
基于Cascade RCNN的热轧带钢表面缺陷检测
2023-09-23 12:55王云森
仪表技术与传感器 2023年8期
陆 尧,薛 林,王云森,王 豪
(大连理工大学机械工程学院,辽宁大连 116024)
0 引言
在制造业中,热轧带钢是很多工业产品不可或缺的原材料,广泛应用于汽车、电机、造船等领域。热轧是生产过程中重要一步,热轧过程包括加热、轧制、冷却等环节,得到的热轧带钢工艺性能好、包容覆盖能力强。在生产过程中,由于各种因素的影响,带钢表面会产生缺陷,影响质量和使用性能,因此需要对表面缺陷进行检测,找出不合格品。人工检测表面缺陷时,需要进行标记、记录等操作,而带钢颜色单一,容易导致人眼疲劳,劳动强度大,检测的效率和精度低[1],严重制约生产效率和品质,需要改进检测方法。
近年来,深度学习的研究不断深入,在目标检测中被广泛运用[2]。叶欣[3]对YOLOv4改进,借鉴CSPNet使用CSP结构并组合残差结构,使用 Mish 激活函数和自适应空间特征融合,提高模型的特征融合能力和模型的检测精度;高志宽[4]提出基于内容与边界融合的显著目标检测方法,并且改进了网络训练损失函数;吴德蓝[5]用双阈值分割算法以及Marr-Hildreth边缘检测算法提取的小轮廓对应框的中心点作为anchor来改进RPN,提高Faster RCNN检测算法的检测速率;王梓洋[6]提出了全卷积网络的端到端交叉互补时空特征融合网络(CCNet),提高模型检测速度和精度;S.N.Shivappriya等[7]提出AAF-Fast RCNN方法,利用激励函数的傅里叶级数和线性组合更新损失函数,具有收敛性好、有界方差清晰等优点。
以上检测模型和改进方法针对所检测的对象都取得了良好的检测结果,但是在还存在数据集包含的数据过少、极大尺寸和极小尺寸的缺陷和缺陷不明显等问题,需要进行改进。针对上述问题,使用深度学习检测模型Cascade RCNN并对其优化,为了增大感受野,首先使用可切换空洞卷积替换标准卷积,同时提高定位精度;然后增加特征金字塔的连接路线,并且使用特征上采样算子,根据输入特征指导重组过程,同时整个算子计算量较小;最后,利用损失函数Focal Loss解决样本分类不均衡问题。
1 基型选择
在深度学习中,目标检测的代表算法可分为两类,分别为RCNN系列和YOLO系列。为了找出合适的检测模型,对目标检测模型进行了选择,首先使用YOLO V3[8]和Faster RCNN 2种目标检测算法训练[9],选择合适的参数,通过对比训练结果,发现YOLO V3只能学习到简单缺陷,对较小缺陷和不明显缺陷检测效果差,甚至还会出现严重漏检情况。Faster CNN法检测速度略低于YOLO V3,但是对于带钢缺陷检测效果更好,故选择Faster RCNN系列算法作为带钢缺陷检测的基础网络[10],其结构如图1所示。
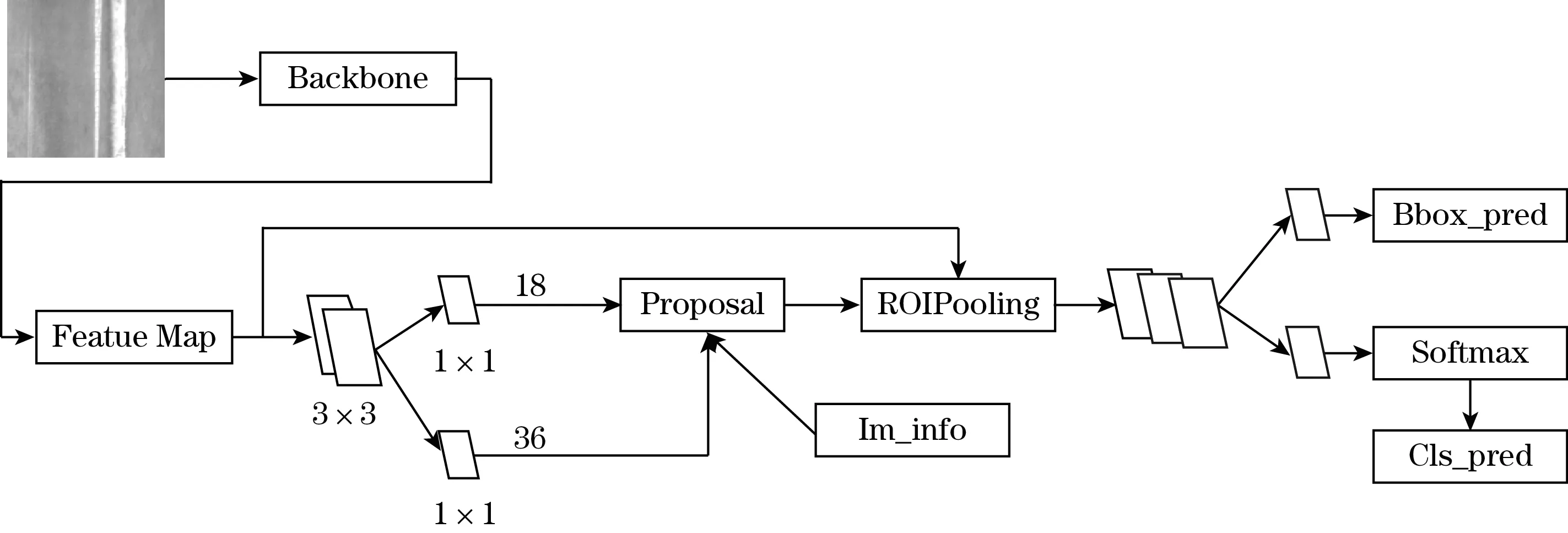
图1 Faster RCNN结构图
Faster RCNN组成为:
(1)特征提取网络,用于得到特征图,然后生成region proposal network(RPN)层并取每个框的坐标Proposal;
(2)RPN模块,生成候选框,包含两部分任务,一部分是分类,判断所有预设锚框属于正样本还是负样本(即锚框内是否有目标,二分类),另一部分是bounding box 回归,用于修正锚框得到对应的较准确的Proposal;
(3)region of interest (RoI) Pooling,用于收集RPN生成的特征图,并从特征图中提取出来生成Proposals Feature Maps送入全连接层;
(4)最后进行分类和回归,得到检测框最终的精确位置。
Faster RCNN网络训练过程中,预测框与标注框的交并比大于阈值被定义为正样本(positive),小于阈值被定义为负样本(negative)。在训练过程中,采取小阈值会产生背景噪声框,导致较多误检,采用较大阈值时,正样本数量呈指数下降,模型容易过拟合,故阈值选取成为目标检测的难点,选择合适的阈值至关重要。
为解决上述问题,选用基于Faster RCNN(图2(a))的多阶段目标检测基础架构网络(图2(b))Cascade RCNN。
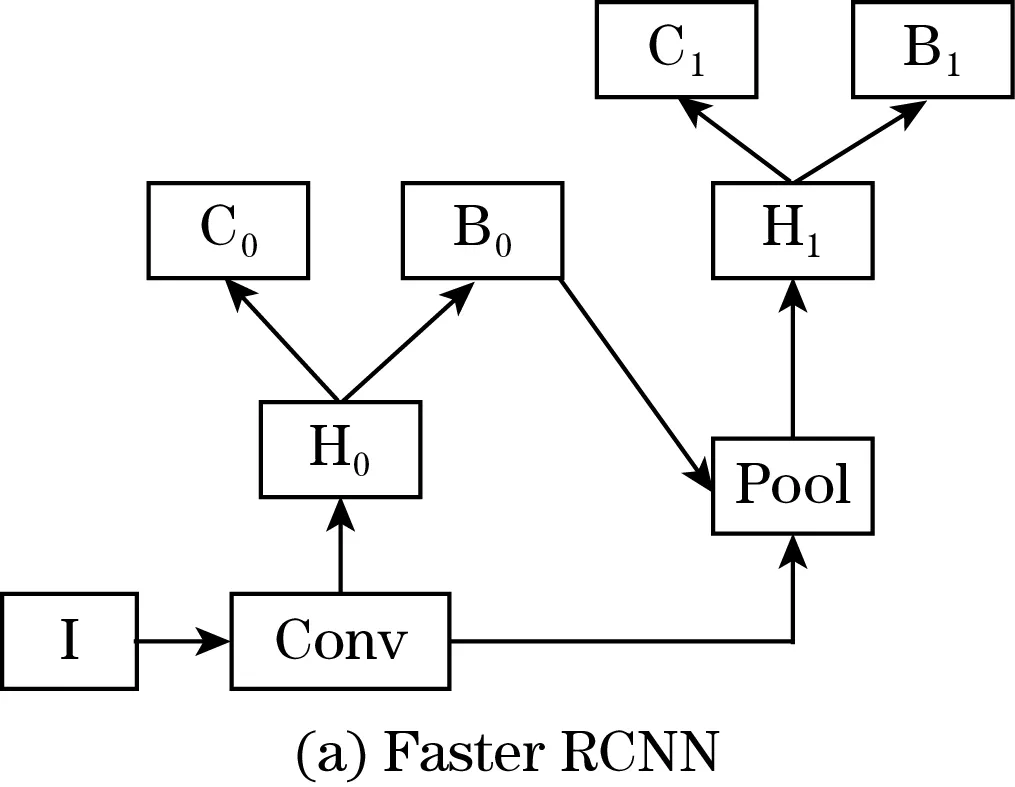
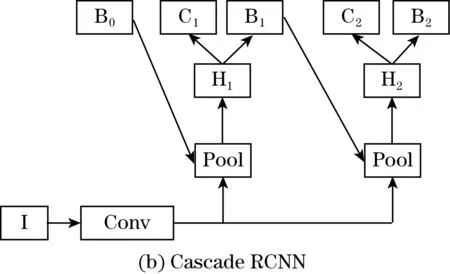
图2 Faster RCNN与Cascade RCNN
I是输入图片,Conv是特征提取网络,Pool 是ROI Pooling层,C是分类层,B是边框回归层,H是ROI Head。与Faster RCNN相比,Cascade RCNN包含多级级联器,然后通过级联器,不断提高候选框的交并比阈值,降低了错误的匹配出现的概率,并且提高了精度。在检测过程中,有多个检测头,把它们串联在一起,前一个的输出也是后一个的输入,存在依赖关系;同时,从前到后阈值得到不断修正,并且阈值逐渐提高,最终样本的质量和模型训练效果得到提高[11]。
2 模型改进
虽然相对于YOLO V3和Faster RCNN, Cascade RCNN的检测精度明显更好,但是检测精度提高较低,因此需要针对数据集的特点和工业应用进行改进。
2.1 主干网络改进
神经网络的组成为神经元,输入不同神经元,赋予其权重,然后再经过激活函数,得到不同的输出。ReLU激活函数[12]如式(1)所示。图像卷积是指对图像和滤波矩阵做内积,卷积神经网络(convolutional neural networks,CNN)[13]包含卷积运算,用于图像分类和物体识别。
ReLU=max(0,x)
(1)
式中x为输入。
神经网络的学习能力会随着网络层数增加而变强,但是层数过多时学习效率会变低,同时准确率降低,残差网络能够解决这些问题。残差网络(residual network,ResNet)[14]由两部分组成,是对CNN的优化,其结构如图3所示。其中残差部分是将输入x进行卷积、池化和归一化等操作得到输出F(x),另一部分是跳跃连接,输出F(x)与输入相加得到输出G(x),计算公式见式(2)。
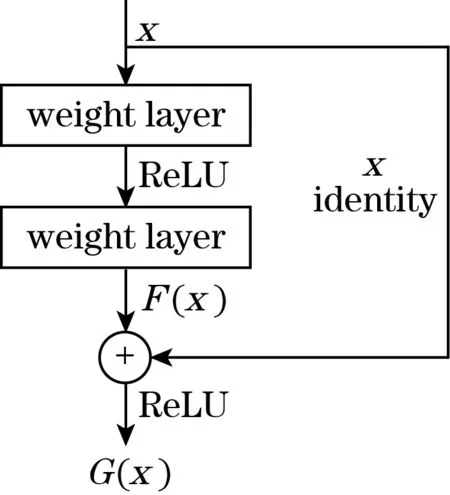
图3 ResNet结构图
G(x)=F(x)+x
(2)
基础模型的骨干网络是ResNet 50,由5个卷积组组成,每个卷积组有1个或多个基本的卷积运算过程,ResNet 50从输入到输出共50层。用ResNet 50得到特征图。特征图的质量会直接影响后续缺陷的检测结果,因此需要针对热轧带钢缺陷的特征对其优化。热轧带钢缺陷的尺寸大小差别大, 存在极大和极小的缺陷,根据热轧带钢缺陷特征,对卷积操作进行改进,使用可切换空洞卷积(switchable atrous convoltion,SAC)[15],特征提取能力得到了强化,提高了检测精度,如图4所示。
SAC模块包括2个全局上下文网络和主要特征提取模块。全局上下文模块通过全局平均池化层获取特征图每一通道上特征的平均值,用其替代原值,而后与输入特征图叠加,将全局信息添加到特征图中。该算法使用Switch路径得到的池化结果S(x)和1-S(x)对不同空洞卷积得到特征图分别加权,最终相加得到输出特征图,计算过程如式(3)所示。
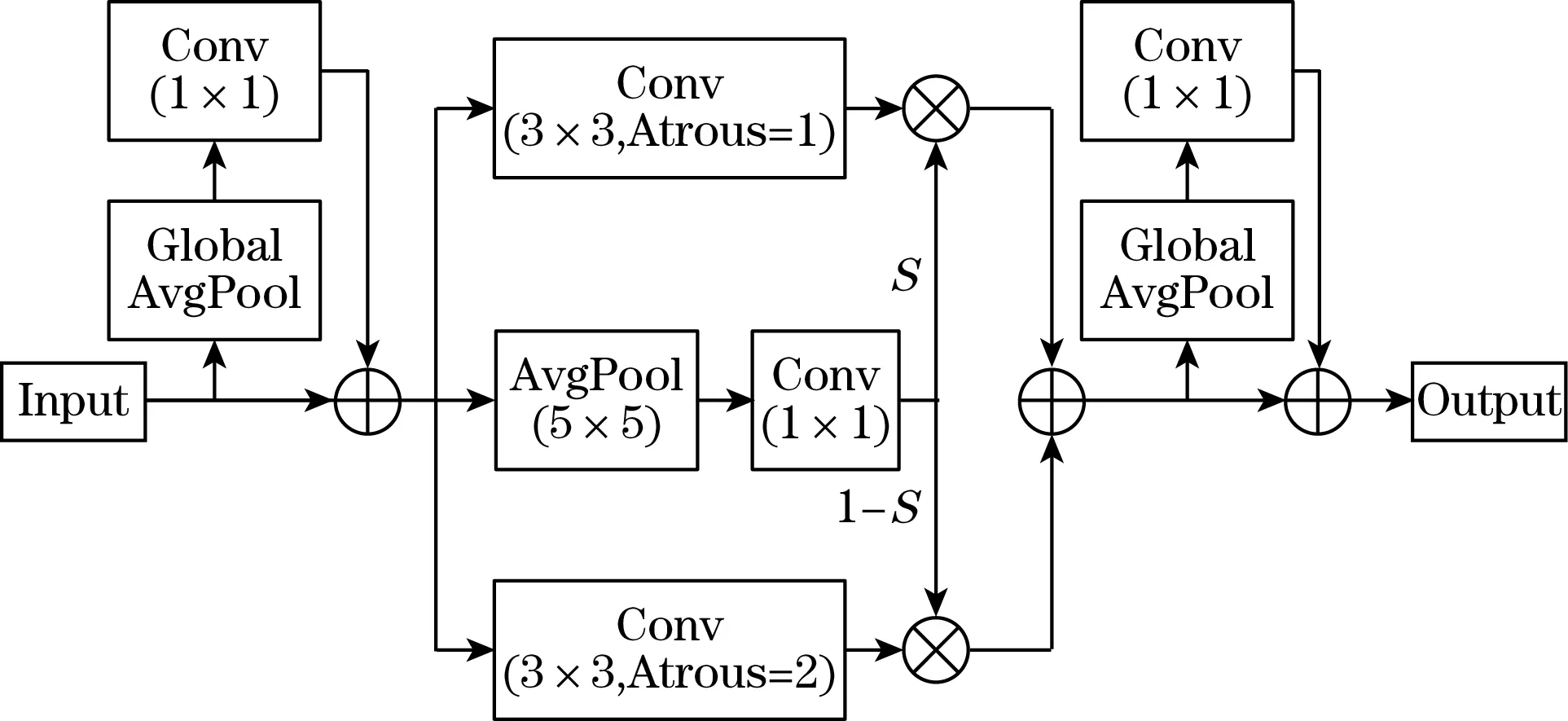
图4 可切换空洞卷积结构
Conv(x,w,1)=S(x)·Conv(x,w,1)+Conv(x,w+Δw,r)
(3)
式中:S(x)为切换操作;Conv(x,w,r)为卷积运算;x为输入特征图;w为权重;r为空洞率。
2.2 特征金字塔优化
Cascade RCNN是原图经过特征提取网络之后,在顶层特征图进行目标识别,但是小目标和不明显缺陷信息容易被多重池化而被淹没,在特征图上得不到缺陷信息。FPN在上层特征图上识别大尺寸缺陷,对于小尺度特征图,虽然有一些定位信息,但是在检测过程中不准确,FPN结构如图5所示。使用PAFPN解决这一问题,它是基于FPN的改进,基本框架不变,但是在连接上进行优化提升,增加从上而下的连接方式,这个连接用于减短从底层与上面层的信息传递的路程,提升了FPN定位精度[16]。
在FPN中采用最近邻上采样方法,由图像的像素点的空间位置得到其上采样核,因此特征图的语义信息并没有被使用,而且感知域通常都很小。特征上采样算子(content-aware reassembly of features,CARAFE)具有较大的感受野,能更好地利用周围的语义信息,根据输入进行上采样,没有引入过多的参数和计算量。
CARAFE由2部分组成,分别是上采样核预测模块(kernel prediction module,KPM)和特征重组模块(content-aware reassembly module,CRM)[17]。KPM过程为:特征图通道压缩、内容编码及上采样核预测、上采样核归一化。CRM过程为:得到的特征图中,对每个位置进行映射,与输入特征图对应,选出相应大小的区域,和预测出的上采样核作点积,得到输出值。
2.3 损失函数Focal Loss
交叉熵损失函数用来计算实际输出与期望输出的差值,其计算过程如式(4)所示:
[1-p(xi)]log[1-q(xi)]}
(4)
式中:H(p,q)为损失函数;p、q分别为期望和实际输出的概率分布;xi为随机变量;n为随机变量个数。
目标检测算法得到定位目标时会生成大量的anchor box,而图片中真实的目标(正样本)个数很少,大量的anchor box处于背景区域(负样本),因此真实的目标和背景区域数量极不平衡。损失函数Focal Loss可以解决这一问题[18],整体缩放Loss,在缩放程度上易分类样本比难分类样本更大,因而在损失函数中,难分类样本权重发生了变化,难分类样本更明显,模型更专注于难分类的样本,损失函数Focal Loss计算如式(5)所示。
(5)
式中:α平衡正负样本;(1-p)γ为调节因子;γ为可调节的聚焦参数,γ≥0;y为样本标签值;p为判断正样本(y=1)的概率,p∈[0,1]。
在Focal Loss中,α对应正样本(占比少的类)的权重,且一般值较小;γ占主导地位,随着γ的增大,α要相应减小。
3 算法试验与测试
3.1 数据图像采集与预处理
数据集来自东北大学,热轧带钢存在6种缺陷,如图6所示,缺陷数量统计如图7所示。数据集存在数据分布不均匀、部分缺陷特征不明显和数据量少等问题,通过图像随机裁剪拼接、图像镜像反转、旋转、滤波模糊等操作,提高了图像的数据量和数据质量。

图6 缺陷图
3.2 模型配置及训练
实验环境为Windows 操作系统,使用pytorch框架,GPU为NVIDIA GeForce RTX 3080Ti,其内存为12 GB,加速库为CUDA 11.1。

图7 缺陷数量统计
3.3 评价指标
评价指标为mean average precision(mAP),先要得出true positives(TP)、true negatives(TN)、false positives(FP)、false negatives(FN),TP为被模型识别正确且被判断为正样本的样本数量,TN为被模型识别正确且被判断为负样本的样本数量,FP为模型识别错误,样本是负样本但是被识别为正样本的样本数量,FN为模型识别错误,样本是正样本但是被识别为负样本的样本数量。
Precision即精度,指的是分类器认为是正类并且确实是正类的部分占分类器认为是正类的比例,计算如式(6)所示。
(6)
Recall即召回率,指的是分类器认为是正类并且确是正类的部分占所有确实是正类的比例,计算如式(7)所示。
(7)
每个分类都可以得到Precision-Recall曲线,它下面的阴影部分的面积就是该类平均精度(average precision,AP)的值,如图8所示,计算公式如式(8)所示。
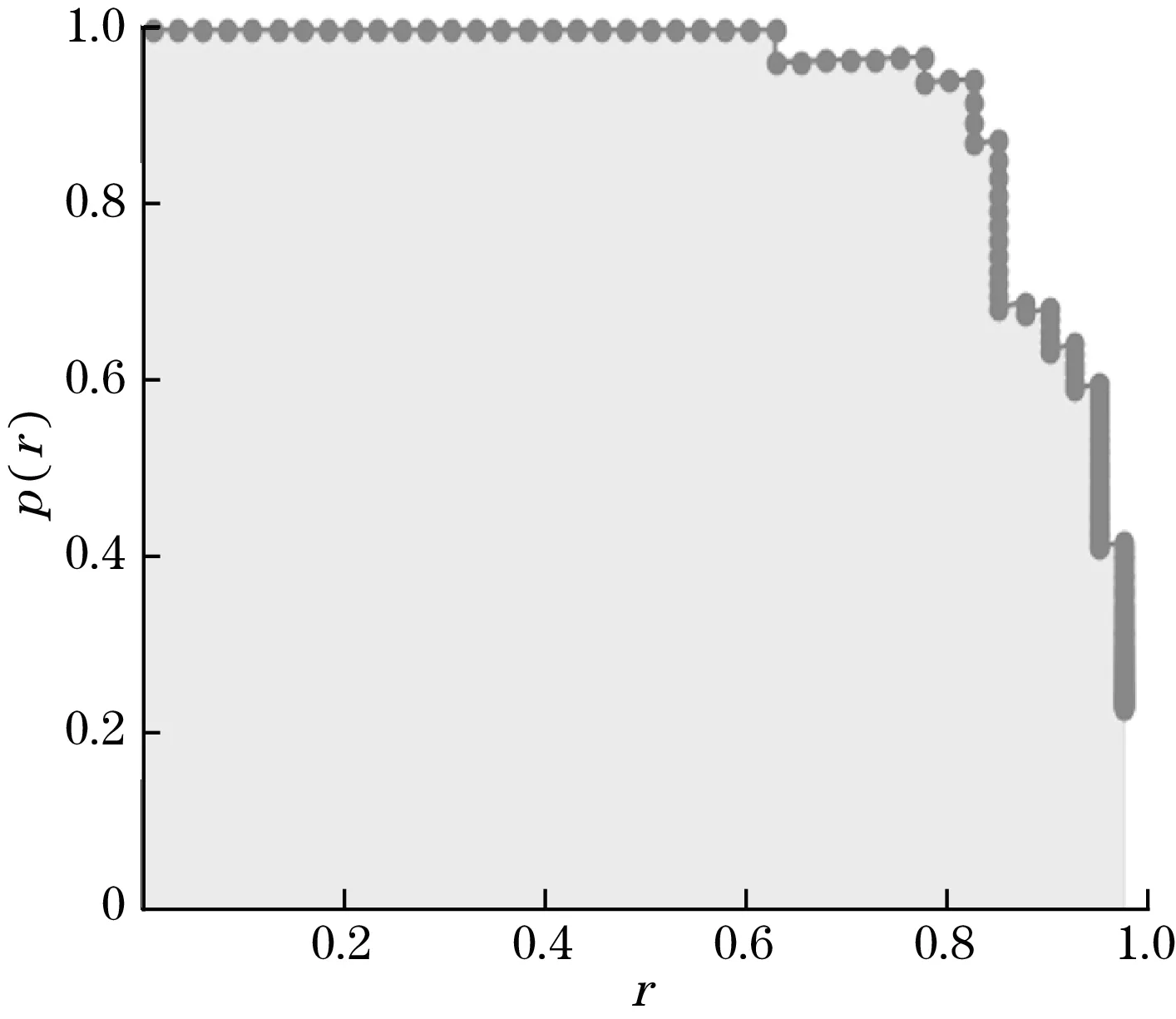
图8 AP曲线
p(r)即Precision,r即Recall。
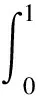
(8)
如果置信度设置的高,预测的结果和实际情况就很符合,如果置信度低,就会有很多误检测,需要将二者进行结合计算。最终对所有的AP值进行求平均,求得平均均值精度(mean average precision,mAP),计算如式(9)所示。
(9)
式中:m为缺陷的种类;APi为第i种缺陷的AP值。
4 实验及结果分析
根据改进方法,分别进行实验,同时调整参数,用相同的训练集进行训练,得到对应的权重文件,最后用相同测试集,分别进行检测。训练集的检测结果如图9所示。

图9 检测结果
YOLO V3与Faster RCNN、Cascade RCNN检测结果对比如表1所示。与YOLO V3相比,Faster RCNN的mAP值提升了11.54%,检测结果显著提升,而且检测速度相差不大,能够满足工业需求。Cascade RCNN与Faster RCNN相比,mAP值提升了3.19%,检测能力得到了提升,虽然检测速度降低,不过仍能满足生产时的需求。
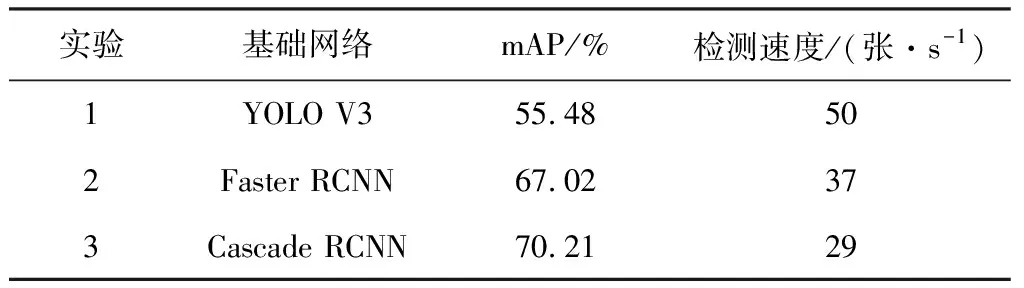
表1 3种基础网络检测结果对比
通过4组实验,对改进网络进行测试,得到的结果如表2所示。

表2 不同实验及其结果
由表2中的检测结果显示,改进后的模型的检测能力不断得到提升,经过4次改进,mAP值提升了7.61%,与原始的Faster RCNN相比,提升了10.8%;与YOLO V3相比,mAP值提升了22.34%。采用的可切换空洞卷积,增大了感受野,使得mAP值提升了2.17%,效果明显;PAFPN增加了新的连接方式,mAP值提升了1.78%;改变特征金字塔的上采样算子,使用特征上采样算子CARAFE,mAP值增加了2.19%;最后使用损失函数Focal Loss解决数据不平衡问题,mAP值达到77.82%。在这些改进方法中,mAP值最少提升了1.47%,最多提升了2.19%,排除了实验随机性对结果的影响。
YOLO V3、原始Cascade RCNN以及改进的 Cascade RCNN中,不同缺陷的AP值如表3所示。
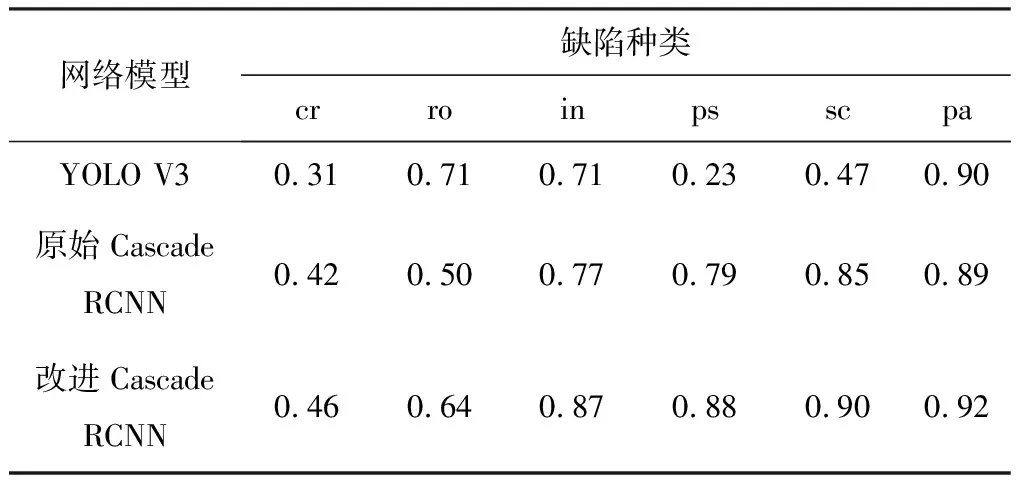
表3 不同缺陷的AP值
表3中,对于改进的Cascade RCNN,斑块(pa)、划痕(sc)、麻点(ps)和夹杂(in) 4种缺陷的AP值都超过了87%,最高的达到了92%,检测结果较好,但是对于裂纹(cr)和氧化皮(ro),AP值分别为46%和64%,检测结果较差,严重影响了模型的检测精度。在图像处理和网络结构改进中,这2种缺陷的检测能力得到了提升,AP值分别提升了4%和14%,但是还需要改进网络,以此提升对这2种缺陷的检测能力,进而使整体检测效果得到改善。与其他的检测结果对比如表4所示[2,19],改进的Cascade RCNN取得了较好的结果。

表4 与其他模型检测结果对比
实验证明,经过上述方法对模型改进优化,模型检测精度得到提高。
5 结束语
针对人工检测效率低和精度差,以及数据集存在数据分布不均匀、部分缺陷特征不明显和数据量少等问题,提出了改进的Cascade RCNN模型,先对数据集进行处理,再将可切换空洞卷积、PAFPN、特征上采样算子和损失函数Focal Loss等加入模型。
为了验证改进后模型是否有效,用测试集检测,对效果进行评价。研究结果表明,检测精度与原始的网络相比,得到了很大的提升;与已有的检测网络相比,检测精度也得到了一定程度的提高,显示出本方法的优越性,为工业现场的自动化检测提供了可靠支撑。然而对于部分缺陷,检测效果并不好,在接下来的工作中,从图像处理和模型处理2个方面,继续进行改进。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
制造技术与机床(2019年9期)2019-09-10
电子制作(2019年11期)2019-07-04
西南交通大学学报(2018年6期)2018-12-18
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
