
优化光谱指数助力机器学习提高马铃薯叶绿素含量反演精度
2023-09-26 01:03:44杨海波贾禹泽
植物营养与肥料学报 2023年8期
刘 楠,李 斐*,杨海波,尹 航,高 飞,贾禹泽,2,孙 智
(1 内蒙古农业大学草原与资源环境学院 / 内蒙古自治区土壤质量与养分资源重点实验室 / 农业生态安全与绿色发展自治区高等学校重点实验室,内蒙古呼和浩特 010011;2 内蒙古包头市园林绿化事业发展中心,内蒙古包头 014010)
马铃薯主粮化对保障我国粮食安全以及农民经济收入起到了极大的促进作用[1]。叶绿素是光合作用的重要色素,直接影响马铃薯的能量物质转换与传输过程,也实时反映了马铃薯的营养状况[2]。大量研究表明叶绿素含量与氮素有较好的相关性,通过叶绿素含量可以对农作物的氮含量进行间接的估测[3-4],所以叶绿素含量的实时监测对于氮素精准管理起到了重要的作用。传统的叶绿素含量测定方法在测定过程中会造成叶绿素的损失,导致结果变异性高,并且实验室测定过程用时较长而且复杂,采样时破坏性强,不适用于现代农业的需求[5]。由于作物的反射率主要受叶绿素含量的影响[6],所以遥感技术已经成为叶绿素含量实时无损估测的主要途径。通过SPAD 值来表征相对叶绿素含量已经得到国内外研究者的认可,前人使用手持叶绿素仪对叶绿素含量进行快速的测定,所得结果与叶绿素实际含量的相关性达到了显著水平[7]。但是使用SPAD 仪进行田间叶绿素的采集是以点带面来表征群体特征,这就需要在田间进行大量的测定,费时费力,而且对于马铃薯作物来说,封垄后很难进入田间开展多点大面积采集,某种程度上不便于使用这种方法对田块氮素养分状况进行更精准的测定。
光谱指数估测方法由于计算方法方便快捷而备受研究人员的欢迎。通过研究发现,光谱的红边区域包含了农作物的重要生长信息,所以利用此范围光谱信息建立的光谱指数多用于预测植物的生理参数,并且研究发现其与叶绿素的相关性较高[8]。然而,大多数的光谱指数在作物生育前期容易受到土壤背景和冠层结构的影响[9],生育后期存在饱和问题,导致估测精度降低[10],为了解决这一问题,学者们优化敏感波段,构建优化光谱指数[11]。通过基于面积估算叶绿素含量的光谱指数类型进行优化,然而优化后的光谱指数由于波段少、稳定性差,对叶绿素含量、氮含量和叶面积指数的估测精度也不尽人意[12-14]。并且光谱指数的敏感波段受到生育时期、地点以及品种等外在因素和光谱指数计算公式内在因素的影响,敏感波段的位置会发生变化,导致已经发表的光谱指数在面对本地化的数据时往往不能达到满意的效果。因此,为了得到高精度的光谱指数来指导当地的监测,对不同方程形式的光谱指数波段进行优化设计仍然是国内外研究热点,在小麦[15-16]、玉米[17-18]、水稻[19]和马铃薯[20]作物参数反演中扮演着重要角色。
随着人工智能的发展,越来越多的学者利用机器学习算法对农作物参数进行估算,如叶面积指数,生物量等[21-22]。机器学习算法根据输入变量和输出变量的数学关系,将模型分为线性非参数模型和非线性非参数模型。研究表明,机器学习算法对大田作物的叶绿素含量能进行有效估测[23-24]。然而,机器学习算法众多,建立的模型稳定性受较多因素的影响,而且计算程度也较为复杂[25],找到一个合适且估测精度高的模型较难。最常用的机器学习算法有非参数线性的偏最小二乘法和非线性的随机森林模型,但是输入变量的选择显著影响了模型的稳定性和估测能力[26]。偏最小二乘法主要运用主成分分析的统计学方法,可以提取出光谱数据中的冠层信息,可以削弱光谱中噪音的影响,但其解决非线性问题的能力较弱[27];随机森林模型一般估测能力变化较大,导致建模集相关性较好,验证集相关性较差[28]。不同输入变量如原始全光谱波段、提取的敏感波段以及组合计算形成的不同形式的光谱指数,分别作为偏最小二乘法和随机森林模型的输入变量,进行玉米、小麦等作物叶绿素含量建模得到有效发展[29-30]。然而,作为我国第四大主粮作物,马铃薯由羽状复叶组成,冠层结构与小麦、玉米和水稻等作物冠层结构有较大的区别,叶绿素是一个重要的作物生长和氮素营养诊断指标,很有必要进行马铃薯叶绿素含量实时监测方法及其应用的研究。
我国西北地区水资源匮乏,作为我国马铃薯种植一作区,滴灌为主要灌溉方式,马铃薯叶绿素的实时监测对滴灌农田进行多次施肥具有重要的意义。本研究以内蒙古马铃薯主产区田间试验为基础,利用马铃薯冠层光谱数据,选用光谱指数算法和最常用的偏最小二乘法、随机森林算法进行马铃薯叶绿素含量建模,评价方法的优劣,比较不同输入变量对两种机器学习算法马铃薯叶绿素含量估测精度的影响,最终得到具有普适性的估测模型,为大田尺度上马铃薯叶绿素含量的监测提供理论支持。
1 材料与方法
1.1 试验设计
分别于2019、2020 年开展两个田间试验,试验地灌溉方式为滴灌,田间管理按照当地大田要求,统一管理。具体试验设计如下:
2019 年的试验在集宁大十号村进行,供试品种为‘冀张薯12’,设有7 个氮水平分别为0、75、150、220、250、300、375 kg/hm2,小区面积76 m2,两垄中心相距为0.9 m,株距为20 cm。试验田每个处理设4 次重复,各小区随机排列。
2020 年的试验在四子王进行,供试品种为‘希森6 号’,设有5 个氮水平分别为198、202、229、287、317 kg/hm2,小区面积120 m2,两垄中心相距为0.9 m,株距为30 cm。试验田每个处理设4 次重复,各小区随机排列。
1.2 光谱数据的采集
马铃薯冠层光谱数据的测定需要选择在天气晴朗、无风的状况下进行,测定的时间段为10:00—14:00。每个小区扫描3 次,最终测定结果取3 次扫描的平均值。光谱仪(tec5, Oberursel)的波段范围为300~1150 nm,探头在测定时距马铃薯冠层高度为50~80 cm,随机选择具有代表性的两行马铃薯植株进行光谱测定。400 nm 以下的波段噪声较大,导致光谱的不连续,为了去除影响,采用的波段为400~1150 nm。2019 和2020 年的马铃薯数据分别进行了4 次采样:苗期、块茎形成期、块茎膨大期、淀粉积累期。苗期和块茎形成期为花前,块茎膨大期和淀粉积累期为花后。
1.3 叶绿素的测定
叶绿素含量的测定采用SPAD-502 型手持式叶绿素仪,在获取光谱的当天同步测定马铃薯的SPAD值,每处理选取代表其生长势的马铃薯植株20 株,每株取功能叶片(倒4 叶)进行测量,取平均值作为该样本的SPAD 值。通过SPAD 值与叶绿素含量的线性关系[31],将SPAD 值转换为叶绿素含量进行估测。具体计算公式如下:
式中:y是SPAD 值;x是叶绿素含量,单位mg/g;r=0.97。
1.4 光谱指数的选择与优化
为了消除光谱指数具有的散射问题,学者们提出了反射率差比(RRD)等式[32]。公式如下:
式中:h、i、j和k代表全光谱范围内的随机波长,本研究中h、k相等。
使用波段优化算法来确定RRD 型光谱指数的最佳波段组合,本研究选取了已发表与叶绿素相关性较高的光谱指数进行建模与波段优化,波段组合与计算形式大不相同。三波段光谱指数进行优化时,固定算法中最小的光谱波段,对其他波段进行优化。在400~1150 nm 波段范围内,按表1 中的公式,将所有波段两两组计算的光谱指数与叶绿素含量进行相关矩阵图的绘制,横、纵坐标皆为光谱反射波段(图1)。图1 中颜色代表原光谱根据计算公式组合后的光谱指数与叶绿素含量的决定系数,颜色越红代表公式与叶绿素含量的相关性越好,决定系数最高的光谱指数波段组合确定为敏感波段[39]。

图1 马铃薯叶绿素含量与不同波段光谱指数之间线性拟合决定系数(R2)的等值线图Fig.1 Contour maps of the coefficient of determination (R2) between potato chlorophyll content and spectral indices

表1 供试光谱指数Table 1 Spectral indices used in this study
1.5 机器学习
本研究采用ANDCONDA NAVIGATOR 中Jupyter的python 编辑器,采用的机器学习方法为偏最小二乘和随机森林,本研究机器学习模型的输入变量有两类,一类是376 个原光谱波段,第二类是根据表1 的公式结合图1 计算出与叶绿素含量相关性最高的6 类优化光谱指数(优化比率光谱指数、优化归一化光谱指数、优化红边氮指数、优化红外叶绿素光谱指数、优化修正红边比指数、优化修正归一化指数)。
1.5.1 随机森林算法 随机森林算法是高维数据分类和回归方法,属于集成算法,主要是运用多棵树的投票机制来解决预测问题。用N来表示训练用例(样本)的个数,M表示特征数目。输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。从N 个训练用例(样本)中以有放回抽样的方式,取样N 次,形成一个训练集,并用未抽到的用例(样本)作预测,评估其误差。对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。对于回归预测的问题,随机森林算法将多棵树的回归结果进行平均,作为预测样本的结果。
1.5.2 偏最小二乘法 偏最小二乘法是一种多元统计的数据分析方法,它主要研究多因变量或单因变量对自变量的回归建模。高光谱数据建立回归模型往往存在共线性,偏最小二乘法不仅可以克服共线性问题,它在选取特征向量时强调自变量对因变量的解释和预测作用,去除了对回归无益输入变量的影响。在建立模型的过程中,偏最小二乘法可以识别光谱信息和噪声,能够有效的减少数据冗余。
1.6 模型的评价
本研究综合已有的光谱指数算法并在EXCEL、Matlab、python 软件实现优化以及计算。建模集分别采用花前、花后和全部数据集的75%进行建模,验证集分别采用花前、花后和全部数据集的25%进行验证。在田间试验资料的基础上,筛选对叶绿素含量敏感的光谱指数,并建立模型,利用决定系数(R2)、均方根误差(RMSE,mg/g)和相对误差(RE,%)综合评价模型,并绘制建模模型或者建模集和验证集的1∶1 关系图。
计算公式如下:
式中:n为样本个数,yi为实测值,i为预测值,为平均值。
2 结果与分析
2.1 基于光谱指数的马铃薯叶绿素含量反演
本研究选择最常用6 类光谱指数(表1)对马铃薯各生育时期的叶绿素含量进行估测,表2 展示了各光谱指数与马铃薯各生育时期叶绿素含量的关系决定系数。从表2 看出,6 类光谱指数与马铃薯叶绿素含量没有很好的相关关系。尤其是花前光谱指数与马铃薯叶绿素含量几乎没有相关性,不能对马铃薯叶绿素含量进行预测;花后光谱指数mNDblue与马铃薯叶绿素含量相关性较好,决定系数达0.44;从整体来看,光谱指数与马铃薯叶绿素含量的相关性较差,其中决定系数最高的是光谱指数mNDblue。

表2 已发表光谱指数与马铃薯叶绿素含量的关系决定系数Table 2 Coefficient of determination of the relationship between published spectral indices and potato chlorophyll content
光谱指数对马铃薯叶绿素含量进行估测的过程中,生育前期由于植株较小,叶片无法有效覆盖扫描区域,在数据采集过程中容易受到土壤背景的影响;生育后期由于叶绿素含量过高,光谱指数会出现数据饱和现象。为了解决这些问题,提高光谱指数在马铃薯叶绿素含量上的估测能力,本研究以选择的6 类指数算法为依据,利用不同光谱指数与叶绿素含量的相关矩阵图进行寻优,确定不同类型的优化光谱指数(图1)。光谱指数经过优化后的敏感波段主要集中在紫光和绿光范围。可以看出6 类光谱指数与马铃薯叶绿素含量的相关性都在0.5 以上,其中相关性最好的为优化的NDVI,决定系数(R2)为0.64,敏感波段组合为408 和552 nm。
为了进一步验证构建优化光谱指数的稳定性和鲁棒性,对大田实测数据与优化后的指数进行不同生育时期相关性分析(表3)。结果表明,对光谱指数中心波段进行优化,可以有效的提高光谱指数估测马铃薯叶绿素含量的能力。在马铃薯花前6 类优化光谱指数与实测数据的相关性较差,决定系数的范围为0.03~0.31;在马铃薯花后优化光谱指数与叶绿素含量的相关性较好,其中光谱指数Opt-NDVI 最好,决定系数为0.81。这些结果表明,生育时期显著影响了光谱指数对马铃薯叶绿素含量的估测能力。

表3 优化光谱指数与马铃薯叶绿素含量的关系决定系数Table 3 Coefficient of determination of the relationship between optimized spectral indices and potato chlorophyll content
2.2 基于PLSR 和RF 算法的建模
为了探索模型输入变量的优劣,从而选择最优马铃薯叶绿素含量估测模型,本研究以376 个光谱波段和6 个优化光谱指数作为输入变量进行建模。从基于机器学习模型的决定系数(表4) 可以看出,随机森林的建模能力最好,其中以优化光谱指数作为输入变量的随机森林模型更优,且受生育时期的影响较小;偏最小二乘法中建模能力较好的是以原光谱波段作为输入变量的模型,受生育时期的影响较大,在花前模型的决定系数较低为0.55,在花后模型的决定系数较高为0.84。与优化指数估测模型相比,机器学习明显提高了马铃薯叶绿素含量的估测能力。

表4 基于机器学习模型的决定系数 (R2) 和均方根误差(RMSE)Table 4 Coefficient of determination and root-mean-square-error (RMSE) based on machine learning models
从以优化光谱指数为输入变量的随机森林和以原光谱波段作为输入变量的偏最小二乘法模型的散点图(图2)可以看出,随机森林的数据分布较为集中,并且通过花前、花后和所有数据集来看,建模能力较为稳定;而偏最小二乘法模型的数据集较为分散,且在花前模型的分散度较大。

图2 优化光谱指数作为输入变量的随机森林建模和原始光谱波段作为输入变量的偏最小二乘法建模Fig.2 Random forest modeling with optimized spectral indices as input variables and partial least square modeling with original spectrum band as input variables
2.3 模型的评价
模型的鲁棒性和准确性取决于建模时的决定系数和均方根误差,本研究采用了验证集均方根误差(RMSE,mg/g)和相对误差(RE,%)对模型进行了评价。从表5 可以看出,在马铃薯花前模型验证能力最好的是以优化光谱指数作为输入变量的随机森林模型,验证集的决定系数(R2) 为0.60;在花后,以优化光谱指数作为输入变量的偏最小二乘法模型的验证集最差,决定系数(R2)为0.50,其中最好的模型验证集是以优化光谱指数为输入变量的随机森林模型,决定系数(R2)为0.89;所有数据中,以优化光谱指数作为输入变量的偏最小二乘法的精度最高,均方根误差(RMSE,mg/g)和相对误差(RE,%)最小,分别为0.91 mg/g 和4.75%。
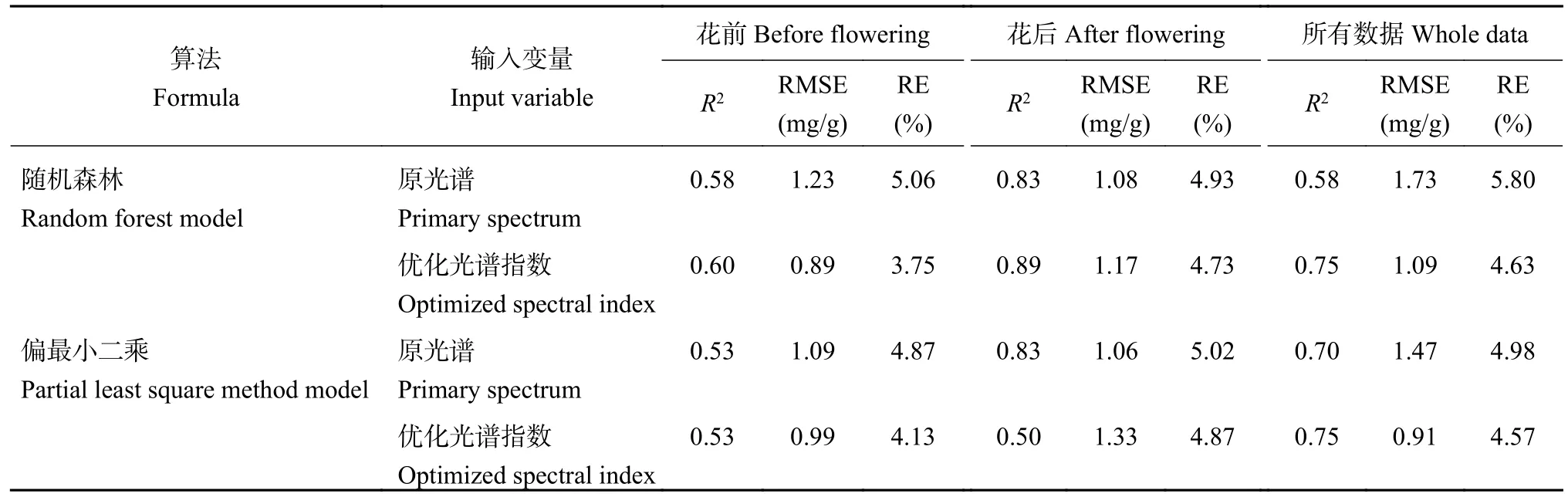
表5 基于机器学习验证集的决定系数(R2)、均方根误差(RMSE)和相对误差(RE)Table 5 Coefficient of determination (R2), root mean square error (RMSE), relative error (RE) of machine learning model based on validation dataset
综合比较以上验证数据集,随机森林模型中,以优化光谱指数为输入变量模型的验证集相关性最好,各生育时期的决定系数最高,且均方根误差(RMSE, mg/g)和相对误差(RE, %)最低;偏最小二乘法模型中,花前,优化光谱指数建立模型的验证集较好,RMSE 和RE 较低,花后以原光谱波段作为输入变量的模型验证集最好,R2最高,为0.83。但是以优化光谱指数为输入变量的偏最小二乘法建立模型的花后验证集较差,R2为0.50 (表5)。为更直观的比较输入变量和两种机器学习模型的验证能力,本研究同样对二者进行作散点图分析(图3)。从图3可以看出,两种模型的验证数据集均匀的分布在1∶1 线周围,偏最小二乘法的验证集数据分布较为分散,且受生育时期的影响,马铃薯花前验证集相关性较差;随机森林模型的验证集,实测值和估测值离散程度较小,分布较为紧密,验证精度明显较高。经过决定系数、均方根误差以及相对误差的综合评价,以优化光谱指数作为输入变量的随机森林模型的验证效果最好,并且受生育时期的影响较小,所以可以用随机森林模型对马铃薯叶绿素含量进行估测。

图3 优化光谱指数作为输入变量的随机森林模型和原始光谱波段作为输入变量的偏最小二乘法模型验证Fig.3 Validation of random forest modeling with optimized spectral index as variables and partial least square modeling with original spectrum band as variables
为了探究生育时期对模型精度的影响,本研究利用花前和花后的数据进行作图(图4),优化后的光谱指数虽然可以提高与叶绿素含量的相关性,但其验证集的数据较为分散(图4a),尤其在生育前期,对模型的精度影响较大;而优化光谱指数作为输入变量的随机森林模型,验证集的数据较为集中且均匀,说明该模型不仅提高了鲁棒性,同时也克服了马铃薯生育时期的影响(图4b)。为了验证模型的实用性,通过PROSAIL 物理模型的模拟也进一步证明了基于优化光谱指数的随机森林模型在某种程度上普适性也较高,模型建模与验证比较稳定(图5)。

图4 基于优化光谱指数模型(a)与优化光谱指数作为输入变量的随机森林模型(b)验证Fig.4 Validation of optimized spectral indices modeling (a) and random forest modeling with optimized spectral index as input variables (b)

图5 基于PROSAIL 模拟数据库计算优化光谱指数作为输入变量的随机森林模型建模(a)与验证(b)Fig.5 Calibration (a) and validation (b) of random forest model based on PROSAIL simulation database with optimized spectral index as input variable
3 讨论
马铃薯叶绿素含量的实时监测是大田管理的前提,随着人工智能的快速发展,将来基于光谱和机器学习算法相结合的监测方法最可能成为叶绿素含量估测的主要途径,然而由于输入变量以及估测模型的复杂性使得机器学习算法估测精准度和稳定性变化较大。本研究利用波段优化算法对光谱指数波段进行优化,随后将优化后的光谱指数与原始光谱波段作为机器学习的输入变量,对不同输入变量的机器学习模型进行比较。通过分析模型的精确性和稳定性证明了以优化光谱指数作为输入变量的随机森林模型预测能力最好,可用于马铃薯叶绿素含量的估测,为机器学习估测马铃薯叶绿素含量提供了理论依据。
光谱波段的组合对光谱指数的预测能力具有显著的影响,而光谱指数的敏感波段实际上主要受到光谱指数方程形式、环境、作物品种和生育时期等因素的影响,从而造成敏感波段在选择上的差异[10,20]。本研究发现优化光谱指数敏感波段在紫光和绿光范围与马铃薯叶绿素含量的相关性最佳,绿光波段在估测马铃薯叶绿素含量的过程中体现出较好的效果[40]。基于紫光408 nm 和绿光552 nm 构建的优化光谱指数Opt-NDVI 在本研究中具有较好的估测效果,这与前人提出来的NDVI (680、800 nm)光谱敏感波段有较大的差别,这可能是因为原NDVI (680、800 nm)是基于玉米叶绿素含量建立,而马铃薯与玉米在生育时期方面有显著的差异[41],所以,作物种类和生育时期会影响光谱指数的估测能力。因此,针对指定作物进行波段优化从而筛选出最佳的敏感波段对提高叶绿素含量估测具有重要意义。
生育时期也是影响光谱指数对叶绿素含量估测能力的重要因素,所以很多研究指出基于光谱指数简单线性回归方法并不能很好地实现作物跨生育时期的叶绿素含量监测[42]。一般而言,在马铃薯花前光谱信息中含有大量的非植被信息,尤其是土壤影响较为突出。随后,花蕾的出现也会干扰到高光谱的预测,所以在花前准确估测马铃薯叶绿素含量有一定的难度[31,43],这也是为什么在马铃薯生育前期优化光谱指数与叶绿素含量线性关系较差的原因。随着生育时期的推进,马铃薯花后时期的冠层相对稳定,土壤背景对光谱波段影响较低,因此有关植被的特征信息增多,优化光谱指数在花后估测叶绿素含量的效果最佳,可见分生育时期对光谱指数进行优化十分重要。
机器学习算法在植被参数估测中具有巨大的潜力。与前人研究结果[44]一致,本研究中优化光谱指数作为机器学习模型输入变量,显著提高了马铃薯叶绿素含量的估测能力。此外,本研究发现输入变量以及机器学习算法对估测模型的预测精度具有一定影响。传统的机器学习算法大多直接使用光谱仪、传感器测量的波段,或者选择几个简单的已发表光谱指数作为机器学习算法的输入变量来训练机器学习模型,而本研究探究了使用优化光谱指数输入到机器学习算法中构建模型的预测性能。优化光谱指数作为输入变量优于原光谱波段,因为光谱波段在采集的过程中,受到环境等因素影响,使光谱中包含的信息太过复杂冗余,这对机器学习建模有不利的影响[2,45]。而光谱指数优化后放大了波段对指标的敏感性,这种叠加效应可以显著提高输入变量的质量和稳定性,也避免了冗余波段的干扰。实际上对光谱数据进行了降维处理,并且方程形式的组合可以挖掘到更多有价值的信息[46]。可以看出,光谱指数提取的敏感波段在前人研究中都有提及,所以通过波段优化算法提取的马铃薯叶绿素含量并没有添加其他与植被不相关的信息[47]。就模型类型来说,本研究中随机森林较偏最小二乘法具有更好的估测水平。基于无人机遥感影像的研究结果也证实了这一点[48]。偏最小二乘法以主成分分析为信息提取基础,当使用光谱波段作为输入变量时,可以较准确的提取对叶绿素敏感的光谱成分[27]。不过很多研究指出,偏最小二乘法在处理线性问题时模型可以表现出较好的能力,但处理非线性问题时,体现不出自身优势。而随机森林属非线性回归算法,不仅能够高效的处理大规模数据集,而且能很好地控制数据的噪声和鲁棒性[48]。但是也应注意机器学习算法在模型训练时的过拟合问题,本研究中模型的训练集和验证集结果差异较大,很可能是因为模型在训练时对数据进行了过度的解读,导致了过拟合现象,从而降低了模型的泛化能力,最终表现出模型在训练集上的精度高于验证集的精度[49-50]。因此,在以后的研究中应该重视对机器学习算法中超参数的控制以降低模型过拟合的问题。此外,验证集数据效果明显低于训练集也与验证集数据本身比较接近有关,较小的数据变化范围使估测值与实测值的数据点比较集中,从而影响了相关性。而训练集数据集的数据样本较多,由高到低的变异性更大,有利于估测模型的建立。为了避免这种现象,应通过多年多点的试验尽可能增加训练集和验证集的数据量[51]。而PROSAIL模型是一个很好的工具,该模型可以通过指定的参数生成大量的模拟数据,帮助随机森林进行模型的训练与验证[28],来提高模型的稳定性与普适性,进一步验证了以优化光谱指数作为输入变量的随机森林估测马铃薯叶绿素含量的方法的可行性。
本研究的结果证明,优化光谱指数作为输入变量建立的机器学习估测模型,估测能力优于优化光谱指数估测模型。优化光谱指数作为输入变量提高了机器学习算法的估测精度,克服了光谱指数估测叶绿素含量时容易“饱和”的缺点,还大大提高了机器学习算法的计算效率,提升了精准农业的高效性和实时性,为今后新型传感器的研制提供了理论基础。然而,本研究的地点所属区域属于我国马铃薯种植的一作区,马铃薯品种众多,不可避免会导致估测模型具有一定的局限性,模型的普适性有待完善。因此,在今后的研究中,应扩大品种范围,加大测定数据量,以提高模型的普适性。
4 结论
光谱指数的预测能力受生育时期的影响较大,优化光谱指数作为输入变量不仅有效减少了输入变量数量从而提高了随机森林算法和偏最小二乘法的计算效率,而且使预测精度有所提高。基于优化光谱指数的随机森林算法对马铃薯叶绿素含量的估测精度最高,在各生育时期都具有较好的估测能力,克服了生育时期的影响,利用该方法可对马铃薯叶绿素含量进行估测。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
少儿科学周刊·儿童版(2021年21期)2021-12-11 01:45:00
阅读(科学探秘)(2020年8期)2020-11-06 06:22:48
中国果业信息(2019年1期)2019-01-05 17:41:42
生物学教学(2017年9期)2017-08-20 13:22:32
陕西画报(2016年1期)2016-12-01 05:35:30
高师理科学刊(2016年8期)2016-06-15 20:27:45
创新作文(小学版)(2016年31期)2016-03-11 19:08:09
西藏科技(2015年4期)2015-09-26 12:12:58
福建农业科技(2015年3期)2015-02-27 10:20:48
