列的注意力(self attention),每个注意力层都沿着一个特定的轴混合信息,从而使另一个轴的信息保持独立。
具体地,在图像宽的方向上定义轴向注意力层为一维的位置敏感自注意力,并在图像高的方向上做类似的定义。给定具有高度h、宽度w和通道din的输入特征图,沿宽的方向上的轴向注意力定义如式(1)所示:
本文分别为高度轴和宽度轴连续使用两个轴向注意力层,两个轴向注意力层都采用了多头注意力机制。Axial Attention 将计算复杂度降低至O(hwm),通过将跨度m设置为整个输入特征来实现全局感受野,以便更好地从大量语义信息中提取出最关键的部分,使得网络在训练过程既提高了效率又提升了分割效果。
2.2.2 ASPPSPB 模块
空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,而条带池化模块SPB 能够捕获孤立区域的远程关系。SPB 由两条路径组成,侧重于沿水平或垂直空间维度编码远程上下文。对于池化图中的每个空间位置,它编码其全局水平和垂直信息。SPB这个模块是轻量级的,可以作为有效的附加块插入任何骨干网络以生成高质量的分割预测。因此,本文在ASPP 的基础上引入了SPB,具体结构如图6 所示。
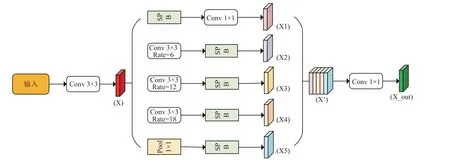
图6 ASPPSPB 结构图Fig.6 ASPPSPB structure diagram
ASPPSPB 模块先引入条形池化模块再进行1×1 的卷积运算,将并联的3 个3×3 膨胀速率为6,12,18 的空洞卷积以及一个全局平均池化运算后又分别进行条形池化操作,以扩大编码器的感受野并收集远距离上下文信息,再将不同尺度的feature map 进行融合后通过一个1×1 卷积操作来降低特征通道数,最后进行上采样将所得特征图恢复到原来图像的大小,经过分类器获得最终的语义分割结果。引入ASPPSPB 模块除了可以从多个尺度上捕获上下文信息,增大模型的感受野外,还消除了使用方形窗口探测输入特征图在捕捉具有长程带状结构、离散分布等特点的无人机图像梯田区域中存在的各向异性上下文方面灵活性的限制,得到了更为准确连续的带状分割结果图。
2.3 基于轻量级CNN-Transformer 混合构架网络模型的解码器
语义分割解码器阶段主要的任务是将经过编码器阶段下采样后的低级特征信息进行处理,进而提取富含语义信息的高级特征信息,并通过相关技术将其分辨率恢复为输入图像的分辨率大小。本研究模型的解码器模块用于恢复分割梯田区域的边界,其结构如图7 所示。

图7 解码器结构图Fig.7 Decoder structure diagram
解码器接收了来自 CNN-Transformer 编码器的 4 层处理后的不同尺寸的特征图Y1,Y2,Y3,Y4。首先将编码器提取到的特征图Y1 进行2 倍下采样后与特征图尺寸相同的Y2 拼接得到一个新的下采样2 倍特征图Y2_1,将Y2_1 送入3×3 的卷积层进行运算后输出特征图Y2_2,采用同样的方法,依次输出特征图Y3_1、Y3_2 及Y4_1。把特征图Y4_1 用2 个3×3 的卷积来提升特征,再用1 个双线性上采样,将得到的特征图与Y3,Y3_2 进行特征融合得到新特征图,将该特征图通过卷积块(Conv block)以及2 倍上采样后与Y2,Y3_2 进行特征融合,再经过同样的操作将其输出特征图与Y1 进行拼接,最后经过2 次上采样块将特征图恢复到原始图像大小输出。无人机图像梯田道路边界模糊,利用该解码器可以得到具有梯田道路边缘细节特征的结果图,实现对梯田及其道路的准确分割。
2.4 基于轻量级CNN-Transformer 混合构架网络模型的损失函数
为了避免因训练样本不均衡影响模型的分割准确性,在训练模型时采用图像分割损失函数OhemCELoss[31],能够对简单样本和一些小数量样本进行抑制,使得训练过程更加高效,定义如式(2)所示。
式中l为损失函数,y(i) 是真实值,是预测值,N是类数。
在改进的MobileVit 模型中采用了主要损失函数和辅助损失函数,综合损失函数如式(3)所示。
式中lp是 主要损失,li是辅助损失,α是损失函数的权重。
2.5 评价指标
为量化分析本文所提模型的语义分割精度与速度,采用像素准确率[32](pixel accuracy,PA)、类别平均像素准确率(mean pixel accuracy,MPA)[33]、平均交并比[34](mean intersection over union,MIoU),频权交并比[35](frequency weighted intersection over union,FWIoU)、帧率(frames per second,FPS)等指标对其进行性能评价。
假设pmn表示属于第m类却被预测为第n类的数量,pmm表示属于第m类且被预测为第m类的数量,pnm表示属于第n类且被预测为第m类的数量,k表示语义类别总数,本文k=5,相关评价指标定义式如下:
1)PA 表示所有像素类别预测正确的数量占像素总数的百分比,定义如式(4)所示。
2)MPA 是评价模型像素预测精度的主要指标,定义如式(5)所示。
3)MIoU 用于评价模型总体目标区域的分割准确度,定义如式(6)所示。
4)FWIoU 是在MIoU 基础上做了改善,直接对每个类别的IOU 进行加权,所有类别的权重仍为1。定义如式(7)所示。
5)FPS 指的是网络每秒钟能够处理图片的数量,定义如式(8)所示。
式中M为视频帧数,T为消耗时间,s。
3 结果与分析
3.1 试验参数
试验模型训练的计算机处理器为Intel(R)Xeon(R)Gold 5 320 M,基准频率为 2.20 GHz,图形处理器(GPU)为 NVIDIA A30,显卡内存为 24 GB,操作系统为 Ubuntu 18.04,配置安装 Pytorch 1.8.1,Python3.7和 OpenMPI 4.0.0。基于轻量级CNN-Transformer 混合构架网络模型训练时训练集图像分辨率为512×512 像素,所采用的迭代次数(Epochs)为 200 次,最小批处理大小为 4 张图片,学习率设置为0.001,最后选取效果最好的语义分割模型。
3.2 消融试验结果对比分析
为了探究引入了条形池化空洞空间金字塔模块和轴向注意力机制的改进模块对MobileVit 模型带来的性能提升,进行了消融试验,通过PA、MPA、MIoU、FWIoU等指标选取最优模型,试验结果如表2 所示。

表2 不同改进模型在测试集上的性能对比Table 2 Performance comparison of different improvement model on test set
由表2 的指标可以看出,PA 从从MobileVit 的89.69%上 升到MobileVit_3 的95.79%,MIoU 从MobileVit 的71.29%上升到MobileVit_3 的80.91%,说明在编码器部分叠加使用这两个改进方法可以获取到更加丰富的语义特征信息,于是选择MobileVit_3 作为本文的最优模型CNN-Transformer 进行试验。
3.3 不同语义分割模型对比分析
本文以狭长且结构复杂的梯田作为试验数据集,以512×512 像素的RGB 图片作为输入。为验证本文所提方法的有效性,选取现有的语义分割模型PSPNet、LiteSeg、BisNetv2、Deeplabv3Plus、MobileViT 与本文所提出的最优模型CNN-Transformer 进行对比试验。在本文的试验中,为了排除其他的干扰因素,所有试验均采用相同的数据增强方法,采用相同数据集和相同的训练参数。对于需分割的每一类别的平均交并比,CNN-Transformer相对其他5 种分割模型的试验结果如表3 所示。

表3 不同模型下不同类别对象的平均交并比Table 3 MIoU of different classes of objects under different models %
由表3 可知,本文方法对背景、田埂、农作物、房屋、行人、树木等农田区域中的常见对象分割,平均交并比达到了87.58%、97.75%、98.23%、79.42%、74.16%、77.23%,均优于改进前的MobileVit 模型以及PSPNet、LiteSeg、BisNetv2、Deeplabv3Plus 模型。所有模型在不同对象的分割结果上都呈现了“农作物、田埂、背景、房屋、行人、树木”的由大到小趋势,说明当对象轮廓明显或特征相对单一时分割比较容易,但是当分割对象比较小或者比较复杂时分割相对困难。对于农作物和田埂等对象,本文引入的条形池化空洞空间金字塔模块和轴向的注意力机制可以捕获到细长的田埂,同时构建的编解码器结构能够利用更多的边缘细节特征,因而将农作物和田埂的MIoU 进一步提升至98.23%和 97.75%,分割更加精准。
为了评价模型的整体性能,从PA、MPA、MIoU、FWIoU 等指标对不同模型进行评价,试验结果如表4所示。

表4 不同模型在测试集上的性能对比Table 4 Performance comparison of different models on the test set
由表4 可知,本文基于轻量级CNN-Transformer 混合构架网络模型在精度方面具有一定的优势,其PA、MPA、MIoU 及FWIoU 均是最高,分别为95.79%、87.82%、80.91%和94.86%,与PSPNet模型相比,分别提 高了12.92、47.02、56.23、20.52 个百分点;与LiteSeg 模型相比,分别提高了6.46、12.86、10.96、8 个百分点;与BisNetv2 模型相比,分别提高了4.76、1.74、2.00、5.11 个百分点;与Deeplabv3Plus 模型相比,分别提高了4.46、3.12、5.47、4.49 个百分点;与MobileVit模型相比,分别提高了6.10、4.56、9.62、7.01 个百分点;这主要是因为该模型引入的空洞空间金字塔池化和条形池化增大了模型的感受野,获得了多尺度的上下文信息,并解决了远距离信息之间没有相关性的问题,提升了模型的分割准确率。
为了综合评估本文提出的CNN-Transformer 模型在轻量化方面的表现,将CNN-Transformer 同其他5 种方法进行比较,试验结果如表4 所示。由表4 可知,LiteSeg 网络的模型参数量最小,只有5.52 M,虽容易训练但获得的精度较低。Deeplabv3Plus 网络的模型参数量最大,有59.75 M,但其分割复杂梯田的结果不够精细,而本文的CNN-Transformer 模型引入了能节省计算和内存Axial Attention 模块,其参数量为8.32 M,与Deeplabv3Plus 相比,减少了51.43 M 的情况下,分割结果仍为最优,且帧率为51.91 帧/s,大于25 帧/s,满足实时性的要求,因此本文的模型是轻量化实时语义分割模型。
通过对各模型性能指标综合分析,基于轻量级CNNTransformer 混合构架网络模型可以实现精度与速度的均衡,对具有不规则狭长结构的梯田区域对象有较高的分割准确率和较好的适应性。
图8 为5 种网络模型与CNN-Transformer 模型对测 试集无人机梯田区域图像语义分割的结果。

图8 不同语义分割方法效果对比Fig.8 Comparison of effect of different semantic segmentation methods
从图8 可以看出,BisNetv2 模型存在分割结果粗糙的情况,PSPNet 和BisNetv2 模型出现了不同程度的类别分割错误,LiteSeg、Deeplabv3Plus 和MobileVit 这3 种模型虽均识别出了测试图片中的语义类别,但在一些细节方面的分割效果明显差于本文的模型,具体表现在第一列放大的蓝色矩形框中,PSPNet、LiteSeg、BisNetv2、Deeplabv3Plus 和MobileVit 模型均有一些缺失的部分,没有准确地分割出狭小细长的田埂,而本文的基于轻量级CNN-Transformer 混合构架网络实现了对该部分的田埂较为准确的分割;对于第二、三列蓝色矩形框放大的田埂边界,PSPNet、LiteSeg、BisNetv2、Deeplabv3Plus和MobileVit 模型在边界轮廓方面的性能均低于本文的混合构架网络。第四列蓝色矩形放大框中,本文的混合构架网络较为准确的识别出水沟,并分割出了田埂边界,在第五、六列蓝色矩形放大框中,其他模型对田埂的分割均有不同程度的断裂,而本文所提网络的分割结果更接近于真实的标注图像,因此,基于轻量级CNN-Transformer 混合构架网络在无人机图像中对梯田区域的分割时,对梯田的形状、位置、轮廓等信息分割较为准确。
4 结论
本文针对无人机图像梯田道路边界模糊、具有较长的带状结构、环境复杂多变等特点,在MobileVit 模型的基础上,采用编码器-解码器结构,提出了基于轻量级CNN-Transformer 混合构架网络的无人机图像梯田区域语义分割模型,选取了PSPNet、LiteSeg、BisNetv2、Deeplabv3Plus、MobileVit 5 种模型进行对比测试,得出以下几点结论:
1)基于轻量级CNN-Transformer 混合构架网络模型在编码器部分引入了条形池化、轴向注意力机制以及空洞空间金字塔池化,增大了模型的感受野,解决了远距离信息之间没有相关性的问题,实现了以简单的训练方法和较少的参数更有效地从大量语义信息中提取高层次语义的特征图。
2)在精度方面,本文模型的像素精度为95.79%,平均像素准确率为87.82%、平均交并比为80.91%以及频权交并比为94.86%,比改进前的MobileVit 模型分别提高了6.10、4.56、9.62、7.01 个百分点,在对复杂无规则的无人机图像梯田区域分割中比其他几种模型更具优势。
3)在轻量化方面,本文模型参数量只有8.32 M,尺寸小、计算复杂度低,帧率为51.91 帧/s,具备实时性,是轻量级实时语义分割模型。将其部署在无人机上,可以很好地满足移动视觉任务轻量化、高精度及低延迟的需求,在对无人机图像中梯田区域的分割时,可以准确的分割出复杂梯田区域对象,进一步获取梯田的形状、位置、轮廓等信息,及时准确地掌握梯田边缘信息为预防和修护加固梯田提供重要的依据,同时有助于梯田区域种植面积和范围的统计,推动梯田和旱作区农业建设的发展。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
开放教育研究(2020年2期)2020-03-31
艺术品鉴(2019年12期)2020-01-18
计算机技术与发展(2019年1期)2019-01-21
乡村地理(2018年2期)2018-09-19
民族音乐(2017年4期)2017-09-22
现代语文(2016年21期)2016-05-25
乡村地理(2015年3期)2015-11-10
