
融合权重自适应损失和注意力的人体姿态估计
2023-09-25 08:57江春灵姚壮泽
计算机工程与应用 2023年18期
江春灵,曾 碧,姚壮泽,邓 斌
广东工业大学计算机学院,广州510006
人体姿态估计一直是计算机视觉中一个基本但具有挑战性的问题,其目标是定位图像中所有人的关键点(例如,肘部、手腕、膝盖等)。人体姿态估计广泛应用于动作识别[1-4]、人机交互以及动画制作等领域。
在深度学习迅速发展的情况下,基于深度卷积神经网络[5]的人体姿态估计方法已经取代传统的图结构模型算法成为主流的人体姿态估计方法。2016年Newell等[6]使用堆叠沙漏网络进行热力图预测和分组,但堆叠的沙漏网络会导致大量的有效信息在不断地上下采样过程中丢失。SimpleBaseline[7]使用反卷积操作代替上采样,在一定程度上缓解了这一点,提升了人体姿态估计的精度,但没有本质上解决这个问题。2017年OpenPose[8]提出一个双分支、多阶段的网络结构,其中一个分支用于热力图预测,一个分支用于分组。同时OpenPose 提出一种部件亲和向量场(part affinity fields,PAFs)的分组方法,该方法学习连接两个关键点之间的二维向量场,通过计算两个关键点之间的线积分,并对具有最大积分的一对关键点进行分组,但分组效率有所降低。2018年PersonLab[9]使用深度残差网络[10]并通过直接学习每对关键点的二维偏移场来对关键点进行分组。2019 年Sun 等[11]提出高分辨率网络HRNet,在始终保留高分辨率分支的同时采用并联的方式将不同分辨率子网并行连接进行多尺度特征融合,充分利用不同尺度下的特征信息。2020 年Cheng 等[12]在HRNet 的基础上提出HigherHRNet,通过在HRNet 的末端加入反卷积模块,进一步提高特征图的分辨率,同时聚合不同尺度下的热力图进行推理,进一步提高了预测的准确性,但并未解决前后背景不平衡的问题。2021 年Luo 等[13]在HigherHRNet的基础上增加一个尺度感知分支,通过自适应调节每个关键点的标准差,增加模型在人体尺度差异和标注歧义问题上的鲁棒性。同年Geng等[14]提出解构式人体关键点回归(disentangled keypoint regression,DEKR),使用自适应卷积和多分支结构,使模型专注于关键点区域的表示,直接回归关键点的位置,但未充分利用高分辨率网络丰富的通道及空间信息。
由于在自底向上的人体姿态估计方法中存在前景和背景样本之间不平衡的问题,同时人体姿态估计方法主要采取的高分辨率网络在特征提取和特征融合时不能有效获得通道信息和空间位置信息。本文以HigherHRNet为基础,提出了一个融合权重自适应和注意力的自底向上人体姿态估计网络。主要贡献如下:(1)提出一种权重自适应损失函数,解决前景和背景样本之间不平衡的问题。(2)设计高效全局自注意力模块,充分利用高分辨率网络的通道和空间信息。(3)引入热力图分布调制模块,解决热力图在最大激活值附近出现多个峰值的问题,提高热力图解码出关键点位置的准确性。(4)算法在公开数据集COCO[15]数据集上进行验证,平均准确率为72.3%,优于其他自底向上人体姿态估计主流算法。
1 相关工作
1.1 多人人体姿态估计
目前主流的多人人体姿态估计方法可以分为两类:自顶向下(Top-down)人体姿态估计和自底向上(Bottom-up)人体姿态估计。
自顶向下的人体姿态估计算法主要包含两个部分,人体检测和单人人体关键点检测:首先通过目标检测算法将每一个人检测出来,然后在人体提议框的基础上做单人人体关键点检测。谷歌提出的G_RMI[16]采用fasterrcnn[17]作为人体检测器,通过ResNet[18]预测每个关键点的热力图以及偏移量,将热力图以及偏移量进行融合来获得关键点的定位。Huang等[19]则是提出一种无偏估计的方法,将热力图的最大值对应的坐标加上偏移量得到关键点的坐标。Alphapose[20]从人体检测器的人体提议框的优化角度出发,添加一个对称空间转换网络分支,在不精准的区域框中提取到高质量的人体区域。同时采用参数化姿态非极大值抑制,消除冗余的姿态。由于自顶向下的方法可以通过裁剪和调整被检测到的人体边界框,将所有人标准化为近似相同的尺度,它们通常对人体的尺度不敏感。因此,在各种多人人体姿态估计基准上的最佳成绩大多是通过自顶向下的方法来实现的。
相比之下,自底向上人体姿态估计通过预测不同人体关键点的热力图,定位图像中所有人的无身份关键点,然后将它们分组到不同的人体实例中。早期的自底向上人体姿态估计方法DeepCut[21]先检测出图像中所有的关键点,将每个关键点作为一个图节点,关键点之间的关联性作为节点之间的权重,形成密集连接图。最后根据整体线性规划,将属于同一个人的关键点关联起来。Openpose[8]则是提出部件亲和向量场,利用关键点之间的向量点乘的值关联两个关键点,根据匈牙利算法进行匹配。Newell[6]提出关联嵌入[22](associate embedding)的方法来进行关键点分组,该方法为每个关键点分配一个标签(一个向量表示),并根据标签向量之间的L2 距离对关键点进行分组。自底向上的方法一次性检测图像中所有的人体关键点,只需对整体图像特征提取一次,即使人体数目增加也不会导致重复的卷积操作,因此这类方法往往效率更高。
1.2 高分辨率网络
计算机视觉领域有很多任务是位置敏感的,比如目标检测、语义分割、实例分割等。为了这些任务位置信息更加精准,很容易想到的做法就是维持高分辨率的特征图,HRNet[11]之前几乎所有的网络都是这么做的,通过下采样得到强语义信息,然后再上采样恢复高分辨率以恢复位置信息,然而这种做法,会导致大量的有效信息在不断地上下采样过程中丢失。而HRNet 通过并行多个分辨率的分支,加上不断进行不同分支之间的信息交互,同时达到获取强语义信息和精准位置信息的目的。HigherHRNet[12]在HRNet 的末端加入反卷积模块,得到1/2初始大小的特征图,同时在推理过程中聚合1/2和1/4特征分支的热力图,解决自下而上的多人姿态估计中的尺度变化挑战,并更精确地定位关键点。因此本文采用HigherHRNet作为基础框架。
HRNet网络结构总体分为4个阶段,第一阶段由一个高分辨率子网构成,第二阶段至第四阶段分别在前一个阶段的基础上增加一个子网,新增的子网分辨率为上一阶段最低分辨率的一半,通道数为原来的两倍。将每一阶段的多分辨率子网以并行的方式进行连接,各阶段之间通过多尺度特征融合来交换信息。根据基础通道数的不同,HRNet分为HRNet-w32和HRNet-w48。
1.3 注意力机制
注意力机制的本质是通过学习卷积特征得到一组权重系数,通过给重要信息分配高权重使网络更加关注重要的信息,从而提高网络的性能。
2015 年Jaderberg 等[23]提出STN(spatial transformer networks)空间注意力模块,在特征图层面上实现全局的缩放、旋转等变换,从而使网络具有缩放、旋转等空间变换不变性。2018 年Hu 等[24]提出SE(squeeze-andexcitation)通道注意力模块,通过压缩和激励构建通道间的关系。同年Woo等[25]提出CBAM(convolutional block attention module)模块,同时融合空间注意力和通道注意力,特征图将得到通道和空间维度上的注意力权重,自适应细化特征。2020年Wang等[26]提出ECA(efficient channel attention)模块,提出了一种不降维的局部跨通道交互策略,有效避免了降维对于通道注意力学习效果的影响,在保持性能的同时显著降低模型的复杂性。
2 本文算法
本文提出的WA-HRNet网络模型的整体结构如图1所示。首先将图像输入特征提取网络,分别得到关键点热力图和标签值热力图。在训练阶段,根据预测的关键点热力图与真值热力图计算权重自适应损失,根据预测的标签值热力图计算分组损失。在测试阶段,将预测的关键点热力图输入热力图分布调制模块,将调制后的热力图进行解码得到所有关键点的位置信息。然后根据关键点的位置信息在预测的标签值热力图中找到关键点对应的标签值。最后根据标签值将关键点进行聚类,将它们分组到不同的人体实例中。

图1 整体框架Fig.1 Overall framework
特征提取网络的整体结构如图2所示,在HRNet的末端加入注意力模块,同时在训练阶段引入多分辨率监督,生成具有不同分辨率的真值热力图以便计算不同分辨率下预测热力图的损失。在推理阶段,使用热力图聚合推理,对所有尺度的预测热力图进行平均处理以得到最后的预测。

图2 特征提取网络Fig.2 Feature extraction network
2.1 权重自适应损失函数
在自底向上的人体姿态估计方法中,存在前景和背景样本不平衡的问题,可能会使得模型更倾向于过拟合背景样本。Lin等[27]提出Focal Loss用于缓解分类任务中正负样本严重不平衡的问题。受此启发,本文提出针对热力图的权重自适应损失函数。
在基于热力图的人体姿态估计方法中,热力图的损失函数如公式(1)所示:
式中,P为预测热力图,H为真值热力图,为了解决样本间不平衡的问题,给原始的L2 损失直接添加一个权重W,如公式(2)所示:
其中,W可以定义为公式(3)所示:
式中,{k,i,j}代表热力图P中的像素位置。然而在热力图中,像素的值是连续的而非离散的0或1,因此很难区分正负样本。为此提出权重自适应损失函数,损失函数的权重W定义如公式(4)所示:
其中,τ是控制软边界的超参数,‖ ‖⋅ 为绝对值函数。区分正负样本的软边界表示为真值热力图的阈值h,定义为1-hτ=hτ。基于热力图的人体姿态估计方法通过以人体关键点作为中心位置,利用高斯函数生成真值热力图,越接近人体关键点的位置,真值热力图的值越接近1。在本文的权重自适应损失函数中,对于真值热力图值越大于阈值h的样本,Hτ的值越接近1,则样本权重更接近正样本(1-P),使得模型更加关注人体关键点的中心区域。反之对于真值热力图值越小于h的样本,Hτ的值越接近0,则样本权重更接近负样本P,模型对其关注度更低。模型通过自适应调节样本的权重,使得模型更关注关键点周围区域,也就是前景区域,从而缓解前景和背景样本不平衡的问题。在实验中,使用τ=0.01。
2.2 高效全局注意力模块
为了充分利用高分辨率网络的通道和空间信息,受CCNet[28]和Coord attention[29]的启发,本文提出一种高效的全局注意力模块,如图3所示。既能获取通道之间的依赖也能很好地建模位置信息和远距离依赖,获取丰富的上下文信息。

图3 注意力模块Fig.3 Attention module
对于输入的特征图F∈ℝC×W×H,首先利用两个具有1×1 滤波器的卷积层生成两个特征图Q、K。其中{Q,K}∈ℝC′×W×H,为了对通道进行降维,减少计算量,使得C′小于C。得到特征图Q和K后,通过Affinity操作进一步生成特征图A∈ℝ(H+W-1)×W×H。在特征图Q的空间维度上的每个位置u,可以获得一个向量Qu∈ℝC′。同时,也可以通过从K中提取与u位置相同的行或列的特征向量来获得集合Ωu∈ℝ(H+W-1)×C′。Ωi,u∈ℝC′表示Ωu中的第i个元素。Affinity 操作如公式(5)所示:
其中,di,u∈D代表特征Qu和Ωi,u之间的关联程度,然后对D在通道维度上进行softmax操作计算出特征图A。
同时对特征图F利用另一个具有1×1 滤波器的卷积层生成特征图V∈ℝC×W×H用于特征适应。在特征图V的空间维度上的每个位置u,可以获得一个向量Vu∈ℝC和集合Φu∈ℝ(H+W-1)×C。集合Φu是特征图V中与u位置相同的行或列的特征向量的集合。然后通过Aggregation 操作来获取上下文信息,如公式(6)所示:
然后对特征图F′,分别使用尺寸为(H,1)和(1,W)的池化核沿着水平坐标方向和垂直坐标方向对每个通道进行编码。因此,第c个通道在高度为h处的表示如公式(7)所示:
上述两种转换分别沿两个空间方向聚集特征,产生一对方向感知的特征图。这两种转换也使注意力块能够沿一个空间方向捕捉长距离的依赖性,并沿另一个空间方向保留精确的位置信息。这有助于网络更准确地定位物体感兴趣的对象。
然后连接公式(7)和公式(8)中生成的两个特征图,再使用共享的1×1卷积变换函数F1生成f,如公式(9)所示:
其中,[⋅,⋅]代表沿着空间维度的连接操作,δ为非线性激活函数,f∈ℝC/r×(H+W)是在水平方向和垂直方向上编码空间信息的中间特征图,r表示下采样的比例。
然后将f沿着空间维度切分为两个单独的张量f h∈ℝC/r×H和f w∈ℝC/r×W,利用两个1×1卷积变换函数Fh和Fw分别将f h和f w变换到和F′一样通道数的张量,如下式所示:
将输出的gh和gw分别拓展作为注意力权重,最后输出的特征图F′如公式(12)所示:
综上本文所设计的注意力模块可以获取丰富的上下文信息,获得空间方向的远距离依赖,同时可更准确地定位感兴趣对象的确切位置。
2.3 热力图分布调制
在训练过程中,通过关键点坐标生成对应的真值热力图用来监督模型预测的热力图。假设代表第p个人第k个关键点的坐标,hp代表与其相关的真值热力图,如公式(13)所示:
“除了划定常年禁渔区外,从今年开始,我们还将全县84条河流列入季节性禁渔区,千岛湖全域均实现了禁渔。”淳安县渔政局局长吴福建说。
其中,{k,i,j}代表hp中的像素位置,σ为高斯函数的标准差。
然而与真值热力图数据相比,人体姿态估计模型预测的热力图并没有表现出良好的高斯结构,预测的热力图存在多个峰值的情况,可能会影响热力图解码的性能。为了解决这个问题,根据DARK[30](distribution-aware coordinate representation of keypoint),本文引入热力图分布调制来改善预测热力图。
利用与训练数据相同的高斯核G来平滑热力图中多个峰值的影响,如公式(14)所示:
其中,⊗表示卷积操作,p表示初始预测热力图。
为了保持原始热力图的大小,对p′进行缩放,使其最大激活值与p相等,转换如公式(15)所示:
在消融实验中验证了热力图分布调制进一步提高了热力图解码的性能。
2.4 人体关键点分组
在本文中采用关联嵌入[22]的方法将图像中所有人的无身份关键点分组到不同的人体实例中。其采用类内最小,类间最大的思想,即同一个人的所有关键点的标签值的间距越小越好,而不同人的关键点之间的标签值差距越大越好。
具体来说,设tk=ℝW×H代表预测的第k个关键点的标签值热力图,t(x)是像素x处的标签值。对于给定的N个人,其真实关键点坐标为S={(xnk)},n=1,2,…,N,k=1,2,…,K,其中xnk代表第n个人的第k个关键点的真实像素位置。假设所有的K个关键点都被标注了,第n个人的参考标签值如公式(16)所示:
则分组损失定义如公式(17)所示:
其中,第一项表示第n个人的所有关键点标签值与其参考标签值之间的损失,第二项表示第n个人的参考标签值与其他人参考标签值之间的损失。
3 实验结果及分析
3.1 实验环境及设置
本文实验使用Python 语言,基于Pytorch 框架实现。CPU为i9-9900x,显卡为NVIDIA GTX 2080ti。
本文算法使用在ImageNet[31]上预训练的HigherHRNet网络作为backbone,使用Adam[32]优化器对模型进行优化,初始学习率为0.001 2,动量为0.9,模型训练360 个epoch。
本文通过随机翻转([-30°,30°]),随机缩放([0.75,1.25]),随机平移([-40,40])和随机水平翻转来进行数据增强。
3.2 数据集介绍
本文模型分别在COCO数据集和Crowdpose[33]数据集上进行验证。COCO 数据集包含超过20万张图片和25 万个人体实例,每个人体实例标注17 个关键点。将COCO数据集中5.7万张图片用于训练,0.5万张图片用于验证,2万张图片用于测试。
CrowdPose 数据集由2 万张照片组成,包含8 万个人体实例,每个人体实例标注14 个关键点,根据5∶1∶4的比例划分训练集、验证集和测试集。相比于COCO数据集,CrowdPose 数据集有更多的拥挤场景,对多人人体姿态估计模型更具有挑战性。
3.3 评价指标
COCO数据集采用官方的目标关键点相似性(object keypoint similarity,OKS)作为评价标准。其中包括AP(在OKS=0.50,0.55,…,0.90,0.95 时关键点预测的平均准确率)、AP50(OKS=0.5 时的准确率)、AP75(OKS=0.75时的准确率)、APM(中型目标的检测准确率)、APL(大型目标的检测准确率)。OKS的定义如公式(18)所示:
其中,di检测到的关键点与其对应的真值之间的欧氏距离,vi是真值的可见性标志位,s表示目标的尺度因子,ki是控制衰减的常量。
CrowdPose数据集也是采用OKS作为评价标准,相比于COCO数据集增加了APE(简单样本的检测准确率)、APM(中等难度样本的检测准确率)和APH(困难样本的检测准确率)作为评价指标。
3.4 实验验证与分析
本文方法与一些先进的人体姿态估计方法分别在COCO数据集和CrowdPose数据集上进行了比较。
首先与一些先进的自底向上人体姿态估计方法在COCO测试集上进行比较,结果如表1所示。通过结果可以看到,不管是在单尺度测试还是多尺度测试上,WA-HRNet 都取得了最好的结果。在使用HRNet-W48作为backbone,多尺度测试的情况下可以在COCO 测试集上AP 值达到72.3%。与基线HigherHRNet 相比,WA-HRNet只增加了少量计算成本,且在不同backbone和输入尺寸的情况下都能取得稳定的提升。

表1 COCO测试集实验结果对比Table 1 Experimental result comparison on COCO test-dev set
同时与一些先进的自顶向下人体姿态估计方法进行了比较,结果如表2 所示。WA-HRNet 已经超过了很多自顶向下方法,进一步减小了自底向上和自顶向下人体姿态估计方法之间的差距。

表2 COCO测试集结果Table 2 Result on COCO test-dev set
表3为WA-HRNet 与其他先进的人体姿态估计方法在CrowdPose 数据集上的实验结果对比。在密集场景下,自顶向下人体姿态估计方法[20,34]失去了优势。这是因为自顶向下的方法假定所有的人都能被人体检测器完全捕获,并且每个检测框只包含一个人。然而,这一假设在密集场景中并不成立,在密集人群中,人通常是严重重叠的。相比之下,自底向上人体姿态估计方法不依赖于人体检测器,在处理密集场景时可能会更好。在使用HRNet-W48 作为backbone,多尺度测试的情况下在CrowdPose 测试集上的AP 值达到73.4%。与基线HigherHRNet 相比,WA-HRNet 的AP 值提升了5.8 个百分点。

表3 CrowdPose测试集结果Table 3 Result on CrowdPose test set
3.5 消融实验
为了验证本文算法各个模块的有效性,对本文模块进行消融实验。图4 展示了引入权重自适应损失函数以及高效全局注意力模块后热力图的可视化结果对比,结果表明引入权重自适应损失函数和高效全局注意力模块后,模型生成的热力图更加关注于关键点的中心区域。表4显示了各个模块在COCO验证集上的结果,消融实验均采用HRNet-W32 作为backbone。实验表明,WA-HRNet 的各个模块都能有效提升人体姿态估计的准确率。使用权重自适应损失函数比基线AP值提升了1.6个百分点,融合权重自适应和注意力比基线AP值提升了2.1 个百分点,加上热力图分布调制后的最终效果比基线AP值提升了2.3个百分点。
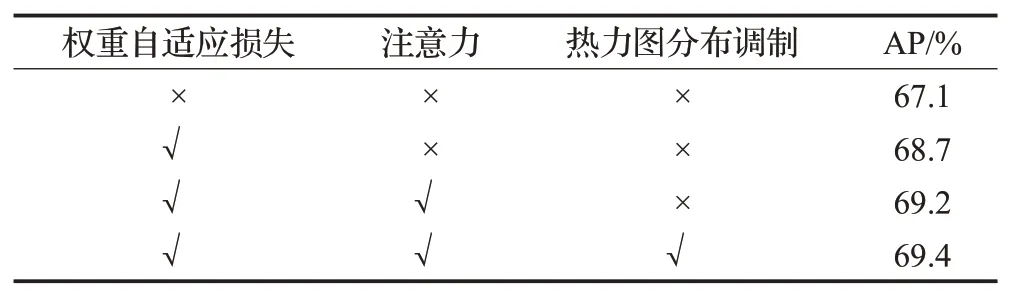
表4 消融实验Table 4 Ablation experiment
3.6 注意力模块对比实验
为了验证本文注意力模块的高效性,表5显示了引入本文注意力模块和主流的SE、ECA 注意力机制前后运算量和参数量的变化,以及在COCO数据集上的准确率。与基线相比,本文提出的注意力模块在基本不增加参数量和计算量的情况下AP 值得到了0.5 个百分点的提升。与主流的SE、ECA模块相比,本文提出的注意力模块在参数量及计算量方面相差不大,但准确率显著提升。SE 注意力提升较小的原因是SE 对特征图通道进行了压缩,会对通道注意力的预测产生负面影响,同时获取所有通道的依赖关系是低效的。ECA 虽然避免了SE 的降维,但其需要人为设置相邻通道信息的交流范围,这个重要的人为参数使得其泛化性不佳。
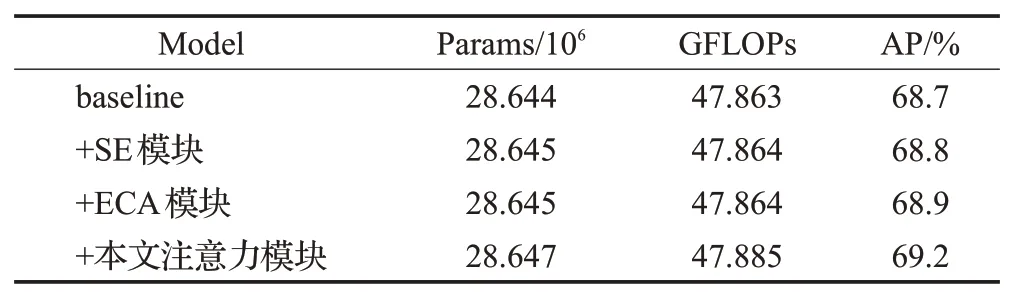
表5 注意力模块对比实验Table 5 Comparative experiment of attention module
3.7 可视化结果
本文对WA-HRNet 在COCO 数据集上的测试结果进行了可视化操作,随机选取遮挡、单人、多人的图片,结果如图5 所示。可以看到,不论是在单人、多人还是遮挡的场景下,WA-HRNet都能获得较好的结果。这表明本文提出的方法具有一定的鲁棒性,可以在大部分情况下保持良好的人体姿态估计性能。

图5 可视化结果Fig.5 Visual display of result
4 结论
本文提出了一个融合权重自适应和注意力的自底向上人体姿态估计方法。通过权重自适应损失函数,解决前景和背景样本之间不平衡的问题。并设计一种高效全局自注意力,充分利用高分辨率网络的通道和空间信息,获取丰富的上下文信息,获得空间方向的远距离依赖,更准确地定位人体关键点的准确位置。引入热力图分布调制模块,解决热力图在最大激活值附近出现多个峰值的问题,提高热力图解码出关键点位置的准确性。本文算法在只增加少量计算成本的情况下,有效提升了自底向上人体姿态估计方法的性能,同时在COCO数据集和CrowdPose 数据集上取得的成绩优于其他自底向上人体姿态估计主流算法。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
英语文摘(2021年4期)2021-07-22
学生天地(2020年3期)2020-08-25
现代临床医学(2019年4期)2019-09-10
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
中学历史教学(2017年12期)2018-01-19
现代检验医学杂志(2015年6期)2015-02-06
中国卫生(2014年2期)2014-11-12
