
改进Yolov5的无人机目标检测算法
2023-09-25 08:59陈范凯李士心
计算机工程与应用 2023年18期
陈范凯,李士心
天津职业技术师范大学电子工程学院,天津300222
随着卷积神经网络(CNN)目标检测算法不断发展,检测性能逐渐提升,使得深度学习算法更适用于机器视觉的应用[1]。根据输入图像的处理方式,常使用两阶段检测和单阶段检测两种物体检测方法,在不同应用场景下均表现出良好准确率和识别速度。其中,R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]、R-FCN[5]等都是两阶段检测方法。DenseBox[6]、RetinaNet[7]、SSD 系列[8]、YOLO系列[9-12]等都是单阶段检测方法。
在无人机飞行过程中,搭载设备需实时传输航拍图像,这对目标检测提出更高要求。此外,图像以小目标为主,具有模糊、密集排列和稀疏分布等特点,而且常常淹没在复杂的环境背景中。综合上述问题,使得传统检测方法很难准确定位无人机航拍图像上的目标,搭建高性能的目标检测模型成为当下研究的热点。近年来,YOLO系列检测方法由于其优越的速度和良好的精度,广泛应用于无人机航拍图像的目标检测。程江川等人[13]采用轻量化高效骨干网络对模型进行改进,提高模型检测速度。李利霞等人[14]设计了一种多级特征融合模块,动态调节各输出检测层的权重,提高模型的适应性。李杨等人[15]在YoloX的基础上,通过Neck多尺度特征融合提高浅层目标的感受野,加大对小目标的识别能力。甄然等人[16]利用深度可分离卷积替换传统卷积,使Yolov5模型轻量化,同时增加注意力机制,提升模型的小目标识别能力。薛珊等人[17]提出了一种动态实时检测网络模型Yolo-Ads,增强了网络对无人机尺度变化的鲁棒性。谢椿辉等人[18]通过增加小目标预测层和优化损失函数来提高模型的检测效果。上述无人机目标检测模型主要采用高效轻量化结构来降低模型参数量和计算复杂度,提高算法检测速度,提升模型识别能力。由于轻量化网络结构使得网络感知深度变浅,图像特征融合和提取能力无法更好发挥,使得无人机航拍图像检测精度不高。针对上述问题,改进后模型需在保证无人机检测速度要求的前提下,致力于提高模型的检测精度和准确率。论文以Yolov5s 模型为基础,首先采用梯度流丰富的C2F模块替换C3模块加强图像特征提取和特征融合能力;其次通过轻量化上采样算子CARAFE 对FPN 网络进行优化,扩展模型的感受野;最后采用动态标签分配策略OTA(optimal transport assignment for object detection),从全局信息角度实现标签最优分配,提高了网络对候选框的处理效果,使得模型训练更加稳定高效,以满足无人机实时检测要求。
1 Yolov5模型
Yolov5 是Yolo 系列第五代,是一款高性能目标检测模型[19],Yolov5 模型架构包含了Input、Backbone、Neck、Head四个部分。
Input部分:目标检测模型输入端,该部分包含一个图像预处理阶段,将输入图像进行自适应缩放来匹配网络的输入大小,并进行归一化操作,同时Yolov5 利用Mosaic图像增强提升模型适应性。
Backbone 部分:Backbone 网络是模型的主干网络,通常采用一些性能优异的分类器作为网络架构用来对目标图像进行特征提取。Yolov5 采用改进后的CSPDarknet53结构,由Conv模块、C3模块以及SPPF模块构成。
Neck部分:Neck部分是网络衔接部分,主要用来获取传递特征信息并进行融合。Yolov5使用FPN-PAN结构,FPN 结构是自顶向下结构,通过上采样和融合底层特征信息的方式得到预测特征图,PAN采用自底向上结构对FPN 特征图进行融合补充的特征金字塔网络结构。Yolov5 在Yolov4 的Neck 网络基础上进行改进,通过借鉴CSPNet设计的C3模块替换普通卷积操作,进一步加强网络特征融合能力。
Head 部分:Yolov3 以后的系列采用三个检测层对目标进行检测识别,分别对应Neck 部分中得到的三种不同尺寸特征图。特征图上每个网格都预设了三个不同宽高比的锚框(anchor),可以在特征图通道维度上保存所有基于anchor的位置信息和分类信息,用来预测和回归目标。
2 Yolov5模型改进
2.1 引入上采样算子CARAFE
现有卷积网络体系结构中,特征上采样是一个关键算子[20]。传统算法中上采样以最近邻插值法为主,仅仅通过像素点位置来决定上采样核,并没有利用特征图的语义信息,而且感知域很小。所以本文采用感受野较大的轻量级通用上采样算子CARAFE,可以很好利用特征图的语义信息,同时没有引入过多参数量和计算量。对于内容信息,CARAFE可以实现在不同位置使用自适应和优化重组内核,实现比主流上采样运算符(如插值或去卷积)更好的性能。利用CARAFE 代替所有特征层中最近邻插值上采样,加强了低分辨率特征图经过CARAFE上采样与高分辨率特征图的融合,提升了特征金字塔网络性能。CARAFE流程图如图1所示。
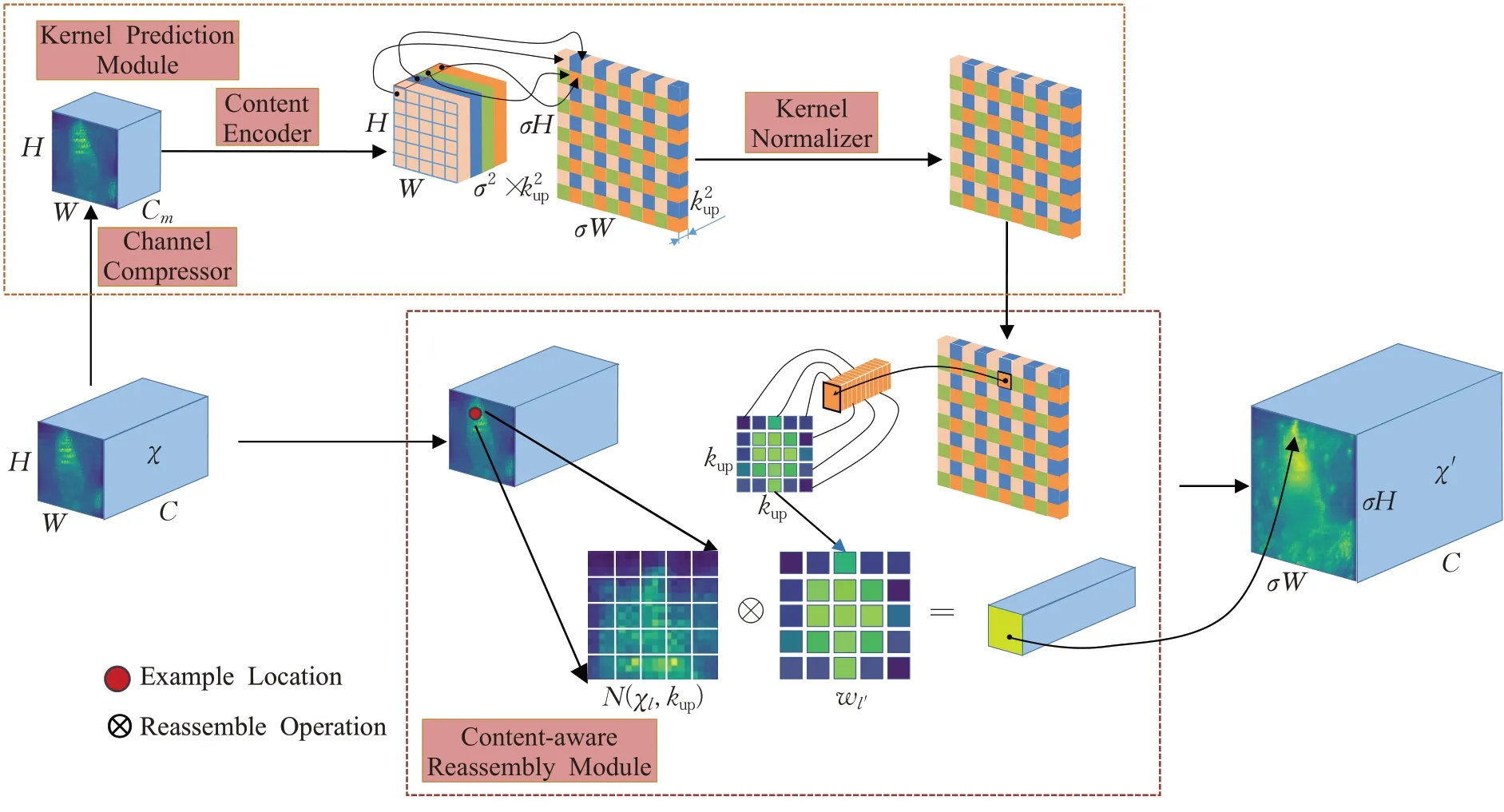
图1 CARAFE流程图Fig.1 CARAFE flow chart
CARAFE分为两个主要模块,分别是上采样核预测模块和特征重组模块。假设上采样倍率为σ,给定一个形状为H×W×C的输入特征图,CARAFE首先利用上采样核预测模块预测上采样核,然后利用特征重组模块完成上采样,得到形状为σH×σW×C的输出特征图。在上采样预测模块中,为了减少后续计算量,首先对于输入形状为H×W×C的特征图经过1×1卷积进行通道数压缩,压缩为H×W×Cm再进行内容编码和上采样核预测,利用Kencoder×Kencoder卷积层来预测上采样核,输入通道数为Cm,输出为,然后将通道在空间维度展开,得到形状为的上采样核,将上采样核进行归一化操作,使其卷积核权重和为1。在特征重组模块中,对于输出特征图中每个位置,将其映射回输入特征图,取以之为中心的Kup×Kup的区域,和预测该点上采样核作点积,得到输出值。相同位置不同通道共享同一个上采样核,最后得到输出为σH×σW×C的输出特征图。
利用CARAFE 上采样替换特征金字塔网络中最近邻上采样改进后的模型,在召回率、准确率和检测精度方面均有提升,增强了特征金字塔网络对图像特征提取和融合的能力。
2.2 利用C2F模块替换C3模块
Yolov5 模型中C3 模块主要借助CSPNet 提取分流结合残差结构的思想,通过n值控制CSPNet 中主分支梯度模块BottleNeck,达到丰富模型语义效果,C3 模块结构如图2 所示。C2F 模块首先经过ConvBnNSiLU 将模块前特征信息进行卷积提取,再通过Spilt模块进行分流,分割后信息进入n个BottleNeck模块分别进行梯度流提取,将信息汇入Concat 模块进行合并,最后经过卷积进行特征融合,C2F模块结构如图3所示。相比较C3模块,C2F 模块主要是通过更多分支层连接,从而丰富模型梯度流,对小目标和密集目标具有更好的识别效果。利用C2F 模块替换所有C3 模块改进后的模型,在增加少量参数量的情况下,较大地提升了模型的识别能力。改进后的模型结构图如图4所示。

图2 C3模块结构图Fig.2 C3 module structure diagram

图3 C2F模块结构图Fig.3 C2F module structure diagram
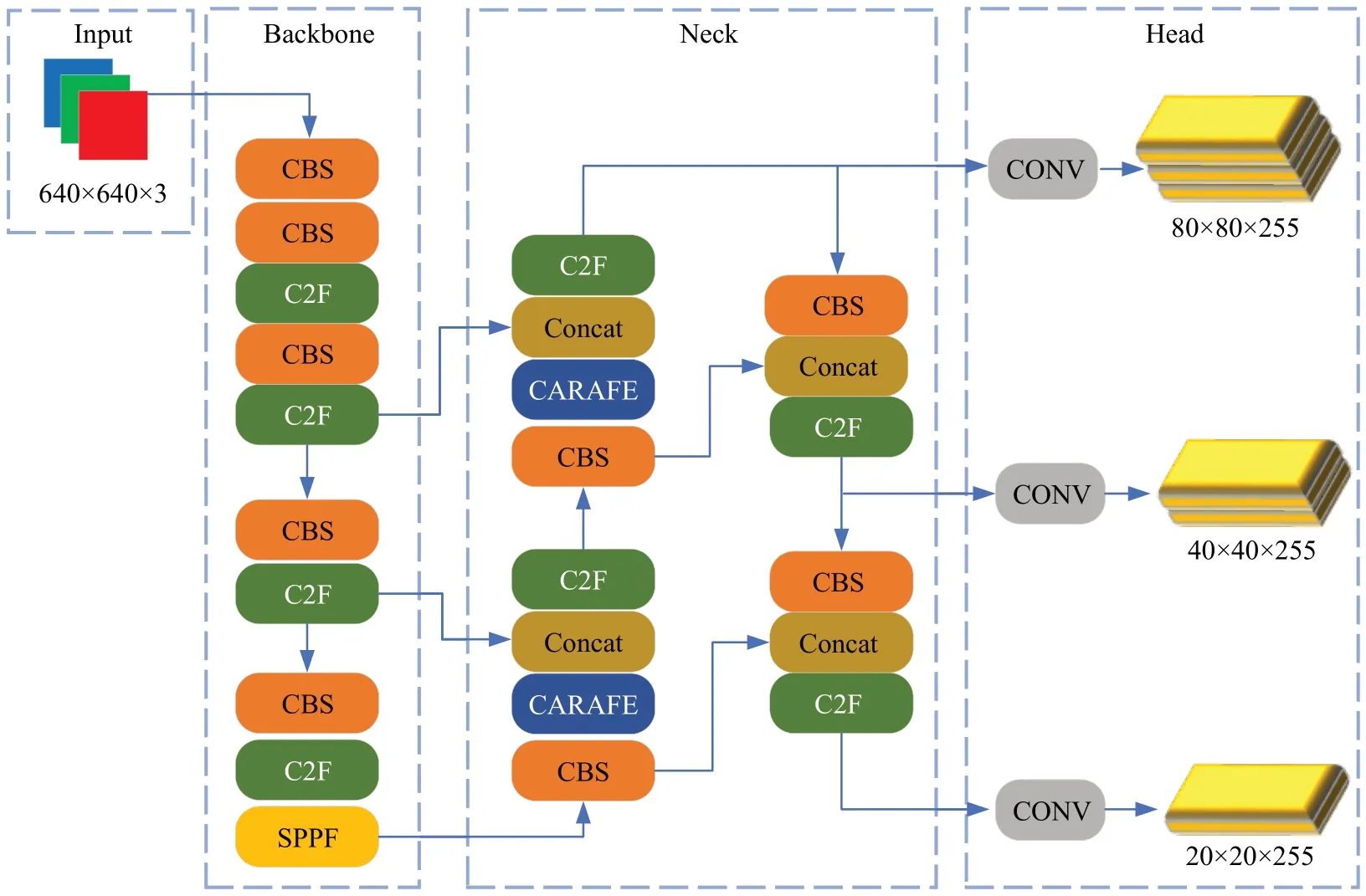
图4 改进后Yolov5模型结构图Fig.4 Improved Yolov5 model structure diagram
2.3 动态标签分配策略
在目标检测中,标签分类主要是为目标框寻求独立的正负样本标签[21]。Yolov5 模型在标签分配上采用真实框和预选框之间的宽高比,这类标签分配机制无法考虑尺寸、形状或者边界遮挡带来的差异性,同时没有进行全局性考虑。在处理不明确锚框时,往往需要局部之外的更多信息,而传统标签分配策略就是独立为每个真实框找寻最优标签,没有利用全局最优思想,容易造成模糊锚框在标签分配时对训练网络进行错误干扰,影响目标检测效率。所以引入了一种基于全局考虑的动态标签分配策略OTA,将标签分配过程公式化为最优运输问题,免去传统手工设定参数的方式来实现标签分配,让检测网络自主选择每个目标框对应候选框的数量,解决了模糊锚框的分配问题,提高了网络对候选框的处理效果。OTA流程图如图5所示。
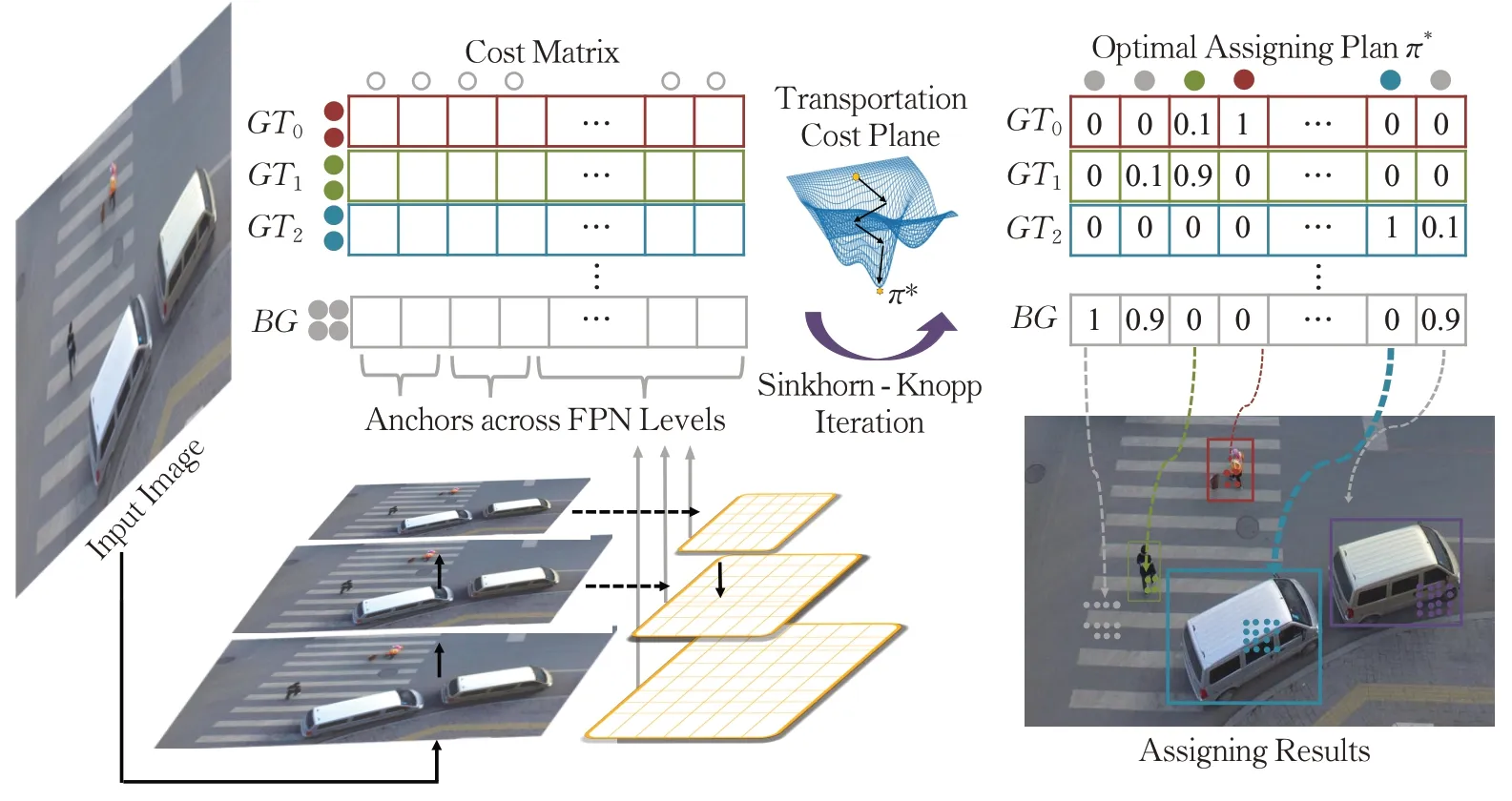
图5 OTA流程图Fig.5 OTA flow chart
被测图片进入目标识别模型,对FPN层上所有锚框进行成本计算,生成正负样本的成本矩阵C(cost matrix),其中GT表示正样本目标框和anchors对应生成的成本大小,BG表示负样本即背景类和anchors 的成本。正样本成本价值表示从真实框传输一个正标签到预选框的运输成本记为,将其定义为真实框和预选框之间的分类损失和回归损失的加权和,如公式(1)。
其中,θ是模型参数,分别表示候选框aj预测分类得分和预测目标得分,和表示真实框相关预测分数。Lcls和Lreg分别表示交叉熵损失和IoU损失,α表示权重系数。
其中,∅表示背景类。将Cbg∈R1×n和Cgt∈Rm×n进行合并组成完整的成本矩阵C∈R(m+1×n),同时将每个目标框对应的标签数S进行适应性变化,如公式(3)所示:
将生成的成本矩阵C和供应量S以及需求量d通过Sinkhorn-Knopp Iteration 算法来获得标签分配方案π*,得到π*后,对应标签分配就是将每个anchor传输给这个anchor最多标签的真实框。
为了进一步优化标签分配策略,针对每个真实框,只挑选每个FPN 层中距离边界框中心最近的r2锚框,对于其他锚框,对应的成本会加上额外常数项,减少训练阶段其被分配为正样本的概率。同时根据预测框和对应真实框的IoU 值动态估计每个真实框合适的正样本数量,降低计算量,加强标签分配策略泛化能力,提高目标识别模型的准确率。
3 实验与分析
3.1 数据集
采用由天津大学团队开源的数据集VisDrone2019,该数据集是一个大型无人机视角下的数据集,数据集亮度、色彩、气候环境等因素丰富,涵盖生活中常见10 种目标,且检测目标小而密集,非常符合本次实验要求。从数据集中分别随机抽取了1 550张,464图片组成本次实验的训练集和验证集。
3.2 实验配置
所有实验均在相同的硬件环境中进行,相关环境配置如表1所示。

表1 实验配置表Table 1 Experimental configuration table
3.3 评价指标
本实验选取了目标检测领域重要评价指标对模型进行性能检测,分别是准确率P(Precision)、召回率R(Recall)、精度AP(average precision)和平均精度mAP(mean average precision)[22],对应计算公式如式(4)~(7)所示:
上述式中,n表示标签种类,TP表示正确识别正样本个数,FP表示错误识别正样本的负样本个数,FN表示错误识别负样本的正样本个数。
3.4 模块对比实验分析
为了验证改进模型算法的可行性和有效性,针对改进模块进行横向对比实验,在保持原有模型基础上,对相同位置不同改进点进行对比实验。实验均在Yolov5-7.0版本基础上进行改进,迭代次数为300次。
3.4.1 CARAFE上采样对比分析
利用轻量级上采样算子CARAFE 替换传统模型中最近邻插值法(Nearest),同时对比上采样插值法,选取双立方插值法(Bicubic)、转置卷积法(ConvTranspose2d)进行对比实验。由表2可知,利用CARAFE上采样改进后的模型准确率达到了49%,召回率达到了42.9%,mAP值达到了42.6%,相较其他上采样算法,性能更佳。
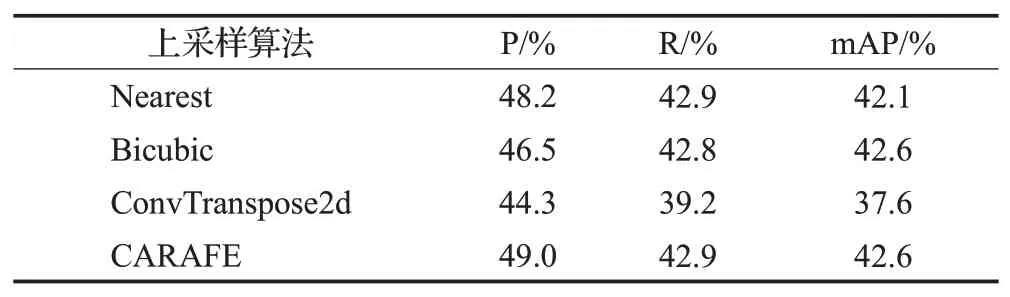
表2 不同上采样算法检测性能对比表Table 2 Different upsampling algorithms detection performance comparison table
3.4.2 C2F模块对比分析
为了验证含有残差结构C2F模块的有效性,针对模型中残差模块进行对比实验分析。Yolov5模型4.0版本以后残差模块采用C3模块。C3_Faster模块是在FasterNet[23]轻量化模型基础上提出的,致力于保证准确率的同时减少模型参数。CSPstage 模块引用DAMO-YOLO 的RepGFPN多尺度特征融合思想[24],通过加强特征融合能力来提高目标检测精度。VoVGSCSP 模块[25]是由高效轻量化卷积GSConv组成的,用于提高模型检测速度和精度。C2F模块采用多层次梯度提取的思想,加深了特征提取的网络层次,加大了模型参数量的同时提升模型检测精度。对比实验选取的5 种残差模块在目标特征提取和特征融合方面均表现出优异效果。由表3可知,相比较其他模块而言,C2F 模块参数量有所增加,但mAP 提升较明显。相较于C3_Faster 模块的mAP@0.5提高了10.7 个百分点,较CSPstage 模块提高了2.1 个百分点,达到46.6%,同时mAP@0.5-0.95 达到24.1%。对比实验结果进一步验证了C2F模块的有效性。

表3 不同残差结构模块实验数据对比表Table 3 Different residual structure module experimental data comparison table
3.5 消融实验结果分析
为了验证改进模型算法的高效性,对算法所提及的改进点在数据集上进行消融实验。由表4可知,Yolov5算法模型在数据集上平均精度为40.6%,用C2F模块替换C3 模块后的Yolov5s_1 模型在平均精度方面提高了5.7 个百分点,表明选用C2F 模块在目标检测模型性能上有所提升。Yolov5s_2是在传统模型基础上通过采用CARAFE上采样算子设计的目标模型,其平均精度提升了0.7 个百分点。利用动态标签分配策略改进的模型Yolov5s_3,性能有了较大提升,mAP@0.5达到了60.4%。Yolov5s_4 模型、Yolov5s_5 模型和Yolov5s_6 模型都为改进点两两融合的模型,从实验结果可知,两两融合后的模型较之前模型均有提升,并且表现出性能叠加效果。Yolov5s_UAV是所有改进点融合的检测模型,在检测速度方面,改进后的模型虽然FPS 有所下降,但仍能达到103 FPS,满足无人机对于目标检测的速度要求。在检测精度方面,改进后的模型较传统模型mAP@0.5 提升24.7个百分点,达到65.3%,mAP@0.5-0.95提升14.3个百分点。对于无人机航拍数据集,所提改进方法在目标检测方面性能均有提升,Yolov5s_UAV模型保持较高检测速度的同时大幅提升了检测精度,具有很高的适用性。

表4 改进过程模型变化实验数据表Table 4 Experimental data sheet for improved process model changes
3.6 模型对比实验分析
将数据集分别通过Yolov5s模型和改进后的Yolov5s_UAV 模型进行对比实验。与原模型相比,改进后的模型无论在召回率、准确率还是精度方面都有一定的提升,对数据集全类别提升效果明显,改进后的模型和传统模型各个类别的训练结果对比如表5 所示。通过训练结果对比图6 可知,传统Yolov5s 模型在训练过程中存在准确率不稳定、召回率不理想和mAP 值不高的问题。改进后的模型在训练方面比传统模型准确率更加稳定,召回率曲线更加平滑,同时mAP值也有所提高。
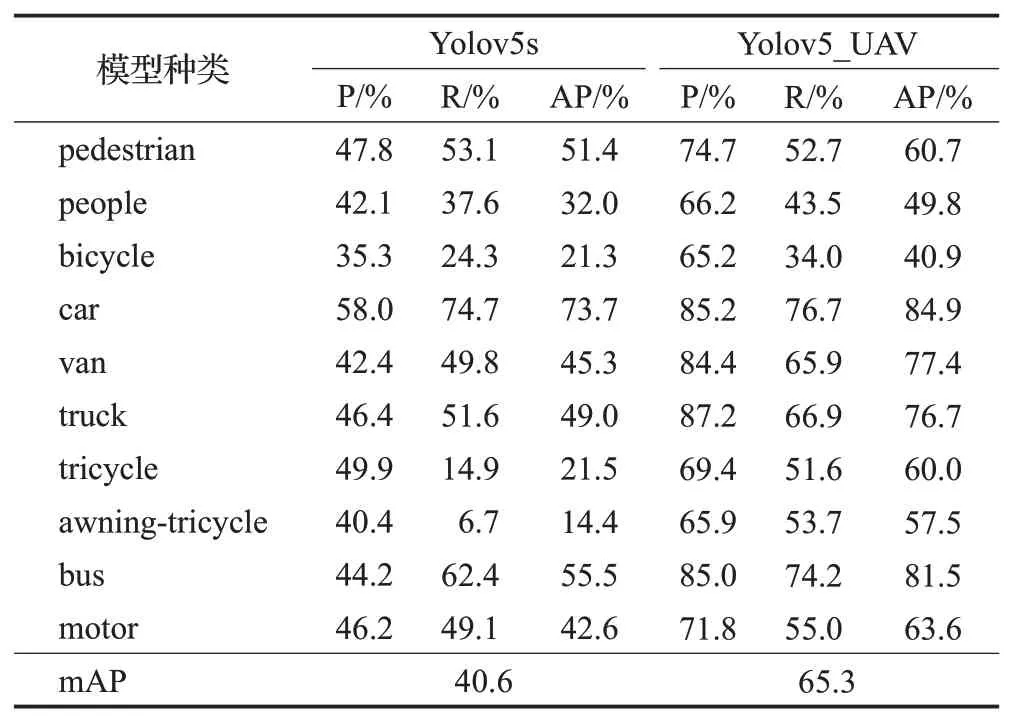
表5 改进模型前后种类检测性能对比表Table 5 Comparison table of species detection performance before and after improved model
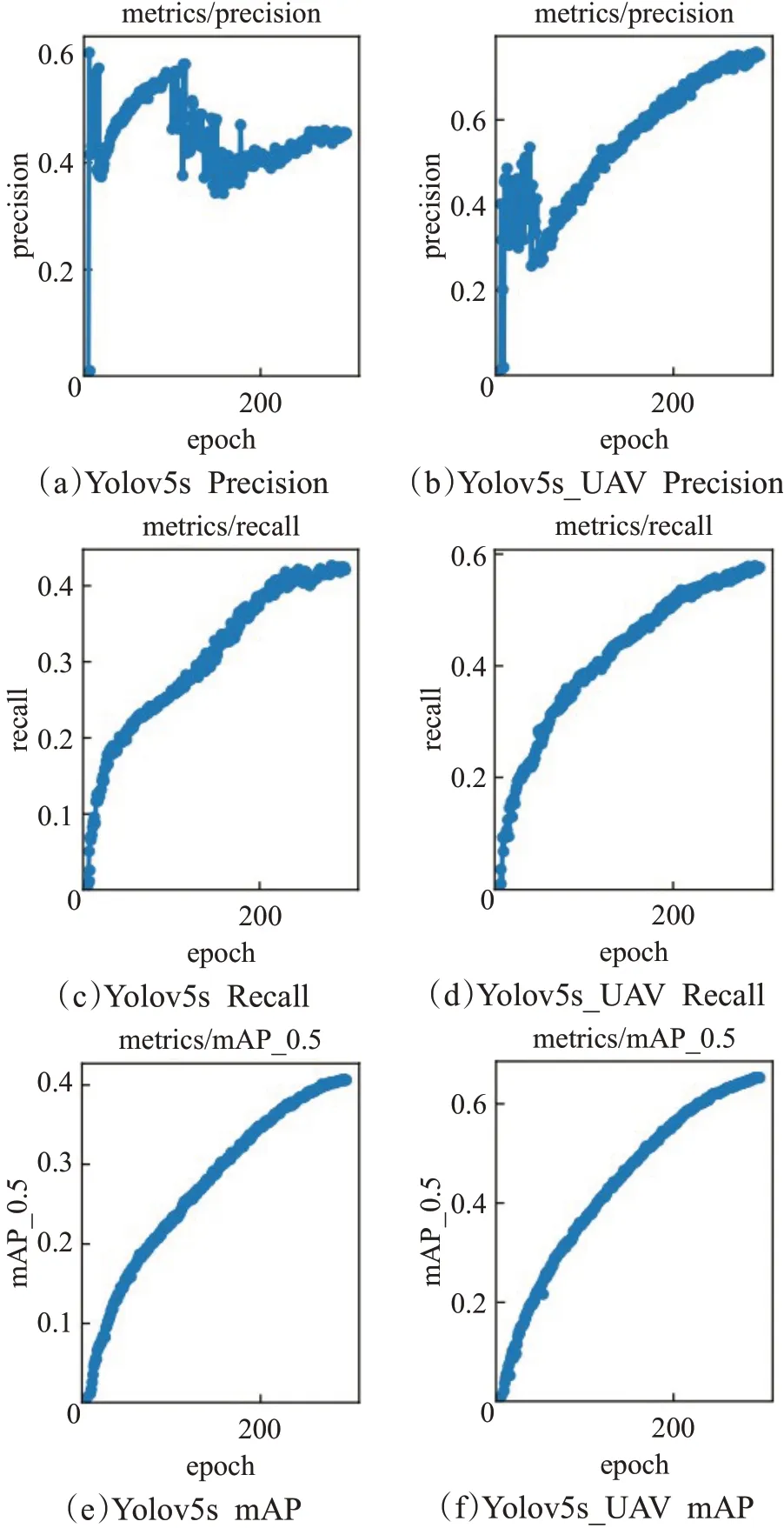
图6 改进前后模型检测性能对比图Fig.6 Comparison of model detection performance before and after improvement
为了验证改进后模型的高效性和适应性,本文采用其他模型对该数据集进行训练验证,分别为Yolov5系列的l、m、s、n版本模型和Yolo系列目前两大高版本Yolov6和Yolov7[26],同时选取了两个热门无人机目标检测算法优化模型进行对比实验,分别是轻量化无人机遥感图像小目标检测模型LUSS-YOLO[22]和对于航拍小目标的改进模型VA-YOLO[27]。选取参数量、计算力(GFLOPs)、模型大小、mAP@0.5 和mAP@0.5-0.95 等5 个性能指标进行记录,数据如表6 所示。从表可知,Yolov5s_UAV具有比Yolov5 系列模型参数少和精度高的优点。对比高版本Yolov6和Yolov7,Yolov5s_UAV模型小且检测精度高。与LUSS-YOLO、VA-YOLO 无人机优化模型相比,改进后模型虽然参数量和模型大小有所增加,但是对于目标识别的精度有较大提高。Yolov5s_UAV 是在满足无人机目标检测速度的前提下,通过优化检测模型结构,从而加强模型性能。

表6 其他主流无人机检测模型实验数据对比表Table 6 Other mainstream UAV detection model experimental data comparison table
考虑无人机飞行过程中极易出现图像抖动、目标遮挡和光线变化等情况,为了更加直观验证改进后模型的高效性以及对复杂环境的适应性,组建无人机航拍目标测试集并对传统模型和改进后的模型进行视觉检测结果对比。对比结果图如图7 所示,图左侧为传统模型Yolov5s的目标检测图,图右侧为改进后的模型Yolov5s-UAV的目标检测图。其中图7(a)表示密集小目标情况下改进前后模型对比图;图7(b)表示黑暗模式下对比图;图7(c)表示强光照射目标模糊情况下检测对比图;图7(d)表示有目标遮挡情况下检测对比图;图7(e)表示超高角度下模型检测对比图。由图7可知,传统模型在面对恶劣环境下存在小目标漏检情况,改进后的模型对小目标检测性能有了提升,减少了小目标漏检情况,提高了模型的检测精度,对复杂环境具有更好的适应性。

图7 复杂环境下改进前后模型检测对比图Fig.7 Comparison of model detection before and after improvement in complex environments
4 结束语
通过分析无人机航拍图像的特点,总结了无人机航拍图像检测方法的不足,在Yolov5模型基础进行了一些改进,利用C2F 模块和CARAFE 上采样算法对骨干网络进行修改,加强了模型对图像的特征提取和特征融合能力;采用全局性动态标签分配策略进行标签分配,提高了模型对密集目标和小目标的检测精度。Yolov5s_UAV模型较传统模型在性能上有较大提升,对数据集被测目标所有种类上的识别准确率、召回率和精度均有显著提升,mAP@0.5 值提升24.7 个百分点达到了65.3%,mAP@0.5-0.95 提升14.3 个百分点达到了34.5%。改进后的模型在满足无人机实时检测的情况下,可以更为准确地完成航拍过程中小目标的检测任务。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
时代邮刊·下半月(2020年9期)2020-09-23
电子制作(2019年11期)2019-07-04
金桥(2018年6期)2018-09-22
车迷(2018年11期)2018-08-30
小学生优秀作文(低年级)(2018年6期)2018-05-19
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
作文通讯·高中版(2017年6期)2017-07-10
公民与法治(2016年10期)2016-05-17
