
基于多模型组合方法的公平水库中长期入库径流预报
2023-09-27 07:40:56肖三明
江西水利科技 2023年5期
肖三明,刘 涛
(1. 汕尾市水利水电建筑工程勘测设计室,广东 汕尾 516600;2. 金风科技股份有限公司,中国 北京 100176)
0 引 言
中长期径流预报是指根据前期或现时已经发生的水文、气象、海洋等多源信息,基于水文学、气象学、水力学、统计学等多学科原理,对河流、湖泊等水体3 天以上、1 年以内的径流趋势做出定性和定量的准确性预报[1]。准确的中长期径流模拟计算,对于研究流域产汇流规律、中长期水文预报、受水区水资源优化配置以及供水规划制定等工作具有重要意义。
国内外关于中长期径流预报方法的研究有很多,大体上可分为三类:统计模型、水量平衡模型以及人工智能模型。统计模型主要是基于数理统计的方法,根据自变量自身的周期反复性,采用数学统计方法建立的模型,例如多元回归模型[2,3]、时间序列模型[4,5]等;水量平衡模型预测主要是以水量平衡为基础理论,基于已经构建好的流域水文模型,将未来的气象预报结果作为数据驱动,预测未来的径流量变化,具有代表性的有新安江模型[6]、两参数水量平衡模型[7]等;人工智能模型主要是基于智能算法对大量数据样本之间的隐射关系进行数据挖掘,构建从“数据”到“径流量”之间的非线性关系,从而实现径流的中长期预报,例如神经网络模型[8,9]、支持向量机模型[10]以及随机森林模型[11]等等。虽然随着计算机水平和深度学习的不断发展,人工智能模型正越来越多的被应用在了水文预报领域,并取得了较好的模拟效果,但是由于水文规律的复杂性及其自身的不确定性,目前为止还未有一种模型能够始终具有最优的模拟精度[11,12],因此基于多模型信息融合的组合预报模型,在综合考虑了各模型优势的基础上,往往能够取得令人满意的预报效果。
为获取准确可靠的水库中长期预报结果,本文以公平水库为研究对象,在预报因子筛选的基础上,对比并分析不同的月入库径流预报模型,并采用线性与非线性组合两种方式构建组合预报方案,研究成果可为公平水库的月径流预报与中长期水文模拟提供指导。
1 研究方法
基于气象因子影响的物理机制,结合数理统计方法与随机森林重要性分析结果,对气象因子进行预报因子筛选,以1961 年~2006 年作为模型训练集,2007~2017 年作为模型验证集,分别选取季节性自回归(SARIMA)、随机森林(RF)、支持向量机(SVM)和极度梯度提升树(XGBoost)4 种模型进行中长期入库径流预报模型的构建。为充分考虑各模型的优势,扬长避短,有效提高径流预报精度,采用线性与非线性2 种方式对4 种模型进行组合。
1.1 线性组合预报
线性加权进行组合预报的方法最早是由Bate 提出的[13,14]。其基本思想就是首先在同一流域的相同时刻利用不同的预报模型对河道径流量进行预报,然后根据不同模型的预报结果确定各模型的权重,最后通过线性加权的方式得到组合预报结果,其计算公式如下:
式中:Qt表示第t 时刻的组合模型预报结果;m 表示参与组合的单一模型个数;ωi表示第i 个单一模型的权重值,qi,t表示第t 时刻第i 个单一模型的预报结果。
因此,线性加权组合预报方法的不同之处在于权重值ω 的确定,当ω 确定了以后,组合模型也就随之确定。目前权重的求解方法主要有简单加权平均法、加权几何平均法、信息熵定权法、贝叶斯模型平均法以及人工智能优化算法等。本文以纳什效率最大为目标函数,基于带有精英策略的快速非支配排序遗传算法(NSGA-Ⅱ)对随机权重进行优化,以期得到最优的权重组合。
1.2 非线性组合预报
对于各模型之间的关系,往往无法通过单一的线性方法进行表征,恒定的最优权重组合通常不能代表任意时刻的最优解,传统的线性加权方式可能无法充分发挥各单一模型的优势,为尽可能地利用预报信息,采用非线性组合的方式进行预报成为了目前组合预报的一种新途径。在理论情况下,若训练样本数量足够多,训练次数足够充分,人工神经网络能够以任意精度逼近任意非线性映射关系。因此本文尝试采用BP 人工神经网络进行多模型之间的非线性组合,将各模型的预报结果输入至神经网络中,通过模型训练寻找各模型之间最优的非线性关系,然后构建组合预报模型,对流域径流进行预报。人工神经网络的搭建基于Python语言机器学习算法库Sklearn 中的Neural Network MLPRegressor 回归预测模型实现。
2 实例验证
2.1 研究区概况及数据来源
本文选取公平水库月入库径流预报作为研究对象。公平水库位于广东省汕尾市海丰县境东北部的黄江河上游中部,是集防洪、灌溉、发电、供水等于一体综合利用水资源的重要水利枢纽工程。水库集雨面积317km2,原设计总库容2.296 亿m3,正常库容1.633 亿m3,相应水位16m,兴利库容为1.461 亿m3。公平水库所在流域属亚热带季风气候区,海洋性气候明显,冬季温暖,夏季炎热,干湿季节分明。水库处于粤东暴雨高区中心,降雨量丰富,但年内年际分布极不均匀,多年平均降雨量为2322mm,平均气温约22℃。
数据资料来源:公平水库管理局的月平均入库径流以及月累积降水数据;中国气象局国家气候中心(https://cmdp.ncc-cma.net/Monitoring/cn-index-130.php)的气象因子数据,包括88 项大气环流指数、26 项海温指数以及16 项其他指数。数据的时间跨度均为1961~2017 年共57年。
2.2 预报因子筛选
本文选用1961~2017 年的130 项气象因子作为初始预报因子。首先通过成因分析法逐一对各因子的物理机制进行分析,去除无显著影响的因子,实现对预报因子的初步筛选。然后通过随机森林重要性排序方法对初步筛选的预报因子进行重要性分析,据此对预报模型的关键预报因子进行筛选。选取各月份重要程度前5 的因子作为公平水库月入库径流的预报因子,因子筛选结果如表1 所示。

表1 公平水库关键预报因子筛选结果

表2 公平水库不同单一模型预报精度
从表1 公平水库的关键预报因子筛选结果可以看出,临近月份的关键预报因子存在相似性。例如4~7月,随机森林法均将8 月赤道中东太平洋200hPa 纬向风指数作为关键预报因子,这符合气象指数对流域降雨径流影响的长时效性规律,同时也表明气象因子筛选结果的可靠性。
2.3 单一模型预报结果
SARIMA 模型表征径流量自身的变化规律,起始训练期定义为1961~1966 年,然后逐年份不断增加样本数据,并预测下一年的逐月入库径流量,直至年份滚动至2007 年,以Nash 系数最大为目标率定模型参数;RF、SVM 和XGBoost 模型以筛选出的各月份关键预报因子为数据输入,逐月预测入库径流量,率定的目标函数与SARIMA 模型相同。公平水库4 个单一模型逐月径流预报结果见图2。

图2 公平水库各单一模型逐月预测结果
可以看出,SARIMA 模型对于月入库径流的趋势拟合较好,径流量呈现明显的周期性变化,但对于低水部分,尤其在非汛期,SARIMA 模型出现模拟结果整体偏高的问题。验证期中的2009 年7~9 月,为公平水库自1961 年以来同时期最低,入库水量均低于5000 万m3,而各模型的模拟结果均较实际值更高,偏差较大。出现该问题的原因主要是由于在过去的一段时间内,太平洋出现了较长时间的拉尼娜事件,使得其海温较往年的同时期更低,无法将海洋中的水汽蒸发至大气中,大大减少了降水量,造成了较为严重的极端气候。而在公平水库7~9 月挑选的预报因子中,训练期对于模型的模拟精度影响较大,但由于2009 年径流量显著降低的原因为海温,因此各单一模型的模拟结果均较差。
从四个单一模型的径流预报精度可知,RF 模型在4 种单一预报模型中的径流预报效果最好,在率定期的Nash 系数为0.93,验证期为0.77,整体上达到了乙级预报精度。受限于水文数据时间序列较短的影响,RF 模型与XGBoost 模型在训练期精度较高,但其验证期的精度却有较大程度的下降,模拟结果出现了略微的过拟合现象。SARIMA 模型与SVM 模型的预测结果较另外两种模型的精度明显更低,训练期的Nash 效率系数仅为0.68 与0.73,验证期为0.52 与0.58,仅达到丙级预报精度。分析其原因,SARIMA 模型仅考虑了径流量本身的变化规律,当遇到气象因素或人类活动影响较大的阶段,径流量自身很难有较为稳定的变化趋势,因此其模拟结果较差;而SVM 模型在预测阶段,需寻找输入数据的超平面并以此作为分类依据,各关键气象因子之间的分类界限并不十分清晰,模糊的超平面界限最终影响了模型的模拟结果。
2.4 组合模型预报结果
线性组合方面,以Nash 效率系数最大为目标函数,基于NSGA-Ⅱ算法对各模型的最优权重值进行求解,通过50 次迭代后,得出的各模型权重值分别为0.09(SARIMA 模型)、0.12(SVM 模型)、0.40(XGBoost模型)和0.39(RF 模型),基本与各单一模型的整体模拟精度呈正相关。基于神经网络的非线性组合方面,激活函数选择为tanh,基于quasi-Newton 优化器(lbfgs),将隐含层设置为3 层,分别为(45,24,50),正则化项参数alpha 确定为0.66。两种组合模型的径流预测结果如图3。

图3 公平水库组合预报模型结果
对比图3 与图2 模型组合前后的模拟结果可以看出,无论是训练期还是验证期,充分考虑了径流量自身以及海洋气象因子变化规律的组合模型较任何单一模型的月入库径流量均更接近实测值。对比线性与非线性组合两种方式,非汛期低水部分的模拟结果均较好,无论是从量级上还是趋势上都有较高的模拟精度,而对于高水部分的汛期而言,由于线性组合对于任意时刻的各模型权重值均采用相同的数值,往往无法充分考虑不同预报模型在不同时刻的优劣,因此其模拟结果较非线性组合略差。与单一模型相同的是,受极端海温的影响,组合模型在2009 年汛期的模拟结果同样较真实值更高。
两种组合模型的径流预报精度见表3。可以看出,通过线性加权与非线性加权两种组合方式对于公平水库月径流预报的Nash 系数与相对平均误差均有较大幅度的提升。以非线性组合为例,一方面,不仅其Nash系数优于任意单一模型,同时还有效降低了水量预报误差,训练期与验证期较单一模型的最优值分别降低了4.59%和7.41%,充分说明采取多模型组合的方式与单一预报模型相比,能够实现公平水库月入库径流的更优预报;另一方面,验证期模型预报精度的增量较训练期更大,表明非线性组合能够适当地解决单一机器学习模型的过拟合趋势,有效提高了模型的泛化能力。
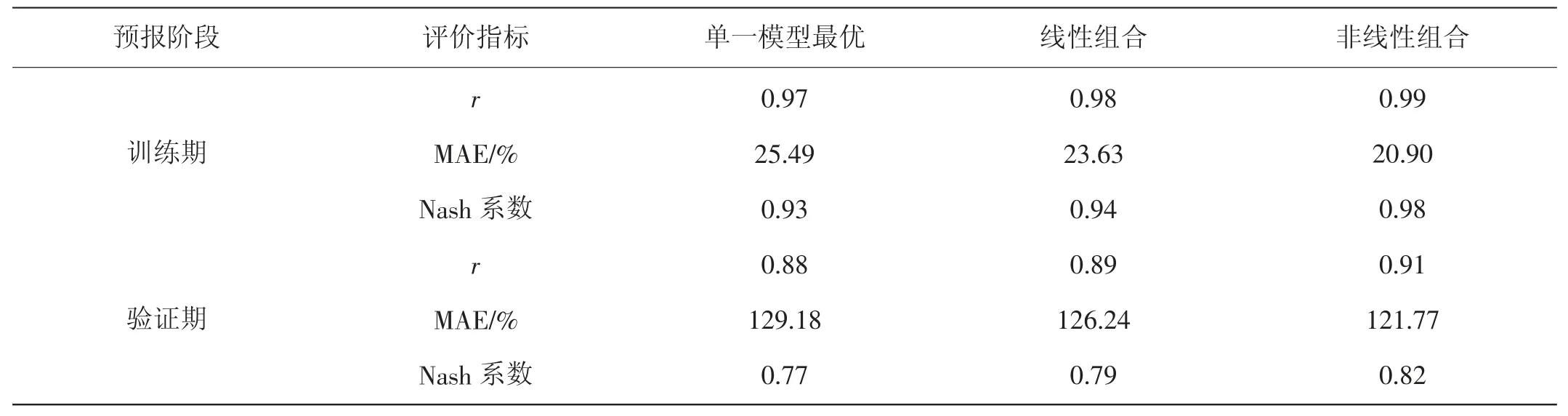
表3 公平水库组合预报模型精度
对比线性组合与非线性组合两种方式,考虑任意时刻不同权重值的非线性组合较前者的径流预报结果更优。训练期与验证期的Nash 系数较线性组合分别提高了0.04 和0.03,水量预报误差分别降低了2.72%和4.47%,对于中长期预报而言,水量预报误差的大幅降低能够有效提高预报模型的应用效果,因此基于神经网络的非线性组合方式较传统线性组合方式更有利于为公平水库兴利除害提供决策支持。
3 结论与展望
本文以公平水库为研究对象开展月入库径流预报研究,在筛选不同月份预报因子的基础上,对比分析了4 种常用月径流预报模型的模拟结果,并采用线性与非线性2 种方式构建多模型组合方案,得到的主要结论如下:
(1)RF 模型与XGBoost 模型的模拟结果较为稳定,训练效果良好,RF 模型在4 种单一模型的径流预报结果中表现最优。受到极端海温的影响,4 种单一模型对于验证期2009 年汛期的径流预报结果均出现偏高现象。
(2)多模型组合方式较单一模型的模拟结果更优,不仅能够获得更优的Nash 系数值,有效降低预报水量误差,同时还能够适当解决单一机器学习模型的过拟合趋势,提高模型的泛化能力。非线性组合与传统的线性组合方式相比,能够更加合理有效地利用各单一模型的优势,在训练数据长度一致的情况下,达到更优的径流预报结果,能够为公平水库的兴利除害提供决策支持。
(3)在后续研究工作中,应着重考虑输入不确定性与参数不确定性对组合模型的影响,构建公平水库不确定性中长期径流预报方案。同时还应采用深度学习等其他机器学习模型对单一模型进行组合,降低水文时间序列不足的影响,提高预报模型的泛化能力。
猜你喜欢
房地产导刊(2021年10期)2021-11-22 07:43:34
中国食品(2021年2期)2021-02-24 03:55:35
水利规划与设计(2017年5期)2017-06-09 08:56:23
水利科技与经济(2016年9期)2016-04-22 01:07:12
人间(2015年8期)2016-01-09 13:12:42
交通建设与管理(2015年15期)2015-03-20 15:19:31
交通建设与管理(2015年15期)2015-03-20 15:19:01
水土保持通报(2014年5期)2014-06-09 08:27:00
吉林地质(2014年4期)2014-03-11 16:48:17
湖南水利水电(2014年3期)2014-02-27 14:46:05
