
多标签文本分类研究回顾与展望
2023-09-25 08:54张文峰奚雪峰崔志明邹逸晨栾进权
计算机工程与应用 2023年18期
张文峰,奚雪峰,3,崔志明,3,邹逸晨,栾进权
1.苏州科技大学电子与信息工程学院,江苏苏州215000
2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏苏州215000
3.苏州智慧城市研究院,江苏苏州215000
文本分类是将文本内容划分为一个或多个类别的过程,是NLP中的一个基础任务。在现实世界中,由于文本数据环境复杂多变以及多义对象的存在,文本分类面临诸多严峻挑战。传统的单标签文本分类方法并不能完全满足用户的需求,多标签学习方法应运而生[1]。多标签学习是指从标签集中将最相关的类标签分配给每个文本的过程,从而直观地反映模糊对象的各种语义信息内容。例如,一篇关于2019冠状病毒病(“COVID-19”)的新闻报道会属于“医疗卫生”类别和“经济危机”或“国家安全”类别等多个类别。
多标签文本分类问题是多标签学习的重要研究方向,主要应用于情感分析[2]、主题标注[3]、问答[4]和对话行为分类[5]。其文本数据具有以下特点:一个文本可属于多个标签,因此需要捕获语义特征的不同层次和方面;文档较长时,语义信息会隐藏在冗余的内容中;大多数文本只属于少量标签[6];文本数据不平衡、标签丢失以及标签集过于庞大。基于上述问题,研究人员主要关注几个方面:如何充分应用标签的相关性;如何捕获有效信息并提取相关的特征信息;以及如何减缓类别不平衡、标签丢失、标签压缩的问题。
本文主要的主要贡献归纳如下:
(1)对多标签文本分类概念和流程进行阐述。
(2)对近年多标签文本分类方法进行回顾,梳理多标签文本分类常用数据集和评估指标;以及对部分模型或方法分析其优势和存在问题。
(3)对多标签文本分类领域的研究方向进行整理回顾。
(4)对多标签文本分类当前的难点和未来研究方向进行总结和展望。
1 多标签文本分类
1.1 多标签文本分类概念
给定一个d维输入空间X=X1×X2×…×Xd和一个输出q标签的空间Y={λ1,λ2,…,λq},q>1。每个标签 |λi|=2 的基数,一个多标签示例可以定义为一对(x,Y),其中x=(x1,x2,…,xd)∈X,Y∈Y 被称为标签集。D={(xi,Yi)|1 ≤i≤m} 是由一组m个文本构成的多标签数据集。
多标签文本分类是构建一个预测模型h:X →2Y,该模型将为文本提供一组相关标签。每个文本可能具有来自先前定义的标签集的与它相关联的几个标签。因此,对于每个x∈X,有一个标签空间Y∈Y 的二分区(Y,Yˉ),Y=h(x)是相关标签集合,Yˉ是不相关标签集合。多标签文本分类如图1所示。
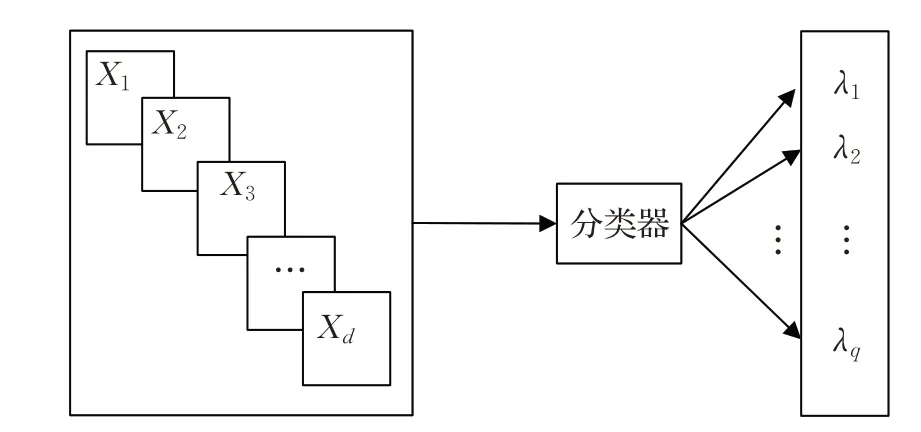
图1 多标签文本分类概念Fig.1 Multi-label text classification concept
1.2 多标签文本分类流程
多标签文本分类的流程如图2所示。
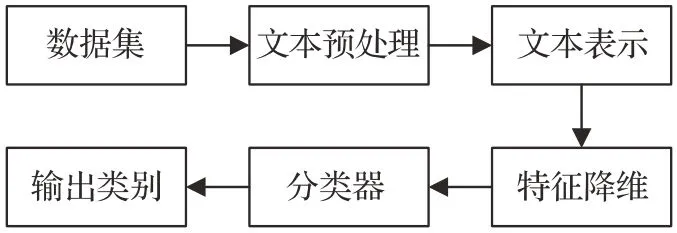
图2 多标签文本分类流程Fig.2 Multi-label text classification process
(1)数据集
多标签文本分类领域常用数据集在第3 章会有详细介绍。
(2)文本预处理
文本预处理是指对原始数据集进行去除停止词、分词、词性恢复等一系列操作,但目前对于上述处理已有非常成熟的技术。如果需要分词,可以直接使用jieba、HanLP[7]等现成的工具,研究人员不需要在这项研究上花费太多精力。
(3)文本表示
文本表示是自然语言处理领域的基石。由于机器无法直接识别自然语言,因此将自然文本转换为机器可以理解的表达式是文本表示的工作。文本表示的生成可以理解为按照一定的模型对文本数据进行编码,其发展大致经历了几个阶段,如One-hot、词袋(bag of words,BOW)、语言模型(LM)、Word2Vec[8]、Glove[9]等。One-hot表示通过二进制编码生成单词向量,每个维度仅指示字典中对应的单词是否在该位置取,该方法不仅会带来维数灾难,导致数据稀疏,还会造成文本语义的特征提取不足;BOW 在一元热的基础上用词频数据替代二进制数据,但仍未能解决维数灾难和语义丢失的问题;LM模型使用条件概率来表达文本序列中单词之间的关联,但LM 模型的语义表示方法比较原始,因此已经发展到Word2Vec模型。Word2Vec模型由连续袋词模型(CBOW)和Skip-Gram 模型组成。Word2Vec 模型使用类似于神经网络的结构来建立词之间关系的过程。近年来兴起的文本表示方法专注于上下文的词嵌入,如语言模型嵌入(ELMo),生成式预训练(GPT)[10]方法和BERT[11]的用双向编码器进行文本表示。ELMo 首先通过语言模型学习每个单词的单词嵌入,对上下文动态调整嵌入,解决了一词多义问题,同时实现语义关系判断的功能。在特征提取方面,ELMo采用了LSTM,但后来提出了一种新的特征提取器Transformer,并且特征提取能力被证明优于LSTM。因此,基于Transformer作为特征处理提出了GPT。GPT模型通过语言模型预训练,然后进行微调进行文本表示;但是,GPT是一种单向语言模型,只注意词的上文,而不考虑词的下文,所以它在语义理解上并不全面。为了同时考虑两个词序方向上的语义信息,提出了BERT针对大型数据集的训练,从而可以学习更合理的词表征,包括了上下文信息[12]。
(4)特征降维
向量化处理后文本特征较为稀疏,维度比较高。特征降维常用方式有TF-IDF[13]和互信息等。而在Transformer提出后,大多数都采用Transformer用作特征降维模块。
(5)分类器和输出类别
将特征降维后的数据送入分类器中进行模型训练,然后用测试集对模型的输出类别进行预测,用验证集和评估指标来评判模型的优劣。
2 多标签文本分类方法
多标签文本分类方法主要可以分为:基于传统机器学习和基于深度学习。传统的机器学习方法根据解决策略角度可以划分为问题转换方法和算法自适应方法。问题转换方法是将多标签问题转化为多个单标签子问题,然后这些子问题直接利用成熟的单标签算法来解决,所以问题转换方法独立于具体的算法,可以根据实际选择合适的算法。算法自适应方法是将现有的单标签算法进行拓展,使其能够直接应用到多标签数据上。多标签文本分类方法详细的分类如图3所示。
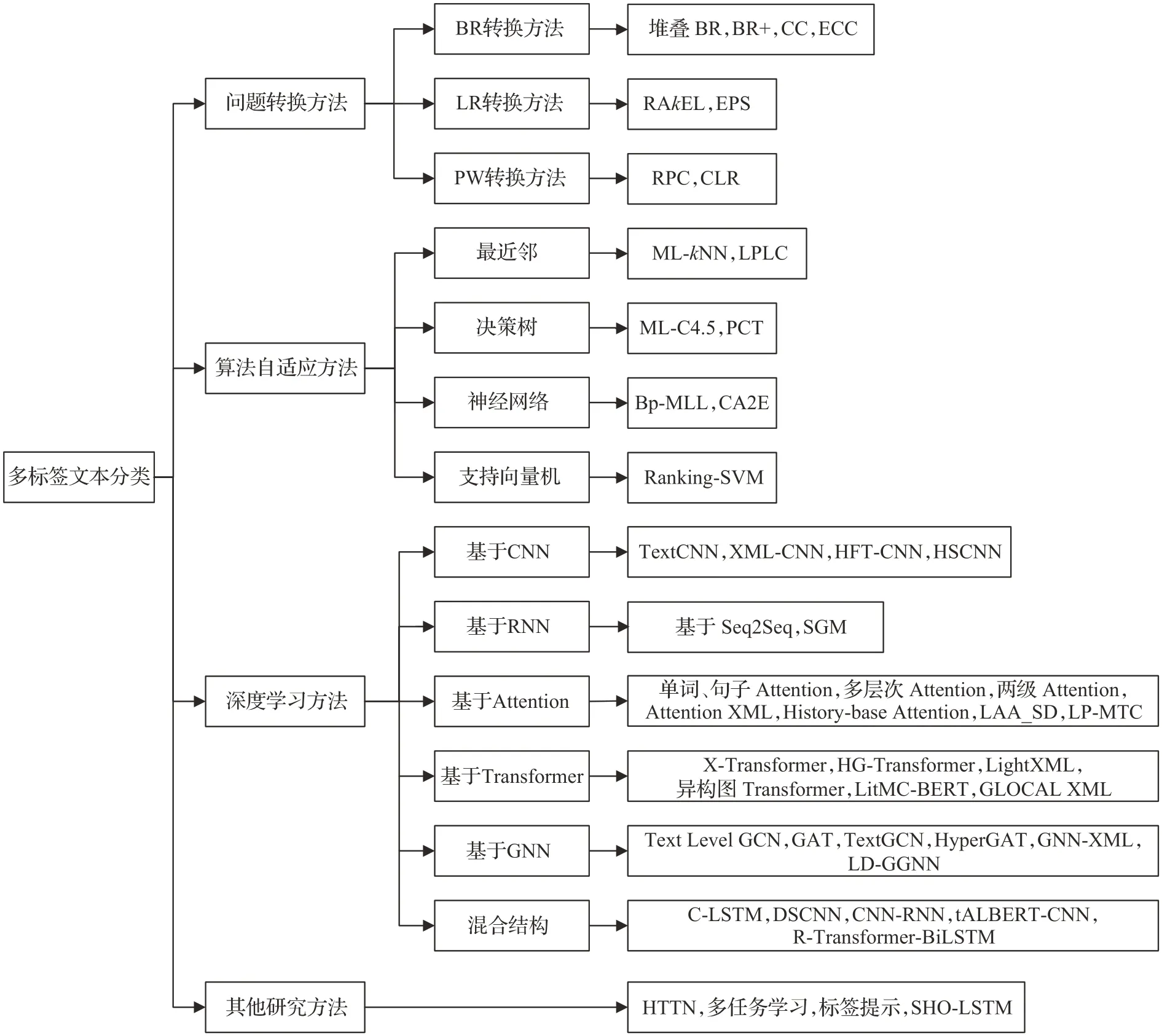
图3 多标签文本分类方法Fig.3 Multi-label text classification method
2.1 问题转换方法
目前,问题转换算法主要基于以下三种方法:(1)二进制相关性(BR)转换方法,(2)标签幂集(LP)转换方法,以及(3)成对方法(PW)。
2.1.1 BR转换方法
BR 是最具代表性的问题转换模型,它为每个标签建立了二元分类模型,但基本的BR 模型[14]忽略了标签相关性。为了利用BR 框架中标签之间的这种相关性,常见的方法是将标签作为额外的特征添加到原始特征中,然后构建相应的分类器,这些改进的BR模型可以分为两种类型。第一种类型是构造两层BR,第一层显示了与原始BR相同的做法,在第二层中,第一层的输出作为额外特征添加到原始特征中;然后,基于这些增强的特征,学习每个标签的二进制分类器。第二层的输出用作预测标签,使用这种方式的BR 模型称为基于堆叠的BR模型。第二种类型是将所有二进制分类器连接成一个链,链上的一个分类器将所有先前分类器的输出作为额外的特征添加到原始特征中,这样的框架称为分类器链模型。下面详细介绍了BR 模型、基于堆叠的BR 模型和分类器链模型。
(1)BR模型
2004 年,Boutell等人[14]首先提出了基本的BR模型。它将多标签问题转换为几个二进制分类子问题,所有子问题共享相同的特征空间,但是标签空间不同。尽管BR算法简单,直观且应用广泛,但由于它忽略了标签之间的关系,因此预测性能较差。
(2)基于堆叠的BR模型
Godbole 等人[15]将集成学习中的基于堆叠的学习策略引入到BR 算法中,考虑了标签相关性。在训练过程中,基于堆叠的BR模型建立了两层BR模型:第一层是基础层,与传统BR学习过程相同,并为每个标签分配相应的二进制分类模型。在元层次的第二层中,将基础层次中所有二元分类模型的预测标签添加到原始特征空间中,在这些扩展的特征上再次学习每个标签,得到相应的二元分类模型。这种基于堆叠的BR算法假定任何标签都与所有标签相关,然而,这在大多数情况下是无效的。相关研究有算法BR+[16]和基于剪枝与堆叠的算法BR[17]。
(3)分类器链模型
Read等人[18]首次提出了分类器链(CC)模型。与BR算法不同,链中的标签将所有先前标签的二进制分类器输出添加到原始特征空间中,作为新的特征进行训练。CC 模型有两个明显的缺点:一是分类器的效果受标签序列的影响很大,不同的序列带来明显不同的分类效果;另一个是当前标签可能与序列的前一部分中的标签无关,因此它可能通过使用所有先前标签的输出来引入噪声。在同一文献中,Read提出了CC的集成框架(ECC)。在ECC中,采用多个随机标签序列的CC模型的均值预测结果,可以在一定程度上解决随机标签序列对分类的影响,然而,这种计算费用成倍增加。Cheng 等人提出了概率分类器链(PCC)模型,并指出可以从标签的条件联合分布中获得基于汉明或秩等损失函数的分类器链。除了改善基于概率推导的CC 算法的效果之外,还有一些其他方法可以找到最佳或更好的标签序列。例如,GA-PratCC 通过使用遗传算法搜索最佳标签序列;OOCC从k近邻中找到每个样本的最佳标签序列。
2.1.2 LR转换方法
LP 变换方法[19]是将训练集中所有标签的组合视为一个类,然后将多标签问题转化为单标签多类问题。从学习中获得分类器后,看不见的实例是输入,类是输出,该类对应于一个标签集,该标签集涵盖了实例所属的所有标签。
LP 变换方法只能预测出现在训练集中的标签集。此外,当有很多标签时,可能会有很多标签集。因此,许多集合可能具有一些相同的实例,从而导致类不平衡。这些问题不仅增加了学习的时间成本,而且降低了模型效果。为了解决这些问题,提出了两个著名的算法RAkEL[19]和EPS[20]。
随机k个标签集(RAkEL)算法通过LP 变换方法训练每个标签集。RAkEL可以获得比BR和LP更准确的性能。此外,RAkEL 还减少了必须学习的模型数量。在预测过程中,使用LP 方法获得的所有学习者来预测看不见的实例,并对所有预测结果进行平均。因此,RAkEL是一种集成学习方法。
EPS算法计算与标签集(Ri)相关的实例数(Count(Ri))。如果Count(Ri)高于指定的阈值,则将与Ri相关的所有实例添加到训练集中。如果计数(Ri)低于阈值,则继续对与Ri的子集相关的实例进行计数。如果子集的频率高于指定阈值,则将与该子集相对应的样本添加到与Ri相对应的训练集中。这样,LP方法就在Ri的相应训练集上进行了训练。同时,EPS还通过集成学习减少了过拟合问题。
2.1.3 PW转换方法
2008 年,Hüllermeier 等人[21]提出了成对比较排序(RPC)算法,并将其应用于多标签分类。该算法将包含q个标签的多标签问题转换为q(q-1)/2 个二进制分类子问题,每个子问题对应一对标签。标签对(yi,yj)的子问题包含原始问题中与标签yi或yj相关的所有实例,但同时与这两个标签相关的文本被排除在外。这样,与标签yi相关的实例是正例,而其余的则被视为负实例。因此,可以通过传统的单标签算法解决此子问题。
显然,RPC算法的规模受标签数量的影响很大。当标签数量很大时,RPC 算法对于高复杂度是不切实际的。此外,RPC算法无法区分与测试一下实例相关的标签。换句话说,它缺乏阈值或划分点来区分标签的哪一部分属于实例。
Fürnkranz 等人[22]提出了校准标签排名(CLR)算法来解决上述划分点问题。在CLR 算法中,添加了校准标签y0作为相关标签和不相关标签的边界。与RPC算法相比,每个标签yj只需添加一个子问题(yj,y0),其中数据涵盖与标签yj相关的所有实例(被视为与y0无关)和与标签yj无关的实例(被视为与y0相关)。
2.2 算法自适应方法
算法自适应是对现有的单标签算法进行拓展以轻松应用于多标签文本数据。在本节中,介绍了几种具有代表性和广泛使用的算法自适应方法。
2.2.1 最近邻
ML-kNN[23]是第一个使用最近邻的多标签算法。其基本思想是计算k个最近邻中标签的出现,然后计算每个标签在不同出现时间下的概率,根据最大后验原理给出预测结果。为了估计相应的概率,ML-kNN必须实现大量的计算和距离比较,时间复杂度相对较高。如果训练集中存在噪声,ML-kNN 算法的效果容易受到影响,并且ML-kNN不考虑标签相关性。为了解决这个问题,LPLC[24]利用了最近邻范围内的一对标签中的相关性。LPLC 与ML-kNN 的概率估计差异很小,关键差异在于LPLC 致力于为预测的标签找到相关标签集。LPLC 假设强相关性仅存在于与训练实例相关的标签之间,对于具有n个实例和q个标签的训练集,需要定义一个n×q矩阵M来记录与每个实例相关的相关标签。然后,基于M计算每个标签的概率。
2.2.2 决策树
Clare 等人[25]提出了一种基于决策树的多标签算法ML-C4.5。它从上到下构建决策树,树根包括所有训练样本。对于非叶节点中的实例,逐一调查每个特征,以找到合适的划分点。此划分点用于划分此节点的实例,从而获得最大的信息增益。
基于预测聚类树(PCT)[26]实现了分层多标签分类学习。与其他决策树类似,PCT也根据最大程度地减少簇内方差的原则,从上到下将当前簇划分为较小的簇。对于当前群集中的实例,方差度S定义为标签向量(ci)与平均标签向量(cˉ)之间的距离的平方和。
2.2.3 神经网络
Bp-MLL[27]是第一个将传统神经网络转换为多标签分类的算法。它构造了一个简单的三层网络,输入层有d个输入单元,每个单元对应于训练集的一个特征;隐藏层包含M个单元;输出层具有q个单元,每个单元对应一个标签。在Bp-MLL中,全局损失函数参与区分实例的相关标签和不相关标签,并指导学习系统输出相对较大的相关标签值以及相对较小的不相关标签值。与传统的直接比较输出层各标签预测值和实际值的损失评估方法相比,Bp-MLL 考虑了不同标签之间的关系,取得了更好的效果。CA2E 是一种基于深度神经网络(DNN)提出的多标签分类算法。CA2E 算法的目标函数可以分为两部分。第一部分是利用DNN模型求解目标函数,得到嵌入特征和标签空间。第二部分旨在使整个模型的输出恢复标签空间,其中使用类似于Bp-MLL的方法来解决该问题。
2.2.4 支持向量机
Elisseeff提出Ranking-SVM算法[28]。首先,Ranking-SVM算法将高效率单标签方法支持向量机(SVM)转化为直接用于多标签分类的方法。Ranking-SVM 首先为每个标签定义线性分类器{hj(X)=<ωj,X>+bj=ωTj+bj|1 ≤j≤q},然后最大化所有相关和无关标签对之间的距离。
2.3 深度学习方法
与传统的机器学习方法不同,深度学习方法更为复杂,但极其促进了多标签文本分类的发展,本节将深度学习模型根据其结构主要划分为基于卷积神经网络(convolutional neural network,CNN)、基于循环神经网络(recurrent neural network,RNN)、基于注意力机制(attention)、基于Transformer、基于图神经网络(graph neural network,GNN)和混合结构。
2.3.1 基于CNN
CNN 包括卷积层、池化层和全连接层。典型CNN结构如图4所示。
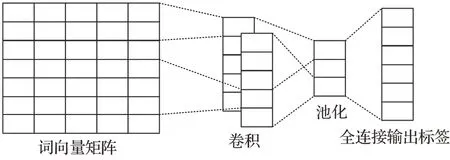
图4 CNN结构Fig.4 CNN structure
CNN在检测局部和位置不变模式很重要的情况下性能良好。2014 年,Kim 等人[29]提出了TextCNN 模型,在预先训练的词向量上训练CNN,用于句子级分类任务,用一个具有少量超参数调优和静态向量的简单CNN测试,通过微调学习特定于任务的向量。但因为CNN中需要利用固定窗口的问题,因此不可以对长文本信息进行建模。Liu 等人[30]改进了TextCNN 的结构,提出XML-CNN。该模型与TextCNN 不同之处是通过将文档通过各种卷积过滤器传递来学习大量的特征表示,采用动态最大池化,从文档的不同区域捕获更多细粒度的特征;利用输出上的二进制交叉熵损失,在池化和输出层之间插入了一个额外的隐藏瓶颈层,以学习紧凑的文档表示形式。Shimura 等人[31]提出了一种利用CNN 的微调技术,一种分层卷积神经网络结构(HFT-CNN),有效利用上层数据为下层分类做出贡献。Yang 等人[32]提出了一种双高光谱CNN(HSCNN)来处理不平衡数据,是一种混合-暹罗卷积神经网络(HSCNN),即基于单网和暹罗网络的多任务结构,对头部分类采用通用网络,对尾部分类采用少射技术。
尽管基于CNN的多标签文本分类不需要花费大量的计算成本,但是由于CNN 的需要利用固定窗口的缺点以及池化操作会造成语义的丢失,所以当上下文文本过长时,基于CNN 的模型不利于捕捉上下文之间的标签关系,因此不利于多标签文本分类。
2.3.2 基于RNN
RNN是一种用于从时间序列数据中捕获信息的网络。RNN 结构如图5 所示,其中,xt为t时刻输入;St为t时刻隐层单元;yt为t时刻输出;O为权重矩阵;U为输入变换矩阵;V为输出变换矩阵,与U在序列的不同时间点上共享,可以视为学习序列中固定的状态转移矩阵。
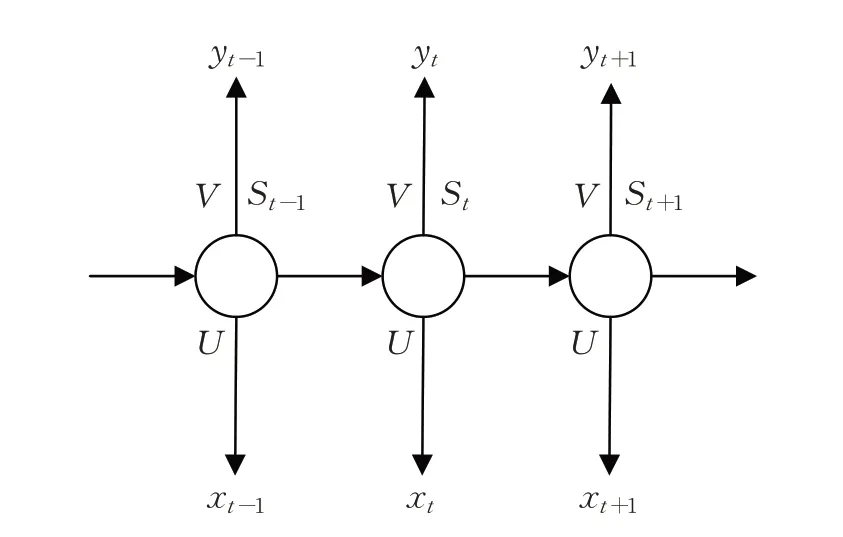
图5 RNN结构Fig.5 RNN structure
基于RNN 的模型将文本视为一个单词序列,旨在为TC捕获单词依赖关系和文本结构。对于多标签文本分类,基于CNN 的方法通常不能捕获多个标签之间的复杂关联,导致查全率低。为了解决这一问题,RNN被广泛应用于探索标签的相关性,用于多标签文本分类[33-34],它是一种逐条预测标签的递归神经网络。Nam 等人[33]使用RNN 代替的分类器链,这是一种序列到序列的预测算法,最近已成功应用于许多领域的序列预测任务。这种方法的关键优势在于,它允许仅专注于正标签的预测,其集合比可能标签的完整集合小得多。此外,所有分类器之间的参数共享可以更好地利用先前决策的信息。后续研究中,Yang等人[35]进一步将深度强化学习纳入Seq2Seq 模型,以减少标签排列对性能的影响。Lin等人[36]提出了基于Seq2Seq 模型的多级扩展卷积,扩张型卷积有效地降低了维数,支持接受域的指数扩展而不丢失局部信息。
但这些模型忽略标签之间的相关性或者不考虑文本内容关键信息,因此,不能得到较好的预测结果。Yang等人[37]把多标签文本分类问题当作序列生成,考虑标签间相关性,对解码部分进行改造,并且自动获取文本的关键信息,提升标签预测的有效性,这一改进在一定程度上改善了模型效果,但还有待提高。
2.3.3 基于Attention
注意力(Attention)机制由Bengio 团队2014 年提出并应用于自然语言处理。Yang 等人[38]将单词级和句子级的注意力纳入模型,处理大规模文本分类。Hong等人[39]提出了注意力池化,增加了2D max 池化操作,以维护更重要的语义信息,降低噪声的影响。此外,为了更好地突出不同情境下的重要文本信息,提出了多层次的注意力机制。Li 等人[40]采用两级注意力来提高文本分类的性能,第一级注意力旨在同时捕获局部和长距离相关的特征,第二级注意力通过双向循环注意网络对生成的特征进行注意。You等人[41]提出Attention XML捕获文本与每个标签最相关的部分,Attention XML 的出现超越所有传统机器学习方法,并证明原始文本与稀疏特征相比的优越性。与在XML-CNN 中使用简单全连接层进行标签评分不同,Attention XML 采用了可以处理数百万个标签的概率标签树(PLT),通过其上层模型初始化当前层模型的权重,可以帮助模型快速收敛。但是,这仍然使Attention XML 在预测和从大型整体模型尺寸中获取数据方面的速度非常慢。Du等人[42]首先使用卷积运算来捕捉注意力信号,每个信号代表一个词在其上下文中的局部信息;然后这些注意信号再被进行预测。Xiao等人[43]第一个试图在Seq2Seq模型中提出了基于历史的注意力机制,以增强多标签文本分类中标签的预测能力。基于历史的注意机制考虑了历史上下文信息以避免陷入标签陷阱,同时考虑了历史标签信息以缓解错误传播问题。Liu 等人[44]提出了LAA_SD 方法,从冗余内容中选择歧视性特征,考虑了语义标签,并基于注意力机制建立了标签与文本之间的关系,该方法将增强的文本特征表示与标签语义依赖相结合,以执行文本多标签学习。Song 等人[45]提出了一种标签提示多标签文本分类模型(LP-MTC),设计了一套多标签文本分类的模板,将标签集成到预先训练好的语言模型的输入中,并通过蒙面语言模型(MLM)联合优化。通过这种方式,在自我注意力机制下捕获标签之间的相关性以及标签与文本之间的语义信息,从而有效地提高了模型性能。
2.3.4 基于Transformer
RNN遇到的计算瓶颈之一是文本的顺序处理。尽管CNN 的顺序性不如RNN,但捕获句子中单词之间关系的计算成本也会随着句子长度的增加而增加,这与RNN类似,Transformer克服了这些问题,其结构只保留了Attention,如图6 所示,不需要与RNN 或CNN 相结合。应用自我注意力来并行计算句子或文档中每个单词的“注意力得分”,以模拟每个单词对另一个单词的影响。由于这一特性,Transformer允许比CNN和RNN更多地并行化,这使得在GPU 上对大量数据高效地训练非常大的模型成为可能。
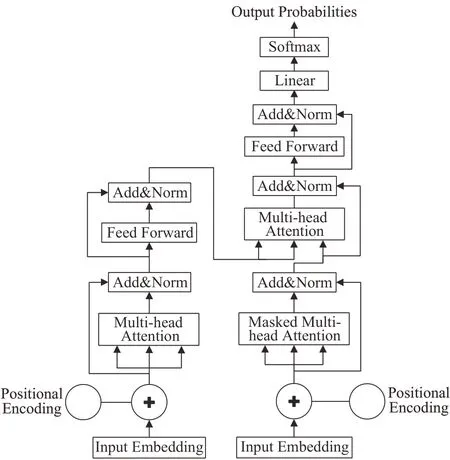
图6 Transformer结构Fig.6 Transformer structure
Chang等人[46]提出了X-Transformer模型,它仅使用深度学习模型来匹配给定原始文本的标签簇,并通过具有深度学习模型的稀疏特征和文本表示的高维线性分类对这些标签进行排序。但由于Transformer模型的计算复杂度高,因此仅对Transformer 模型进行微调作为标签聚类匹配器,无法充分利用Transformer 模型的功能。尽管X-Transformer可以以较高的计算复杂度和模型大小为代价,达到比AttentionXML更高的精度,但因为通过使用更多的集成模型,AttentionXML可以在相同的X-Transformer计算复杂度下达到更好的精度。Gong等人[47]提出了HG-transformer,该模型将输入文本建模为图结构;然后在词、句、图三个层次采用多层转换结构,充分捕捉文本特征;最后利用标签之间的层次关系生成t个标签表示。Jiang 等人[48]提出LightXML,采用端到端训练和动态负标签采样。在LightXML 中,使用生成式合作网络对标签进行调用和排序,其中标签调用部分生成负标签和正标签,而标签排序部分将正标签与这些标签区分开来。通过这些网络,在标签排名部分训练期间,通过馈送相同的文本表示来动态采样负标签,提升模型的效果。Ye等人[49]提出了一种新颖的基于神经网络的多标签文档分类方法,其中使用异构图Transformer构造和学习两个异构图。一种是元数据异构图,它对各种类型的元数据及其拓扑关系进行建模;另一个是标签异构图,它是根据标签的层次结构及其统计依赖性构建的。Chen 等人[50]提出LitMC-BERT 模型使用共享Transformer主干,同时还捕获特定于标签的特征和标签对之间的相关性,来进行多标签分类。Zhang 等人[51]认为全局特征向量可能不足以表示文档中语义的不同粒度级别,因此结合了Transformer 模型产生的局部和全局特征,以提高分类器的预测能力。
2.3.5 基于GNN
虽然自然语言文本表现出连续的顺序,但是它们也包含内部的图结构,例如语法和语义分析树,其定义句子中的词之间的语法和语义关系。为NLP 开发得最早的基于图的模型之一是TextRank。作者提出将自然语言文本表示为图形(V,E),其中V表示一组节点,E表示节点之间的一组边。根据具体的应用,节点可以表示各种类型的文本单位,例如单词、搭配、整句话等。同样,边缘可以表示任何节点之间的不同类型的关系,例如词汇或语义关系、上下文重叠关系等。
在各种类型的GNN 中,图卷积网络(GCN)[52]及其变体,是最流行的一种,因为它们有效且方便地与其他神经网络组合,并且在许多应用中已经实现了最先进的结果。GCN将卷积操作从网格数据推广到图数据。主要思想是通过聚合它自己的特征和相邻的特征来生成节点的表示,GCN 堆叠多个图卷积层以提取高级的节点表示。Liu 等人[53]提出的Text Level GCN 模型为每个输入的文本建构独立,但具有全局参数共享的图而不是为整个训练、测试语料库建立一个巨大的单图,并通过滑动窗口来构建图形,当中可以设定n元语法的数量,用于提取更多的局部特征,并减少大量的计算资源,这也使图神经网络能够从已有的资料中归纳出模式,并应用于新的任务。Velikovi等人[54]提出的图注意力网络(graph attention network,GAT)是GCN 的一个变体,它操作图形结构数据,利用隐藏的自我注意力层来解决了先前基于图卷积缺点。通过层层叠加,节点能够参与到它们邻近节点的特性,支持(隐式地)指定不同的权重一个邻域中的不同节点,不需要任何昂贵的矩阵运算(如反转)或依赖于预先了解图的结构。Yao 等人[3]提出了TextGCN 模型,使用GCN 为整个资料集建立一个基于文本和词的异构图,可以用来得到全局图的共现信息使GCN能够对文本进行半监督分类。Pal等人[55]提出了一种基于图注意力网络的模型来捕捉标签之间的注意依赖结构。图注意力网络使用特征矩阵和相关矩阵来捕获和探索标签之间的关键依赖关系,并为任务生成分类器。所生成的分类器被应用于从文本特征提取网络(BiLSTM)获得的句子特征向量以实现端到端训练。Ding 等人[56]提出了一个原则性模型——超图注意网络(HyperGAT),它可以在文本表示学习中以更少的计算消耗获得更强的表达能力。Zong 等人[57]提出了GNNXML,这是一个可扩展图神经网络框架。通过挖掘它们的共现模式来利用标签相关性,并基于相关矩阵构建标签图;然后,通过使用低通图滤波器进行图卷积来联合建模标签依赖关系和标签特征,从而进行属性图聚类,诱导语义标签聚类。Zheng 等人[58]提出了一种标签划分门控图神经网络(LD-GGNN),可以更好地区分同级标签,实现文本与标签之间的自适应交互,优化了门控图神经网络(GGNN),以准确捕获标签层次结构的结构特征,并深入探索标签依赖性,利用GGNN 更强的非线性特性来解决过平滑问题。
2.3.6 混合模型
许多混合模型已经被开发出来应用于多标签文本分类。
Zhou 等人[59]提出了一种卷积LSTM(C-LSTM)网络。C-LSTM 利用CNN 来提取较高级短语(n元语法)表示的序列,该序列被馈送到LSTM网络以获得句子表示。类似地,Zhang 等人[60]提出了用于文档建模的依赖性敏感CNN(DSCNN)。DSCNN是一个分层模型,其中LSTM学习句子向量,这些句子向量被馈送到卷积和最大池层以生成文档表示。Chen等人[34]提出了一种CNNRNN模型,以准确获得全局和局部文本语义信息,建模高阶标签相关性。Transformer 的提出对自然语言处理领域产生了巨大的影响,但Transformer 模型所需的模型参数往往较多,网络结构复杂,在实际应用过程中有一定的局限性。Liu 等人[61]提出了一种tALBERT-CNN的多标签文本分类方法,使用LDA主题模型和ALBERT模型获取每个词(文档)的主题向量和语义上下文向量,采用一定的融合机制获得文档的深度主题和语义表示,通过TextCNN模型提取文本的多标签特征,训练多标签分类器,减少了模型参数。Yan 等人[62]本文提出了一种基于标签嵌入和注意力机制的R-Transformer_BiLSTM模型用于多标签文本分类。首次将实体识别模型引入文本分类利用R-Transformer模型结合部分语音嵌入来获取文本序列的全局和局部信息;同时使用BiLSTM+CRF获取文本的实体信息,使用自我注意力机制获取实体信息的关键词;然后,使用双向注意力和标签嵌入进一步生成文本表示和标签表示;最后,分类器根据标签表示和文本表示进行文本分类。
2.3.7 其他研究方法
Xiao 等人[63]提出了一种头对尾网络(HTTN),将元知识从数据丰富的头部标签转移到数据贫乏的尾部标签。Zhang等人[64]引入了一种具有多任务学习的新颖方法,以增强标签相关性反馈。首先利用联合嵌入(JE)机制同时获得文本和标签表示,在MLTC 任务中,采用了文档标签交叉注意力机制(CA)来生成更具歧视性的文档表示。此外,提出了两个辅助标签共现预测任务来增强标签相关性学习:(1)成对标签共现预测(PLCP)和(2)条件标签共现预测(CLCP)。Khataei 等人[65]提出了一种基于LSTM 网络和SHO 算法的MLTC 的斑点鬣狗优化器-长短期记忆(SHO-LSTM)模型。在LSTM网络中,将单词嵌入到向量空间中,采用SHO算法优化LSTM网络的初始权值。调整LSTM 中的权重矩阵是一个重大挑战,如果神经元的权重准确,那么输出的精度会更高。表1列举了部分深度学习模型或方法。
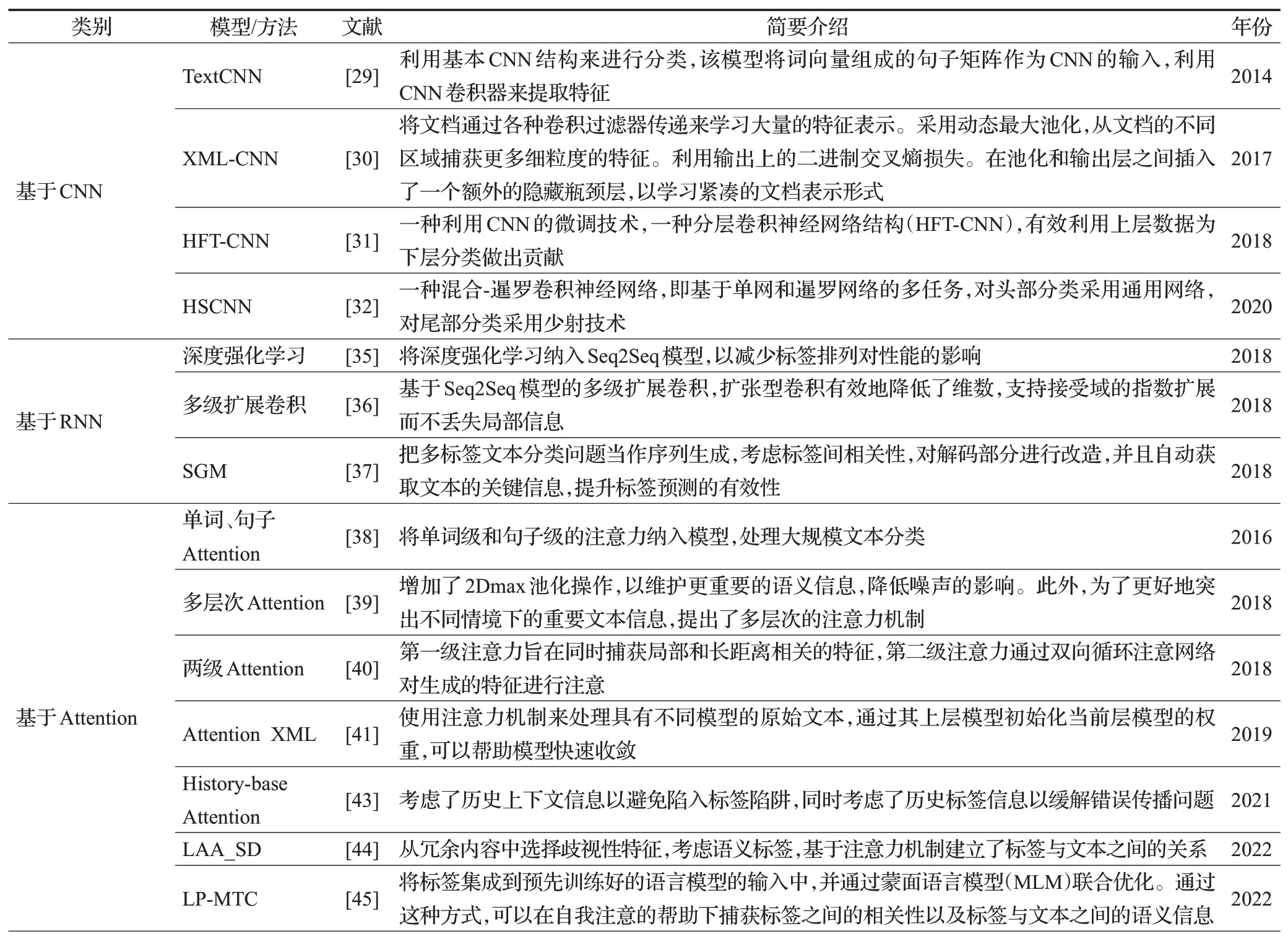
表1 深度学习模型及方法Table 1 Deep learning models and methods
3 多标签文本分类数据集
总结了13 个多标签文本分类领域的主流数据集,涵盖中英文、长文本、短文本、极端多标签和普通多标签。并按照样本的平均标签数进行排列并在表2 中显示了相关数据。
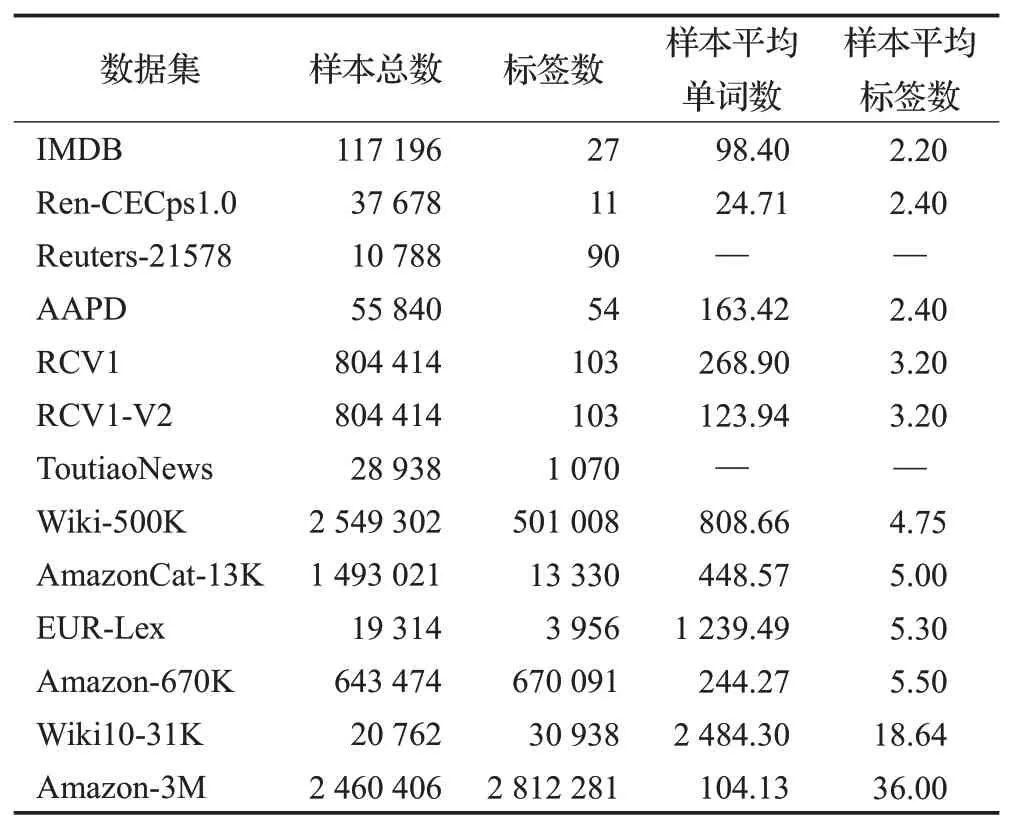
表2 多标签文本分类数据集Table 2 Multi-label text classification dataset
(1)IMDB:包含117 196 个电影介绍(英文),共有27个电影类别,每个电影介绍都有一种或多种可能的类型。数据集根据电影是否属于特定类型,为每个电影提供多标签二进制掩码。
(2)Ren-CECps1.0:该数据集是中文情感语料库,包含37 678个中文博客的句子和11种情感标签。
(3)Reuters-21578:数据集包含22 个文档,总共10 788篇来自路透社的新闻文章,总共90个标签。
(4)AAPD:该数据集收集了55 840 篇论文的摘要和相应学科类别,一篇学术论文属于一个或者多个学科。
(5)RCV1:共有804 414篇新闻报道,涉及103个类别。每个报告可能包含一个或多个类别。平均而言,每个新闻报道包含3.2个类别标签。
(6)RCV1-V2:该数据集共有804 414 篇新闻,每篇新闻故事分配有多个主题,共有103个主题。
(7)ToutiaoNews:该数据集为今日头条统计新闻的中文数据集。
(8)Wiki-500K:数据也包含自维基百科,但与Wikil0-31K数据集相比,样本数量更大,标签数量更大。
(9)AmazonCat-13K:该数据集来自亚马逊,包含用户评论和产品信息等数据。
(10)EUR-Lex:数据集组织来自各种欧盟法律、条约等的文件,并包含15 449 个训练文档和3 865 个测试文档,整个数据集总共有3 956个标签。
(11)Amazon-670K:该数据集是亚马逊商品的评论,有643 474条样本数据。
(12)Wiki10-31K:数据集包含维基百科上的20 762篇文章,但标签数量达到了30 938个。
(13)Amazon-3M:该数据集是亚马逊商品的产品信息、链接和评论,标签数量达到2 812 281个。
4 多标签文本分类评估指标与模型分析
4.1 评估指标
多标签文本分类(MLTC)模型的评估不同于单标签分类模型的评估。因此,根据文献[66],已经提出了几种多标签文本分类评估指标,它们分为两种主要方法:基于实例的指标和基于标签的指标。第一种方法是测试每个实例,然后对所有测试实例进行平均计算。第二种方法是对每个标签计算,然后在所有标签上取平均值。
4.1.1 基于实例的指标
下面介绍了用于评估多标签文本分类模型的最常见的基于实例的指标。假设:m指数据集中的实例总数,i表示数据集中的实例(其中1 ≤i≤m),n为标签总数,Zi和Yi分别指预测的和实际的标签。
(1)汉明损失(Hamming loss):计算在实例标签对中发现的平均错误数,并在所有实例上平均。此度量的表达式如公式(1)所示:
其中∆定义了预测标签和实际标签之间的对称差,因子1/n用于获得[0,1]中的归一化值。
(2)多标签精度(ML-accuracy):计算正确预测的标签与标签总数的比率,计算如公式(2)所示:
(3)子集精度(Subset-accuracy):称为精确匹配比或分类精度。这是一个非常严格的指标,用于测量预测标签的比率,该比率与它们相应的实际标签集完全匹配,计算如公式(3)所示:
(4)精度(Precision):该指标提供了正确分类的标签与预测标签的比率,计算如公式(4)所示:
(5)召回率(Recall):计算实际标签的正确预测标签的比率,计算如公式(5)所示:
(6)F-度量(F-measure):精度和召回率的调和平均,计算如公式(6)所示:
除了汉明损失度量之外,本小节中描述的所有基于示例的度量都表明具有越高值的度量具有更好的性能,汉明损失的值越低表示性能越好。
4.1.2 基于标签的指标
基于两种计算平均值的方法为所有标签计算二进制评估指标(例如召回率、精度和F-度量);宏观或微观平均方法。这些指标被广泛用于测量召回率、精度和F-度量的平均值。设B为一种用于计算这些指标的二进制评估度量,该度量基于真正类(tp)、假正类(fp)、真负类(tn)和假负类(fn)的数量进行计算。如公式(7)、(8)中说明了B(tp,fp,tn,fn)的宏观平均和微观平均指标的表达式。
4.2 模型分析
表3为对相关多标签文本分类方法在部分数据集上的结果分析。
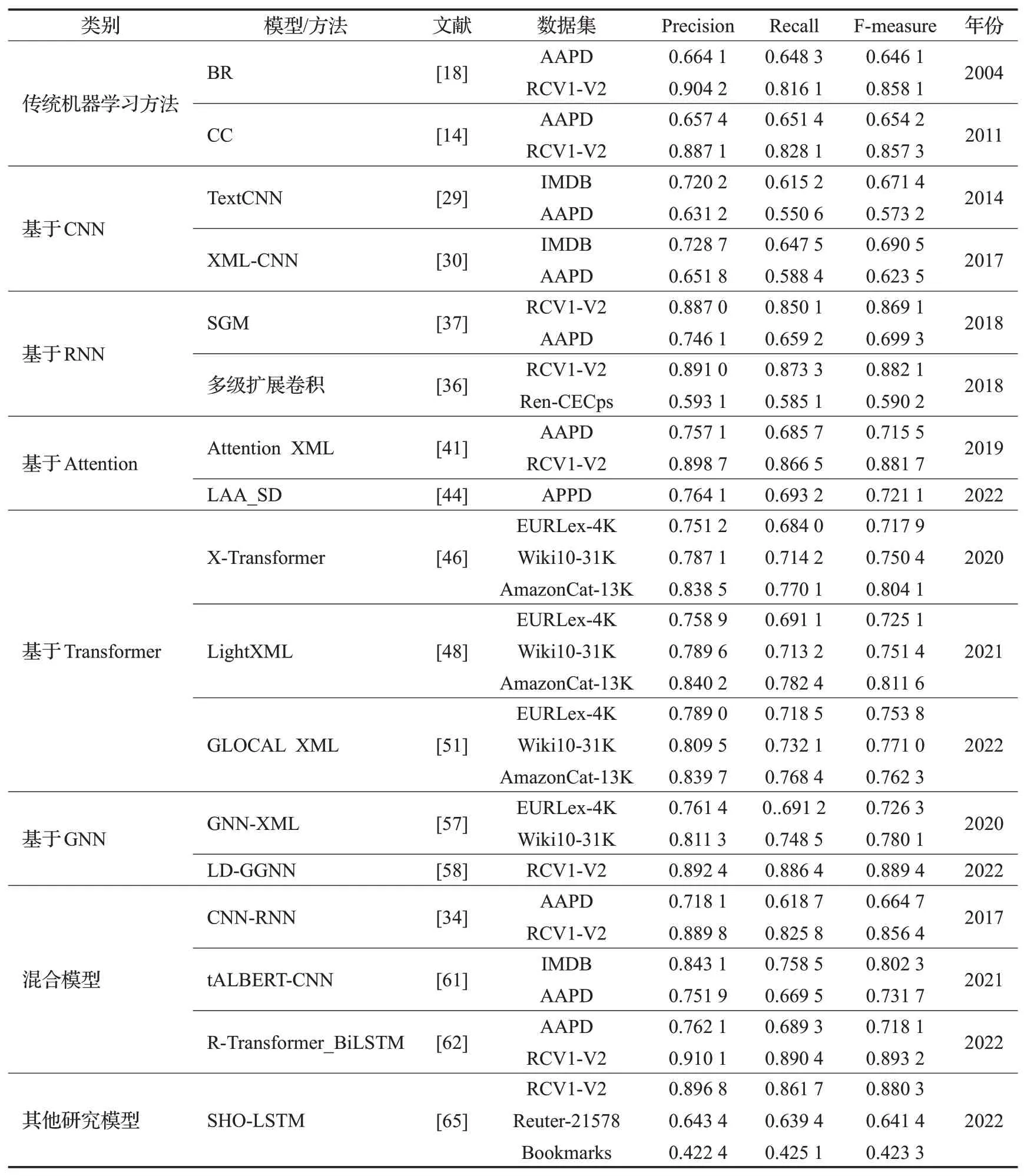
表3 模型方法结果分析Table 3 Analysis of model method results
从模型结果可以看出,随着深度学习的发展,基于深度学习方法的模型在不同数据集上的F-measure值都有显著的提升。在APPD 数据集上,F-measure 值从BR模型的0.641 2 提升到LP-MTC 模型的0.745 8,提升的效果十分明显。在RCV1-V2数据集上,F-measure从BR模型的0.851 8 提升到R-Transformer_BiLSTM 模型的0.893 2。在EURLex-4K数据集上模型的效果从0.717 9提升到0.753 8。在其他的数据集上,随着深度学习的发展,模型都有显著的提升。R-Transformer_BiLSTM 模型在RCV1-V2数据集上的表现完全优于在AAPD数据集的表现,说明此模型对大规模数据标签的文本分类依然具有良好的性能。
传统的机器学习方法,如BR和CC 等,因为其不考虑标签的相关性,并且当前标签可能与序列的前一部分中的标签无关,从而在使用先前标签的输入来引入了噪声,导致分类器性能的降低,因此在部分数据集上的表现较差。
基于CNN 的深度学习网络模型,如TextCNN 和XML-CNN等,由于CNN固定窗口的缺点以及其池化操作导致语义的丢失,影响了它的分类器的性能。虽然XML-CNN模型对这一缺点有一定程度上的改进,但是由于根本上CNN 结构简单,因此在不同数据集的表现一般。
基于RNN 的深度学习网络模型,如SGM 等,对模型进一步改善,提高了分类器的性能,但其在预测标签时,基于序列的模型因为后一个标签往往依赖于前一个标签,所以前一个错误标签的影响往往是叠加的,导致分类器性能下降。基于RNN的模型虽然考虑了标签的相关性,但是模型的效果提升不明显。
基于Attention 的深度学习网络模型,如Attention XML 和LAA_SD 等,应用动态最大池化来学习文本表示,运用多层次Attention来捕捉特征,Attention XML使用双向长短时记忆(BiLSTM)网络从原始文本输入中提取嵌入,在模型的性能上提升的效果明显,但是因为不充分考虑局部或者全局的标签相关性,在一定程度上影响了模型性能。
基于Transformer的深度学习网络模型,如X-Transformer等,克服了文本的顺序处理的问题以及减少了捕获句子中单词之间关系的计算成本,从而提升了模型的性能,但是在实际的应用场景中,Transformer模型所需的模型参数往往较多,网络结构复杂,所以还是一定程度上影响了模型性能。
基于图神经网络的深度学习网络模型,如GNNXML 和LD-GGNN 等,挖掘文本内部的图结构,从网络数据推广到图数据,提取更多的局部特征,减少大量的计算资源,不断挖掘标签之间的相关性,提高了模型的性能,在不同的数据集上表现明显。
混合的深度学习网络模型,如tALBERT-CNN和RTransformer_BiLSTM 模型利用注意力机制考虑上下文信息,考虑标签之间的相关性,抽取出文本的关键信息,用于多标签文本分类,其分类器效果显著,但是分类效果依然有提升的空间。
近年来,其他研究模型在不同的数据集上的分类效果都有明显提高,但是在面对大规模标签数据集以及层次多标签数据集时的分类效果并不明显,未来研究需要进一步提升。
5 多标签文本分类研究方向
5.1 标签相关性
5.1.1 标签相关性的类型
在多标签问题中,标签不是独立的,而是存在一些相关性。标签相关性的使用有利于学习更有效和稳健的分类模型。在多标签文本分类问题中,某些标签的正样本很少,在这种情况下,使用标签相关性是极其重要的。充分利用标签相关性已成为目前多标签分类的主要研究方向之一,它是许多算法的重要组成部分[67-68]。现有的标签相关使用策略可以分为三种类型[69]:一阶、二阶和高阶。
(1)一阶算法
一阶算法如BR、ML-C4.5 和ML-kNN[23]。BR 为每个标签构建二进制分类方法,目的是学习相应的分类器hi:X→{0,1}。在学习过程中,输入是原始特征空间,而输出是标签yi的值。因此,不同的标签具有相同的输入,但具有不同的输出。ML-C4.5通过决策树将训练数据集逐层分成几个小子集,树根覆盖所有训练数据。对于非叶节点,应用信息熵和基尼指数等指标进一步将非叶节点划分为子节点,使得子节点数据的“纯度”高于父节点。ML-kNN是一种惰性学习方法。在预测时,MLkNN 模型根据预测数据在训练数据的最近邻中各标记的分布情况,采用最大化后验概率的原则决定测试样例是否与某一标记相关。但这些一阶算法完全忽略标签相关性。
(2)二阶算法
二阶算法如Rank-SVM[28]、CLR[22]、MLPP[70],CPNL[71]、PCT[72]和GBRAML[73]考虑了的标签相关性。Rank-SVM定义了在相关性-非相关性标签对中最大化距离的优化目标,并利用SVM 技术解决了多标签分类问题。CLR算法通过成对比较方法将常见的学习扩展到多标签文本分类中,引入一个人工校准标签,在每个实例中,将相关标签从不相关标签中分离出来。MLPP 通过每对标签对分类器进行训练,并通过投票结合各种分类器的预测结果来确定标签相关性的序列。CPNL 利用了标签的正负相关性,扩展了BR 算法。PCT 根据排序损失的定义,提出了一种标签两两比较变换方法,将每个原始的多标签样本转化为特征向量相同、标签向量不同的多个样本。GBRAML是一种基于颗粒批处理模式的多标签排序活动模型。从自下而上的角度来看,依次构造了三个造粒算子,以形成三个颗粒结构。在低级造粒算子中,引入辅助标签以增强每个标签的信息性和代表性。表4列举了标签相关性研究的一阶算法和二阶算法。
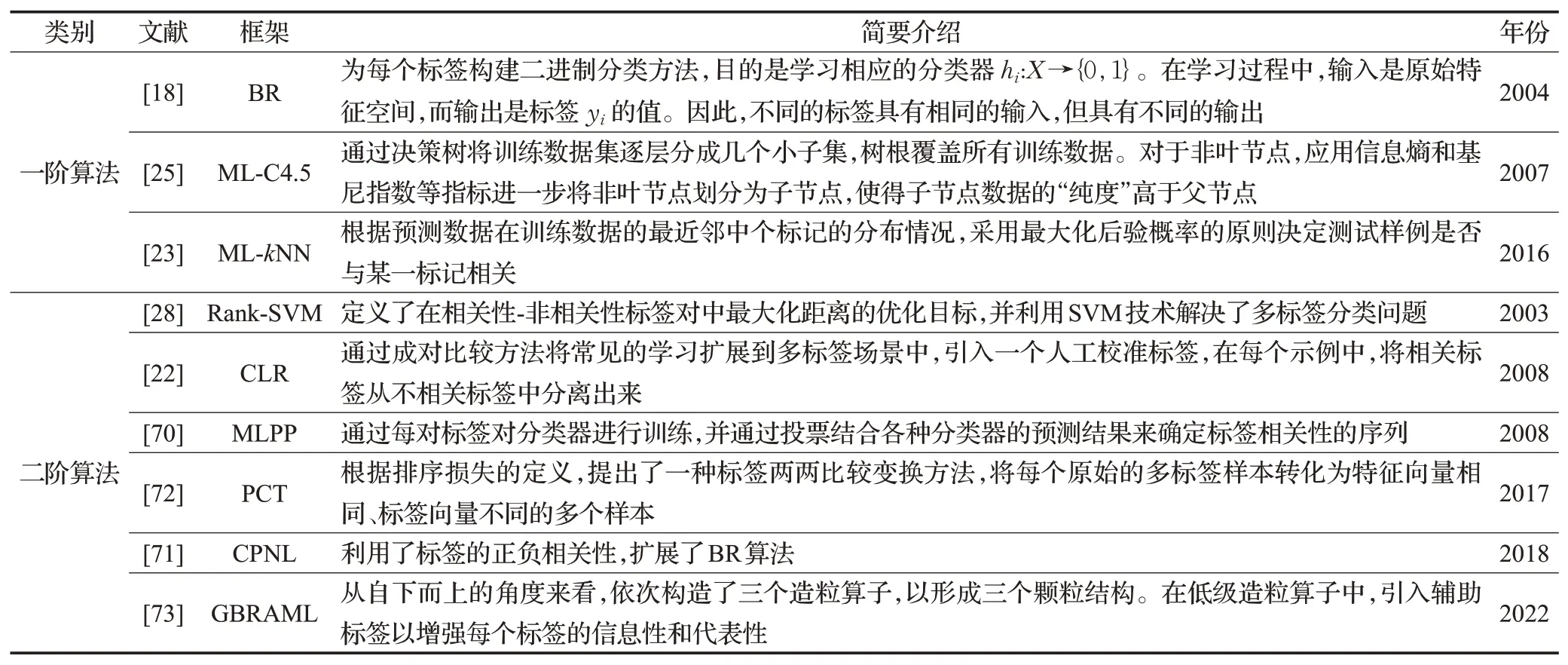
表4 一阶算法和二阶算法Table 4 First-order algorithms and second-order algorithms
(3)高阶算法
高阶算法如RAkEL[19]、CC[18]、BNCC[74]和MLMF[75]考虑几个或所有标签之间的相关性。作为一种集成学习方法,RAkEL 算法通过考虑一个小的标签随机子对于任何标签,序列前部的标签都会作为新特征添加到原始特征中,以这种方式利用了多个标签之间的关系。BNCC利用贝叶斯网络对标签相关性进行建模,用条件熵描述标签之间的依赖关系,以节点为标签,以边的权重为依赖关系,并引入了一种启发式算法来优化BN结构,通过对优化后的BN 节点进行拓扑排序,得到构建CC 模型的标签顺序。MLMF设计一个有效的多标签分类器,自动学习高阶非对称标签相关性,降低特征空间的维数,处理完整标签和缺失标签的情况。从关系提取或使用角度来看,高阶算法可以分为全局关系算法、局部关系算法和全局-局部组合关系算法。
①全局关系算法
全局关系算法认为标签相关性是全局的,换句话说,标签之间的相关性存在于所有训练数据中。全局关系算法如CC、MLLS[76]、ML-LPC[77]、CLSF[78]和A-GCN[79]。CC将所有标签放在一个随机序列中。先前标签的二进制分类器输出作为新特征添加到标签的原始特征空间中。MLLS 是一个通用的框架来提取多标签分类中的共享结构,在这个框架一个公共子空间被多个标签共享,从而阐明了它们的内在关系。ML-LPC学习标签之间的相关性同时训练多标签模型。采用低秩结构来捕获标签之间复杂的相关性,利用标签相关性得到不完整的标签矩阵。CLSF首先定义每个标签的基本要素和特征反映了内部特性和标签之间的联系。此外,还提供了计算单个标签的基本元素的过程,其次,通过考虑不同标签所确定的基本元素集合的重叠,描述了标签的相关性以及与标签集对应的相关性判断矩阵,因此,几个具有强关系的标签被分配到一个相关的标签组中,同时,可以计算局部和全局标签相关性。A-GCN使用标签图来学习带有单词嵌入的全局标签相关性。
②局部关系算法
在局部关系算法中,标签相关性存在于训练数据的一部分中。在这种情况下,标签的依赖关系仅存在于某些数据中。如果从全局角度提取或使用此类标签相关性,则将对所有实例施加不必要甚至误导的约束,这将降低分类模型的性能。这些局部考虑标签相关性的算法LPLC[80]。LPLC在局部考虑标签相关性,为所有训练实例找到每个标签的正负标签相关性。然后,对于每个测试实例,基于其k近邻的局部正负标签相关性,使用最大后验概率进行预测。Ma等人[81]提出了一个具有局部特征选择和局部标签相关性的新框架,在该框架中,假设实例可以聚到不同的组中,且特征选择权重和标签相关性只能由同一组中的实例共享。该框架包括一个特定于组的特征选择过程和一个特定于标签组选择过程。前者通过提取实例组-相关性将实例投射到不同的组中,后一个过程通过提取组-标签相关性,基于相关组为每个实例选择标签集,并学习一个单标签分类器来预测这个子集的幂集中的每个元素来构造集合的每个元素。CC 算法将标签随机放入一个序列中,为每个标签构建二进制分类器。
③全局-局部关系算法
全局-局部组合关系算法同时考虑全局和局部标签相关性,建立高效分类模型。例如,GLOCAL[82]通过流形正则化学习全局和局部标签相关性。GLkEL[83]通过近似联合互信息从标签空间中选择最相关的k标签集,以评估全局标签相关性。然后,它将训练数据聚类为不同的组,并评估每个组中的局部标签相关性。LFGLC[84]集成了全局和局部标签相关性,以提取每个标签的标签特定特征。Liu等人[85]在整个标签空间中计算一个全局标签相关矩阵,根据簇内标签的余弦相似度,为每个实例子集分配一个局部标签相关矩阵,基于标签相关性可以从原始类别空间转移到数值标签空间的假设,添加了全局和局部标签相关性正则化项,将重要性估计和模型训练整合到一个统一的框架中。表5 列举了标签相关性的高阶算法。
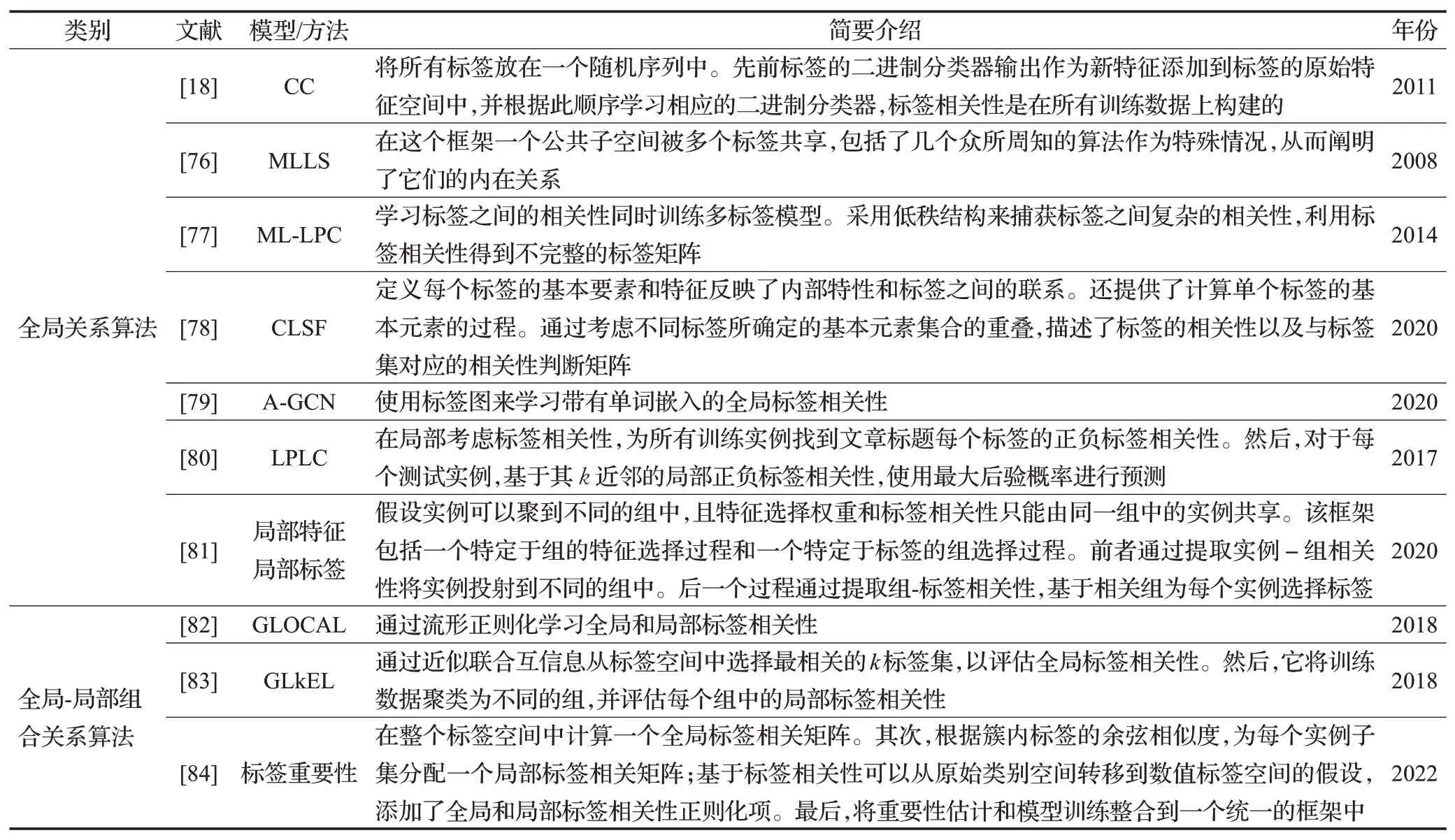
表5 高阶算法Table 5 High-order algorithms
5.1.2 标签相关性的研究
(1)基于标签相关性的特征压缩
为了消除冗余和不相关的特征,研究人员提出了许多方法来压缩多标签数据特征。这些方法中的许多方法通过使用标签相关性来选择特征或实现特征转换。在参考文献[86]中,提出过滤特征选择方法;最小冗余和最大相关性(mRMR);用互信息来衡量标签的重要性;通过多种权重策略估计特征和标签之间的关系。
(2)基于标签相关性的特征扩展
上述方法基于标签相关性对原始特征空间进行压缩。一些算法通过使用标签相关性来扩展特征,基于堆叠的BR算法[17],其中BR的第二层中二进制分类器从第一层中选择强相关的输出来扩展原始特征空间。在参考文献[87]中,提出了一种分类器链模型来处理多标签问题,主要创新在于它选择了一个有向无环图来对标签相关性进行建模,并通过条件熵来测量标签相关性,从而最大化了图中表示的所有标签之间的相关性之和;再根据这个有向无环图和预测扩展了原始特征空间,即将与原有标签相对应的二进制分类器的结果添加进去;最后,基于扩展特征训练二进制分类器。ML-LOC[88]也是一种基于标签相关性的特征扩展算法。
(3)基于标签相关性的标签嵌入
标签嵌入是一种重要的多标签分类算法,它可以联合提取所有标签的信息,从而获得更好的性能。Chen等人[89]提出了使用图卷积网络学习标签嵌入和标签之间的相关性,使用融合层将标签信息与文本的上下文语义信息结合起来。Wang等人[90]提出了一个新的基于跨视图的模型,具有多标签分类鉴别结构的鲁棒交叉视图嵌入(RCEDS)。该方法实现了一种鲁棒和鉴别嵌入,在RCEDS中,设计了一种新的超图融合技术,利用特征空间和标签空间之间的互补性,同时利用双边度量学习挖掘特征空间和标签空间的一致性。
5.2 特定标签特性
2014年,Zhang等人[91]提出了一种提升算法,首次提出了标签特定特征的概念。大多数现有的多标签方法通常使用相同的实例表达式来为不同的标签构建分类模型。换句话说,不同的标签在学习过程中使用相同的特征矩阵。尽管如此,提升算法认为标签应具有其唯一的表达式,因此,不同的标签应使用适当的特征表达。只有利用这些特征,才能进一步提高分类模型的效果,这些功能被称为“特定于标签的功能”。标签特定特征的概念与传统特征压缩的概念有明显的区别。在传统特征压缩的概念中,一般通过特征提取或特征选择向所有标签提供统一的特征表达。标签特定功能是指与特定标签相关的功能,而不是与所有标签相关的功能。
目前,构建标签特定特征的方法主要有两种:特征提取和特征选择。前者用LIFT表示[91],后者用LLSF表示[92]。表6列举了特定标签特性的研究。
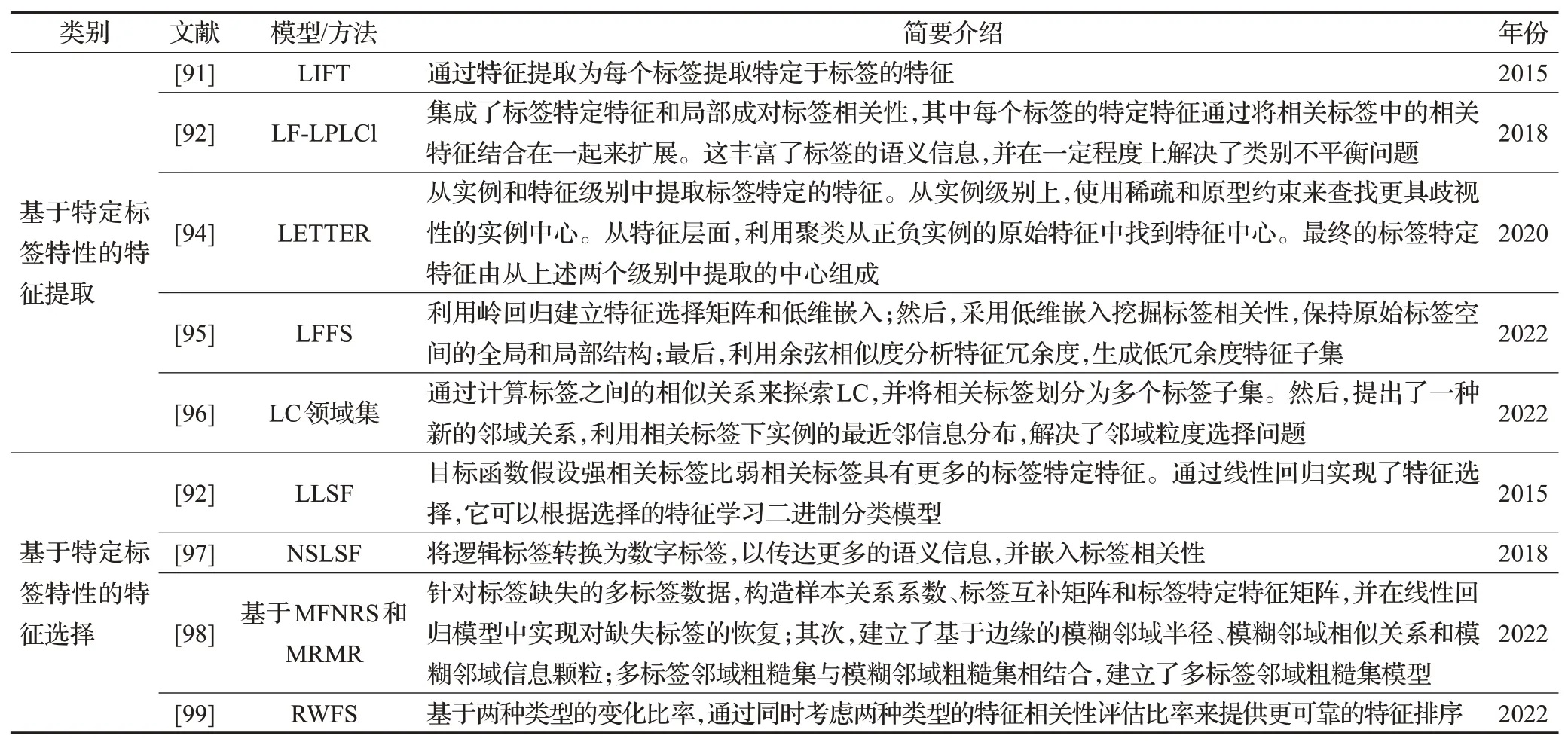
表6 特定标签特性Table 6 Features of lable-specific
5.2.1 基于特定标签特性的特征提取
LIFT通过特征提取为每个标签提取特定于标签的特征。具体来说,与任何标签相关的样本被视为正样本,而其余样品被视为负样本。k均值分别用于对正样本集和负样本集进行聚类,计算从样本到聚类中心的距离,这些距离形成了新的样本特征。接下来,在这些新的标签特定功能的空间上学习二进制分类器。对于不同的标签,正样本和负样本的分布是不同的,因此构建的标签特定特征彼此不同。在大量实验的基础上,证明其性能的非凡效果。此后,特定于标签的功能引起了学术界的广泛兴趣,并相继提出了一系列算法。
基于LIFT、LF-LPLCl[93]集成了标签特定特征和局部成对标签相关性,其中每个标签的特定特征通过将相关标签中的相关特征结合在一起来扩展,这丰富了标签的语义信息,并在一定程度上解决了类别不平衡问题。LETTER[94]从实例和特征级别中提取标签特定的特征。从实例层面,使用稀疏和原型约束来查找更具歧视性的实例中心;从特征层面,利用聚类从正负实例的原始特征中找到特征中心,最终的标签特定特征由从上述两个级别中提取的中心组成。Fan等人[95]提出了一种新的基于标签相关性和特征冗余度的LFFS方法。首先利用岭回归建立特征选择矩阵和低维嵌入;然后,采用低维嵌入挖掘标签相关性,保持原始标签空间的全局和局部结构;最后,利用余弦相似度分析特征冗余度,生成低冗余度特征子集。Wu 等人[96]引入了一个新的考虑LC 的领域集模型。首先,通过计算标签之间的相似关系来探索LC,并将相关标签划分为多个标签子集;然后,提出了一种新的邻域关系,利用相关标签下实例的最近邻信息分布,解决了邻域粒度选择问题。
5.2.2 基于特定标签特性的特征选择
上述算法均采用特征变换提取标签特有的特征,但是,Huang 等人[92]提出的LLSF 算法通过特征选择技术来学习标签特定的特征。LLSF假设每个标签仅与一些原始特征相关,并且它在具有约束的线性回归中表达了这种稀疏性,非零回归参数表示相应的特征是特定于标签的,而其他特征则不是。
LLSF的目标函数假设强相关标签比弱相关标签具有更多的标签特定特征。由于LLSF通过线性回归实现了特征选择,它可以根据选择的特征学习二进制分类模型。NSLSF[97]认为稀疏性假设在某些应用中不成立,提出了一种基于特征选择的方法来选择标签特定的特征。它将逻辑标签转换为数字标签,以传达更多的语义信息,并嵌入标签相关性。MCUL还利用系数矩阵上的范数正则化来学习稀疏标签特定特征,从而处理缺失和完全未观察到的标签。Sun等人[98]提出了一种基于多标签模糊邻域粗糙集(MFNRS)和最大相关最小冗余(MRMR)的特征选择方法,可用于缺少标签的多标签数据。首先,针对标签缺失的多标签数据,构造样本关系系数、标签互补矩阵和标签特定特征矩阵,并在线性回归模型中实现对缺失标签的恢复;其次,建立了基于边缘的模糊邻域半径、模糊邻域相似关系和模糊邻域信息颗粒;多标签邻域粗糙集与模糊邻域粗糙集相结合,建立了多标签邻域粗糙集模型。基于代数和信息视图,提出了基于模糊邻域熵的MFNRS 不确定度测度,改进了基于模糊邻域互信息的标签相关MRMR 模型,用于评价候选特征的性能。Hu等人[99]提出一个基于权重特征选择的方法(RWFS),基于两种类型的变化比率,通过同时考虑两种类型的特征相关性评估比率来提供更可靠的特征排序。
5.3 其他研究方向
5.3.1 类别不平衡
类别不平衡问题已成为许多标签数据集的固有特征,其中样本及其对应的标签在数据空间上分布不均匀。多标签文本分类中的不平衡问题给多标签数据分析带来了挑战,可以从三个角度来看:标签内部、标签之间和标签集之间的不平衡。
在传统的二元类和多类问题中也普遍存在类不平衡问题。因此,该问题解决思路可以为处理多标签不平衡问题提供一些启示。Zhang等人[100]提出了一种COCOA算法来解决多标签应用中的类不平衡问题。Charte 等人[101]提出了多标签不平衡度的几种复杂测量标准,同时Charte 等人还提出了用于多标签数据不平衡预处理的欠采样和过采样算法(LP-RUS 和LP-ROS)。Pereira 等人[102]提出MLTL,是一种类似的基于启发式的方法。该方法采用经典的Tomek Link 算法来解决不平衡问题,可以用作欠采样或清洗技术。MLSMOTE 算法[103]讨论了一种用于多标签学习得过采样技术,该技术与SMOTE使用了类似的策略。首先,MLSMOTE算法通过MeanIR和CVIR识别少数标签;然后,为这些标签合成新样本。另一个提出的方法是MLSOL[104]。该方法主要通过观察少数群体样本的局部特征来分析不平衡,而不是整个数据集的不平衡。在文献[105]中提出了一种适应方法来解决MLC 中的不平衡问题,它基于非对称阶段损失函数来动态调整正负样本的损失成本。Rastogi等人[106]通过构建标签权重矩阵来处理类不平衡问题,权重估计由标签出现、缺席和未观察的频率来指导,利用类不平衡敏感权值和辅助标签相关性,引入带有歧视性标签权值的加权平方损失函数,指导缺失标签补全。
总之,通过采样实现了多标签问题种类不平衡的常见直观处理,需要进一步研究如何在抽样中使用标签相关性。此外,通过集成学习和成本敏感性,可以尽可能消除类别不平衡的不利影响。
5.3.2 标签丢失
在许多实际应用中,由于以下两个主要原因,获得训练集中所有样本的所有真实相关标签是不切实际的[107-108]。一方面,许多应用程序包含许多需要大量标签类;另一方面,不同标签的含义可能会重叠,因此很难完全区分。因此,基于此类部分标签的数据的学习模型可能无法准确捕获标签相关性以及标签与特征之间的关系。Taha 等人[109]提出了基于聚合特征和标签图的缺失标签处理方法(GB-AS)和基于统一图的缺失标签传播方法(UG-MLP)。一方面,GB-AS算法根据基于特征的加权表示和基于标签的加权表示两种文档级别的相似度,获得初始标签矩阵。另一方面,引入UG-MLP 构造一个混合图,将GB-AS 和标签相关结合到一个单一的基础上,从不完整的训练数据中获取高阶标签相关性,并将其用于补充缺失的标签矩阵,指导多标签分类模型的建立。Ai 等人[110]提出了一种改进的MLTSVM(LSFML-MLTSVM),利用标签缺失的标签特定特征。LSFML-MLTSVM 首先通过半监督聚类分析提取标签特异性特征,然后获得样本的结构信息和边缘分布的几何信息。Sun 等人[111]提出了一种基于两阶段邻域的多标签分类方法,用于邻域决策系统中缺失标签的不完全数据分类。首先,为了解决人工选取邻域半径的问题,以及在邻域内平衡样本,定义了基于特征分布函数的邻域半径,分别通过可识别矩阵和不可识别矩阵计算样本间的异同,在此基础上,提出了一种缺失特征值的恢复方法;其次,考虑到特征间的非线性关系,基于高斯核函数研究了样本间基于邻域的模糊相似关系;在模糊相似关系矩阵、标签特定特征矩阵和标签相关矩阵的综合基础上,提出了基于回归模型的目标函数,给出了基于梯度下降策略的标签特定特征矩阵和标签相关矩阵的最优解,并在第二阶段提出了一种新的缺少标签的多标签分类方法;最后,设计了两阶段多标签分类算法。
5.3.3 标签压缩
由于许多实际的多标签问题中的标签数量可以达到数万个,因此许多研究已经将注意力转移到涉及大量标签的多标签分类上,过多的标签可能会给算法带来相当大的时间和空间成本。此外,许多成熟和常见的算法,如BR[14]和ECC[18]不适用于处理这些过多的标签。为了解决这个问题,研究人员提出了标签的空间尺寸压缩技术,将高维标签压缩到低维标签空间中,并在低维标签空间中训练分类模型以减少计算负担。当然,低维标签空间中的预测结果必须恢复到原始特征空间中。根据现有研究,标签压缩不仅可以缩短算法的运行时间,而且可以提高分类效果。Cao等人[112]提出了一种新的标签压缩编码方法,同时考虑特征和标签信息。基于标签变换的标签压缩算法具有理论基础强、易于实现等优点。但是,转换后的标签缺乏原始标签的含义,因此它们很难相互连接。基于标签子集的标签压缩算法经常使用群稀疏学习、随机抽样、布尔矩阵分解等。这些算法可以获取低维标签,或者标签直接来自原始标签,或者可以完全恢复原始特征空间。Yu等人[113]介绍了一种PML 方法(PML-LCom),使用标签压缩来有效地从部分多标签数据中学习。PML-LCom 首先将观察到的标签数据矩阵分解为潜在的相关标签矩阵和不相关的标签矩阵,然后将相关的标签矩阵分解为两个低秩矩阵,一个对样本的压缩标签进行编码,另一个对潜在的标签相关性进行探究;然后,对压缩后的标签矩阵对多标签预测器的系数矩阵进行优化。Yang等人[114]提出一种多同步压缩变换方法(MSST),对处理后的数据进行变换。在同步压缩变换的基础上,采用迭代重分布代替原始数据,完成模式识别。此外,针对样本的特征相似度,对压缩后的标签矩阵进行正则化,并对标签矩阵和预测器进行了一致性优化。因此,标签压缩算法具有很强的解释力。表7 列举了其他研究方向上的部分模型分析。
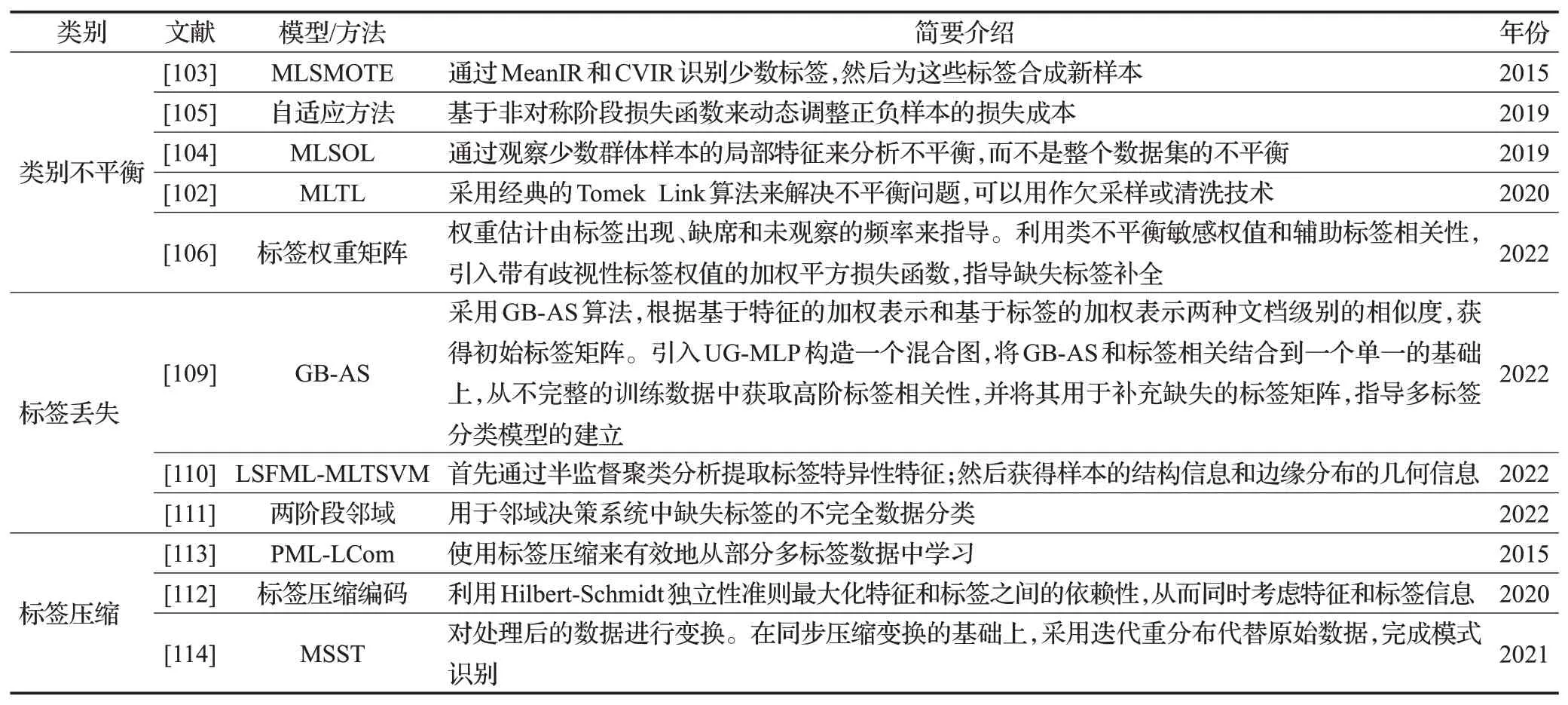
表7 其他研究方向Table 7 Other research directions
6 总结与展望
多标签文本分类的研究随着深度学习的到来取得了丰硕的成果,尤其是在BERT 的到来之后,大大提高了相关研究的准确性。尽管该领域已经有相当成熟和实用的技术,但仍有一些棘手的问题值得研究人员共同探索:
缺乏数据集和低质量数据集问题。多标签文本分类比单标签文本分类要复杂得多,因此数据集资源的缺乏极大地限制了研究人员对模型的开发,并且特定领域如医疗、法律、金融和建筑的数据集十分匮乏;其次,由于该领域的当前数据集普遍存在数据分布不均匀的问题,因此主要表现为长尾问题,即同一数据集中的大多数文档仅与一个或极少数的标签相关。因此,创建更多高质量的数据集是一个值得长期讨论的问题。
文本相关标签的动态划分问题。目前,多标签文本分类主要依靠监督学习,标签发生变化,就需要对模型进行重新训练,适应变化,但重新标记数据集或训练模型都需要很高的成本。因此,如何低成本、快速地使训练好的模型适应标签的变化是一个值得考虑的问题。
极端多标签文本分类问题。极端多标签文本分类(XMC)目的是从一个极大的标签集合中为给定的文本找到相关的标签。XMC的主要难点是文本标签的数目非常多。目前提出模型的内存占用随着标签空间的变大而变大。因此,如何减小极端多标签文本分类模型的大小是未来主要研究方向之一。
层级多标签文本分类问题。许多现实世界的文本分类任务通常处理以层次结构或分类法组织的大量紧密相关的类别。当需要处理大量紧密相关的类别时,层级多标签文本分类(HMTC)变得非常具有挑战性。层次标签概念:一级标签包含二级标签,二级标签包含三级标签。HTMC 的难点在于考虑垂直类别相关性的平面多标签以及同一级别类别之间的水平相关性;充分地建模层级依赖关系,提高各层级标签,尤其是下层长尾标签的预测性能,此外,整个层次结构中所有类别的结构特征及其类别标签的单词语义对于提高大量紧密相关类别的文本分类准确性非常有帮助。因此,如何设计这样一个模型去解决这些问题是未来亟待解决的一个难点。
小样本多标签文本分类也是当前和未来研究热点,在实际的应用场景中,得到文本数据可能会面临分类类别多、样本数据小和文本短等问题。小样本数据集的构建,也更利于模型可以应用于不同的领域。
7 结语
本文对近年来多标签文本分类概念、流程、方法和研究方向的文献进行了综述。将多标签文本分类方法分为传统机器学习方法和深度学习方法;研究方向划分为标签相关性、特定标签特性、类别不平衡、标签丢失和标签压缩;最后对多标签文本分类的挑战和未来方向进行了讨论。
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电测与仪表(2014年15期)2014-04-04
