
Markov网络查询扩展模型综述
2023-09-25 03:39王千千王英
电脑知识与技术 2023年22期
王千千,王英
(1.江西工业职业技术学院,江西 南昌 330039;2.江西师范大学,江西 南昌 330022)
0 引言
近年来,互联网迅速发展,人们对信息的需求快速增长,获取信息的方式大部分通过Google、百度、火狐等搜索引擎,查询的精确度和准确率成为衡量搜索引擎的指标。由于用户表达查询的模糊性以及查询语句的多样性等原因,造成检索效果不理想。查询扩展是提高精确度和准确率的有效方式,查询扩展是通过向查询语句加入新的关键词来重构查询语句,使得新的查询语句包含更多的有效信息,从而检索更多的有效文档[1]。
查询扩展的方法有许多种[2]。人工的查询扩展,相关反馈的查询扩展,基于人工字典wordNet、How-Net等查询扩展,还有利用图形网络的查询扩展方式。人工查询扩展是指用户根据自己的想法修正查询;相关反馈的查询是通过用户交互来提高检索的效果;基于人工字典的查询扩展是通过相关的算法从字典中查询相关的词,加入查询语句提高检索效果。常用的网络图像查询扩展模型有贝叶斯网络、推理网络以及信任网络[3],这些网络模型能较好地提高检索的效果。Markov网络也是一种图像网络模型,它是一种不确定性推理的有效工具,常用其表示知识之间的关联度。Markov网络图模型是由节点构成的无向图,通过训练数据集构建无向图。 Markov 网络无方向性,计算的开销很小,构造Markov 网络比发现贝叶斯网络简单,因此Markov 网络模型成为信息检索的常用网络图模型。
本文根据扩展词的来源将Markov 查询扩展模型分为以下几种:基于层次的Markov 网络查询扩展模型、基于团的Markov网络检索模型以及基于其他方式的Markov 网络查询扩展模型。文章首先详细介绍这三种类型的网络图模型,然后介绍实验的数据集和评价指标,最后对未来的研究方向和发展趋势进行展望。
1 基于层次的Markov网络查询扩展模型
Markov网络可以表示为一个二元组(V,E),V表示节点的集合,E 表示无向边的集合。左[3]等将查询与文档构造为Markov网络检索模型,如图1所示。
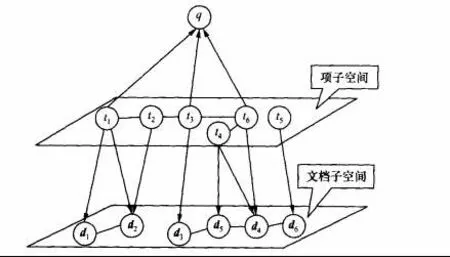
图1 Markov网络检索模型
模型分为三层,查询子空间、词项子空间和文档子空间,所有的层构成了一个推理网络,图1中q代表查询子空间的查询项,t代表词项子空间的词项,d代表文档子空间的文档。
通过互信息构造词项子空间,公式如下:
如果式(1) 大于给定的阈值,则词项子空间tj和tk有边存在,否则不存在。
通过文档向量之间的相似度构造文档子空间,公式如下:
如果式(2) 大于给定的阈值,则文档di和dj之间有边存在,否则不存在。
如图1所示,原始查询q={t1,t3,t6},由于t1与t2有关联,t3与t2、t6有关联,t6与t3、t4有关联,即可得到扩展后的查询语句q={{t1,t2},{t2,t3,t6},{t6,t3,t4}},原始的相关文档为d={d1,d3,d4,d2,d5},扩展后的相关文档为d={d1,d3,d4,d2,d5,d6},通过实例数据的训练得到词项子空间和文档子空间,将词项子空间和文档子空间的信息加入检索模型中。
基于Markov 网络的信息检索模型通过构造词项子空间和文档子空间获得新的Markov网络,这种检索模型具备较强的表达能力,检索性能可以达到较好的提高。左家莉等[4]为信息检索搭建了一个基准平台,在其基础上许多工作进行了扩展,包括廖亚男[5]等提出的基于多层Markov网络检索模型,利用与已有查询的相关性来构造查询网络,将查询子空间网络、词项子空间网络和文档子空间网络融入检索模型,从而查询扩展和重构。查询子空间数据的构造是甘丽新[6]等提出的检索模型得出的检索结果,反馈给定查询对应的文档,由反馈的文档计算查询之间的相关性,接着构造查询子空间。
由于上述Markov 网络查询扩展模型中扩展词的来源仅考虑词与词之间的相关性、文档与文档之间的相关性以及查询之间的相关性,这会导致查询扩展时加入不必要的扩展词,影响检索的效果。随着研究的深入,提出了团的概念,将词团、查询团和文档团引入Markov网络查询扩展,为检索的精确度和准确率提供了一个更好的选择。
2 基于团的Markov网络查询扩展模型
该方法利用团与团之间的映射关系强化查询词与文档之间的关系,团的提取的根据是如下离散数学的定理:C是一个团,那么必存在一个最大团C∈Cmax使得,在文献[7] 中该定理的证明如下:设T={t1,t2...tk},构造团序列C0,C1,C2...Cmax。其中C0=C且Ci+1=Ci⋃{ti},其中j是满足tj∉ti,而tj与Ci中各节点都有相容关系的下标。由于T的词节点个数|T|=n,所以至多经过n- |c|步,就使得这个过程终止,而此序列的最后一个团就是要找的最大团。该方法可以分为基于文档团的Markov网络检索模型[8]和基于迭代方法的多层Markov网络信息检索模型[9]。
2.1 基于文档团的Markov网络检索模型
采用上述离散数学定理来获得词团和文档团,词团和文档团之间存在较强的语义关联,即存在映射关系。给定一个词团,该词团的词项同时出现在多个文档内,则反映此词团与文档团存在语义关联,定义该词团为依赖词团,否则为非依赖词团。在检索模型中,通过权重比例的分配区分依赖词团和非依赖词团。检索模型的公式如下:
上述公式中α为非文档关联的词团,β为文档关联的词团。通过调整α和β的取值达到提高检索性能的效果。
虽然基于文档团的Markov检索模型[8]得到了广泛的应用,但洪欢[9]等认为该模型存在以下问题,Markov网络模型的构造没有考虑查询子空间的查询团信息,这会导致检索结果不高。因此,他们提出了基于迭代方法的多层Markov网络信息检索模型,加入查询团信息重新对文档检索,提高检索效果。
2.2 基于迭代方法的多层Markov网络信息检索模型
文献[8]得到了最大词团和文档团,同时利用此文献进行初次查询得到检索结果,将检索结果排名的前两项文档合并成一个新的文档,查询子空间的计算方法如下:
式(4) 的值大于给定的阈值,则查询语句qi和qj有边存在,反之,则不存在。查询子空间最大词团的提取方法与词团和文档团的提取方法一致,检索的模型如下:
其中:
具体的迭代过程如下:
1) 利用式(6) 获得初始的检索结果,得到初始的最大查询团信息。
2) 将得到查询团信息代入式(5) 重新对文档检索,得到检索结果,再次获得最大查询团信息。
3) 重复迭代上述的检索过程,直至检索结果收敛。
4) 收敛的条件为检索的结果提高的比例不大,或者不提高。
基于迭代方法的多层Markov 网络检索模型融合了最大查询团、词团和文档团,检索结果得到了有效提高,促进了检索模型的发展。但此模型存以下问题,第一:在度量词的权重时假定词项与词项之间是独立存在,这种度量词的方法没有考虑词项之间的相关性,王[10]等提出了基于词重要性的Markov网络检索模型;第二,选取查询扩展词时只考虑单个查询词,进而选取扩展词项,实际上查询词之间具有相关性且不同的扩展词具有不同的权重,曹等[11]提出了基于PageRank的Markov网络信息检索模型。
3 基于其他方式的Markov网络查询扩展模型
Markov网络查询扩展方式存在其他方式,模型中词项权重的度量方式可以采用文献[12-14]的Ti-idf模型方式度量,考虑词项之间的相关由此得到词项图,进而得到共现矩阵和词项间的概率转移矩阵,将得到的共现矩阵代入马尔科夫链,得到词项的权重;模型中Markov网络的构建是基于独立的文档,查询语句和词项,文献[10]采用奇异值分解提取词之间的潜在语义,进而构建Markov,并对查询进行扩展;查询扩展词的方式不仅考虑词项共现相关性,文献[11]也考虑了候选词与查询词之间的层次距离、词间相关性等因素获取候选词。
3.1 基于词重要性的Markov网络查询扩展模型
传统的Markov 检索模型度量词项权重的方法是基于词项独立性原则,该方法忽略了词项之间的关联性,基于词重要性的Markov 网络查询扩展模型采用Ti-idf的模型度量词项的权重[12-14],查询候选词的获取方式采用文献[9]的方法。Ti-idf的模型度量词项权重的算法如下:
1) 将预处理的数据构建词项图[12]。
2) 根据词项图得到词项的共现矩阵和词项间的概率转移矩阵。
3) 将上述得到的共现矩阵和概率转移矩阵代入马尔科夫链计算得到Ti-idf。
将得到的Ti-idf代入基于迭代方法的多层Markov网络信息检索模型,检索结果有所提高。这也从另一方面证明了词项与词项之间的关联性对度量词项的权重有影响。
3.2 一种基于潜在语义的Markov网络信息检索模型
该方法对原始的词-文档矩阵进行奇异值分解[15],得到一个比原始空间小很多的有效语义空间。构造的公式如下:
其中:
其中:
经过上述转换得到Markov网络模型,查询词与词项之间有边连接,则将其作为候选词,将得到的候选词的权重代入原始的检索公式,实验结果比较理想。此方法在候选词的选取方法上只考虑了词项子空间,没有考虑查询子空间和文档子空间。文献[6-7,15]综合考虑了查询子空间和文档子空间,检索性能得到了较好的提高。
3.3 基于层次依赖的Markov网络信息检索模型
该方法在候选词的选取过程不仅考虑了词项与词项之间的直接相关性[16],也考虑了词项之间的间接相关性,间接相关性包括词间的层次距离、词层权重、词节点的出度和路径选择等因素。该方法的算法如下:
1) 使用词项之间的共现关系构造词项网络结构图,举例如图2所示。
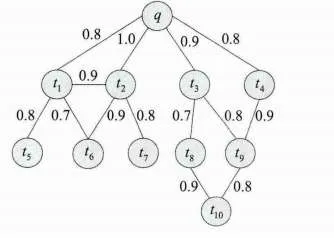
图2 词项网络结构图
2) 以查询词项为中心,逐层向外扩展候选词,综合考虑词间的层次距离、词层权重、词节点的出度和路径选择。
3) 采用信任法计算查询词与候选词之间的相关度。相关度的计算公式如下:
4) 将查询词与候选词的相关度进行排序,得到与查询词相关度的结果。候选词的选择策略基于以下两点:第一,选择与查询词相关度最大的值;第二,候选词与查询词相关度相同,则优先选取查询词与候选词经过中间词节点最少的词。
此方法综合考虑了查询词与候选词之间的多层因素,能有效挖掘有效信息,检索结果有较大幅度的提高。
4 数据集和评价指标
Markov网络检索模型常用的数据集有以下两类:第一类由adi、med、cran、cisi和cacm五个数据集构成,各数据集信息如表1所示。
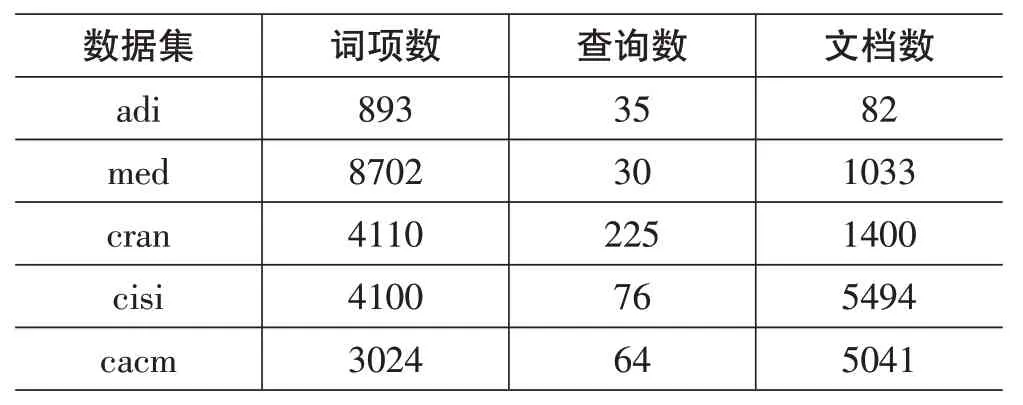
表1 数据集1
这类数据集规模较小,时间开销短。第二类数据集是TREC 的四个数据集,分别是AP(美联社新闻专线故事文章)、DOE(美国能源部技术文章摘要)、WSJ(华尔街日报文章)和ZIFF((ZIFF-Davis 出版公司文章),数据集信息如表2所示,其中查询选用 TREC-ad hoc topics.51-100,这类数据集规模较大,评价效果较好。
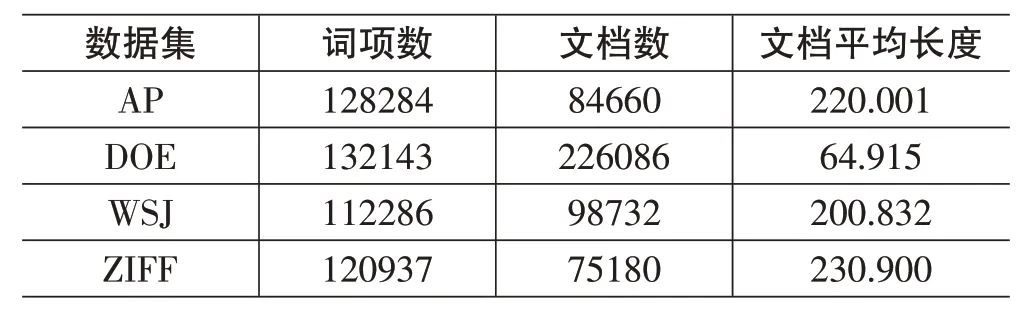
表2 数据集2
Markov 网络查询扩展模型的评价指标有3-avg、11-avg,3-avg 代表在一组查询在三个召回率点(0.2,0.5,0.8) 精确率的平均值,11-avg 代表查询在11 个召回率(0,0.1......1.0) 精确率的平均值,此组检索指标能全面评价检索性能。
5 未来发展趋势
Markov 网络查询扩展模型能提高检索的精确度和召回率,其未来的研究方向包括:
1) 将Markov 网络查询扩展模型的算法融合到搜索引擎,提高检索的精确度和召回率。
2) 随着数据规模的增大,Markov网络的构造方法会越来越烦琐复杂,因此需要寻找优化Markov网络的构造方法;构造Markov 网络时,各子层采用顺序计算模式,随着数据集的增大,考虑采用并行计算的方法,优化计算速度。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
哲学评论(2018年1期)2018-09-14
信息安全研究(2016年4期)2016-12-01
新闻传播(2016年18期)2016-07-19
现代计算机(2016年11期)2016-02-28
河南科技(2014年11期)2014-02-27
图书馆界(2013年5期)2013-03-11
上海理工大学学报(社会科学版)(2011年4期)2011-09-26
