
基于GPU的列车卫星定位接收机捕获引擎设计
2023-09-25 13:11:14黄颂巴晓辉蔡伯根姜维王剑
铁道科学与工程学报 2023年8期
黄颂,巴晓辉, ,蔡伯根 , ,姜维,,王剑,
(1.北京交通大学 电子信息工程学院,北京 100044;2.北京交通大学 智慧高铁系统前沿科学中心,北京 100044;3.北京市轨道交通电磁兼容与卫星导航工程技术研究中心,北京 100044;4.北京交通大学 计算机与信息技术学院,北京 100044)
以我国北斗、美国GPS 为代表的全球卫星导航系统(Global Navigation Satellite System,GNSS)能够为全球范围内的用户提供定位、定速和授时等服务[1]。随着卫星导航系统在公路、民航等交通运输的广泛应用,下一代列控系统提出了应用BDS系统提供位置服务的需求。在铁路建设中,通过卫星导航接收机测量线路、道岔等关键点的位置坐标,生成高精度轨道数字地图辅助车载传感器完成列车的高精度定位[2]。在区间内,使用卫星导航接收机接收卫星信号解算列车的速度和位置,来替代依赖应答器与轨道电路进行定位、占用检查的传统方法,降低了区间内轨旁设备的数量,减轻设备维护的工作量[3]。利用卫星导航系统建立可靠的列车运行控制系统,保障铁路的安全性和可维护性是新型列控系统建设的关键问题。卫星导航接收机作为提供位置服务的终端设备,不同的应用场景对其性能参数有着不同的要求。在用于列车定位过程中,WISS 等[4]结合卫星导航在铁路定位应用领域的需求,归纳形成了GNSS列车定位应用技术开发指导性文件,为卫星导航专用接收机相关技术发展以及实用化奠定了基础。自1997 年起莫斯科COMPASS 设计局与莫斯科铁路管理局研制列车安全设备KLUB-U,利用GPS/GLONASS 导航接收机及车载线路地图实现列车位置的精确检测,至今为止已在俄罗斯铁路上千列机车上安装使用[5]。但随着新体制卫星信号的播发,多模多频信号之间的兼容与互操作性给接收机的设计与发展带来了诸多挑战。常规基于ASIC(Application Specific Integrated Circuits)的硬件接收机因缺乏灵活性及不可编程性,不能对功能结构、计算处理逻辑等进行针对性调整,限制了接收机的性能。为对用于列车定位的接收机进行相应调整与优化,科研人员引入软件接收机的思想,采用可编程的软件化结构完成卫星信号的接收处理功能。软件接收机可对应用于列车的辅助定位算法进行验证以及为虚拟应答器实现以及轨道电子地图的生成提供服务,缩短项目研发周期,降低列车定位系统的成本。BERTRAN 等[6]分析了铁路设备引起的电磁干扰对硬件GPS 接收机性能的影响,验证了低成本的软件接收机用于列车定位方案的必要性。上官伟等[7]设计实现了可用于列车定位的软件接收机,但只能捕获强信噪比的卫星信号。由于铁路沿线存在山体、建筑、遮挡物等复杂环境,此环境下卫星信号微弱(小于30 dBHz),而普通的商用接收机则不能正确地捕获跟踪信号进行定位。为此,可利用软件接收机的灵活性、通用性等特点,根据不同卫星的信号体制、铁路沿线的应用场景设计相应的基带算法,实现开阔场景、遮挡场景下卫星信号的捕获。冷启动情况下,卫星信号的捕获影响列车首次定位的时间,而传统的软件接收机串行实现的GNSS信号捕获算法耗时长。随着GPU 的可编程性的不断提高,对大规模并行数据处理的计算能力已经在云计算、人工智能等领域得到应用,为软件接收机的实时化提供了解决方案[8]。捕获过程可在英伟达(NVIDIA)推出的CUDA(Compute Unified Device Architecture,即统一计算设备架构)上进行编程开发,并行处理中频数据。针对基于GPU 并行捕获国内外学者已进行一些研究,HOBIGER 等[9]首次利用GPU实现了GPS的并行捕获。HUANG等[10]设计了一种基于高性能GPU 的实时软件接收机STARx,可并行捕获跟踪 GPS,Galileo,GLONASS和BDS系统与一些区域系统所有频点的民用信号,满足实时性的要求。XU 等[11]设计了一款基于GPU 的实时软件接收机NAVSDR,在9.75 MHz复采样率、相干积分时间为10 ms下捕获32 颗L1 C/A 信号的速度提升约为CPU 的3.3 倍。杨智博等[12]基于嵌入式Jetson TX2 平台,在62 MHz 采样率下利用GPU 将B3I 信号的捕获速度提高16.83 倍。覃新贤等[13-15]基于CUDA 平台实现了北斗B1I 和B3I 信号的快速捕获。张武迅[16]利用数据和导频双通道相干组合能捕获到-145 dBm 的B1C 信号,进而实现B1I 信号的快速位同步。若B1C和B1I的信号总功率一致时,导频通道的BOC(1,1)分量占B1C 总功率的29/44,只使用导频进行捕获会损失一定的功率;若数据通道和导频通道联合捕获,也往往忽略BOC(6,1)分量,会损失一定的信号功率;此外若没有对子码剥离,捕获B1C 信号只能使用10 ms 相干积分长度。本文在上述基础上,结合基于FFT 的并行码相位捕获算法[17],设计了基于GPU 的强信号与弱信号的并行捕获架构。在铁路开阔场景下,利用短时间的非相干积分对强信号实现多通道的并行捕获;在具有遮挡的条件下,采用全比特法实现微弱信号的捕获。本文着重论述了GPU 架构下并行信号捕获的耗时以及弱信号捕获灵敏度,提出的码多普勒补偿的双模并行捕获方法在强信号场景下提升捕获的速度,在弱信号场景下提高捕获灵敏度的同时有效减少了弱信号的捕获耗时。基于GPU 的强弱信号并行捕获架构场景灵活度高,便于算法验证,可在普通的PC机上运行,设备成本低。
1 基于FFT的信号捕获算法
GPS L1 C/A 和BDS B1I 信号经过射频前端下变频、采样后得到的中频信号分别表示如下:
式中:j 表示卫星的PRN 号;A 表示信号幅度;C表示扩频码;D 表示扩频码上面调制的导航电文;NH表示调制的二级码;fIF是载波中频频率;fd为载波多普勒;φ0是载波初始相位。
卫星信号捕获的实质是将接收信号与本地复现的载波和扩频码作相关运算,得到相关峰值,根据设置的阈值进行门限判决,从而得到卫星PRN号、码相位和载波多普勒估计值。GPS L1C/A与BDS 的B1I信号采用BPSK 调制方式,导航电文每20 ms 可能出现一次比特翻转,但对于MEO 和IGSO 卫星B1I信号上还存在的1 kbps的NH 码,可能会在相干积分时间内出现二级码翻转,导致相干增益的削减。本文采用补零FFT[18]的方法来解决B1I 信号二级码跳变产生的不利影响,算法原理如图1所示。

图1 信号捕获算法示意图Fig.1 Schematic diagram of signal acquisition algorithm
为了消除电文翻转或者二级码跳变产生的影响,每次使用2 ms 的中频数据,这是因为2 ms 至少会包含一个完整周期的扩频码,但最终只保留前1 ms 有效结果。对于强信号捕获只需对最终产生的1 ms 相关值取模进行非相干累积得到捕获检测量。而对于弱信号捕获,本文采用全比特法充分利用一个比特的相干积分时间(20 ms),需要将1 ms相关值进行20 次相干累积,再进行非相干累加得到最终捕获检测量。不同于强信号的是,弱信号捕获不仅需要对不同载波频点、码相位进行搜索,还需要搜索20 次导航电文的比特边沿,并且为了减少因码多普勒频移造成的影响,本地复制的码相位需根据当前搜索的载波多普勒进行调整。
2 基于CPU 与GPU 的强弱信号捕获架构设计
信号捕获过程中的点乘、相干、非相干累加等都存在大量的重复性工作,且每个采样点的计算都是独立的,符合GPU 运算单指令多数据流(Single Instruction Multiple Data,SIMD)的规则。其次,不同的卫星在搜索每个频点的处理流程也是相同的,即不同卫星、不同搜索频点之间的相关运算是相对独立的运算过程,故可以采用并行计算方式来处理。英伟达公司开发的CUDA 并行计算架构采用了单指令多线程执行模型,可以设计合适的并行结构加速采样点的计算。
本文设计的捕获模块采用了CPU 与GPU 异构并行计算的结构,强弱信号并行捕获架构如图2所示。捕获模块包括本地载波产生、本地扩频码生成、各个多普勒频点的码相位搜索、相干与非相干累加、峰值检测及门限判决等子模块。其中,载波剥离、FFT 运算、向量相乘、IFFT 运算、向量累加取模等存在大量数据运算的操作,可以将其交与GPU 端并行化处理,提升捕获的速度;而CPU 端则读取中频数据等复杂的逻辑运算,完成门限判决与存储捕获结果。
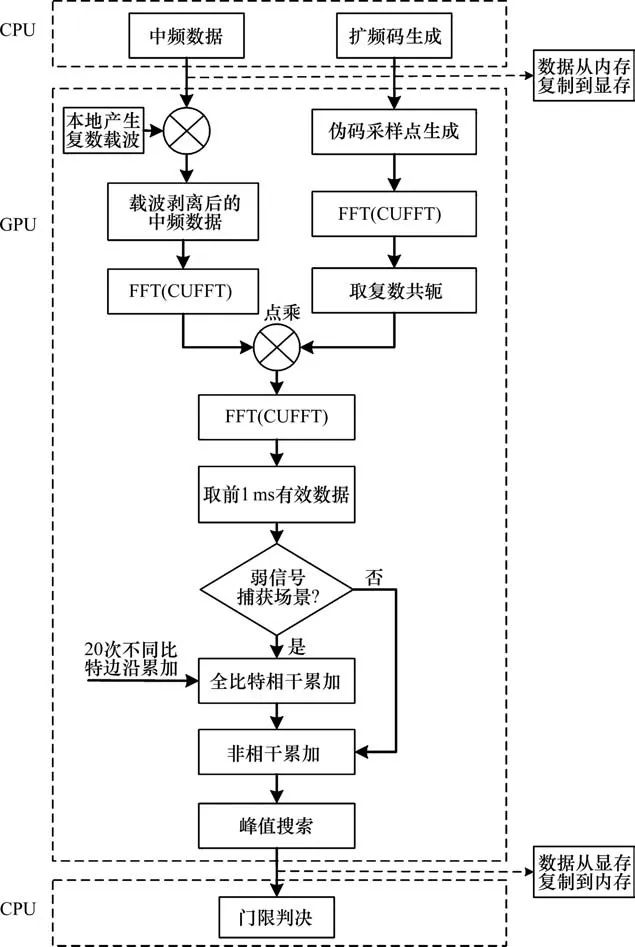
图2 信号并行捕获架构Fig.2 Signal parallel acquisition architecture
从CPU 端读取中频信号采样点并且生成多颗卫星的扩频码,并将中频信号、扩频码采样点由CPU 内存拷贝到GPU 显存中进行并行运算,最终得到多个1 ms 有效数据。对于强信号捕获进行多次非相干积分即可,而微弱信号捕获利用了20 ms相干积分时间,为防止相干增益被抵消需要并行搜索导航电文的比特边沿。得到每个码相位(采样点)的累加值后,最终在GPU 端搜索码相位的最大峰值,将其拷贝至CPU 中进行门限判决得到捕获结果。综上,强弱信号捕获需具体设计相应的核函数完成各自计算任务的并行处理。
3 并行计算模型设计
3.1 载波相位并行线程模型
CUDA 是由NVIDIA 推出的专门用于GPU 编程开发的平台,其编程模型如图3 所示。CPU 与GPU 通过PCIe 总线相连接来协同工作,CPU 所在位置称为为主机端(host),其包含的存储空间称为主机内存;而GPU 所在位置称为设备端(device),包含的存储空间称为设备内存。CUDA 的线程组织结构[19]如图3 所示,自上到下可以分为Grid,Block和Thread 3级,多个线程(Thread)组成一个线程块(Block),多个线程块构成一个网格(Grid),一个网格对应着一个核函数(运行在GPU 上的并行计算函数)。在CUDA 中每一个线程都要执行核函数,所以每个线程会分配一个唯一的线程号,并且每一级都有其相应的编号,从而利用编号使线程执行并行计算的任务。

图3 CUDA线程组织架构Fig.3 CUDA thread organization architecture
在进行载波剥离的过程中,本地载波相位的计算是通过数控振荡器的形式来实现,每次步进的长度是由载波多普勒频移计算得到,若在CPU以串行的方式计算中频信号采样点数值时,每个点的载波相位和码相位是通过上一个采样点与步进值累加得到。本文利用GPU 对每个采样点并行生成,无法依据上一个采样点进行推导,可以根据线程编号来索引每一个采样点。因此本地载波生成的并行计算模型可设计为一维Block 和二维Grid 的结构,由此可以得到每个采样点的载波相位为:
其中:threadIdx.x 为每个Block 内线程的列编号,blockIdx.x 为Grid 中Block 的列编号,生成不同频点的载波可用blockIdx.y来索引。
3.2 码相位并行线程模型
本地码相位的生成方式与载波相位相同,也是通过数控振荡器的形式来实现,但卫星和接收机之间的相对运动会产生码多普勒效应,卫星信号的扩频码频率会发生偏移,随着时间的推移,接收信号与本地信号的码相位将会发生相对滑动即码相位误差将逐渐变大,可能造成相干积分的峰值下降与移位。考虑码多普勒的码相位步进长度可由式(5)表示:
其中:frf代表卫星射频频率;fcode为扩频码速率;fs为采样率。捕获强信号时,使用的中频数据短,基本可以忽略接收信号与本地信号的码相位滑动,只需生成1 ms 长度的伪码然后补1 ms 长度的0 作为本地码。本地伪码以并行多路的形式在GPU 生成,采用二维的Block 和一维的Thread 结构,其中Block 的X 维线程索引本地码相位采样点,Y 维线程索引不同卫星本地码的产生。
在进行弱信号的捕获时,需要进行长时间的信号累积来提高灵敏度,并且载波多普勒较大时势必造成相干积分的损失,因此需考虑码多普勒的影响。若本地码相位采样点将根据上式计算,则需要连续生成与中频信号相同长度的伪码采样点进行FFT 运算,这将占用大量的显存资源,且进行大点数的FFT 会导致弱信号捕获时间大大增加。为了减少FFT 耗时、节省显存资源,本文提出一种间隔性补偿码多普勒的全比特法:假设t1为接收的中频数据的某个采样时刻,在生成本地伪码时,t1至t1+N(N为20 ms整数倍)时段内Nms的伪码采样点可用从t1+N/2 时刻生成的1 ms 长度的伪码采样点替代,这样2Nms长度的FFT运算量减少到2 ms(补零后的长度),考虑到码多普勒对码相位滑动的影响,需要对从t1+N/2 时刻生成的1 ms 伪码进行码多普勒补偿,由此可以得到经过码多普勒补偿后t1+N/2时刻开始生成的码相位为:
3.3 比特边沿搜索并行线程模型
本地伪码采样点生成后,将其FFT 结果取共轭与中频信号的FFT 结果进行频域相乘,在点乘时采用多采样点并行计算可显著降低相关运算的时间;对相乘的结果调用cuFFT 库进行IFFT 运算,得到多个IFFT 的前1 ms 有效结果后,捕获弱信号需要搜索比特边沿搜索即20 次并行相干累加,设计的并行线程模型如图4所示。

图4 三维并行架构Fig.4 3D parallel architecture
考虑到20 次相干积分中采样点的相加运算、载波频率的搜索以及比特边沿的搜索,并行计算模型可设计为一维的Block 和三维的Grid 的结构。比特边沿的搜索通过blockIdx.z 索引,不同载波频点的计算则使用blockIdx.y 来索引,同时在Block内每个线程索引1 ms 相干积分的每个采样点。此外,进行相干累加的过程中,BDS 与GPS 不同的是还需要剥离二级码,即BDS 每1 ms 的采样点都需要与NH 码相乘才能进行相干累加。经过相干积分、非相干积分后的结果需要在GPU 端进行峰值检测,可利用CUDA的cuBLAS库实现数据的并行处理,得到峰值所在的位置,最后将结果从显存拷贝到内存中进行门限判决。受限于设备内存的大小,弱信号捕获需要处理较长的中频数据和搜索大量的载波频点,不可能一次性在GPU 中进行所有载波频点的并行搜索,而强信号捕获则可以一次进行所有频点的并行搜索。
3.4 内存分配与程序优化设计
在Nvidia GPU 内部为不同的数据结构和内存读取方式定义了一些特殊的内存,如寄存器、共享内存、纹理内存、全局内存、锁页内存等,每种不同类型的内存空间都有不同的作用域、生命周期和缓存行为,合理利用内存能够提升程序的并行效率。纹理存储器(texture memory)是一种只读存储器,对数据的读(写)操作通过专门的texture cache(纹理缓存)进行,速度优于全局内存。由于GPS 与BDS 的伪随机序列是固定不变的,伪随机序列存放在设备端的纹理内存之中能够减少伪码在GPU与CPU之间传输所消耗的时间。
页锁定内存是在主机内存中开辟一块供GPU交换数据而不与磁盘进行数据交换的空间,具有更高的内存读取速度,其传输效率高于被交换的可分页内存。在处理中频数据之前,需要将中频数据采样点从CPU 的内存空间提前传输到GPU 显存中,当弱信号捕获需要较长的中频数据或者采样频率较高时,采样点内存的读取将花费大量的时间,因此可以使用页锁定内存存放采样点数据。
对于中频信号进行载波剥离时,载波生成模块载波生成模块有2种常用方式,一种是在核函数中调用sincosf 进行单精度浮点三角函数计算;第二种是使用查询表的方式得到,将提前计算好的正余弦函数表存放在纹理内存中,每次调用时根据相位读取相应数值,这是一种空间换时间的方式,由于GPU 具有强大的浮点计算能力,上述2种方式所花时间相差不大。
在上一节的并行计算模型之中,无论是码相位和载波相位的计算,还是点乘、相干与非相干累加,都可以采用一个线程计算多个采样点的策略提高程序的运行速度。而CUDA 核函数运算之前需要访问显存读取数据,当满足合并访问时,能够实现显存带宽的最大化利用,提高内核函数的执行性能。综上,设计核函数时让相邻的线程计算相邻的点,这样既实现了合并访问又保证了单个线程计算多采样点。
4 实验验证及数据分析
4.1 实验数据及设备
本文实验的硬件环境如下。
CPU:Intel Core i7-9750H;
GPU:NVIDIA GeForce GTX 1650,计算能力7.5,显存8 G。
在硬件层面,GPU 是以线程束的形式在多处理器(Streaming Multiprocessor,SM)来运行实现并行计算,在每个SM 中线程束的占用率越高则说明当前程序的并行性越高。共享内存与寄存器的占用也是影响程序效率的重要因素,并且GPU 中的硬件资源是有限的,随着线程数量的变化,每个线程可以使用的硬件资源也不同,这是影响线程束占用率的主要因素。实验所使用的GPU 硬件资源如表1所示。

表1 GPU硬件资源Table 1 GPU hardware resource
本文使用模拟器和2018 年7 月京沈客运专线黑山北站—沈阳西站区间实测轨迹数据仿真生成了不同信噪比的中频测试数据,以此模拟铁路的强弱信号场景来进行捕获。在采样率为16.368 MHz下生成的GPS 和BDS 中频数据频谱图如图5 和图6所示。由于捕获卫星信号时使用的数据在该时段内列车的速度与卫星的速度变化微小,可认为载波多普勒保持不变。结合以上实验数据,本文将从捕获速度、正确性和捕获灵敏度分析信号并行捕获的性能。

图5 GPS中频信号频谱图Fig.5 Spectrogram of GPS IF signal

图6 BDS中频信号频谱图Fig.6 Spectrogram of BDS IF signal
4.2 捕获速度分析
实时性能是衡量软件接收机的数据计算能力的关键因素,对于软件接收机来说,捕获作为计算最大的模块,其消耗的时间会影响到冷启动或卫星信号失锁时重捕的首次定位时间,从而影响到系统接收的实时性,本小节对强弱信号环境下的捕获速度进行分析。
设置GPS 和BDS 强信号捕获的相干积分时间为1 ms,捕获GPS L1C/A 与BDS B1I 采用补零FFT 算法,对于1 ms 的相干积分需要进行2 ms 长度的数据运算。根据第2节可知,捕获模块主要由本地载波生成及剥离,本地码生成,FFT/IFFT 和非相干积分等部分组成,当采样率相同时上述模块中参与运算的采样点的数量是相同的,因此2种信号捕获各模块的运算量基本相同,即耗时相同。
表2 给出了62 MHz 采样率下,单通道以及1 ms 相干积分时间内分别搜索1 个与21 个载波多普勒的耗时。表3 列出了不同文献的GPU 捕获耗时情况,与文献[16]相比,非相干次数为1 时,搜索一颗卫星本文消耗的时间是其50%左右;与文献[10]相比,本文捕获所消耗的时间是其75%左右,由于同等架构下Cuda 核心的数量会与运算速度成正比,因此与本文的加速效果相差不大。

表2 GPS/BDS强信号GPU捕获耗时Table 2 Strong signal acquisition time of GPS/BDS

表3 捕获耗时对比Table 3 Comparison of acquisition time
设置相干积分时间1 ms,非相干次数20 次,图7给出了3种采样率下不同通道数GPU 捕获的总耗时。采样率为16.368 MHz 时,搜索一颗卫星且同时搜索21个频点,需要24 ms左右;降低采样率为5 MHz 时,同时搜索10 颗卫星且每颗卫星同时搜索21个频点需要27 ms左右。
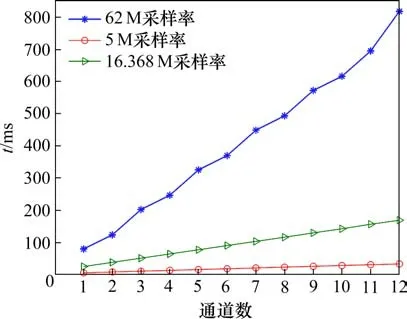
图7 多通道捕获总耗时Fig.7 Total time for multi-channel acquisition
对于弱信号捕获可以通过3.2 所述的间隔性补偿码多普勒的全比特法来减少耗时。若处理100 ms的中频数据本地将生成200 ms(补零)长度的伪码采样点作FFT 运算,这会使捕获的耗时显著增加,因此本文用第10 ms开始的1 ms采样点、第30 ms 开始的1 ms 采样点、第50 ms 开始的1 ms 采样点、第70 ms 开始的1 ms 采样点、90 ms 开始的1 ms 采样点来替代0 至20 ms,20 ms 至40 ms,40至60 ms,60 m 至80 ms,80 m 至100 ms 的20 ms伪码采样点,因此每个载波频点200 ms 长度的伪码FFT 运算量降低到了10 ms。表4 给出了采用间隔性补偿码多普勒和连续补偿码多普勒的全比特法(对每一毫秒的伪码都进行码多普勒补偿)时,2种采样率下GPS 与BDS 弱信号捕获的运行耗时,并且同样采样率下捕获2种弱信号参与运算采样点的数量是相同的,因此捕获各模块的运算量相同。

表4 GPS/BDS弱信号GPU捕获耗时Table 4 Weak signal acquisition time of GPS/BDS
当采样率为5 MHz 时,采用间隔性补偿码多普勒的全比特法搜索单颗GPS/BDS 所消耗的时间相比于连续补偿码多普勒的全比特法减少了111.64 ms;在16.368 MHz 搜索单颗GPS/BDS 消耗的时间减少了778.05 ms。因为采用间隔性补偿码多普勒的方法从产生本地伪码、补零、本地伪码FFT 三方面显著减少了捕获耗时,且采样率越高、使用的数据越长,减少耗时越明显。此外,由于中频数据过长、搜索的频点数目过多和比特边沿的搜索,无疑将占用大量的显存资源,使得GPU的并行资源达到最大限制,因此捕获模块就变成串并混合的形式。
4.3 不同信噪比的正确捕获能力
为验证不同信噪比下2种并行捕获架构的正确捕获能力,仿真产生了不同载噪比的GPS/BDS 中频信号测试数据。强星捕获的测试数据参数设置为:采样率16.368 MHz,中频4.092 MHz。对20 ms长度的中频数据进行20次非相干积分的基础上启动多颗星、多频点的并行捕获,表5 列出了GPS和BDS不同载噪比下的捕获结果。
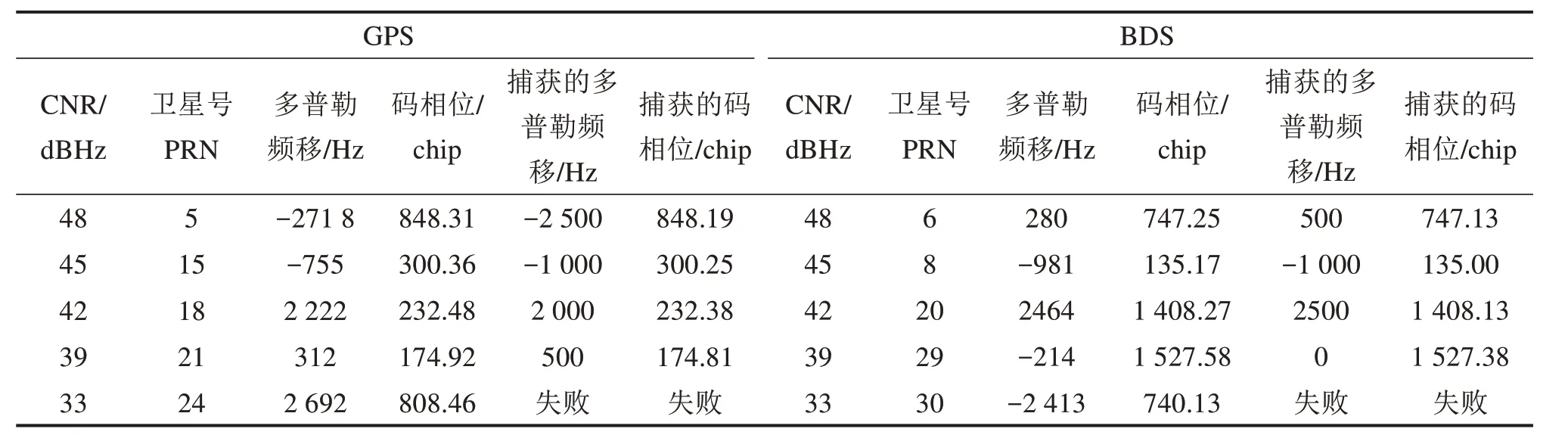
表5 GPS/BDS强信号捕获结果Table 5 Acquisition results of GPS/BDS strong singal
运行GPU 程序将捕获的码相位、多普勒频移与中频数据的原始多普勒频移、码相位对比,以此来验证捕获的正确性。由表4~5 可知,进行多次独立的捕获实验,对不同的卫星设置不同且较高的载噪比,GPS 与BDS 检测到的码相位和多普勒频移与原始值均在误差范围内,证明了强信号并行捕获的正确性。当信号强度减弱到33 dBHz时,仅仅是非相干积分已经不能完成弱信号的捕获,必须延长相干积分时间来提高信噪比。
为了验证本文算法对GPS/BDS 弱信号的捕获性能,实验仿真对比了间隔性补偿码多普勒与连续补偿码多普勒的全比特法在大多普勒频偏、低载噪比下的信号检测概率。弱信号捕获的测试数据参数设置与表3相同,GPS和BDS设置采样率为5 MHz;中频频率1.25 MHz;码片初始值延迟666个码片,载波多普勒频移为4 500 Hz。图8 和图9分别表示GPS和BDS在不同载噪比下运行1 000次蒙特卡洛仿真的检测概率比较结果。仿真结果表明采用间隔补偿码多普勒在捕获灵敏度上与连续补偿码多普勒的捕获灵敏度相差甚微,在载噪比为25 dBHz下的GPS捕获概率能达到90%,BDS的捕获概率能达到80%,证明了本文算法的有效性,提高了基于GPU的弱信号捕获的速度。

图8 GPS算法性能对比Fig.8 Algorithms performance comparison of GPS

图9 BDS算法性能对比Fig.9 Algorithms performance comparison of BDS
根据以上总结与对比,结合信号捕获在不同线路及运行场景中的实际需求,基于GPU 的强信号捕获显著提升了捕获速度,可用于开阔环境、卫星观测条件较好的线路区域,而基于GPU 的微弱信号方案适用于沿线部分区域信号观测条件多变、卫星信号存在遮挡弱信号的铁路线路。
5 结论
1) 针对开阔、存在遮挡的铁路场景,将京沈高铁的实测轨迹数据作为依据,模拟了生成不同载噪比的场景文件(中频数据),利用设计的双模捕获引擎实现了GPS/BDS强弱信号捕获。
2) 针对传统信号捕获耗时较长的问题,引入软件无线电的思想,设计了基于GPU 与CPU 异构并行计算架构的卫星信号捕获方法,详细分析了信号捕获过程的并行计算模型、GPU 内存结构以及捕获耗时。针对弱信号捕获提出一种间断性补偿码多普勒的全比特法来提升捕获速度,同时保证了弱信号的捕获灵敏度。
3) 由于铁路线网规模庞大,沿线环境复杂,还存在无卫星信号场景的情况,后续工作将进一步研究伪卫星信号的捕获方法以及新型信号体制(BOC调制)的卫星信号捕获算法,设计面向铁路应用的卫星/伪卫星多系统软件接收机,在开阔、存在遮挡以及完全遮挡的情况下能够给列车提供位置服务,配合车载传感器实现列车的无缝定位。
猜你喜欢
广东通信技术(2023年9期)2023-10-29 07:09:32
测控技术(2018年6期)2018-11-25 09:50:18
电子制作(2018年19期)2018-11-14 02:36:40
环球市场(2017年36期)2017-03-09 15:48:21
电子制作(2016年1期)2016-11-07 08:42:41
系统工程与电子技术(2016年4期)2016-08-24 07:46:04
电信工程技术与标准化(2015年10期)2015-12-22 09:08:10
电信工程技术与标准化(2013年4期)2013-08-09 08:22:28
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
电信工程技术与标准化(2010年10期)2010-03-22 00:52:12
