
基于深度学习的目标检测算法研究与应用综述
2023-09-25 08:54张阳婷黄德启王东伟贺佳佳
计算机工程与应用 2023年18期
张阳婷,黄德启,王东伟,贺佳佳
新疆大学电气工程学院,乌鲁木齐830017
近年来,基于深度学习的目标检测算法在计算机视觉领域取得了长足的发展,与传统的计算机视觉技术相比,这些模型表现出卓越的性能,展示了深度学习技术的潜力。目标检测在于定位和分类物体,并识别物体类别。作为计算机视觉领域中的重要研究方向,目标检测发挥着关键作用,在人脸检测[1]、行人检测[2]、视频检测[3]、车辆检测[4]等领域都有着广泛的应用。
在计算机视觉领域,目标检测可以分为传统目标检测和基于深度学习的目标检测两类。传统目标检测的算法主要有DP(deformable parts model)[5]、Selective Search(SIFT+SVM)[6]、Oxford-MKL(HOG+Cascade SVM)[7]、NLPR-HOGLBP(LBP/HOG+Latent SVM/Boosting)[8]等。
但随着技术及数据的发展,传统的检测算法明显无法满足人们的应用需求。传统特征虽然在某些方面可以帮助深度学习模型精度的提高,但对于传统检测算法来说,仍然存在一定的局限性。第一,大多采用滑动窗口算法,其计算时间效率低下,为多流程的步骤处理,处理复杂且准确度低。第二,特征设计与选择极大程度上依赖于人工,其准确度、客观性、鲁棒性与泛化性都受到了一定的制约。
随着深度学习的发展,基于深度学习的目标检测技术成为计算机视觉邻域研究的焦点。相较于传统算法,它能够充分学习到图像的特征,性能大幅提升。2012年,Krizhevsky等人[9]提出AlexNet网络,是第一个现代深度卷积网络的技术算法,引起了DCNN的研究热潮。2014年,Girshick等人[10]提出一种基于卷积神经网(convolutional neural network,CNN)的RCNN 网络,该网络是目标检测领域的一个里程碑。2015 年,Redmon 等人[11]提出一种基于单个神经网络的目标检测系统YOLO(you only look once:unified,real-time object detection),目标检测技术有了新的发展。随着研究人员深入探索,基于DCNN的目标检测算法突破了传统算法的局限,使得目标检测进入新的时期。
随着目标检测的快速发展,为满足不同复杂应用场景的需求,提高检测精度的同时,也需要优化检测速度以支持实时应用。因此,在追求更优检测结果的同时,准确性与速度两者同样重要。文章的主要内容如下:(1)综述了深度卷积神经网络(DCNN)的发展,对目前主流的两阶段目标检测算法架构和单阶段目标检测算法架构的发展及优缺点进行归纳。(2)对近些年来用于目标检测的主干网络进行了分析,并比较了相关主干网络的性能和参数。(3)总结了关于目标检测的数据集以及评价指标,对比了经典算法的检测精度,总结经典目标检测算法的改进策略。(4)对目标检测的应用进行总结,对其中使用的技术进行了详细的分析。
1 目标检测的体系结构
目标检测任务主要是找到图像中的目标位置并对其进行分类。基于深度学习的目标检测算法代替传统的手动选取特征,主要可以分为Two-stage 目标检测和One-stage 目标检测。Two-stage 目标检测算法先进行区域生成,该区域称为region proposal,再通过卷积神经网络进行样本分类。常见Two-stage 目标检测算法有:R-CNN[10]、Mask R-CNN[12]、SPPNet[13]、Fast R-CNN[14]和Faster R-CNN[15]等。One-stage 目标检测架构,通过DCNN直接进行定位和分类,单阶段目标检测可以在一个阶段中可以直接生成目标的类别概率和位置的坐标,不需要生成候选区域过程。常见One-stage目标检测算法有YOLO系列[11]、SSD[16]、DSSD[17]和FSSD[18]。
1.1 双阶段目标检测架构
R-CNN:R-CNN(regions with CNN features)使用了DCNN 作为特征提取骨干网络,模型结构如图1 所示,但对每个候选区域特征的单独提取没有利用DCNN的特征共享能力,造成了大量计算资源的浪费,并且会消耗大量的存储空间。王子琦等人[19]提出的改进R-CNN算法,具有更好的泛化能力。
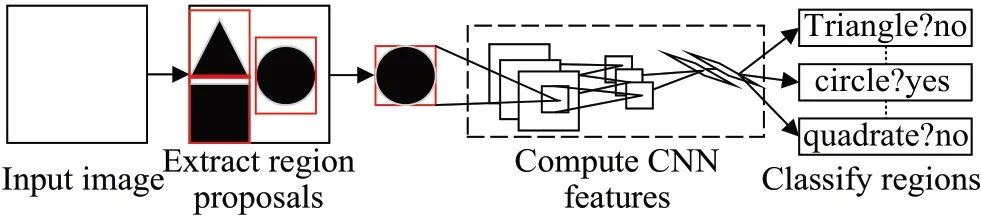
图1 R-CNN模型结构Fig.1 R-CNN model structure
SPPNet:它可以任意尺寸输入,固定大小输出,可对任意尺寸提取的特征进行池化。如图2 所示,SPP 层通常被放置在最后一层卷积之后,避免重复计算需要特征图池化的部分,从而减少计算量,但SPPNet没有实现端到端训练,减少了准确性。
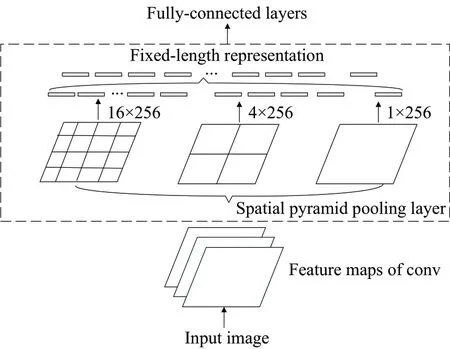
图2 SPPNet模型结构Fig.2 SPPNet model structure
Fast R-CNN:Fast R-CNN是在R-CNN算法的基础上进行了改进,与R-CNN/SPPNet 相比,减少了存储空间的占用,具有更高的准确性,但耗时较长,无法满足实时应用。
Faster R-CNN:Faster R-CNN 中提出了候选区域网络(RPN),以取代选择性搜索算法来生成候选区域,它在精度和速度上都有很大的提高,结构模型如图3所示。
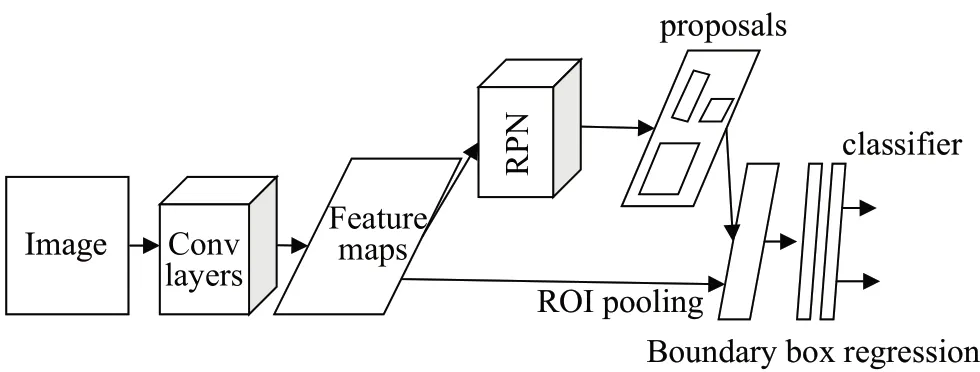
图3 Faster R-CNN模型结构Fig.3 Faster R-CNN model structure
但需要大量的样本和计算资源,在实时应用场景下速度还不够快。赵珊等人[19]提出通道分离双注意力机制的目标检测算法,通过改进Faster+FPN主干网络来提高小目标的检测精度,具有较好的应用性。
Mask R-CNN:Mask R-CNN是由Faster R-CNN和语义分割算法FCN 组成,进行目标分类和边界框回归并行的RoI预测分割,同时完成目标检测和实例分割。
其中的RoIAlign 层使用了双线性插值来实现像素级对齐,解决两次量化导致的特征像素丢失和偏差,性能优于Faster R-CNN。林娜等人[21]提出一种基于优化Mask-RCNN 的提取算法,对高精度遥感图像的提取具有实际的意义。
Sparse R-CNN:Sparse R-CNN[22]利用了点云(point cloud)和对称卷积(symmetric convolution)两种新型神经网络结构,在减少运算量与参数数量的同时达到更好的精度表现。在保持准确性的同时还大大降低了计算成本,具有很高的实用价值两阶段的目标检测算法相较于传统算法,性能大幅提升,表1总结了Two-stage目标检测算法优势以及局限。
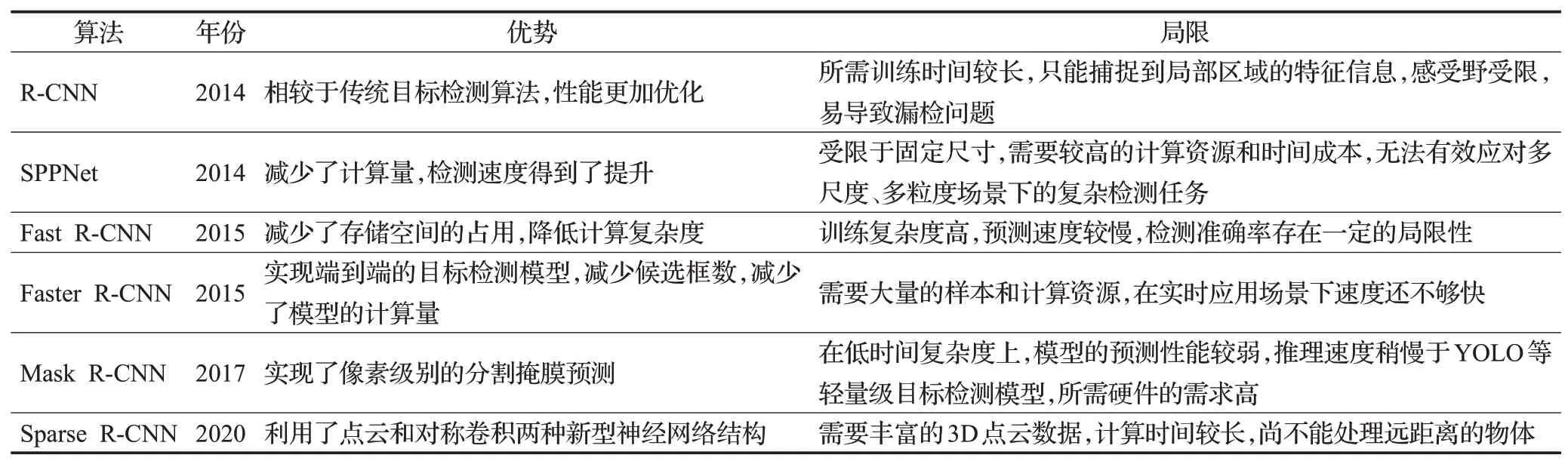
表1 Two-stage目标检测算法总体分析Table 1 Overall analysis of Two-stage target detection algorithm
从表1 可以看出Two-stage 目标检测算法的优点(1)准确性高。能够准确地检测出目标物体,并且对于小目标检测效果也比较好。(2)可扩展性强。可以通过改变网络架构和调整参数等方式来适应不同的应用场景和数据集。(3)稳定性好。在噪声和遮挡等情况下的表现相对稳定。缺点(1)速度慢。需先生成候选框再进行后续处理,检测速度较慢。(2)复杂度高。由于需要进行多次卷积、池化等操作,部署和使用都会带来一定的困难。(3)特征重复计算。候选框的生成和后续处理是分开进行的,导致重复计算。
因此,在进行Two-stage 目标检测算法时需要在保证模型准确性的前提下来考虑如何优化模型结构和模型参数的设置,使得算法既可以获得较高的检测精度,又可以满足实际应用场景下的实时性要求。未来的发展趋势将会朝向更深、更高效的方向发展,以提高模型的准确性和速度。
1.2 单阶段目标检测架构
OverFeat:Sermanet等人[23]改进AlexNet提出OverFeat算法,它利用DCNN的特征共享将目标分类和目标定位集成到一个网络架构中。OverFeat在速度上快于RCNN,但精度较低。
YOLO:YOLO算法是一种端到端的神经网络,YOLO是一种基于全局图像信息进行目标预测的算法。其模型结构如图4 所示,相较于R-CNN 算法,YOLO 采用统一框架,在速度上更具优势。但它的网格单元只能预测两个边界框并且只能属于同一类,因此YOLO不适用于密集的小目标。
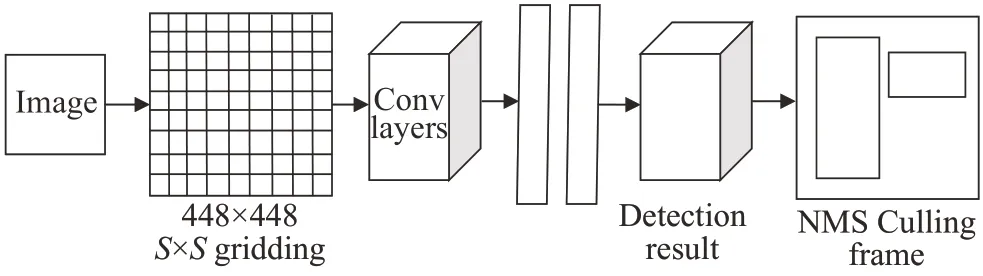
图4 YOLO模型结构Fig.4 YOLO model structure
SSD:SSD(single shot MultiBox detector)是一种基于单阶段目标检测的方法,可以实现快速、高效、准确的物体检测。RCNN 算法和YOLO 算法在速度和准确性方面有不同的优缺点。RCNN 系列具有较高的检测精度,但检测的速度较慢。YOLO 虽然检测速度快,但是在对小目标的检测效果较差。陈欣等人[24]提出了一种改进型多尺度特征融合SSD方法,能够降低小目标的漏检率。为了提高SSD 表达低层次特征图的能力,DSSD使用ResNet101作为骨干网络,超越了以前的SSD框架。同样,FSSD 将低层次的特征融合到基于SSD 的高层次特征中,旨在短时间内提供多样性模式集,减少了运行时间。
YOLOv2:YOLOv2[24]对YOLOv1进行了改进,让精度得到了提高。加入BN 层之后,能够更好地对小目标的物体进行检测,并且借鉴Faster R-CNN 的做法,YOLOv2 移除了YOLOv1 中的全连接层而采用了卷积核anchor boxes来预测边界框,提高了检测的精度。
YOLOv3:YOLOv3[26]改进了前期YOLO 算法的不足,改良了网络的主干,利用多尺度特征图进行目标检测,采用单独的神经网络对图像进行处理,将图像分割成多个区域,并预测每个区域的概率和边界框信息,从而实现了目标检测的全局感知和局部精度结合,取得了良好的检测结果。
YOLOv4:该算法由Alexey Bochkovskiy、Chien-Yao Wang 和Hong-Yuan Mark Liao 共同开发,并于2020 年发布,采用了一系列的优化策略,如快速测试、跨层连接和卷积操作等,使得其在保持高精度的同时可以实现更快的检测速度。
YOLOv5:2020年6月,Jocher等人提出YOLOv5[27]。在输入端方面,采用了自适应锚框计算和自适应图片放缩技术,以获取合适的锚框并减少模型计算量,并提高整个目标检测算法的性能表现和效果质量。张艳等人[28]提出基于金字塔分割注意力与线性变换的轻量化目标检测算法PG-YOLOv5,提高了检测的精度,更易部署。
YOLOv7:YOLOv7[28]目标检测算法作为YOLO 系列的最新成果,相较于以往模型具有更高的检测精度和更快的检测速度。并且针对不同目标检测任务,具有YOLOv7-w6、YOLOv7-d6等7种大小不同的模型,具有更强的适应性,可以应用在不同的工作环境。
表2总结One-stage目标检测算法改进方式、优势以及局限。从表2 可以看出,从算法性能来说,单阶段目标检测算法的优点(1)速度快。不需要生成候选框,直接在特征图上进行处理,检测速度较快。(2)简单高效。不需要多次卷积、池化等操作,模型较简单,部署和使用都比较容易。(3)对小目标检测效果好。采用密集检测的方式,对于小目标检测效果较好。缺点(1)准确性稍逊:相对于两阶段目标检测,单阶段目标检测的准确性稍逊,对于小目标、遮挡严重、光照暗淡等情况下的检测效果更为有限。(2)容易过拟合。由于可能存在大量背景样本,容易出现过拟合现象。
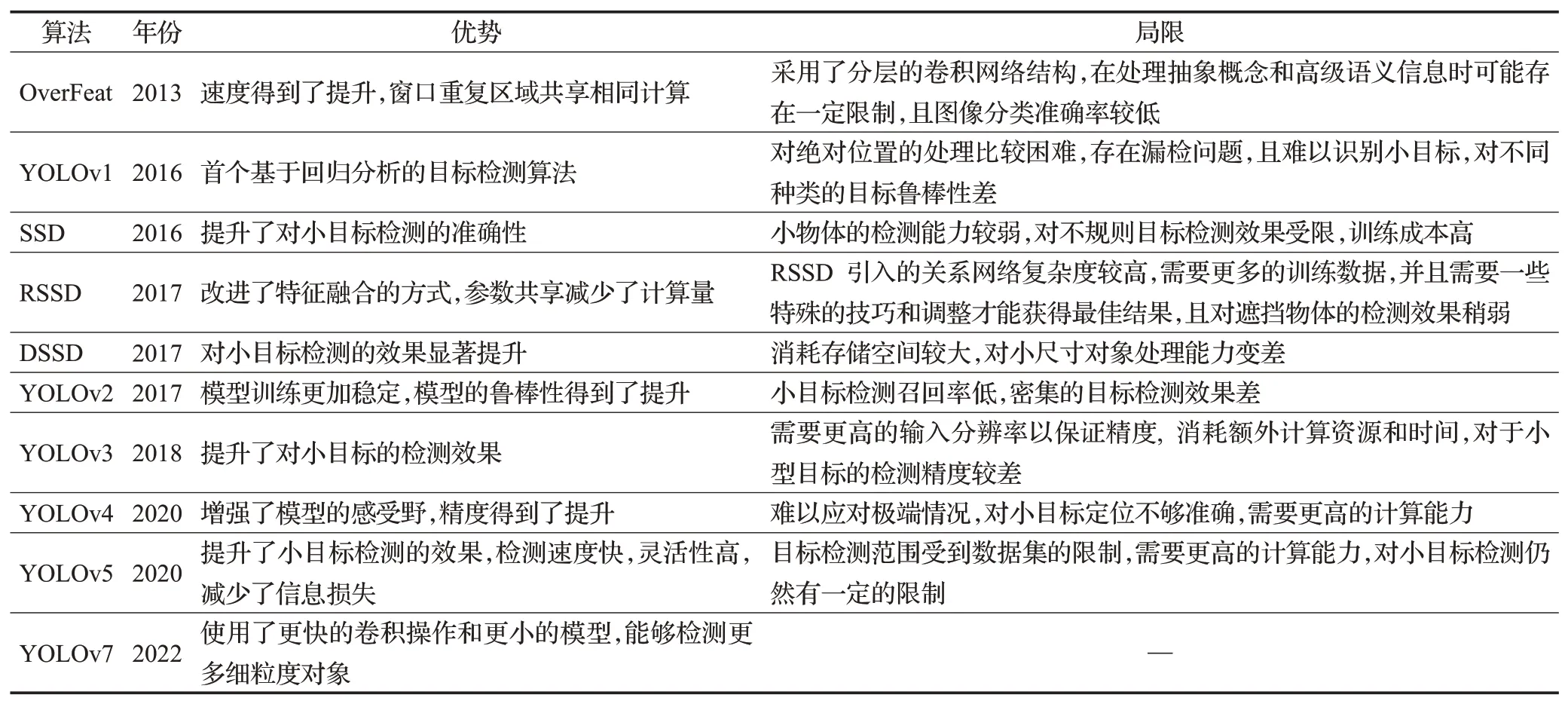
表2 One-stage目标检测算法总体分析Table 2 Overall analysis of One-stage target detection algorithm
随着深度学习技术的进步,许多单阶段目标检测算法的性能已经接近或超过两阶段模型,因此在准确性方面具有一定优势。但较于两阶段算法,其检测精度还有提升空间,对于小目标和密集目标的检测效果可能不如两阶段算法,因此,在应用单阶段目标检测模型时,需要根据具体应用场景和需求选择合适的算法,并对其进行适当的调整和优化。
2 骨干网络
作为目标检测任务的基本组成部分,骨干网络主要负责将图像输入转换为对应的特征图输出,并对输入图像进行特征提取和表示,如表3 所示,总结比较了复杂骨干网络和轻量级骨干网络,在表3 中TOP5 精度则是指预测结果在前5 名中与标签相同的标检测的骨干网络,主干网络的TOP1 精度指的是在分类任务中,预测结果与标签完全相同的比例;而复杂骨干网(complex backbone network,CBN)的精度,在不影响轻量级骨干网络(lightweight backbone network,LBN)准确性的前提下,以合适的方式减少参数。
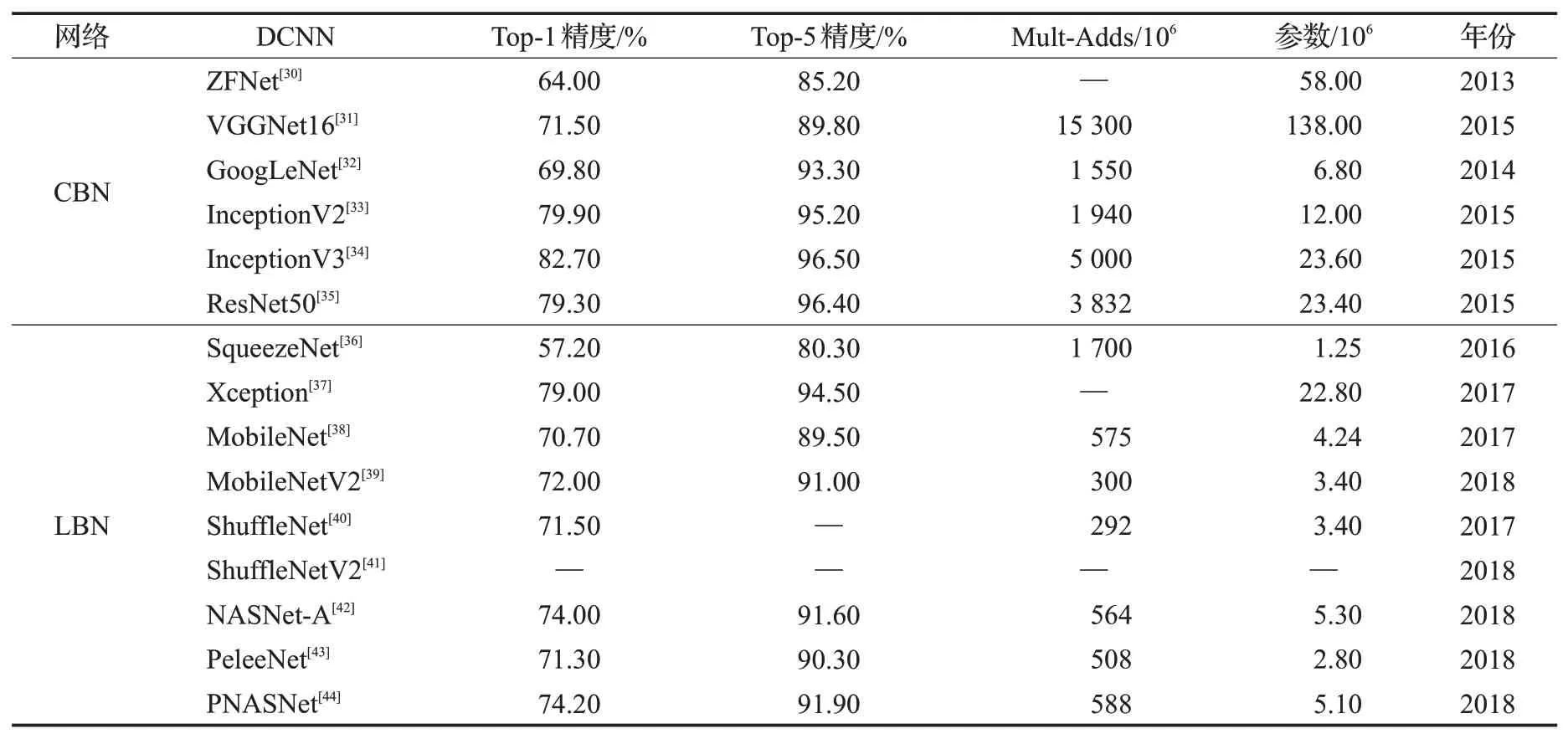
表3 复杂骨干网络(CBN)与轻量级骨干网络(LBN)的比较Table 3 Comparison of complex backbone network(CBN)and lightweight backbone network(LBN)
2.1 复杂的骨干网络
ZFNet:ZFNet 使用非池化层和去卷积层来可视化特征图方法。ZFNet 主要采用更小的卷积核来增加深度,并利用重叠池化技术来充分利用每个像素信息。相对后续提出深度卷积神经网络,如VGG、ResNet等,ZFNet网络结构较浅,可能会限制它在更复杂任务上的表现。
VGGNet:VGGNet具有非常深的网络结构,并且通过大量的卷积层和池化层来提取图像特征。但同时也使用参数多,耗费了更多的计算机资源,导致占用的内存较多。刘猛等人[45]提出了基于迭代剪枝VGGNet 的方法,与轻量级的骨干网络相比,具有较好的性能。
Inception:Inception 使用密集的并行卷积层和池化操作来提取输入图像的高层次特征,并使用多个分支来处理不同尺度的信息。它通过分解卷积操作从而减少参数数量和计算量,同时保证了实现更深层次的网络结构。Inceptionv2中采用了更高效的网络拓扑结构,提高了模型的性能和稳定性。Inceptionv3 则在Inceptionv2的基础上进一步优化了模型,加入了inception-residual模块,以增大模型可训练深度。Inceptionv3相比Inceptionv2具有更高的精度和更好的鲁棒性,但也因此在计算和存储上需要更多的资源。两个模型都在实际应用中得到了广泛的应用。
ResNet:ResNet 是一个残差学习模块,可以加深网络的深度,增强了网络的特征表示能力。与其他网络结构相比,ResNet 有非常深的网络层数,被广泛应用于各种计算机视觉任务中。
复杂骨干网络常用于目标检测、图像分类与分割,这些网络可以提取高级语义特征,帮助识别和定位图像中的目标物。这些网络可以学习人脸图像中的特征表示,用于识别和验证人脸身份。同时,复杂骨干网络在医学图像分析领域具有重要应用潜力。它们可用于医学图像的病变检测、分割和分类,帮助医生进行疾病诊断和治疗决策。复杂骨干网络部署需要综合考虑硬件资源、网络结构、模型优化和部署框架等因素。
2.2 轻量级骨干网络
骨干网络的结构复杂,参数众多,因此需要更多的计算资源以及更长的训练时间来达到较好的效果。而轻量级骨干网络可以有效地缩短模型训练和推理所需的时间,从而提高实际应用的效率和响应速度。此外,在一些需要快速响应和实时决策的场景下,使用轻量级骨干网络也能够减少传输和处理延迟,提高用户体验和数据隐私性。
SqueezeNet:SqueezeNet 的主要设计目标是在保持较高准确率的前提下,大幅压缩模型大小和计算复杂度。SqueezeNet 中提出了新的网络架构,称为Fire Module,进行特征提取与分类,其引入的Fire模块用来增加神经元数量、提取更强特征,但同时也增加了网络的计算量。王文秀等人[46]提出了一种基于改进SqueezeNet 的检测算法,使模型更加轻量化。
Xception:Xception 的全称是Extreme Inception,它基于Inception架构,通过采用深度可分离卷积替代标准卷积,可以显著减少卷积层的参数量,降低了计算复杂度和过拟合的风险,同时准确率也有所提高。黄英来等人[47]提出了一种改进Xception 网络模型的图像分类方法,有较高的准确性,但对于小数据集而言,可能会出现过拟合问题。
MobileNet:MobileNet使用深度可分离卷积(depthwise separable convolution)架构,减少了需要学习的参数数量和计算复杂度。王志强等人[48]提出MCA-MobileNet模型,具有很高的计算效率和较小的模型。在移动设备等资源受限的场景下实现高效的图像分类和目标检测任务。MobileNetV2 针对MobileNet 存在的一些问题进行了改进,使用的反向残差神经单元结构使得它在同样精度下拥有更小的模型体积,并且其计算效率也相对更高。
ShuffleNet:ShuffleNet使用了轻量化的组卷积(group convolution)和通道混洗(channel shuffle)技术,可以在几乎不损失准确率的情况下大幅减少模型大小和计算资源,并且相对于MobileNet 等其他轻量级卷积神经网络表现更优。ShuffleNetV2在精度、速度和模型大小等指标上均优于ShuffleNet,提供了更多的可配置参数,如层间通道数比例、非线性激活函数选取等,在实际使用中可以进行更微调的优化。
PeleeNet:PeleeNet 是一种轻量级卷积神经网络模型。采用密集连接思想和逐层缩减的方法设计,紧密地连接预处理、特征提取和分类输出而不牺牲准确度。PeleeNet的参数量较小,适合在资源受限的环境下进行嵌入式或移动图像分类任务。刘星等人[49]提出了一种PeleeNet与YOLOv3相结合的目标检测算法,具有较小的运算量和参数量。但相对于一些较新的深度学习网络,PeleeNet在处理更大且更复杂的任务时精度可能会有所降低。
轻量级骨干网络广泛应用于移动设备上的计算机视觉任务,如智能手机、平板电脑和嵌入式系统等。由于轻量级骨干网络具有较低的计算复杂度和模型大小,因此在需要实时响应的应用中得到广泛应用,例如视频监控、自动驾驶和增强现实等。轻量级模型可以根据特定场景的需求进行优化和定制化。在针对人脸检测、车辆检测或工业场景中的物体检测等特定任务中,可以通过设计轻量级模型,提高检测的精度和效率。
3 数据集与评价指标
3.1 数据集
数据集通常包含多张图片和每张图片上对应的目标物体的位置、类别等信息。目标检测数据集的构建需要大量的人工标注和筛选,例如MNIST[47]、CIFAR-10[51]、ImageNet[52]、Open Images[53]、MS COCO[54]、Pascal VOC[55]、Tiny Images[56]、DOTA[57]、WIDER Face[58]、KITTI Vision Benchmark Suite[59]和MVTec AD[60]等数据集。这些数据集中涵盖了各种不同的物体类别、尺度、姿态、光照等变化,以及复杂的背景干扰和遮挡情况,具有较高的多样性和代表性。这些数据集的广泛应用推动了计算机视觉领域中的算法开发和技术进步,在促进图像识别、目标检测、图像分割等方面取得了重要成果,可以广泛地验证和优化目标检测算法的效果。
ImageNet 是一个用于视觉对象识别软件研究的大型可视化数据库。用于评估算法性能的广泛而多样的图像数据集,被认为是深度学习革命的开始。复杂的数据集可以推动实际应用和计算机视觉任务。它使用了WordNet架构的变体来对对象进行分类,是一个巨大的视觉训练图片库。
MS COCO 数据集是微软公司提供的一个大型图像理解数据集,其中包括了各种类型的物体和场景,并且图像注释非常详细。图像中包含了各种复杂的场景和拥有不同颜色、形状、大小等属性的物体。每张图像都标注了物体位置、类别、数量,以及与该物体有关联的语义信息。被广泛应用于图像识别、目标检测、图像生成等多个任务的研究中。
PASCAL VOC 数据集是经典的图像识别数据集。PASCAL VOC 在学术界广泛使用,因为其提供了公开和标准的基准测试数据和评估协议,可以帮助研究者更好地比较算法的性能。相比其他大型数据集如ImageNet和COCO,PASCAL VOC的数据量相对较小,适合小规模模型训练和快速原型开发。
DOTA(detection in aerial images)数据集是一个广泛用于航空图像目标检测的大规模数据集。它由中国科学技术大学所创建,具有多样的标注信息,这些图像覆盖了188个不同地区的遥感场景,包括城市、农田、港口、森林等各种环境。包含15个常见的目标类别,如飞机、船只、车辆、建筑物等。每个目标类别都有不同的形状和尺寸,从小型车辆到大型建筑物,覆盖了各种实际场景中的目标。为研究人员提供了一个丰富和多样的航空图像目标检测资源。
WIDER Face数据集应用于人脸检测,它来自于不同的环境,包括户外、户内、大规模人群、极端天气等。其人脸实例具有不同的尺度、姿态、表情和遮挡情况。这些人脸特征增加了数据集的难度,要求算法具有较强的鲁棒性和泛化能力。其大规模和多样性成为人脸检测算法研究的重要基准。
KITTI Vision Benchmark Suite数据集是一个广泛用于自动驾驶和计算机视觉任务的综合数据集。该数据集基于真实世界的道路场景,涵盖了不同的天气条件下城市和乡村道路的交通情况。数据集提供了丰富的标注信息,包括车辆、行人、自行车等物体的边界框标注,道路标记、语义分割等信息。这些标注信息可用于算法训练和性能评估。
MVTec AD 数据集针对工业质量控制应用中的缺陷检测任务。每个产品类别都包含正常样本和带有各种常见和罕见缺陷的异常样本。数据集的图像是在实际工业生产环境中拍摄的,具有真实的光照条件和复杂的背景。这使得数据集更贴近实际应用场景,并具有挑战性。
表4和表5 分别总结了One-stage 和Two-stage 检测算法发表时所用的主干网络、检测速率、检测时的GPU型号,以及在VOC2007 数据集、VOC2012 数据集和COCO 数据集上的检测精度。“—”表示无相关数据,mAP值中的括号表示以其作为训练集。
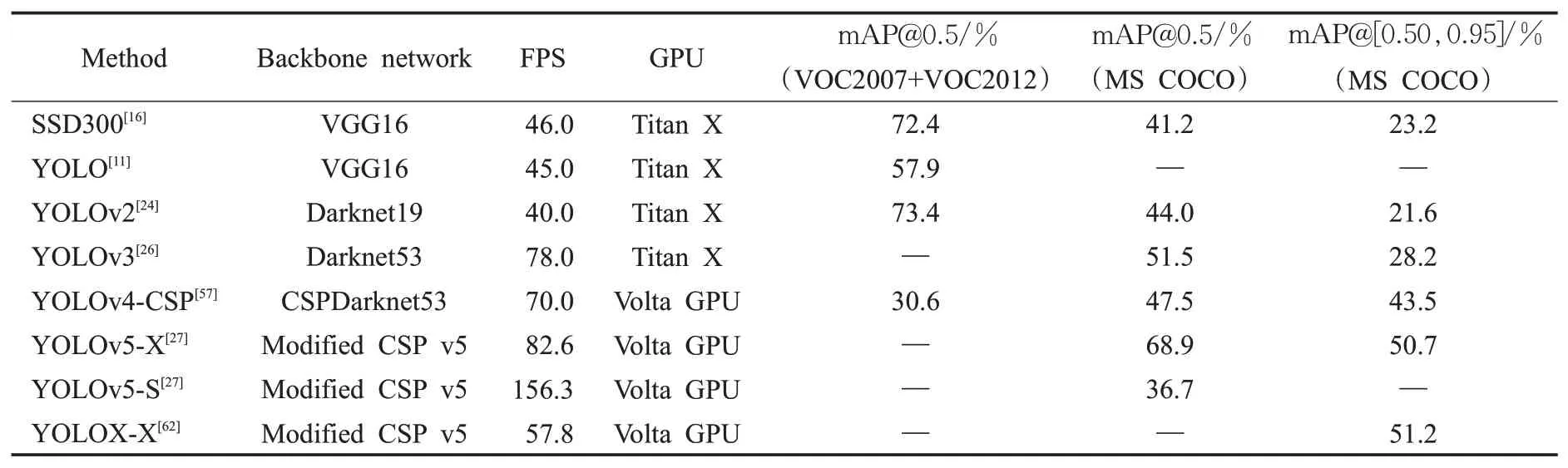
表4 One-stage目标检测算法性能对比Table 4 One-stage target detection algorithm performance comparison

表5 Two-stage目标检测算法性能对比Table 5 Two-stage target detection algorithm performance comparison
从表4 和表5 可以得知,One-stage 目标检测算法在同一系列算法中,其检测精度不断提高,甚至超过了Two-stage 目标检测算法的精度。另外,在相同的算法架构下,主干网络模型越深,输入图片尺寸越大,检测精度也越高;但是在相同的GPU环境下,检测速度会变慢。
3.2 评价指标
评价指标是评价目标检测算法方法好坏的重要依据。当前,主要的性能评价标准有IoU(intersection over union)、Precision、Recall、AP和mAP(mean average precision)等指标。
IoU 是一种常用的评价目标检测算法性能的指标。它是通过计算预测框与真实目标框之间的重叠面积大小来量化目标检测算法的准确率。当IoU 为1 时,表示预测框完全覆盖了真实目标框;当IoU为0时,表示两个框没有交集,预测错误。不同任务和数据集可能需要不同的IoU阈值,通常情况下IoU阈值越高,算法的准确率也越高,但同时漏检率也会相应地增加。
其中TP表示真正例,FP表示假正例。精度越高,表示被视为目标的检测结果更准确,但可能会漏检部分实际存在的目标。Precision、Recall公式定义如下:其中,Precisioncij表示类别Ci在第j张图像中的准确率,Recallcij表示类别Ci在第张图像中的召回率。其中TP 表示真正例(预测目标正确),FN 表示假反例(未检测到的目标),召回率越高,表示模型检测到了更多的目标。
类别的平均精度(AP)如下所示:
mAP 用于描述模型对所有目标类别的检测性能。在实际场景中,可能会有多个类别的目标检测,当数据集有多个类别{C1,C2,…,Cn} ,mAP如式(4)所示:
PR 曲线是由准确率和召回率来构建的曲线,可以更准确地评估检测器的性能。PR曲线的两个指标都聚集于正例,PR 曲线越靠近右上角越好。ROC(receiver operating characteristic)曲线是与PR曲线对应的接受者操作特征曲线,它是一种比较均衡的评估方法。ROC曲线使用了假阳性率FPR 和真阳性率TPR,与PR 曲线不同的是,ROC曲线越靠近左上角,说明检测器的性能越好。ROC曲线下面积可以更直观地表示检测器的好坏,通常AUC 值介于0.5 和1.0 之间,AUC 值越大表示性能越好。
ROC 曲线兼顾正例和负例,适用于评估分类器的整体性能。如果想要评估相同的类别分布下正例的预测情况,宜选用PR曲线。在实际的应用中,应根据实际需要选择PR曲线或ROC曲线。
4 经典目标检测算法的改进策略
4.1 模型结构改进
通过改进网络模型的结构,可以提升目标检测算法的性能。引入更深的网络结构或者采用更轻量化的网络可以提高算法的感受野和特征表示能力。
4.1.1 引入更深的网络结构
更深的网络结构可以提供更多的层次抽象表达能力,从而更好地捕捉数据中的特征信息,如ResNet、EfficientNet[63]等。这类网络结构通常由多个卷积层、池化层和全连接层组成,与浅层的网络结构相比,较深的网络结构可以提高模型的表现能力和性能,在一些复杂的任务中取得更好的效果。
因网络参数增加,其可以适应各种不同规模度的图像,相比较传统的目标检测方法具有更强的泛化能力。足够的训练数据量可以给予更深的网络更强的适应性和泛化能力,使其在不同数据集、不同场景下都能取得较好的效果,提高目标检测的准确率和鲁棒性。
4.1.2 轻量级模型结构
通过设计轻量级的模型结构,以在保持较高准确率的同时减少参数量和计算复杂度。常见的轻量化设计包括使用深度可分离卷积、轻量化的模块设计、模型剪枝和模型量化等。
轻量级模型相对于大型复杂模型具有更少的参数,因此可以在计算资源受限的情况下实现较快的推断速度。Google 团队[64]提出了MobileNetV3 模型,在保证精度的同时,使计算量减少了15%。Han 等人[64]提出了GhostNet 轻量化模型,采用两个卷积串联的结构,利用低精度Full-Resolution Residual Connections(FRRC)解决信息流的问题。轻量级模型结构可以为目标检测任务的快速实现、较弱计算资源设备上的部署和优化等提供解决方案。
常用的轻量级模型部署有剪枝、量化、蒸馏、模型压缩等方法。设计轻量级的网络结构和层次结构,例如采用深度可分离卷积、shufflenet等网络结构来大大减小网络参数量和计算负载。这些方法可以单独或组合使用来优化模型大小和性能,以适应不同的部署环境。在实际应用中,需要根据具体要求和限制来选择适当的方法进行轻量级模型部署。
4.2 损失函数设计
在目标检测领域,改进损失函数是常见的研究主题。改进损失函数可以引导目标检测算法更好地优化模型。目标检测中常用的损失函数有交叉熵损失、平方损失和Smooth L1损失等,这些损失函数对于预测目标类别和位置都有一定的优劣性。改进目标检测损失函数通常会引入一些正则化项或一些特定的度量指标,以增强模型的鲁棒性并减少过拟合或偏差问题的发生。这有助于提高目标检测模型在新数据集上的泛化能力和可靠性。
传统的交叉熵损失等损失函数不能很好地适应物体检测任务,而改进后的损失函数可以更好地判断目标是否存在、位置是否准确,从而提高模型的准确度。并且有助于解释模型处理过程中所做的决策,进一步提高目标检测算法的可解释性。修改成本函数的策略可以使模型学习更好地利用数据,从而在相同时间内获得更快和更稳定的收敛速度。
4.3 区域生成方法改进
区域生成方法用于生成候选目标框,改进这一步骤可以提高目标检测算法的效率和准确性。一种常见的策略是引入基于Anchor的方法,如Faster R-CNN、RetinaNet等,通过设计不同尺度和长宽比的Anchor 来生成候选框。另外,也有一些基于候选框生成的方法,如Selective Search、EdgeBoxes等方法,可以用于改进区域生成的效果。
改进区域生成方法的输入条件更加灵活和丰富,其图像生成过程也可以提供更多的中间结果以及分别对应不同目标属性的部分图像信息,如颜色、纹理、形状等。这使得该方法具有更强的可控性和可解释性,在特定任务和应用场景下具有较好的效果。
4.4 上下文信息利用
利用目标周围的上下文信息可以提升目标检测算法的准确性。一种常见的策略是引入注意力机制,通过引入注意力机制,使模型能够自动学习重要区域和关键特征。此外,特征融合策略也可以用于扩展模型的感受野并提升目标检测算法的性能。
4.4.1 引入注意力机制
通过引入注意力机制模块,针对不同的目标及环境特征,自适应选择和调整重要区域和特征,可以帮助模型在处理图像时关注重要的目标区域,从而提高检测的精度和鲁棒性。
全局注意力(global attention):全局注意力是将图像整体视为一个注意力矩阵,通过对整个图像进行权重计算,从而实现不同程度的区域加权。通常采用全连接层或卷积层实现,能够有效捕获图像基本特征和背景信息,但不能很好地处理局部目标和噪声。
自适应注意力(adaptive attention):自适应注意力是指根据图像的内容和上下文,自动调整注意力矩阵的大小和形状,以更好地关注重要的目标区域。比较常见的是基于空间注意力、通道注意力和特征注意力进行计算和调整。
多层次注意力(multilevel attention):多层次注意力通常将不同深度和尺度的特征分别建立注意力模块,并分别计算每个位置和通道的权重,然后将所有注意力结果融合起来,并通过反馈机制对模型进行优化。能够较好地处理不同尺度和复杂场景下的目标检测问题。
注意力机制能够自动调整关注区域,在面对不同场景和任务时具有较好的适应能力,能够提高模型的泛化能力和可迁移性。
4.4.2 特征融合策略
特征融合是利用上下文信息进行目标检测时广泛应用的一种策略。它将不同来源和不同维度的特征组合起来,以增强检测模型对目标的判别能力和鲁棒性。常见的特征融合方法包括以下几种:
早期特征融合(early fusion):将不同分辨率和抽象级别的特征在输入层直接拼接或相加,构造多通道特征进行统一处理。优点是简单易用,可以较好地保留图像的粗略低级特征,但同时也容易导致过度拟合和冗余计算。
晚期特征融合(late fusion):将不同层次或位置的特征分开提取、独立处理,再在输出层或后续模块中融合,具有较好的灵活性和可扩展性。
注意力机制特征融合(attention-based fusion):通过引入学习到的注意力权重,自适应选择和调整不同特征的贡献和重要性,从而实现针对性融合。
特征融合是一种有力地利用上下文信息的策略,可以有效提高目标检测算法的性能和鲁棒性,但需要根据具体应用场景和数据情况选择合适的方法和参数。
4.5 数据增强技术
通过合理的数据增强策略可以增加目标检测算法的训练样本,提升模型的鲁棒性和泛化能力。常见的数据增强技术包括随机裁剪、缩放、旋转、颜色变换等,还可以结合图像语义分割、实例分割等任务进行数据增强。
5 应用现状
目标检测技术已经取得了很大的进展,在图像识别、目标跟踪、智能安防等应用场景中显示出极高的精度和效率,为实现智能化时代的到来奠定了坚实的基础。目标检测根据实际场景需求的不同,在技术的实现上也有所不同。在现实的应用场景中,目标检测具有非常重要的现实意义,具有广泛的应用前景。本章主要列举了当前目标检测的重要应用。目标检测技术的研究方向正在朝着高效、准确和实时性方面发展,应用场景也日益多样化和广泛。
5.1 人脸检测
人脸检测作为目标检测中最重要的应用之一,与人们的日常生活密切相连。然而在现实世界中,由于人脸表征的多样性、外部环境光照和手势等因素的影响,人脸检测任务具有挑战性。
传统的人脸检测主要基于滑动窗口和手工特征提取器,利用人脸模板特征与检测到的图像特征进行滑动匹配,以确定人脸的位置。代表方法是Viola和Jones于2001年设计的VJ检测算法[65]。这种算法使用了Haar特征和级联AdaBoost 分类器构建检测器,能够大大提高检测速度和准确率。随着深度学习算法的逐渐发展,基于深度学习的人脸检测技术也越来越成熟。
随着卷积神经网络的深入研究,基于卷积神经网络的人脸检测取得了很好的检测结果。Najib等人[67]提出一种SSH,通过在不同尺度的特征图上进行检测来实现多尺度人脸检测,提高了检测速度。Wu等人[68]建立了模板匹配方法,丰富了检测模型。Jiang等人[69]在Faster R-CNN的基础上提出了Face R-CNN,并添加了基于Softmax的中心损失,性能得到了提升,但检测的速度较慢,无法满足人脸检测对速度的极高要求。Bazarevsky等人[70]提出了一种用于实时人脸检测的轻量级网络模型,具有较快的推理速度和较小的模型尺寸。在今后的研究中,随着技术水平的发展,研究结果也将更加贴近实际应用。
5.2 显著目标检测
显著性目标检测通过模仿人的视觉感知系统,寻找最吸引视觉注意的目标,已被广泛应用于图像理解、语义分割、目标跟踪等计算机视觉任务中。基于深度学习的显著性目标检测方向大致分为基于RGB 图像、基于RGB-D/T图像以及基于光场图像的显著性目标检测。
1998年,Itti等人[71]提出了显著目标检测方法,基于手工提取图像特征进行显著性目标检测也得到了一定的发展。随着深度学习的发展,此后的研究主要集中于基于深度学习技术开展。李俊文等人[72]提出一个轻量级显著性目标检测模型,提高了检测效率。Sheng等人[73]提出了一种轻量级MobileFaceNets模型,适用于在移动设备上进行高准确度的实时人脸验证任务。与传统手工特征提取方法相比,基于深度学习的轻量级目标检测模型可以充分利用大规模数据进行模型训练,实现更精准的特征提取和显著目标定位,具备更强的应对复杂多变场景的能力。
5.3 行人检测
行人检测技术在智能交通系统、智能安防监控、智能机器人等领域均拥有广泛的应用前景和价值,已经成为计算机视觉领域的重要研究方向之一。由于行人物体更容易受到人体姿态、外界光照和视角的影响,因此检测难度也较高。
在早期时,行人检测主要依赖于手工设计的特征进行目标表征,利用边缘的方向和强度信息来描述行人的形状和外观。然而,手工特征只能利用行人外观等浅层信息作为判断依据,这容易导致误检测和低准确率问题的发生。
随着深度学习技术的不断发展,行人检测引起了广泛关注。Mao 等人[72]提出了HyperLearner,通过修改锚点的尺度来增强对行人和背景的识别。对于行人的多尺度问题,Li等人[75]根据大尺度和小尺度的差异设计了两个子网络进行并行检测,通过使用尺度感知来合并两个子网络。陈宁等人[76]对遮挡情形下的行人问题进行了研究,总结了不同的方法。Tian等人[77]提出了DeepParts方法,将人体分为多个部分检测后再进行合并,解决了行人遮挡问题。Wang等人[78]提出了一种基于密集连接的轻量级目标检测网络模型,适用于移动设备上的实时行人检测。基于卷积神经网络的深度学习方法在行人检测领域的发展中具有重要推动作用。
5.4 遥感图像检测
遥感图像检测是指利用遥感技术获取的卫星或航空影像数据进行物体识别和分类的过程。遥感图像检测可以应用于土地利用、环境监测、城市规划等领域,为决策者提供重要的信息支持。常见的遥感图像检测任务包括建筑物检测、道路提取、农作物识别、水域分类等。
通过遥感技术,可以获取地表、海洋、大气等多种地球物理参数信息,为资源调查和环境监测提供了可靠数据支持。张大奇等人[79]提出了一种U-PSP-Net结构的卷积神经网络,证明了神经网络结构在含阴影的冰川遥感影像中的可行性和有效性。李坤亚等人[80]改进YOLOv5的遥感图像目标检测算法,有效提高了检测精度。Li等人[81]总结了基于光学遥感影像的船舶检测与分类方法存在的问题和未来发展趋。遥感图像检测对农田检测、城市规划、城市更新、军事侦察等领域具有重要意义。
6 总结与展望
本文对基于深度学习的目标检测方法进行了全面的回顾,主要包括两个方面:检测架构和骨干网络。综合两阶段目标检测方法和单阶段目标检测方法,总结归纳出它们各自的优缺点。介绍了数据集和评价指标,并总结了目标检测的重要应用。随着目标检测技术的逐步发展,检测精度在目前有了逐渐的提升。但随着应用场景的多元化发展,目标检测技术在改进模型算法、数据预处理、深度学习网络设计、模型优化等方面仍然存在多种挑战和待解决的问题。综合当前目标检测的研究现状,对今后的研究做出如下展望:
(1)多元化数据集:单一数据集包含信息较少,限制网络作用发挥,检测的效果较弱,建立多元化的数据集,可以用来训练多领域目标检测模型是未来的研究方向。
(2)轻量化模型:目前存在的网络模型架构通常复杂、参数众多,难以满足边缘设备实时检测的需求。因此,在保证高准确度的前提下,提升检测速度,让模型变得更加轻量化,显得尤为重要。为此,研究人员正在积极探索诸如压缩算法、量化方法、深度可分离卷积等轻量级技术,来降低模型的计算量和存储空间占用,从而使目标检测技术能够更好地适应实际场景中的需求。
(3)小目标检测:随着深度卷积神经网络的普及,基于深度学习的目标检测方法已成为主流。然而,一些方法在小目标检测方面存在较差的表现,并且通过深层网络对小目标进行特征提取容易出现语义信息丢失的问题。利用超分辨率重建来丰富小目标的细节信息,如SRCNN、VDSR、EDSR等方法使用卷积层来学习低分辨率图像的映射,对低分辨率图像进行学习和重建,能够提高重建图像的视觉质量和对小目标细节的还原能力。
(4)多模态目标检测:多模态数据融合学习方法在提升微弱目标检测效果方面表现突出,相对于单一模态具有更加丰富的目标信息,在许多应用场景中有着广泛的应用。然而,多模态数据融合也会带来计算量的增加,从而使得在计算资源受限的环境下难以实现实时目标检测效果。因此,如何在保证目标检测准确率的前提下,提高目标检测速度以满足实时监测需求,成为了未来发展的重要挑战。为此,研究者正在积极探索一系列优化策略,诸如网络剪枝、混合精度训练、硬件加速等,以解决多模态数据融合过程中的瓶颈问题,推进目标检测技术在实践中的广泛应用。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
电视技术(2014年19期)2014-03-11
