
融入句法结构信息的句子级情感分析算法*
2023-09-29 05:51李成路
计算机与数字工程 2023年6期
李成路 许 凤
(1.南京理工大学计算机科学与工程学院 南京 210094)(2.南京财经大学会计学院 南京 210023)
1 引言
句子级情感分析作为自然语言处理(Natural Language Process,NLP)领域的入门级任务,自深度学习从计算机视觉及语音识别领域被迁移至NLP任务中后,已有大量的研究工作对长短不一的文本进行建模,依据对文本处理方式的不同,这些研究工作提出的深度学习模型大致可分为两类,一类是对文本按序列化形式建模,代表的深度学习模型有卷积神经网络(Convolutional Neural Network,CNN)[1~2]、循环神经网络(Recurrent Neural Network,RNN)[3]和长短时记忆(Long Short-Term Memory,LSTM)网络[4]等,另一类是对文本的句法结构树进行建模,代表的深度学习模型有递归神经网络(Recursive Neural Network,RvNN)[5]和树状长短时记忆(Tree-structure LSTM,Tree-LSTM)网络[6]。
在过去的研究工作中,序列模型因其训练速度快,模型只需按从左至右、从下到上的顺序实现,CNN、RNN 和LSTM 等常用的基础深度学习模型都封装在各大深度学习框架工具中,而Tree-LSTM 网络一直因其训练数据是以文本句法解析树的形式表示,并且每棵句法解析树的形状不同,这就导致了该网络不能批量训练且收敛速度慢,加上文本的句法结构信息难以利用,相比之下,有关的研究工作略显少了些。
近年来,Gan 等[7]就如何将文本的序列信息和句法结构信息相融合做了很多研究,大多是先用LSTM之类的序列模型先编码文本得到每个词的隐藏表示,再作为Tree-LSTM 网络中叶子节点的初始化表示,这方面的研究提供了同时利用文本序列信息和句法结构信息的新思路。Williams等[8]总结了关于文本潜在句法结构(Latent Syntactic Structure)的研究工作,并说明潜在句法结构大都不符合规范的句法规则,并且对句子级情感分析任务的提升也是有限的。因此本文利用的文本结构化信息是通过规范化的句法解析器解析得到的,因为这样更易于根据下游任务从句法解析树中提取利于提高模型效果的重要句法结构信息。
2018 年Google AI 团队提出了BERT 模型[9],BERT模型在句子级情感分析任务上的效果远远超过了之前常用的深度学习模型,紧接着,Wang等[10]在Transformer 中引入了文本的句法结构信息,BERT 模型其实就是由多层的Transformer 组合而成,这说明融入文本的句法结构信息到最新的深度学习模型中的可能性。Jawahar 等[11]表示BERT 模型的较低层可以捕捉文本的短语信息,中间层可以捕捉文本的句法结构信息,而较高层可以捕捉文本的语义信息,并且还通过实验发现BERT 模型可以隐式地学习到一些文本句法解析中比较常见的句法树结构。但是,近两三年来还未有研究工作提出如何让只接受序列数据的BERT 模型能够巧妙地显示地利用文本的句法结构信息。
针对BERT 模型的这一不足,本文提出了Tree-BERT 模型让文本的句法结构信息融入到BERT 模型中。该模型受知识蒸馏(Knowledge Distillation,KD)[12~13]里Teacher-Student 模型框架的启发,以模型参数较轻量级的Tree-LSTM 网络作为Teacher model 指导Student model 参数较重量级的BERT 模型,让BERT 模型能显示地利用文本的句法结构信息从而进一步提高BERT 模型在句子级情感分析任务上的准确率。
2 Tree-BERT模型
图1 展示了Tree-BERT 模型的整体框架,从图中可以看出模型主要分为左右两部分,左边是Tree-LSTM 网络用来提取文本的句法结构信息,右边BERT 模型将Tree-LSTM 网络中节点产生的可训练样本作为输入,按知识蒸馏理论里定义的损失函数计算样本的损失值,对BERT 进行微调(Fine-tune)。下面具体介绍两部分模型。

图1 Tree-BERT的整体模型框架
2.1 Tree-LSTM提取句法结构信息
本文将含有n个词的句子表示为s={x1,x2,…,xn} ,句子的真实情感标签,或称为硬标签(hard label),记作yℎard_label,由Teacher model预测文本得到的情感概率分布称为软标签(soft label),记作ysoft_label。这两种标签的区别如图1 最上方浅蓝色块和浅黄色块所示,浅蓝色块表示训练样本的真实标签,采用One-Hot 表示方法,即只有该样本所属的情感类别位置的值为1,其他位置的情感值都为0,例如图1 中送给BERT 的训练样本“like this camera”的情感是积极的,那该样本的真实标签表示为yℎard_label={0,1};浅黄色块表示训练样本的软标签,是由Tree-LSTM 网络中节点的隐藏表示经过Softmax 分类器后得到的情感概率分布,即该样本属于某个情感类别的概率值,并且各个情感类别的概率值加和为1,例如图1 中该样本的软标签表示为ysoft_label={0.2,0.8}。
首先要让Tree-LSTM 网络在SST(Stanford Sentiment Treebank)数据集上学习文本的句法结构信息,该网络编码句子成分结构树的过程如图2 所示,具体计算公式如下:

图2 Tree-LSTM网络的训练和预测
其中ij,fjk,oj,uj,cj,ℎj同LSTM深度神经网络里一样,分别为输入门、遗忘门、输出门、输入表示、单元状态和输出的隐层状态,W,U,b均为可学习参数,N是指父节点所包含子节点数,对于成分句法树来讲N=2,即每个父节点只有左、右两个子节点。
接下来使用Stanford Parser[14]将目标领域训练集样本解析成句法树的结构,然后如图2 所示使用冻结参数的Tree-LSTM 网络计算句法树上每个节点的隐藏表示并得到每个节点的软标签,图2 虚线框中的文本是以该节点为子树的叶子节点上的词语组合而成,这样就构造了可以用于训练深度学习网络的“文本-软标签”样本,这样构造出来的样本就带有了句法结构信息。
2.2 微调BERT模型
如图1 右边所示,BERT 模型在扩充后的目标领域训练集上进行微调。具体的过程是在训练文本前后分别拼上[CLS]和[SEP]特殊标识符后作为BERT 模型的输入,经过BERT 模型计算后使用[CLS]特殊标识符的隐藏表示作为整句话的编码表示,最后送入Softmax 分类器得到训练样本的情感分类概率值,记作p,该样本最后的误差计算取决于样本的类别。
1)样本既有One-Hot 情感真实标签,即yℎard_label={y1,y2,…,yC} ,又有软标签,记作ysoft_label={y1',y'2,…,yC' },其中C为情感类别数,针对本章节中的句子级情感分析任务,因为只有积极和消极情感,显然C=2。那么该样本的损失函数由yℎard_label和ysoft_label与情感分类概率值p分别计算得到,两部分的损失函数都使用交叉熵损失函数(Cross Entropy Loss,CE),分别记作Lℎard_loss和Lsoft_loss,具体的计算公式公式如下:
2)样本只有软标签,那该样本的损失函数计算只要考虑Lsoft_loss,因为此时Lℎard_loss=0 ,即LCE=Lsoft_loss。
最后计算批训练样本的总损失值LBatcℎ_CE,计算公式如下:
其中B为批训练样本的样本数量。使用总损失值LBatcℎ_CE通过反向传播算法(Back Propagation,BP)[15]微调BERT 模型的参数,并在目标领域测试集上计算模型的情感分类准确率,记录分类准确率最高的结果。
3 实验
3.1 实验结果和分析
本文使用Yu 等[16]发布在会议EMNLP 上的三个数据集,分别是Camera,Restaurant和Laptop三个领域的二分类句子级情感分析数据集,使用情感分类准确率(Accuracy,Acc.)来评估模型的性能,计算公式如下:
其中N是样本总数,yn,ŷn分别是第n个样本的真实标签和预测标签,I(∙)为指示函数,即真实标签与预测标签一致时,I(∙)=1,否则,I(∙)=0。
本文比较了Tree-BERT 模型和设计的其他四个模型:
1)BERT(Target Dataset):BERT 模型在目标领域训练集上微调,在目标领域测试集上测试;
2)BERT(Merged SST):将SST训练集和目标领域训练集合并后作为新的训练集,BERT 模型在合并后的训练集上微调;
3)BERT(Twice fine-tune):合并SST 训练集和目标领域训练集时,为了避免两部分训练集因样本数量差距过大而影响BERT 模型在目标测试集上的效果,先让BERT模型在SST训练集上微调一次,再在目标领域训练集上微调一次,两次微调时评估模型的情感分类准确率都是在目标领域测试集上;
4)BERT-BERT:Teacher model 换成在SST 数据集上微调后的BERT 模型,Student model 依然是BERT模型。
观察表1 每一列的准确率可以看出与设计的四个模型相比,本文提出的Teacher-Student模型框架,即Tree-BERT模型在三个目标领域测试集上的准确率都有提高。

表1 Tree-BERT模型和其他模型在三个目标领域测试集上情感分类准确率比较
表1 第一行是一个最基础的基准模型(Baseline),即使用单独的BERT 模型在目标领域训练集上微调,对比发现,本节提出的Tree-BERT 模型的情感分类准确率在三个目标领域测试集上分别有2.2%,3%和2.5%的提高,说明使用Teacher-Student的框架结构,可以通过Teacher model先对文本中的句法结构信息进行“蒸馏”,然后指导Student model,即BERT模型,显式地学习“蒸馏”出的句法结构信息,从而提升了单独BERT 模型在句子级情感分析任务上的情感分类准确率。
设计表1 第二行的BERT(Merged SST)模型是因为Teacher model,即Tree-LSTM 深度学习网络,使用了额外的SST 训练集中的情感标签,所以将SST 训练集和目标领域训练集合并后让BERT 模型在扩充后的训练集上微调,对比第一行发现,简单地合并训练集,只能提升BERT模型在Camera测试集上的情感分类准确率,在其他两个目标领域测试集上的准确率是没有提升的。对比Tree-BERT 模型在三个目标领域测试集上的情感分类准确率,该模型的准确率分别下降了0.2%、3.5%和2.5%,说明SST 数据集中文本的句法结构信息不是简单合并训练集就可以让BERT 模型学习到的,体现了使用知识蒸馏方法先让Tree-LSTM 网络提取文本中的句法结构信息的优势。
考虑到简单合并训练集会出现样本不平衡问题,即最终微调好的BERT 模型的情感分类表现会更偏向于数据量大的训练集,导致模型在数据量相对小的目标领域测试集上的情感分类准确率下降,所以设计了表1 第三行的BERT(Twice fine-tune)模型,对比前两行的准确率,该模型在Restaurant和Laptop 两个测试集上的准确率提高了,在Camera测试集上的准确率略有下降,说明数据集之间的领域差异性是一定存在的;对比Tree-BERT模型在三个目标领域测试集上的情感分类准确率,该模型的准确率分别下降了1%,3%和1.5%,同样说明了在句子级情感分析任务上,通过知识蒸馏方法在BERT模型中融入文本句法结构信息给模型带来的提升要优于简单扩充训练集的方法。
为了体现Teacher model 使用Tree-LSTM 网络的优势,即“蒸馏”出的软标签蕴含更多的文本句法结构信息,设计了表1第四行的BERT-BERT模型,将Teacher model 换成BERT 模型来产生文本的软标签,让左路的BERT 模型先在SST 数据集上微调好后固定参数,然后用于预测Tree-LSTM 网络预测过的目标领域训练集上的短语文本的情感概率分布,即预测图2 中每个节点上对应的短语文本或者一个词的情感概率分布,构建的新训练样本扩充到原目标领域训练集中给Student model训练,也就是让右路另一个BERT 模型在扩充后的训练集上微调,结合表1 和表2 可以发现,虽然同样作为在SST训练集上调参到最优的Teacher model,Tree-LSTM网络在SST测试集上的准确率比BERT模型的准确率低3.5%,差距是比较大的,但是在三个目标领域测试集上的情感分类准确率,Tree-BERT模型要比BERT-BERT 模型分别高出0.6%,1.5%和0.5%,这说明使用Tree-LSTM 模型预测得到的软标签比用BERT模型预测得到的软标签蕴含更多的句法结构信息,因为Tree-LSTM 网络是显式地利用文本的句法树信息,该网络对文本句法知识的“蒸馏”会更准确,因此预测得到的软标签会把句法知识信息蕴含在情感概率分布之间,也就是说右路BERT 在微调时不仅在学习软标签显式的情感概率分布,更重要的是在学习蕴含在软标签中的句法结构信息特征;这两个模型的对比结果也支撑了本节最主要的贡献,即通过Tree-LSTM 网络“蒸馏”出文本的句法结构信息来指导BERT 模型显式地学习句法结构信息,Teacher model换作其他深度学习模型是达不到“蒸馏”句法结构信息这一效果的。
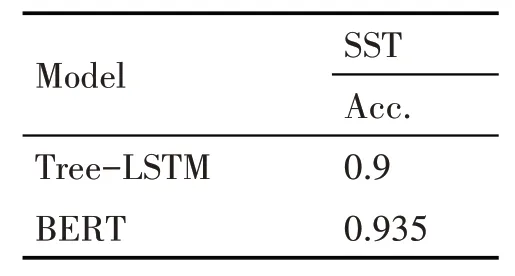
表2 Tree-LSTM和BERT在SST测试集上的情感分类准确率
3.2 实验中超参对模型效果的影响
在实验Tree-BERT模型的初期,实验结果还不是很好,在寻找问题所在和优化方法时,受Wu[17]等人处理文本句法树的启示,即限制文本的长度。考虑到Tree-LSTM 网络对节点的情感分类存在偏差,应当过滤掉一些节点构造的训练样本,从图2 中可以发现,网络中越高层节点对应的文本长度就越长,因此可以通过设置文本长度来过滤掉一些文本较短的训练样本,因为这些样本会对BERT 模型带来较大的噪声。在实验过程中,便设置了一个超参来控制训练集中文本的长度,用tℎresℎold表示,用来过滤掉扩充后的训练集中文本长度小于tℎresℎold的样本,但是拥有One-Hot真实标签的样本,即目标领域训练集最初的样本,它们的文本长度即使小于tℎresℎold也是要保留的。
从图3 中可以看出文本长度阈值对Tree-BERT模型在三个目标领域测试上的情感分类准确率的影响还是很大的,并且三个目标领域数据集上的总体变化趋势是一致的,随着文本长度阈值变大,情感分类准确率先升高再降低,不同数据集情感分类准确率的峰值所对应的文本长度阈值也不同。之所以该超参对准确率有较大影响,是因为Tree-LSTM 网络中上层节点相比叶子节点或低层节点的句法结构更复杂,那所蕴含的句法结构信息更加丰富,也更能表示整句话的情感倾向,并且太短的短语或者一个词语的情感倾向存在预测偏差,这会在微调BERT 模型时带入较大的噪声,因此根据短语文本的长度,过滤那些过短的短语或者一个词语的样本,可以提高扩充后目标领域训练集的质量。当然文本长度阈值也不是越大越好,因为Tree-LSTM 网络中高层节点的情感分类也存在较大误差,如果作为训练样本的话,也会给微调BERT模型时带来太大的噪声从而降低模型的情感分类准确率。

图3 文本长度阈值与Tree-BERT模型在三个目标领域测试集上情感分类准确率的关系
4 结语
本文受知识蒸馏方法的启发,以Teacher-Student框架为模型设计的基础,提出了Tree-BERT 模型将句法结构信息融入到了无法利用文本句法结构信息的BERT 模型中,创新性地提出了一种融合文本的序列信息和句法结构信息的新思路,也是知识蒸馏方法的一种新应用,同时也为提高模型在跨领域文本情感分析数据集上的性能提供了一条新道路。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学物理学报(2017年5期)2017-11-23
山西青年(2017年7期)2017-01-29
国际汉语学报(2016年1期)2017-01-20
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
新课程学习·中(2013年3期)2013-06-14
