
基于深度学习的城市区域短时交通拥堵预测算法
2023-09-27 09:02:38李帅杨柳赵欣卉
科学技术与工程 2023年25期
李帅, 杨柳, 赵欣卉
(1.西南交通大学唐山研究生院, 唐山 063002; 2.综合交通大数据应用技术国家工程实验室, 成都 611756; 3.西南交通大学信息科学与技术学院, 成都 610000)
近年来,城市交通发展和机动车的保有量增长迅速,截至2020年,中国汽车的保有量为2.81亿辆,年平均增长2 000多万辆,而全国的道路每年的增长率仅为3%~5%。城市道路的容纳力无法满足现有机动车数量的增长,严重影响了日常交通出行,城市的交通拥堵已经成为各个城市中的普遍现象。所以提前预知城市交通状况,可以帮助城市交通管理人员提前做好准备,极大缓解交通拥堵现象,也可以为公众出行提供参考。
城市的交通流预测一直是科研人员研究的热点,在不同的时期采用不同的预测方法,都取得了较为优秀的成功。目前,对于城市交通预测的研究方法国内外主要分为三大类:参数模型、非参数模型以及混合模型。
第一类:参数模型。
基于参数模型的预测方法中典型的代表是自回归积分滑动平均模型(autoregressive integrated moving average,ARIMA)[1]。王晓全等[2]基于ARIMA提出了一种组合模型ARIMA-GARCH-M进行短时交通流预测,并利用城市快速路交通流数据进行模型预测精度的检验。
ARIMA模型通常只能应对简单的问题,要求输入的数据是平稳的,对于复杂的交通流数据,实际中无法和潜在的目标函数完全吻合,容易出现欠拟合。
第二类:非参数模型。
基于非参数模型的预测方法包括支持向量机回归模型(support vector regression, SVR)、人工神经网络模型、深度学习模型等。常用的人工神经网络模型有BP神经网络、小波神经网络、模糊神经网络等[3]。
李建森等[4]结合BP神经网络模型和自回归求和滑动平均(ARIMA)模型对城市道路交通短时区间流量进行预测。首先利用ARIMA模型拟合训练集,然后利用BP神经网络模型拟合残差,通过这种方式来提高预测的精准度。
蒲斌等[5]通过实验验证了ARIMA 乘积季节模型、BP神经网络的多种训练函数的预测精度及适应性,证明了BP神经网络的预测方法具有更好的适应性。牟振华等[6]提出一种小波降噪与贝叶斯神经网络联合模型的预测方式。该预测模型通过小波降噪的方式处理交通数据,构建贝叶斯神经网络模型使用降噪后的数据进行拟合、预测。宋瑞蓉等[7]提出了一种基于果蝇算法的混合小波神经网络模型。该模型选择果蝇优化算法对小波神经网络的初始参数进行调节,解决了小波神经网络预测对初始参数敏感的问题。其次,将迭代次数和当前解的情况作为搜索半径和种群规模的动态调整因子,对果蝇算法进行了改进,提高了果蝇算法的全局寻优能力和局部收敛速度。
随着人工智能技术的不断发展,深度学习已经成为当前研究人员的研究热点。Bai等[8]在时间序列预测方面,把卷积神经网络(convolutional neural networks,CNN)与其他预测模型进行了众多对比实验,证明了CNN可以用于时间序列预测,且取得了很好的效果。Ma等[9]提出了一种基于CNN的流量学习方法,该方法将流量学习为图像,并对大规模、全网络流量速度进行高精度预测。但是CNN并不完全适用于时间序列的预测,因此会需要各种辅助性处理,局限性太大。
循环神经网络(recurrent neural network,RNN)可以处理输入的任意长度的序列,所以RNN适用于捕捉交通流数据的时空演变。但RNN对于捕捉输入序列的长时间依赖显得无能为力,同时RNN还存在梯度消失和梯度爆炸的问题。为了进一步提高预测精准度,长短期记忆(long-short term memory, LSTM)神经网络被开始应用于交通预测领域。相比于RNN,LSTM极大避免梯度消失的问题,可以处理长时间跨度的时间序列。
文献[10-11]将LSTM神经网络应用于交通流预测,证明了LSTM在交通预测的可行性,同时基于LSTM循环神经网络模型分析了不同输入配置对交通流量预测精度的影响。
交通流数据的预测是和时间相关的,故利用LSTM来处理交通流数据,提取交通流数据的时间特征。但是交通流数据不仅仅和时间相关,还和空间相关,而LSTM 自身无法获取到数据的空间特征,必须通过人工方式,将数据的空间信息通过编码作为网格进行输入,但通过这个方式会影响到预测的精度。RNN的梯度问题在LSTM里面得到了一定程度的解决,但还是存在。LSTM不能够进行并行计算,训练LSTM模型对硬件的要求非常高,需要大量资源,导致训练效率低下。
在2017年,Transformer的出现引爆了AI圈[12]。文献[13-16]证明了Transformer的优越性,同时证明了在交通流量预测方面的可行性,因为Transformer的特点,在交通流预测方面也取得了非常优秀的成绩。各种深度学习方法应用在交通流预测上可以得到不错的效果,但是绝大多数的深度学习方法在实际的预测当中仍然存在一些问题,例如对于交通数据的时空特征不能进行有效的提取,使得预测精度受到了局限性。
第三类:混合模型。
为了解决单一预测模型无法精确的提取时间序列数据中的时空特征问题,混合模型被提了出来。Shi等[17]首次提出了卷积神经网络CNN和循环神经网络LSTM的结合体CNN-LSTM。CNN-LSTM模型后来也被开始应用于交通流预测[18-20]。
文献[21-22]针对交通流量特性和外部因素对交通流量预测结果的影响,在CNN-LSTM的基础上提出了CNN-ResNet-LSTM城市短时交通流量预测的模型。王海起等[23]利用CNN 模型和基于注意力机制的 LSTM 模型建立了交通流短时预测模型,通过嵌入注意力机制来处理交通流的趋势变动性。
宋瑞容等[24]为了精准预测交通流量,充分提取交通流中复杂的线性和非线性特征及其依赖关系,提出了融合多维时空特征的CLABEK模型。CLABEK模型由Conv-LSTM、BiLSTM和Dense神经网络分别提取时空特征、周期特征和额外特征,并通过将上述模型融合从而全面获取交通流的非线性特征,通这种方法来提高模型预测的准确率。
为了更准确地对城市交通状态进行预测,现结合以往的研究,通过网格划分的方法,把城市区域划分为多个区域,根据城市交通数据流的时空特征,提出一种基于深度学习的城市交通拥堵预测模型CS-Transformer(CNN-SPEM Transformer)。该模型通过使用卷积神经网络(CNN)提取基于网格划分的城市区域交通数据的空间特征,然后采用全连接神经网络增强模型的表达能力,再通过相似性位置编码机制(similarity position encoding mechanism,SPEM)把位置信息加入交通数据中,最后运用Transformer网络捕捉交通数据的时间依赖特征。
1 城市区域交通预测问题定义
1.1 问题定义
通过城市网格划分的方法,将城市划分为了I×J个不重叠的网格矩阵区域,网格矩阵代表的是时间片t下成都市各个区域的交通拥堵状态,如图1所示。将网格指标记作X={xi,j},xi,j为时间片段t下位置(i,j)区域的拥堵情况,如图1所示。
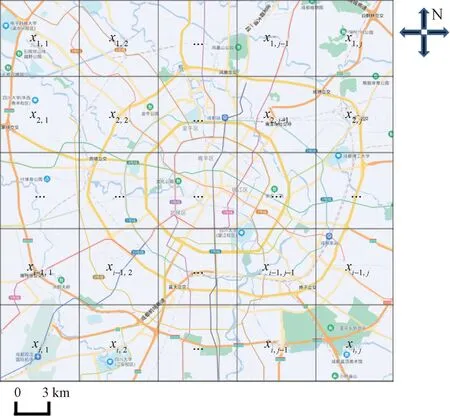
图1 网格地图划分图Fig.1 Grid map division map
城市区域交通拥堵预测是一个时空序列预测问题,可以定义为:在给定的时间片段t的条件下,通过n个历史时间片段的交通拥堵状态网格矩阵{Y1,Y2,…,Yn},来预测未来时间片段t下的城市交通拥堵状态{Yn+1}。对于城市交通的拥堵状态预测,不仅仅需要考虑时间特征的连续性和周期性,还需要考虑空间特征的依赖性。
1.2 时间特性
城市短时交通拥堵预测是通过以往的历史交通拥堵状态预测未来城市交通拥堵状态,在时间方面精确的预测受2个因素影响。
1.2.1 邻近性
城市短时交通拥堵预测是指在给定的时间片段t的条件下,通过n个历史时间片段的交通拥堵状态网格矩阵{Y1,Y2,…,Yn},来预测未来时间片段t下的城市交通拥堵状态{Yn+1},未来预测的交通拥堵状态与它前一时刻的拥堵状态是相关的。即每一个时间片段的拥堵状态往往受前一个时间片段的拥堵状态的影响,同时也会影响下一个时间片段的拥堵状态。
1.2.2 周期性
城市区域的拥堵状态具有周期性。即每一天相同时间片段的城市区域的拥堵状态是大致相同的。例如,2018年3月1日10:15—10:30的城市区域拥堵状态与2018年3月2日10:15—10:30的城市区域拥堵状态大致相同。
为了使城市区域交通拥堵状态的预测更加精准,需要考虑时间周期性的特性。所以可以把需要预测的某一天的时间片段前一天相同时间段的时间片段,也作为历史时间片段序列来进行预测。例如,需要预测的时间片段为2018年3月6日10:30的拥堵状态,可以把前一天相同时间片段放入历史时间片段序列中,即把2018年3月5日10:30放入n个历史时间片段中,历史片段就变成了n+1个,就成为{W1,Y1,Y2,…,Yn},W1为需要预测的时间片段前一天相同时间段的时间片段,称为历史相同日周期片段。
1.3 空间特征
对城市进行网格区域划分为X={xi,j}后,每个区域网格指标代表该位置区域的拥堵情况。每区域的拥堵情况不仅仅与历史拥堵情况具有相关性,与附近其他区域的拥堵情况也具有相关性,区域xi,j的拥堵情况会受到周围{xi-1,j-1,xi-1,j,xi-1,j+1,xi,j-1,xi,j+1,xi+1,j-1,xi+1,j,xi+1,j+1}这8个区域的影响,如图2所示。

图2 城市网格区域表示图Fig.2 Urban grid area representation
2 基于CS-Transformer的城市区域交通状态预测
根据基于网格划分的城市区域交通拥堵状态预测的时空特性,以及现有模型存在的一些局限性,提出了一种基于CNN和相似性位置编码机制(similarity position encoding mechanism,SPEM)的模型CS-Transformer(CNN-SPEM Transformer)的预测模型,如图3所示。模型由CNN空间组件、相似性位置编码机制(similarity position encoding mechanism,SPEM)和Transformer时间组件三部分组成。

W1、{X1,X2,…,Xn}为编码器的输入;Xn为解码器的输入;{H1,H2,…,Hn}为SPEM模块处理数据的输出图3 CS-Transformer模型架构图Fig.3 CS-Transformer model architecture
该模型首先通过使用CNN组件提取基于网格划分的城市区域交通数据的局部空间特征,然后采用全连接神经网络增强模型的表达能力。然后输入SPEM中,通过位置编码组件给输入的序列加入位置信息,再输入Transformer组件,运用Transformer 组件捕捉交通数据的时间依赖特征。
2.1 空间组件:CNN模型
CNN是卷积神经网络的简称,在图像处理领域得到了广泛的应用,具有强大的特征学习能力。在交通流预测方面,引入CNN进行空间建模,可以更好地刻画交通流的空间特征。通过CNN的卷积核可以更加高效地处理高维数据,同时自动地学习交通流数据的空间特征,从而达到提高模型预测精准度的目的。
CNN组件的主要任务是利用CNN中的卷积层来提取基于网格划分的城市交通拥堵状态的空间特征。将时间片段t下的城市交通拥堵矩阵Y看作是一张单通道的图像,把Y作为输入,对其进行卷积操作,挖掘局部的空间特征。图4为CNN组件结构图。

图4 CNN组件结构图Fig.4 Structure diagram of CNN components
(1)卷积层1。对输入的8×8二维矩阵进行卷积操作,通过卷积操作可以挖掘局部的空间特征,城市区域的拥堵状态不仅仅是与自身区域的交通流有关,和周围区域的交通流也有关系,所采用维度为3×3的卷积维度,移动步长设置为1,填充设置为1。经过卷积操作后,再输入池化层进行池化操作。
(2)卷积层2。经过卷积层1的处理后,城市交通拥堵状态矩阵由8×8变为了4×4,再把4×4的二维矩阵输入卷积层2中进行卷积操作,卷积核采用3×3的卷积维度,移动步长设置为1,填充设置为1。经过卷积操作后,再输入池化层进行池化操作。经过卷积层2的操作后,输出的矩阵大小为2×2,输入两层全连接层后,再输入到位置编码组件Position中。
2.2 时间组件:Transformer模型
Transformer是作为一种新的深度学习框架而被开发出来的,基于注意力机制和位置编码策略进行序列建模。Transformer完全建立在注意力机制上,这使得它能够访问序列的任何部分,无视其距离目标的距离。从本质上讲,Transformer是以编码组件-解码组件的方式进行构建的,编码组件部分由一堆编码器构成,解码组件是由一堆解码器构成,编码器和解码器的数量是相同的。每个编码器模块是由一个多头自注意层和一个位置前馈层组成,而每个解码器模块又多了一层编码器-解码器注意层,插在自注意层和前馈层之间,作为编码器和解码器部分的桥梁。图5为Transformer模型结构图。

图5 Transformer模型结构图Fig.5 Structure diagram of Transformer model
因为城市交通流数据具备时间序列的特点,必须考虑时间序列的连续性和周期性等时间特征。所以Transformer时间组件的主要作用是用来提取时城市交通流数据的时间特征。通过Transformer模型可以在城市交通时间序列预测的过程中,可以不必考虑距离去访问历史序列数据的任何部分,所以适用于具有长期依赖关系的时间序列预测应用场景,同时还具有更强的并行性,来捕捉时间序列的连续性和周期性。
2.3 相似性位置编码机制:SPEM
由于Transformer模型不包含循环和卷积,为了使模型能够利用序列的顺序信息,必须给输入的序列加入一些关于位置的信息。故在编码器和解码器堆栈底部的输入嵌入中添加了位置编码。位置编码后的序列与嵌入序列具有相同的维数,因此两者可以直接相加。位置编码的公式定义为
PE(pos,2i)=sin(pos/10 0002i/d)
(1)
PE(pos,2i+1)=cos(pos/10 0002i/d)
(2)
式中:pos和i分别为输入序列的位置索引和输入序列维度位置;d为输入序列的维度大小。位置编码的每个维度对应于一个正弦信号,波长为2π~10 000×2π,呈几何级数。
Transformer引入了位置编码策略,它对序列中数据的先后位置进行编码。Transformer根据序列中元素的位置建立索引,然后通过一系列正弦函数传递索引。Transformer在自然语言处理方面取得了重大成功,包括机器翻译。尽管这种编码策略对机器翻译很有用,但它不适用于交通预测,因为对于交通预测,必须考虑时间序列的连续性和周期性等时间特征。所以把Transformer应用于交通预测需要改变编码策略。在机器翻译中,输入序列和目标序列代表着两种不同的语言相同含义的句子,因此两个序列应该共享相同的位置索引。然而在交通预测中,历史序列和预测序列是连续的,因此历史序列和预测序列不能共享相同的位置索引。此外,交通数据还具有周期性,即每一天相同时间片段的城市区域的拥堵状态是大致相同的。因此,把Transformer应用于交通预测时,需要采用新的策略对时间特性进行编码。
根据城市交通流数据特性,提出了3种不同的位置编码策略,即局部位置编码策略、全局位置编码策以及周期性位置编码策。在首届世界城市日论坛上,上海在“2035规划”中提出“15分钟社区生活圈”的概念。生活圈代表的是配备生活所需的基本服务功能与公共活动空间,形成安全、友好、舒适的社会基本生活平台。其中的15分钟指的是指社区居民的步行尺度,同时也包含依托自行车和机动车出行的能力,故采用15分钟为一个时间片段进行预测。使用{W1,Y1,Y2,…,Yn}为历史城市区域交通拥堵状态序列,来预测城市交通拥堵状态{Yn+1}序列。
2.3.1 局部位置编码策略
该编码方式是为了保证时间序列的局部连续性,即只关心历史交通序列-预测交通序列之间的连续性,而不去考虑整个交通序列的连续性。首先把历史交通序列-预测交通序列按照时间进行排序,先不考虑历史相同周期片段W,把0作为起始位置,每往后一个时间步就把索引位置加1,即可得到局部位置索引LP,如式(3)所示。再把LP通过式(1)和式(2)运算即可得到每一个时间序列的局部位置编码。例如{Y1,Y2,…,Yn}为历史交通序列,{Yn+1}为需要预测的交通序列,使用局部位置策略得到的索引位置分别为(0,1,…,n-1)和(n)。对于周期历史片段W,把W设置为和预测的交通序列相同的索引位置,即{n},再放入相对历史位置索引中可得(n,0,1,…,n-1)。再把索引位置利用式(1)和式(2)得到局部位置编码。
LP={Y1,Y2,…,Yn}→{0,1,…,n-1}
(3)
2.3.2 全局位置编码策略
局部位置策略可以保证序列的局部连续性,但也忽略了一个时间片段序列在不同的历史交通序列-预测交通序列其实是同一个时间片段序列。例如时间在3:00—3:15的交通拥堵状态序列在不同的历史交通序列-预测交通序列中,其实是一样的。因此,局部位置策略的局限性就在于没能让同一个时间序列在不同的历史交通序列-预测交通序列表现出相同的位置编码。因此提出全局位置策略来解决局部位置策略的局限性,保证时间序列的全局连续性。
全局位置策略可以保证在整个时间周期中的时间片即使出现在了不同的序列中,也只有一个位置编码,保证了唯一性。首先,把数据集中的所有时间片按照时间进行排序,然后从0开始进行索引,每过一个时间片索引就加1,再把所有索引代入式(1)和式(2)得到每个时间片的全局位置编码,然后根据历史交通序列-预测交通序列在整个数据集中的排序截取相应位置的编码,即可得到历史交通序列-预测交通序列的全局位置编码,如式(4)所示。
GP={Y1,Y2,…,Yn}→{97,98,…,97+n}
(4)
2.3.3 周期位置编码策略
在交通序列中,不仅仅要考虑连续性的时间特征,还需要考虑序列的周期性时间特征。通过加入周期性的时间特征,可以保证模型具有更好的预测精准度。由于每一周相同的数据时间片段具有相同特性,所以可以把使用的交通数据每一周看作是一个周期进行编码。
把一周7 d按先后顺序进行排列进行索引,即{0,1,2,3,4,5,6}分别对应星期一到星期日,再把输入预测模型的时间序列数据按属于星期几进行标注,如式(11)所示。例如输入的时间序列数据{Y1,Y2,…,Yn}都在星期一,那么索引就为{0,0,…,0},再输入式(1)和式(2),得到位置编码。
把历史交通序列-预测交通序列分别按照局部位置编码策略、全局位置编码策略和周期性位置编码得到3份位置编码,因为3份位置编码的维度相同,所以可以直接相加,把相加后的结果作为新的位置编码pos,位置编码既考虑到了序列的局部性,又考虑到了序列的全局性和周期性。
WP={Y1,Y2,…,Yn}→{1,1,…,1}
(5)
把位置编码pos与输入模型中的历史交通序列-预测交通序列直接相加的方式,为输入的序列加入一些关于位置的信息。但由于位置编码pos既包括了局部位置编码,又包括全局位置编码和周期性位置编码,如果通过与输入序列直接相加的方式为输入的序列加入一些关于位置的信息,可能会隐藏序列之间的其他关系,导致训练模型更加困难,降低预测的精准度,尤其在数据集很小的时候。
所以提出了一种改进的方式,即相似性位置组合模块SPEM,通过相似性的方式把3种位置编码更好地融合进入输入的序列中,既为输入的序列加入一些关于位置的信息,又可以保证位置编码不会隐藏序列之间的其他关系,导致训练模型更加困难。在CNN空间组件和Transformer时间组件加上一层基于注意力机制的位置组合方式,通过对CNN-Transformer模型的进一步改进提高预测的精准度。计算公式如下。
S=softmax[pos(pos)T]
(6)
(7)
式中:pos为输入序列的位置编码;Q、K、V分别为输入序列进行线性变换后的查询向量、键向量以及值向量;dk为K的维度;Pos_Attention(Q,K,V,S)为结果输出矩阵。
图6为相似性位置组合方式过程图。
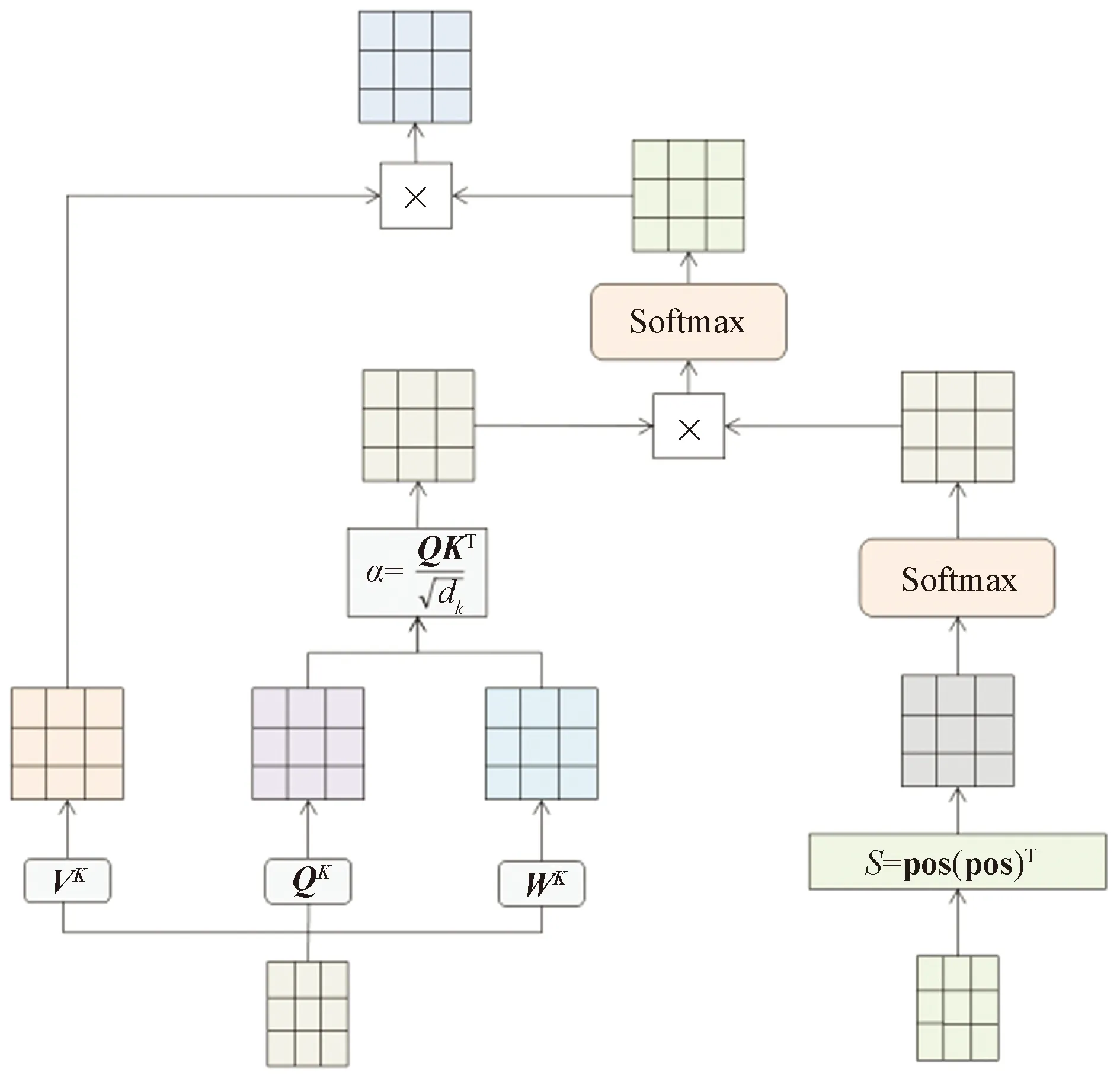
图6 相似性位置组合方式过程图Fig.6 Process diagram of similarity position combination mode
3 城市区域网格交通拥堵状态计算
3.1 数据集概况及预处理
使用的数据集是成都2018年3月出租车的GPS点定位数据,是对成都区域的出租车每隔10 s进行一次的GPS数据采集,属于高频率采样,共计31 d。出租车是每个城市都有的交通工具,而且遍布全城,故出租车会出现在城市的各个地方,所以出租车的行驶速度可以反映城市道路的真实交通状态。但是仍然存在问题,即出租车为未载客状态时的行驶速度不能反映当前道路的真实交通状态,因为未载客的出租车的目的是寻找乘客,所以说会降低行驶速度寻找乘客。故后续研究会选择载客的出租车作为数据集,因为载客的出租车目的是将乘客送达乘客目的地,所以会以出租车目前可以行驶的最快速度进行行驶,故可以反映当前道路真实的交通状态。
数据集中包含了1 372 331 359条数据,同时拥有10个字段。使用前23 d的数据作为训练数据,后8 d的数据作为测试数据。本数据集的字段如表1所示。
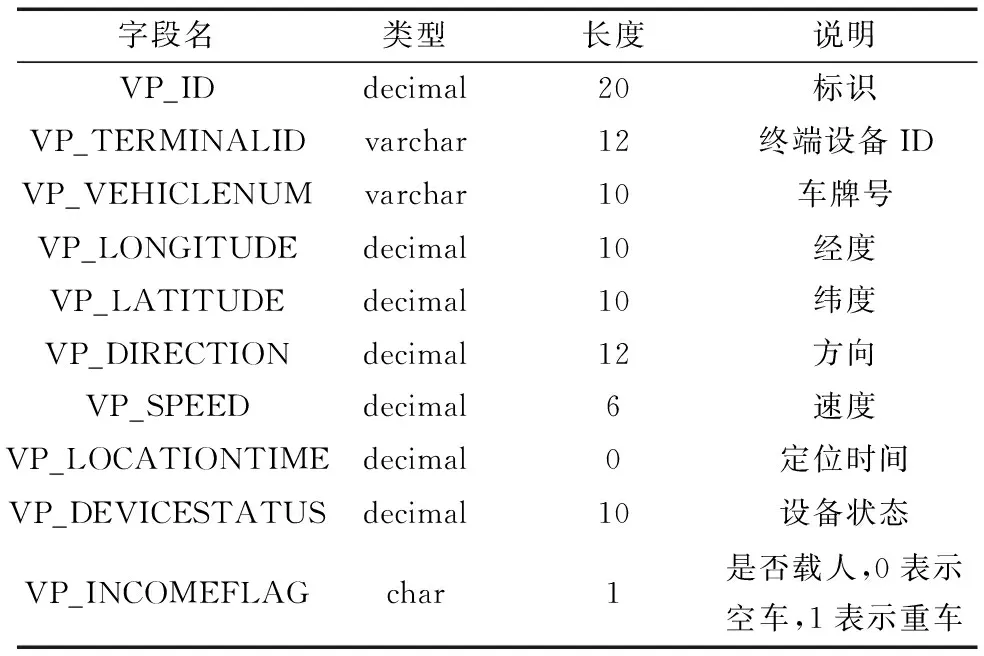
表1 数据集字段及说明Table 1 Data set fields and descriptions
在数据集中,存在着同一时刻对同一个出租车有多个GPS定位数据,这种数据就是重复的数据,对于这种数据只保留一个数据即可,其他的GPS定位点需要进行删除操作。字段VP_INCOMEFLAG代表的是出租车此刻是否载人,0代表空车,1代表载人。由于是研究城市交通状态,当出租车没有载客时,为了拉客会放慢速度,四处游荡寻找乘客,所以没有载客的出租车数据对于研究是没有意义的,需要进行剔除,保留VP_INCOMEFLAG为1的数据。
对于缺失值根据缺失的程度进行补全或者去除。如果某一条数据出现某个字段缺失,可以根据其他字段进行补全,例如车牌号或者出现缺失时,可以根据其终端设备ID进行补全操作。如果是经纬度或者速度这些无法通过其他信息补全的字段缺失,那么就进行删除操作。
3.2 路网匹配
路网匹配是地理服务中非常关键的一个数据处理步骤,它的作用是把GPS轨迹点匹配到实际的路网当中去。通过对GPS轨迹点的路网匹配后的数据进行挖掘和分析,就可以辅助本课题的城市区域交通状态预测研究。成都路网是从Open Street Map开源社区获取得到的。Open Street Map(简称OSM)是一款由网络众人共同携手打造的一个开源免费的世界地图,它的目标是建造一个能够任何人都可以编辑的世界地图。图7为下载成都的部分路网图。

图7 成都的部分路网图Fig.7 Partial road network of Chengdu
由于出租车GPS定位中可能会因为所处的环境,对用户设备的接收产生较大误差。例如当车辆行驶在高楼大厦之间时,可能会因为建筑的遮挡,导致卫星信号出现变弱或者中断,导致定位点于实际所在位置出现偏离。图8为GPS轨迹点偏离路网示意图。
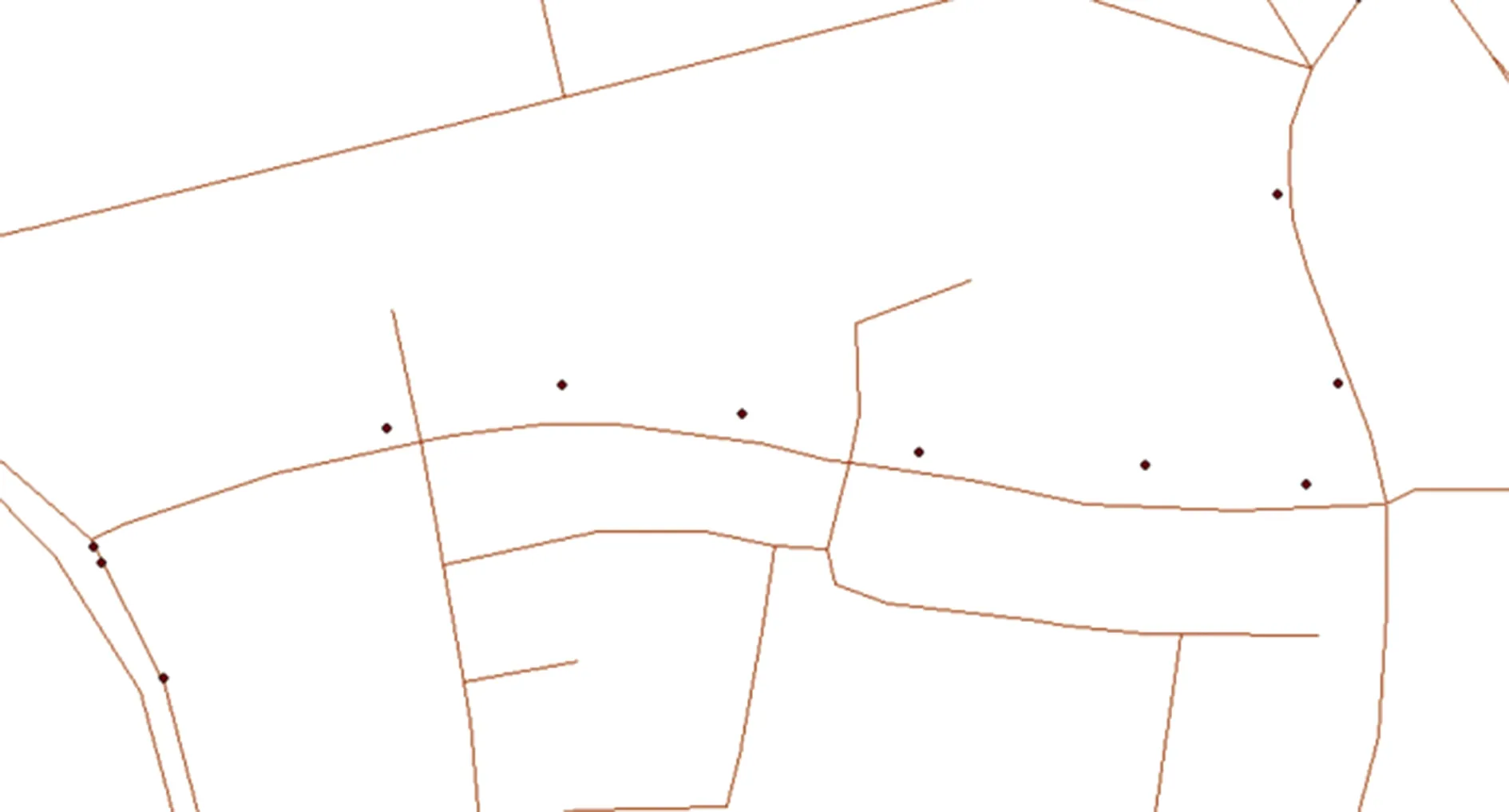
图8 GPS轨迹点偏离路网示意图Fig.8 Schematic diagram of GPS track point deviation from road network
通过路网匹配来解决GPS轨迹点偏离实际位置的问题。采用的是基于隐马尔可夫模型(hidden Markov model,HMM)的路网匹配算法。隐马尔可夫模型在进行路网匹配有较大的优势,因为它可以较为平滑地处理噪声数据,并和路径约束相整合,从而在许多可能的路径中选择出一条最大似然路径。
基于隐马尔可夫的路网匹配就是一个解码问题。因为出租车在路网的交叉路口行驶时,符合隐马尔可夫模型。出租车的GPS轨迹为隐马尔可夫中的观察序列,隐藏序列即为出租车在路网当中的经过的轨迹,即所求的真实轨迹。故基于HMM的路网匹配就是在知道出租车GPS观察轨迹的条件下,求最大可能的隐藏轨迹,即出租车实际移动的轨迹。通过这样方式,就可以把HMM应用于路网匹配中了。采用HMM进行路网匹配时,把出租车GPS位置作为观察变量,出租车在路网的真实位置为隐藏变量,而且认为下一个轨迹点的位置仅仅与上一个轨迹点的位置存在关系。
对于观察变量,可能因为各种情况,导致误差存在,所以对于每一个轨迹点都需要去确定一组候选路段。确定候选路段时,首先确定一个距离值d,以d为半径,轨迹点作为圆心画圈,在每个圆当中的路段即为该轨迹点的候选路段。每一个候选路段都被当作HMM中的隐藏变量,对每一个候选路段根据公式计算出它的概率值,这就是HMM的先验概率,该先验概率计算公式为
(8)
式(8)中:j为这一时刻GPS点的候选路段的序号;dis为这一时刻GPS点到候选路段的距离;σ为根据具体情况设置的值。
下一时刻的轨迹点位置只与上一时刻的轨迹点的位置与之间存在着关系,即t+1时刻的轨迹点位置仅与t时刻的轨迹点位置有关。那么t时刻与t+1时刻的候选路段就存在着转移概率,该转移概率的计算公式为
(9)
式(9)中:i和j分别为t时刻和t+1时刻候选路段的标号;dis为t时刻候选路段和t+1时刻候选路段的距离;β为设置的权重值。每个时刻观测值的最优匹配点为所有候选路段的先验概率和上一时刻转移概率之积中最大的候选点。过程如图9所示。表2为部分出租车GPS轨迹匹配结果。
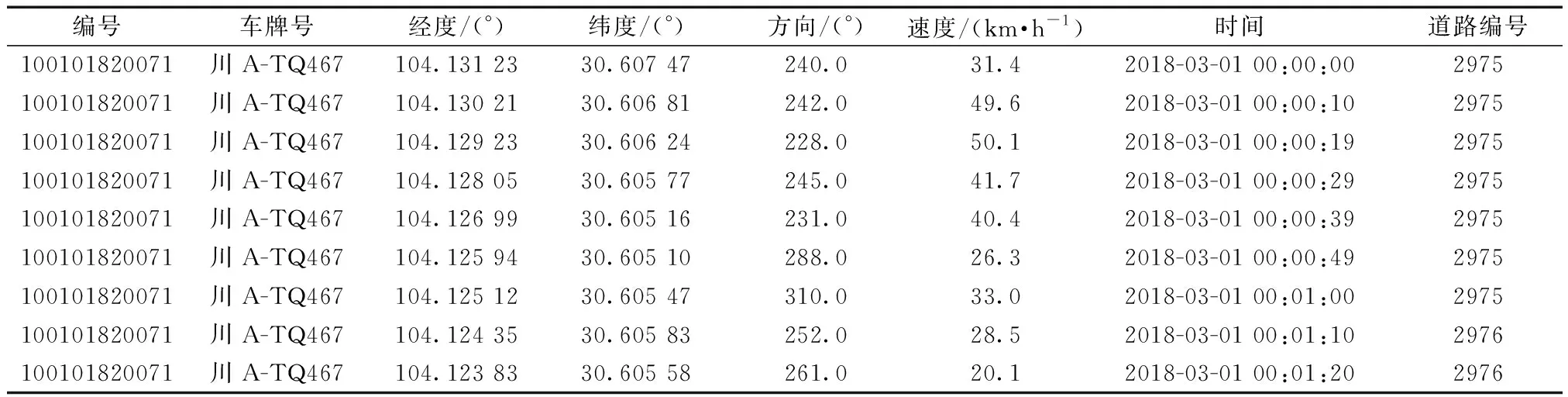
表2 部分出租车GPS轨迹匹配结果Table 2 GPS track matching results of some taxis
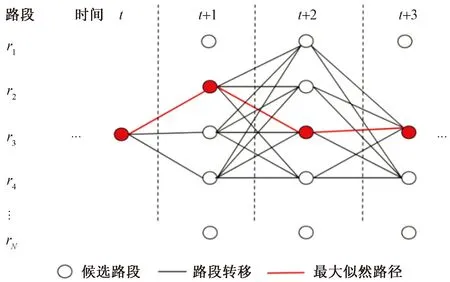
图9 基于HMM的路网匹配过程Fig.9 Road network matching process based on HMM
3.3 交通拥堵指标计算
目前,在国外有许多对交通拥堵状态进行评价的指标。国外对于城市交通拥堵评价指标主要分为4类:基于道路速度的交通拥堵指标、基于交通量的交通拥堵指标、基于路段交通密度的交通拥堵指标、其他交通拥堵计算方法。对于城市交通拥堵评价指标采用的是基于道路速度的交通拥堵指标。
INRIX Index就是典型的基于道路速度的交通拥堵指标。INRIX Index的计算核心就是基于的道路速度,通过INRIX Index来计算城市不同区域的交通拥堵指标。计算步骤如下。
步骤1计算路段的实际路段速度CSij。课题时间间隔设置为15 min,故CSij计算公式为
(10)
式(10)中:CSij为路段i第j个时间间隔的实际的路段速度;n为第j个时间间隔内通过路段i的车辆数量;Sk为通过车辆的实际速度。
步骤2计算时间间隔内每个路段的INRIX Index指标值Aij。故INRIX Index指标值Aij计算公式为
(11)
式(11)中:RSij为路段i第j个时间间隔的路段自由流速度。
步骤3计算城市不同区域的INRIX Index指标值Bij。把路段的长度作为权值系数对Aij进行加权求平均,Bij计算公式为
(12)
式(12)中:Bij为城市区域i第j个时间间隔INRIX Index指标值;Lk为路段长度;N为城市不同区域里面的路段总数。
3.4 城市网格区域划分
通过网格划分的方法,将成都市城区划分为8×8不重叠的网格区域,每个网格长为3.2 km,宽为2.9 km。图10所示为成都市网格区域划分示意图。
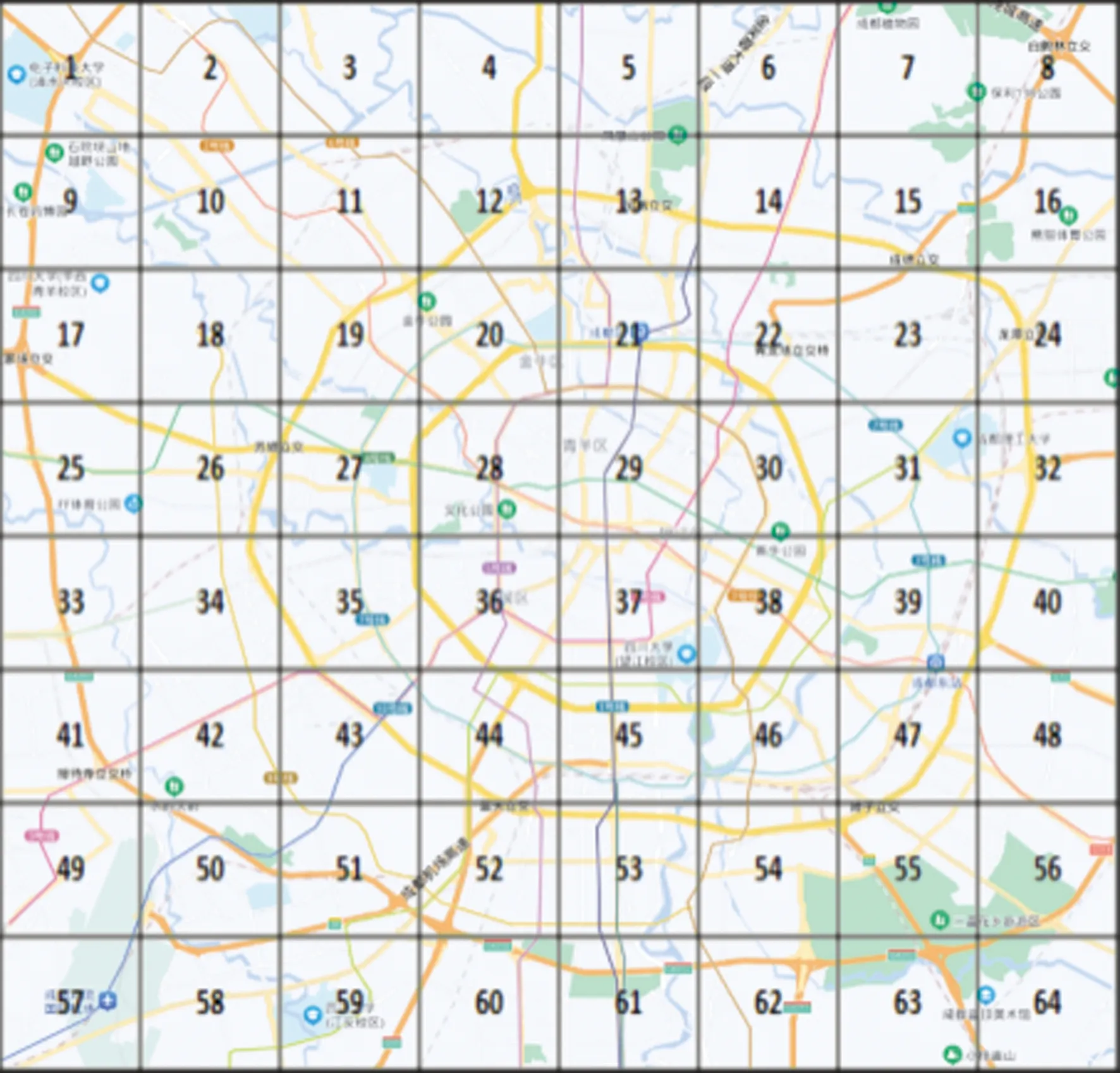
图10 成都市网格区域划分示意图Fig.10 Schematic diagram of grid area division in Chengdu
通过INRIX Index计算城市不同区域的INRIX Index指标值Bij。表3为2018年3月1日9:00—9:15成都市各个网格区域的拥堵指标。
4 实验与结果分析
4.1 基准指标及实验参数设置
采用均方误差(mean square error, MSE)、平均绝对误差(root mean square error, MAE)来测试模型训练的效果,详细计算公式如下。
(13)
(14)
4.2 性能对比
为了验证模型的预测效果,选取了CNN和CNN-Transformer来进行对比。把数据集前23 d的数据作为训练数据,后8 d的数据作为测试数据。时间选取了3月24日和3月27日,分别为周末和工作日。对整个城市区域的平均拥堵指标进行比较,城市区域的平均拥堵指标为城市各个区域的拥堵指标除以区域数而得到的平局值。预测模型采用CNN模型、Transformer模型、CNN-Transformer模型以及CS-Transformer模型进行预测对比。
图11~图14为各个预测模型在3月24日的城市区域平均拥堵指标预测对比图。
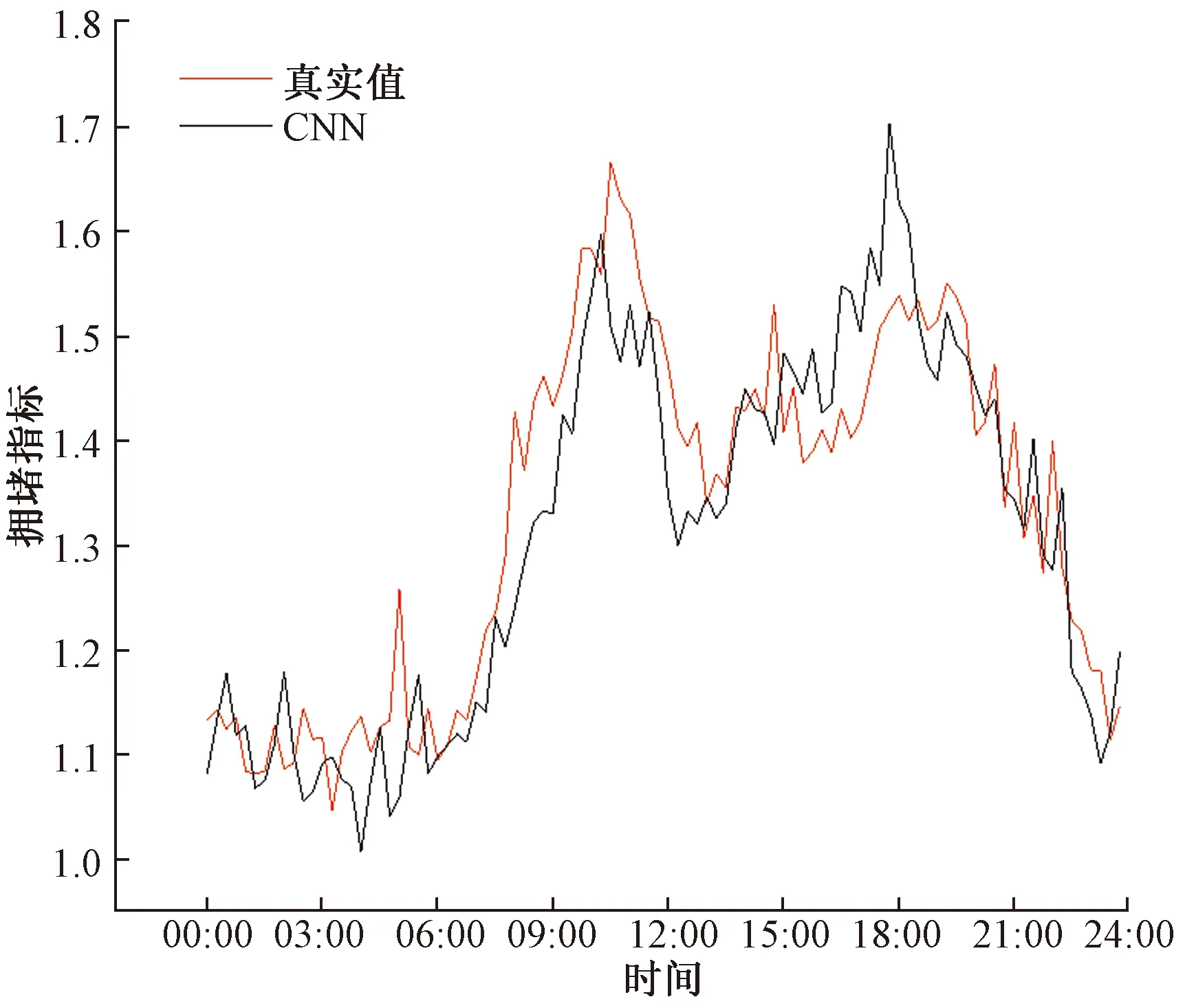
图11 CNN模型城市区域平均拥堵指标预测对比图Fig.11 Comparison chart of CNN model urban area average congestion index forecast

图12 Transformer模型城市区域平均拥堵指标预测对比图Fig.12 Comparison of forecast of average congestion indexes in urban areas of Transformer model

图13 CNN-Transformer模型城市区域平均拥堵指标预测对比图Fig.13 Comparison chart of forecast of average congestion indexes in urban areas of CNN-Transformer model

图14 CS-Transformer模型城市区域平均拥堵指标预测对比图Fig.14 Comparison chart of forecast of average congestion index in urban area of CS-Transformer model
图15~图18为各个预测模型在3月27日的城市区域平均拥堵指标预测对比图。
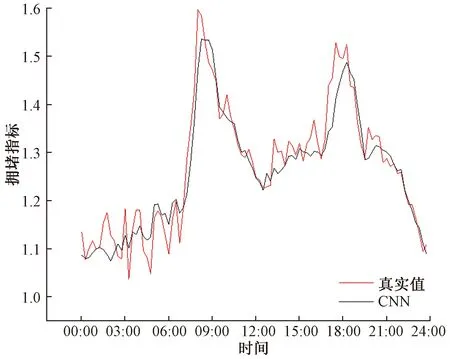
图15 CNN模型城市区域平均拥堵指标预测对比图Fig.15 Comparison chart of CNN model urban area average congestion index forecast

图16 Transformer模型城市区域平均拥堵指标预测对比图Fig.16 Comparison of forecast of average congestion indexes in urban areas of transformer model
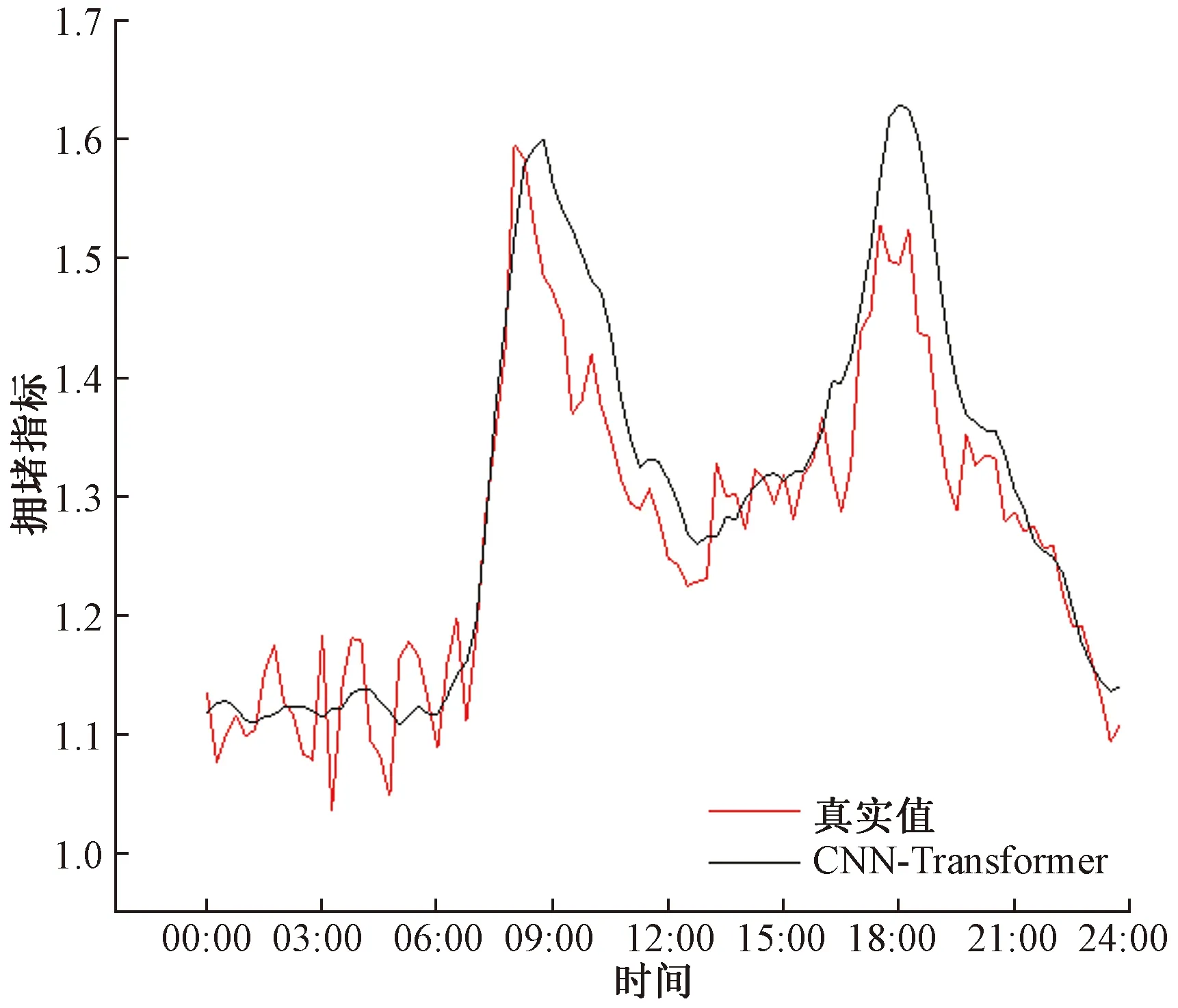
图17 CNN-Transformer模型城市区域平均拥堵指标预测对比图Fig.17 Comparison chart of forecast of average congestion indexes in urban areas of CNN-Transformer model
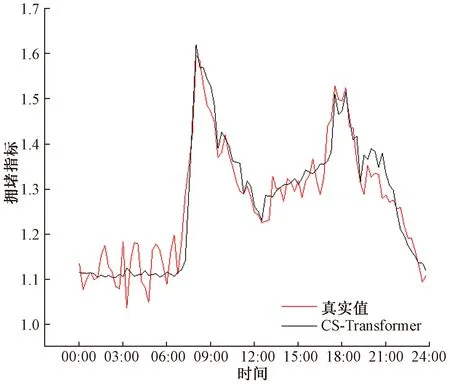
图18 CS-Transformer模型城市区域平均拥堵指标预测对比图Fig.18 Comparison chart of forecast of average congestion index in urban area of CS-Transformer model
再选用均方误差(MSE)、平均绝对误差(RMSE)来测试模型训练的效果,结果如表4所示。

表4 预测指标对比表Table 4 Comparison of prediction indexes
通过预测对比图以及MSE和MAE对几个模型进行对比可以发现,仅仅使用Transformer模型进行交通状态预测,效果是最差的,这是因为单一的Transformer只捕捉到了交通数据的时间特征,而忽略了交通数据的空间特征。其次是CNN模型,因为CNN模型考虑了交通的空间特征和时间特征,所以预测效果比仅考虑了时间特征的Transformer效果要好,但由于单一的CNN模型不能够有效地捕捉交通数据的时空特征,所以预测效果相比于CNN-Transformer要差一些。
CNN-Transformer模型由CNN空间组件和Transformer时间组件两部分组成。使用CNN组件提取交通数据的空间特征,采用全连接神经网络增强模型的表达能力。然后将这些特性输入Transformer组件,运用Transformer 组件捕捉交通数据的时间依赖特征。通过CNN-Transformer模型可以更加有效地提取交通数据的时空特征,进一步提高预测精准度。
CNN-Transformer模型虽然进一步提高了精确度,但仍有一定缺陷。CNN-Transformer模型中的时间组件Transformer不包含循环和卷积,为了使模型利用序列的顺序,必须给输入的序列加入一些关于位置的信息。故在编码器和解码器堆栈底部的输入嵌入中添加了位置编码。位置编码后的序列与嵌入序列具有相同的维数,通过直接相加的方式向输入的序列加入位置信息。由于考虑到了交通数据的时间连续性,位置编码包括全局位置编码和局部位置编码,如果把位置编码直接通过相加的方式为输入的序列加入一些关于位置的信息,可能会隐藏序列之间的其他关系,导致训练模型更加困难,降低预测的精准度。
CS-Transformer基于CNN-Transformer模型位置编码的缺点,做出了进一步改进,提出了一种改进的方式,把位置编码更好地融合到了输入的序列中,既为输入的序列加入一些关于位置的信息,又可以保证位置编码不会隐藏序列之间的其他关系,导致训练模型更加困难,进一步提高了预测的精准度。
5 结论
为了准确地对城市交通状态进行预测,基于成都出租车的GPS数据,根据城市交通数据流的时空特征,提出一种基于CNN和Transformer改进的城市交通拥堵预测模型CS-Transformer。该模型通过使用卷积神经网络(CNN)提取基于网格划分的城市区域交通数据的空间特征,然后采用全连接神经网络增强模型的表达能力,最后运用Transformer网络捕捉交通数据的时间依赖特征。所提出的改进方式(相似性位置组合)把位置编码更好地融合进入输入的序列当中,既为输入的序列加入一些关于位置的信息,又可以保证位置编码不会隐藏序列之间的其他关系,导致训练模型更加困难。在CNN空间组件和Transformer时间组件加上一层基于注意力机制的位置组合方式,通过对CNN-Transformer模型的进一步改进提高预测的精准度。
通过城市交通预测,可以及时地帮助出行者规划出一条合理的路线,提高交通安全,避免时间的浪费,从而提高城市交通的运行效率,极大避免了城市交通拥堵的出现。对城市交通进行准确的预测对于支持城市交通的管理者管理城市网络,并合理地分配资源具有重大意义。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
童话世界(2020年32期)2020-12-25 02:59:14
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
电子制作(2019年19期)2019-11-23 08:42:00
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
小学生导刊(2018年16期)2018-07-02 09:20:52
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
