
基于麻雀搜索算法和SVM的学生成绩预测研究
2023-09-22 06:31张广海
池州学院学报 2023年3期
张广海,祖 璇
(安徽师范大学皖江学院a.电子工程系;b.经济系,安徽芜湖 241003)
随着信息技术的不断革新,大数据分析技术已被应用到了各个领域,进而推动着社会的进步和发展。在大数据时代,如何利用数据挖掘方法探索出教育发展规律,从而有针对性地丰富教学模式、帮助同学们改进学习过程,成为目前急需解决的问题。研究[1]发现,学生期末考试成绩与平时测试、学生学习行为、学生学习背景及父母行为等有关。因此根据学生平时学习的各种因素,可以有效预测出学生的期末考试成绩,使老师和学校提前发现问题,及时进行干预。
针对学生成绩预测,国内外许多科研人员都开展了大量的研究。目前已有多种学生成绩预测的模型,大致可分为两类:基于神经网络模型和基于概率统计模型[2]。姚明海等[3]把BP(back propagation)神经网络引入高校学生成绩预测中,实验表明大一成绩与学生的毕业成绩间存在关联关系。王芮[4]采用联合粒子群算法(particle swarm optimization,PSO)和BP神经网络(PSO-BP)对目标课程学习成绩进行预测。郭华伟等[5]采用SVM 分类器对训练样本进行训练学习,并通过PSO 优化SVM 的参数,从而建立体育成绩预测模型。刘艳杰等[6]利用贝叶斯网络推理的联合树算法预测学生成绩。FRANCIS B K等[7]运用聚类和分类相结合的算法构建成绩预测模型。线性回归[8-10]、决策树[11-13]等基于概率统计的模型也被用于学生成绩预测。目前,用于学生成绩预测的机器学习算法还有SVM[14-16]、最小二乘支持向量机[17]、推荐算法[18]等。
在分类领域中,SVM 模型的分类效果普遍较好,当数量集较少时分类准确率较高且泛化能力强[19-20]。但是,SVM 分类器的惩罚因子c 和核函数参数g 难以确定,如果将其直接用于学生成绩预测,预测的准确率相对较低且运行效率不高。麻雀搜索算法(sparrow search algorithm,SSA)[21]是一种新型智能优化算法,该算法主要受麻雀捕食行为启发。算法具有全局搜索寻优能力强、稳定性高且收敛速度快等优点,可以有效优化SVM 分类器的参数。因此,提出了一种基于麻雀搜索算法优化SVM(SSA-SVM)的学生成绩预测模型,实验结果验证了该方法的性能与可行性。
1 算法原理
1.1 SVM分类算法
SVM 是在统计学习和结构风险最小化理论的基础上发展起来的[22-23]。考虑到结构风险是训练误差和建模复杂性之间的合理权衡,因此SVM 具有很好的泛化能力,其思想是发现一个超平面来区分正负样本。
为了获得最优超平面分类样本,SVM 通过核函数将输入空间映射为高维特征空间。首先必须进行二次规划优化:
其中:ξi是一个松弛变量,用于控制训练误差并保持约束;c是惩罚因子,其值越高,表示对误差的容忍度越差,此时容易出现过拟合,反之,则容易出现欠拟合;Φ(xi)是方程系数。
其次,由于RBF 核函数可以直观有效地反映出两个数据向量之间的距离,因此选择径向基核函数:
其中,g为核函数参数,其值影响模型的训练速度和预测速度。
1.2 麻雀搜索算法
2020 年,受麻雀捕食行为启发,薛建凯等人提出了麻雀搜索算法。根据设定,麻雀算法事先将模拟麻雀分为三类:发现者、加入者和警戒者。
发现者不仅需要负责寻找食物,还肩负着引导整个种群移动的任务。因此,发现者可以在更广泛的位置和区域寻找食物。其位置更新公式为:
其中,X是一个矩阵,表示麻雀的位置,如式(5)所示。所有参数及说明如表1所示。

表1 公式(4)、(5)相关参数及说明
加入者时刻盯着发现者,当其感知到发现者找到好的食物,他们会立刻向发现者聚集,去抢夺食物。其位置更新如公式(6)所示:
其中,A+=AT(AAT)-1。其余参数及说明如表2所示。

表2 公式(6)、(7)相关参数及说明
在整个种群中,一般设定10%到20%的麻雀充当警戒者,且随机产生初始位置。其位置更新公式为:
其中,所有参数及说明如表2所示。
为提高SVM 的预测准确率,采用SSA 优化SVM,即通过不断迭代获得全局最优位置Xbest来确定SVM的惩罚因子c和核函数参数g。
2 学生成绩预测模型
基于SSA-SVM的学生成绩预测流程分为三个部分:数据预处理、SSA 优化SVM 参数和分类预测。流程图如图1 所示。
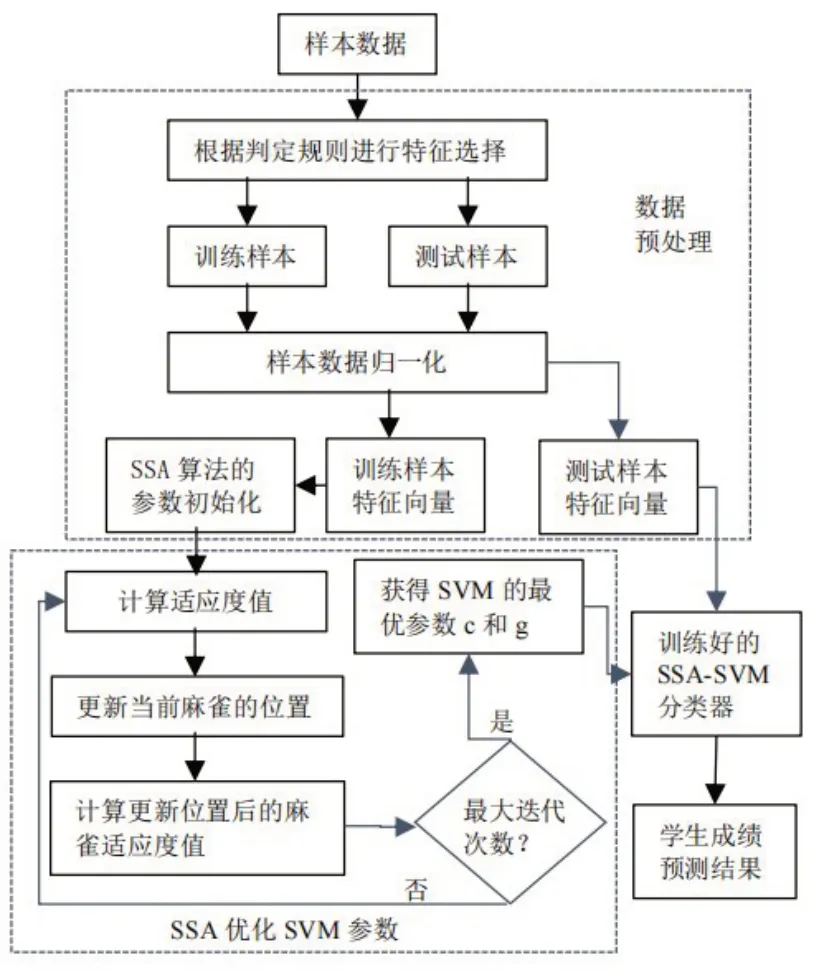
图1 SSA-SVM学生成绩预测流程图
(1)数据预处理
为了对数据进行预处理,需要筛选和清洗原始特征。将样本数据根据学生学习习惯等判定规则进行特征选择;数据集中的原始特征包含整型与字符型,需要将字符型进行类型转换,即字符型特征数值化。例如将“Yes”和“No”分别置换为1和0;将处理后的数据样本按比例随机分为训练样本和测试样本;将分类后的样本数据利用公式(8)进行归一化处理。
式中,xi为第i 个样本的归一化值,xmin、xmax为选取数据集中的最大值和最小值。
(2)SSA优化SVM参数
对训练样本特征向量进行训练,利用SSA算法优化SVM 参数,将预测准确率作为适应度函数。根据适应度值不断迭代更新麻雀的最优位置和全局最优解,若达到最大迭代次数,则获得最优的惩罚因子c和核函数参数g。
(3)分类预测
利用训练好的SVM 分类器进行分类预测,将优化好的两个参数带入,对学生成绩预测结果进行验证。
3 实验结果分析
3.1 数据准备与评价指标
(1)数据集
为了验证成绩预测模型的真实有效性,选用的数据集来源于UCI Machine Learning Repository(https://archive.ics.uci.edu/ml/datasets/Student + Performance),由葡萄牙米尼奥大学(Universidade do Minho)的Paulo Cortez 提供[24]。数据集中共有两个文件,分别包含两所中学学生的数学(UCI-Mat)成绩和葡萄牙语(UCI-Por)成绩,数据属性包括人口特征、学生学习行为特征和家长特征等。两种数据集调查方法和数据属性基本一致,所以随机选取了数据集UCI-Mat作为样本数据集进行实验。
(2)评价指标
学生成绩预测领域有4个主要评价指标,分别是准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1-score)。
如公式(9)所示为准确率,它是指在所有样本中,预测正确的样本所占的比值。
如公式(10)所示为精确率,它是指在所有预测为正样本的样本中,实际为正样本所占的比值。
如公式(11)所示为召回率,它是指在所有实际为正样本的样本中,预测正确的样本所占的比值。
如公式(12)所示为F1 分数,它是一个综合评价指标。其值越低,表明模型的稳定性越差;反之,模型的稳定性越好。
其中,设1和0分别为正例和负例,则:
TP:预测为1,实际为1,预测正确。
FP:预测为1,实际为0,预测错误。
FN:预测为0,实际为1,预测错误。
TN:预测为0,实际为0,预测正确。
3.2 数据处理
UCI-Mat数据集中共有33个属性,包括学生所在学校,学生性别、年龄,父母职业、受教育程度,学生行为习惯等,每一个特征对学生的学习成绩都有一定的影响。为重点研究学生的行为习惯特征对成绩的影响问题,利用数据可视化方法分析了所有属性后,从中选取13个属性用于构建预测模型,如表3所示。
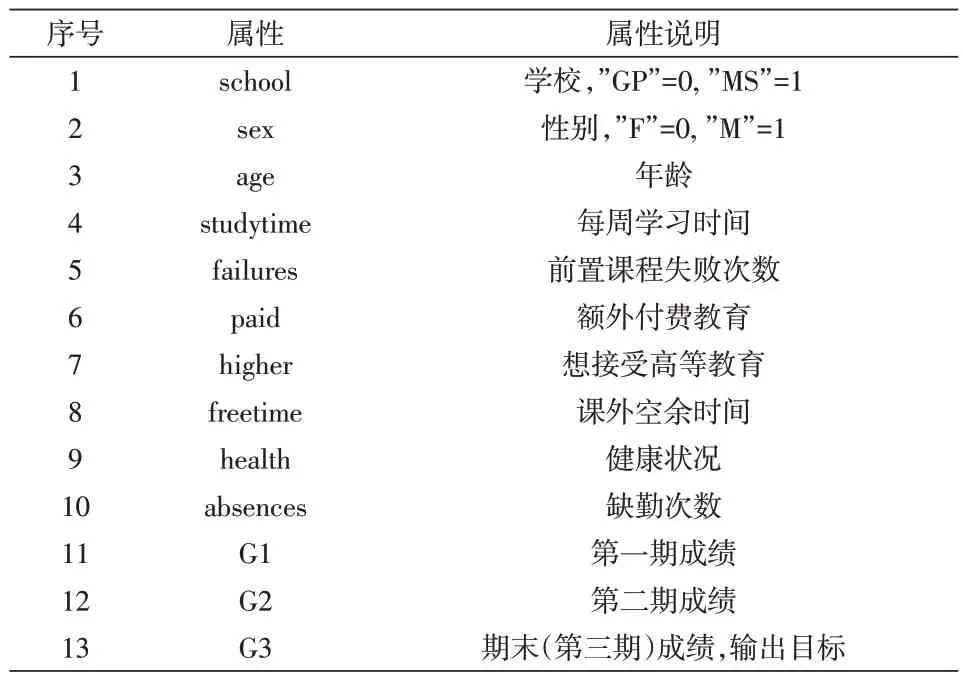
表3 数据集属性信息及说明
本模型主要是对输出目标G3 进行二分类研究,即将学生的期末考试成绩预测结果分为合格和不合格两类。因此,在数据集UCI-Mat中将分数小于等于10 分设为0(0 表示不合格),其余设为1(1表示合格)。之后使用公式(9)所示的准确率来度量二分类问题。
3.3 实验结果与分析
实验在UCI-Mat成绩数据集上进行,对数据预处理后将训练数据与测试数据按照9:1 随机分配。麻雀算法中种群数量设定为20,发现者占比30%,预警值是0.6,迭代次数是30 次,意识到有危险的麻雀占种群数量的20%。
实验采用Python 编程环境,在配置为Intel(R)Core(TM)i5-10210U CPU@1.60GHz、2.11 GHz、内存为16.00G、64位win10操作系统的计算机上进行。
利用SSA 优化SVM 模型后,最优值惩罚因子c和核函数参数g 分别为1.20737689 和0.10390249,学生成绩预测的分类结果如图2所示。由图2中结果分析,在测试过程中,只有2个0类别的样本被误预测成了1 类别。如图3 所示为SSA 适应度曲线,在达到最大迭代次数时,模型的分类准确率为95.0%。
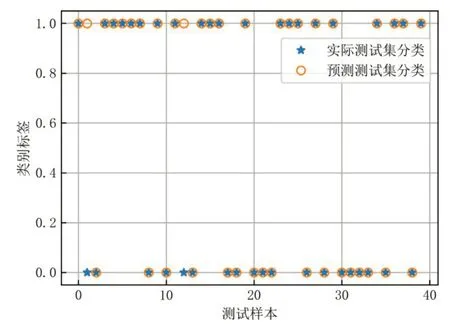
图2 测试集分类结果
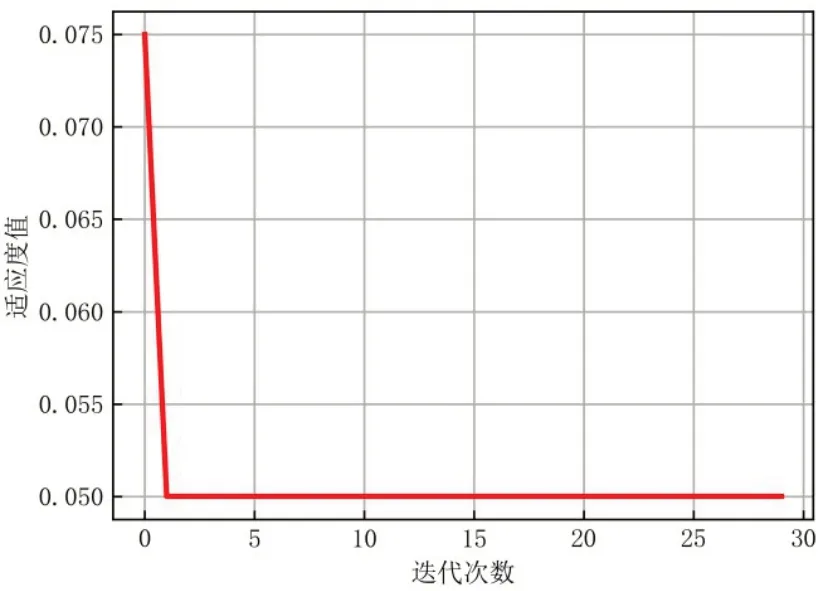
图3 SSA适应度曲线
目标属性G3是第三期(期末)的成绩,G1和G2分别是第一期和第二期的成绩。如果在没有G1和G2的情况下预测G3,其分类结果如图4所示,预测准确率为67.5%。实验结果显示在没有平时成绩的情况下,对期末成绩进行预测,其准确率会大大下降。这说明了平时成绩与期末成绩具有很强的关联性。
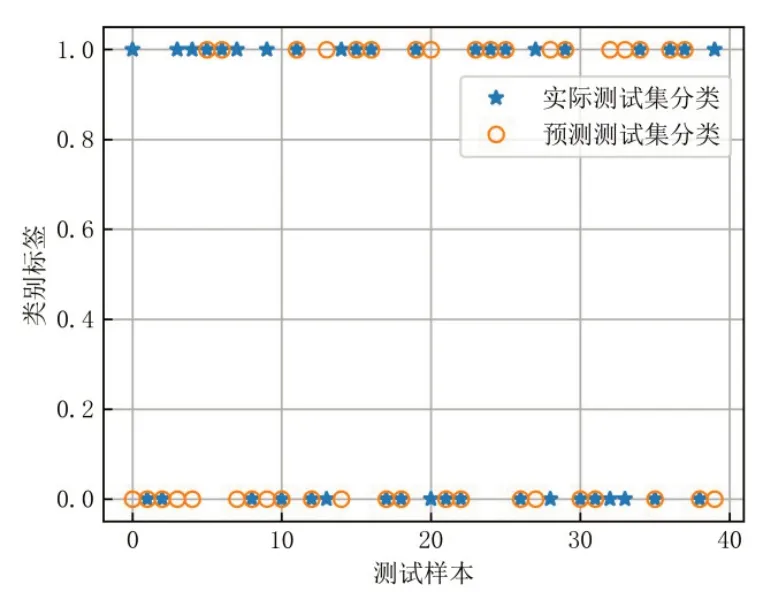
图4 没有G1和G2情况下的测试集分类结果
为了体现SSA-SVM分类预测的有效性和可行性,与SVM、随机森林和BP算法3种分类方法进行了比较,结果如表4 所示。图5 是4 种分类方法性能比较的可视化示意图,可以更直观有效地观测其性能变化。表5为4种分类方法的准确率。
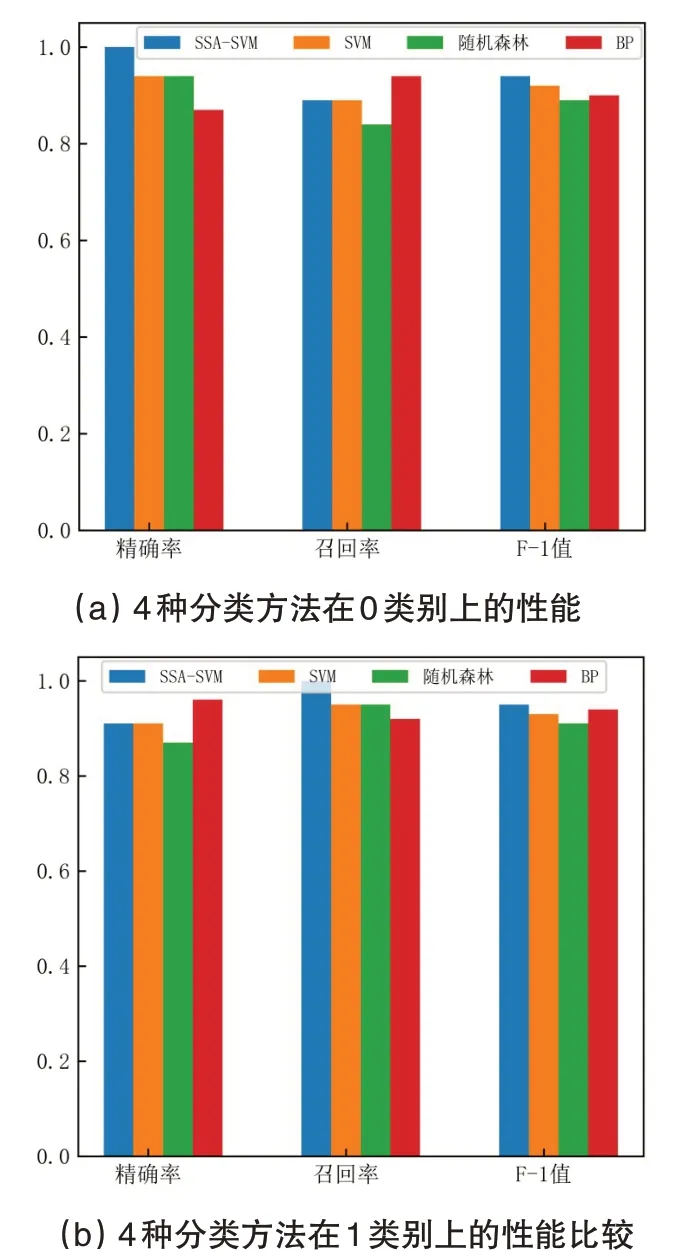
图5 4种分类方法性能比较
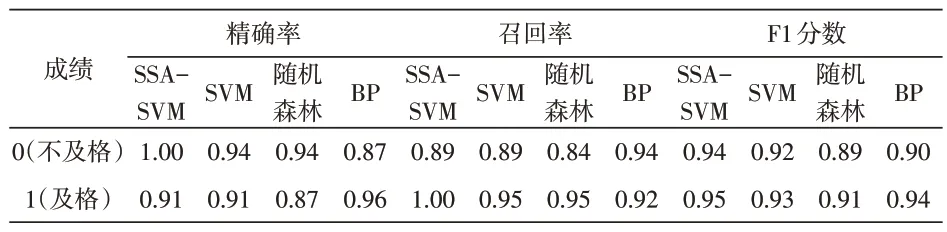
表4 4种分类方法性能比较

表5 4种分类方法准确率比较
对表4 和图5 分析可知:1)在这些学生成绩预测模型中,通过4种方法性能对比,除了基于BP神经网络模型在1类别上的精确率和0类别上的召回率稍高外,SSA-SVM模型具有较明显的优势;2)在0类别和1类别上,SSA-SVM分类预测方法的F1分数都是最高的,说明了该预测模型最稳定,性能最好。
对表5 分析可知:1)SVM 模型准确率仅次于SSA-SVM 模型,达到了92.5%。这是由于在SVM分类器模型中,使用了网格搜索交叉验证方法,目的是最大程度上获取最优超参数,在一定程度上可以获得较好的惩罚因子c 和核函数参数g;2)与其他模型相比,SSA-SVM模型的分类准确率最高,超出了其他方法2.5%,有较强的实用性。
4 结语
为辅助学校和老师适时动态调整学生的学习状态,以帮助其更高质量地完成学习要求,提出了一种基于SSA-SVM学生成绩预测模型。首先利用麻雀搜索算法不断迭代,以期得到支持向量机的最优核心参数,使分类器达到最优效果;然后在UCIMat成绩数据集上,与其他3种方法进行性能对比,证明了SSA-SVM分类方法的优越性。由于数据集样本数量的限制,在一定程度上会影响预测的准确性;麻雀搜索算法也有很大的改进空间,所以下一步的重点工作是合理选择、优化数据集和进一步探究学生成绩预测模型的新方法。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
作文小学中年级(2019年10期)2019-11-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
新世纪智能(高一语文)(2018年11期)2018-12-29
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
趣味(语文)(2018年2期)2018-05-26
