
基于车辆横向运行数据的遗传-支持向量机算法的分心驾驶状态判别模型
2023-09-27 09:03文香邓超
科学技术与工程 2023年25期
文香, 邓超,2,3,4*
(1.武汉科技大学汽车与交通工程学院, 武汉 430065; 2.武汉科技大学智能汽车工程研究院, 武汉 430065; 3.四川省无人系统智能感知控制技术工程实验室, 成都 610225; 4.云基物联网高速公路建养设备智能化实验室, 济南 250357)
分心状态是造成交通事故的重要原因。Carney等[1]发现在追尾事故中,超过75%的人有潜在的分心驾驶行为,最常见的分心行为分别为使用手机、观察车外及与乘客交谈。使用手机会对驾驶人控制活动的强弱、灵敏程度及稳定性造成影响[2]。因此深入研究分心驾驶,对减少交通事故具有重要意义。
目前,相关学者从多个角度对分心驾驶状态指标进行了研究,如头部位置[3]、眼动特征[4]、面部表情及嘴部变化[5]、脑电信号[6]、皮电信号[7]、心率变异性及心电信号[8]、方向盘转角[9]、车头时距、纵/横向加速度、速度及车道位置[10],以及融合驾驶绩效与生理活动指标[11]、生理特征与眼动指标等。其中,驾驶人行为检测方法主要依赖于摄像头进行图像识别。此方法易受周围环境(如光照)、设备位置及复杂事件的影响,造成误报率相对较高。基于生理心理的检测方法需要驾驶员佩戴脑电仪、生理心理反馈仪等医学设备,通过侵入式方法检测驾驶员是否处于分心状态。此方法成本高,且侵入式检测可能会影响驾驶任务,在实际驾驶场景中难以实现。基于驾驶绩效的分心检测成本较低且易获取数据,在实际应用中可通过CAN总线采集车辆运行数据进行检测,适用性较强,且数据较为可靠。
随着对分心驾驶的深入研究,不同分类算法被应用于分心状态判别。主要包括AdaBoost[12]、长短期记忆神经网络[13]、支持向量机(support vector machine,SVM)[14]、迁移学习[15]等。周扬等[16]将迁移学习与Grad-Cam算法方法相结合,对驾驶行为的重点关注区域进行识别并进行可视化,最终建立分心状态判别模型;Wang等[17]使用脑电图信号早期检测驾驶员分心,运用浮动顺序搜索方法提取相关指标,对驾驶员认知分心开始和结束的总体准确度值分别为81%和70%;张辉等[18]运用基因选择算法融合驾驶绩效及眼动特征,提取出14项有效指标,建立了Adaboost-GA-BP组合算法分心判别模型;马艳丽等[19]选取速度、加速度及横向偏移等有效指标,使用支持向量机构建车载信息系统操作分心判别模型,其分心识别率为89.86%。在分类算法中,支持向量机(SVM)避免了局部极小问题,对小样本二分类问题具有较好的适用性,在追求分类效果上泛化能力较好,适用于作为本文分心驾驶判别模型。目前,已有研究使用SVM对分心状态进行判别,并对比了不同核函数对分心状态识别的影响。但SVM模型识别效果的好坏主要取决于惩罚因子与核函数参数的选择,因此将选取合适的算法对SVM参数进行优化,建立基于参数优化的SVM分心状态判别模型。
驾驶绩效具有采集成本低易获取等优点,因此在驾驶员分心状态判别领域具有良好的应用。根据车辆运行特征可分为横向控制、纵向控制及跟驰能力3类。横向控制包括方向盘转角、车道偏离、横向加速度等;纵向控制包括纵向速度、加速度等;跟驰包括车头间、时距等。目前多数车辆能通过自适应巡航控制系统对车辆纵向运动进行自动控制。因此,来自刹车、油门踏板及速度等的信号将不再显示有关驾驶员分心的有力信息,从而使现有的识别模型和研究在一定情况下不再适用。为了使驾驶员分心状态识别在未来几年保持相关性,需要考虑新的分类方法和策略。具体来说,基于车辆运行数据条件下,驾驶员对车辆的横向控制是分心状态识别的可靠信息源。刘文丽[20]基于主客观综合评价方法得到各车辆运行指标的混合权重,建立了驾驶能力评估模型,其中车道偏离与方向盘转角占据较高的权重。
为研究车辆横向控制指标对分心驾驶状态判别的识别效果,现采用非侵入式检测设计驾驶人接听手机的模拟试验。首先从时域和频域中提取出车辆横向运行绩效指标,建立分心状态判别指标集。其次构建以径向基为核函数的SVM分心判别模型,并通过网格搜索算法(grid search algorithm,GSA)、粒子群算法(particle swarm optimization,PSO)、遗传算法(genetic algorithm,GA)对SVM模型参数进行优化。最后采用多种模型评价指标对模型进行性能评估,验证模型的有效性。
1 实验设计
1.1 实验设备
驾驶模拟实验所需的设备,如图1所示,均使用国际技术标准。硬件设备方面,配备罗技G29模拟驾驶控制器以及电脑显示屏;软件方面,使用一款开源的赛车游戏程序TORCS模拟赛道和车辆状态。

图1 模拟驾驶实验设备Fig.1 Experimental equipment for driving simulation
1.2 实验参与者
实验共有40名实验参与人员。实验前,所有实验人员在参与研究前均表示知情同意。实验人员在开始实验之前需要填写一份个人信息问卷,包括姓名、性别、年龄、驾龄、职业、年驾驶里程、交通事故以及是否在测试前喝过咖啡或其他会影响大脑功能的刺激性饮料和药物等。实验结束后统计有效样本共36份。
1.3 实验步骤
驾驶人在手机通话时,交通环境、车辆行驶信息与通话内容在脑中发生交错,使驾驶人的脑力负荷大幅上升。而人脑的注意资源和容量有限,驾驶时使用手机通话极易使驾驶人产生认知分心。
实验选取手机通话形式作为分心影响因素,设计了正常驾驶、免提通话、手提通话3个维度,采取组内实验方式。在实验过程中,被试可能会感到一定程度的不适或紧张。为了使被试尽快适应实验设备和流程,减少由外界环境和对设备不熟引起的分心,每个被试在正式模拟驾驶前须进行2次适应性驾驶练习,练习的路线选取模拟驾驶路线的一小段。通过驾驶练习,一方面可消除被试初到新环境引起的紧张感,同时还可让被试适应模拟驾驶的相关操作,如方向盘、挡位、刹车等,同时尽量消除学习效应的影响。在实验开始后,为了使驾驶员专注于驾驶任务,实验人员不会再进行指导,以避免分散驾驶员注意力。实验过程中的因变量主要为驾驶绩效。
为了消除实验顺序效应对模拟实验结果带来的影响,事先对3种驾驶情境出现的次序进行排序,使得这3种情境出现在两次驾驶中的概率相等,共排列出6种顺序:“正常驾驶—免提通话—手提通话”、“正常驾驶—手提通话—免提通话”、“免提通话—正常驾驶—手提通话”、“免提通话—手提通话—正常驾驶”、“手提通话—正常驾驶—免提通话”、“手提通话—免提通话—正常驾驶”。把被试分为6组,每组被试使用一种顺序,参与者在试验中被要求专注于驾驶任务,并将剩余的注意力分配到其他任务上(手持通话/免提通话)。如果被试被分配到手机通话的条件下,被试会在每次试验的第5分钟、第12分钟和第20分钟收到电话,通话持续时间略少于2 min,通话内容包括简单算术题和日常生活问题。在每次试验中,参与者在这条城市快速路上模拟驾驶开车大约25 min。
每个驾驶情境完成后被试休息5 min,然后进入下一轮情境测试。试验中,软件自动记录车辆运行数据,包括行驶速度、方向盘转角和车道偏离数据等,数据的采样频率为40 Hz。
1.4 实验场景
在城市快速路模拟驾驶的过程中,驾驶速度设置上限,模拟平均正常行驶速度(60~80 km/h);驾驶道路环境设置一致;驾驶路线和路程设置一致。驾驶车辆在跟车控速的条件下行驶。跟车控速条件做如下设定:跟车驾驶,控制车辆尽量稳定地行驶在车道中央;适当监视速度表,将车速稳定在路段要求的速度上(不超过道路设计速度的20%)。
2 车辆运行状态特征提取
集中研究分心驾驶情况下车辆横向控制特征(方向盘转角、车道偏离)的变化。对3种驾驶情况下的方向盘转角、车道偏离截取部分时间数据,如图2所示。
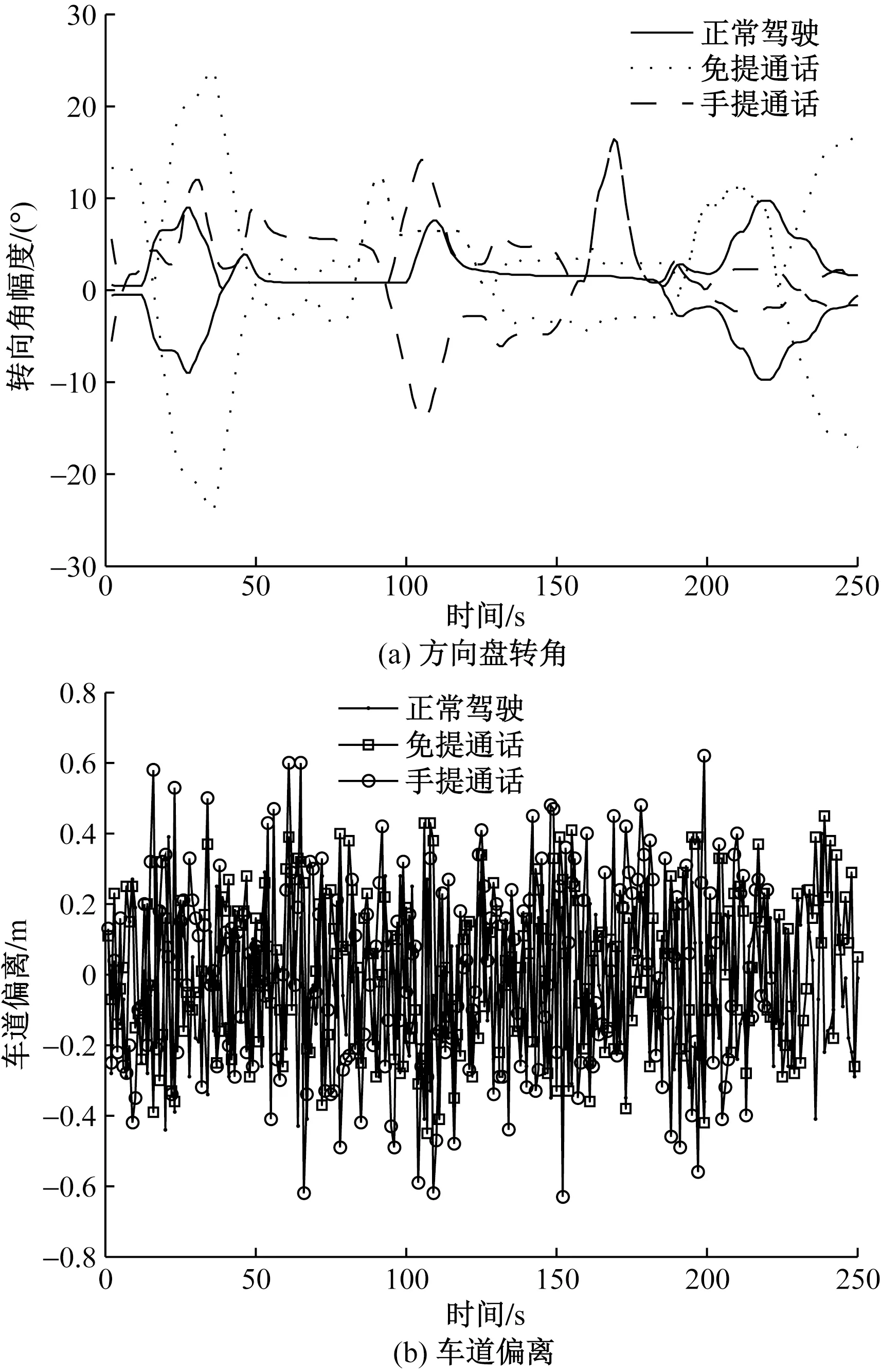
图2 数据采集Fig.2 Data collection
数据预处理过程中,剔除车辆在变道、转弯以及弯道行驶过程中的数据,避免车辆转弯等对车辆横向运行数据造成干扰。最终在正常驾驶及分心驾驶条件下共提取出732组车辆横向运行数据,其中正常驾驶256组,手机通话驾驶476组。
2.1 时域特征分析
驾驶人在进行手机通话任务时,方向盘转角及车道偏离发生明显变化:均值及标准差均增大。说明在通话分心驾驶时驾驶人的横向控制受到了影响。为分析正常驾驶与通话分心驾驶下各指标的统计性差异,运用Man Whitney U对各指标进行显著性检验。根据P可得,方向盘转角标准差(P<0.05)与车道偏离标准差(P<0.05)为显著性指标。相关指标的统计学结果如表1所示。

表1 各项指标的统计学结果Table 1 Statistical results of each indicator
2.2 频域特征分析
为提取方向盘转角与车道偏离在频域内的特征,利用傅里叶变换将各指标从时域转到频域进行分析。考虑到驾驶模拟器采集的各指标数据并非确定性信号,因此对各横向控制指标计算其自相关函数,再对其自相关函数进行傅里叶变换得到各状态下的功率谱及能量值。
对正常驾驶与通话分心驾驶下的方向盘转角及车道偏离频谱能量进行Man Whitney U检验,结果如表2所示。
由P可知,方向盘转角及车道偏离频谱能量在正常驾驶与通话分心驾驶状态下具有显著性差异(P<0.05)。
通过时、频域特征分析,得到与通话分心驾驶具有显著性效应的车辆横向运行指标,如表3所示。

表3 车辆运行状态显著性指标Table 3 Significant indicators of vehicle operating status
3 分心驾驶行为SVM判别模型
SVM基于结构风险最小化原则,建立一个超平面作为决策面,使正负样本之间的间隔最大化,对小样本二分类问题具有较好的适用性。因此选择SVM作为手机通话分心驾驶的判别模型。
3.1 分心驾驶行为判别模型构建
将表3中的4项指标作为分心状态判别特征指标,模型构建流程如下。
步骤1构建训练及测试集。
通过随机分配数据集的方式,将数据样本的80%作为训练集,20%作为测试集,标记好数据样本的类别标签,将数据进行归一化转换到[0,1]区间。
步骤2核函数的选取及参数优化。
选择径向基函数(radical basis function,RBF)作为SVM的核函数类型。SVM模型的识别效果跟惩罚因子C与核函数参数g的选取有关,因此使用GSA、GA及PSO对参数C、g进行优化。
步骤3模型训练与测试。
利用GSA、GA及PSO优化后的最优参数C、g分别对SVM模型进行训练,并应用训练好的优化模型对测试集进行分类。
步骤4模型性能评估。
通过对比不同优化算法寻参的SVM模型分类结果,选出最适合作为分心驾驶行为的识别模型。运用接受者操作特征(receiver operating characteristics,ROC)曲线及曲线下的面积(area under curve,AUC)对参数寻优后的SVM模型进行性能评估。
3.2 模型参数优化
当RBF应用于支持向量机时,参数C和g都会影响支持向量机的性能。g是RBF核函数自带的参数,g过大,模型分类效果好,但容易过拟合,导致模型鲁棒性差,g过小会造成平滑效应太大,分类识别率低;惩罚因子C表示对误差的宽容度,C越大,对误差的容忍度越小,分类标准越严格,容易出现过拟合,反之亦然。因此构建一个具有良好性能的分类器SVM,需要选择合适的g,并根据此参数确定一个最优惩罚因子C。使用SVM模型对随机训练集进行训练,对测试集进行预测,分类准确率为85.034%。此时模型参数C=1,g=0.25,模型准确率较低,因此需要优化SVM模型参数以提高模型识别精度。
3.2.1 网格搜索算法
GSA将参数的搜索范围分成一些网格,通过在每个网格里遍历、搜索来寻找使模型性能达到最优的参数。使用网格搜索对最佳C和g进行选择,C、g选择高等密度图如图3所示。利用GSA寻优算法得到SVM最佳惩罚参数C=16,最优核函数参数g=16,此时十折交叉验证正确率为86.154%。
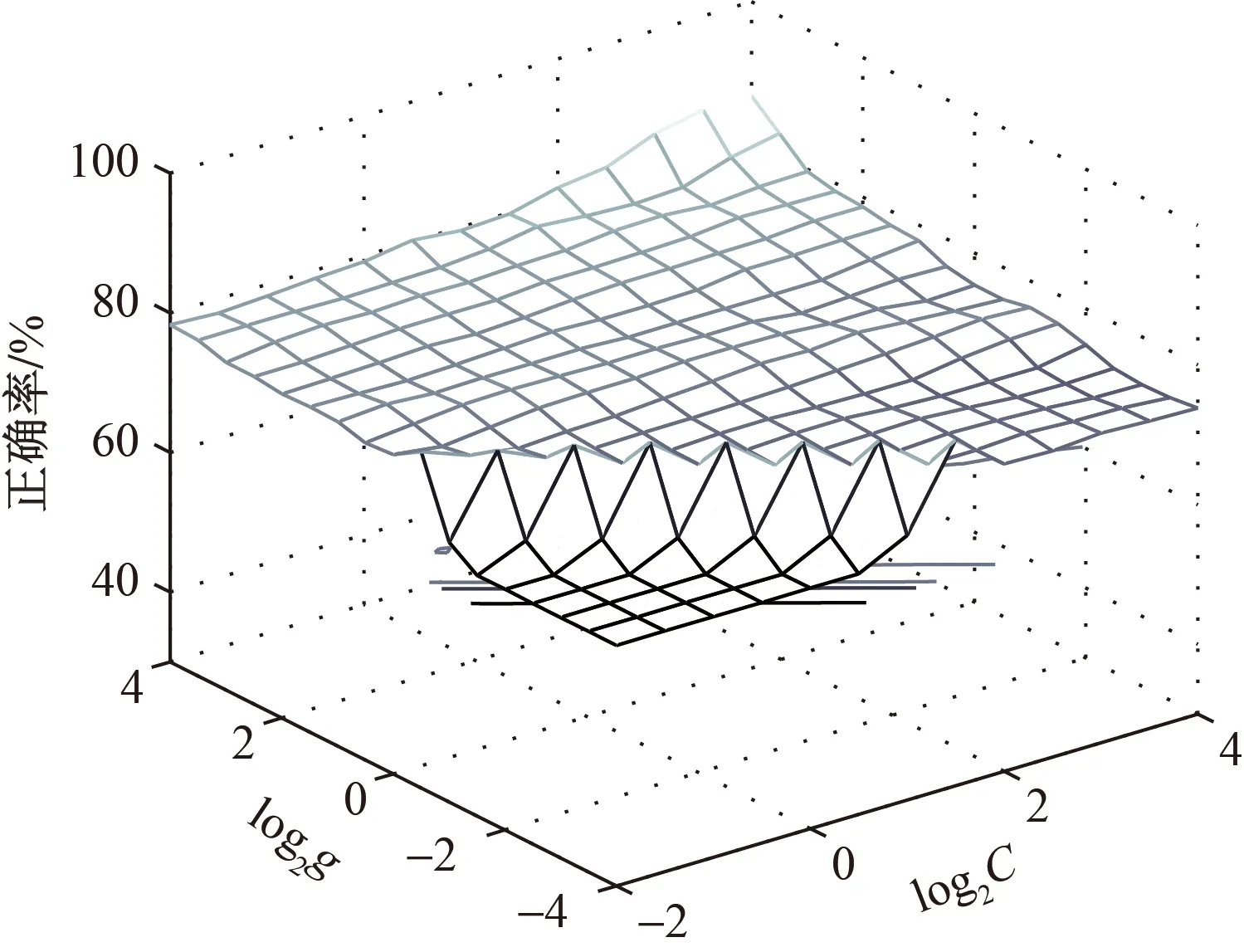
图3 网格搜索参数寻优Fig.3 GSA optimized parameters
3.2.2 遗传算法
GA包括选择、交叉与变异等操作,能自适应地调整搜索方向。运用GA对参数C、g寻优,种群数量大小为50,迭代终止代数为50,选取十折交叉验证准确率的平均值作为适应度目标函数,迭代过程如图4所示。可以看出,最佳适应度为88.03%,此时最佳参数C、g分别为2.52、252.5。

图4 遗传算法参数寻优Fig.4 GA optimized parameters
3.2.3 粒子群算法
粒子群优化算法是通过群体中个体之间的协作和信息共享来寻找最优解。通过PSO对参数进行优化,粒子群体个体数目设为50,终止代数为50,设置速度更新的惯性权重w初始值为1。其他控制参数设置一定寻优步长,其迭代过程如图5所示。可得最佳适应度值为87.863 2%,此时PSO-SVM最佳参数C为2.60,g为252.4。

图5 粒子群算法参数寻优Fig.5 PSO optimized parameters
为防止模型欠拟合或过拟合,使用K重交叉验证(K-fold cross validation)对优化后的C、g进行模型训练,提高SVM识别模型的泛化能力。取K个模型分类准确率的平均值作为模型最终准确率。程序中取K=10,使用MATLAB对GSA-SVM、GA-SVM与PSO-SVM模型进行训练与测试。
3.3 优化模型结果对比
将3种优化模型的最佳参数C、g应用于SVM模型对测试集(n=148)进行预测,模型分类结果如表4所示。
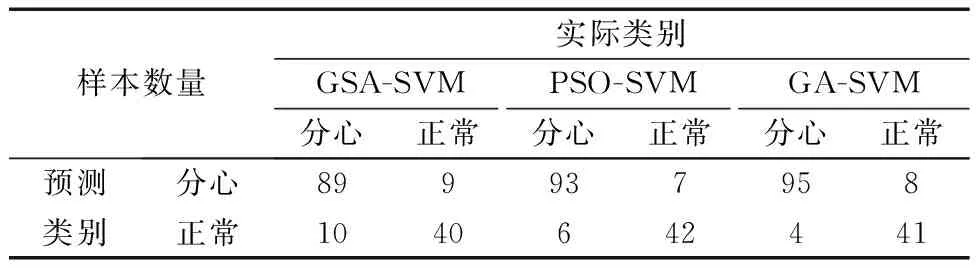
表4 模型分类结果Table 4 Model classification results
考虑到数据集的样本标签存在一定不平衡性,因此除了用准确率对模型进行评价之外,还使用精确率、召回率、F1等进一步对实验结果进行评价。其中精确率(precision,P)指所有被预测为分心驾驶的样本中,实际为分心驾驶的样本概率;召回率(recall)指实际为分心驾驶的样本中被预测为分心驾驶的样本概率;F1是精确率与召回率的一种调和平均,计算公式为
(1)
使用精确率、召回率、准确率及F1对GSA-SVM、GA-SVM与PSO-SVM模型分类效果进行评价,评价结果如图6所示。
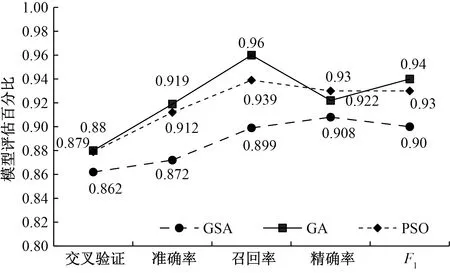
图6 模型评估指标Fig.6 Model evaluation metrics
由图6可知,GSA-SVM、PSO-SVM及GA-SVM的准确率(87.2%、91.2%、91.9%)均高于无优化SVM(83.034%)。GA-SVM分心判别模型最优交叉验证准确率、分类准确率及F1分别为88.03%、91.9%、94.05%,相比GSA-SVM(86.2%、87.2%、90.35%)与PSO-SVM(87.9%、91.2%、93.46%)更高。这是因为遗传算法能通过选择、交叉和变异等操作,生成新的群体,且具有较强的收敛性能和良好的全局搜索能力;粒子群算法通过粒子的随机漫步来寻找最优参数,但容易陷入局部极值;网格搜索算法搜索每个网格对应的点寻找全局最优解,但搜索速度较慢,精度不够高。结合图4和图5,GA参数寻优最佳适应度88.03%,平均适应度从85.75%提高到86.81%,而PSO参数寻优平均适应度整体呈下降趋势,说明GA-SVM分心判别模型相比于PSO-SVM更加稳定。
通过对比模型评价指标及稳定性,可知遗传算法优化参数更适合作为分心驾驶行为SVM判别模型的分类器。
3.4 模型评估
在样本不平衡且可能小幅变化的情况下,ROC曲线依然能够对分类器做出合理的评价。因此运用ROC曲线对GA-SVM分类器整体性能进行评估。
当ROC曲线越接近于(0,1)坐标,表示模型区分正例和负例的能力越强,分类器准确性越高。其中真阳率表示分心驾驶中被预测为分心驾驶的概率,假阳率表示正常驾驶中被预测为分心驾驶的概率。ROC曲线下方的面积,即AUC值,是综合评价模型区分能力的指标。如图7所示,ROC曲线接近于(0,1)坐标,计算得AUC值为0.935 3,由此认为GA-SVM分心判别模型具有良好的判别效果。
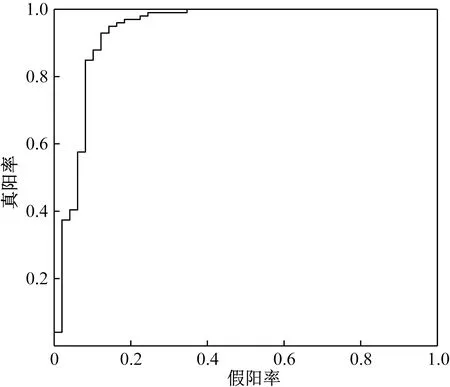
图7 GA-SVM判别模型的ROC曲线Fig.7 ROC curve of GA-SVM discriminant model
基于分心特征构建分心状态判别模型,马艳丽等[19]通过提取速度、加速度均值等六项指标,在使用RBF核函数时对驾驶人分心识别准确率为89.86%。在此基础上通过优化算法寻找SVM最佳参数,使分心驾驶状态识别率提高到91.9%。虽然所搭建的基于车辆横向运行数据的分心驾驶状态识别模型具有较高的识别率及良好的泛化能力,但模型的识别精度与其他相关研究还存在一定差距,主要原因为:为研究车辆横向控制指标对分心驾驶状态识别效果,实现低成本条件下提高对分心状态的识别精度,仅从车辆横向运行数据中提取相关指标,相关研究则通过融合驾驶绩效与驾驶人行为指标或者采用车辆横纵向运行指标与跟车指标相结合的驾驶绩效指标构建分心判别模型。
4 结论
通过在驾驶模拟器上开展手机通话驾驶试验,采用低成本非侵入式检测采集数据。在时域和频域范围内提取出与手机通话驾驶显著相关的车辆横向控制指标,验证了在手机通话驾驶情况下车辆运动指标作为分心判别变量的有效性。
基于提取的车辆横向指标集构建了手机通话分心驾驶下SVM分心判定模型。使用GSA、GA、PSO优化算法对SVM模型参数C、g进行优化。实验表明,基于GA优化的SVM判别模型分类效果最好,具有一定的可行性,更符合实时监测的需要。
对最终GA-SVM分心判别模型进行模型评估,其AUC为0.935 3。表明GA-SVM判别模型性能较好,泛化性能较高,适用于作为驾驶人分心驾驶状态判别模型。
手机通话分心驾驶试验研究中免提/手持通话情境不能完全做到与实际驾驶一致。考虑不同交通场景下,免提/手持通话等具体情境下的驾驶分心识别具有重要意义。另外,驾驶实验中将免提和手持通话驾驶合并处理,对于手机接听方式以及驾驶人个体差异化因素对车辆运行状态的影响,还需要进一步深入研究。
猜你喜欢
小学生作文(低年级适用)(2019年5期)2019-07-26
中华诗词(2018年5期)2018-11-22
小太阳画报(2018年3期)2018-05-14
读友·少年文学(清雅版)(2018年12期)2018-04-04
阅读与作文(小学低年级版)(2016年12期)2016-12-22
发明与创新(2016年30期)2016-08-22
山东青年(2016年3期)2016-02-28
汽车文摘(2015年11期)2015-12-02
电子设计工程(2015年8期)2015-02-27
电信科学(2013年5期)2013-02-19
