
基于词袋模型的地铁车辆螺栓丢失故障检测*
2023-09-29 05:52戚玮玮柴晓冬郑树彬张乔木
计算机与数字工程 2023年6期
刘 桂 戚玮玮 柴晓冬 郑树彬 张乔木
(上海工程技术大学城市轨道交通学院 上海 201620)
1 引言
地铁车辆的螺栓故障检测对地铁的安全运行具有重要意义,为了保障车辆高效安全的行驶,检修人员会在每日车辆回库后,通过用眼看的方式对车辆进行检查,但是因为螺栓体积小、数量多、位置隐秘、特征不明显,检查时耗时耗力,且检修标准无法统一质量无法确保。
随着图像识别算法的不断更新与优化,目前行业内已经出现了利用图像分类识别技术来检测螺栓的状态。图像分类的第一步是提取目标的特征并描述图像,第二步利用分类器判别目标类别,李静[1]等提出了一种基于方向梯度直方图特征和支持向量机(Support Vector Machine,SVM)结合的检测螺栓的方法,可以很好地将螺栓识别出来;胡绍海等[2]通过螺栓丢失的区域会产生暗边缘丢失,形成一个半径更小的亮边缘效应,然后结合FAST 角点特征检测对动车底板螺栓进行故障检测;吴应永[3]等首先通过提取螺栓图像的尺度不变特征(Scale-Invariant Feature Transform,SIFT),然后通过SVM 分类器完成对螺栓故障的分类,类似的方法还被广泛应用于车牌检测[4]、发动机轴承盖分类[5]、户外天气状况识别与分类[6]、滚动轴承故障诊断[7]等领域。
本文基于此背景,提出了基于词袋模型的螺栓丢失故障检测方法,首先通过滑动窗口产生丢失螺栓的候选区域,然后利用Harris-SIFT 提取特征,特征聚类构建词袋获得词袋描述向量,SVM分类器对候选区域进行检测,获得了较高的准确率,具有一定的实用性。
2 基于词袋模型的地铁车辆螺栓丢失故障检测
词袋模型[8]最初用于解决文本分类问题,它不考虑文本中每个单词的含义和语法,通过将文本视为单词的组合,构建词汇表,并对每个文本中的单词信息进行统计,因其计算量小,运行效率较高,深受研究学者的喜爱。2003 年,Sivic[9]等成功将词袋模型引入到目标检测领域。基于词袋模型的目标检测由四个部分组成:提取图像的底层特征、创建词袋、构建图像的词袋描述和分类器检测。因此本文方法的整体流程如图1 所示,整个流程分为两个阶段:第一阶段为训练阶段,首先人工截取地铁车辆轴箱图片的螺栓图片,获得丢失螺栓和正常状态螺栓的的样本集,然后使用Harris-SIFT 结合算法对提取特征和描述,构建词袋,利用词袋统计每幅图像中每个单词出现的次数,从而获得每幅图像的词袋描述向量,最后将每张图像的词袋描述向量送入SVM 分类器进行训练,获得检测模型。第二阶段为检测阶段,本文检测时以整个轴箱图片作为输入,使用滑动窗口在输入图像上多尺度扫描,每扫描一次获得一个图像块,对图像块提取Harris-SIFT 特征,并通过词袋得到图像块的词袋描述向量,使用训练好的分类器对其进行分类预测,判断螺栓是否丢失,对重叠框使用非极大抑制,最后输出最终检测结果。
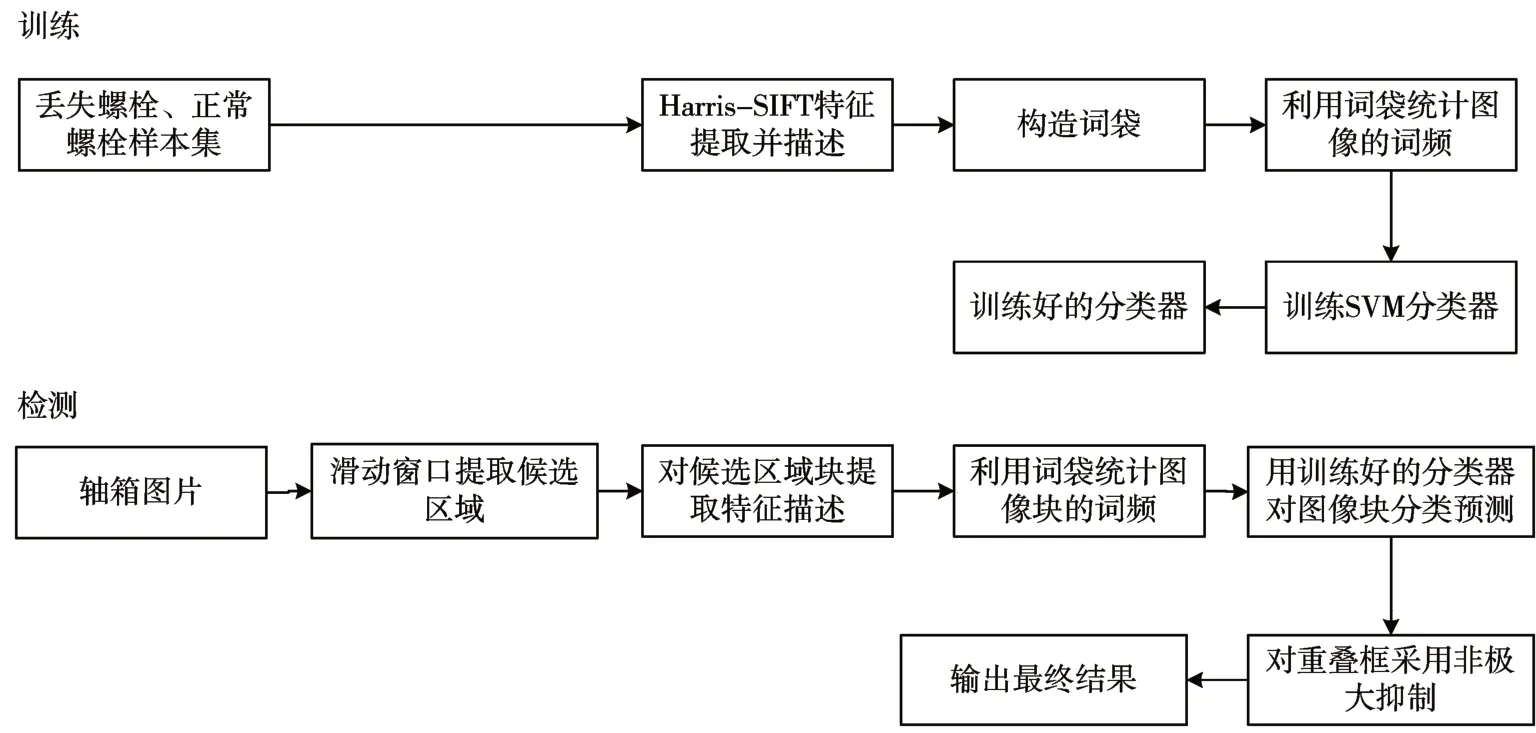
图1 基于词袋模型的螺栓丢失故障检测流程
3 具体过程
3.1 候选区域提取
候选区域提取是传统目标检测的第一步,滑动窗口法是选择候选区域的经典算法。滑动窗口,顾名思义就是使用一个比图像小的窗口以一定的步长在整个图像上滑动,得到候选区域,如图2所示。

图2 滑动窗口示意图
3.2 特征提取
Harris[10]算子是一种角点检测算法,它基于图像的灰度特征,运用图像中灰度值的变化完成特征检测。SIFT[11]是由加拿大教授David G.Lowe 在1999 年提出,2004 年完善总结的一种特征描述子,对旋转、尺度变化、亮度变化具有很好的不变性和稳定性,也是一种常用的图像底层局部特征提取算法。但是因为其算法的第一步中通过构建高斯差分尺度空间,并将空间内所有极值点去除边缘效应后作为特征点,计算量大且会生成许多无用的特征点影响计算时间,且Harris 算法已经可以清晰地标记出丢失螺栓的框架,因此本文考虑将Harris 算法与SIFT 算法结合,先对图像进行Harris 特征点检测,然后再用SIFT 算法对特征点确定方向和描述,使得特征提取算法更加简单,效率更高。
Harris-SIFT算法的主要步骤如下:
1)计算图像I中像素点(x,y)在水平和竖直方向上的梯度Ix和Iy和两个方向梯度的乘积Ixy;
2)将图像I与高斯函数卷积,分别计算G*Ix,G*Iy,G*Ixy,生成像素点(x,y)处的自相关矩阵M:
3)计算该像素点处的Harris响应值CRF:
其中,det(M)和trace(M)分别是矩阵M的行列式和直迹,k是一个常数,一般为0.04~0.06,本文取0.04;
4)在以像素点(x,y)为中心的邻域内,判断点(x,y)的CRF值是否是该邻域内的最大值,若是,则将其标记为特征点;若不是,则跳过;
5)为特征点指定方向:按照图像梯度的方式给每个特征点分配稳定方向;对于已经检测到的特征点,先求最接近当前尺度值的高斯图像:
使用有限差分,计算以特征点为中心,3×1.5σ为半径的区域内图像梯度的幅角和模值,幅角和模值的计算公式如下:
通过直方图统计像素点邻域内的梯度方向和模值。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。直方图的峰值代表特征点的主方向;
6)生成特征描述子:对特征点当前的尺度周围像素区域进行分块,计算每个分块内的梯度直方图,生成特征描述子。取特征点周围一个16×16 的窗口作为邻域,再计算该窗口内每个像素点的梯度方向和大小。然后,将该窗口划分为16 个4×4 的子区域,统计每个子区域中不同方向梯度的大小。在统计过程中,将原先36°的10 个方向缩减为45°的8 个方向。最后,每个子区域内都可以获得一个由8 个方向上梯度大小组成的8 维特征矢量,而整个窗口则可以获得一个16×8=128 维特征矢量,该矢量就是特征点最终的描述向量。
3.3 构建词袋
对所有图像按照Harris-SIFT 算法进行特征提取,每张图的特征点数量不一样,无法直接应用分类器进行分类,因此在使用分类器训练前,需要将整个图像表示为一个多维向量。而且通过Harris-SIFT 提取的特征为128 维向量,在存储和后续计算具有一定的困难,因此有必要采用K-Means聚类算法对该特征向量进行聚类操作,此步骤不仅解决了特征点数目不一无法分类的问题,同时解决了上一步提取的特征向量无法高维不便计算的问题。
K-Means[12]算法作为一种最常用的聚类方法,因计算流程简便,被广泛用于词袋模型中。它的主要实现步骤是[13]:1)首先随机选取k个特征点作为初始聚类中心;2)计算每个特征点与聚类中心的相似度即欧式距离,并将特征点划分到距离最近的类中;3)根据上一步的结果,通过取类中特征各自维度的算数平均数,重新计算得出新的聚类中心;4)重复2)、3)操作直到新旧聚类中心的距离为0或者达到设置的迭代次数为止,此时的k个聚类中心就是k个基础单词,词袋构建完成。
获得词袋后,图像的高维Harris-SIFT 特征便可以通过矢量量化转换为词袋描述向量。矢量量化的具体过程为对于提取的Harris-SIFT 特征,分别计算它与词袋中k个单词间的欧式距离,使用与其距离最近的单词代替这个特征,再统计图像中每个单词出现的次数,就可以得到图像的k维的词袋描述向量,每张图片均可表示为一个词袋描述向量。
3.4 分类
得到图像的词袋向量后,为了进一步完成图像分类,需要建立分类器。SVM[14]是词袋模型中最常用的分类器,核心思想是寻找一个使得分类间隔最大化的分类超平面,在解决小样本、线性或非线性问题上具有较好的优势。在实际场景中,非线性可分的特征样本空间更为常见,此时SVM 需要运用核函数将低维样本空间映射到一个更高维的特征空间,并在高维空间中构建最优分类超平面来完成分类。因螺栓图片两两之间较为相似,特征点分布趋近,因此难以通过简单的线性分割平面进行分类,又因径向基核函数非线性能力强,也是目前应用最广泛的核函数,所以本文选径向基核函数作为分类器核函数。
4 实验结果与分析
4.1 数据集
本文选用上海地铁9 号线地铁车辆图片作为数据集来源,共有400 张轴箱端盖图片,如图3 所示,图片的大小为2000×4096px,其中螺栓均为正常状态。因在实际场景中,螺栓丢失的情况极少出现,需要通过PS 来模拟螺栓脱落丢失的情景,如图4 所示,最终本文数据集共400 张,其中200 张螺栓正常轴箱图片,200张存在螺栓丢失轴箱图片。

图3 地铁车辆轴箱正常图

图4 地铁车辆轴箱丢失螺栓图
本节实验分为两部分,第一部分是基于词袋模型对螺栓紧固状态检测,因螺栓仅是整个轴箱的一小部分,本文通过人工截取的方式,采集了400 个丢失螺栓,400 个正常螺栓,图片大小均为150×150,部分数据集如图5所示,上面5个是正样本,下面5 个是负样本;第二部分测试词袋模型对轴箱图像中螺栓丢失的检测效果。

图5 部分样本示意图
4.2 词袋模型对螺栓的紧固状态检测效果
首先构造了标准的训练集和测试集图库,正样本图像为丢失螺栓图,总共400 张;负样本图像为正常状态螺栓图共400 张,然后选取其中300 张正样本和300 张负样本当作训练集,并对这600 张图像在经过Harris-SIFT 特征提取后构建词袋模型并进行描述,得到相应的K 维向量,将得到的向量进行标记后送入SVM 分类器,完成训练;最后将剩下的100张正样本图像与100张负样本图像作为测试集,用于测试词袋模型的效果。
表1 是基于词袋模型的丢失螺栓目标检测算法的混淆矩阵,其中TP表示丢失螺栓检测为丢失的个数,FP丢失螺栓检测为正常螺栓的个数,FN表示正常螺栓被检测为丢失的个数,TN表示正常螺栓检测为正常的个数。本次实验以识别准确率ACC作为评价指标,公式如式(6)所示。

表1 基于词袋模型的丢失螺栓目标检测算法的混淆矩阵
表2 反映了视觉单词个数K的取值大小与检测准确率ACC 变化关系。由表可知,单词数为70时,准确率最高达到了95.5%,当K值低于70 时,K越大,准确率越高;当K值大于70时,准确率随着K的增大而下降。理想状态下,聚类的类别数越多,则词袋模型中用于描述图像的单词越多,描述就会越详细,检测的准确率越好。但是当K值增大到一定程度时,很多相似或相同的特征可能就被划到不同的视觉单词类中去,使得到词袋变得庞大复杂,大大增加了模型的复杂度,检测的准确率也随之下降。

表2 不同单词数的准确率
4.3 轴箱的螺栓丢失故障检测效果
在轴箱图片中,螺栓占整幅图的大小不足百分之一,所以在使用词袋模型对其中的螺栓状态检测前,本文需先使用滑动窗口选择候选区域,再使用表2 中分类准确率最高的K值进行实验。在滑动窗口中,一般需要建立图像金字塔,在每一层图像上使用150×150的滑动窗口以步长20进行扫描,每扫描得到一个图像块,使用词袋模型训练好的的SVM分类器对图像块判断是否是脱落螺栓,若有则保存,没有则继续滑动。在判断检测的过程中由于是多尺度逐行逐列扫描,所以在螺栓丢失的位置可能会做多次标记。本文采用目标检测中一种标准的方法:非极大值抑制[15]的方法,根据在一定区域内的检测响应值,比较其大小,取最大的保留,这样在图像中的螺栓脱落位置就不会重复的标记保存,检测结果如图6所示。

图6 丢失螺栓轴箱检测结果图
本次实验检测100 幅螺栓丢失轴箱图中实际含有丢失螺栓106 个,依次对100 幅图片进行目标检测,共耗时8min,平均1 张图片耗时4.8s,最终检出丢失螺栓97 个,因此检测丢失螺栓准确率为91.5%。
5 结语
以地铁车辆轴箱端盖的丢失螺栓为检测目标,本文提出了一种基于词袋模型的螺栓丢失状态检测方法。首先特征提取时将Harris-SIFT 算法结合,减少计算量,然后对其构建词袋模型,获得图像的词袋描述后送入SVM 分类器中进行训练,并不断调整参数获得具有最高准确率的模型。实验结果表明,本文方法是一种有效、可靠的螺栓丢失故障检测方法。本文仅研究了螺栓的丢失一种异常状态,在此基础上可以进一步对螺栓松动等其他故障检测进行研究。
猜你喜欢
中国特种设备安全(2022年5期)2022-08-26
装备制造技术(2021年2期)2021-07-21
四川建筑(2020年1期)2020-07-21
制造技术与机床(2019年12期)2020-01-06
减速顶与调速技术(2018年1期)2018-11-13
电子测试(2018年1期)2018-04-18
制造技术与机床(2017年8期)2017-11-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
铁道运营技术(2015年3期)2015-12-23
